
Customer Churn in Retail E-Commerce Business: Spatial and Machine Learning Approach


Abstract
:1. Introduction
2. Customer Churn in CRM and Modelling—Literature Review
2.1. Quantitative Methods in Customer Churn Prediction
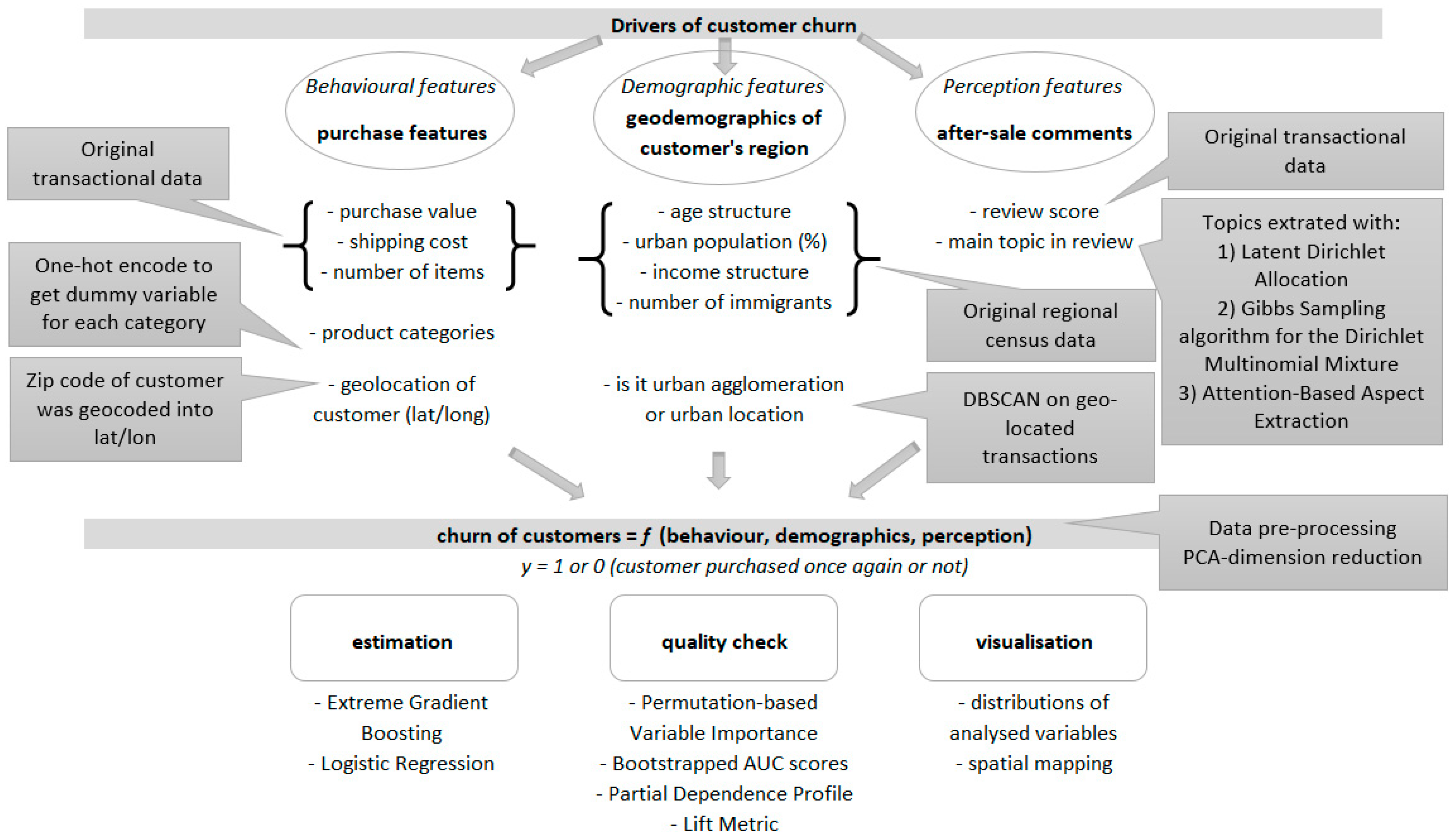
2.2. Information Used in Churn Prediction
- Behavioural—describing how the customer has interacted with the company previously.
- Demographic—describing the customer in terms of their inherent characteristics, independent of their interactions with the company.
- Perception—describing how the customer rate their previous interactions with the company.
3. Methods Used in the Analysis
- Pre-processing the variables present in the dataset so that they can be included in the model.
- Defining the machine learning modelling methods to be used, in particular choice of the metric to be optimised and the type of model.
- Training the model using various sets of variables, and the selection of independent variables which maximise the performance of the proposed model.
- Running the predictions from the selected models.
- The methodology used in this study can be divided into four broad categories:
- Methods used in pre-processing applied to the variables present in the dataset.
- Methods used for variable selection.
- Machine learning modelling methods—choice of model, cross-validation, up-sampling, etc.
- Methods used to check the strength of the variable’s influence.
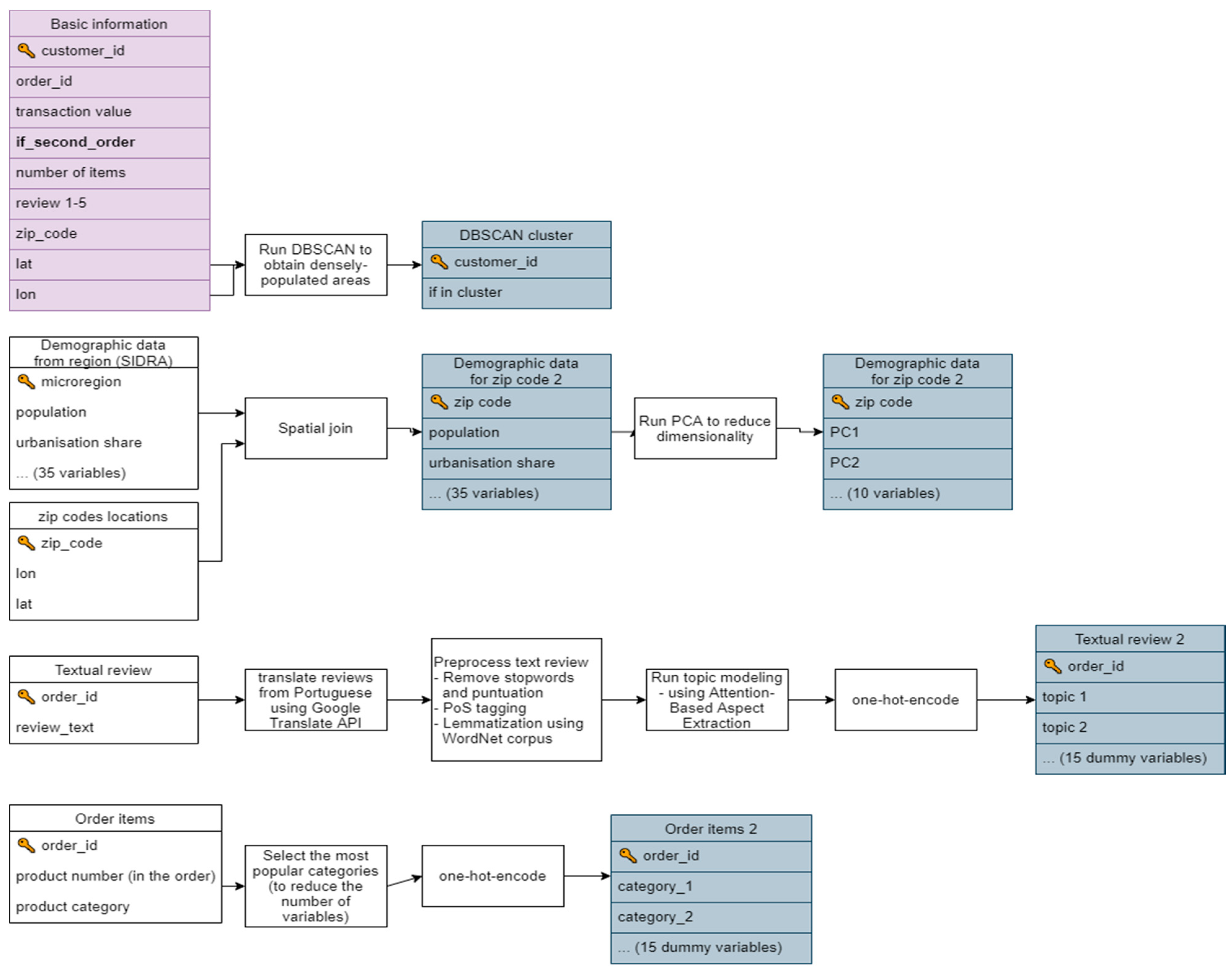
3.1. Data Pre-Processing
- Create the list points_to_visit with all the points from the dataset.
- Assign all points as noise.
- Select a point x randomly from points_to_visit and remove it from the list. Check how many points have a distance to it less than ϵ. If this number is more than k, a new cluster is created that includes all these points. Assign all these points to a list cluster_points. For each of the points from this list, repeat recursively step 3 until cluster_points does not contain any points.
- After creating the previous cluster, select the next random point from points_to_visit and repeat step 3 until all points have been visited.
3.2. Methods for Topic Modelling
- Latent Dirichlet Allocation [53]—because it is a go-to standard for topic recognition.
- Gibbs Sampling algorithm for the Dirichlet Multinomial Mixture [55]—this method is an improvement over LDA, intended primarily for short texts. This is relevant for this case, where most of the reviews were just a couple of words long.
- Attention-Based Aspect Extraction [57]—this method is also meant for short texts, and at the same time, it uses the most modern, state-of-the-art NLP techniques. Furthermore, in the original paper, the authors worked in a similar domain of internet text reviews.
- Consider a text corpus consisting of D documents. Each document D has N words that belong to the vocabulary V. There are K topics.
- Each document can be modelled as a mixture of topics. Document D can be characterised by the distribution of topics θ_D that come from the Dirichlet family of probability distributions. Each topic has a distribution of words φ_k which come from the Dirichlet family. Then, a generative process aimed at obtaining document D of the length of N words w_(1, …, N) is as follows:
- To generate a word at position i in the document:
- ○
- Sample from the distribution of topics θ_D, and obtain an assignment of word w_i to one of the topics k = 1, …, K. This is to obtain information from which of the topics the word should be sampled.
- Sample from the distribution of words in topic φ_k, and obtain the word to be inserted at position i.
- Sample from the distribution of topics θ_D and obtain an assignment of the document to one of the topics k = 1, …, K.
- Sample all words from the topic distribution φ_k.
