Learning Entropy: Multiscale Measure for Incremental Learning

Abstract
:1. Introduction
2. Funding Principles
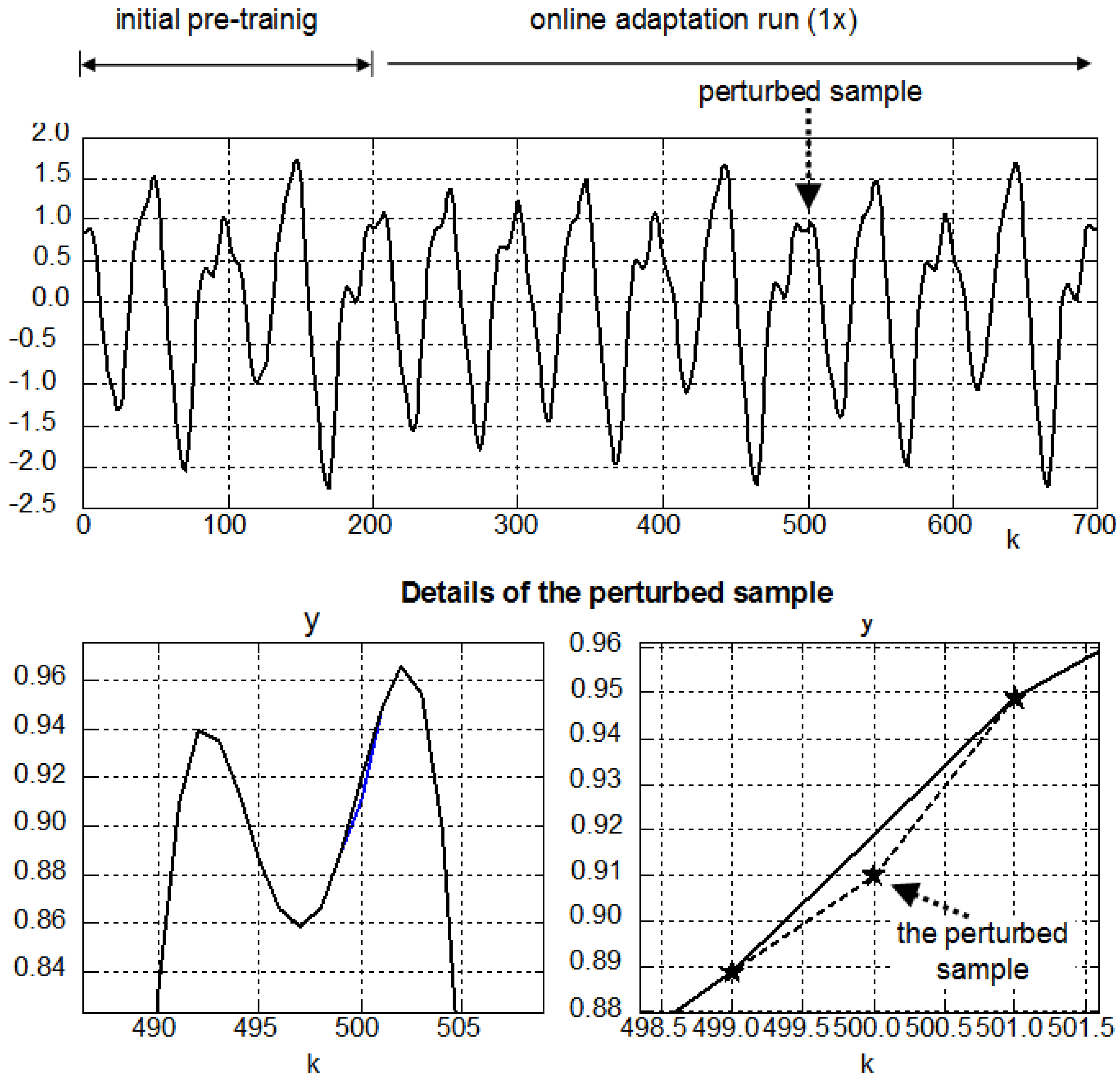
2.1. Predictive Models and Adaptive Learning







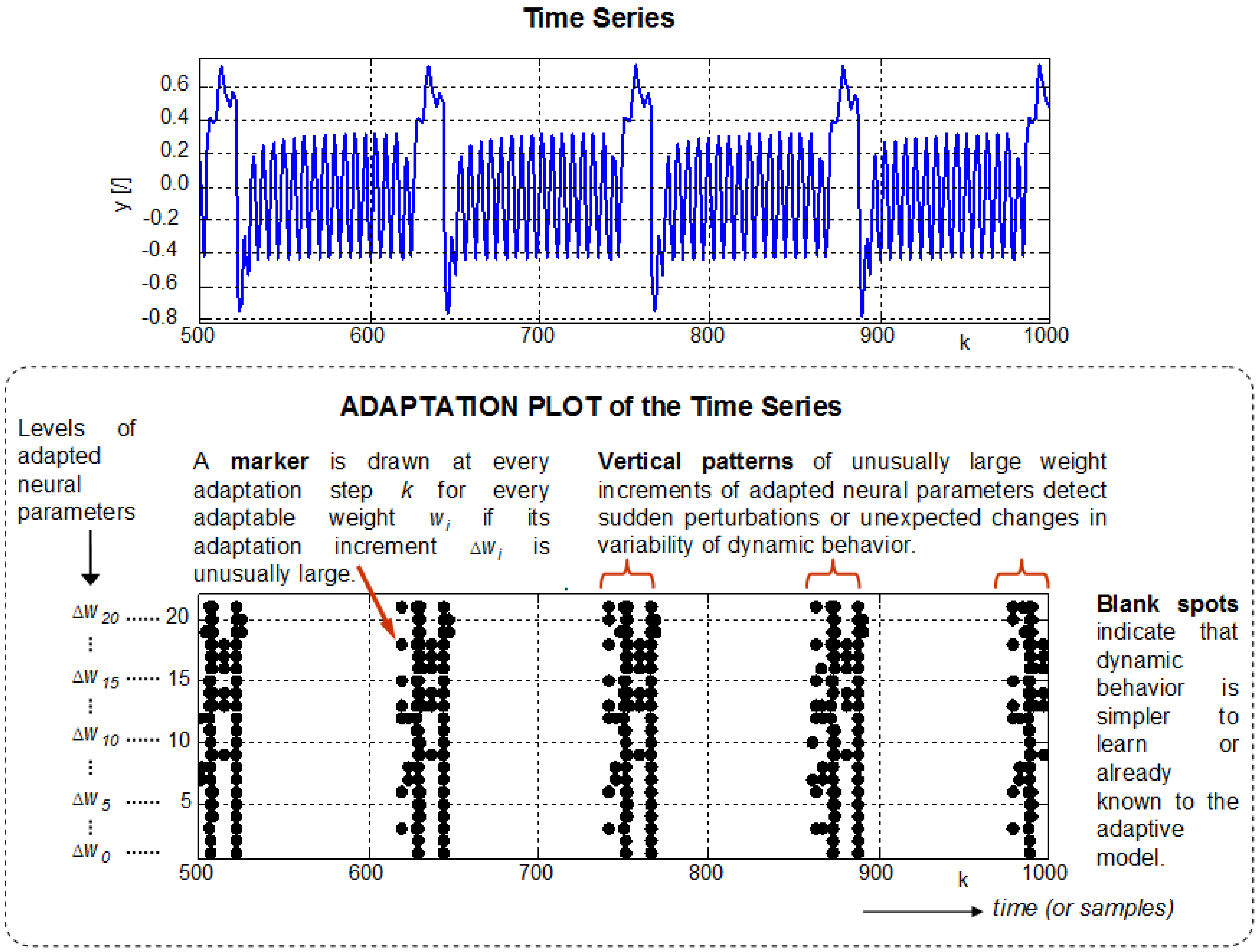
