Simple Urban Simulation Atop Complicated Models: Multi-Scale Equation-Free Computing of Sprawl Using Geographic Automata

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Background
3. Methods
3.1. Automata-Based Data Structures, Geographic Automata, and Polyspatial Functionality
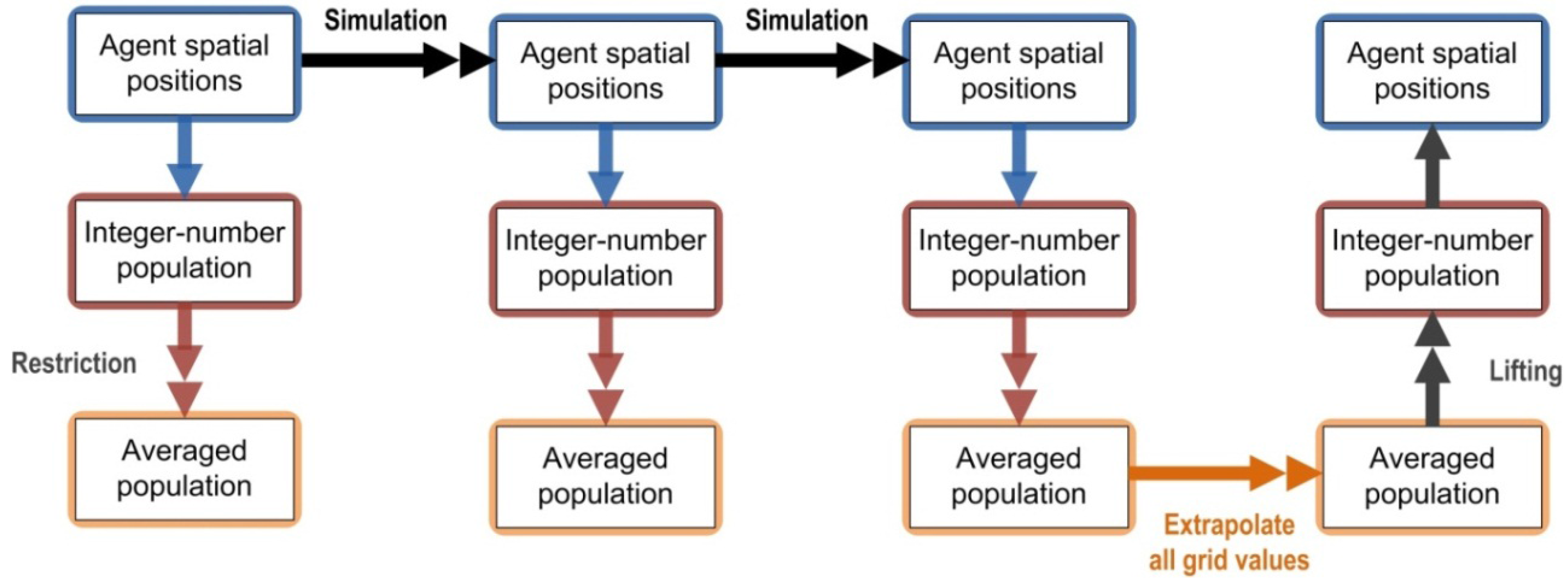
3.2. Multi-Scale Equation-Free Computing on Population
4. Modeling Sprawl
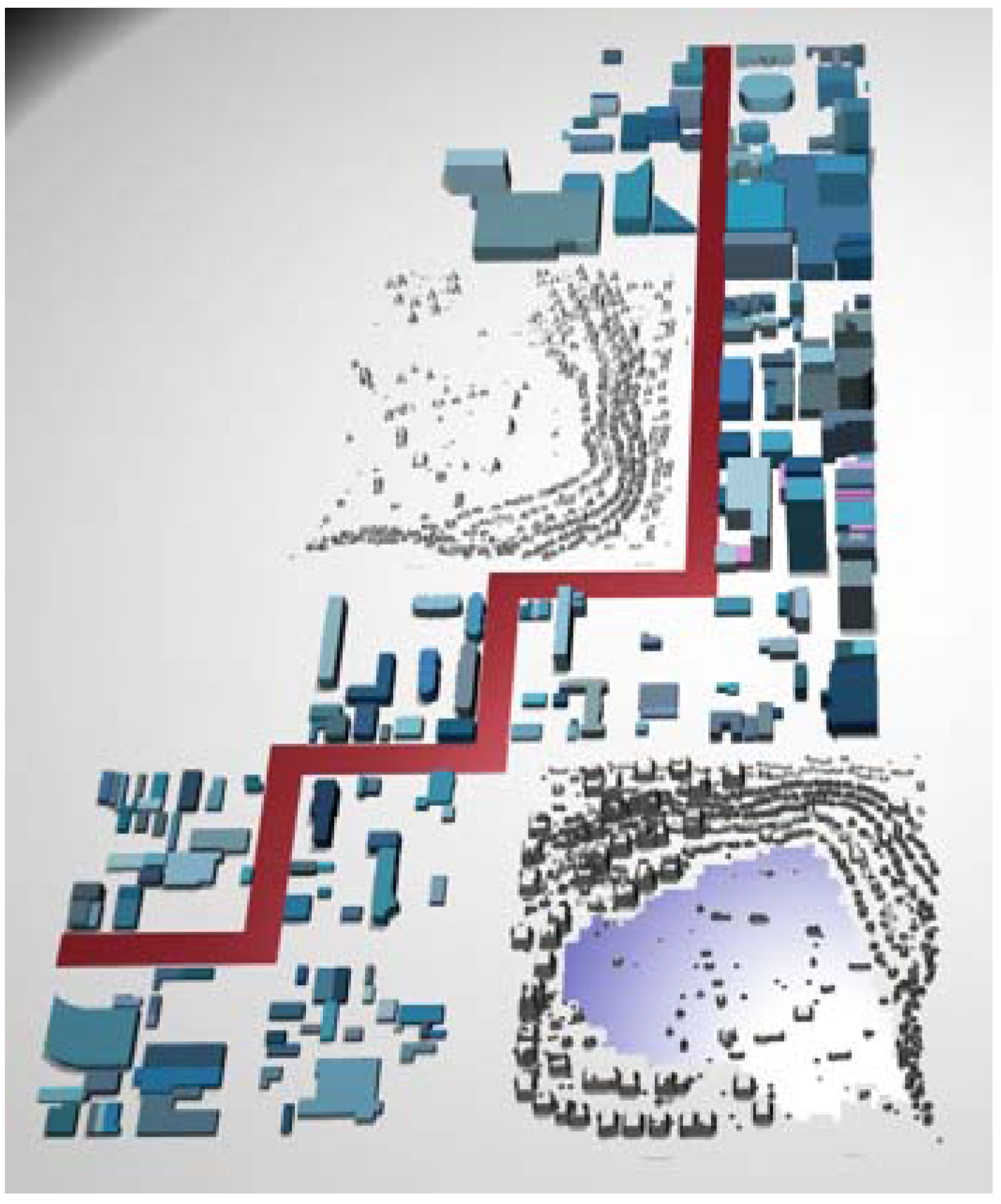
4.1. Automata-Based Model Design for Sprawl Processes



4.2. Time-Stepping and Coarse Projective Integration of Population as a Macroscopic Observable of Urban Sprawl

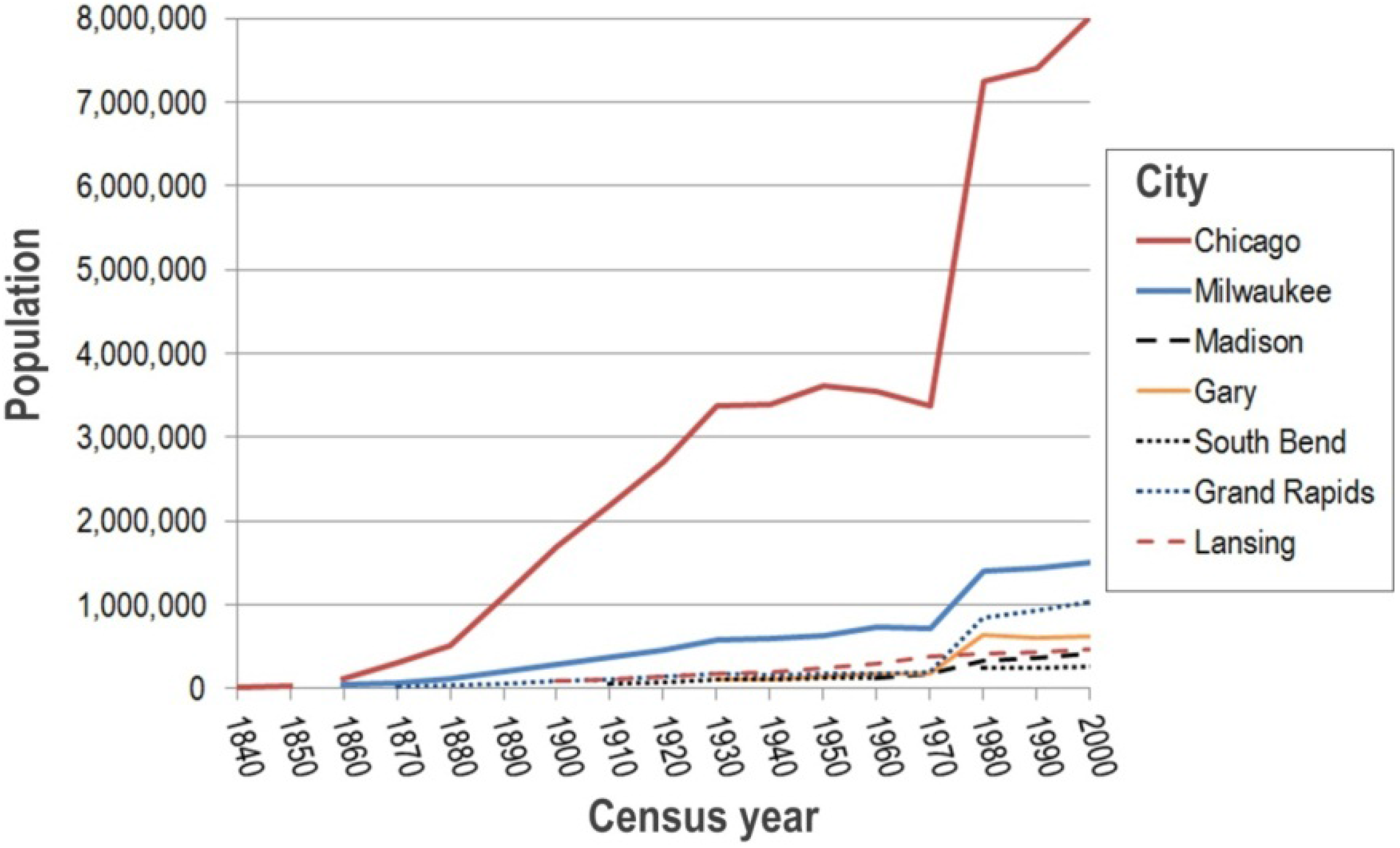
4.3. Simulating Sprawl in the American Midwest
4.4. Parallel Computing

5. Results

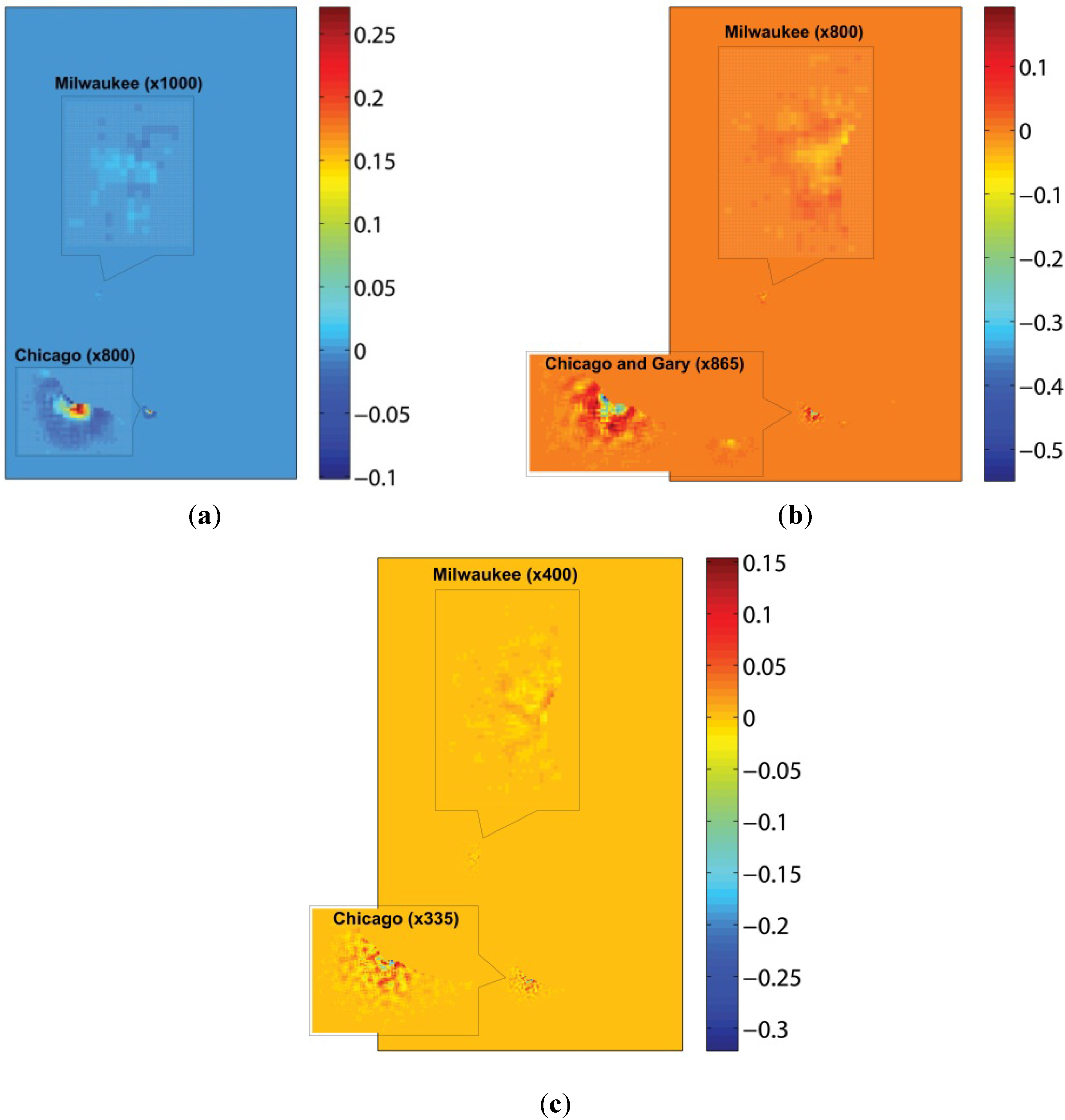
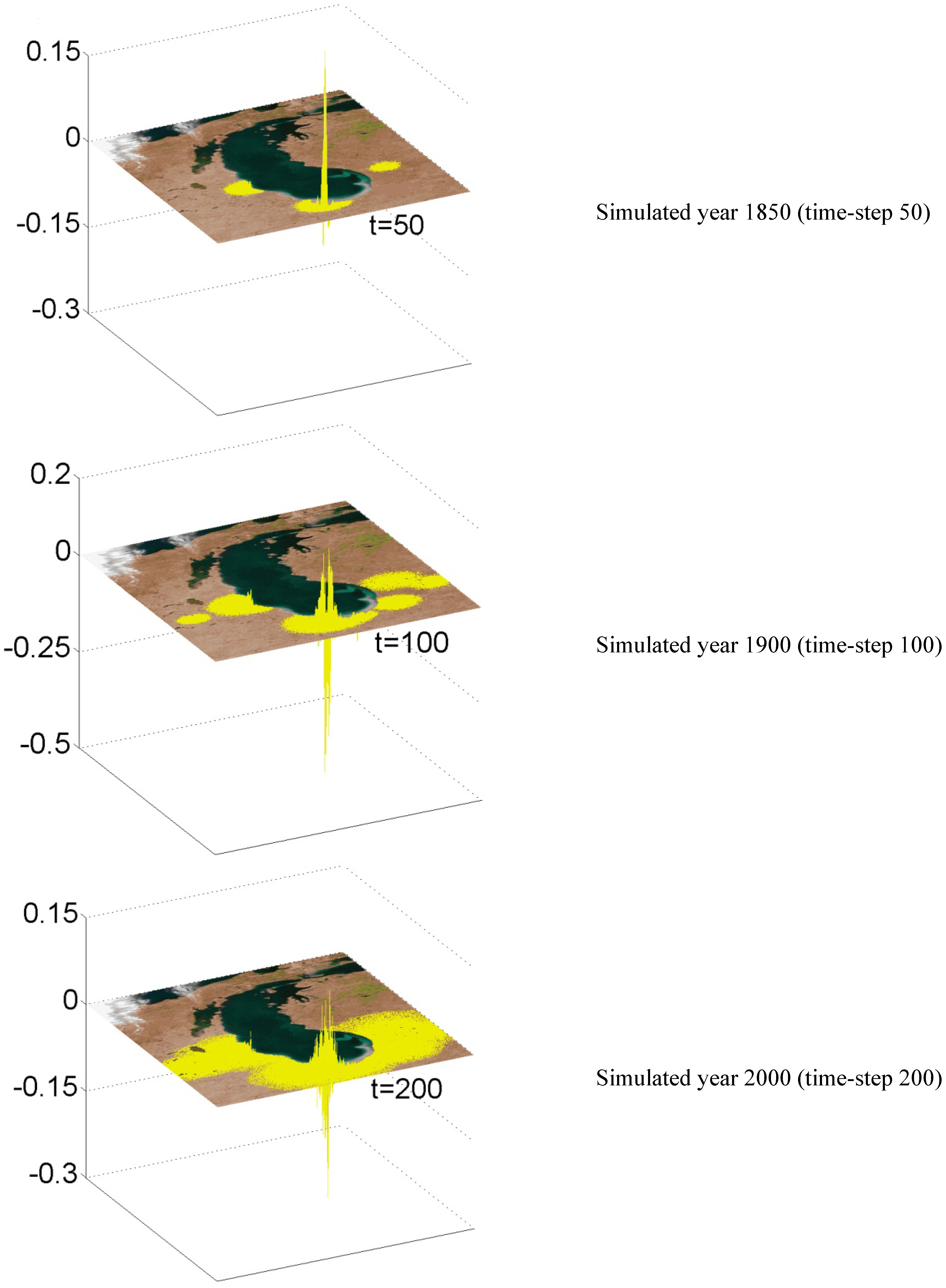
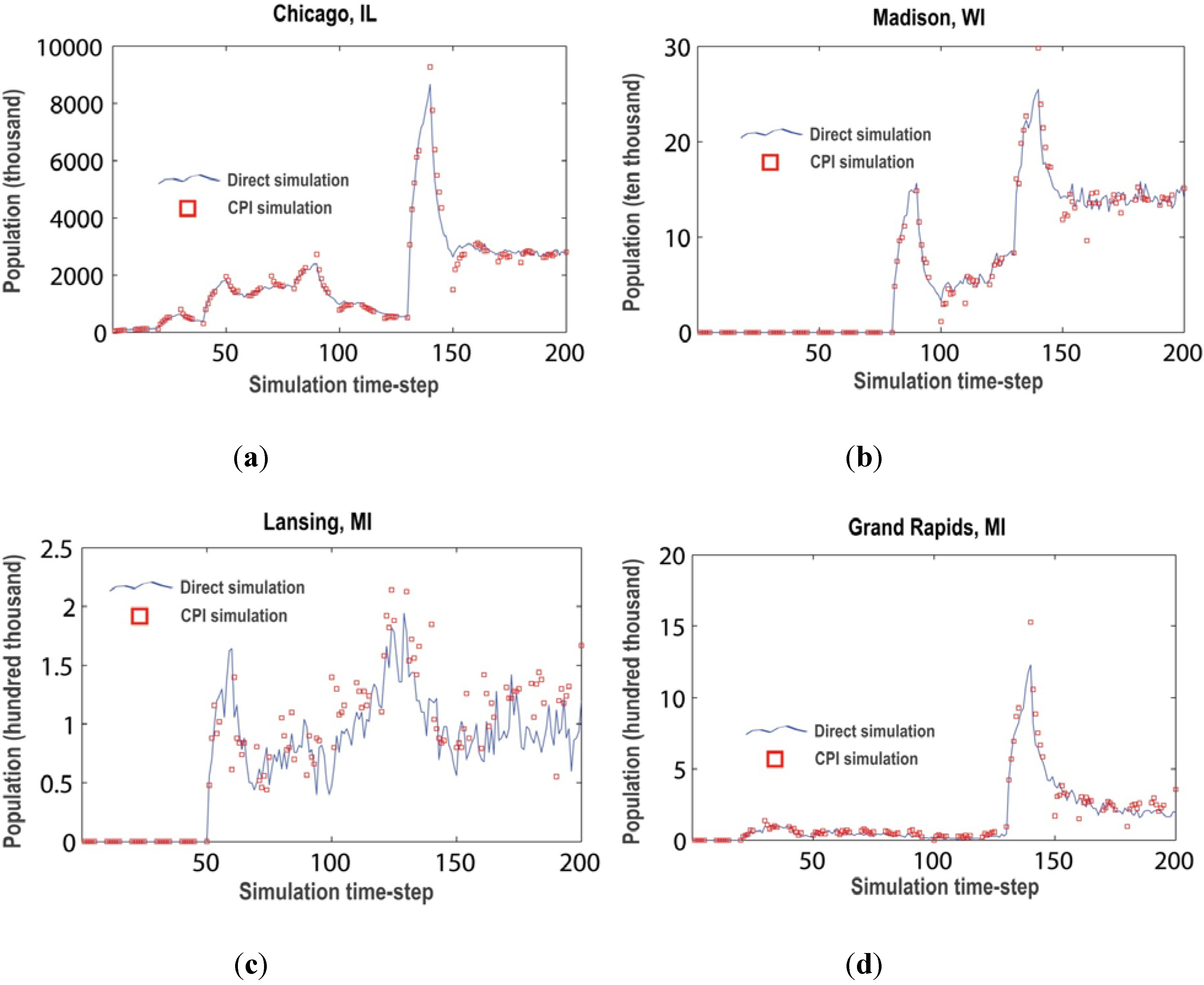
5.1. Plausibility of Equation-Free Sprawl



5.2. Efficiency of the Meta-Simulation Architecture
6. Conclusions
Acknowledgements
Conflict of Interest
References
- Maandig, M.; Reznor, T.; Ross, A.; Sheridan, R. Strings and attractors. In Welcome Oblivion, How to Destroy Angels; Columbia: New York, NY, USA, 2013; Track 6. [Google Scholar]
- Gordon, P.; Richardson, H.W. Where’s the sprawl? J. Am. Plann. Assoc. 1997, 63, 275–278. [Google Scholar]
- Schwarz, N.; Haase, D.; Seppelt, R. Omnipresent sprawl? A review of urban simulation models with respect to urban shrinkage. Environ. Plann. B: Planning and Design 2010, 37, 265–283. [Google Scholar] [CrossRef]
- Torrens, P.M. Simulating sprawl. Ann. Assoc. Am. Geogr. 2006, 96, 248–275. [Google Scholar] [CrossRef]
- Brown, D.G.; Robinson, D.T. Effects of heterogeneity in residential preferences on an agent-based model of urban sprawl. Ecol. Soc. 2006, 11, 46–68. [Google Scholar]
- Batty, M.; Xie, Y.; Sun, Z. The dynamics of urban sprawl; CASA Working Paper series, No. 15; University College London, Centre for Advanced Spatial Analysis (CASA): London, UK, 1999. [Google Scholar]
- Torrens, P.M.; O’Sullivan, D. Cellular automata and urban simulation: Where do we go from here? Environ. Plann. B 2001, 28, 163–168. [Google Scholar] [CrossRef]
- Hall, P. Cities of Tomorrow: An Intellectual History of Urban Planning and Design in the Twentieth Century; Blackwell: Oxford, UK, 1988. [Google Scholar]
- Batty, M.; Torrens, P.M. Modeling and prediction in a complex world. Futures 2005, 37, 745–766. [Google Scholar] [CrossRef]
