1. Introduction
Since the introduction of entropy to information theory [
1], a lot of research has been concerned with refining and applying the term entropy for different fields of application.
In our work presented in this paper, we study the impact of entropy for the field of handwriting recognition. Why handwriting? Handwriting is more than just the use of pen and paper. It can also be seen as a very natural way of communication between humans and computers. Even though keyboards have proven to be an effective interface, the advancement in computational technology calls for a new or at least different way of human-computer interaction. The ultimate goal here is to make the communication with electronic devices feel as natural as communicating with other humans, without the restriction of an additional learning process. This puts speech recognition and handwriting recognition in the focus of future user interfaces.
In 2007 Steve Jobs argued “Who need a stylus?". Yet interestingly, Apple has made a patent application on stylus [
2], and the use of stylus even dates back to the Apple Newton [
3]. Undoubtedly, it is true that touch input is well accepted and easy to learn, even amongst non-computer literate people and elderly people [
4,
5]. Devices with touch screens are useful in hospitals, where patients can, for example, fill out questionnaires while they are waiting for their examination, for the reception by the doctor, or during other spare times [
6].
Direct input of questionnaire answers by the patients makes the error prone and time consuming copying of completed paper sheets unnecessary. This saves time, which can be used for direct contact with the patient, thereby improving the overall quality of the interaction between doctors and their patients. Although touch is a very intuitive way of interaction, it was shown that in a professional medical context, styluses are preferred over finger-based input [
7].
Input via stylus has the advantage of being more precise and the action is similar to the user’s accustomed writing on sheets of paper—and paper is still a preferred medium in the hospital [
8]. For addressing the problem of imprecise touch using fingers, Vogel and Baudisch [
9] developed a system called Shift, which makes it possible to make more precise selections using a finger. Shift shows a copy of the touched screen location and shows a pointer representing the selection point of the finger if the finger is placed over a small target. However, for further improving the precision of touch input via finger it must be better understood how people touch touch screens [
10].
Another problem with touch input using fingers is that the user’s “fat fingers" also cover the areas the user intends to touch. To circumvent this problem, [
11] developed a mobile device that can be operated from the back. In addition, by using back-of-device interaction, it is possible to create very small touch devices [
12].
Despite all these facts, medical professionals (medical doctors, nurses, therapists, first responders,
etc.) are more familiar with dictation and handling a stylus, since they are used to handling a pen all the time [
7,
13], despite the issue of poor handwriting in medicine generally [
14].
As regards input technology, the most recent development on the mobile market is at contrast to the preferred input technique of professionals in the medical domain, whereas from the viewpoint of Human-Computer Interaction (HCI), handwriting can be seen as a very natural input technology [
15]. Studies have shown that a recognition rate below 97% is not acceptable to end users [
16]. The challenge in developing such a system is the fact that the art of handwriting is very individual, making a universal recognition of all handwriting particularly demanding [
17].
A typical example is the case of incoming patients in the triage (aka EBA: first clinical examination), where it is similar to an emergency: Rapid patient information collection is crucial. Promptly and accurately recorded and well communicated vital patient data can make the difference between life and death [
18,
19]. Consequently, the data acquisition should have as little disruptive effect on the workflow of the medical professionals as possible. In the past, solutions for data input on mobile applications have been tested in the field [
7,
15,
17,
20,
21,
22,
23].
Due to the fact that emergencies are usually complicated by difficult physical situations, special attention has to be given to the design of information technology for emergencies [
24]. A key issue of any such information system is the acquisition of textual information. However, extensive text entry on mobile devices is principally to be avoided and a simple and easy to use interface, in accordance with the maxim
less is more, is a supreme necessity [
22].
The basic evidence is that entering data into a mobile device via a stylus is slower, more erroneous and less satisfactory for end users than entering data via a QWERTZ (de) or QWERTY (us) keyboard, as has been demonstrated in some studies [
25,
26], however, the use of a stylus is much faster and more accurate than using finger touch [
7].
We will start by talking about the theory behind handwriting and briefly explain how online handwriting recognition is practised today. After explaining the mathematical background, we will go into related work and talk about how entropy has been used in the field of handwriting for the last 35 years. There is very little application, as of today, in the field of online handwriting recognition. This enabled us to carefully re-implement those processes step by step. After presenting our results, we will conclude this paper by talking about possible future application of entropy in the field of handwriting recognition.
1.1. History of Handwriting Recognition
Handwriting has a long tradition in mankind and goes back to the early cave painters [
27]. The ingenious idea of captivating human thoughts into signs and symbols (pictures, later with letters) was a major cultural step. Plato (428–328 BC) described the human memory as a wax tablet and the Romans used a stylus (Latin: stilus) and wax-tablet (Latin: tabula cerata) as handwriting capturing tool, which looks astonishing similar to our stylus and touch-tablets of today (see
Figure 1).
With the advent of modern technology, more sophisticated ideas of captivating handwriting emerged: The first patent was issued in the US to Elisa Gray in 1888 for an electrical stylus for captivating handwriting and transmission via telegraph. The first patent on handwriting recognition, as we know it still today, was issued in 1914 and in 1915 to Hyman Eli Goldberg on the on-line recognition of hand-written numerals to control a machine in real-time. In 1945 handwriting recognition was also described by Vannevar Bush within the context of the MEMEX (Memory expander) vision, followed by real-world implementations in form of the Stylator in 1957, the RAND tablet in 1961 and the electronic ink project GRAIL in 1969. For detailed information on the Archaeology of handwriting recognition refer to [
28].
Figure 1.
A roman writer from Constantinian time (306-337 AD) holding a wax-tablet (Latin: hexaptychon) in his left hand and a stylus in his right hand (Sculpture in the Lapidarium of the Landesmuseum Joanneum in Graz, Eggenberg, picture taken 7 November 2012 by the authors.
Figure 1.
A roman writer from Constantinian time (306-337 AD) holding a wax-tablet (Latin: hexaptychon) in his left hand and a stylus in his right hand (Sculpture in the Lapidarium of the Landesmuseum Joanneum in Graz, Eggenberg, picture taken 7 November 2012 by the authors.
1.2. Model of Handwriting
Handwriting recognition (HWR) methods can generally be classified into offline and online recognition. While offline handwriting recognition deals with a bitmap presentation of the handwriting, online handwriting recognition uses the pen trajectory as input. Since in this paper we are concerned with online handwriting recognition, we model the continuous handwriting input signal given by an input device as
It contains the coordinates
and
as well as the pressure
of the stylus [
29]. It might be interesting to note that some devices also provide azimuth and inclination of the stylus [
30]. After the digitalization process,
is considered as a discrete time series sampled at different points
over time. Let the sampling times be
, satisfying
. If the time points are equally spaced (
i.e.,
for all
,
some constant), we call the input signal
regularly sampled.
Let
be the Euclidian distance with respect to the coordinates
and
. A sampling of the handwriting trajectory satisfying
, for some constant
and
, is referred as the
equidistant re-sampling of the time series
. One notices that
holds and in general the equidistant re-sampling is not regular (see
Figure 2).