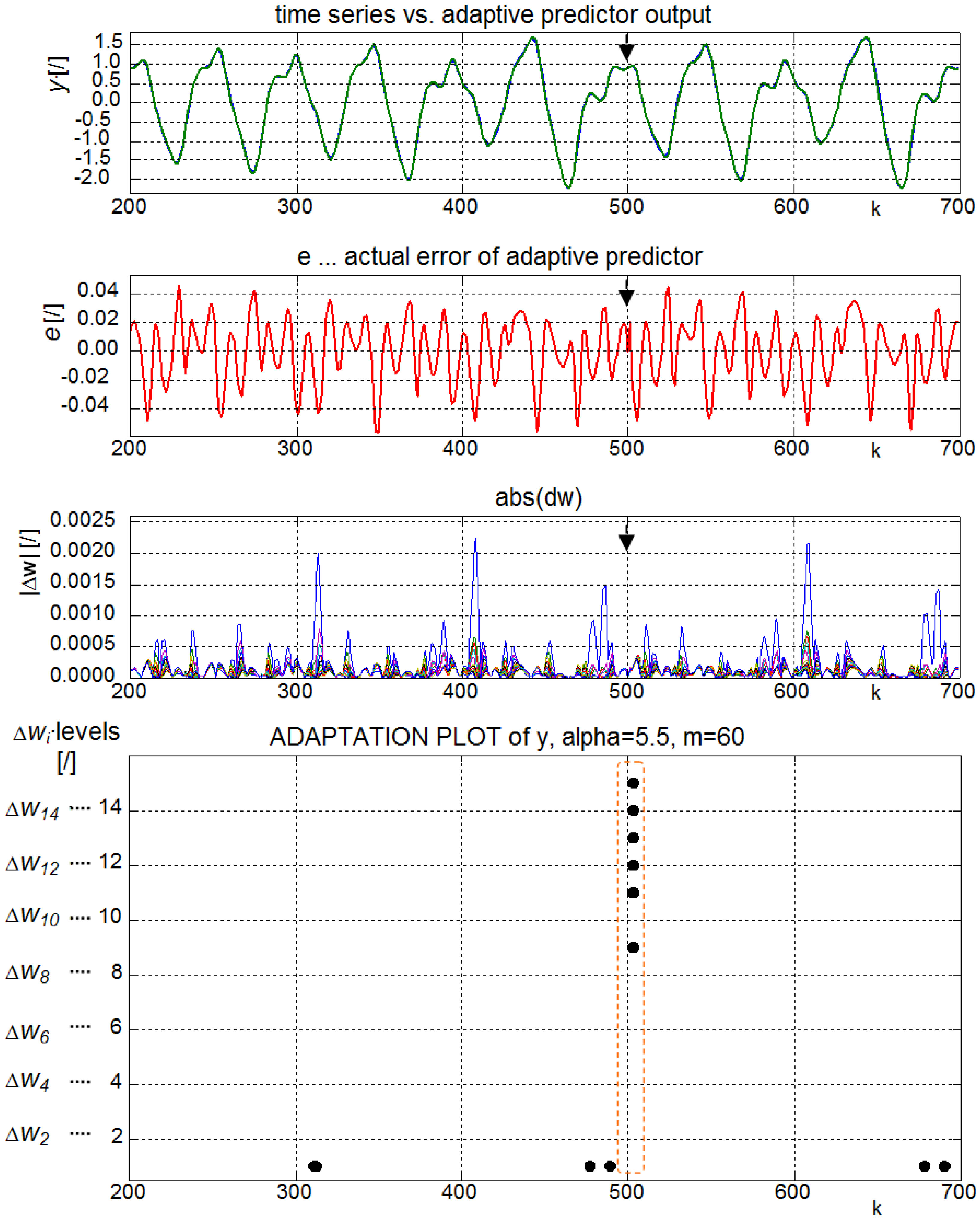
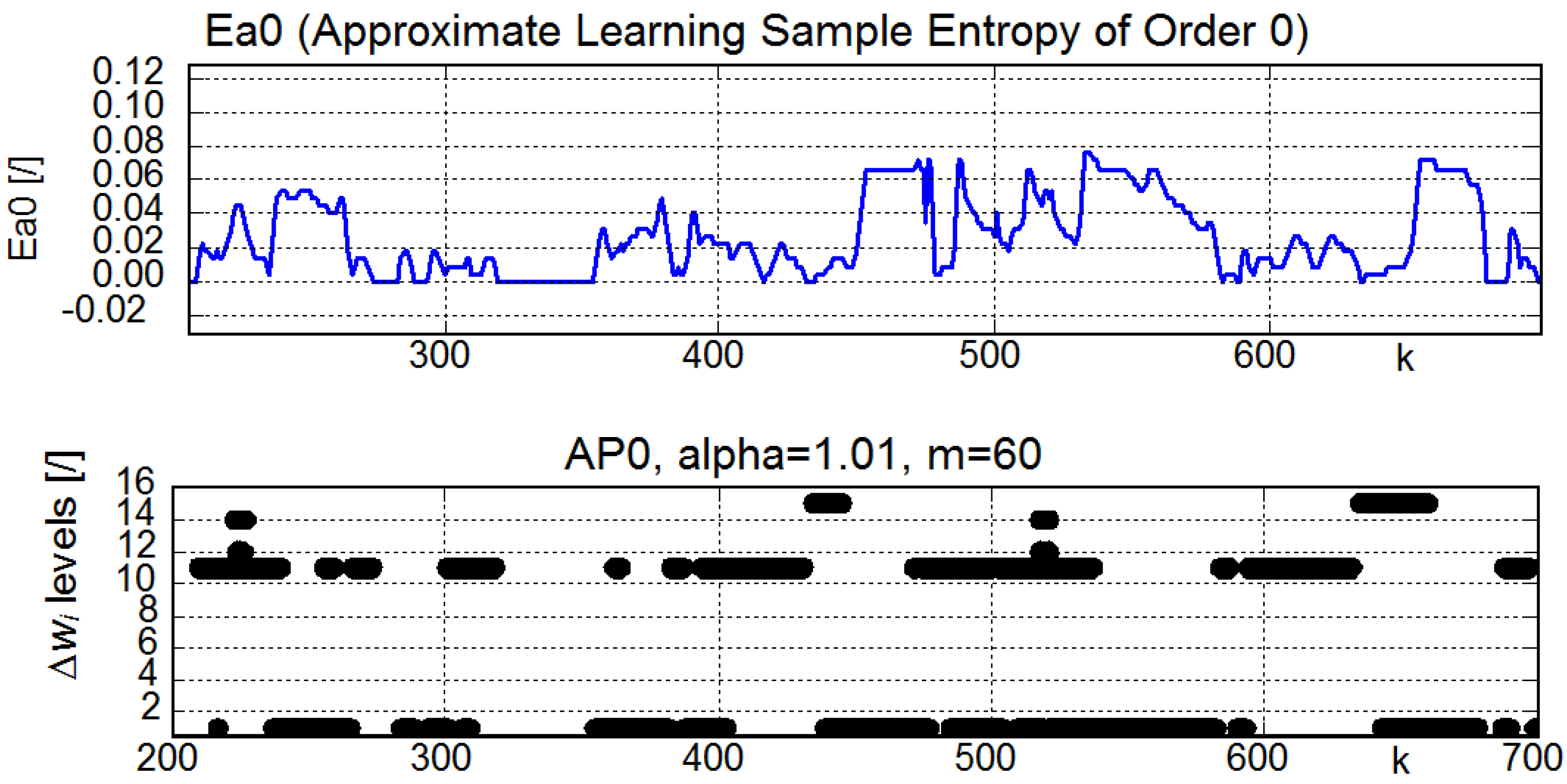
2.2. Adaptation Plot (AP)



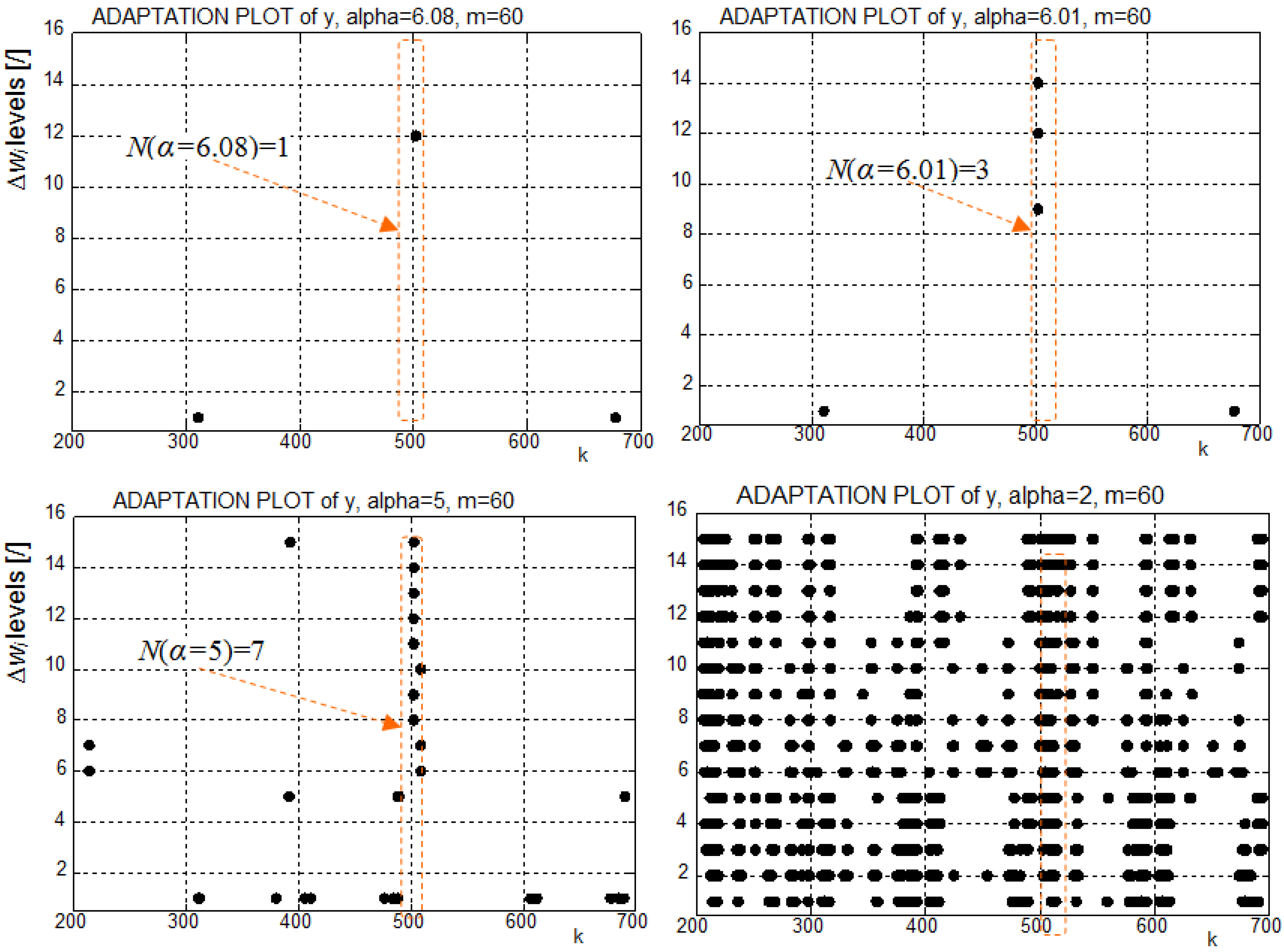
- The larger value of α, the larger magnitudes of weight increments (i.e., |Δw|) are considered to be unusual.