- Horgan, J. From complexity to perplexity: Can science achieve a unified theory of complexity systems? Even at the santa fe institute, some researchers have their doubts. Scientific American 1995, 272, 104–109. [Google Scholar] [CrossRef]
- Faith, J. Why gliders don’t exist: Anti-reductionism and emergence. In Artificial Life VI: Proceedings of the Sixth International Conference on Artificial Life; Adami, C., Ed.; MIT Press: Cambridge, MA, USA, 1998; pp. 389–392. [Google Scholar]
- Batty, M. Building a science of cities. Cities 2012, 29, S9–S16. [Google Scholar] [CrossRef]
- Kanda, M. Progress in the scale modeling of urban climate: Review. Theor. Appl. Climatol. 2006, 84, 23–33. [Google Scholar] [CrossRef]
- Batty, M. Fifty years of urban modeling: Macro-statics to micro-dynamics. In The Dynamics of Complex Urban Systems; Albeverio, S., Andrey, D., Giordano, P., Vancheri, A., Eds.; Physica-Verlag HD: Berlin, Germany, 2008; pp. 1–20. [Google Scholar]
- Atkinson-Palombo, C. New housing construction in phoenix: Evidence of “new suburbanism”? Cities 2010, 27, 77–86. [Google Scholar] [CrossRef]
- Torrens, P.M. A toolkit for measuring sprawl. Appl. Spat. Anal. Policy 2008, 1, 5–36. [Google Scholar] [CrossRef]
- Lang, R.E.; Dhavale, D. Beyond megalopolis: Exploring america’s new “megapolitan” geography. Metropolitan Institute Census Report Series 2005, 5, 1–35. [Google Scholar]
- Carruthers, J.I. Growth at the fringe: The influence of political fragmentation in united states metropolitan areas. Pap. Reg.Sci. 2003, 82, 472–499. [Google Scholar] [CrossRef]
- Pendall, R. Do land-use controls cause sprawl? Environ. Plann. B 1999, 26, 555–571. [Google Scholar] [CrossRef]
- Katsoulakis, M.A.; Majda, A.J.; Vlachos, D.G. Coarse-grained stochastic processes for microscopic lattice systems. Proc. Natl. Acad. Sci. 2003, 100, 782–787. [Google Scholar] [CrossRef] [PubMed]
- Katsoulakis, M.A.; Vlachos, D.G. Coarse-grained stochastic processes and kinetic monte carlo simulators for the diffusion of interacting particles. J. Chem. Phys. 2003, 119, 9412–9428. [Google Scholar] [CrossRef]
- Gear, C.W.; Kevrekidis, I.G. Projective methods for stiff differential equations: Problems with gaps in their eigenvalue spectrum. SIAM J. Sci. Comput. 2003, 24, 1091–1106. [Google Scholar] [CrossRef]
- Rico-Martınez, R.; Gear, C.W.; Kevrekidis, I.G. Coarse projective kmc integration: Forward/reverse initial and boundary value problems. J. Comput. Phys. 2004, 196, 474–489. [Google Scholar] [CrossRef]