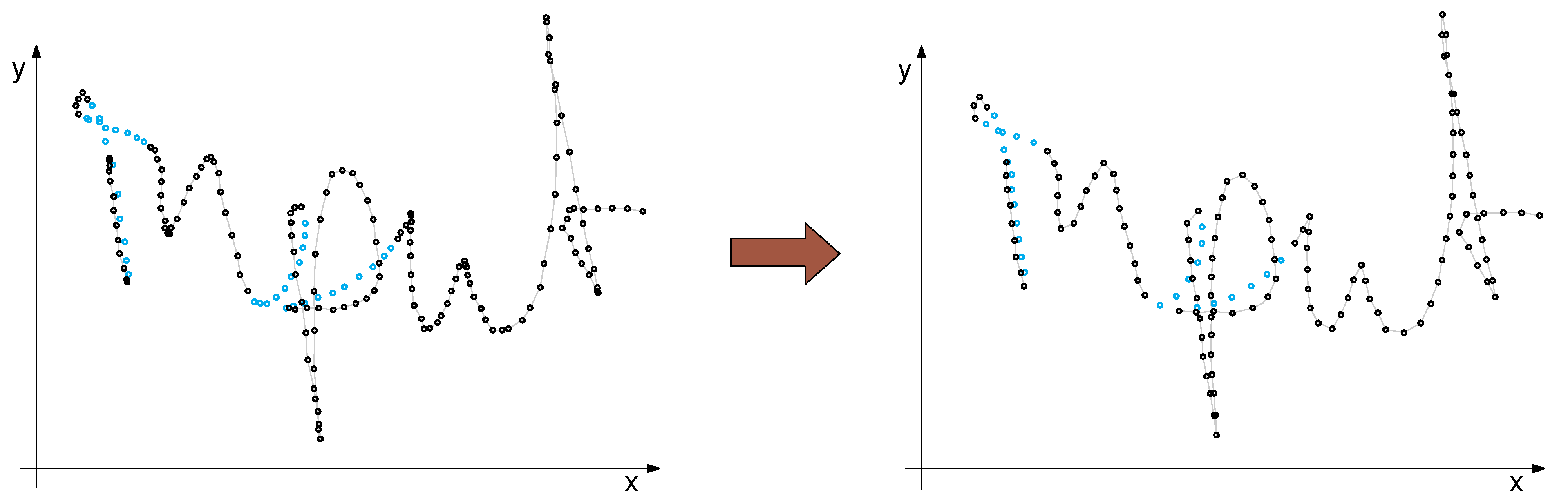
Figure 2.
Example of a regularly sampled input signal (left) and its equidistant re-sampling (right).
Figure 2.
Example of a regularly sampled input signal (left) and its equidistant re-sampling (right).
2. Theoretical Background
Handwriting recognition in general has to overcome a lot of obstacles. To understand handwriting recognition, one has to recognize a few basic things about handwriting in general. Every writer differs in his handwriting-style from one another in a unique way. Sometimes they differ so much that it is even hard for the other person to read it.
Many people do not write in distinct letters with clear spacing between them. Often letters tend to run together, making it harder to separate them. But even if one can segment the characters, identification remains a problem. Some characters, such as I-1, O-0, l-1, 5-S, 6-G tend to look alike, or even the same, again depending on the writer [
31]. Hence, sometimes characters are only distinguishable through the context in which they occur [
32].
Handwriting recognition is still considered an open research problem, mainly due to the substantial individual variation in appearance. Consequently, the challenges include the distortion of handwritten characters, since different people may use different style of handwriting, direction,
etc. [
33].
If a system needs to deal with the input of different end users, a training phase is required to enable the system to understand the user’s art of writing. The data received in this phase is stored in a database. During the recognition process, the system compares the input with the stored data and calculates the output.
Handwriting can be characterized as a sequence of basic strokes connected according to a rule. Consequently, recognition can be seen as a matching process, used as the fundamental principle in a handwriting recognizer. Early work in handwriting recognition dates back into the 1960s [
34].
2.1. Handwriting Properties
Every written language has an alphabet consisting of different characters and most of the time a handful of symbols for punctuation. Handwriting typically consists of different strokes done by the writer. A stroke is the path of the tip of a pen from pen down to pen up. There can be more than one stroke per letter, but there can also be more than one letter per stroke.
A basic principle behind any written language, and the condition that makes communication possible, is that the difference between different characters is greater than the difference between multiple drawings of the same character [
31]. An example for different drawings of the letter “R" can be seen in
Figure 3. There are however exceptions, as was mentioned before. Some characters, like O and 0, tend to look alike and are sometimes only distinguishable through the context in which they occur [
32].
Figure 3.
Different drawings of the same character.
Figure 3.
Different drawings of the same character.
In the Latin alphabet, all characters vary in their static and dynamic properties. Static properties would be things like size and shape, while dynamic properties are typically things like stroke number and order [
31].
2.2. The Process of Online Handwriting Recognition
The process of online handwriting recognition can be broken down into a few general steps: preprocessing, feature extraction and classification [
35].
The purpose of preprocessing is to discard irrelevant information in the input data that can negatively affect the recognition [
36]. This means speed and accuracy. Preprocessing usually consists of binarization, normalization, sampling, smoothing and denoising [
35].
The second step is feature extraction. Out of the two- or three-dimensional vector field received from the preprocessing algorithms, higher dimensional data is extracted. The purpose of this step is to highlight important information for the recognition model [
32]. This data may include information like pen pressure, velocity or the changes of writing direction.
The last big step is classification. In this step various models are used to map the extracted features to different classes and thus identifying the characters or words the features represent.
2.3. Impact of Skew and Slant in Handwriting Recognition
Tang
et al. [
37,
38] pointed out the potential of preprocessing by introducing the Entropy-Reduced Transformation, where the goal is to reduce the entropy of the input data set. Since distortions in the input data, like skew or slant, increase the entropy of the data set, they increase the variations within samples that represent the same class and thus making it more challenging for the recognition process to yield good results. While slant correction can often be ignored in writer dependent systems, where the slant might be consistent for the writer, it is especially important for writer independent systems. The goal is to minimize the variation between different drawings of the same character. Slant correction is also useful to simplify the segmentation procedure.
Brakensiek
et al. [
39] investigated the influence of skew- and slant-correction in the recognition rate, while using entropy-based techniques. In the case of a writer independent system, they reported an increase of 0.9% to a total recognition rate of 86.7% for a test set of 4153 words. They have also shown that the recognition error of their writer independent system can be reduced by about 7% (compared with only re-sampled data). This tells us that good solutions for skew- and slant-correction would in fact be useful.
Kosmala [
32] reported a precision of about
for an entropy based skew correction approach, with the restriction of enough data points being available. For an entropy based slant correction approach he reported an average precision of
.