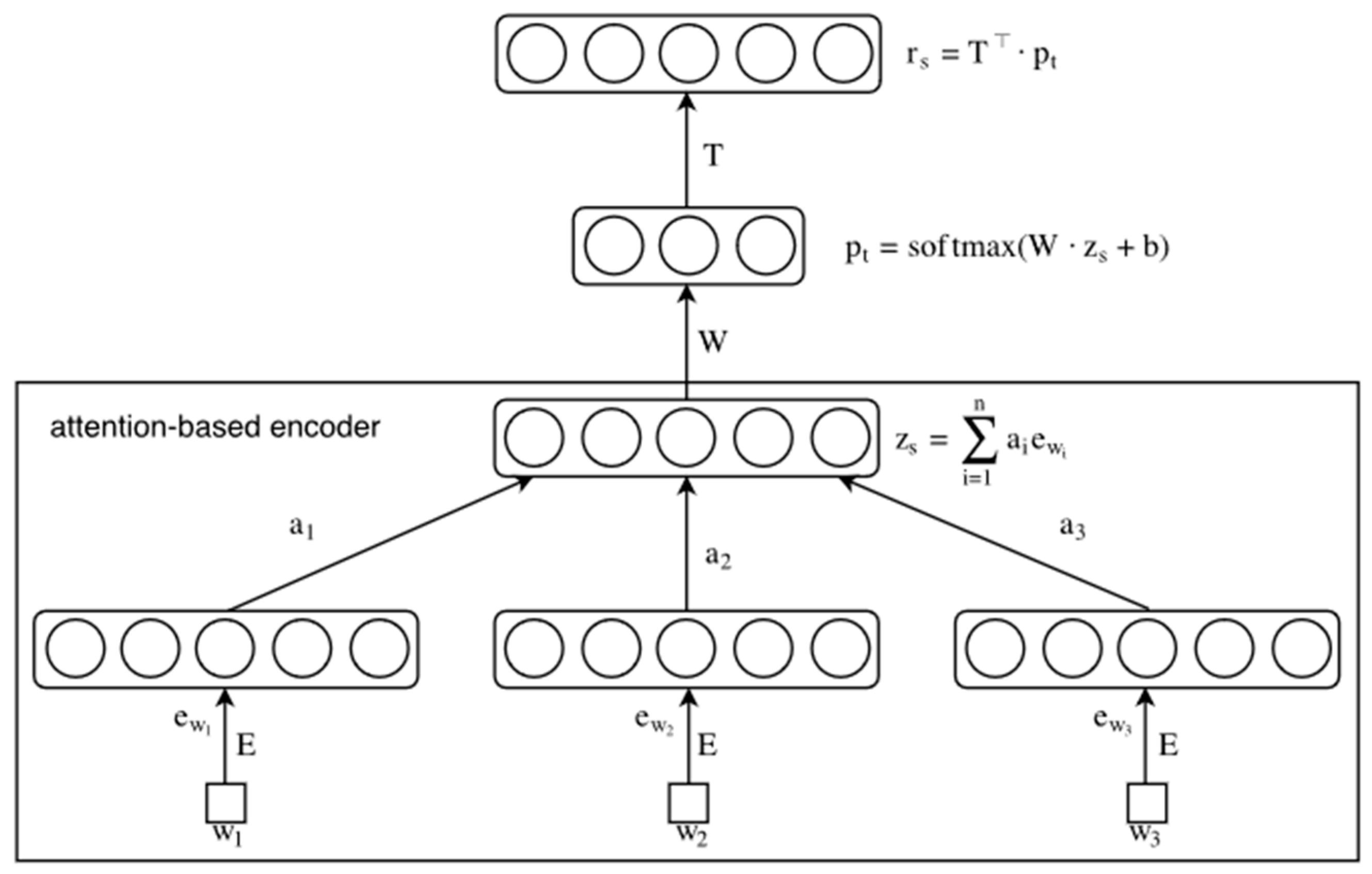
- Calculate the word embeddings e_(w_1), e_(w_2), e_(w_3), … with dimensionality d for each of the words from the vocabulary based on the whole corpus. From this point, one obtains an assignment of the word w to the feature vector e_w in the feature space R^d.
- Obtain document embedding z_s. This is done by averaging the embeddings of all the words from the document. The average is weighted by attention weights a_1, a_2, a_3 given to each of the words. These weights are estimated during the model training and can be thought of as a probability that the particular word is the right word to focus on to infer the document’s main topic correctly. It is worth noting that the document embedding shares the same feature space as the word embeddings.
- Then, calculate p_t using softmax non-linearity and linear transformation W. This vector p_t is of the same dimensionality as the number of aspects to be learned and can be thought of as a representation of the probability that the sentence is from the particular aspect. By taking the biggest probability of this vector, one can obtain the assignment to the particular topic.
- Increase the dimensionality of the vector p_t to the original dimensionality d by transforming it with aspect matrix T. Vector r_s is obtained.
- The training of the model is based on minimising the reconstruction error between the vectors z_s and r_s.
- Translation of the reviews from Portuguese to English. The Olist e-commerce store operates only in Brazil, which is why most of the reviews are written in Portuguese. Google Translate API was used to change their language to English. This is not only to facilitate understanding of the reviews, but also because NLP tools available for the English language are more advanced than for other languages.