- Setayeshgar, S.; Gear, C.W.; Othmer, H.G.; Kevrekidis, I.G. Application of coarse integration to bacterial chemotaxis. Multiscale Model. Simul. 2005, 4, 307–327. [Google Scholar] [CrossRef]
- Alonso, W. A reformulation of classical location theory and its relation to rent theory. Pap. Reg. Sci. 1967, 19, 22–44. [Google Scholar] [CrossRef]
- Batty, M.; Chapman, D.; Evans, S.; Haklay, M.; Kueppers, S.; Shiode, N.; Smith, A.; Torrens, P.M. Visualizing the city: Communicating urban design to planners and decision-makers. In Planning Support Systems in Practice: Integrating Geographic Information Systems, Models, and Visualization Tools; Brail, R.K., Klosterman, R.E., Eds.; ESRI Press and Center for Urban Policy Research Press: Redlands, CA and New Brunswick, NJ, USA, 2001; pp. 405–443. [Google Scholar]
- Epstein, J.M. Generative Social Science: Studies in Agent-Based Computational Modeling; Princeton University Press: Princeton, NJ, USA, 2007. [Google Scholar]
- Epstein, J.M.; Axtell, R. Growing Artificial Societies from the Bottom up; MIT Press: Cambridge, MA, USA, 1996. [Google Scholar]
- Edmonds, B.; Moss, S. From kiss to kids—An “antisimplistic” modelling approach. In Multi Agent Based Simulation: Lecture Notes in Artificial Intelligence, 3415; Davidsson, P., Ed.; Springer: Berlin, Germany, 2004; pp. 130–145. [Google Scholar]
- Gerber, E.R.; Gibson, C.C. Balancing regionalism and localism: How institutions and incentives shape american transportation policy. Am. J. Poli. Sci. 2009, 53, 633–648. [Google Scholar] [CrossRef]
- Imrie, R. Urban geography, relevance, and resistance to the “policy turn”. Urban Geogr. 2004, 25, 697–708. [Google Scholar] [CrossRef]
- Deichsel, S.; Pyka, A. A pragmatic reading of friedman’s methodological essay and what it tells us for the discussion of abms. J. Artif. Soci. Soc. Simul. 2009, 12. Available online: http://jasss.soc.surrey.ac.uk/12/14/16.html/ (accessed on 1 January 2012). [Google Scholar]
- Brenner, T.; Werker, C. Policy advice derived from simulation models. J. Artif. Soci. Soci. Simul. 2009, 12. Available online: http://jasss.soc.surrey.ac.uk/12/14/12.html/ (accessed on 01/01/2012). [Google Scholar]
- Rheingold, H. Tools for Thought: The History and Future of Mind-Expanding Technology; The MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Axelrod, R. Advancing the art of simulation in the social sciences. Complexity 1997, 3, 16–22. [Google Scholar] [CrossRef]
- Hall, P.G. Cities in Civilization; Pantheon Books: New York, NY, USA, 1998. [Google Scholar]