Guerfali and Plamondon [
40] used the least squares method for skew correction and reported a precision of
for a range of allowed angles of
. For their window based slant correction they have shown an average precision of
, which they considered as acceptable, because the accuracy of the subjects slant was about
[
40].
2.4. Challenges of Skew- and Slant-Correction
The effectiveness of skew- and especially slant-correction is still very much dependent on some properties of the input data. Short words, for example, can be a big problem for skew correction. Also, the range of allowed angles can significantly influence the correction precision. A bigger range of angles allow for bigger outliers.
For words written without an available reference line, the base line might not be unique, as the characters tend to vary in size. Also some writers may vary in the shearing angle even within the same word, rendering slant correction with only one angle to describe the distortion impractical. An example for a slant variation of about
can be seen in
Figure 4. Thus, automatic identification of a unique slant angle might not always be possible—not even with human intervention. To emphasize this, Guerfali and Plamondon [
40] asked ten subjects to determine the slant of each one of 275 words. They used the averages of the selected angles as references, while the standard deviations were treated as indication of an acceptable error. Their results have shown that the standard deviation is about
. This does not necessarily apply for our test results. Nevertheless, it shows that there is in fact an ambiguity involved.
There are promising approaches using local slant. They do so by employing dynamic programming techniques to apply different shearing angles at different points within the word [
41]. However, as the algorithm has more freedom to make errors within a word, there are more robustness issues to address [
42].
Figure 4.
Challenges of slant correction. The angle ϕ varies between 30 and 43 degrees.
Figure 4.
Challenges of slant correction. The angle ϕ varies between 30 and 43 degrees.
2.5. Mathematical Background
In this section we describe the mathematical background necessary to understand the methods we mention in this paper. We start by defining the entropy along with a partitioning. We will use them as correction mechanism for rotation distortions (skew) and sheering distortions (slant).
Let
be a discrete probability set of a variable
X, then the entropy
is defined as
Denote
a partition for an equidistant re-sampling of
with some constant mesh
,
. The partitioning resembles a binning, which can be used to determine the properties
with
being the indicator function for the
j-th bin
As an alternative method for skew correction, we use the least square method to identify the error angle alpha [
40]. Let
n be the number of minima in
X,
be the coordinates of the minimum point
and
be the sampling instant of the
i-th minima, then the error angle
α is defined as
Since we deal with distortions, to be precise with rotation and sheering distortions, we need to define correction mechanism once the error angles have been defined.
Let
X be the input signal to be rotated by an angle
α. Then the skew corrected signal
is defined as
with
being the rotation matrix
Let
X be the input signal to be slanted by an angle
ϕ. Then the slant corrected signal
is defined as
with
being the sheering matrix
3. Related Work
Entropy found its way into pattern recognition in a number of ways. In this paper, however, we will focus on handwriting recognition. To be specific, we focus on the online handwriting recognition. However, entropy is also used in optical character recognition. In this section we will briefly describe how entropy is applied in the case of the offline handwriting recognition and the writer identification in online handwriting.
Sesa-Nogueras
et al. [
30] analyzed, from an information theory perspective, the gestures produced by human beings when handwriting a text. They used additional handwriting features, such as azimuth and inclination of the stylus. By analyzing the entropy of on-surface and in-air trajectories, which means that the stylus is either touching the surface or is in the air transitioning between strokes, they showed that the amount of information is similar in both trajectories, which in turn appear to be notably non-redundant.
Handwritten characters vary a lot, which consequently requires measures that reflect the variation for a given set of data. For this purpose, Kim
et al. [
43] defined four properties that a variation measure for character data is supposed to satisfy.
Boundedness: because a variation measure should be independent of the size of the image and the number of images in a single data set, i.e., the variation values should be bounded by a constant maximum and a constant minimum;
Independency: because a variation measure should be independent of the size of the white area in an image as well as the pen used to create images;
Monotonicity, because a variation measure should increase monotonically as the grey area of a data set increases;
Constancy, because a variation measure should be independent of the complexity of the character itself.
The authors demonstrated that none of the variation measures proposed at that time satisfied all four properties. Consequently, they introduced a new variation measure,
Average Entropy Difference, and showed that it satisfied all four properties.
Average Entropy Difference Let C be defined as where is the entropy of the point . Denote the cardinality of C, then the Average Entropy Difference is defined as with being the Entropy Difference of a point . Since for , the Average Entropy Difference is also defined as Park
et al. [
44] proposed a quality measurement method of gray-scale handwriting data to compare different data objectively. For this they defined an Extended Average Entropy, as an extension of the Average Entropy (AE) in binary-scale. They intended to directly measure the handwriting qualities in a given gray-scale character database. Moreover, they measured the quality of each sample in a class, and classified all data within a class into several groups according to their handwriting qualities. The results of Park
et al. confirmed that their method was useful for measuring the qualities of handwritten Hangul characters (the Korean alphabet). This Extended Average Entropy (EAE) works as follows:
Extended average entropy Given M images of size with L gray levels , let the gray level of a pixel be denoted by . Then, the frequency of the gray level l at position is defined as where when , i.e.
, the gray level at position is equal to l. Therefore, the frequency has a value of . Furthermore, let be probability of the gray level l at position and be the corresponding entropy with a logarithmic base of L, then the extended average entropy (EAE) in gray-scale is defined as 4. Materials and Methods
In this section we will go through preprocessing step by step, while focusing on the normalization techniques using entropy. In particular, we will focus on performing normalization techniques based on the idea of Cote
et al. [
45], as well as Kavallieratou
et al. [
46] and adapted to online handwriting recognition by Kosmala [
32] as well as Schenk and Rigoll [
29].
We will also describe alternative methods for the normalization processes, like skew correction with the use of the least squares method described by Guerfali and Plamondon [
40], which we will later use to benchmark the entropy based methods against.
4.1. Sampling
Most of the time sampling, sometimes referred to as filtering [
40], is performed after normalization and may as well be the last step of preprocessing. However, it is also common to start the preprocessing with sampling as well, since it is a low cost process that can significantly increase the performance and accuracy of the other preprocessing steps, especially for normalization techniques that use the projection profile of the input data along an axis, as we will explain further down.
There are usually two reasons to perform sampling. One is to remove unnecessary detail in the form of over-fitting (too many points representing the drawing). The other one is to remove artifacts like pen velocity out of the input data. Keep in mind that the pen velocity could still be interesting for the recognition [
47]. In that case it has to be extracted and stored before applying the sampling process.
As mentioned before, the continuous input signal
is in general regularly sampled, resulting in an equidistant time series data concerning the time dimension [
32]. In some cases, such as in on-line handwritten whiteboard note recognition, the digitalized data may neither be equidistant in time nor in space [
29]. However, the goal of sampling remains the same, namely to re-sample the data to be equidistant in space, ideally without distorting the data. An example for data before and after the sampling process can be seen in
Figure 5.
Figure 5.
Visualization of the re-sampling process. The regularly sampled data (left) and its equidistant re-sampling (right).
