

A Hyper-Personalized Product Recommendation System Focused on Customer Segmentation: An Application in the Fashion Retail Industry


Abstract
:1. Introduction
2. Related Work
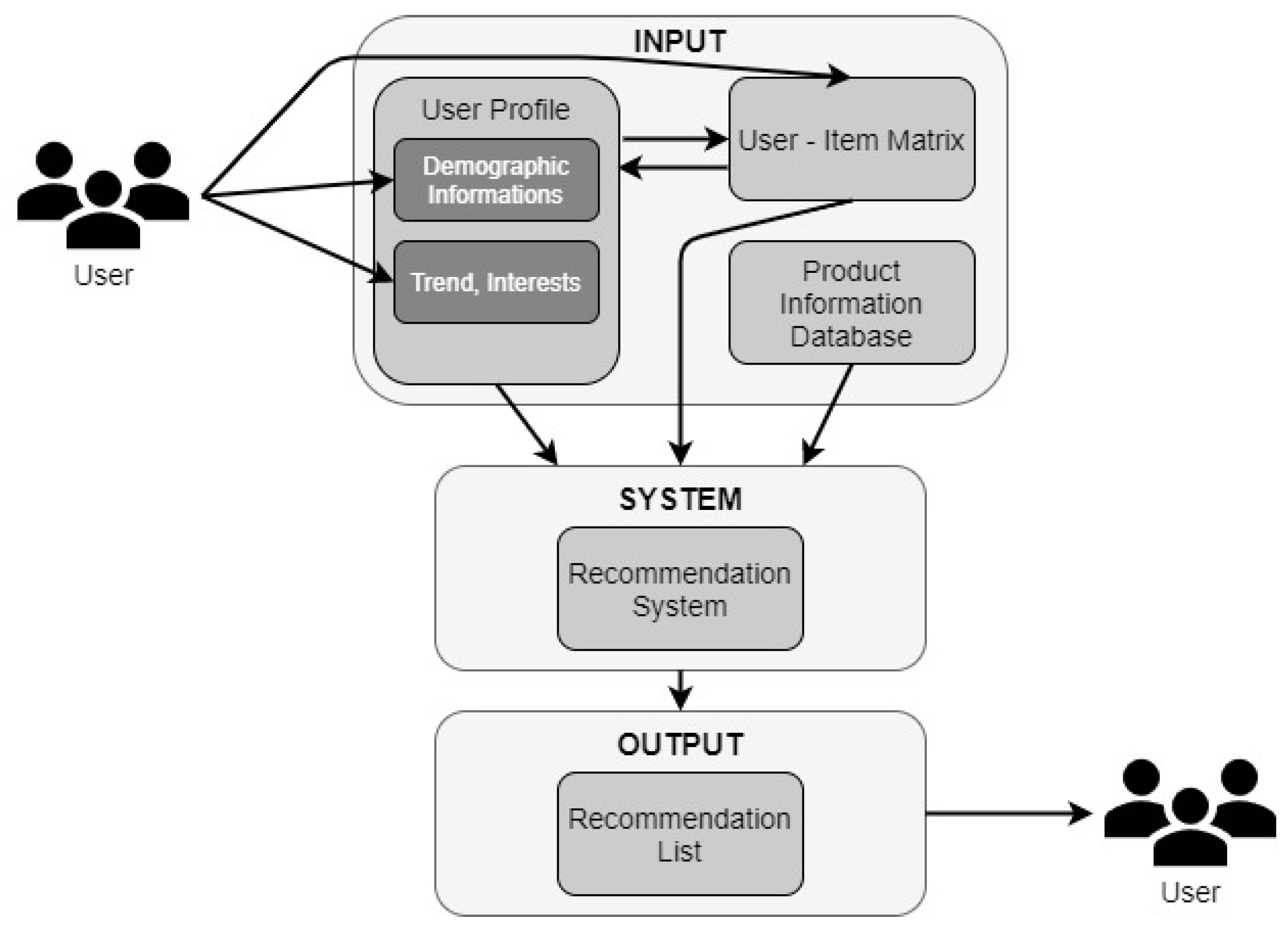
2.1. Recommendation Systems
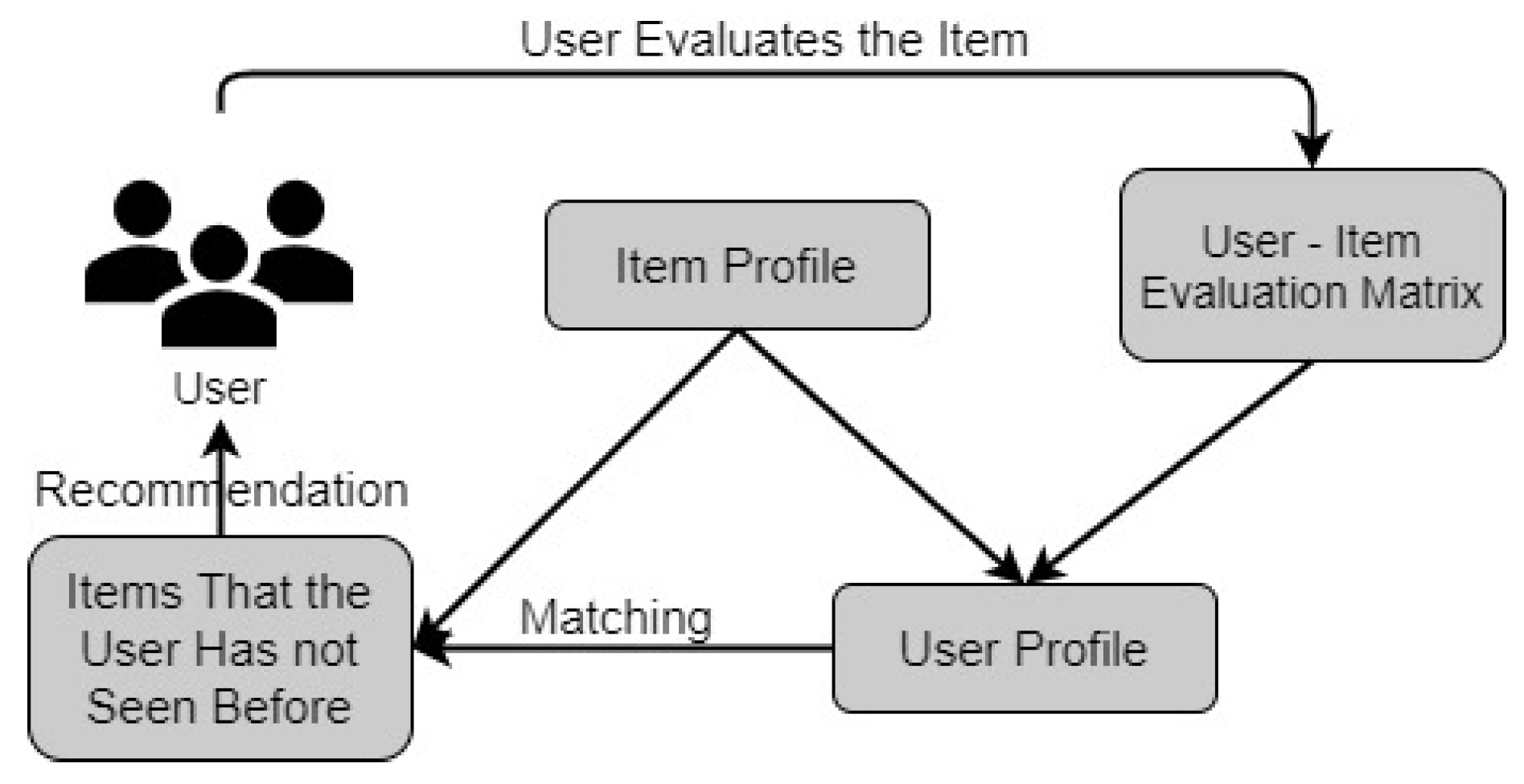
2.2. Structure of Collaborative Filtering Algorithms
2.3. Literature Review on the Development of Recommendation Systems
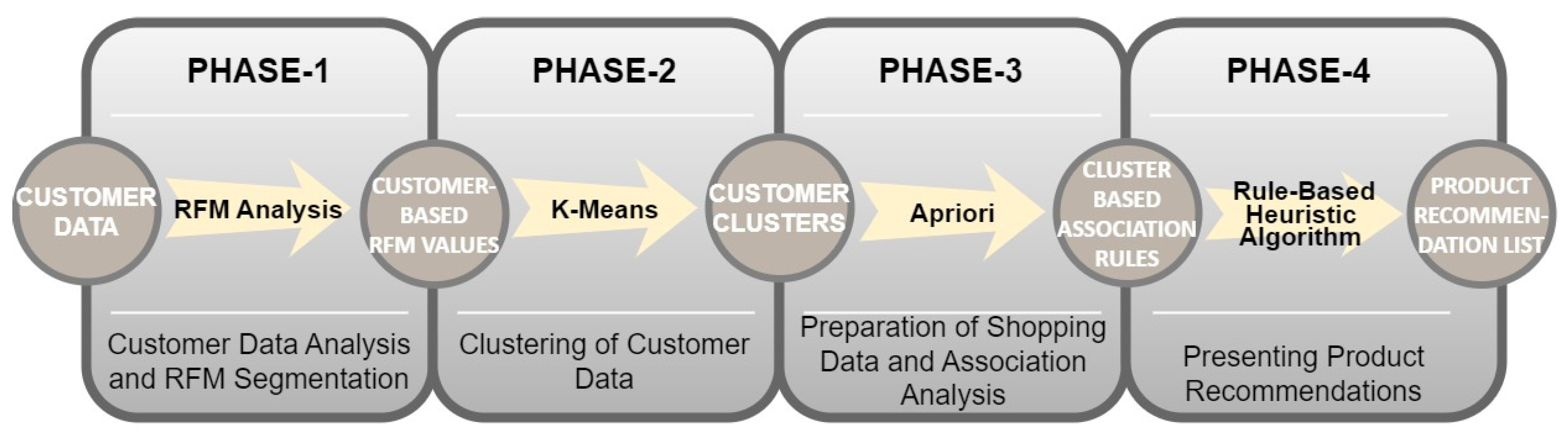