- Batty, M. The size, scale, and shape of cities. Science 2008, 319, 769–771. [Google Scholar] [CrossRef] [PubMed]
- Bettencourt, L.; Lobo, J.; Helbing, D.; Kühnert, C.; West, G. Growth, innovation, scaling and the pace of life in cities. Proc. Natl. Acad. Sci. 2007, 104, 7301–7306. [Google Scholar] [CrossRef] [PubMed]
- Benenson, I.; Torrens, P.M. Geosimulation: Automata-Based Modeling of Urban Phenomena; John Wiley & Sons: London, UK, 2004. [Google Scholar]
- Ewing, R. Causes, characteristics, and effects of sprawl: A literature review. Environ. Urban Issues 1994, 21, 1–15. [Google Scholar]
- Ewing, R. Is los angeles-style sprawl desirable? J. Am. Plann. Assoc. 1997, 63, 107–126. [Google Scholar] [CrossRef]
- Gordon, P.; Richardson, H.W. Are compact cities a desirable planning goal? J. Am. Plann. Assoc. 1997, 63, 95–106. [Google Scholar] [CrossRef]
- Galster, G.; Hanson, R.; Ratcliffe, M.R.; Wolman, H.; Coleman, S.; Freihage, J. Wrestling sprawl to the ground: Defining and measuring an elusive concept. Hous. Pol. Debate 2001, 12, 681–717. [Google Scholar] [CrossRef]
- Peiser, R. Density and urban sprawl. Land Econ. 1989, 65, 193–204. [Google Scholar] [CrossRef]
- Gottman, J.; Harper, R.A. Metropolis on the Move: Geographers Look at Urban Sprawl; John Wiley & Sons: New York, NY, USA, 1967. [Google Scholar]
- Sultana, S.; Weber, J. Journey-to-work patterns in the age of sprawl: Evidence from two midsize southern metropolitan areas. Prof. Geogr. 2007, 59, 193–208. [Google Scholar] [CrossRef]
- Alberti, M. Quantifying the urban gradient: Linking urban planning and ecology. In Avian Ecology in an Urbanizing World; Marzluff, J.M., Bowman, R., McGowan, R., Donnelly, R., Eds.; Kluwer: New York, NY, USA, 2001. [Google Scholar]
- Song, Y.; Knaap, G.-J. Measuring urban form: Is portland winning the war on sprawl? J. Am. Plann. Assoc. 2004, 70, 210–225. [Google Scholar] [CrossRef]
- Hasse, J.E.; Lathrop, R.G. Land resource impact indicators of urban sprawl. Appl. Geogr. 2003, 23, 159–175. [Google Scholar] [CrossRef]
- Brown, D.G.; Page, S.E.; Riolo, R.; Rand, W. Modeling the effects of greenbelts on the urban-rural fringe, iEMSs: Integrated Assessment and Decision Support. Lugano, Switzerland, June 24–27, 2002; Lugano, Switzerland.
- Bone, C.; Dragićević, S.; Roberts, A. Evaluating forest management practices using a gis-based cellular automata modeling approach with multispectral imagery. Environ. Model. Assess. 2007, 12, 105–118. [Google Scholar] [CrossRef]