Figure 5.
Visualization of the re-sampling process. The regularly sampled data (left) and its equidistant re-sampling (right).
4.2. Normalization
The normalization process is concerned with removing the variation of size and position information out of the input data. Most of the time this step consists of scaling and translating, in order to define a common base for recognition and give the writer the freedom to define the size he or she wants to write in. However, depending on the freedom the writer may have, it may also include correction mechanism for skew and slant. Again, the purpose of normalization is to define a common base, so that the recognizer does not have to deal with different sizes, skews and so forth.
4.2.1. Skew Correction Based on Entropy
Skew correction, or sometimes referred to as baseline drift correction [
40], is aimed at bringing the writing direction to the horizontal level.
A typical user interface for handwriting today contains some sort of indication on where to draw your character, word or sentence [
48,
49]. This may be in the form of a line or even a box. Hence, usually the drawing has the right orientation and does not have to be rotated. But if this is not the case, and the user is presented with the freedom to choose the user’s own point of reference, the input data might have a skew that needs to be corrected.
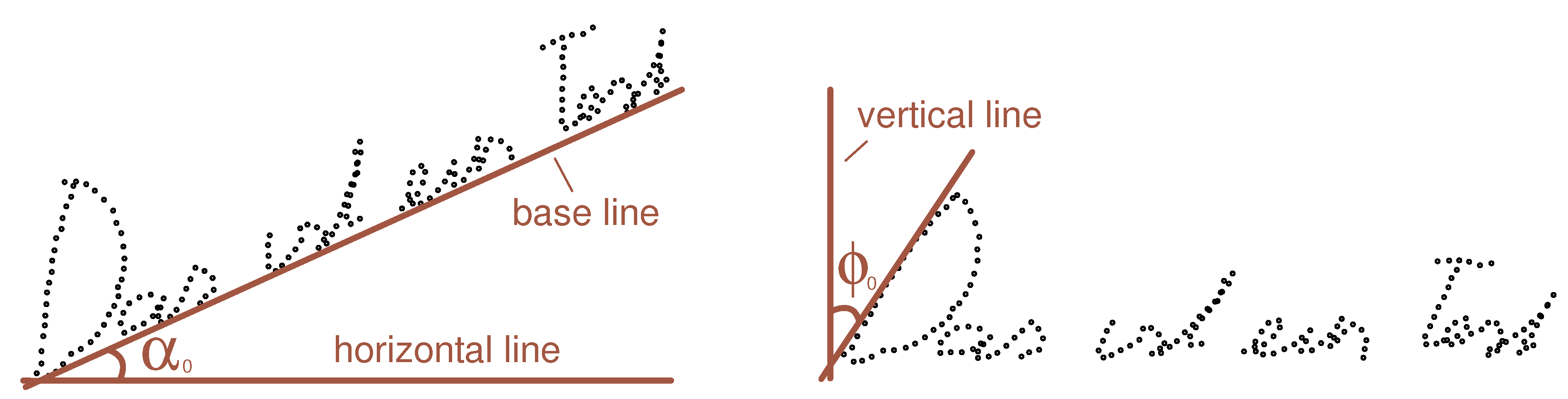
If skew correction needs to be done, the first issue that has to be identified is the error angle
. This is the angle between the base line and the horizontal line, as can be seen on the left side in
Figure 6.
Figure 6.
Visualization for the error angles and for performing skew- (left) or slant- (right) correction. The right figure is already skew corrected.
Figure 6.
Visualization for the error angles and for performing skew- (left) or slant- (right) correction. The right figure is already skew corrected.
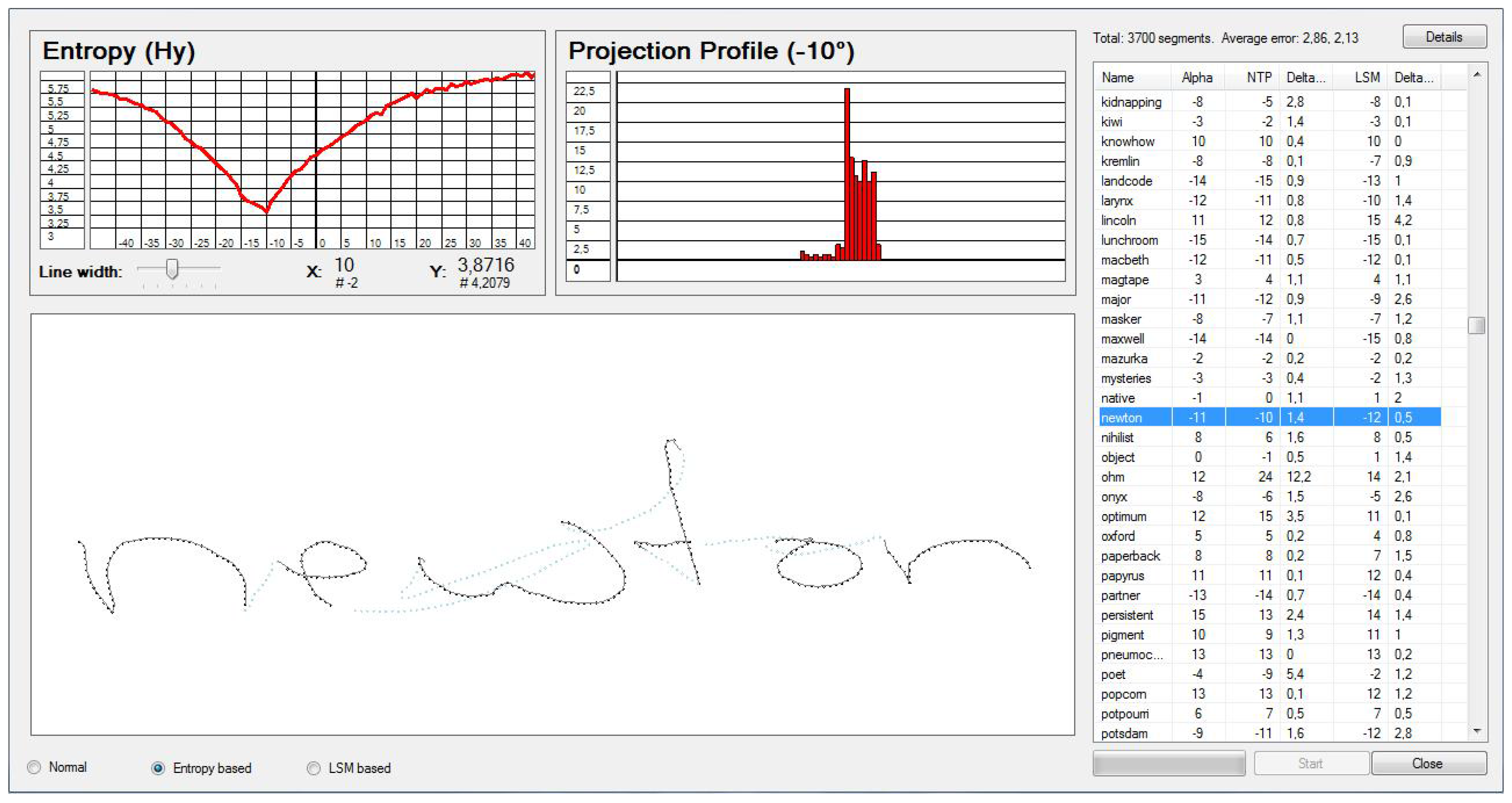
Once the error angle
has been identified, the data points have to be rotated. With respect to Equation (
6), let
be the time series after an equidistant re-sampling then the corresponding time series after the rotation is defined as
A promising approach described by Kosmala [
32] to identify the error angle
is to calculate the projection profile histogram
for a range of binns
. The minimum of the entropy distribution of
for a range of angles
α is then calculated.