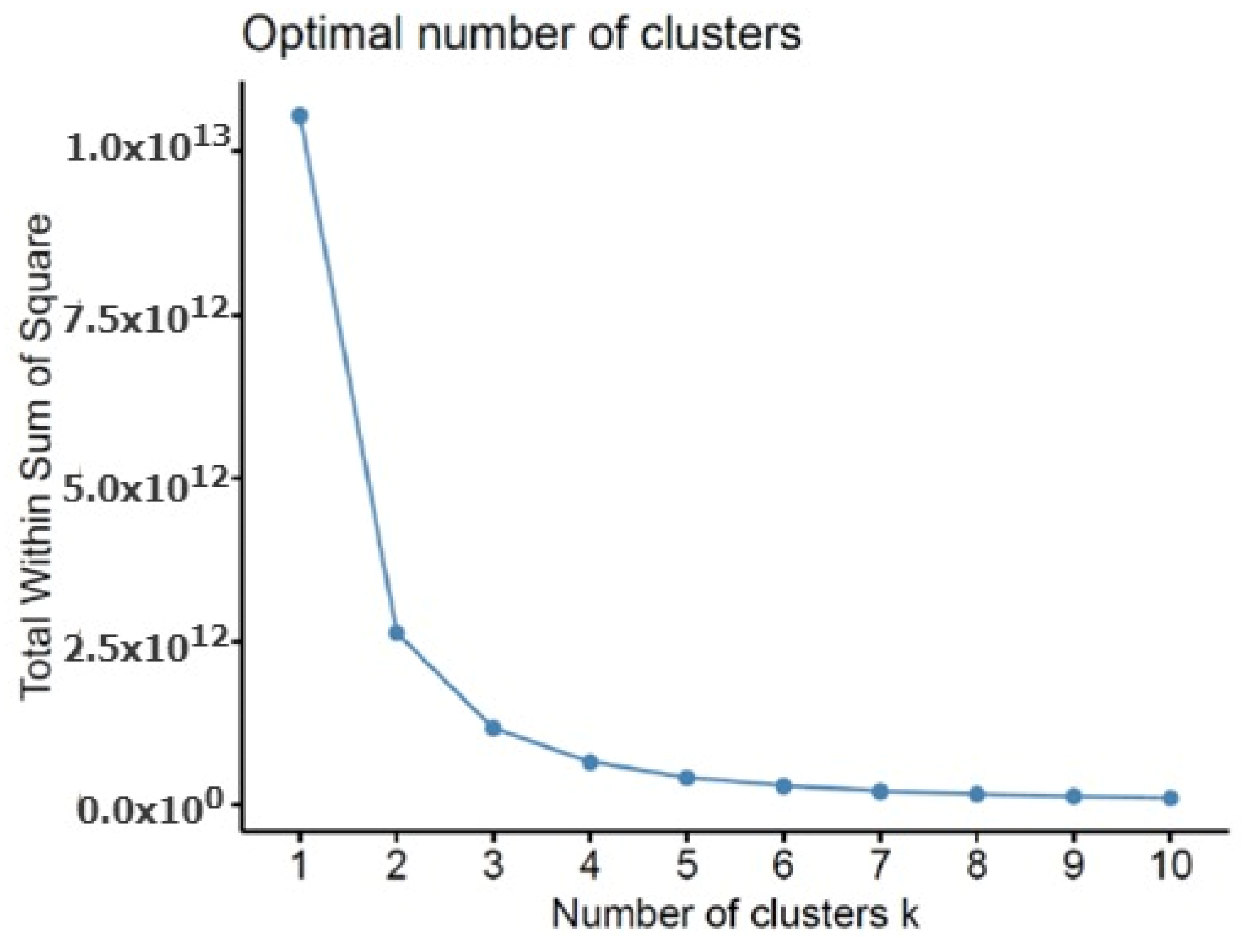
3. Proposed Recommendation System
Phases of the Proposed Recommendation System
- ⮚
- Determination of arbitrarily taken k elements as cluster center (,…,),
- ⮚
- Assigning each element to the set of to which it is closest,
- ⮚
- Recalculating the values ,…, of the clusters,
- ⮚
- Continue from the first step until there is no change in the cluster. If there is no change, stop.