- Bone, C.; Dragicevic, S. Incorporating spatio-temporal knowledge in an intelligent agent model for natural resource management. Land. Urb. Plann. 2010, 96, 123–133. [Google Scholar] [CrossRef]
- Cervero, R. Transit Metropolis: A Global Inquiry; Island Press: Washington D.C., USA, 1998. [Google Scholar]
- Johnson, M. Environmental impacts of urban sprawl: A survey of the literature and proposed research agenda. Environ. Plann. A 2001, 33, 717–735. [Google Scholar] [CrossRef]
- Skinner, C.J. Urban density, meteorology and rooftops. Urban Policy Res. 2006, 24, 355–367. [Google Scholar] [CrossRef]
- Wang, F.; Zhou, Y. Modelling urban population densities in beijing 1982–1990: Suburbanisation and its causes. Urban Studies 1999, 36, 271–287. [Google Scholar] [CrossRef]
- Sutton, P. Modeling population density with night-time satellite imagery and GIS. Comput. Environ. Urban Syst. 1997, 21, 227–244. [Google Scholar] [CrossRef]
- Moudon, A.V.; Hess, P.M.; Snyder, M.C.; Stanilov, K. Effects of site design on pedestrian travel in mixed-use, medium-density environments. Transp. Res. Rec. 1997, 1578, 48–55. [Google Scholar] [CrossRef]
- Batty, M.; Kwang, S.K. Form follows function: Reformulating urban population density functions. Urban Stud. 1992, 29, 1043–1070. [Google Scholar] [CrossRef]
- Alperovich, G.; Deutsch, J. Population density gradients and urbanisation measurement. Urban Stud. 1992, 29, 1323–1328. [Google Scholar] [CrossRef]
- Zielinski, K. Experimental analysis of eleven models of urban population density. Environ. and Plann. A 1979, 11, 629–641. [Google Scholar] [CrossRef]
- Clark, C. Urban population densities. J. R.l Stat. Soc. Series A 1951, 114, 490–496. [Google Scholar] [CrossRef]
- Zou, Y.; Torrens, P.M.; Ghanem, R.; Kevrekidis, I.G. Accelerating agent-based computation of complex urban systems. Int. J. Geogr. Inf. Sci. 2012, 26, 1917–1937. [Google Scholar] [CrossRef]
- Torrens, P.M.; Nara, A. Polyspatial agents for multi-scale urban simulation and regional policy analysis. Reg. Sci. Policy Pract. 2013, 44, 419–445. [Google Scholar] [CrossRef]
- Von Neumann, J. The general and logical theory of automata. In Cerebral Mechanisms in Behavior; Jeffress, L.A., Ed.; Wiley: New York, NY, USA, 1951; pp. 1–41. [Google Scholar]
- Ulam, S. A Collection of Mathematical Problems; Interscience: New York, NY, USA, 1969. [Google Scholar]
- Turing, A.M. On computable numbers, with an application to the entscheidungsproblem. Proc. London Math. Soc. 1936, Series 2, 230–265. [Google Scholar]