- The larger α, the more unusual data samples in signal are detected and visualized in AP.
- The larger α, the less sensitive AP is to data that do not correspond to the contemporary dynamics learned by a model.
- The larger α, the lower density of markers in AP.
3. Learning Entropy (LE)
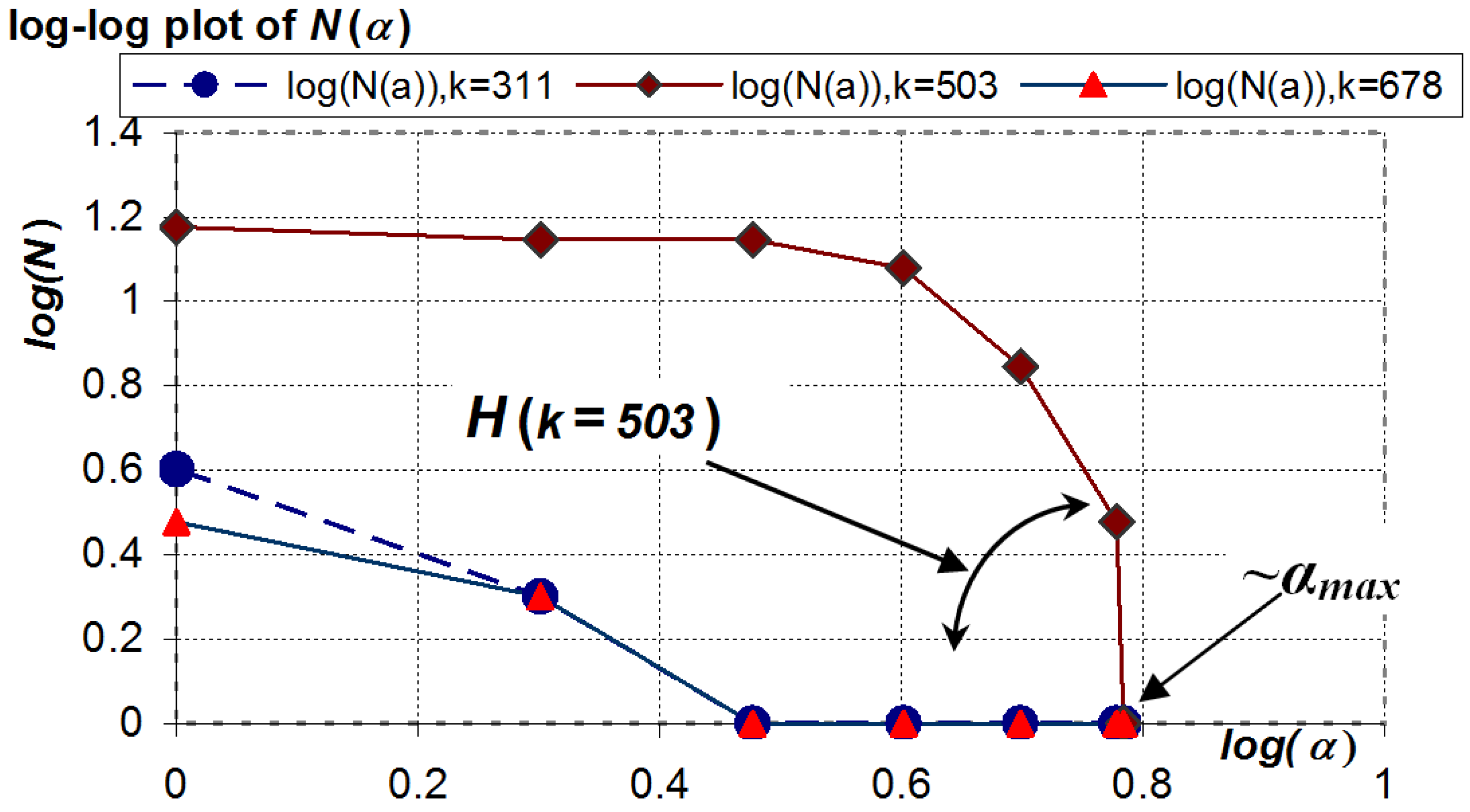
3.1. Individual Sample Learning Entropy (ISLE)













| α | 6.08 | 6 | 5 | 4 | 3 | 2 | 1 |
|---|---|---|---|---|---|---|---|
| N(α), k = 311 | 1 | 1 | 1 | 1 | 1 | 2 | 4 |
| N(α), k = 503 | 1 | 3 | 7 | 12 | 14 | 14 | 15 |
| N(α), k = 678 | 1 | 1 | 1 | 1 | 1 | 2 | 3 |


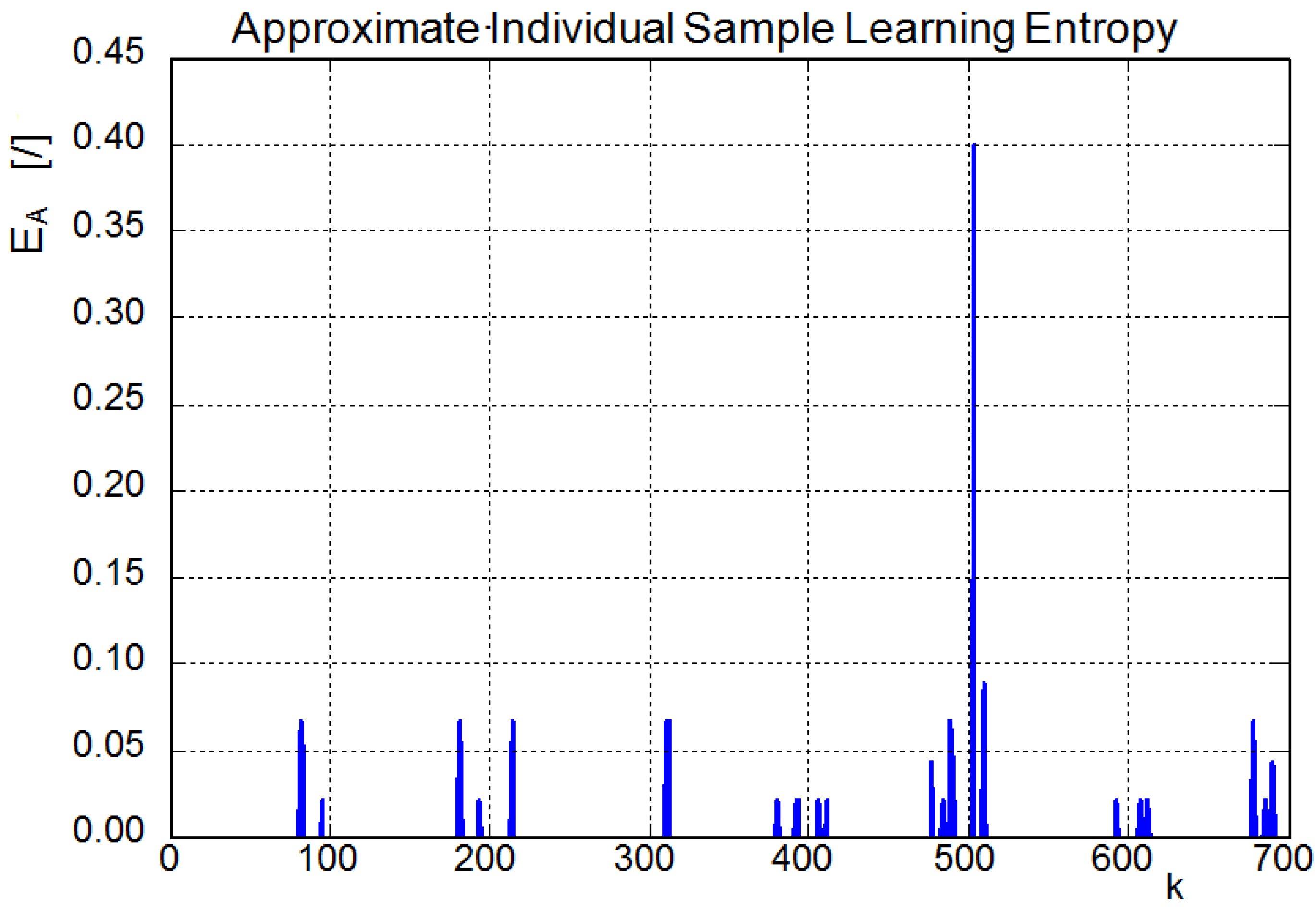
3.2. Approximate Individual Sample Learning Entropy (AISLE)

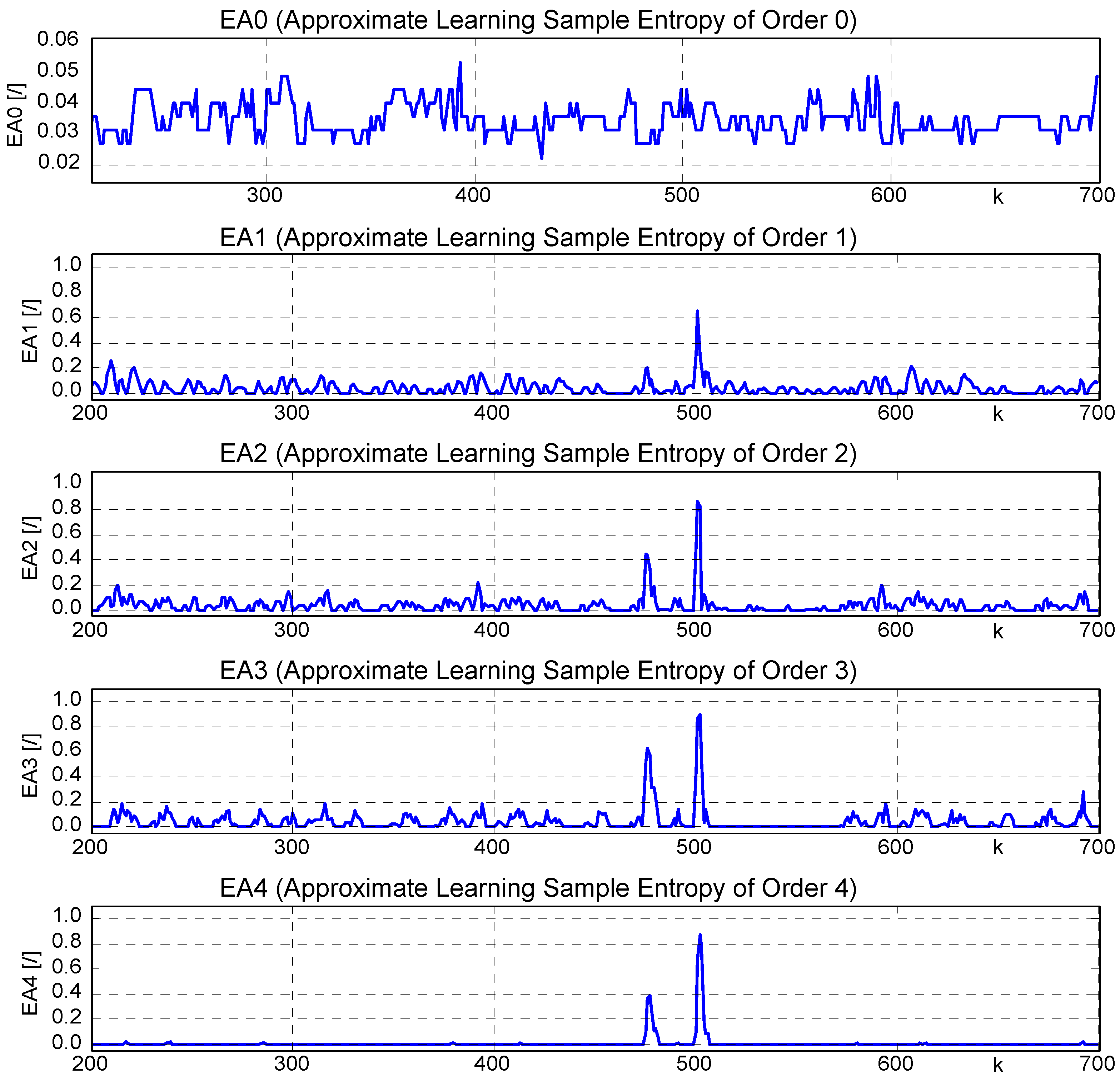
3.3. Orders of Learning Entropy (OLEs)
- Order learning energy of weight wi corresponds to exceeding the floating average of its m recent magnitudes
![Entropy 15 04159 i020]() ,
, - 1st Order learning energy of wi corresponds to exceeding the floating average of its m recent first derivative magnitudes
![Entropy 15 04159 i021]() (this is the case of rule (8) ),
(this is the case of rule (8) ), - 2nd Order learning energy of wi corresponds to exceeding the floating average of its m recent second order derivative magnitudes
![Entropy 15 04159 i022]() , see (22), and similarly,