- Removal of stop-words and punctuation.
- Lemmatisation using WordNet lemmatizer [60] combined with a Part-of-Speech tagger. This step is needed to limit the number of words in the vocabulary. Thanks to the Part-of-speech tagger, the lemmatizer can change the form of the word on a more informed basis and thus apply correct lemmatisation to more words.
3.3. Variable Selection Methods
- Basic information: the value of the purchase, geolocation in raw format lat/long, shipping cost, number of items in the package, review score (six variables).
- Geodemographic features for the region where the customer is based: age structure, percentage of the population in an urban area, income structure, number of immigrants (35 variables).
- Geodemographic features transformed using PCA (10 variables/components).
- An indicator of whether the customer is in an agglomeration area obtained from DBSCAN location data (one variable).
- Product category that the customer has bought from in prior purchase (15 dummy variables).
- The main topic that the customer mentioned in their review (15 dummy variables).
- basic features
- geodemographic + basic features
- geodemographic with PCA + basic features
- agglomeration + basic features
- product categories + basic features
- review topic + basic features
- all variables (with geodemographic features transformed using PCA)
3.4. Modelling Methods
4. Dataset Statistical Overview
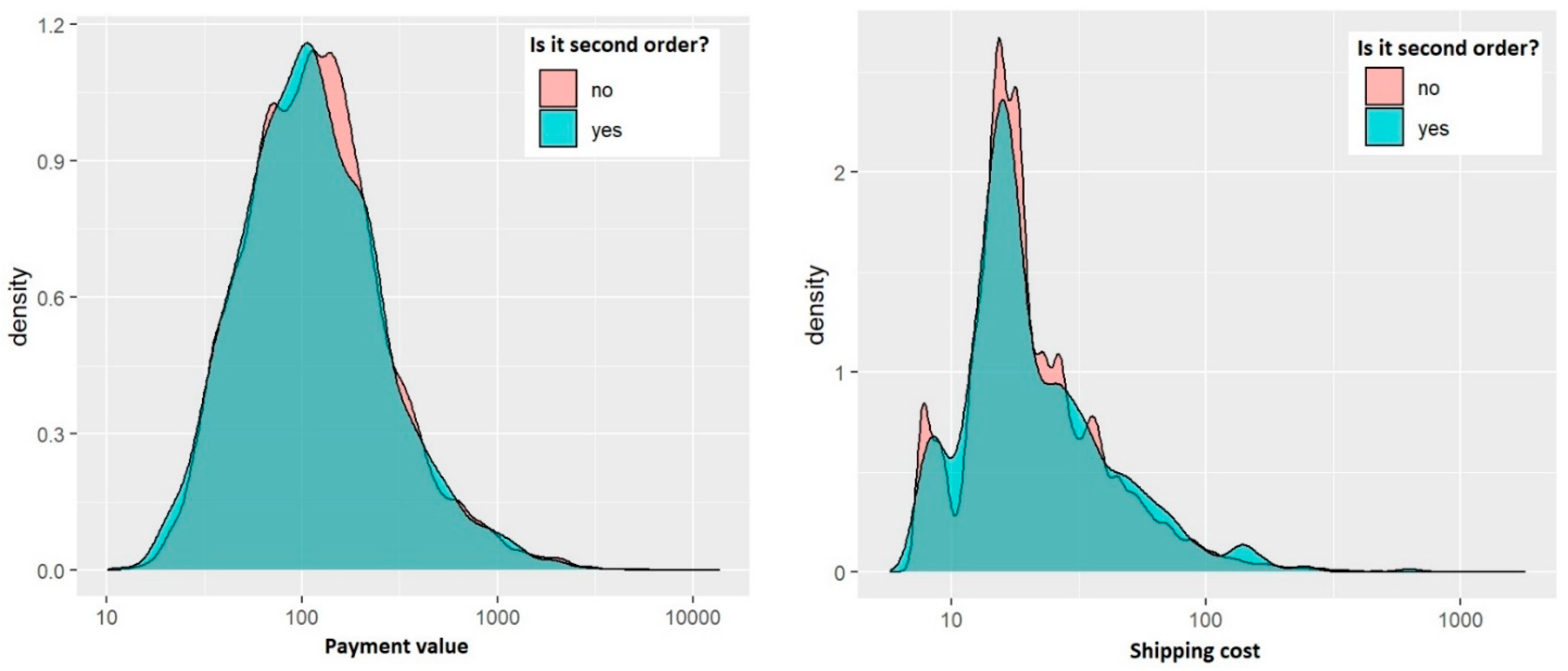
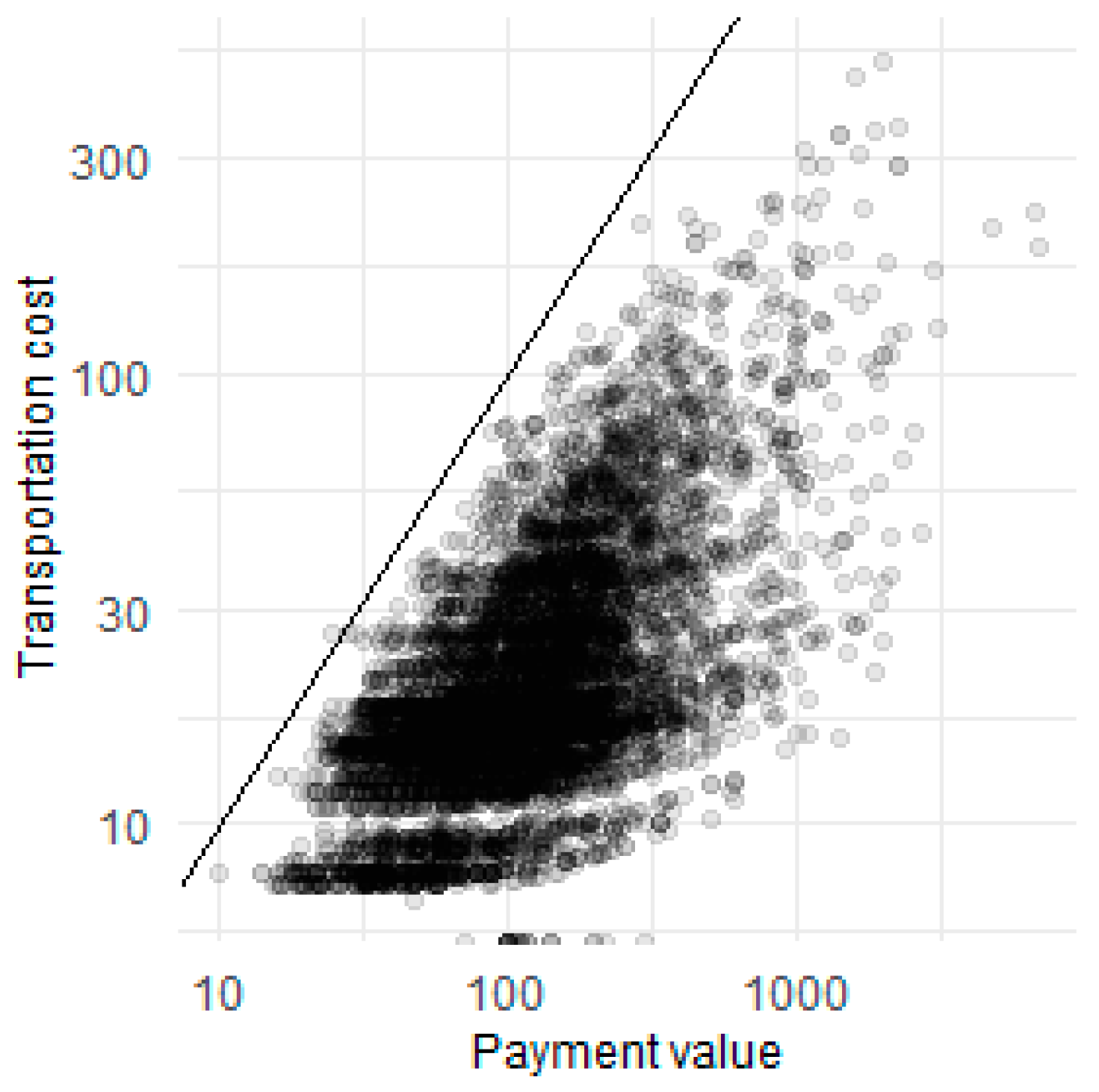
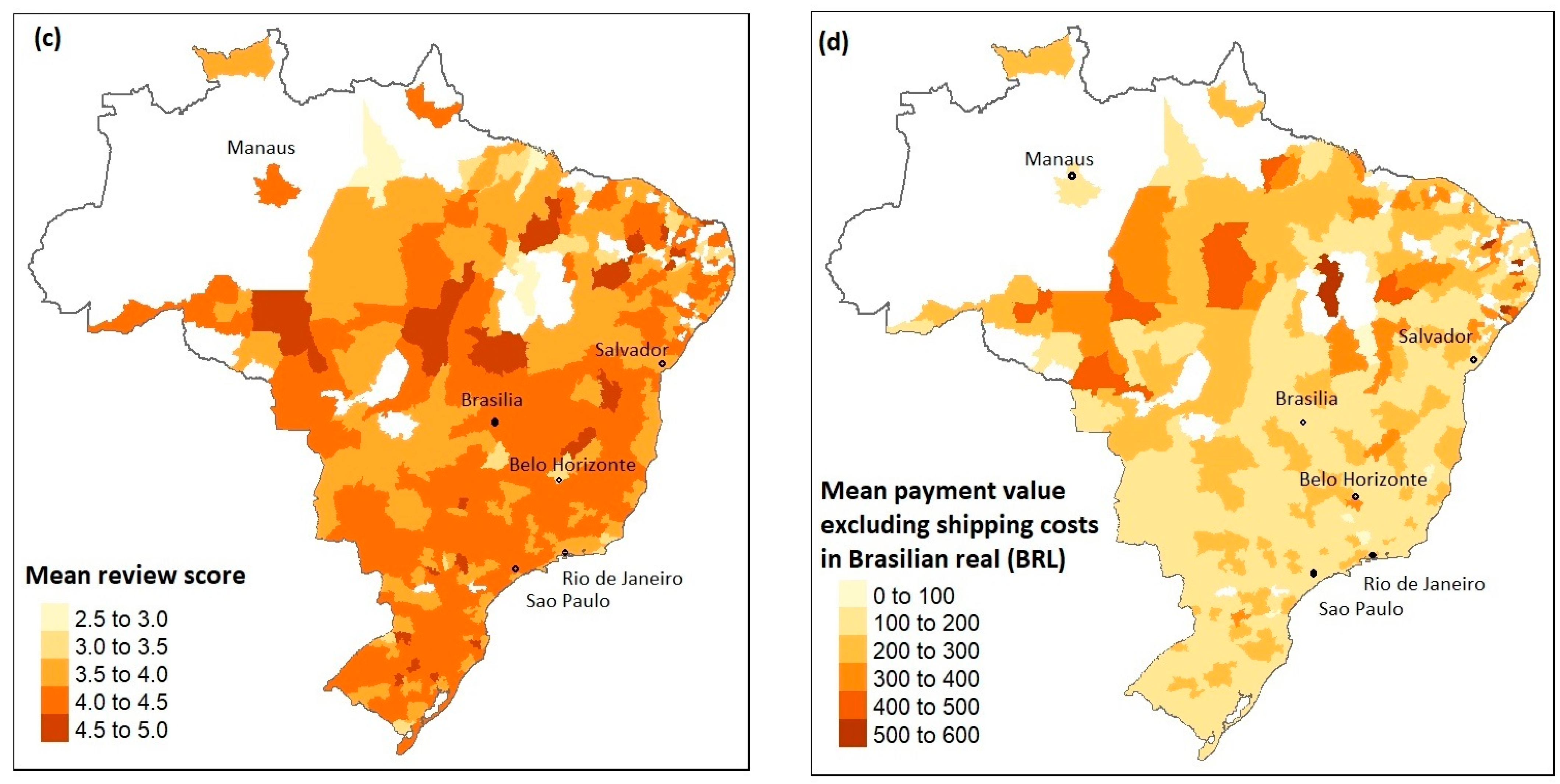
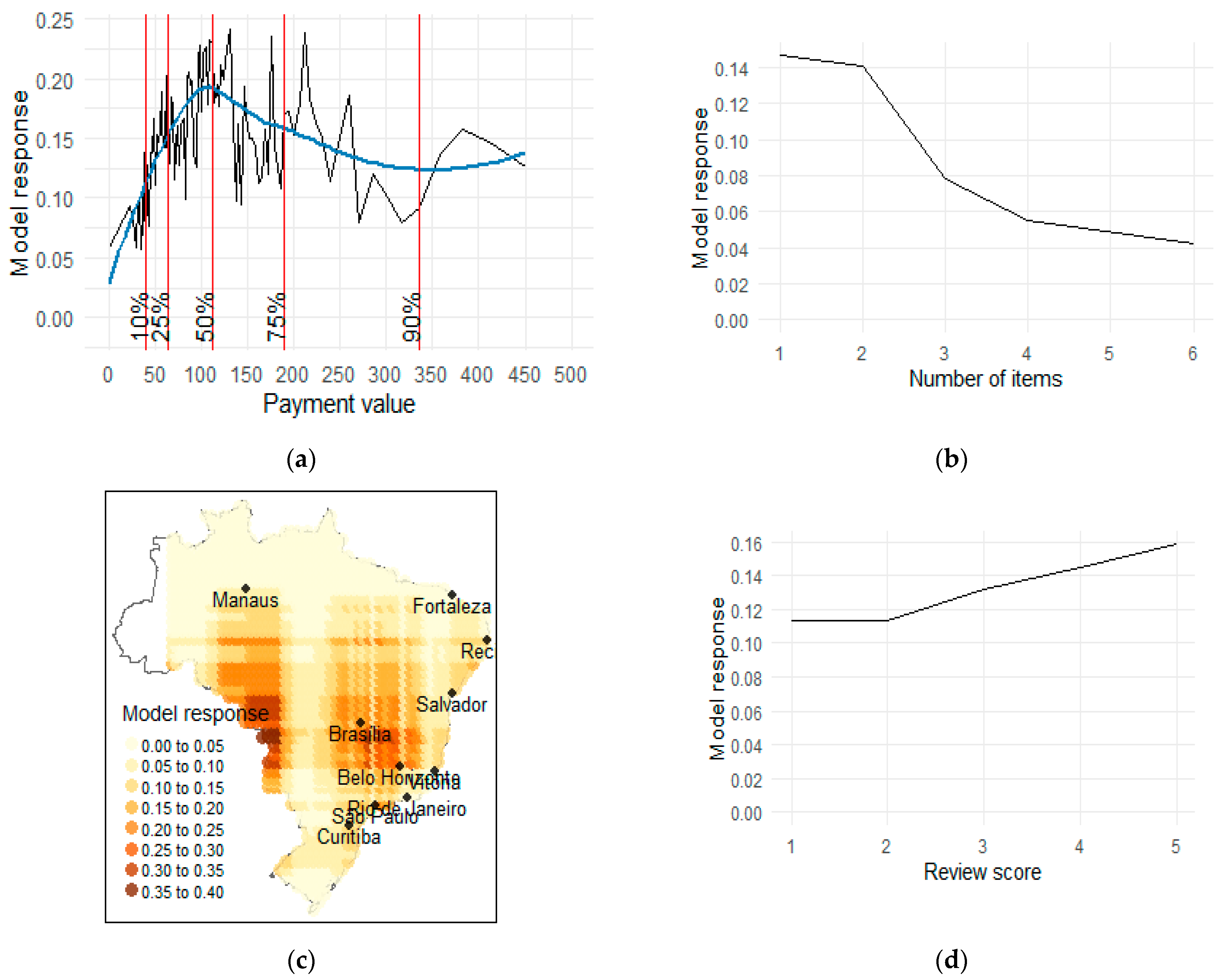
- payment value—the value of the order in Brazilian Reals.
- transportation value.
- number of items the customer purchased in a particular order.