- Turing, A.M. Correction to: On computable numbers, with an application to the entscheidungsproblem. Proc. London Math. Soc. 1938, Series 2, 544–546. [Google Scholar] [CrossRef]
- Turing, A.M. Computing machinery and intelligence. Mind 1950, 49, 433–460. [Google Scholar] [CrossRef]
- Torrens, P.M.; Benenson, I. Geographic automata systems. Int. J. Geogr. Inf. Sci. 2005, 19, 385–412. [Google Scholar] [CrossRef]
- Portugali, J. Self-Organization and the City; Springer-Verlag: Berlin, Germany, 2000. [Google Scholar]
- Torrens, P.M.; Li, X.; Griffin, W.A. Building agent-based walking models by machine-learning on diverse databases of space-time trajectory samples. Trans. Geogr. Inf. Sci. 2011, 15, 67–94. [Google Scholar] [CrossRef]
- Openshaw, S.; Charlton, M.E.; Wymer, C.; Craft, A. A mark 1 geographical analysis machine for the automated analysis of point data sets. Int. J. Geogr. Inf. Sys. 1987, 1, 335–358. [Google Scholar] [CrossRef]
- Samet, H. The quadtree and related hierarchical data structures. ACM Comput. Surv. 1984, 16, 187–260. [Google Scholar] [CrossRef]
- Benenson, I.; Torrens, P.M. A minimal prototype for integrating GIS and geographic simulation through geographic automata systems. In Geodynamics; Atkinson, P., Foody, G., Darby, S., Wu, F., Eds.; CRC Press: Boca Raton, FL, USA, 2005; pp. 347–369. [Google Scholar]
- Batty, M. Geocomputation using cellular automata. In Geocomputation; Openshaw, S., Abrahart, R., Eds.; Taylor and Francis: London, 2000; pp. 95–126. [Google Scholar]
- Longley, P.A.; Brooks, S.M.; McDonnell, R.; Macmillan, B. Geocomputation: A primer; John Wiley and Sons: London, UK, 1998. [Google Scholar]
- Kevrekidis, I.G.; Gear, C.W.; Hyman, J.M.; Kevrekidis, P.G.; Runborg, O.; Theodoropoulos, C. Equation-free, coarse-grained multiscale computation: Enabling microscopic simulators to perform system-level analysis. Commun. Math. Sci. 2003, 1, 715–762. [Google Scholar]
- Harris, C.D.; Ullman, E.L. The nature of cities. Ann. Am. Acad. Political Social Sci. 1945, 242, 7–17. [Google Scholar] [CrossRef]
- Burgess, E.W. The growth of the city: An introduction to a research project. In The City; Park, R.E., Burgess, E.W., McKenzie, R.D., Eds.; University of Chicago Press: Chicago, IL, USA, 1925; pp. 47–62. [Google Scholar]
- Harris, B. Urban simulation models in regional science. J. Reg. Sci. 1985, 25, 545–567. [Google Scholar] [CrossRef]
- Isard, W.; Azis, I.J.; Drennen, M.P.; Miller, R.E.; Saltzmann, S.; Thorbecke, E. Methods of Interregional and Regional Analysis; Ashgate: Aldershot, UK, 1998. [Google Scholar]
