Development of Metrics and a Complexity Scale for the Topology of Assembly Supply Chains



Abstract
:1. Introduction
2. Related Works
3. Generating of Assembly Supply Chain Classes

- The initial nodes “i” in topological alternatives are allocated to possible tiers tl (l = 1,...,m), ordered from left to right, except the tier tm, in which a final assembler is situated. We assume to model ASCs only with one final assembler. In a case when a real assembly process consists of more than one final assembler (for example 3) then it is advisable, for the purpose of the complexity measuring, to split the assembly network into three independent networks.
- The minimal number of initial nodes “i” in the first tier tl equals 2.
- In case of non-modular assembly supply chain structure, the number of initial nodes “i” in the most upstream echelon is equal to the number of individual assembly parts or inputs (in = 1,..., r).



- R1: If the numerical combination “K” consists only of numeric characters (digits), assigned by symbol “n”, n ≤ 2, e.g. K = (2;1) or K = (2;2;1) then M(2;1) or M(2;2;1) = 1.
- R2: If the numerical combination “K” consists just of one digit “3” and other digits are < 3, e.g., K = (3;1) or (3;2;2), then M(3;1) or M(3;2;2) = 2.
- R3: If the numerical combination “K” consists just of one digit “4” and other digits are < 3, e.g., K = (4;2), then M(4;2) = 5.

{kind=link}
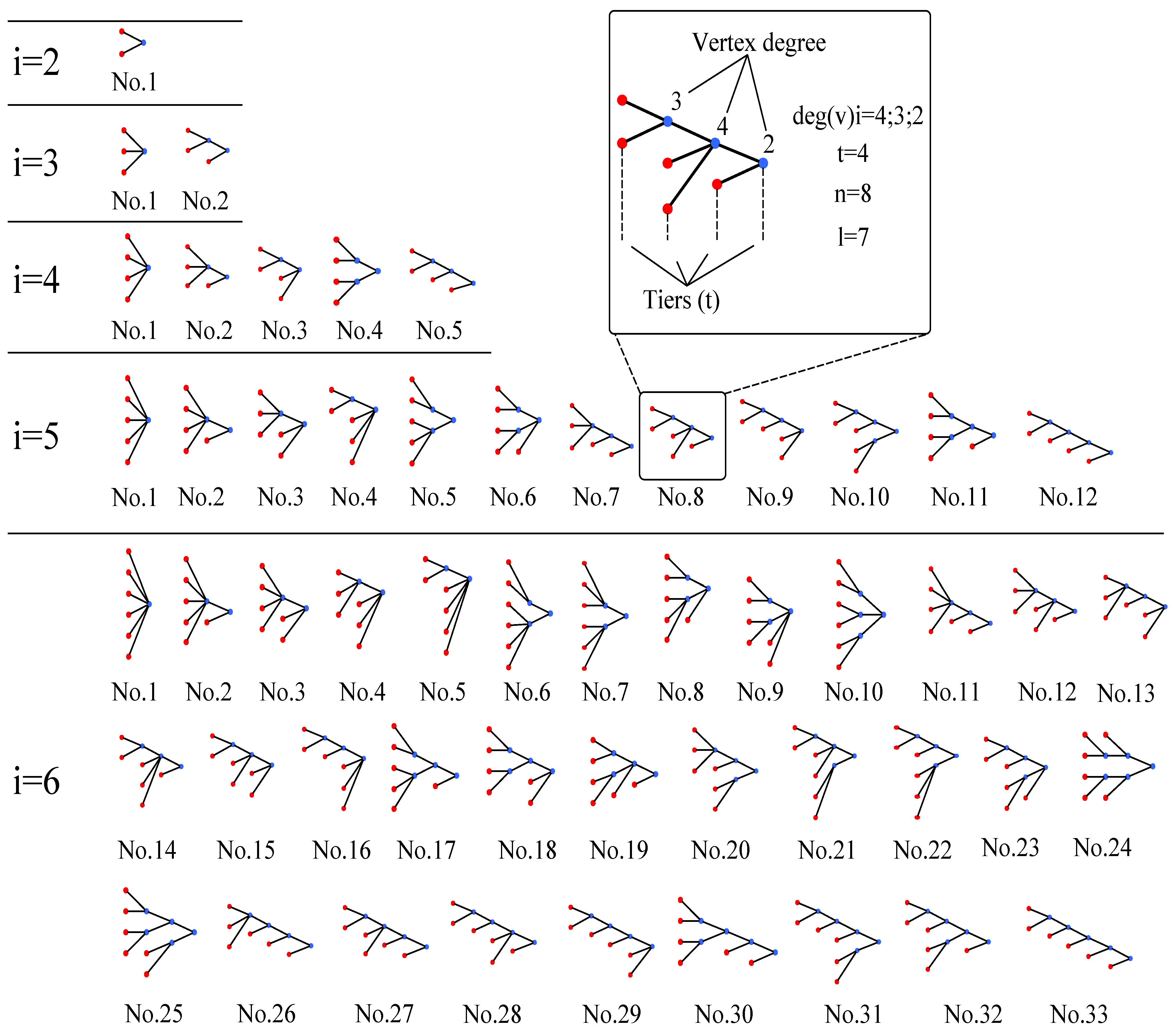{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| The highest digit of combination set under condition that other digits are < 3 | Number of alternatives for the given combinations |
|---|---|
| 2 | 1 |
| 3 | 2 |
| 4 | 5 |
| … | … |
| 8 | 261 |
| 9 | 766 |
| … | … |
| 17 | 7,305,788 |
| … | … |
4. Static Structural Complexity Metrics for ASC Structures
4.1. Some Terminology and Definitions
4.2. Specifications of ASC Networks Complexity Measure