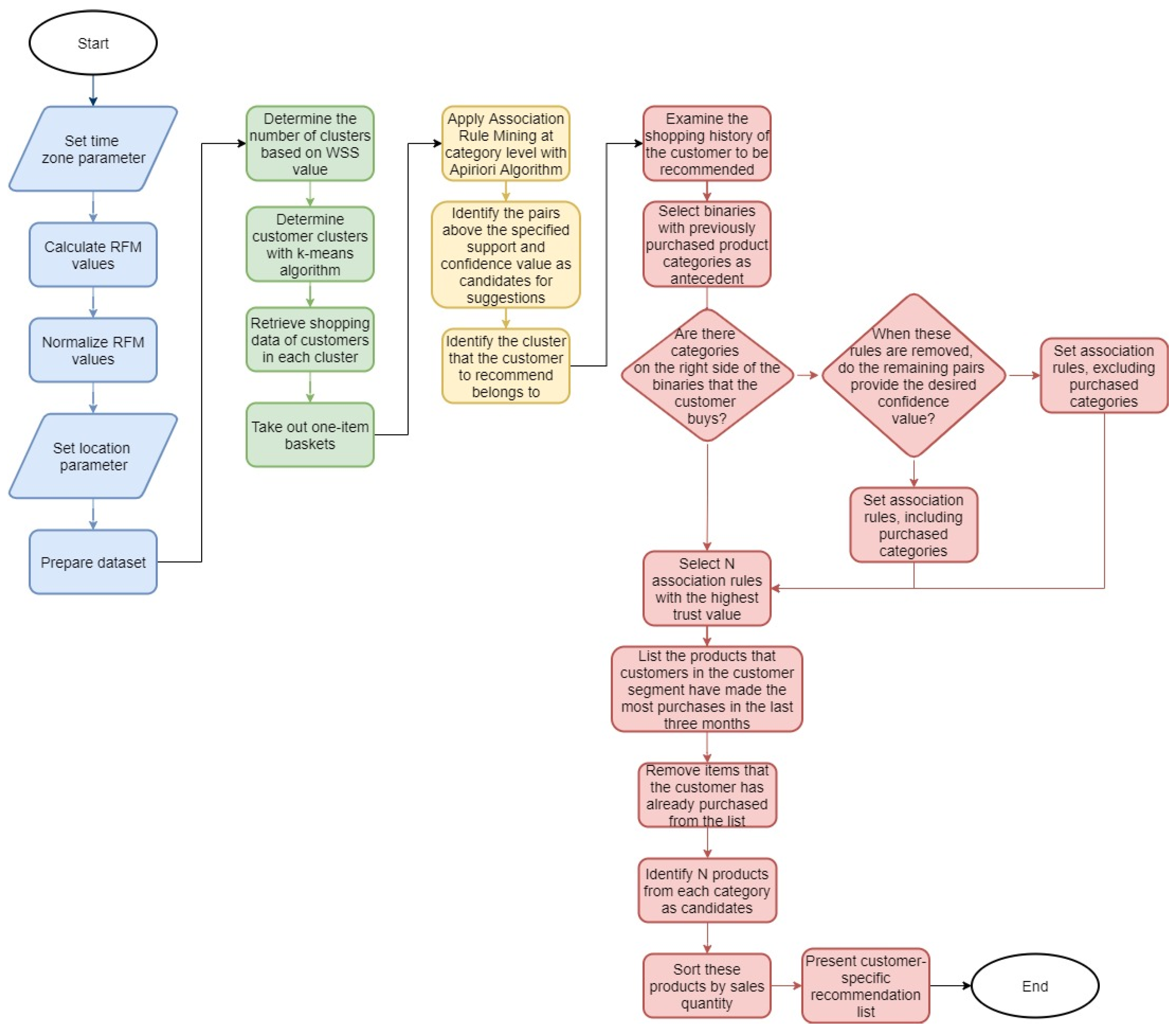
4. Experimental Design
Implementation of the Proposed Recommendation System
5. Discussion
6. Conclusions and Future Studies
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Literature Review Table
| Authors (Year) | Sector/Object | Real Application | Approach | Customer Segmentation | Customer Location | Techniques |
| Pazzani & Billsus (1997) | Web Content | No | CBA | No | No | NBC, k-NN, PEBLS, DT, Rocchio, ANN |
| Ha, (2002) | Retail | Yes | UBCF | Yes | No | RFM, SOM, ARM |
| Liu & Shih, (2005) | Medical stuff | No | UBCF | Yes | No | RFM, AHP, k-means, ARM |
| Kim et al. (2010) | Web Content | Yes | UBCF | No | No | NBC, k-NN |
| Lee, (2010) | Retail | Yes | UBCF | Yes | No | RFM, C4.5 |
| Choi et al. (2012) | Retail | Yes | UBCF | No | No | SPA, CBS, ED |
| Jomaa et al. (2012) | Book | No | UBCF | Yes | No | CBS, ED |
| Sun et al. (2014) | Tobacco Products | Yes | OBCF | No | No | CBS, k-NN |
| Rezaeinia & Rahmani (2016) | Wholesale | Yes | UBCF | Yes | No | RFM, AHP, k-NN |
| Rodrigues & Ferreira (2016) | Retail | Yes | UBCF | Yes | No | RFM, k-means, ARM |
| Li et al. (2017) | Retail | Yes | Hybrid | No | No | CBR, CBS |
| Najafabadi et al. (2017) | Music | No | UBCF | Yes | No | Clustering, ARM |
| Zhao et al. (2017) | Movie | No | CBA | No | No | URBD |
| Son & Kim (2017) | Movie | No | CBA | No | No | DS, MC, MN |
| Hwangbo et al. (2018) | Fashion | Yes | OBCF | No | No | CBS, k-means |
| Liji et al. (2018) | Movie | No | UBCF | No | No | EC, Improved CBS, SCM, k-NN |
| Jing et al. (2018) | Retail | Yes | UBCF | No | No | PF, SA |
| Cao et al. (2019) | Web Content | No | HCF | No | No | CBS |
| Iwanaga et al. (2019) | Retail | Yes | UBCF | No | No | NMF |
| Cai et al. (2020) | Movie | No | Hybrid | No | No | k-means, MaOEA |
| M. Li et al. (2020) | Q&A | No | CF+CBA | No | No | SC |
| Walek & Fojtik (2020) | Movie | No | CF+CBA | No | No | SVD, CBS, FES |
| Noulapeu Ngaffo et al. (2021) | Web Content | No | UBCF | No | No | - |
| Z. Chen et al. (2021) | Movie | No | UBCF | No | No | TCA, RNS, k-means |
| Bellini et al. (2022) | Fashion | Yes | MLC | No | No | K-medoids, k-means, ARM |
| Vahidy Rodpysh et al. (2022) | Movie | Yes | MDA | No | Yes | SVD |
| Zhou et al. (2022) | Web Content | No | UBCF | No | No | PC, top-k |
| CBA: Content-Based Approach, OBCF: Object-Based CF, UBCF: User-Based CF, HCF: Hybrid CF, MLC: Multi-Level Clustering, LSIER: Latent Semantic Integrated Explicit Rating, SPA: Sequential Pattern Analysis, SVD: Singular Value Decomposition, ARM: Association Rule Mining, CBS: Cosine-Based Similarity, ED: Euclidean Distance, AHP: Analytic Hierarchy Process, k-NN: k-Nearest Neighbor, ANN: Artificial Neural Networks, DT: Decision Trees, SOM: Self-Organizing Maps, NBC: Naive Bayes Classifier, CBR: Case-Based Reasoning, URBD: User Rating Based Distance, DS: Dice Similarity, MC: Modularity Clustering, MN: Multiattribute network, PM: Preference Mining, SA: Sentiment Assessment EC: Evolutionary Clustering, SCM: Score Matrix Filling, SC: Sequential Clustering, FES: Fuzzy Expert System, NMF: Non-Negative Matrix Factorization, MaOEA: Many-Objective Evolutionary Algorithm, PC: Pearson’s correlation, HSM: Hybrid Similarity Measure, PMF: Probabilistic Matrix Factorization, TCA: Target Category Adjustment, RNS: Random Neighbor Selection, MDA: Model-Driven Approach, UCSM: User Context Similarity Measure, ICSM: Item Context Similarity Measure. | ||||||
Appendix B. Product Category Descriptions
| Code | Description | Code | Description | Code | Description |
| M_ATH | Male Athlete | W_SCK | Women Socks | W_OVR | Women Jumpsuit |
| W_ATH | Women Athletes | M_SCR | Men Scarf | M_OVS | Men Overshirts |
| M_BAG | Men Bag | W_SCR | Women Scarf | W_OVS | Women Overshirt |
| W_BAG | Women Bag | M_SET | Men Beat-Scarf-Gloves | M_PJM | Men Pajamas |
| M_BJT | Men Jewelry | W_SET | Women Beat-Scarf-Gloves | W_PJM | Women Pajamas |
| W_BJT | Women Jewelry | M_SGL | Men Glasses | M_PLV | Men Sweater |
| W_BKN | Women Bikini / Swimsuit | W_SGL | Women Glasses | W_PLV | Women Sweater |
| W_BLL | Women Blouse Long Sleeve | M_SHG | Men Shirt Long Sleeve | M_PNT | Men Trousers |
| W_BLR | Women Bolero | W_SHG | Women Shirt Long Sleeve | W_PNT | Women Pants |
| W_BLS | Women Blouse Short Sleeve | M_SHL | Men Shawl | W_PRE | Women Pareo |
| M_BLT | Men Belt | W_SHL | Women Shawl | M_PTK | Men Polo Short-Sleeve |
| W_BLT | Women Belt | M_SHS | Men Shirt Short Sleeve | W_PTK | Women Polo Short-Sleeve |
| M_BOT | Men Boots / Boots | W_SHS | Women Shirt Short Sleeve | M_PTL | Men Polo Long Sleeve |
| W_BOT | Women Boots / Boots | W_SKR | Women Skirt | W_PTL | Women Polo Long Sleeve |
| M_BRT | Men Bean | M_SLR | Men Slipper | M_PUM | Men Jacket Pu |
| W_BRT | Women Bean | W_SLR | Women Slipper | W_PUM | Women Jacket Pu |
| M_CAP | Men Hat | M_SND | Men Sandals | M_PUW | Men Vest Pu |
| W_CAP | Women Hat | W_SND | Women Sandals | W_PUW | Women Vest Pu |
| M_COA | Men Coat | M_SOE | Men Shoes | M_RCO | Men Raincoat |
| W_COA | Women Coat | W_SOE | Women Shoes | W_RCO | Women Raincoat |
| M_CPR | Men Capri | M_SRB | Men Sea Shorts | M_SCK | Men Socks |
| W_CPR | Women Capri | W_SRB | Women Sea Shorts | M_TSL | Men T-Shirt Long Sleeve |
| M_CRD | Men Cardigan | M_SRT | Men Shorts | W_TSL | Women T-Shirt Long Sleeve |
| W_CRD | Women Cardigan | W_SRT | Women Shorts | M_TSS | Men T-Shirt Short Sleeve |
| W_DRS | Women Dress | M_SWS | Men Sweatshirt | W_TSS | Women T-Shirt Short Sleeve |