- Batty, M. Urban Modelling: Algorithims, Calibrations, Predictions; Cambridge University Press: London, UK, 1976. [Google Scholar]
- De la Barra, T. Integrated Land Use and Transport Modelling: Decision Chains and Hierarchies; Cambridge University Press: Cambridge, UK, 1989. [Google Scholar]
- Wegener, M. Operational urban models: State of the art. J. Am. Plann. Assoc. 1994, 60, 17–29. [Google Scholar] [CrossRef]
- Wilson, A.G. Urban and Regional Models in Geography and Planning; John Wiley & Sons: London, UK, 1975. [Google Scholar]
- Ratti, C.; Williams, S.; Frenchman, D.; Pulselli, R. Mobile landscapes: Using location data from cell phones for urban analysis. Environ. Plann. B 2006, 33, 727–748. [Google Scholar] [CrossRef]
- Eagle, N.; Pentland, A.; Lazer, D. Inferring social network structure using mobile phone data. Proc. Natl. Acad. Sci. 2009, 106, 15274–15278. [Google Scholar] [CrossRef] [PubMed]
- Longley, P.A. Geodemographics and the practices of geographic information science. Int. J. Geogr. Inf. Sci. 2012, 26, 2227–2237. [Google Scholar] [CrossRef]
- Batty, M. Cities and Complexity: Understanding Cities with Cellular Automata, Agent-Based Models, and Fractals; The MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Portugali, J.; Meyer, H.; Stolk, E.; Tan, E. Complexity Theories of Cities Have Come of Age; Springer: New York, NY, USA, 2012. [Google Scholar]
- Torrens, P.M. Calibrating and validating cellular automata models of urbanization. In Urban Remote Sensing: Monitoring, Synthesis and Modeling in the Urban Environment; Yang, X., Ed.; John Wiley & Sons: Chichester, UK, 2011; pp. 335–345. [Google Scholar]
- Epstein, J.M. Agent-based computational models and generative social science. Complexity 1999, 4, 41–60. [Google Scholar] [CrossRef]
- Herold, M.; Couclelis, H.; Clarke, K.C. The role of spatial metrics in the analysis and modeling of urban land use change. Comput. Environ. Urban Syst. 2005, 29, 369–399. [Google Scholar] [CrossRef]
- Asanovic, K.; Bodik, R.; Catanzaro, B.; Gebis, J.; Husbands, P.; Keutzer, K.; Patterson, D.; Plishker, W.; Shalf, J.; Williams, S.; et al. The Landscape of Parallel Computing Research: A View from Berkeley; Technical Report No. UCB/EECS-2006-183; Department of Electrical Engineering and Computer Science, University of California, Berkeley: Berkeley, CA, 2006; Available online: http://www.eecs.berkeley.edu/Pubs/TechRpts/2006/EECS-2006-183.pdf (accessed on 18 December 2006).