, see (22), and similarly, - 3rd Order learning energy of wi relates to ,
- 4th Order learning energy of wi to
- etc.






| OLE | Notation | Detection Rule for AP Markers |
|---|---|---|
| 0 |  | |
| 1 |  | |
| 2 |  | |
| 3 |  | |
| 4 |  |



4. Experimental Analysis
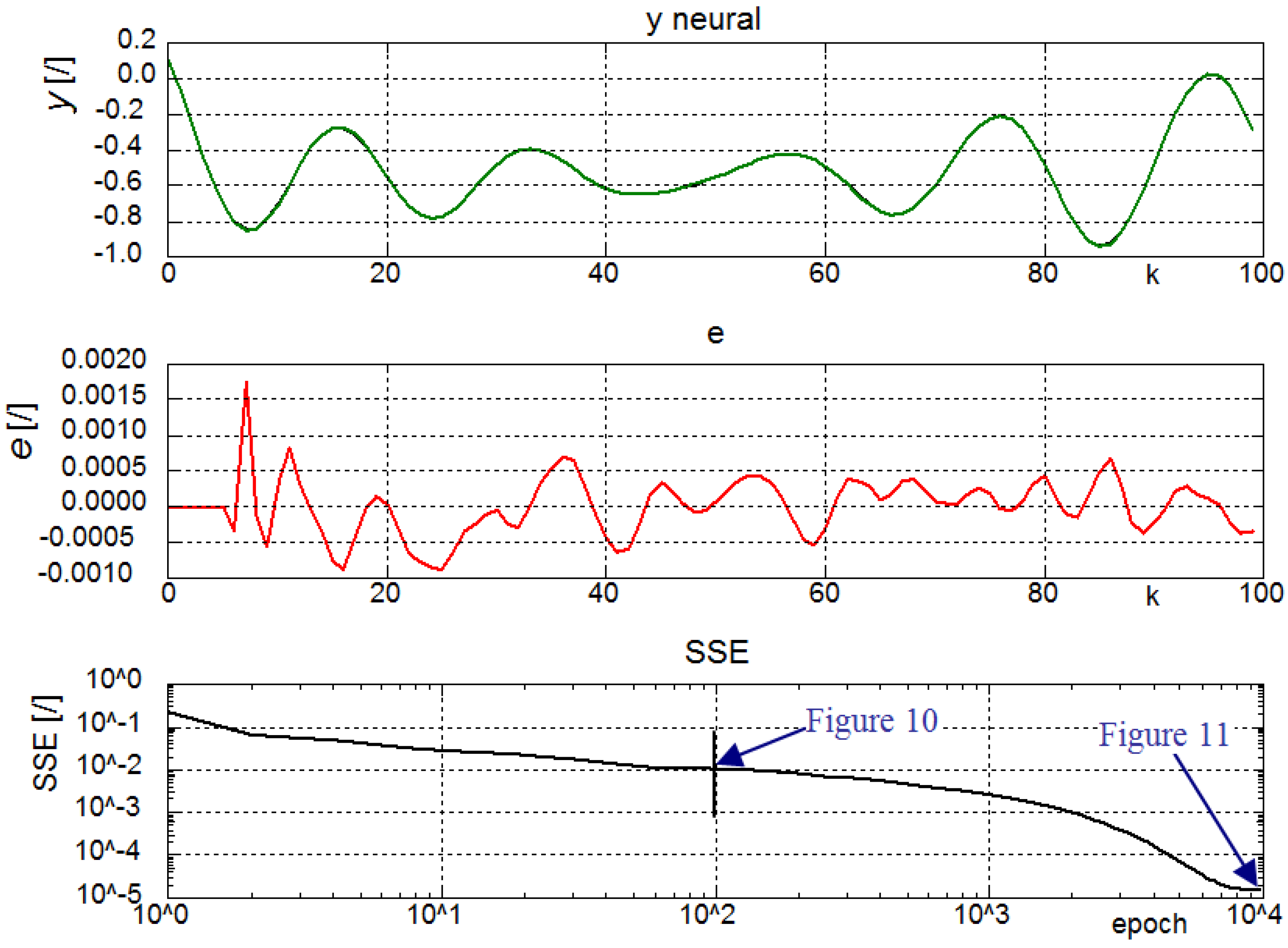
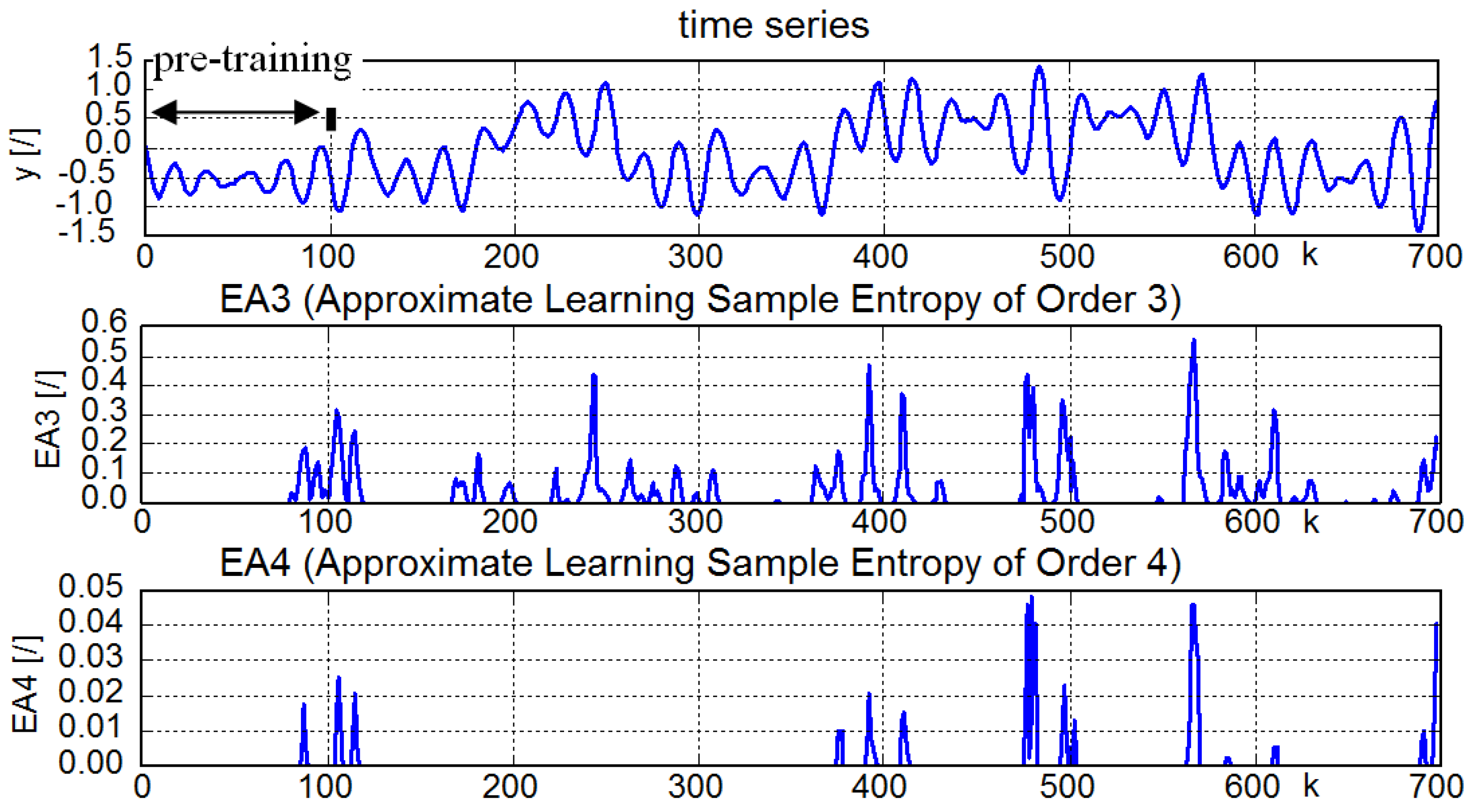
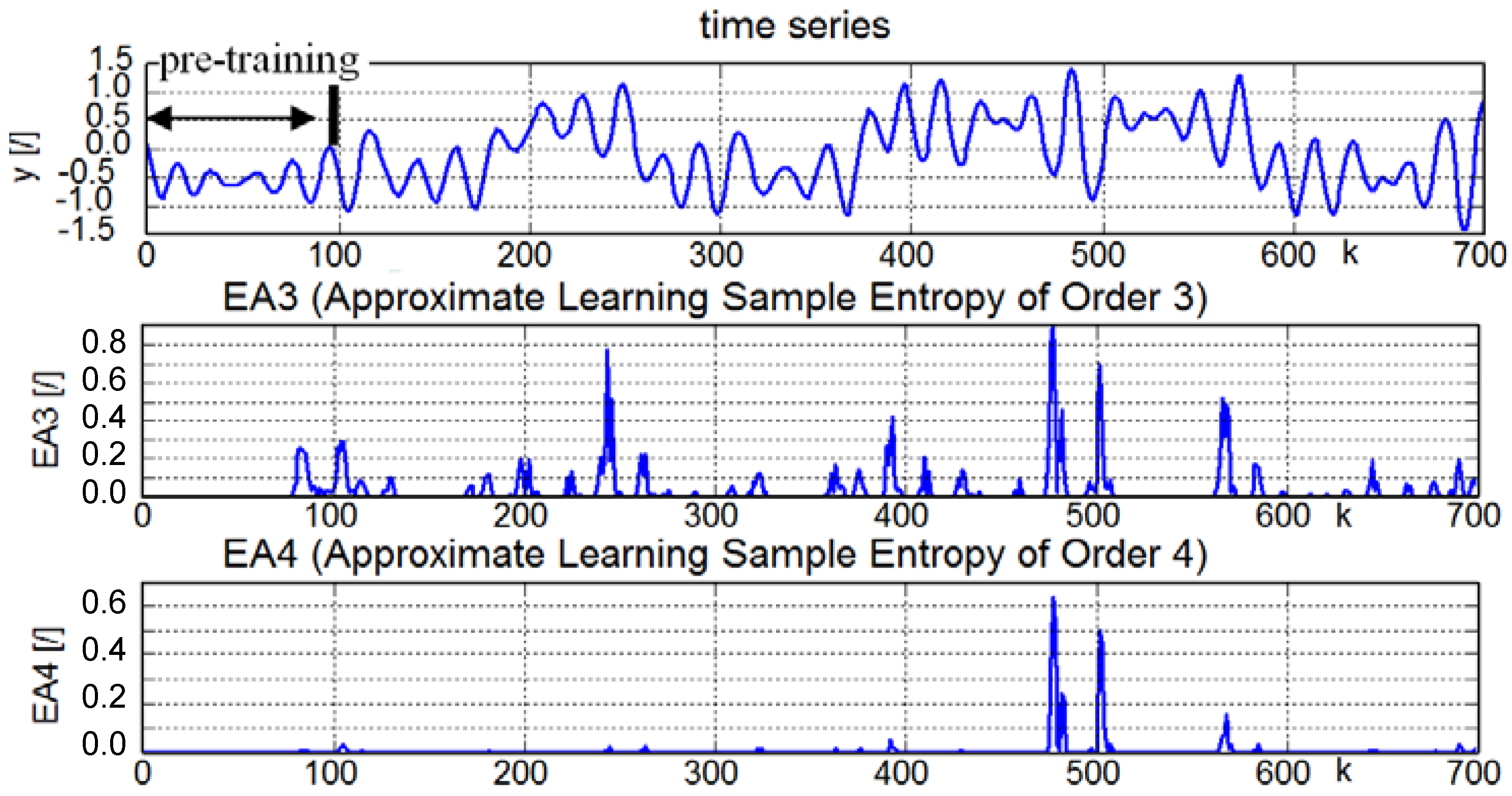
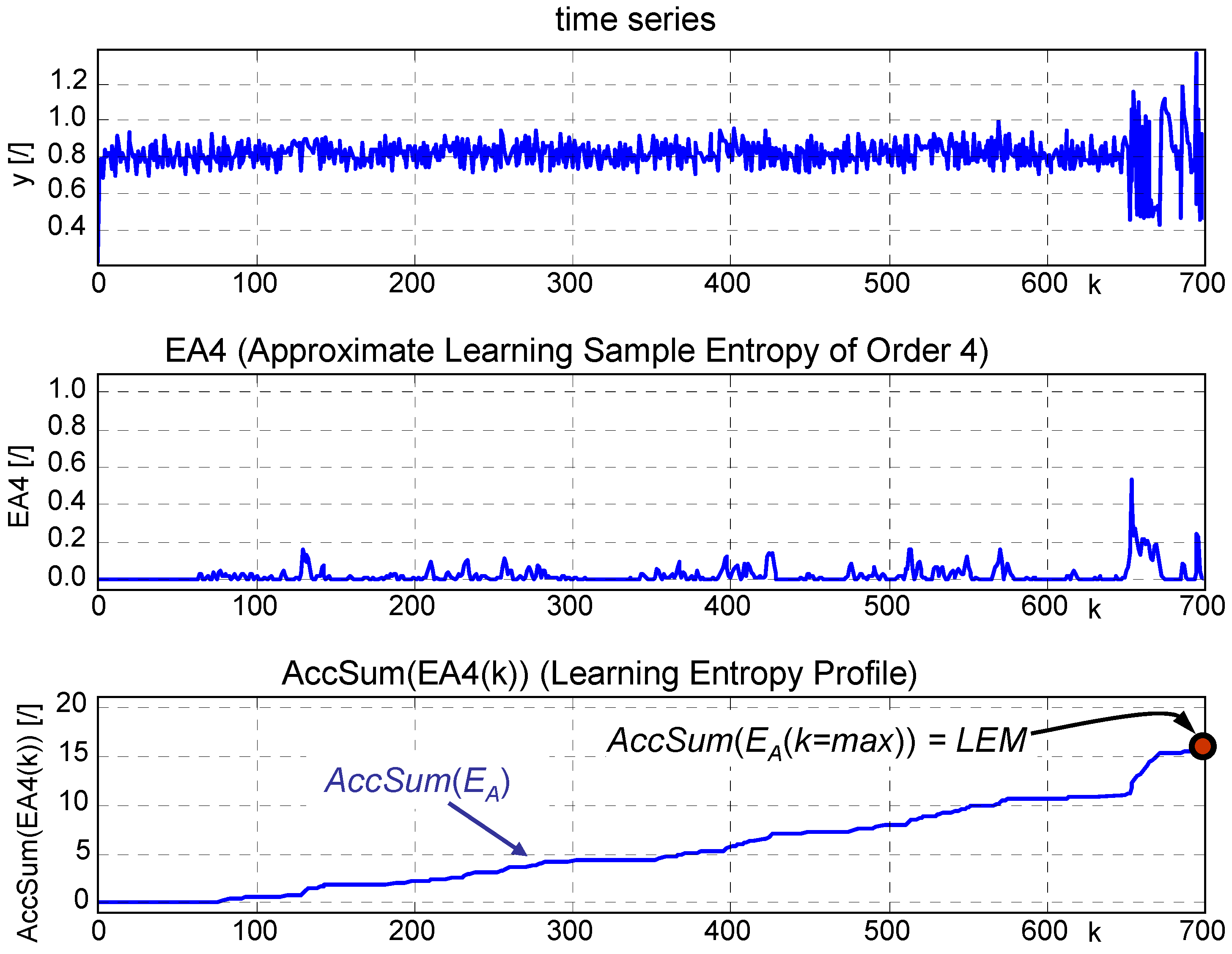
4.1. A Hyper-Chaotic Time Series




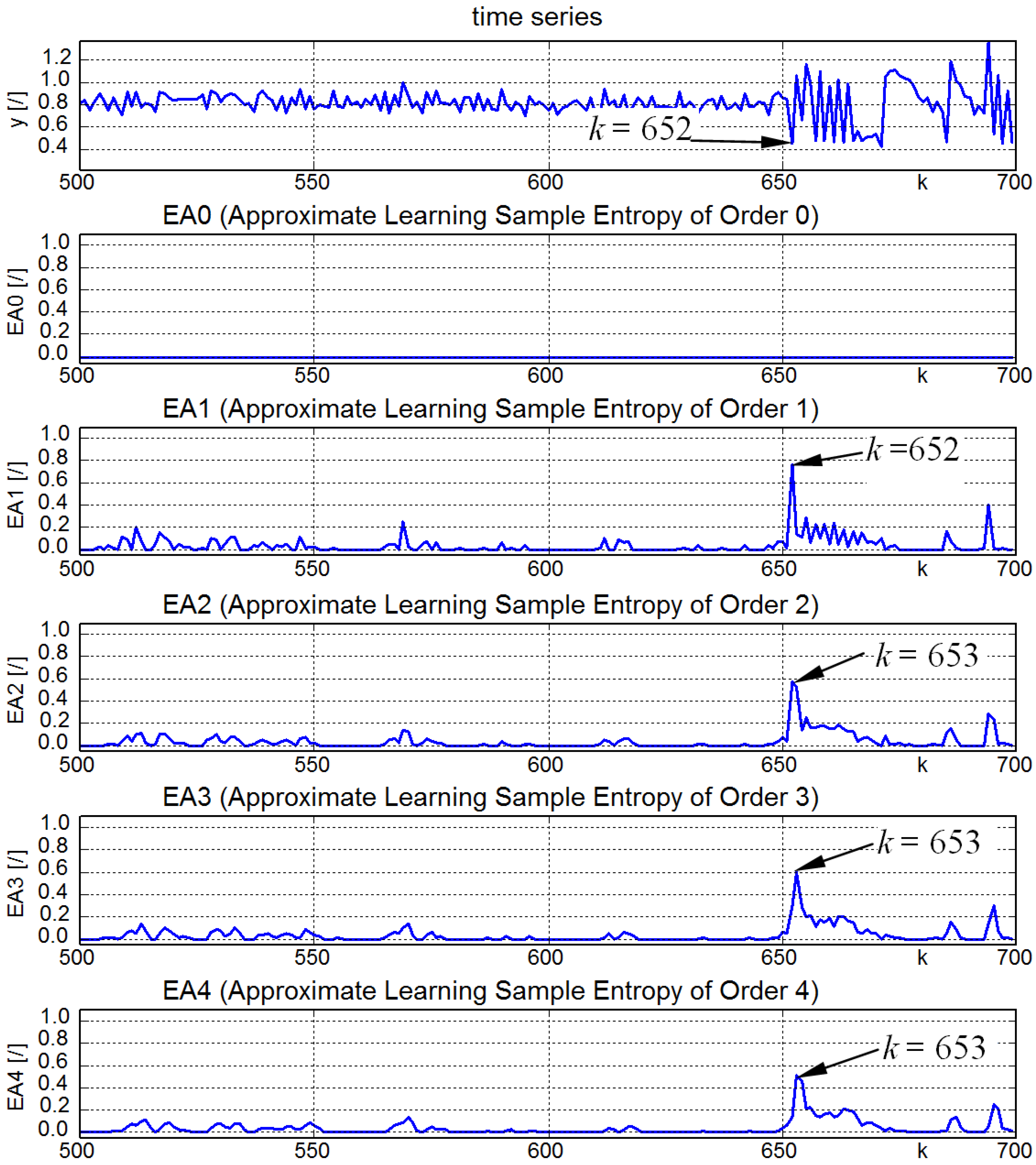
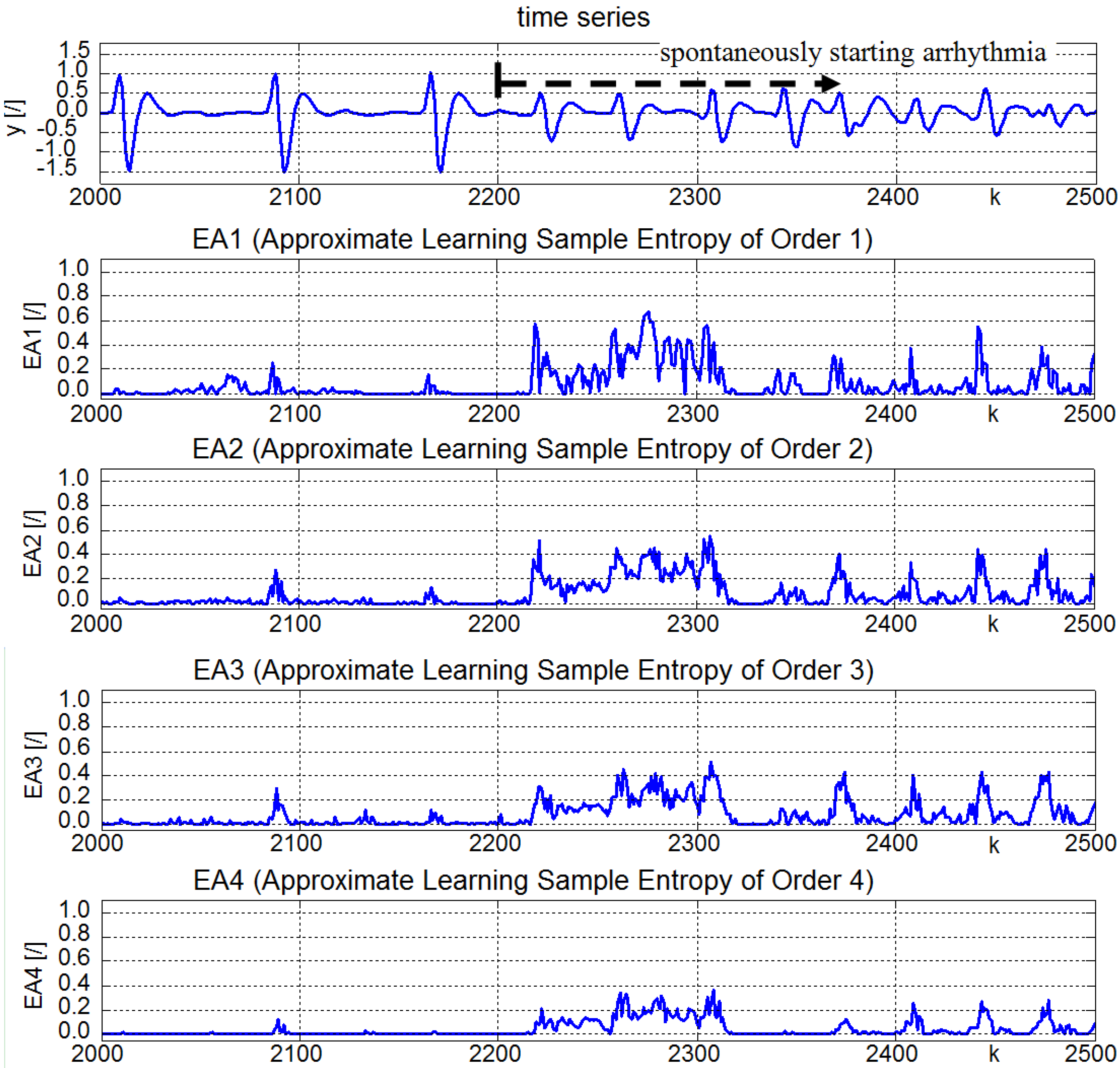
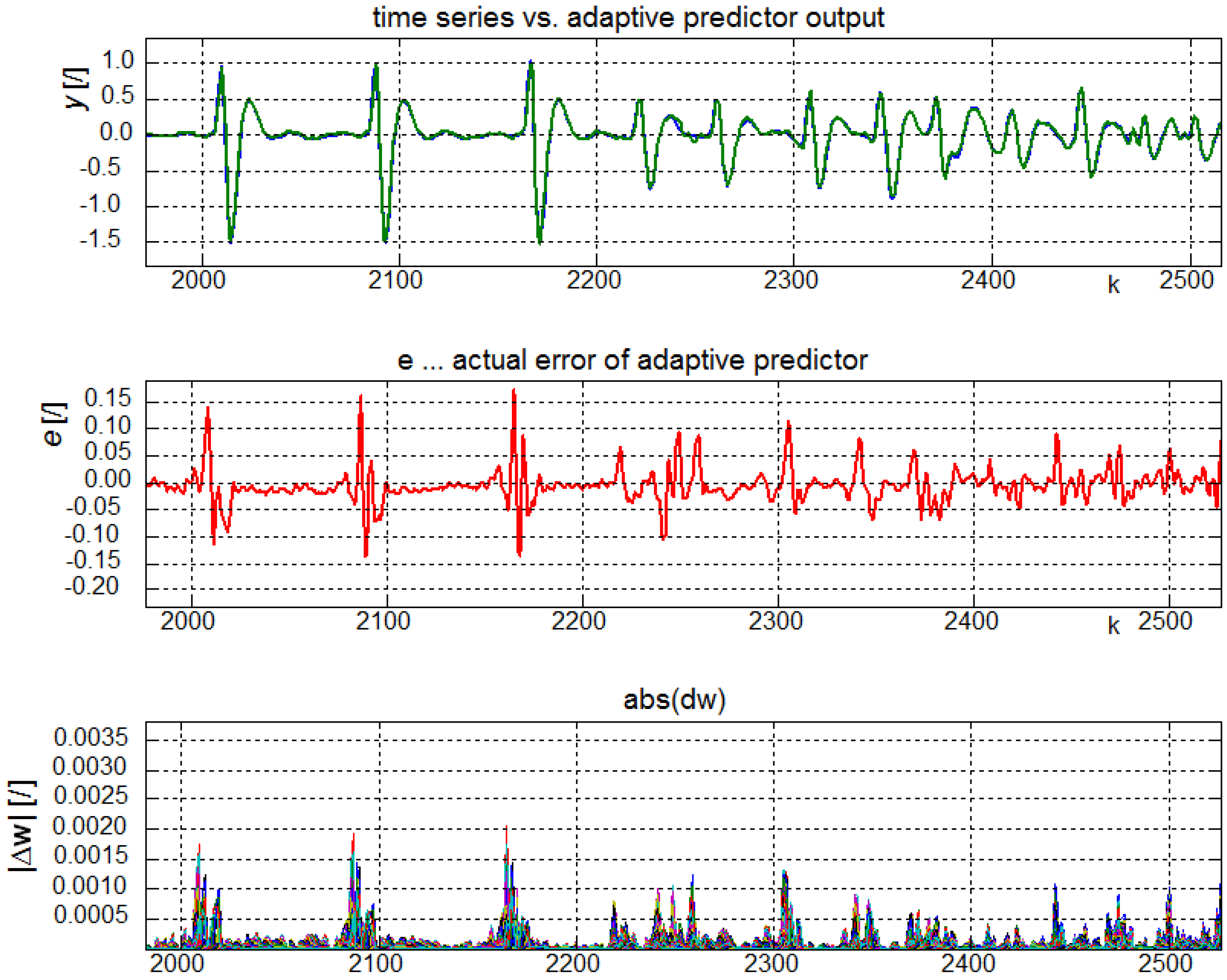
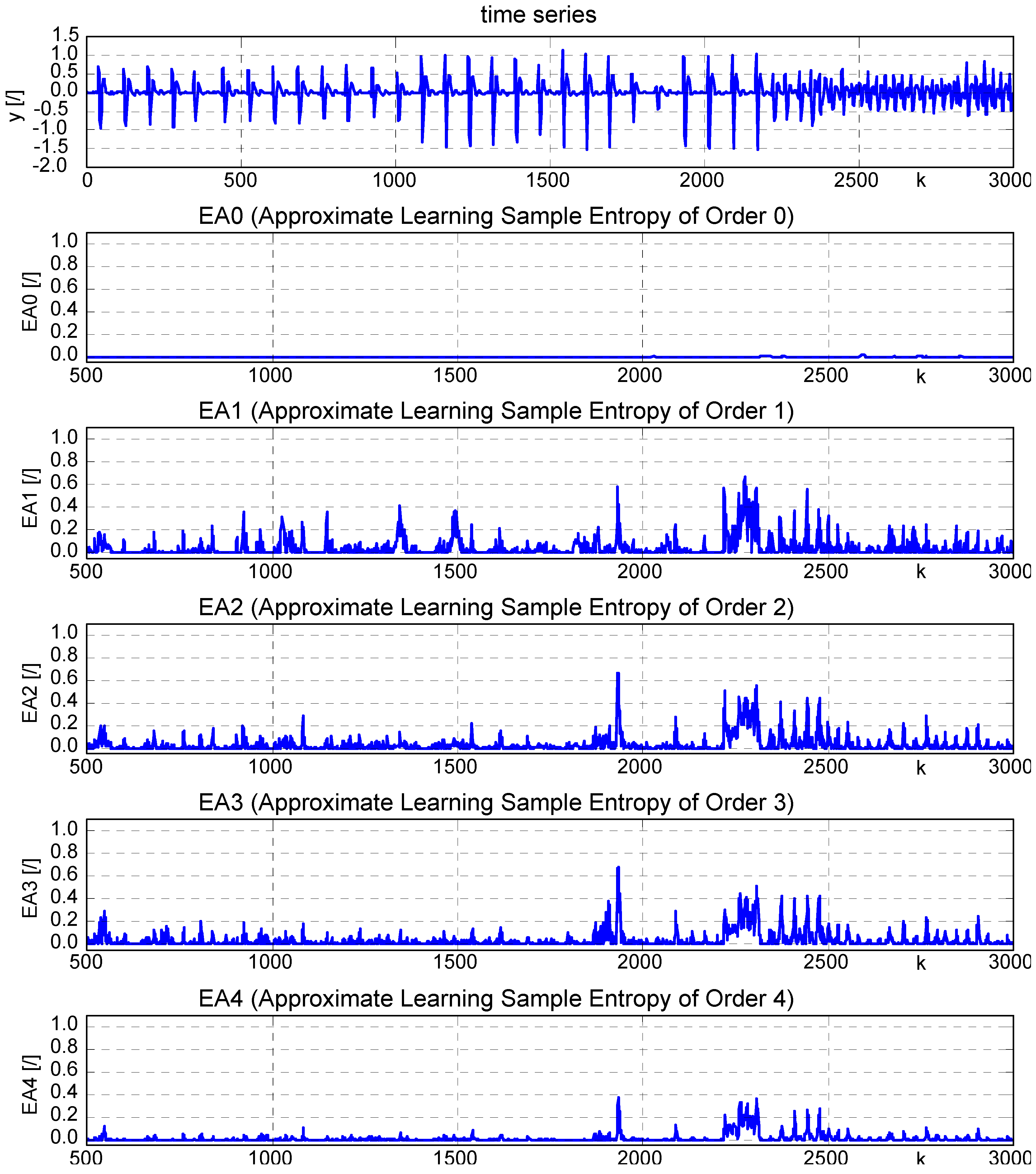
4.2. Real Time Series




5. Discussion

6. Conclusions
Acknowledgments
Conflicts of Interest
Nomenclature
| LE | Learning Entropy |
| ALE | Approximate Learning Entropy |
| ISLE | Individual Sample Learning Entropy |
| AISLE | Approximate Individual Sample Learning Entropy |
| OLE | Order of Learning Entropy |
| LEM | Learning Entropy of a Model |
| ApEn | Approximate Entropy (by Pincus) |
| SampEn | Sample Entropy (by Pincus) |
| AP | Adaptation Plot |
| GD | Gradient Descent |
Appendix

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
References
- Bukovsky, I. Modeling of complex dynamic systems by nonconventional artificial neural architectures and adaptive approach to evaluation of chaotic time series. Ph.D. Thesis, Czech Technical University, Prague, Czech Republic, 2007. [Google Scholar]