| M_GLV | Men Gloves | W_SWS | Women Sweatshirt | M_TST | Men Track Suit |
| W_GLV | Women Gloves | M_TCH | Men Trenchcoat | W_TST | Women Track Suit |
| W_HPN | Women Buckle | W_TCH | Women Trenchcoat | M_TSU | Men Sweatpants |
| M_JCK | Men Jacket | W_TGT | Women Tights | W_TSU | Women Sweatpants |
| W_JCK | Women Jacket | M_TIE | Men Tie | M_TWL | Men Beach Towel |
| M_MNT | Men Jackets | M_TNC | Men Tunic | W_TWL | Women Beach Towel |
| W_MNT | Women Jackets | W_TNC | Women Tunic | M_UDW | Men Underwear |
| W_WST | Women Vest | W_UNB | Women Umbrella | W_UDW | Women Underwear |
| M_WTC | Men Watch | M_WLT | Men Wallet | M_UNB | Men Umbrella |
| W_WTC | Women Watch | W_WLT | Women Wallet | M_WST | Men Vest |
References
- Wu, F.; Lyu, C.; Liu, Y. A personalized recommendation system for multi-modal transportation systems. Multimodal Transp. 2022, 1, 100016. [Google Scholar] [CrossRef]
- Alamdari, P.M.; Navimipour, N.J.; Hosseinzadeh, M.; Safaei, A.A.; Darwesh, A. A Systematic Study on the Recommender Systems in the E-Commerce. IEEE Access 2020, 8, 115694–115716. [Google Scholar] [CrossRef]
- Fayyaz, Z.; Ebrahimian, M.; Nawara, D.; Ibrahim, A.; Kashef, R. Recommendation Systems: Algorithms, Challenges, Metrics, and Business Opportunities. Appl. Sci. 2020, 10, 7748. [Google Scholar] [CrossRef]
- Ko, H.; Lee, S.; Park, Y.; Choi, A. A Survey of Recommendation Systems: Recommendation Models, Techniques, and Application Fields. Electronics 2022, 11, 141. [Google Scholar] [CrossRef]
- Acharya, N.; Sassenberg, A.-M.; Soar, J. Consumers’ Behavioural Intentions to Reuse Recommender Systems: Assessing the Effects of Trust Propensity, Trusting Beliefs and Perceived Usefulness. J. Theor. Appl. Electron. Commer. Res. 2022, 18, 4. [Google Scholar] [CrossRef]
- Wang, R.; Ma, X.; Jiang, C.; Ye, Y.; Zhang, Y. Heterogeneous information network-based music recommendation system in mobile networks. Comput. Commun. 2019, 150, 429–437. [Google Scholar] [CrossRef]
- Khademizadeh, S.; Nematollahi, Z.; Danesh, F. Analysis of book circulation data and a book recommendation system in academic libraries using data mining techniques. Libr. Inf. Sci. Res. 2022, 44, 101191. [Google Scholar] [CrossRef]
- Behera, G.; Nain, N. Collaborative Filtering with Temporal Features for Movie Recommendation System. In Procedia Computer Science; Elsevier B.V.: Amsterdam, The Netherlands, 2023; Volume 218, pp. 1366–1373. [Google Scholar] [CrossRef]
- Hallikainen, H.; Luongo, M.; Dhir, A.; Laukkanen, T. Consequences of personalized product recommendations and price promotions in online grocery shopping. J. Retail. Consum. Serv. 2022, 69, 103088. [Google Scholar] [CrossRef]
- Tyrväinen, O.; Karjaluoto, H.; Saarijärvi, H. Personalization and hedonic motivation in creating customer experiences and loyalty in omnichannel retail. J. Retail. Consum. Serv. 2020, 57, 102233. [Google Scholar] [CrossRef]
- Chakraborty, S.; Hoque, S.; Jeem, N.R.; Biswas, M.; Bardhan, D.; Lobaton, E. Fashion Recommendation Systems, Models and Methods: A Review. Informatics 2021, 8, 49. [Google Scholar] [CrossRef]
- Mendia, J.M.V.; Flores-Cuautle, J.J.A. Toward customer hyper-personalization experience—A data-driven approach. Cogent Bus. Manag. 2022, 9, 1. [Google Scholar] [CrossRef]
- Jain, G.; Rakesh, S.; Nabi, M.K.; Chaturvedi, K. Hyper-personalization—Fashion sustainability through digital clienteling. Res. J. Text. Appar. 2018, 22, 320–334. [Google Scholar] [CrossRef] [Green Version]
- Jain, G.; Paul, J.; Shrivastava, A. Hyper-personalization, co-creation, digital clienteling and transformation. J. Bus. Res. 2020, 124, 12–23. [Google Scholar] [CrossRef]
- Jannach, D.; Zanker, M.; Felfernig, A.; Friedrich, G. Recommender Systems: An Introduction; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar] [CrossRef]
- Sarwar, B.; Karypis, G.; Konstan, J.; Riedl, J. Item-Based Collaborative Filtering Recommendation Algorithms. In Proceedings of the 10th International Conference on World Wide Web, WWW ’01, Hong Kong, China, 1–5 May 2001; Association for Computing Machinery: New York, NY, USA, 2001; pp. 285–295. [Google Scholar] [CrossRef] [Green Version]
- Bobadilla, J.; Ortega, F.; Hernando, A.; Gutiérrez, A. Recommender systems survey. Knowl. Based Syst. 2013, 46, 109–132. [Google Scholar] [CrossRef]
- Marx, P.; Hennig-Thurau, T.; Marchand, A. Increasing Consumers’ Understanding of Recommender Results: A Preference-Based Hybrid Algorithm with Strong Explanatory Power. In Proceedings of the Fourth ACM Conference on Recommender Systems, RecSys ’10, Barcelona, Spain, 26–30 September 2010; Association for Computing Machinery: New York, NY, USA, 2010; pp. 297–300. [Google Scholar] [CrossRef]
- Ricci, F.; Rokach, L.; Shapira, B. Recommender Systems Handbook, 2nd ed.; Springer: New York, NY, USA, 2015. [Google Scholar] [CrossRef]
- Bhatnagar, V. (Ed.) . Collaborative Filtering Using Data Mining and Analysis; IGI Global: Hershey, PE, USA, 2016. [Google Scholar] [CrossRef]
- Adomavicius, G.; Tuzhilin, A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749. [Google Scholar] [CrossRef]
- Akrivas, G.; Wallace, M.; Andreou, G.; Stamou, G.; Kollias, S. Context—Sensitive Semantic Query Expansion. Proceedings 2002 IEEE International Conference on Artificial Intelligence Systems (ICAIS 2002), Divnomorskoe, Russia, 5–10 September 2002; pp. 109–114. [Google Scholar]
- Anand, S.S.; Mobasher, B. (Eds.) Intelligent Techniques for Web Personalization. In Intelligent Techniques in Web Personalization; Springer: Berlin, Germany, 2005; pp. 1–36. [Google Scholar] [CrossRef]