We state the following assumption:
Hypothesis 1 The slope angle of the baseline, of an equidistant re-sampled time series representing a Latin based word, is closest to when the most y-coordinates of the time series are concentrated within some interval , , where is the height of the lower case letters.
Note that the height of the lower case letters is unknown. However, the entropy of a projection profile histogram gives a good indication on degree of order in the distribution. Hence if most of the data points are located within a small interval, the entropy is supposedly at its minimum.
We define projection profile histogram it in respect to Equation (
3) for the
y- axis and a range of different angles
α as
with
being the
y-component of
. An example for such a histogram can be seen in
Figure 7.
Figure 7.
Skew correction of a equidistant re-sampling of the handwriting trajectory . It was performed with the help of the projection profile histograms . This image shows the histogram for the corrected angle of .
Figure 7.
Skew correction of a equidistant re-sampling of the handwriting trajectory . It was performed with the help of the projection profile histograms . This image shows the histogram for the corrected angle of .
After calculating the projection profile
, the corresponding entropy
is computed based on Equation (
2) as
is set to the angle
α where
is at its minimum, as can be seen in
Figure 8.
Figure 8.
Skew- and slant-correction performed with the entropy of various projection profile histograms [
29,
32]. These images show the entropy distributions for different angles. The error angles
and
are set to the angle where the corresponding entropy distribution is at its minimum. Note that the entropy distribution of
(right side) is in general not as distinctive as the one of
(left side).
Figure 8.
Skew- and slant-correction performed with the entropy of various projection profile histograms [
29,
32]. These images show the entropy distributions for different angles. The error angles
and
are set to the angle where the corresponding entropy distribution is at its minimum. Note that the entropy distribution of
(right side) is in general not as distinctive as the one of
(left side).
This approach for skew correction supposedly can yield a high precision of about
, if there are enough data points available [
32].
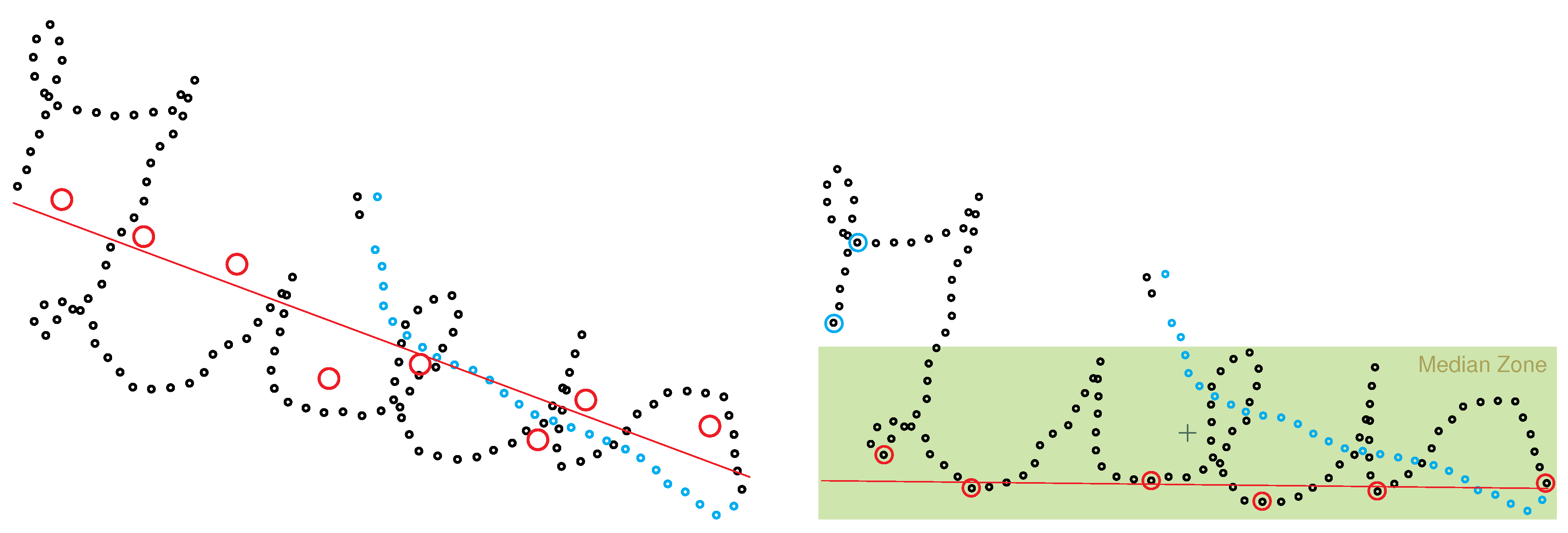
4.2.2. Skew Correction Based on Least Squares Method (LSM)
An alternative approach for skew correction based on the least squares method was introduced by Guerfali and Plamondon [
40]. The idea is that the writing baseline is defined as the best fitting straight line passing through the minima of the character drawings [
40].
Their approach is divided into two steps. The first step is aimed at detecting major deviations, which can cause errors in locating the real minima of the character drawings. The whole drawing is divided into eight equally spaced regions. For each region, the center of mass of all points within the region is calculated. The eight resulting points serve as input for the LSM to calculate an approximation for the real baseline. The angle α is set to the angle between the calculated baseline and the horizontal.
The second step uses a retroactive process consisting of successive estimations and rotations until satisfactory results are achieved [
40]. For this purpose the current minima of the drawing are located. To eliminate superfluous points, only minima within the median zone are used as input for the LSM. Again, the angle
α is set to the angle between the calculated baseline and the horizontal. The second step is repeated until an estimated baseline angle of less than
is reached [
40]. Both steps are visualized in
Figure 9.
Figure 9.
Skew correction performed with the least squares method [
40]. Step 1 uses the centers of mass of eight regions to compute the regression line can be seen on the left. Step 2 uses the minima within the median zone for the regression line on the right.
Figure 9.
Skew correction performed with the least squares method [
40]. Step 1 uses the centers of mass of eight regions to compute the regression line can be seen on the left. Step 2 uses the minima within the median zone for the regression line on the right.