- Bukovsky, I.; Bila, J. Adaptive evaluation of complex dynamic systems using low-dimensional neural architectures. In Advances in Cognitive Informatics and Cognitive Computing, Series: Studies in Computational Intelligence; Zhang, D., Wang, Y., Kinsner, W., Eds.; Springer-Verlag: Berlin & Heidelberg, Germany, 2010; Volume 323, pp. 33–57. [Google Scholar]
- Baker, W.; Farrell, J. An introduction to connectionist learning control systems. In Handbook of Intelligent Control: Neural, Fuzzy, and Adaptive Approaches; White, D.A., Sofge, D.A., Eds.; Van Nostrand and Reinhold: New York, USA, 1993; pp. 36–63. [Google Scholar]
- Polycarpou, M.M.; Trunov, A.B. Learning approach to nonlinear fault diagnosis: Detectability analysis. IEEE Trans. Autom. Control 2000, 45, 806–812. [Google Scholar] [CrossRef]
- Markou, M.; Singh, S. Novelty detection: A review—Part 1: Statistical approaches. Signal Process. 2003, 83, 2481–2497. [Google Scholar] [CrossRef]
- Markou, M.; Singh, S. Novelty detection: A review—Part 2: Neural network based approaches. Signal Process. 2003, 83, 2499–2521. [Google Scholar] [CrossRef]
- Pincus, S.M. Approximate entropy as a measure of system complexity. Proc. Natl. Acad. Sci. USA 1991, 88, 2297–2301. [Google Scholar] [CrossRef] [PubMed]