- Jones, G. Challenges and Opportunities of Context-Aware Information Access. In Proceedings of the International Workshop on Ubiquitous Data Management, Tokyo, Japan, 4 April 2005; pp. 53–62. [Google Scholar] [CrossRef] [Green Version]
- Chen, Z.-S.; Jang, J.-S.R.; Lee, C.-H. A Kernel Framework for Content-Based Artist Recommendation System in Music. IEEE Trans. Multimed. 2011, 13, 1371–1380. [Google Scholar] [CrossRef]
- Jurado-Lucena, A.; Errasti-Alcalá, B.; Escot-Bocanegra, D.; Fernández-Recio, R.; Poyatos-Martínez, D.; Montiel Sánchez, I. Methodology to Achieve Accurate Non Cooperative Target Identification Using High Resolution Radar and a Synthetic Database. In Trends in Applied Intelligent Systems; García-Pedrajas, N., Herrera, F., Fyfe, C., Benítez, J.M., Ali, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 427–436. [Google Scholar]
- Goldberg, D.; Nichols, D.; Oki, B.M.; Terry, D. Using collaborative filtering to weave an information tapestry. Commun. ACM 1992, 35, 61–70. [Google Scholar] [CrossRef]
- Schafer, J.B.; Konstan, J.; Riedl, J. Recommender Systems in E-Commerce. In Proceedings of the 1st ACM Conference on Electronic Commerce, EC ’99, Denver, CO, USA, 3–5 November 1999; Association for Computing Machinery: New York, NY, USA, 1999; pp. 158–166. [Google Scholar] [CrossRef]
- Rashid, A.M.; Lam, S.K.; Karypis, G.; Riedl, J. ClustKNN: A Highly Scalable Hybrid Model- & Memory-Based CF Algorithm. Search 2006, 35, 61–70. [Google Scholar]
- Breese, J.S.; Heckerman, D.; Kadie, C. Empirical Analysis of Predictive Algorithms for Collaborative Filtering. In Proceedings of the Fourteenth conference on Uncertainty in artificial intelligence, Madison, WI, USA, 24–26 July 1998; pp. 43–52. [Google Scholar]
- Felfernig, A.; Burke, R. Constraint-Based Recommender Systems: Technologies and Research Issues. In Proceeding of the 10th International Conference on Electronic Commerce, Innsbruck, Austria, 19–22 August 2008. [Google Scholar] [CrossRef]
- Burke, R. Hybrid Recommender Systems: Survey and Experiments. User Model. User-Adapted Interact. 2002, 12, 331–370. [Google Scholar] [CrossRef]
- Herlocker, J.L.; Konstan, J.A.; Borchers, A.; Riedl, J. An algorithmic framework for performing collaborative filtering. In Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval—SIGIR ’99, Berkeley, CA, USA, 15–20 August 1999; Association for Computing Machinery (ACM): New York, NY, USA, 1999; pp. 230–237. [Google Scholar]
- Tan, P.-N.; Steinbach, M.; Karpatne, A.; Kumar, V. Introduction to Data Mining, 2nd ed.; Pearson: New York, NY, USA, 2018. [Google Scholar]
- Ding, Y.; Li, X.; Orlowska, M.E. Recency-Based Collaborative Filtering. In Proceedings of the 17th Australasian Database Conference—Volume 49, ADC ’06, Hobart, Australia, 16–19 January 2006; Australian Computer Society, Inc.: Hobart, Australia, 2006; pp. 99–107. [Google Scholar]
- Pazzani, M.; Billsus, D. Learning and Revising User Profiles: The Identification of Interesting Web Sites. Mach. Learn. 1997, 27, 313–331. [Google Scholar] [CrossRef]
- Kim, H.-N.; Ji, A.-T.; Ha, I.; Jo, G.-S. Collaborative filtering based on collaborative tagging for enhancing the quality of recommendation. Electron. Commer. Res. Appl. 2010, 9, 73–83. [Google Scholar] [CrossRef]
- Jomaa, I.; Poirson, E.; Da Cunha, C.; Petiot, J.-F. Design of a Recommender System Based on Customer Preferences: A Comparison Between Two Approaches. In Proceedings of the ASME 2012 11th Biennial Conference on Engineering Systems Design and Analysis, Nantes, France, 2 July 2012; pp. 827–836. [Google Scholar] [CrossRef]
- Sun, C.; Gao, R.; Xi, H. Big data based retail recommender system of non E-commerce. In Proceedings of the Fifth International Conference on Computing, Communications and Networking Technologies (ICCCNT), Hefei, China, 11–13 July 2014; pp. 1–7. [Google Scholar] [CrossRef]
- Hwangbo, H.; Kim, Y.S.; Cha, K.J. Recommendation system development for fashion retail e-commerce. Electron. Commer. Res. Appl. 2018, 28, 94–101. [Google Scholar] [CrossRef]
- Iwanaga, J.; Nishimura, N.; Sukegawa, N.; Takano, Y. Improving collaborative filtering recommendations by estimating user preferences from clickstream data. Electron. Commer. Res. Appl. 2019, 37, 100877. [Google Scholar] [CrossRef]
- Ngaffo, A.N.; El Ayeb, W.; Choukair, Z. A service recommendation approach based on trusted user profiles and an enhanced similarity measure. Electron. Commer. Res. 2021, 22, 1537–1572. [Google Scholar] [CrossRef]
- Zhao, Y.-S.; Liu, Y.-P.; Zeng, Q.-A. A weight-based item recommendation approach for electronic commerce systems. Electron. Commer. Res. 2015, 17, 205–226. [Google Scholar] [CrossRef]
- Son, J.; Kim, S.B. Content-based filtering for recommendation systems using multiattribute networks. Expert Syst. Appl. 2017, 89, 404–412. [Google Scholar] [CrossRef]
- Choi, K.; Yoo, D.; Kim, G.; Suh, Y. A hybrid online-product recommendation system: Combining implicit rating-based collaborative filtering and sequential pattern analysis. Electron. Commer. Res. Appl. 2012, 11, 309–317. [Google Scholar] [CrossRef]
- Li, Y.-H.; Fan, Z.-P.; Qiao, G. Product recommendation incorporating the consideration of product performance and customer service factors. Kybernetes 2017, 46, 1753–1776. [Google Scholar] [CrossRef]