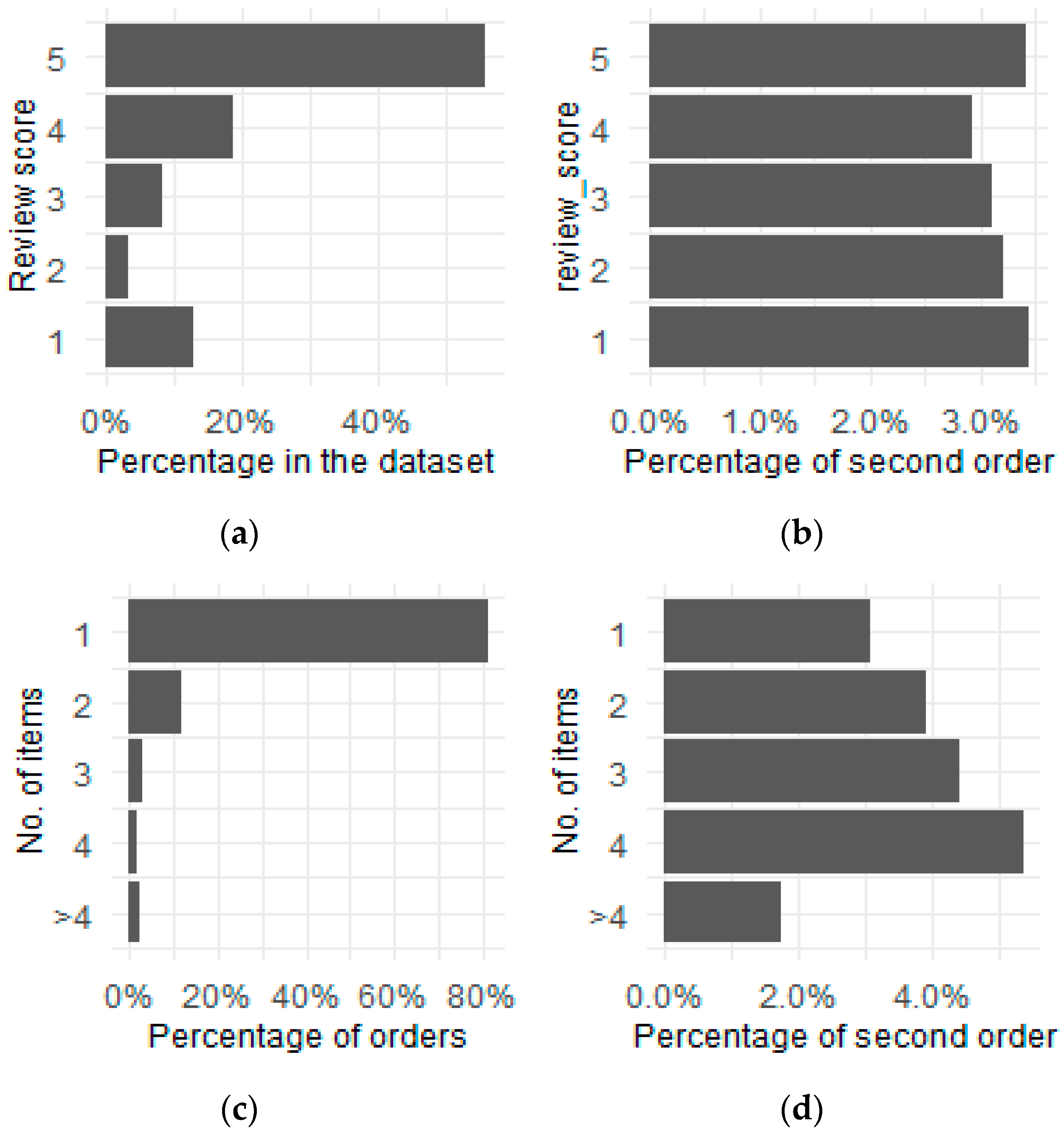
- review of the order—the customer is able to review the finalised order in two forms: on a numerical scale of 1–5 or through a textual review. In the dataset codebook, the authors stated that not all customers wrote reviews, but this dataset was sampled so that the records without a numerical score from 1–5 were excluded. Only 50% of the records contained textual reviews. The data with a numerical review score from 1–5 was included in the models without pre-processing, but the textual reviews were pre-processed.
- location of the customer—the main table containing customer information contains the 5-digit ZIP code of the customer’s home. The company also provided a mapping table in which each ZIP code is assigned to multiple latitude/longitude coordinates. This was probably done for anonymisation—so that one cannot connect the customer from the dataset with their exact house location. To obtain an exact one-to-one customer-geolocation mapping to each zip code, the most central geolocation from the mapping table was assigned. To get the most central point, the Partitioning Around Medoids (PAM) algorithm was used with only one cluster, and the algorithm was run separately for each ZIP code.
- products bought—the dataset contains information about how many items there were in the package, as well as the product category of each item in the form of raw text. In total, there were 74 categories, but the top 15 accounted for 80% of all the purchases. To limit the number of variables used in the modelling process, the label of all the least popular categories was changed to “others”.