- Richman, J.S.; Moorman, J.R. Physiological time-series analysis using approximate entropy and sample entropy. Am. J. Physiol. Heart Circul. Physiol. 2000, 278, 2039–2049. [Google Scholar]
- Kinsner, W. Towards cognitive machines: Multi-scale measures and analysis. Intern. J. Cognit. Inf. Natural Intell. 2007, 1, 28–38. [Google Scholar] [CrossRef]
- Kinsner, W. A unified approach to fractal dimensions. Intern. J. Cognit. Inf. Natural Intell. 2007, 1, 26–46. [Google Scholar] [CrossRef]
- Kinsner, W. Is entropy suitable to characterize data and signals for cognitive informatics? Intern. J. Cognit. Inf. Natural Intell. 2007, 1, 34–57. [Google Scholar] [CrossRef]
- Zurek, S.; Guzik, P.; Pawlak, S.; Kosmider, M.; Piskorski, J. On the relation between correlation dimension, approximate entropy and sample entropy parameters, and a fast algorithm for their calculation. Physica A 2012, 391, 6601–6610. [Google Scholar] [CrossRef]
- Schroeder, M., R. Fractals, Chaos, Power Laws: Minutes from an Infinite Paradise; Freeman: New York, NY, USA, 1991. [Google Scholar]
- Costa, M.; Goldberger, A.L.; Peng, C.K. Multi-scale entropy analysis of complex physiologic time series. Phys. Rev. Lett. 2002, 89, 68102. [Google Scholar] [CrossRef]
- Costa, M.; Goldberger, A.L.; Peng, C.K. Multi-scale entropy analysis of biological signals. Phys. Rev. E Stat. Nonlin Soft Matter Phys. 2005, 71, 021906. [Google Scholar] [CrossRef] [PubMed]