- Cao, M.; Zhou, S.; Gao, H. A Recommendation Approach Based on Product Attribute Reviews: Improved Collaborative Filtering Considering the Sentiment Polarity. Intell. Autom. Soft Comput. 2019, 25, 595–605. [Google Scholar] [CrossRef]
- Cai, X.; Hu, Z.; Zhao, P.; Zhang, W.; Chen, J. A hybrid recommendation system with many-objective evolutionary algorithm. Expert Syst. Appl. 2020, 159, 113648. [Google Scholar] [CrossRef]
- Walek, B.; Fojtik, V. A hybrid recommender system for recommending relevant movies using an expert system. Expert Syst. Appl. 2020, 158, 113452. [Google Scholar] [CrossRef]
- Li, M.; Li, Y.; Lou, W.Q.; Chen, L.S. A hybrid recommendation system for Q & A documents. Expert Syst. Appl. 2020, 144, 11308. [Google Scholar] [CrossRef]
- Rodpysh, K.V.; Mirabedini, S.J.; Banirostam, T. Model-driven approach running route two-level SVD with context information and feature entities in recommender system. Comput. Stand. Interfaces 2022, 82, 103627. [Google Scholar] [CrossRef]
- Zhou, Q.; Zhuang, W.; Ren, H.; Chen, Y.; Yu, B.; Lou, J.; Wang, Y. Hybrid collaborative filtering model for consumer dynamic service recommendation based on mobile cloud information system. Inf. Process. Manag. 2022, 59, 102871. [Google Scholar] [CrossRef]
- Ha, S.H. Helping online customers decide through Web personalization. IEEE Intell. Syst. 2002, 17, 34–43. [Google Scholar] [CrossRef]
- Liu, D.-R.; Shih, Y.-Y. Hybrid approaches to product recommendation based on customer lifetime value and purchase preferences. J. Syst. Softw. 2005, 77, 181–191. [Google Scholar] [CrossRef]
- Lee, S.-L. Commodity recommendations of retail business based on decisiontree induction. Expert Syst. Appl. 2010, 37, 3685–3694. [Google Scholar] [CrossRef]
- Rodrigues, F.; Ferreira, B. Product Recommendation based on Shared Customer’s Behaviour. Procedia Comput. Sci. 2016, 100, 136–146. [Google Scholar] [CrossRef] [Green Version]
- Rezaeinia, S.M.; Rahmani, R. Recommender system based on customer segmentation (RSCS). Kybernetes 2016, 45, 946–961. [Google Scholar] [CrossRef]
- Najafabadi, M.K.; Mahrin, M.N.; Chuprat, S.; Sarkan, H.M. Improving the accuracy of collaborative filtering recommendations using clustering and association rules mining on implicit data. Comput. Hum. Behav. 2017, 67, 113–128. [Google Scholar] [CrossRef]
- Chen, Z.; Wang, Y.; Zhang, S.; Zhong, H.; Chen, L. Differentially private user-based collaborative filtering recommendation based onk-means clustering. Expert Syst. Appl. 2020, 168, 114366. [Google Scholar] [CrossRef]
- Bellini, P.; Palesi, L.A.I.; Nesi, P.; Pantaleo, G. Multi Clustering Recommendation System for Fashion Retail. Multimed. Tools Appl. 2022, 82, 9989–10016. [Google Scholar] [CrossRef] [PubMed]
- Jing, N.; Jiang, T.; Du, J.; Sugumaran, V. Personalized recommendation based on customer preference mining and sentiment assessment from a Chinese e-commerce website. Electron. Commer. Res. 2017, 18, 159–179. [Google Scholar] [CrossRef]
- U, L.; Chai, Y.; Chen, J. Improved personalized recommendation based on user attributes clustering and score matrix filling. Comput. Stand. Interfaces 2018, 57, 59–67. [Google Scholar] [CrossRef]
- Wang, R.; Wang, J.; Su, Z. Learning compatibility knowledge for outfit recommendation with complementary clothing matching. Comput. Commun. 2021, 181, 320–328. [Google Scholar] [CrossRef]
- Wang, S.; Qiu, J. A deep neural network model for fashion collocation recommendation using side information in e-commerce. Appl. Soft Comput. 2021, 110, 107753. [Google Scholar] [CrossRef]
- Balim, C.; Özkan, K. Diagnosing fashion outfit compatibility with deep learning techniques. Expert Syst. Appl. 2023, 215, 119305. [Google Scholar] [CrossRef]
- Sulikowski, P. Evaluation of Varying Visual Intensity and Position of a Recommendation in a Recommending Interface towards Reducing Habituation and Improving Sales. In Proceedings of the 16th International Conference on e-Business Engineering (ICEBE 2019), Shanghai, China, 12–13 October 2019; Chao, K.-M., Jiang, L., Hussain, O.K., Ma, S.-P., Fei, X., Eds.; Springer: Berlin/Heidelberg, Germany, 2019; pp. 208–218. [Google Scholar]
- Sulikowski, P.; Zdziebko, T. Deep Learning-Enhanced Framework for Performance Evaluation of a Recommending Interface with Varied Recommendation Position and Intensity Based on Eye-Tracking Equipment Data Processing. Electronics 2020, 9, 266. [Google Scholar] [CrossRef] [Green Version]
- Sulikowski, P.; Zdziebko, T. Horizontal vs. Vertical Recommendation Zones Evaluation Using Behavior Tracking. Appl. Sci. 2020, 11, 56. [Google Scholar] [CrossRef]
- Sulikowski, P.; Ryczko, K.; Bąk, I.; Yoo, S.; Zdziebko, T. Attempts to Attract Eyesight in E-Commerce May Have Negative Effects. Sensors 2022, 22, 8597. [Google Scholar] [CrossRef]
- Sulikowski, P.; Kucznerowicz, M.; Bąk, I.; Romanowski, A.; Zdziebko, T. Online Store Aesthetics Impact Efficacy of Product Recommendations and Highlighting. Sensors 2022, 22, 9186. [Google Scholar] [CrossRef]
- Sharma, M.; Mittal, R.; Bharati, A.; Saxena, D.; Singh, A.K. A Survey and Classification on Recommendation Systems. In Proceedings of the 2nd International Conference on Big Data, Machine Learning and Applications (BigDML 2021), Silchar, India, 19–20 December 2021; pp. 1–16. [Google Scholar]
- Çano, E.; Morisio, M. Hybrid recommender systems: A systematic literature review. Intell. Data Anal. 2017, 21, 1487–1524. [Google Scholar] [CrossRef] [Green Version]
- Christy, A.J.; Umamakeswari, A.; Priyatharsini, L.; Neyaa, A. RFM ranking—An effective approach to customer segmentation. J. King Saud Univ. Comput. Inf. Sci. 2018, 33, 1251–1257. [Google Scholar] [CrossRef]