- total population of the micro-region: one variable.
- age structure—the percentage of people in a specific age group (where the width of the groups are equal to 5 years): 20 variables.
- percentage of people living in rural areas and urban areas: two variables.
- percentage of immigrants compared to total micro-region population: one variable.
- earnings structure—share of the people who earn between x0*minimum_wage and x1*minimum_wage: 11 variables.
4.1. Statistics of Transactions
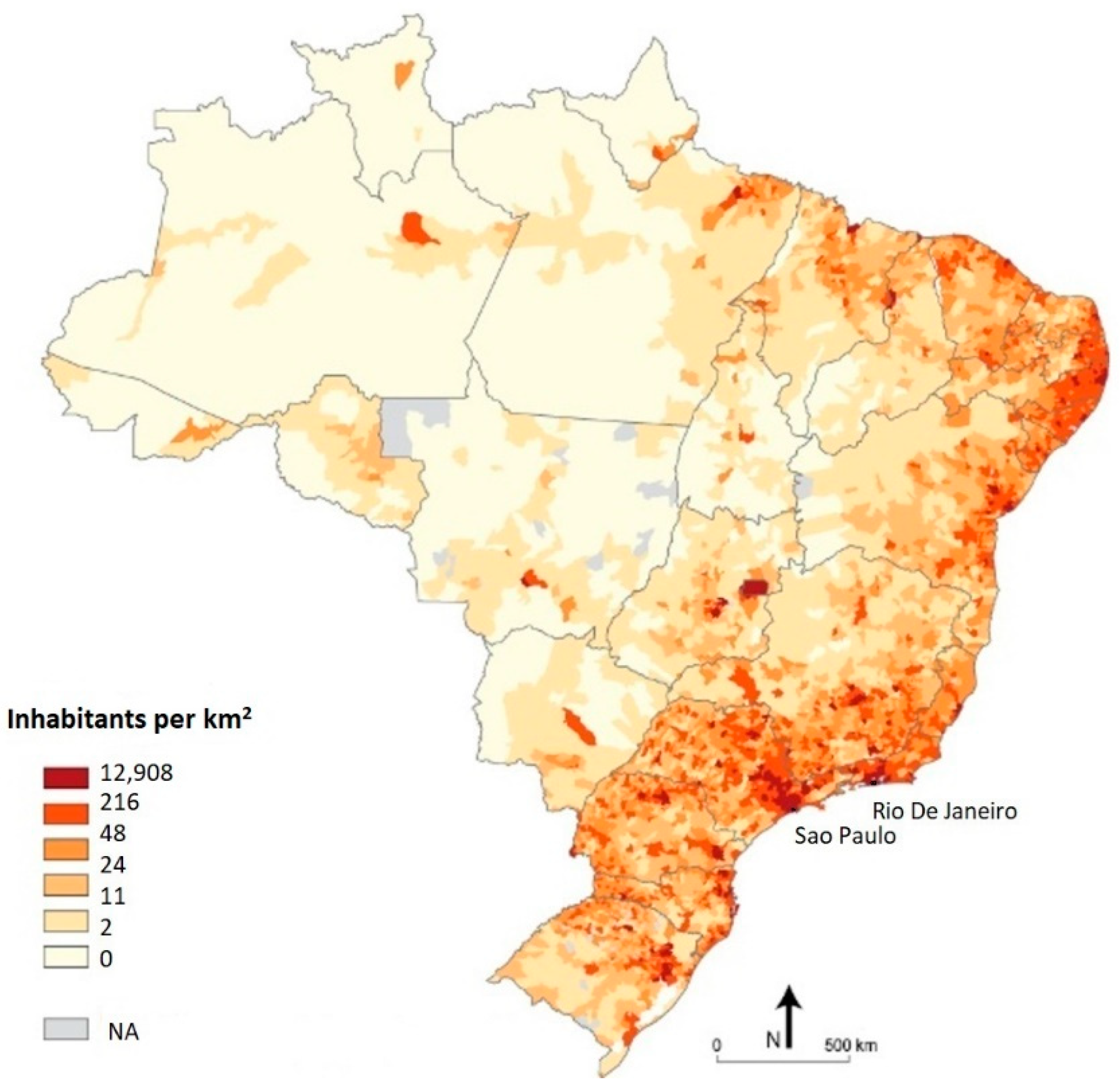
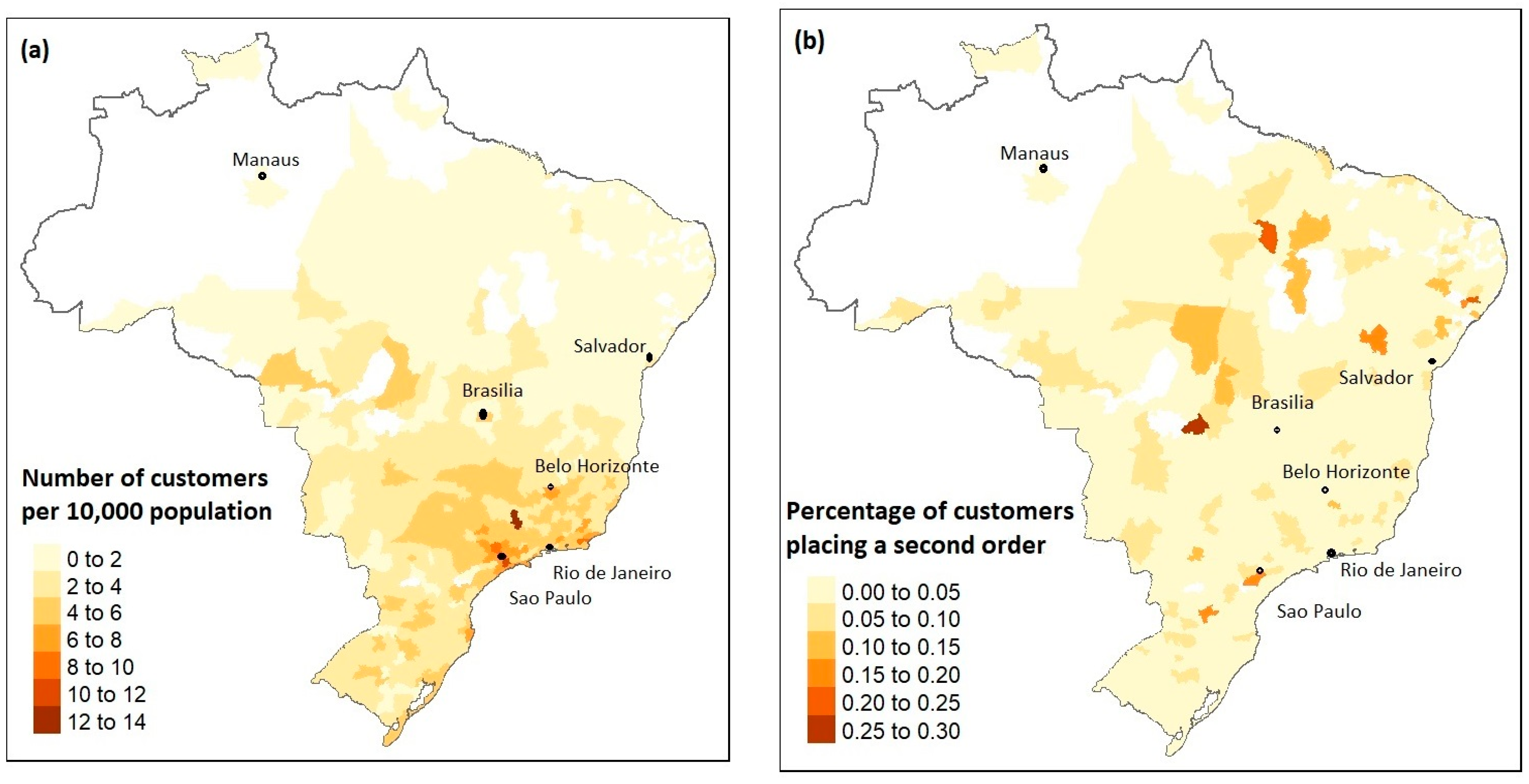
4.2. Spatial Analysis of Data
5. Modelling Results
5.1. Results of the Pre-Modelling Phase
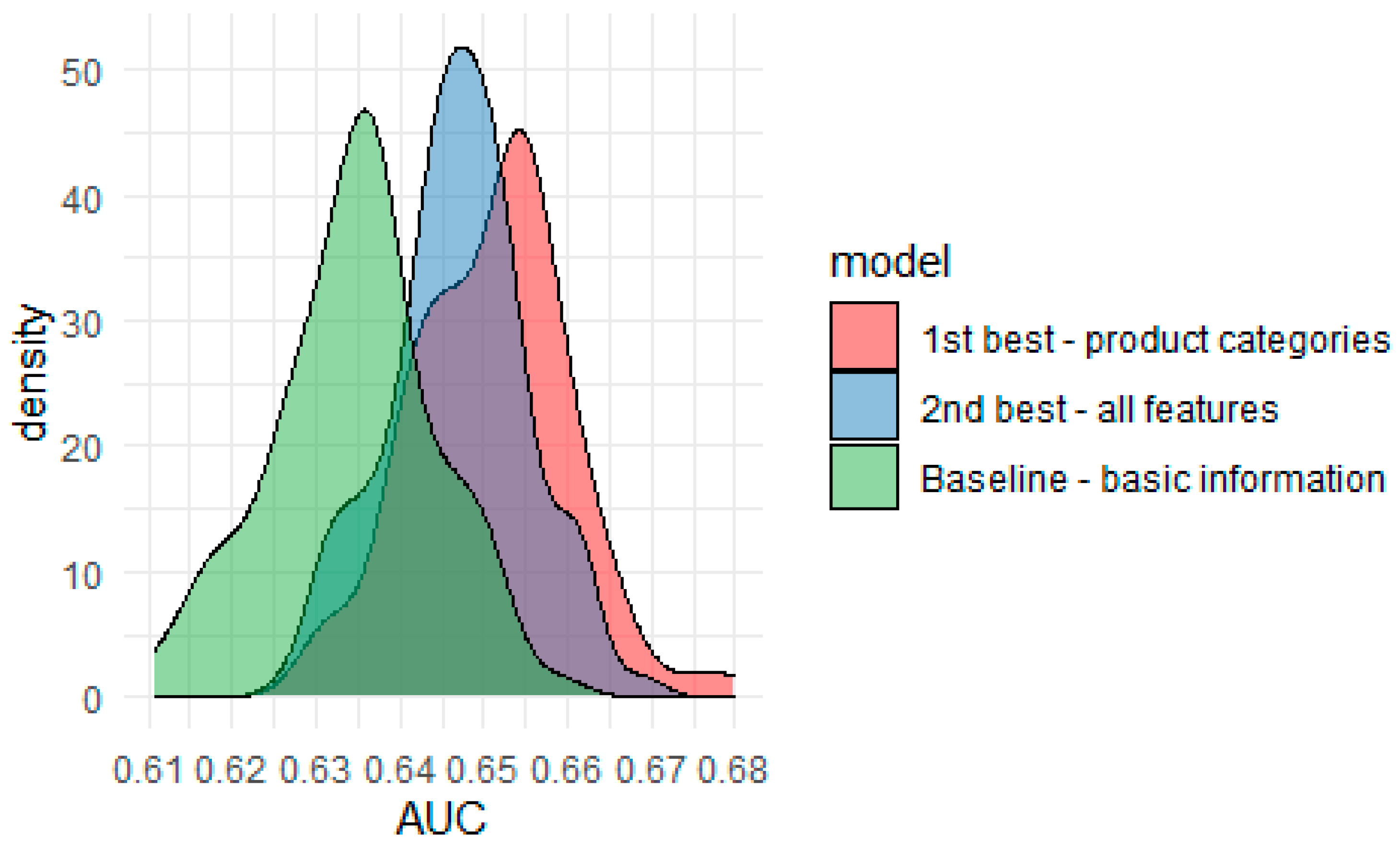
5.2. Performance Analysis
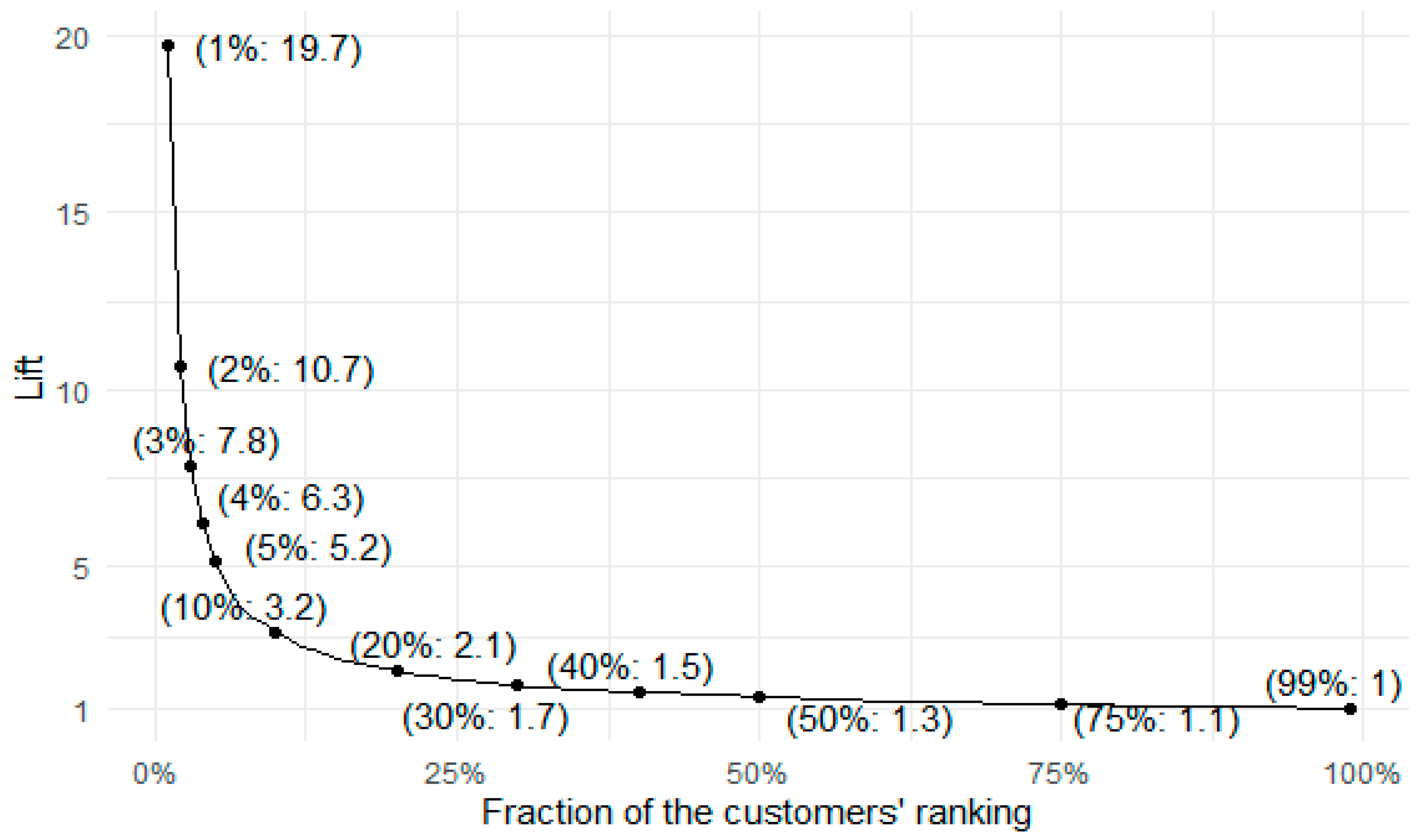
- Sample 5% of all customers. Calculate the share of these customers (share_random), who have a positive response (who truly bought for a second time).
- Using a machine learning model, predict the probability of buying for a second time all the customers. Then, rank these customers by the likelihood and select the top 5% with the highest probability. Calculate the share of these customers (share_model) who have a positive response.
- Calculate the lift measure as share_model/share_random. If the lift value is equal to one, this means that the machine learning model is no better at predicting the top 5% of the best customers than random guessing. The bigger the value, the better the model is in the case of this top 5% segment. For example, if the lift metric is equal to three, the model is three times better at targeting promising customers than random targeting.