4.3. Selection of ASC Networks with Non-repeated Sets of Vertex Degrees

5. The Concept of Quantitative Complexity Scale for ASC Networks


6. Conclusions
- (1)
- A new exact framework for creating topological classes of ASC networks is developed. This methodological framework enables one to determine all relevant topological graphs for any class of ASC structure. The usefulness of such a framework is especially notable in cases when it is necessary to apply relative complexity metrics to compare the complexity of the existing configuration against the simplest or/and the most complex one.
- (2)
- In order to parameterize properties of vertices of the ASC networks, an efficient method to identify total number of the graphs with non-repeated sets of vertex degrees structure is presented. The determination of the non-repeated sets of vertex degrees structure (for selected classes of ASC networks are described in Figure 5) shows that the total numbers of such graphs follows the Omar integer sequence [37], with the first number omitted.
- (3)
- The Vertex degree index was applied to a new area of configuration complexity.
- (4)
- The quantitative object-oriented model for defining degrees of configuration complexity of ASC networks was outlined.
Acknowledgments
Conflicts of Interest
References
- Hartmanis, J. New developments in structural complexity theory. Theor. Comput. Sci. 1990, 71, 79–93. [Google Scholar] [CrossRef]
- Manson, S.M. Simplifying complexity: a review of complexity theory. Geoforum 2001, 32, 405–414. [Google Scholar] [CrossRef]
- ElMaraghy, W.; ElMaraghy, H.; Tomiyama, T.; Monostori, L. Complexity in engineering design and manufacturing. CIRP Ann. Manuf. Technol. 2012, 61, 793–814. [Google Scholar] [CrossRef]
- Kolmogorov, A.N. Three Approaches to the Quantitative definition of information. Probl. Inf. Transm. 1965, 1, 1–7. [Google Scholar] [CrossRef]
- Chaitin, G. On the Length of programs for computing finite binary sequences. J. ACM. 1966, 13, 547–569. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Technol. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Bonchev, D.; Trinajstic, N. Information theory, distance matrix and molecular branching. J. Chem. Phys. 1977, 67, 4517–4533. [Google Scholar] [CrossRef]
- Bonchev, D.; Kamenska, V. Information theory in describing the electrionic structure of atoms. Croat. Chem. Acta 1978, 51, 19–27. [Google Scholar]
- Bochnev, D. Information indices for atoms and molecules. MATCH-Commun. Math. Co. 1979, 7, 65–113. [Google Scholar]
- Grassberger, P. Information and complexity measures in dynamical systems. In Information Dynamics; Atmanspacher, H., Scheingraber, H., Eds.; Plenum Press: New York, NY, USA, 1991; Volume 1, pp. 15–33. [Google Scholar]
- Crutchfield, J.P.; Young, K. Inferring statistical complexity. Phys. Rev. Lett. 1989, 63, 105–108. [Google Scholar] [CrossRef] [PubMed]
- Bucki, R.; Chramcov, B. Information support for logistics of manufacturing tasks. Int. J. Math. Mod. Meth. App. Sci. 2013, 7, 193–203. [Google Scholar]
- Ouchi, W.G. The relationship between organizational structure and organizational control. Admin. Sci. Q. 1977, 22, 95–113. [Google Scholar] [CrossRef]
- Blau, P.M.; Schoenherr, R.A. The Structure of Organizations; Basic Books: New York, NY, USA, 1971; pp. 1–445. [Google Scholar]
- Blau, P.M.; Scott, W.R. Formal Organizations; Chandler Publishing Co.: San Francisco, CA, USA, 1962; pp. 1–312. [Google Scholar]
- Strogatz, S.H. Exploring complex networks. Nature 2001, 410, 268–276. [Google Scholar] [CrossRef] [PubMed]
- Blecker, T.; Kersten, W.; Meyer, C. Development of an approach for analyzing supply chain complexity. In Mass Customization. Concepts – Tools – Realization; Blecker, T., Friedrich, G., Eds.; Gito Verlag: Klagenfurt, Austria, 2005; Volume 1, pp. 47–59. [Google Scholar]
- Frizelle, G.; Suhov, Y.M. An entropic measurement of queueing behaviour in a class of manufacturing operations. Proc. Royal Soc. London Series. 2001, 457, 1579–1601. [Google Scholar] [CrossRef]