- Rahim, M.A.; Mushafiq, M.; Khan, S.; Arain, Z.A. RFM-based repurchase behavior for customer classification and segmentation. J. Retail. Consum. Serv. 2021, 61, 102566. [Google Scholar] [CrossRef]
- Hughes, A.M. Strategic Database Marketing: The Masterplan for Starting and Managing a Profitable, Customer-Based Marketing Program, 3rd ed.; McGraw-Hill Pub. Co.: New York, NY, USA, 2005. [Google Scholar]
- Yavuz, S.; Deveci, M. The Effect of Statistical Normalization Techniques on the Performance of Artificial Neural Network. J. Erciyes Univ. Fac. Econ. Adm. Sci. 2012, 1, 167–187. [Google Scholar] [CrossRef]
- Ikotun, A.M.; Ezugwu, A.E.; Abualigah, L.; Abuhaija, B.; Heming, J. K-means clustering algorithms: A comprehensive review, variants analysis, and advances in the era of big data. Inf. Sci. 2023, 622, 178–210. [Google Scholar] [CrossRef]
- Agarwal, S. Data Mining: Data Mining Concepts and Techniques. In Proceedings of the 2013 International Conference on Machine Intelligence and Research Advancement, Katra, India, 21–23 December 2013; pp. 203–207. [Google Scholar] [CrossRef]
- Nainggolan, R.; Perangin-angin, R.; Simarmata, E.; Tarigan, A.F. Improved the Performance of the K-Means Cluster Using the Sum of Squared Error ({SSE}) optimized by using the Elbow Method. J. Phys. Conf. Ser. 2019, 1361, 12015. [Google Scholar] [CrossRef]
- Kumar, B.; Rukmani, K. Implementation of Web Usage Mining Using APRIORI and FP Growth Algorithms. Int. J. Adv. Netw. Appl. 2010, 404, 400–404. [Google Scholar]
- Bilgin, T.T.; Çamurcu, Y. Applied Comparison of DBSCAN, OPTICS and K-Means Clustering Algorithms. J. Polytec. 2005, 8, 139–145. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Numeric Code | Region |
|---|---|
| 1 | Marmara Region |
| 2 | Aegean Region |
| 3 | Mediterranean Region |
| 4 | Central Anatolia Region |
| 5 | Eastern Anatolia Region |
| 6 | Southeastern Anatolia Region |
| 7 | Black Sea Region |
| Cluster | Frequency | Monetary | Recency | Two Busiest Regions | Customer Quantity |
|---|---|---|---|---|---|
| 1 | 1.355 | 155.773 | 203.985 | 1 and 2 | 18,244 |
| 2 | 6.343 | 1075.469 | 223.297 | 1 and 4 | 674 |
| 3 | 0.634 | 132.360 | 798.468 | 1 and 3 | 14,258 |
| Cluster | Antecedent | Description | Consequent | Description | Support (%) | Confidence (%) |
|---|---|---|---|---|---|---|
| 1 | M_BLT | Men Belt | M_PNT | Men Trousers | 2.442 | 46.847 |
| 1 | W_SHS | Women Shirt Short Sleeve | W_TSS | Women T-Shirt Short Sleeve | 1.579 | 43.454 |
| 1 | W_ATH | Women Athletes | W_TSS | Women T-Shirt Short Sleeve | 4.795 | 38.440 |
| 1 | M_ATH | Male Athlete | M_TSS | Men T-Shirt Short Sleeve | 1.157 | 38.403 |
| 1 | M_SCK | Men Socks | M_PNT | Men Trousers | 3.621 | 35.358 |
| 1 | M_SRT | Men Shorts | M_TSS | Men T-Shirt Short Sleeve | 3.779 | 35.274 |
| 1 | W_BLT | Women Belt | W_PNT | Women Pants | 2.838 | 35.194 |
| 1 | M_SHG | Men Shirt Long Sleeve | M_PNT | Men Trousers | 7.193 | 33.700 |
| 1 | W_TSL | Women T-Shirt Long Sleeve | W_TSS | Women T-Shirt Short Sleeve | 2.820 | 33.541 |
| 1 | W_SCK | Women Socks | W_PNT | Women Pants | 3.951 | 32.183 |
| 2 | M_BLT | Men Belt | M_PNT | Men Trousers | 3.804 | 55.970 |
| 2 | M_TSS and W_PNT | Men T-Shirt Short Sleeve and Women Pants | W_TSS | Women T-Shirt Short Sleeve | 1.022 | 55.556 |
| 2 | W_BLT | Women Belt | W_PNT | Women Pants | 1.646 | 51.724 |
| 2 | M_SCK | Men Socks | M_PNT | Men Trousers | 2.299 | 50.617 |
| 2 | W_SHG and W_TSS | Women Shirt Long Sleeve and Women T-Shirt Short Sleeve | W_PNT | Women Pants | 2.157 | 50.000 |
| 2 | M_SHG | Men Shirt Long Sleeve | M_PNT | Men Trousers | 10.304 | 49.587 |
| 2 | M_PLV and M_SHG | Men Sweater and Men Shirt Long Sleeve | M_PNT | Men Trousers | 1.107 | 48.718 |
| 2 | W_SCK | Women Socks | W_PNT | Women Pants | 2.157 | 48.684 |
| 2 | M_SHS | Men Shirt Short Sleeve | M_PNT | Men Trousers | 6.812 | 46.667 |
| 2 | W_TNC | Women Tunic | W_TSS | Women T-Shirt Short Sleeve | 1.646 | 46.552 |
| 3 | M_BLT | Men Belt | M_PNT | Men Trousers | 3.556 | 48.667 |
| 3 | W_TNC | Women Tunic | W_TSS | Women T-Shirt Short Sleeve | 1.387 | 45.299 |
| 3 | W_SHS | Women Shirt Short Sleeve | W_TSS | Women T-Shirt Short Sleeve | 1.576 | 41.353 |
| 3 | M_SRT | Men Shorts | M_TSS | Men T-Shirt Short Sleeve | 5.109 | 38.051 |
| 3 | M_PTK | Men Polo Short-Sleeve | M_TSS | Men T-Shirt Short Sleeve | 4.498 | 37.286 |
| 3 | W_ATH | Women Athletes | W_TSS | Women T-Shirt Short Sleeve | 4.350 | 37.193 |
| 3 | M_SRB | Men Sea Shorts | M_TSS | Men T-Shirt Short Sleeve | 2.465 | 37.019 |
| 3 | M_SHG | Men Shirt Long Sleeve | M_PNT | Men Trousers | 8.416 | 35.775 |
| 3 | M_SLR | Men Slipper | M_TSS | Men T-Shirt Short Sleeve | 2.027 | 35.380 |
| 3 | W_TSL | Women T-Shirt Long Sleeve | W_TSS | Women T-Shirt Short Sleeve | 3.360 | 35.097 |
| Category | Description | Purchase Quantity |
|---|---|---|
| W_PNT | Women Pants | 6 |
| W_CRD | Women Cardigan | 4 |
| W_TSS | Sleeve | 3 |
| W_PLV | Women Sweater | 2 |
| W_SRT | Women Shorts | 2 |
| W_ATH | Women Athletes | 1 |
| W_COA | Women Coat | 1 |
| W_SCK | Women Socks | 1 |
| W_SHG | Women Shirt Long Sleeve | 1 |
| W_SKR | Women Skirt | 1 |
| W_SRB | Women Sea Shorts | 1 |
| W_SWS | Women Sweatshirt | 1 |
| Antecedent | Description | Consequent | Description | Support (%) | Confidence (%) |
|---|---|---|---|---|---|
| W_TSS | Women T-Shirt Short Sleeve | W_PNT | Women Pants | 13.738 | 39.876 |
| W_CRD | Women Cardigan | W_PNT | Women Pants | 3.094 | 35.780 |