- Wu, S.-D.; Wu, Ch.-W.; Lin, S.-G.; Wang, Ch.-Ch.; Lee, K.-Y. Time series analysis using composite multi-scale entropy. Entropy 2013, 15, 1069–1084. [Google Scholar] [CrossRef]
- Gonçalves, H.; Henriques-Coelho, T.; Rocha, A.P.; Lourenço, A.P.; Leite-Moreira, A.; Bernardes, J. Comparison of different methods of heart rate entropy analysis during acute anoxia superimposed on a chronic rat model of pulmonary hypertension. Med. Eng. Phys. 2013, 35, 559–568. [Google Scholar] [CrossRef] [PubMed]
- Wu, S.-D.; Wu, Ch.-W.; Wu, T.-Y.; Wang, Ch.-Ch. Multi-scale analysis based ball bearing defect diagnostics using mahalanobis distance and support vector machine. Entropy 2013, 15, 416–433. [Google Scholar] [CrossRef]
- Faes, L.; Nollo, G.; Porta, A. Compensated transfer entropy as a tool for reliably estimating information transfer in physiological time series. Entropy 2013, 15, 198–219. [Google Scholar] [CrossRef]
- Yin, L.; Zhou, L. Function based fault detection for uncertain multivariate nonlinear non-gaussian stochastic systems using entropy optimization principle. Entropy 2013, 15, 32–52. [Google Scholar] [CrossRef]
- Vorburger, P.; Bernstein, A. Entropy-based concept shift detection. In Proceedings of the 2006 IEEE International Conference on Data Mining (ACDM 2006), Hong Kong, China, 18–22 December 2006; pp. 1113–1118.