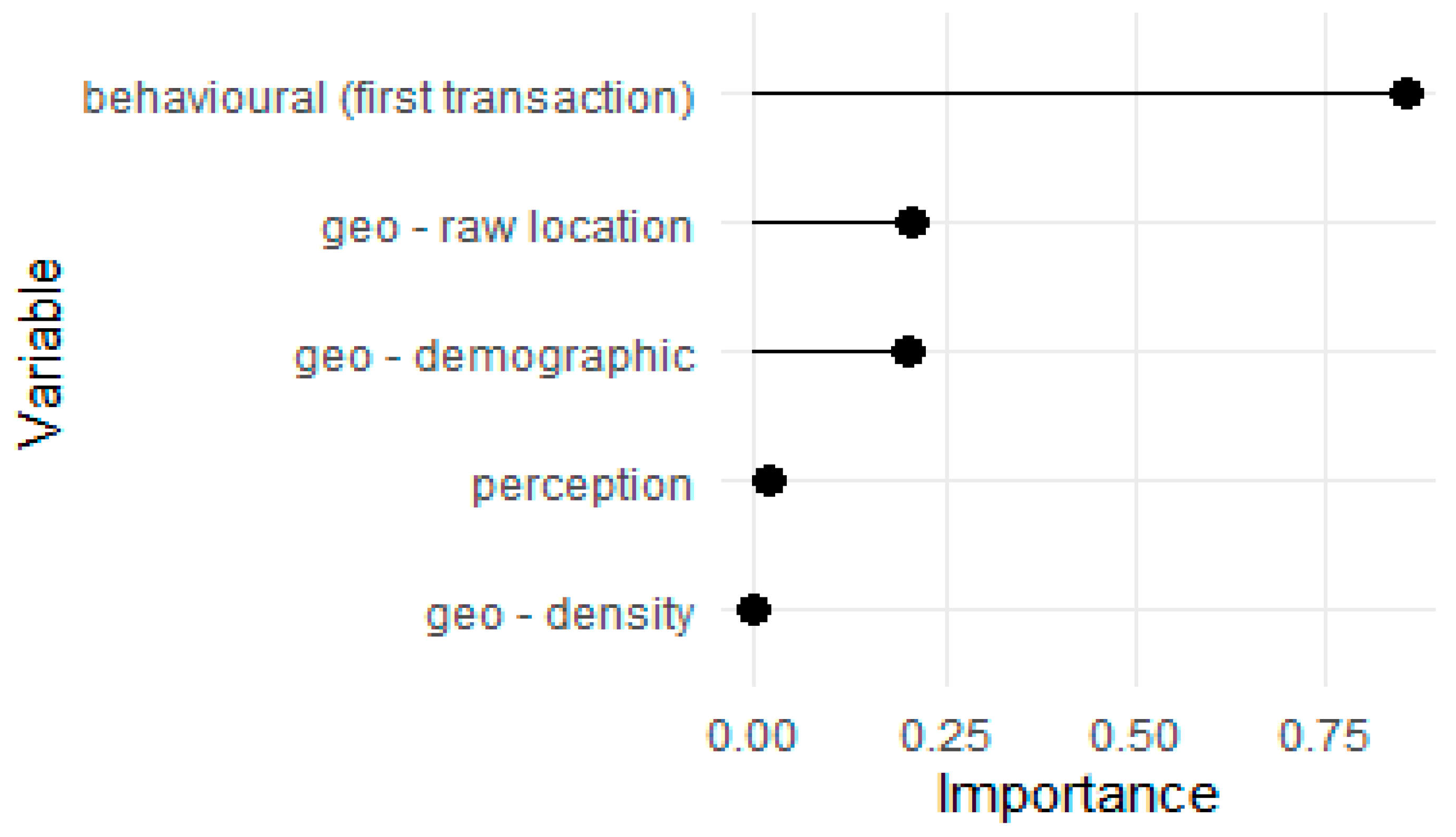
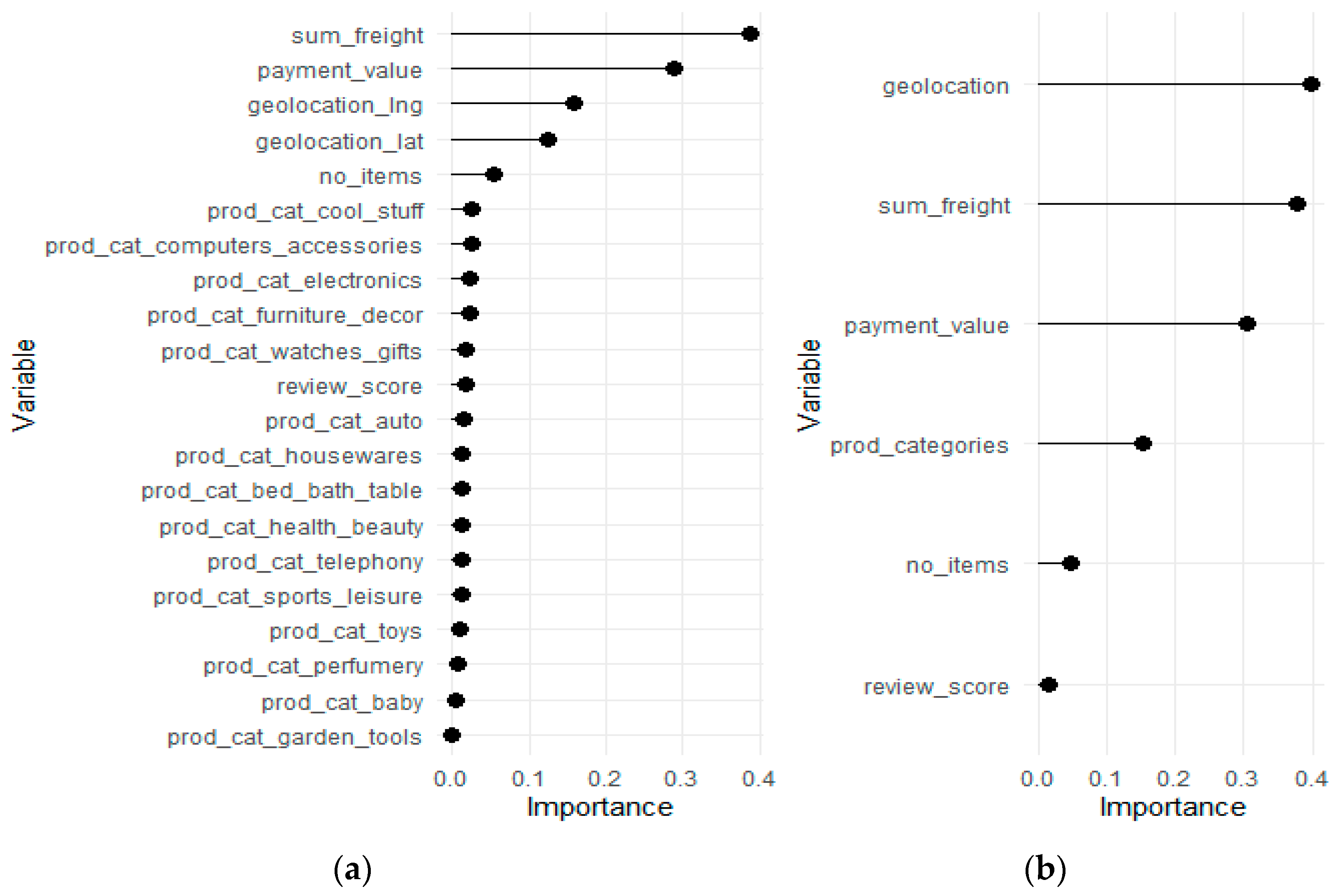
5.3. Understanding Feature Impact with Explainable Artificial Intelligence
- behavioural—variables describing the first transaction of the customer: payment value, product category, etc.
- perception—variables describing quantitative revives (on a scale of 1–5) and dummies for textual (topic) reviews.
- “geo” variables—with three subgroups:
- ○
- demographic variables describing the population structure of a customer’s region.
- ○
- raw location, being simply longitude/latitude coordinates.
- ○
- density variable, indicating whether the customer lives in a densely populated area.
6. Discussion, Implications and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
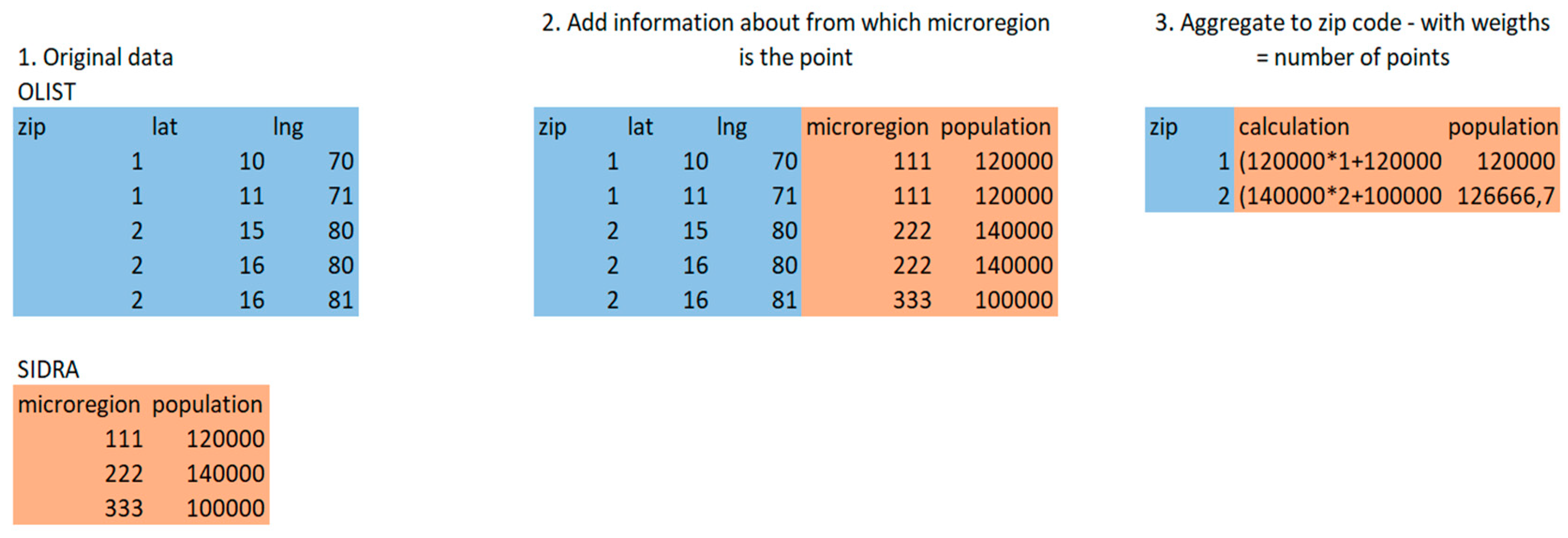
- In the e-commerce dataset, the spatial dimensions are encoded mainly in the form of ZIP codes, while in the demographic dataset they are in the form of micro-regions (a Brazilian administrative unit).
- The boundaries of zip codes and micro-regions do not align.
- The customer’s geolocation data has three columns—zip code and lat/long coordinates. For each zip code, there are multiple entries for coordinates. This probably means that the company has exact coordinates of each of their customers but decided to not provide exact customer-location mapping in the public dataset for anonymisation reasons. Because of this, the boundaries of zip codes cannot be specified precisely, and one has to rely on the particular points from this zip code area.
- For each point in the geolocation dataset, establish in which micro-region it is located, then join the dataset for that region to the OLIST geolocation dataset.
- Group the dataset by zip code and calculate the mean of each of the features in the dataset; in this case, this mean would be a weighted mean (weighted in the form of “how many customers are in this area?”) (An example is shown in Figure A1).