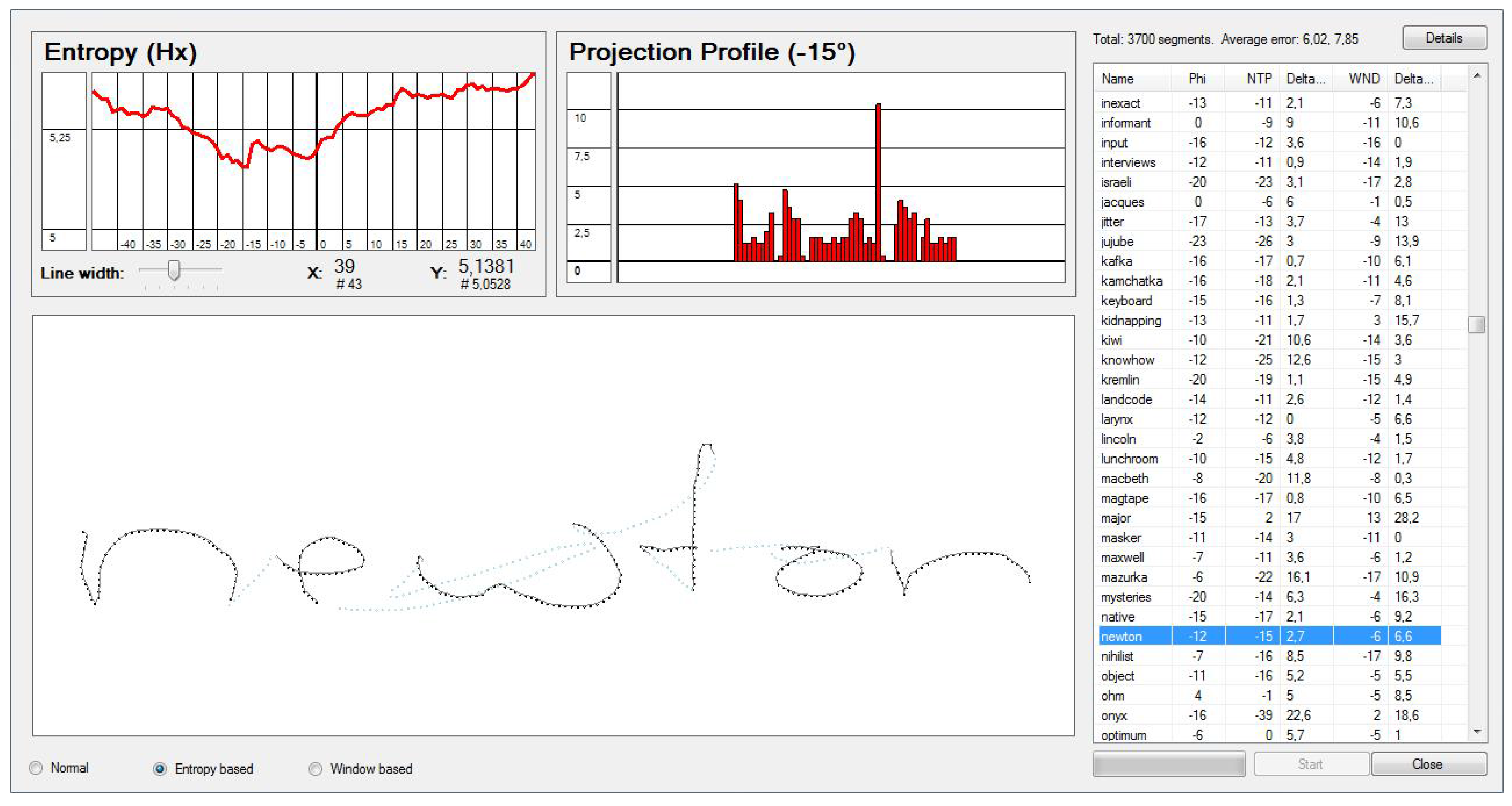
4.2.3. Slant Correction Based on Entropy
Slant correction is a little more problematic than skew correction. The slant is described by the error angle
, which is the angle between the vertical line and those lines of the drawn text that are supposed to be vertical. Also, the slant may vary along the drawing and might not be the same for all characters as was mentioned in
Section 2.4 and can be seen in
Figure 4.
The error angle
describing the slant can be computed similar to the error angle
mentioned in entropy based skew correction. The difference is that instead of calculating the relative occurrence of the data points along the
y-axis, the relative occurrence along the
x-axis
is used. The idea is that the entropy of the relative occurrence is at its minimum when all characters are oriented straight up [
29,
32]. However, the minimum of the entropy distribution might not always be unique, or correct for that matter. In a lot of cases, slant correction is not deemed to be applicable enough just now [
32].
Once the error angle
has been identified, the slant correction can be performed similar to the way the skew correction was performed. In respect to Equation (
8), let
be the time series after skew correction then the corresponding time series after slant correction is defined as.
For slant correction, we define the projection profile histogram with respect to Equation (
3), but this time for the
x-axis and a range of different angles
ϕ with
being the
x-component of
.
After calculating the projection profile histogram
, the corresponding entropy
is computed similar to skew correction and based on Equation (
2).
is set to the angle
ϕ where
is at its minimum, as can be seen in
Figure 8.
4.2.4. Script Line Identification
Script line identification is an important step in the normalization process. The primary purpose of the script lines in preprocessing is size normalization. However, they may also serve for feature extraction [
47]. In fields like whiteboard note recognition, where the script lines are much harder to detect, the script line identification process may also serve as a form of de-noising, in the sense that the data points might be modified in the process [
47].
There are four lines that have to be identified. Top line and bottom line are where the maximum and minimum
y coordinates of the data points are, and the whole drawing is between top and bottom line. However, those two lines alone are not enough information for scaling, because ascenders and descenders may distort the font size information of the drawing. Good indications for the font size would be the height of the lower case letters in the drawing. For that purpose, corpus line and base line have to be identified. An example for script lines can be seen in
Figure 10.
One approach to compute corpus- and base line is to use the relative occurrence
of the input data as it was described in skew correction and compute (or in the concrete case approximate) the first derivative [
29]
The minimum and maximum of the derivative are a good indication for the script line positions in general. Of course, the accuracy depends a lot on the proper alignment of the text [
29]. A visualization of this approach can be seen in
Figure 10.
Figure 10.
Visualization for script line identification utilizing the occurrence histogram along the y-axis. Note that in this example the corpus- and the base line may not be optimal. The reason for that are variations in size and position of the text, probably caused by the lack of reference lines in the writing process.
Figure 10.
Visualization for script line identification utilizing the occurrence histogram along the y-axis. Note that in this example the corpus- and the base line may not be optimal. The reason for that are variations in size and position of the text, probably caused by the lack of reference lines in the writing process.
Another way to compute the corpus- and the base line would be by putting regression lines through the upper and lower turning points of the data itself [
32], or a combination of both approaches [
40].