- Willsky, A. A survey of design methods for failure detection in dynamic systems. Automatica 1976, 12, 601–611. [Google Scholar] [CrossRef]
- Gertler, J. Survey of model-based failure detection and isolation in complex plants. IEEE Contr. Syst. Mag. 1988, 8, 3–11. [Google Scholar] [CrossRef]
- Isermann, R. Process fault detection based on modeling and estimation methods: A survey. Automatica 1984, 20, 387–404. [Google Scholar] [CrossRef]
- Frank, P.M. Fault diagnosis in dynamic systems using analytical and knowledge-based redundancy—A survey and some new results. Automatica 1990, 26, 459–474. [Google Scholar] [CrossRef]
- Widmer, G.; Kubat, M. Learning in the presence of concept drift and hidden contexts. Machine Learn. 1996, 23, 69–101. [Google Scholar] [CrossRef]
- Polycarpou, M.M.; Helmicki, A.J. Automated fault detection and accommodation: A learning systems approach. IEEE Trans. Syst. Man Cybern. 1995, 25, 1447–1458. [Google Scholar] [CrossRef]
- Demetriou, M.A.; Polycarpou, M.M. Incipient fault diagnosis of dynamical systems using online approximators. IEEE Trans. Autom. Control 1998, 43, 1612–1617. [Google Scholar] [CrossRef]
- Trunov, A.B.; Polycarpou, M.M. Automated fault diagnosis in nonlinear multivariable systems using a learning methodology. IEEE Trans. Neural Networks 2000, 11, 91–101. [Google Scholar] [CrossRef] [PubMed]
- Alippi, C.; Roveri, M. Just-in-time adaptive Classifiers—Part I: Detecting nonstationary changes. IEEE Trans. Neural Networks 2008, 19, 1145–1153. [Google Scholar] [CrossRef]
- Alippi, C.; Roveri, M. Just-in-time adaptive Classifiers—Part II: Designing the Classifier. IEEE Trans. Neural Networks 2008, 19, 2053–2064. [Google Scholar] [CrossRef] [PubMed]
- Alippi, C.; Boracchi, G.; Roveri, M. Just-In-time Classifiers for recurrent concepts. IEEE Trans. Neural Networks Learn. Syst. 2013, 24, 620–634. [Google Scholar] [CrossRef] [PubMed]
- Alippi, C.; Ntalampiras, S.; Roveri, M. A Cognitive fault diagnosis system for distributed sensor networks. IEEE Trans. Neural Networks Learn. Syst. 2013, 24, 1213–1226. [Google Scholar] [CrossRef] [PubMed]
- Grossberg, S. Adaptive resonance theory: How a brain learns to consciously attend, learn, and recognize a changing world. Neural Networks 2013, 37, 1–47. [Google Scholar] [CrossRef] [PubMed]
- Gupta, M.M; Liang, J.; Homma, N. Static and Dynamic Neural Networks: From Fundamentals to Advanced Theory; John Wiley & Sons: New Jersey, USA, 2003. [Google Scholar]
- Bukovsky, I.; Bila., J.; Gupta, M.M.; Hou, Z.-G.; Homma, N. Foundation and Classification of Nonconventional Neural Units and Paradigm of Nonsynaptic Neural Interaction. In Discoveries and Breakthroughs in Cognitive Informatics and Natural Intelligence; Wang, Y., Ed.; IGI Publishing: Hershey, PA, USA, 2009. [Google Scholar]
- Bukovsky, I.; Homma, N.; Smetana, L.; Rodriguez, R.; Mironovova, M.; Vrana, S. Quadratic neural unit is a good compromise between linear models and neural networks for industrial applications. In Proceedings of the 9th IEEE International Conference on Cognitive Informatics (ICCI 2010), Beijing, China, 7–9 July 2010.
- Bukovsky, I.; Anderle, F.; Smetana, L. Quadratic neural unit for adaptive prediction of transitions among local attractors of Lorenz systems. In Proceedings of the 2008 IEEE International Conference on Automation and Logistics, Qingdao, China, 1–3 September 2008.
- Bukovsky, I.; Bila, J. Adaptive evaluation of complex time series using nonconventional neural units. In Proceedings of the 7th IEEE International Conference on Cognitive Informatics (ICCI 2008), Stanford, CA, USA, 14–16 August 2008.
- Bukovsky, I.; Kinsner, W.; Bila, J. Multi-scale analysis approach for novelty detection in adaptation plot. In Proceedings of the 3rd Sensor Signal Processing for Defence (SSPD 2012), London, UK, 25–27 September 2012.
- Mandic, D.P. A generalised normalised gradient descent algorithm. IEEE Signal Process. Lett. 2004, 11, 115–118. [Google Scholar] [CrossRef]
- Choi, Y.-S.; Shin, H.-Ch.; Song, W.-J. Robust regularization for normalized lms algorithms. IEEE Trans. Circuits Syst. Express Briefs 2006, 53, 627–631. [Google Scholar] [CrossRef]
- Williams, R.J.; Zipser, D. A learning algorithm for continually running fully recurrent neural networks. Neural Comput. 1989, 1, 270–280. [Google Scholar] [CrossRef]
- Mackey, M.C.; Glass, L. Oscillation and chaos in physiological control systems. Science 1977, 197, 287–289. [Google Scholar] [CrossRef] [PubMed]
- Cannas, B.; Cincotti, S. Hyperchaotic behaviour of two bi-directionally coupled chua’s circuits. Inter. J. Circuit Theory Appl. 2002, 30, 625–637. [Google Scholar] [CrossRef]
- R-R diagram, record #: 222. PhysioBank: MIT-BIH Arrhythmia Database. Available online: http://www.physionet.org/ physiobank/database/mitdb (accessed on 5 April 2001).
- Yoshizawa-Homma Lab. http://www.yoshizawa.ecei.tohoku.ac.jp/~en (accessed on 5 July 2013).
- Van Rossum, G.; de Boer, J. Linking a stub generator (AIL) to a prototyping language (Python). In Proceedings of the Spring 1991 EurOpen Conference, Troms, Norway, 20–24 May 1991.
© 2013 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Bukovsky, I. Learning Entropy: Multiscale Measure for Incremental Learning. Entropy 2013, 15, 4159-4187. https://doi.org/10.3390/e15104159
Bukovsky I. Learning Entropy: Multiscale Measure for Incremental Learning. Entropy. 2013; 15(10):4159-4187. https://doi.org/10.3390/e15104159
Chicago/Turabian StyleBukovsky, Ivo. 2013. "Learning Entropy: Multiscale Measure for Incremental Learning" Entropy 15, no. 10: 4159-4187. https://doi.org/10.3390/e15104159
APA StyleBukovsky, I. (2013). Learning Entropy: Multiscale Measure for Incremental Learning. Entropy, 15(10), 4159-4187. https://doi.org/10.3390/e15104159