Appendix B

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Topic No. | Topic Description | Number of Reviews | Percent of Customers with Second Order | Example Review |
|---|---|---|---|---|
| 0 | Mentions product | 9720 | 3.2% | Reliable seller, ok product and delivery before the deadline. |
| great seller arrived before the deadline, I loved the product | ||||
| Very good quality product, arrived before the promised deadline | ||||
| 1 | Unsatisfied (mostly about delivery) | 1439 | 2.8% | I WOULD LIKE TO KNOW WHAT HAS BEEN, I ALWAYS RECEIVED AND THIS PURCHASE NOW HAS DISCUSSED |
| Terrible | ||||
| I would like to know when my product will arrive? Since the delivery date has passed, I would like an answer, I am waiting! | ||||
| 2 | Short positive message | 2270 | 3.6% | Store note 10 |
| OK I RECOMMEND | ||||
| OK | ||||
| 3 | Short positive message, but about the product only | 1379 | 2.9% | Excellent quality product |
| Excellent product. | ||||
| very good, I recommend the product. | ||||
| 4 | Non-coherent topic | 6339 | 3.6% | I got exactly what I expected. Other orders from other sellers were delayed, but this one arrived on time. |
| I bought the watch, unisex and sent a women's watch, much smaller than the specifications of the ad. | ||||
| so far I haven't received the product. | ||||
| 5 | Positive message but longer than topic 2 | 1194 | 4.5% | Wonderful |
| super recommend the product which is very good! | ||||
| Everything as advertised.... Great product... | ||||
| 6 | Problems with delivery—wrong products, too many/too little things in package | 2892 | 3.8% | I bought two units and only received one and now what do I do? |
| I bought three packs of five sheets each of transfer paper for dark tissue and received only two | ||||
| The delivery was split in two. There was no statement from the store. I came to think that they had only shipped part of the product. | ||||
| 7 | Good comments about particular seller | 4839 | 3.4% | Congratulations lannister stores loved shopping online safe and practical Congratulations to all happy Easter |
| I recommend the seller... | ||||
| congratulations station... always arrives with a lot of antecedence.. Thank you very much.... | ||||
| 8 | Short message, mostly about quality of the product | 3808 | 3.4% | But a little, braking... for the value ta Boa. |
| Very good. very fragrant. | ||||
| I loved it, beautiful, very delicate | ||||
| 9 | non-coherent | 1275 | 3.4% | The purchase was made easily. The delivery was made well before the given deadline. The product has already started to be used and to date, without problems. |
| I hope it lasts because it is made of fur. | ||||
| I asked for a refund and no response so far | ||||
| 10 | Short message, lots of times wrong spelling/random letters | 15 | 9.1% | vbvbsgfbsbfs |
| I recommend... mayor; | ||||
| Ksksksk | ||||
| 11 | non-coherent | 2614 | 2.5% | I always buy over the Internet and delivery takes place before the agreed deadline, which I believe is the maximum period. At stark, the maximum term has expired and I have not yet received the product. |
| Great store for partnership: very fast, well packaged and quality products! Only the cost of shipping that was a little sour. | ||||
| I DID NOT RECEIVE THE PRODUCT AND IS IN THE SYSTEM I RECEIVED BEYOND PAYING EXPENSIVE SHIPPING | ||||
| 12 | Praises about the product | 2003 | 2.2% | very beautiful and cheap watch. |
| Good product, but what came to me does not match the photo in the ad. | ||||
| Beautiful watch I loved it | ||||
| 13 | Short positive message about the delivery | 1788 | 3.0% | On-time delivery |
| It took too long for delivery | ||||
| super fast delivery.... arrived before the date... |
Appendix C. Table of Lift Values for Selected Quantiles
| Fraction of Customers | No. Customers in Group | Probability in Selected Group | Lift |
|---|---|---|---|
| 1% | 320 | 0.65 | 19.71 |
| 2% | 640 | 0.35 | 10.66 |
| 3% | 959 | 0.26 | 7.84 |
| 4% | 1279 | 0.21 | 6.26 |
| 5% | 1598 | 0.17 | 5.16 |
| 10% | 3196 | 0.10 | 3.16 |
| 20% | 6392 | 0.07 | 2.07 |
| 30% | 9587 | 0.05 | 1.65 |
| 40% | 12,783 | 0.05 | 1.48 |
| 50% | 15,978 | 0.04 | 1.35 |
References
- Dick, A.S.; Basu, K. Customer Loyalty: Toward an Integrated Conceptual Framework. J. Acad. Mark. Sci. 1994, 22, 99–113. [Google Scholar] [CrossRef]
- Gefen, D. Customer Loyalty in e-Commerce. J. Assoc. Inf. Syst. 2002, 3, 2. [Google Scholar] [CrossRef]
- Buckinx, W.; Poel, D.V.D. Customer base analysis: Partial defection of behaviourally loyal clients in a non-contractual FMCG retail setting. Eur. J. Oper. Res. 2005, 164, 252–268. [Google Scholar] [CrossRef]
- Bach, M.P.; Pivar, J.; Jaković, B. Churn Management in Telecommunications: Hybrid Approach Using Cluster Analysis and Decision Trees. J. Risk Financ. Manag. 2021, 14, 544. [Google Scholar] [CrossRef]
- Nie, G.; Rowe, W.; Zhang, L.; Tian, Y.; Shi, Y. Credit Card Churn Forecasting by Logistic Regression and Decision Tree. Expert Syst. Appl. 2011, 38, 15273–15285. [Google Scholar] [CrossRef]
- Dalvi, P.K.; Khandge, S.K.; Deomore, A.; Bankar, A.; Kanade, V.A. Analysis of customer churn prediction in telecom industry using decision trees and logistic regression. In Proceedings of the 2016 Symposium on Colossal Data Analysis and Networking (CDAN), Indore, India, 18–19 March 2016; pp. 1–4. [Google Scholar]
- Gregory, B. Predicting Customer Churn: Extreme Gradient Boosting with Temporal Data. arXiv 2018, arXiv:1802.03396. [Google Scholar]
- Xiao, J.; Jiang, X.; He, C.; Teng, G. Churn prediction in customer relationship management via GMDH-based multiple classifiers ensemble. IEEE Intell. Syst. 2016, 31, 37–44. [Google Scholar] [CrossRef]
- Miguéis, V.; Van Den Poel, D.; Camanho, A.; e Cunha, J.F. Modeling partial customer churn: On the value of first product-category purchase sequences. Expert Syst. Appl. 2012, 39, 11250–11256. [Google Scholar] [CrossRef]
- Tamaddoni Jahromi, A.; Sepehri, M.M.; Teimourpour, B.; Choobdar, S. Modeling Customer Churn in a Non-Contractual Setting: The Case of Telecommunications Service Providers. J. Strateg. Mark. 2010, 18, 587–598. [Google Scholar] [CrossRef] [Green Version]
- Sithole, B.T.; Njaya, T. Regional Perspectives of the Determinants of Customer Churn Behaviour in Various Indus-tries in Asia, Latin America and Sub-Saharan Africa. Sch. J. Econ. Bus. Manag. 2018, 5, 211–217. [Google Scholar]
- Ngai, E.W.; Xiu, L.; Chau, D. Application of data mining techniques in customer relationship management: A literature review and classification. Expert Syst. Appl. 2009, 36, 2592–2602. [Google Scholar] [CrossRef]
- Hadden, J.; Tiwari, A.; Roy, R.; Ruta, D. Computer assisted customer churn management: State-of-the-art and future trends. Comput. Oper. Res. 2007, 34, 2902–2917. [Google Scholar] [CrossRef]
- Mozer, M.C.; Richard, W.; David, B.G.; Eric, J.; Howard, K. Predicting Sub-scriber Dissatisfaction and Improving Retention in the Wireless Telecommunications Industry. IEEE Trans. Neural Netw. 2000, 11, 690–696. [Google Scholar] [CrossRef] [Green Version]
- Long, H.V.; Son, L.H.; Khari, M.; Arora, K.; Chopra, S.; Kumar, R.; Le, T.; Baik, S.W. A New Approach for Construction of Geodemographic Segmentation Model and Prediction Analysis. Comput. Intell. Neurosci. 2019, 2019, 9252837. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, B.; Li, X.; Liu, W.; Ren, S. Customer Churn Prediction Using Improved One-Class Support Vector Machine. In Proceedings of the Computer Vision–ECCV 2014; Springer: Berlin/Heidelberg, Germany, 2005; pp. 300–306. [Google Scholar]
- Jha, M. Understanding Rural Buyer Behaviour. IIMB Manag. Rev. 2003, 15, 89–92. [Google Scholar]
- Kracklauer, A.; Passenheim, O.; Seifert, D. Mutual customer approach: How industry and trade are executing collaborative customer relationship management. Int. J. Retail. Distrib. Manag. 2001, 29, 515–519. [Google Scholar] [CrossRef]
- De Caigny, A.; Coussement, K.; De Bock, K.W.; Lessmann, S. Incorporating textual information in customer churn prediction models based on a convolutional neural network. Int. J. Forecast. 2020, 36, 1563–1578. [Google Scholar] [CrossRef]
- Bardicchia, M. Digital CRM-Strategies and Emerging Trends: Building Customer Relationship in the Digital Era; Independently published; 2020. [Google Scholar]
- Oliveira, V.L.M. Analytical Customer Relationship Management in Retailing Supported by Data Mining Techniques. Ph.D. Thesis, Universidade do Porto, Porto, Portugal, 2012. [Google Scholar]
- Achrol, R.S.; Kotler, P. Marketing in the Network Economy. J. Mark. 1999, 63, 146. [Google Scholar] [CrossRef]
- Choi, D.H.; Chul, M.K.; Kim, S.I.; Kim, S.H. Customer Loyalty and Disloyalty in Internet Re-tail Stores: Its Antecedents and Its Effect on Customer Price Sensitivity. Int. J. Manag. 2006, 23, 925. [Google Scholar]
- Burez, J.; Poel, D.V.D. CRM at a pay-TV company: Using analytical models to reduce customer attrition by targeted marketing for subscription services. Expert Syst. Appl. 2007, 32, 277–288. [Google Scholar] [CrossRef] [Green Version]
- Au, W.-H.; Chan, K.C.; Yao, X. A novel evolutionary data mining algorithm with applications to churn prediction. IEEE Trans. Evol. Comput. 2003, 7, 532–545. [Google Scholar] [CrossRef] [Green Version]
- Verbeke, W.; Martens, D.; Mues, C.; Baesens, B. Building comprehensible customer churn prediction models with advanced rule induction techniques. Expert Syst. Appl. 2011, 38, 2354–2364. [Google Scholar] [CrossRef]
- Paruelo, J.; Tomasel, F. Prediction of Functional Characteristics of Ecosystems: A Comparison of Artificial Neural Networks and Regression Models. Ecol. Model. 1997, 98, 173–186. [Google Scholar] [CrossRef]
- Murthy, S.K. Automatic Construction of Decision Trees from Data: A Multi-Disciplinary Survey. Data Min. Knowl. Discov. 1998, 2, 345–389. [Google Scholar] [CrossRef]
- Caruana, R.; Niculescu-Mizil, A. An empirical comparison of supervised learning algorithms. In Proceedings of the 23rd International Conference on Machine Learning-ICML ’06, Pittsburgh, PA, USA, 25–29 June 2006; Association for Computing Machinery (ACM): New York, NY, USA, 2006; pp. 161–168. [Google Scholar]
- Chen, T.; He, T.; Benesty, M.; Khotilovich, V.; Tang, Y.; Cho, H. Xgboost: Extreme Gradient Boosting; R Package Version 0.4-2; 2015; Volume 1, pp. 1–4. [Google Scholar]
- Nielsen, D. Tree Boosting with Xgboost-Why Does Xgboost Win “Every” Machine Learning Competition? Master’s Thesis, Norwegian University of Science and Technology’s, Trondheim, Norway, 2016. [Google Scholar]