4.2.5. Slant Correction Based on Window
Another approach for slant correction was proposed by Guerfali and Plamondon [
40] and is based on an offline slant correction method introduced by Bozinovic and Srihari [
50].
First, the script line identification (See
Section 4.2.4) is performed in order to identify three possible regions: the upper zone between top line and corpus line (ascenders), the lower zone between base line and bottom line (descenders) and the central region of the middle zone, which is between corpus line and base line. Within those three regions, observation windows are extracted. Each one of those windows is then divided into an upper part and a lower part [
40]. For every existing part, the center of mass of all data points within the part is computed. The local slant of a window is then defined as the slope angle of the line connection the mass centers of the upper and lower part of the window. The error angle
of the word is then set to the average of the local slants.
6. Future Work
Although soft virtual keyboards are well-established in the B2C market, e.g., iPad and tablet computers running on Android, handwriting offers many benefits in contrast to a keyboard, particularly if it comes to using mobile devices in B2B applications. The tremendous success of tablet computers suggests bringing the underlying concepts (User Interface design, social media, mobile devices) into the B2B market and enriching the proven UI concepts with a stylus-based handwriting recognition.
Briefly we can summarize the benefits of handwriting as follows. Firstly, it feels more natural as we have learned writing with pen and paper very early at school. Secondly, using a pen instead of a keyboard has the advantage that one can immediately sketch and draw. This process supports communication and enhances creativity in a natural way. Thirdly, the ongoing trend of “bringing your own device” (ByoD [
52]) in many businesses allows for enriching the positive user experience on the own device in terms of a handwriting application used in the professional (B2B) field: Employees are familiar with handling their individual device and could use a stylus-based handwriting application where suitable for the specific task in mind. Moreover, companies amongst the various sectors start introducing tablet computers in their daily working process [
53]. As the daily use of tablets is a precondition for deploying handwriting applications, it is important to overcome the following obstacles:
Tablet computers have originally been developed for private use only. It is thus important to ensure appropriate policies for the security of sensitive data in the B2B domain.
IT departments have to ensure appropriate access policies as they have to know who is allowed to access which kind of data pools in the enterprise. This raises challenges in the field of identity management, as employees access the relevant data pools from various locations with different devices.
Configuration and software deployment usually need to be handled using a central authority. This includes establishing inventories and automatic software updates and security measures.
In some cases establishing an own tablet infrastructure has proven successful (also see [
53]).
Once these obstacles have been mastered, the companies can benefit from introducing mobile devices like tablets the daily working process. As an example, we briefly mention two application scenarios in which using a stylus might offer benefits. In both cases, requirements from the core business suggest the usage of handwriting recognition. The first example stems from the field of medicine. Previous research has shown that medical doctors are accustomed to using a pen in their daily work and have a high willingness to use an electronic stylus as input device [
7], whereas elderly people or people who are not computer literate prefer their finger as input medium [
5]. Further, as medical doctors usually wear gloves, many of the UI concepts (multi-touch, capacitive displays,
etc.) do not work in this field. The medical domain is thus a perfect test-bed for introducing handwriting recognition.
The second example is from the insurance industry. With the consequences of the financial crisis starting in 2008, the requirements for insurance companies and financial brokers have become much stricter. According to the MIFID directive (Markets in Financial Instruments Directive [
54]), an insurance company (or the broker selling insurance products) is required to document the process of consultancy in detail, including the consideration of the risk awareness of the customer. The fact that the sales and consulting staff of insurance companies typically act at the customer site suggests equipping these departments with mobile devices. In this way, any kind of relevant information regarding new products (e.g., Produpedia, also see [
55]) and the documentation of the sales and consulting process can be deployed on a tablet and any kind of (handwritten) documentation can be immediately processed after entering the relevant information at the site of the customer. In this respect, a working solution for handwriting recognition is a valuable contribution to deal with these directives. In particular, if approval by signature is part of the process, a handwriting solution is desirable since a stylus is anyway in place in this case. Popular examples of using tablets (alongside with social media and the idea to bring the successful concepts from the B2C market to the B2B market) include Deutsche Bank and SAP [
53].
7. Conclusions
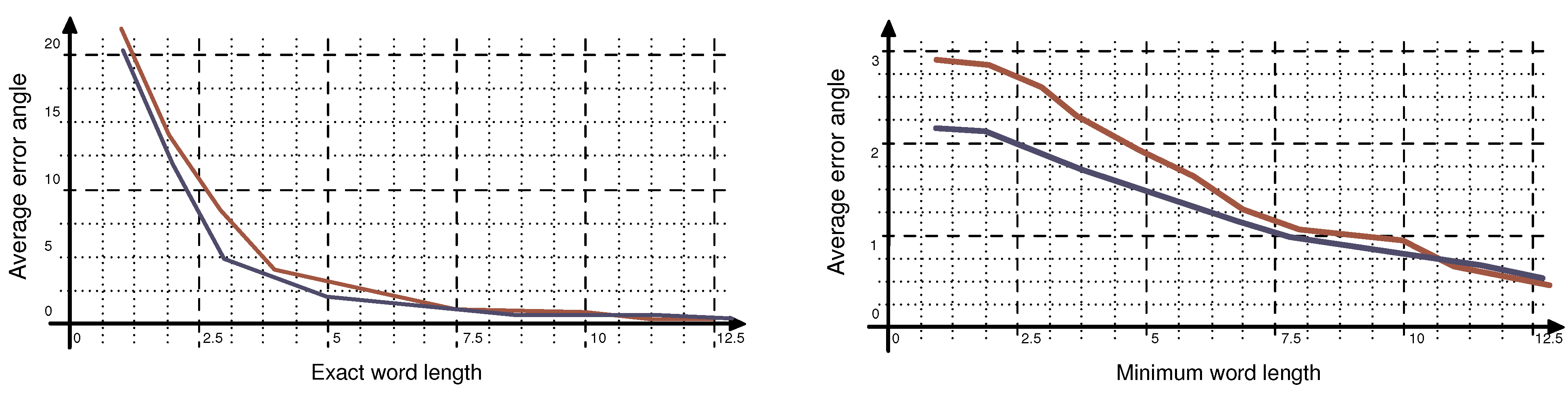
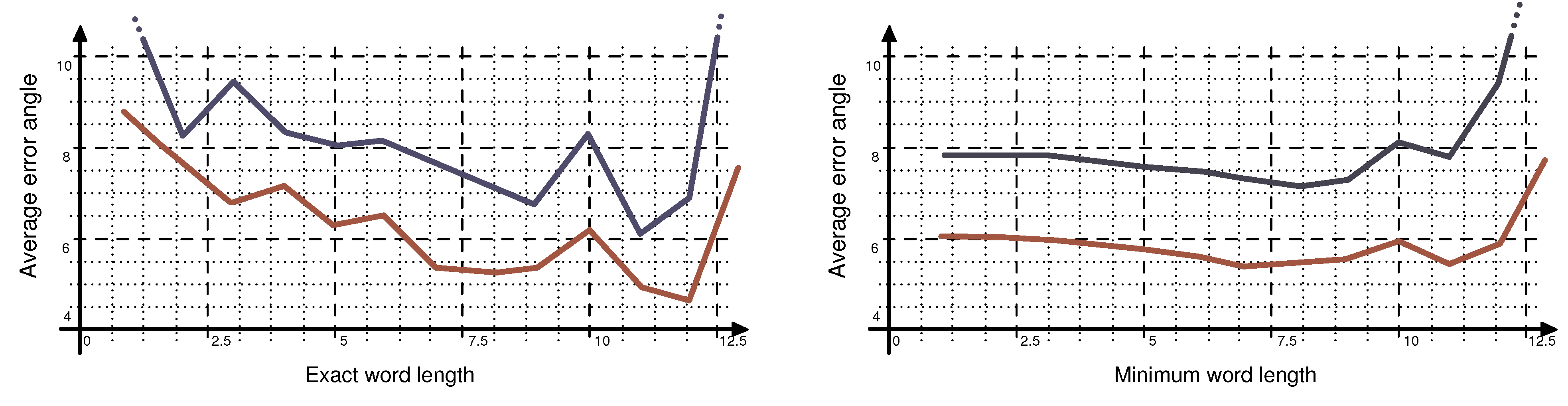
In this paper we demonstrated the strengths and weaknesses of using entropy for skew- and slant-correction. We showed that for our test set, the entropy based skew correction does not outperform older methods like skew correction based on the least squares method. In fact it is the other way around. We suspect that the noise in the drawing distorts the real minima of the entropy distribution. In many cases where the global minimum was the wrong choice, there was a local minimum close to the real error angle. Even though both approaches yield satisfying result for words longer than five letters, we suggest further investigation into the entropy-based skew correction method, with noise reduction in mind.