- AlGeddawy, T.; Samy, S.N.; Espinoza, V. A model for assessing the layout structural complexity of manufacturing systems. J. Manuf. Sys. in press.
- Hasan, M.A.; Sarkis, J.; Shankar, R. Agility and production flow layouts: An analytical decision analysis. Comput. Ind. Eng. 2012, 62, 898–907. [Google Scholar] [CrossRef]
- MacDuffie, J.P.; Sethurman, K.; Fisher, M.L. Product variety and manufacturing performance: Evidence from the international automotive assembly plant study. Manag. Sci. 1996, 42, 350–369. [Google Scholar] [CrossRef]
- Schleich, H.; Schaffer, L.; Scavarda, F. Managing complexity in automotive production. In Proceedings of the 19th international conference on production research, Valparaiso, Chile, 29 July–2 August 2007.
- Fast-Berglund, A.; Fässberg, T.; Hellman, F.; Davidsson, A.; Stahrea, J. Relations between complexity, quality and cognitive automation in mixed-model assembly. J. Manuf. Sys. 2013, 32, 449–455. [Google Scholar]
- Zou, Z.H.; Morse, E.P. Statistical tolerance analysis using GapSpace. In Proceedings of the 7th CIRP Seminar, Cachan, France, 24–25 April 2001.
- Zhu, X.; Hu, S.J.; Koren, Y.; Huang, N. A complexity model for sequence planning in mixed-model assembly lines. J. Manuf. Sys. 2012, 31, 121–130. [Google Scholar] [CrossRef]
- Samy, S.N. Complexity of products and their assembly systems. Ph.D. Thesis, University of Windsor, Ontario, Canada, June 2011. [Google Scholar]
- Hu, S.J.; Zhu, X.W.; Wang, H.; Koren, Y. Product variety and manufacturing complexity in assembly systems and supply chains. CIRP Ann. Manuf. Technol. 2008, 57, 45–48. [Google Scholar] [CrossRef]
- Deiser, O. On the development of the notion of a cardinal number. Hist. Philos. Logic 2010, 2, 123–143. [Google Scholar] [CrossRef]
- Sloane, N.J.A.; Plouffe, S. The Encyclopedia of Integer Sequences; Academic Press: San Diego, CA, USA, 1995; pp. 1–587. [Google Scholar]
- Sloane, N.A.J. A Handbook of Integer Sequences; Academic Press: Boston, MA, USA, 1973; pp. 1–206. [Google Scholar]
- Barrat, A.; Barthelemy, M.; Vespignani, A. Dynamical Processes on Complex Networks; Cambridge University Press: Cambridge, UK, 2008; pp. 1–368. [Google Scholar]
- Bonchev, D.; Buck, G.A. Quantitative measures of network complexity. In Complexity in Chemistry, Biology and Ecology; Bonchev, D., Rouvray, D.H., Eds.; Springer: New York, NY, USA, 2005; pp. 191–235. [Google Scholar]
- Modrak, V.; Marton, D. Complexity metrics for assembly supply chains: A comparative study. Adv. Mat. Res. 2013, 629, 757–762. [Google Scholar] [CrossRef]
- Modrak, V.; Marton, D.; Kulpa, W.; Hricova, R. Unraveling complexity in assembly supply chain networks. In Proceedings of the LINDI 2012—4th IEEE International Symposium on Logistics and Industrial Informatics, Smolenice, Slovakia, 5–7 September 2012; pp. 151–156.
- Munson, J.C.; Khoshgoftaar, T.M. Applications of a relative complexity metric for software project management. J. Syst. Soft. 1990, 12, 283–291. [Google Scholar] [CrossRef]
- Comber, T.; Maltby, J. Investigating layout complexity. In Computer-Aided Design of User Interfaces; Vanderdonckt, J., Ed.; Press Universitaires de Namur: Namur, country, 1996; pp. 209–227. [Google Scholar]
- The on-line encyclopedia of integer sequences (OEIS). http://oeis.org/A139582 (accessed on 6 February 2013).
© 2013 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Modrak, V.; Marton, D. Development of Metrics and a Complexity Scale for the Topology of Assembly Supply Chains. Entropy 2013, 15, 4285-4299. https://doi.org/10.3390/e15104285
Modrak V, Marton D. Development of Metrics and a Complexity Scale for the Topology of Assembly Supply Chains. Entropy. 2013; 15(10):4285-4299. https://doi.org/10.3390/e15104285
Chicago/Turabian StyleModrak, Vladimir, and David Marton. 2013. "Development of Metrics and a Complexity Scale for the Topology of Assembly Supply Chains" Entropy 15, no. 10: 4285-4299. https://doi.org/10.3390/e15104285
APA StyleModrak, V., & Marton, D. (2013). Development of Metrics and a Complexity Scale for the Topology of Assembly Supply Chains. Entropy, 15(10), 4285-4299. https://doi.org/10.3390/e15104285