- Nanayakkara, S.; Fogarty, S.; Tremeer, M.; Ross, K.; Richards, B.; Bergmeir, C.; Xu, S.; Stub, D.; Smith, K.; Tacey, M.; et al. Characterising Risk of in-Hospital Mortality Following Cardiac Arrest Using Machine Learning: A Retrospective International Registry Study. PLoS Med. 2018, 15, e1002709. [Google Scholar] [CrossRef] [Green Version]
- Biecek, P.; Tomasz, B. Explanatory Model Analysis: Explore, Explain, and Examine Predictive Models; CRC Press: Boca Raton, FL, USA, 2021. [Google Scholar]
- Doshi-Velez, F.; Kim, B. Towards a Rigorous Science of Interpretable Machine Learning. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- Rai, A. Explainable AI: From black box to glass box. J. Acad. Mark. Sci. 2019, 48, 137–141. [Google Scholar] [CrossRef] [Green Version]
- Suryadi, D. Predicting Repurchase Intention Using Textual Features of Online Customer Reviews. In Proceedings of the 2020 International Conference on Data Analytics for Business and Industry: Way Towards a Sustainable Economy (ICDABI), Sakheer, Bahrain, 26–27 October 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Lucini, F.R.; Tonetto, L.M.; Fogliatto, F.S.; Anzanello, M.J. Text mining approach to explore dimensions of airline customer satisfaction using online customer reviews. J. Air Transp. Manag. 2020, 83, 101760. [Google Scholar] [CrossRef]
- Schmittlein, D.C.; Peterson, R.A. Customer Base Analysis: An Industrial Purchase Process Application. Mark. Sci. 1994, 13, 41–67. [Google Scholar] [CrossRef]
- Bhattacharya, C.B. When Customers Are Members: Customer Retention in Paid Membership Contexts. J. Acad. Mark. Sci. 1998, 26, 31–44. [Google Scholar] [CrossRef]
- Athanassopoulos, A.D. Customer Satisfaction Cues To Support Market Segmentation and Explain Switching Behavior. J. Bus. Res. 2000, 47, 191–207. [Google Scholar] [CrossRef]
- Lee, J.Y.; Bell, D.R. Neighborhood Social Capital and Social Learning for Experience Attributes of Products. Mark. Sci. 2013, 32, 960–976. [Google Scholar] [CrossRef] [Green Version]
- Verbeke, W.; Dejaeger, K.; Martens, D.; Hur, J.; Baesens, B. New insights into churn prediction in the telecommunication sector: A profit driven data mining approach. Eur. J. Oper. Res. 2012, 218, 211–229. [Google Scholar] [CrossRef]
- De la Llave, M.Á.; López, F.A.; Angulo, A. The Impact of Geographical Factors on Churn Pre-diction: An Application to an Insurance Company in Madrid’s Urban Area. Scand. Actuar. J. 2019, 3, 188–203. [Google Scholar] [CrossRef]
- Harris, R.; Sleight, P.; Webber, R. Geodemographics, GIS and Neighbourhood Targeting; John Wiley & Sons: Hoboken, NJ, USA, 2005; Volume 8. [Google Scholar]
- Singleton, A.D.; Spielman, S.E. The Past, Present, and Future of Geodemographic Research in the United States and United Kingdom. Prof. Geogr. 2014, 66, 558–567. [Google Scholar] [CrossRef] [Green Version]
- Braun, T.; Webber, R. Targeting Customers: How to Use Geodemographic and Lifestyle Data in Your Business (3rd edition). Interact. Mark. 2004, 6, 200–201. [Google Scholar] [CrossRef]
- Sun, T.; Wu, G. Consumption patterns of Chinese urban and rural consumers. J. Consum. Mark. 2004, 21, 245–253. [Google Scholar] [CrossRef]
- Sharma, S.; Singh, M. Impact of brand selection on brand loyalty with special reference to personal care products: A rural urban comparison. Int. J. Indian Cult. Bus. Manag. 2021, 22, 287. [Google Scholar] [CrossRef]
- Felbermayr, A.; Nanopoulos, A. The Role of Emotions for the Perceived Usefulness in Online Customer Reviews. J. Interact. Mark. 2016, 36, 60–76. [Google Scholar] [CrossRef]
- Zhao, Y.; Xu, X.; Wang, M. Predicting overall customer satisfaction: Big data evidence from hotel online textual reviews. Int. J. Hosp. Manag. 2019, 76, 111–121. [Google Scholar] [CrossRef]
- Howley, T.; Madden, M.G.; O’Connell, M.-L.; Ryder, A.G. The Effect of Principal Component Analysis on Machine Learning Accuracy with High Dimensional Spectral Data. In Proceedings of the International Conference on Innovative Techniques and Applications of Artificial Intelligence, Cambridge, UK, 15–17 December 2020; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Corner, S. Choosing the Right Type of Rotation in PCA and EFA. JALT Test. Eval. SIG Newsl. 2009, 13, 20–25. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Hong, L.; Davison, B.D. Empirical study of topic modeling in Twitter. In Proceedings of the First Workshop on Social Media Analytics-SOMA ’10; Association for Computing Machinery (ACM): New York, NY, USA, 2010; pp. 80–88. [Google Scholar]
- Yin, J.; Wang, J. A dirichlet multinomial mixture model-based approach for short text clustering. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; Association for Computing Machinery (ACM): New York, NY, USA, 2014; pp. 233–242. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- He, R.; Lee, W.S.; Ng, H.T.; Dahlmeier, D. An Unsupervised Neural Attention Model for Aspect Extraction. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Vancouver, BC, Canada, 2017. [Google Scholar]
- Tulkens, S.; van Cranenburgh, A. Embarrassingly Simple Unsupervised Aspect Extraction. In Proceedings of the Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics; Association for Computational Linguistics: Vancouver, BC, Canada, 2020; pp. 3182–3187. [Google Scholar] [CrossRef]
- Luo, L.; Ao, X.; Song, Y.; Li, J.; Yang, X.; He, Q.; Yu, D. Unsupervised Neural Aspect Extraction with Sememes. In Proceedings of the Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, Macao, 10–16 August 2019; pp. 5123–5129. [Google Scholar] [CrossRef] [Green Version]
- Kilgarriff, A.; Fellbaum, C. WordNet: An Electronic Lexical Database; MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Kursa, M.; Rudnicki, W. Feature Selection with the Boruta Package. J. Stat. Softw. 2010, 36, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Kumar, S.S.; Shaikh, T. Empirical Evaluation of the Performance of Feature Selection Approaches on Random Forest. In Proceedings of the 2017 International Conference on Computer and Applications (ICCA), Doha, United Arab Emirates, 6–7 September 2017; pp. 227–231. [Google Scholar]
- Li, K.; Zhou, G.; Zhai, J.; Li, F.; Shao, M. Improved PSO_AdaBoost Ensemble Algorithm for Imbalanced Data. Sensors 2019, 19, 1476. [Google Scholar] [CrossRef] [Green Version]
- Sagi, O.; Rokach, L. Approximating XGBoost with an interpretable decision tree. Inf. Sci. 2021, 572, 522–542. [Google Scholar] [CrossRef]
- Biecek, P. DALEX: Explainers for Complex Predictive Models in R. J. Mach. Learn. Res. 2018, 19, 3245–3249. [Google Scholar]
- Minhas, A.S.; Singh, S. A new bearing fault diagnosis approach combining sensitive statistical features with improved multiscale permutation entropy method. Knowl.-Based Syst. 2021, 218, 106883. [Google Scholar] [CrossRef]
- Greenwell, B.M.; Boehmke, B.C.; Gray, B. Variable Importance Plots-An Introduction to the vip Package. R J. 2020, 12, 343. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Behrens, T.; Schmidt, K.; Rossel, R.A.V.; Gries, P.; Scholten, T.; Macmillan, R.A. Spatial modelling with Euclidean distance fields and machine learning. Eur. J. Soil Sci. 2018, 69, 757–770. [Google Scholar] [CrossRef]
- Kaya, E.; Dong, X.; Suhara, Y.; Balcisoy, S.; Bozkaya, B.; Pentland, A. “Sandy” Behavioral attributes and financial churn prediction. EPJ Data Sci. 2018, 7, 41. [Google Scholar] [CrossRef] [Green Version]
- de la Llave Montiel, M.A.; López, F. Spatial models for online retail churn: Evidence from an online grocery delivery service in Madrid. Pap. Reg. Sci. 2020, 99, 1643–1665. [Google Scholar] [CrossRef]
- Fridrich, M. Understanding Customer Churn Prediction Research with Structural Topic Models. Econ. Comput.-Tion Econ. Cybern. Stud. Res. 2020, 54, 301–317. [Google Scholar]














| Order Number | No. of Orders | Share of Number of Orders | Mean Value | The Proportion from the Previous Stage |
|---|---|---|---|---|
| 1 | 96,180 | 96.57% | 161 | - |
| 2 | 3060 | 3.07% | 150 | 3.18% |
| 3 | 262 | 0.26% | 152 | 8.56% |
| 4 | 49 | 0.05% | 197 | 18.70% |
| 5 or more | 47 | 0.05% | 101 | - |
| Total | 99,598 | 100% | - |
| Product Category | No. Items | Percentage of the First Order | Percentage of the Second Order |
|---|---|---|---|
| bed_bath_table | 7509 | 11.4% | 13.8% |
| furniture_decor | 5801 | 8.8% | 11.5% |
| sports_leisure | 6170 | 9.4% | 9.4% |
| health_beauty | 6996 | 10.6% | 7.4% |
| computers_accessories | 5601 | 8.5% | 6.7% |
| housewares | 5047 | 7.7% | 5.8% |
| watches_gifts | 4475 | 6.8% | 3.8% |
| telephony | 3512 | 5.3% | 3.5% |
| garden_tools | 3432 | 5.2% | 3.4% |
| auto | 3316 | 5.0% | 2.9% |
| toys | 3250 | 4.9% | 2.6% |
| perfumery | 2792 | 4.2% | 2.6% |
| cool_stuff | 3041 | 4.6% | 2.0% |
| baby | 2530 | 3.8% | 1.9% |
| electronics | 2423 | 3.7% | 1.3% |
| AUC Test | AUC Train | Performance Drop vs. the Best Model | ||||
|---|---|---|---|---|---|---|
| Model with Included Basic Variables and… | XGB | LR | XGB | LR | XGB | LR |
| Product categories | 0.6505 | 0.5862 | 0.9995 | 0.5922 | 0.00% | 0.00% |
| All remaining variables | 0.6460 | 0.5813 | 0.9997 | 0.5960 | −0.68% | −0.84% |
| Features selected by Boruta algorithm | 0.6426 | 0.5801 | 0.9998 | 0.5912 | −1.20% | −1.05% |
| Population density indicator | 0.6382 | 0.5464 | 0.9993 | 0.5532 | −1.88% | −6.79% |
| Review topics | 0.6353 | 0.5639 | 0.9992 | 0.5595 | −2.34% | −3.81% |
| Nothing more | 0.6338 | 0.5535 | 0.9991 | 0.5529 | −2.56% | −5.58% |
| Geodemographics (with PCA) | 0.6323 | 0.5482 | 0.9996 | 0.5606 | −2.80% | −6.48% |
| Geodemographics (without PCA) | 0.6254 | 0.5492 | 0.9995 | 0.5632 | −3.86% | −6.31% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Matuszelański, K.; Kopczewska, K. Customer Churn in Retail E-Commerce Business: Spatial and Machine Learning Approach. J. Theor. Appl. Electron. Commer. Res. 2022, 17, 165-198. https://doi.org/10.3390/jtaer17010009
Matuszelański K, Kopczewska K. Customer Churn in Retail E-Commerce Business: Spatial and Machine Learning Approach. Journal of Theoretical and Applied Electronic Commerce Research. 2022; 17(1):165-198. https://doi.org/10.3390/jtaer17010009
Chicago/Turabian StyleMatuszelański, Kamil, and Katarzyna Kopczewska. 2022. "Customer Churn in Retail E-Commerce Business: Spatial and Machine Learning Approach" Journal of Theoretical and Applied Electronic Commerce Research 17, no. 1: 165-198. https://doi.org/10.3390/jtaer17010009
APA StyleMatuszelański, K., & Kopczewska, K. (2022). Customer Churn in Retail E-Commerce Business: Spatial and Machine Learning Approach. Journal of Theoretical and Applied Electronic Commerce Research, 17(1), 165-198. https://doi.org/10.3390/jtaer17010009