| W_CRD | Women Cardigan | W_PLV | Women Sweater | 3.094 | 30.275 |
| W_CRD | Women Cardigan | W_TSS | Women T-Shirt Short Sleeve | 3.094 | 23.853 |
| W_CRD | Women Cardigan | W_SWS | Women Sweatshirt | 3.094 | 22.018 |
| W_PNT | Women Pants | W_TSS | Women T-Shirt Short Sleeve | 27.022 | 20.273 |
| W_CRD | Women Cardigan | W_TSL | Women T-Shirt Long Sleeve | 3.094 | 18.349 |
| W_CRD | Women Cardigan | W_SHG | Women Shirt Long Sleeve | 3.094 | 17.431 |
| W_TSS | Women T-Shirt Short Sleeve | W_SHG | Women Shirt Long Sleeve | 13.738 | 15.702 |
| W_TSS | Women T-Shirt Short Sleeve | W_ATH | Women Athletes | 13.738 | 15.289 |
| W_TSS | Women T-Shirt Short Sleeve | M_TSS | Men T-Shirt Short Sleeve | 13.738 | 15.289 |
| Model | Category | Description | Order |
|---|---|---|---|
| CL1004735 | W_PLV | Women Sweater | 1 |
| CL1003827 | W_PLV | Women Sweater | 2 |
| CL1006477 | W_PLV | Women Sweater | 3 |
| CL1005006 | W_PLV | Women Sweater | 4 |
| CL1005054 | W_PLV | Women Sweater | 5 |
| CL1013242 | W_PNT | Women Pants | 1 |
| CL1013265 | W_PNT | Women Pants | 2 |
| CL1017746 | W_PNT | Women Pants | 3 |
| CL1013322 | W_PNT | Women Pants | 4 |
| CL1013333 | W_PNT | Women Pants | 5 |
| CL1014261 | W_SWS | Women Sweatshirt | 1 |
| CL1022345 | W_SWS | Women Sweatshirt | 2 |
| CL1022346 | W_SWS | Women Sweatshirt | 3 |
| CL1023071 | W_SWS | Women Sweatshirt | 4 |
| CL1024806 | W_SWS | Women Sweatshirt | 5 |
| CL1018843 | W_TSS | Women T-Shirt Short Sleeve | 1 |
| CL1018592 | W_TSS | Women T-Shirt Short Sleeve | 2 |
| CL1017197 | W_TSS | Women T-Shirt Short Sleeve | 3 |
| CL1018603 | W_TSS | Women T-Shirt Short Sleeve | 4 |
| CL1017935 | W_TSS | Women T-Shirt Short Sleeve | 5 |
| E-mail ID | Item Code | Category | Description | Order Number |
|---|---|---|---|---|
| 40881 | CL1021011 | W_SHG | Women Shirt Long Sleeve | 0000115725_WO |
| 40881 | CL1017746 | W_PNT | Women Pants | 0000115725_WO |
| 40881 | CLBDEWSRT0329070 | W_SRT | Women Shorts | 0000115725_WO |
| 40881 | CL1019961 | W_SRB | Women Sea Shorts | 0000115725_WO |
| Cluster | Period of the Analyzed Timeframe’s 3rd Year | Recall | Precision | F1 | Average of Sales |
|---|---|---|---|---|---|
| 1 | January–March | 0.167 | 0.140 | 0.152 | 76.38 |
| 1 | April–June | 0.248 | 0.161 | 0.195 | 71.18 |
| 1 | July–September | 0.081 | 0.069 | 0.075 | 77.76 |
| 1 | October–December | 0.266 | 0.138 | 0.182 | 75.92 |
| 2 | January–March | 0.117 | 0.096 | 0.106 | 65.53 |
| 2 | April–June | 0.212 | 0.153 | 0.178 | 73.28 |
| 2 | July–September | 0.235 | 0.099 | 0.139 | 74.36 |
| 2 | October–December | 0.192 | 0.130 | 0.155 | 76.99 |
| Average | 0.148 | 73.92 | |||
| Cluster | Period of the Analyzed Timeframe’s 3rd Year | Recall | Precision | F1 | Average of Sales |
|---|---|---|---|---|---|
| 1 | January–March | 0.184 | 0.137 | 0.157 | 80.89 |
| 1 | April–June | 0.242 | 0.171 | 0.200 | 67.65 |
| 1 | July–September | 0.085 | 0.082 | 0.084 | 84.32 |
| 1 | October–December | 0.212 | 0.149 | 0.175 | 73.87 |
| 2 | January–March | 0.122 | 0.105 | 0.113 | 71.05 |
| 2 | April–June | 0.231 | 0.161 | 0.190 | 79.92 |
| 2 | July–September | 0.221 | 0.102 | 0.139 | 75.37 |
| 2 | October–December | 0.209 | 0.124 | 0.155 | 72.51 |
| Average | 0.152 | 75.70 | |||
| Cluster | Period of the Analyzed Timeframe’s 3rd Year | Recall | Precision | F1 | Average of Sales |
|---|---|---|---|---|---|
| 1 | January–March | 9.239 | −2.190 | 3.185 | 5.575 |
| 1 | April–June | −2.479 | 5.848 | 2.500 | −5.218 |
| 1 | July–September | 4.706 | 15.854 | 10.714 | 7.780 |
| 1 | October–December | −25.472 | 7.383 | −4.000 | −2.775 |
| 2 | January–March | 4.098 | 8.571 | 6.195 | 7.769 |
| 2 | April–June | 8.225 | 4.969 | 6.316 | 8.308 |
| 2 | July–September | −6.335 | 2.941 | 0.000 | 1.340 |
| 2 | October–December | 8.134 | −4.839 | 0.000 | −6.178 |
| Average | 3.114 | 2.075 | |||
| Cluster | Period of the Analyzed Timeframe’s 2nd Year | Recall | Precision | F1 | Average of Sales |
|---|---|---|---|---|---|
| 3 | January–March | 0.183 | 0.150 | 0.165 | 74.42 |
| 3 | April–June | 0.143 | 0.125 | 0.134 | 61.56 |
| 3 | July–September | 0.166 | 0.114 | 0.135 | 78.42 |
| 3 | October–December | 0.196 | 0.139 | 0.162 | 68.70 |
| Average | 0.149 | 70.78 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yıldız, E.; Güngör Şen, C.; Işık, E.E. A Hyper-Personalized Product Recommendation System Focused on Customer Segmentation: An Application in the Fashion Retail Industry. J. Theor. Appl. Electron. Commer. Res. 2023, 18, 571-596. https://doi.org/10.3390/jtaer18010029
Yıldız E, Güngör Şen C, Işık EE. A Hyper-Personalized Product Recommendation System Focused on Customer Segmentation: An Application in the Fashion Retail Industry. Journal of Theoretical and Applied Electronic Commerce Research. 2023; 18(1):571-596. https://doi.org/10.3390/jtaer18010029
Chicago/Turabian StyleYıldız, Emre, Ceyda Güngör Şen, and Eyüp Ensar Işık. 2023. "A Hyper-Personalized Product Recommendation System Focused on Customer Segmentation: An Application in the Fashion Retail Industry" Journal of Theoretical and Applied Electronic Commerce Research 18, no. 1: 571-596. https://doi.org/10.3390/jtaer18010029
APA StyleYıldız, E., Güngör Şen, C., & Işık, E. E. (2023). A Hyper-Personalized Product Recommendation System Focused on Customer Segmentation: An Application in the Fashion Retail Industry. Journal of Theoretical and Applied Electronic Commerce Research, 18(1), 571-596. https://doi.org/10.3390/jtaer18010029