On the other hand, we demonstrated that entropy is in fact useful when performing slant correction, as it does outperform the window-based approach. We have come to the conclusion that the window-based method is too much dependent on a number of factors. Its performance is influenced a lot by the outcome of zone detection and by the writing style of the writer. It is also influenced a lot by window selection. We think that the entropy-based slant correction is more stable in that regard.
We also pointed out that all four preprocessing techniques have problems when it comes to short words or letters. In real world applications, it might be useful to identify or approximate the word length before applying any of the above described techniques.




















{kind=link}
{kind=link}
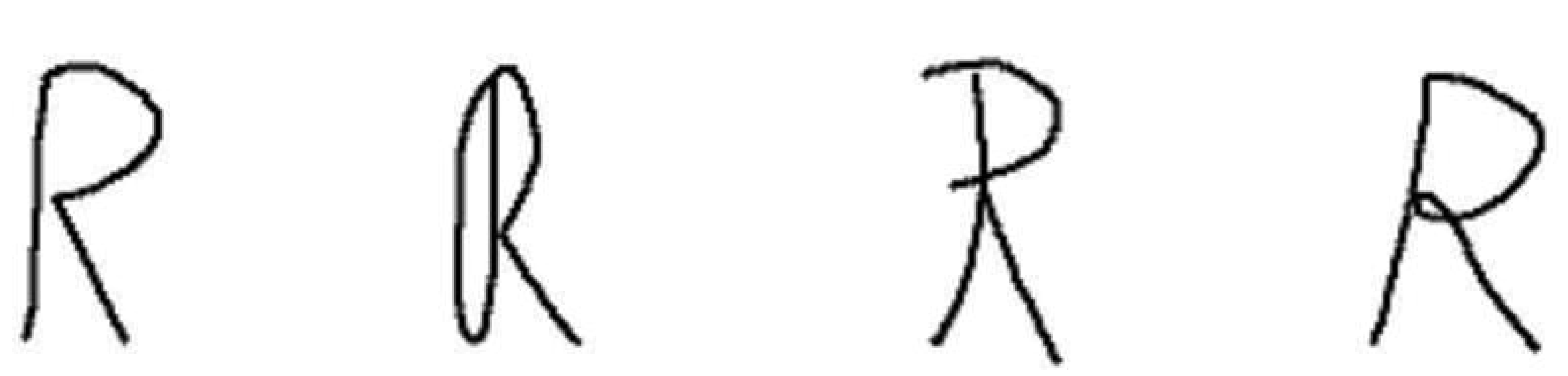{kind=link}
{kind=link}
{kind=link}
{kind=link}
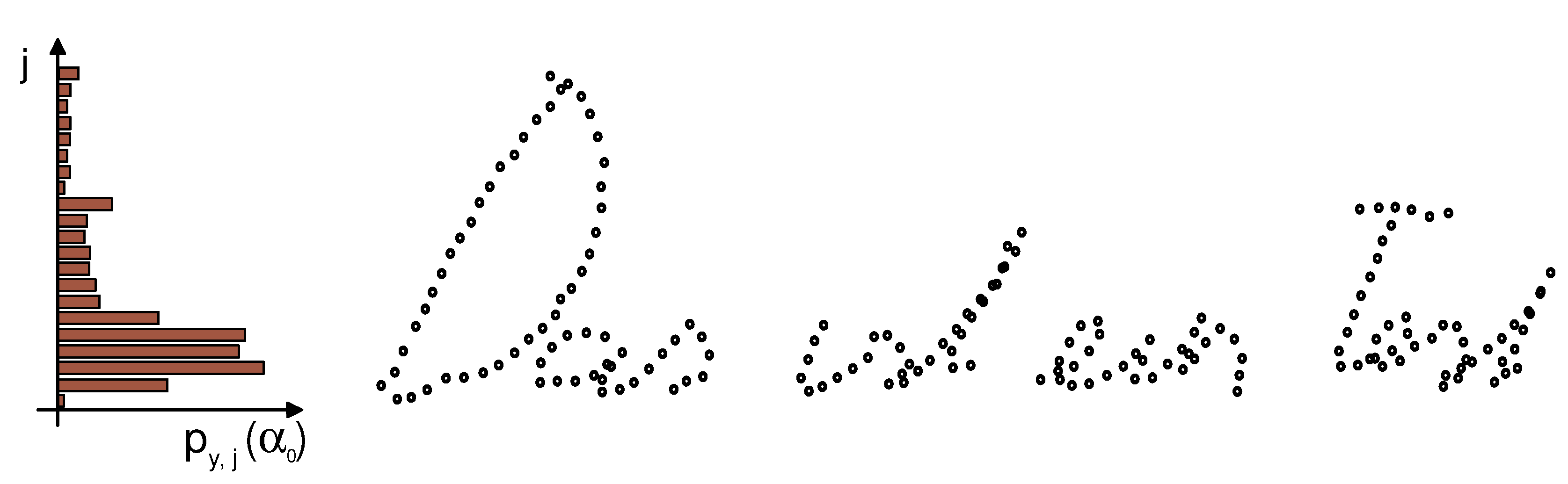{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