- Nagel, K.; Rickert, M. Parallel implementation of the transims micro-simulation. Parallel Comput. 2001, 27, 1611–1639. [Google Scholar] [CrossRef]
- Guan, Q.; Clarke, K.C.; Zhang, T. Calibrating a Parallel Geographic Cellular Automata Model; AutoCarto: Vancouver, WA, USA, 2006. [Google Scholar]
- Theodoropoulos, C.; Qian, Y.-H.; Kevrekidis, I.G. “Coarse” stability and bifurcation analysis using time-steppers: A reaction-diffusion example. Proc. Natl. Acad. Sci. 2000, 97, 9840–9843. [Google Scholar] [CrossRef] [PubMed]
- Audirac, I.; Shermyen, A.H.; Smith, M.T. Ideal urban form and visions of the good life: Florida’s growth management dilemma. J. Am. Plann. Assoc. 1990, 56, 470–482. [Google Scholar] [CrossRef]
- Bae, C.-H.C.; Richardson, H.W. Automobiles, the Environment and Metropolitan Spatial Structure; Lincoln Institute of Land Policy: Cambridge, MA, USA, 1994. [Google Scholar]
- Benfield, F.K.; Raimi, M.D.; Chen, D.D.T. Once There Were greenfields: How Urban Sprawl Is Undermining America’s Environment, Economy, and Social Fabric; Natural Resources Defense Council: New York, NY, and Washington DC, USA, 1999. [Google Scholar]
- Calthorpe, P.; Fulton, W.; Fishman, R. The Regional City: Planning for the End of Sprawl; Island Press: Washington DC, USA, 2001. [Google Scholar]
- Clawson, M. Urban sprawl and speculation in suburban land. Land Econ. 1962, 38, 99–111. [Google Scholar] [CrossRef]
- Downs, A. New Visions for Metropolitan America; Brookings Institute: Washington DC, USA, 1994. [Google Scholar]
- Duany, A.; Plater-Zyberk, E.; Speck, J. Suburban Nation: The Rise of Sprawl and the Decline of the American Dream; North Point Press: New York, NY, USA, 2000. [Google Scholar]
- El Nasser, H.; Overberg, P. A comprehensive look at sprawl in america. USA Today 2001, 12. [Google Scholar]
- Farley, R.; Schuman, H.; Binachi, S.; Colasanto, D.; Hatchett, S. Chocolate city, vanilla suburbs: Will the trend toward racially separate communities continue? Soc. Sci. Res. 1978, 7, 319–344. [Google Scholar] [CrossRef]
- Fulton, W.; Pendall, R.; Nguyen, M.; Harrison, A. Who sprawls most? How growth patterns differ across the U.S.; The Brookings Institution: Washington DC, USA, 2001. [Google Scholar]
- Hall, P. Decentralization without end? In The Expanding City: Essays in Honor of Professor Jean Gottmann; Academic Press: London, UK, 1983. [Google Scholar]
- Handy, S. Smart growth and the transportation-land use connection: What does the research tell us? Int. Reg. Sci. Rev. 2005, 28, 146–167. [Google Scholar] [CrossRef]
- Harvey, R.O.; Clark, W.A.V. The nature and econmics of sprawl. Land Econ. 1965, 61, 1–9. [Google Scholar] [CrossRef]
- Lang, R.E. Open spaces, bounded places: Does the american west’s arid landscape yield dense metropolitan growth? Hous. Pol. Debate 2003, 13, 755–778. [Google Scholar] [CrossRef]
- Lessinger, J. The cause for scatteration: Some reflections on the national capitol region plan for the year 2000. J. Am. Inst. Plan. 1962, 28, 159–170. [Google Scholar] [CrossRef]
- Mayer, H. The pull of land and space. In Metropolis on the Move: Geographers Look at Urban Sprawl; Gottmann, J., Harper, R.A., Eds.; John Wiley & Sons: New York, NY, USA, 1967. [Google Scholar]
- Ottensmann, J.R. Urban sprawl, land values and the density of development. Land Econ. 1977, 53, 389–400. [Google Scholar] [CrossRef]
- Sui, D.Z.; Wei, T.; Gavinha, J. How smart is smart growth? The case of austin, texas. In Worldminds: Geographical Perspectives on 100 Problems; Janelle, D.G., Warf, B., Hansen, K., Eds.; Kluwer Academic Publishers: Dordrecht, The Neatherlands, 2004; pp. 209–214. [Google Scholar]
- Hasse, J.; Lathrop, R.G. A housing-unit-level approach to characterizing residential sprawl. Photo. Eng. Rem. Sens. 2003, 69, 1021–1030. [Google Scholar] [CrossRef]
- Ewing, R.; Schmid, T.; Killingsworth, R.; Zlot, A.; Raudenbush, S. Relationship between urban sprawl and physical activity, obesity, and morbidity. Am. J. Healt. Prom. 2003, 18, 47–57. [Google Scholar] [CrossRef]
- Kahneman, D. Thinking, Fast and Slow; Farrar, Straus and Giroux: New York, NY, USA, 2011. [Google Scholar]
- Batty, M. Visually-driven urban simulation: Exploring fast and slow change in residential location. Environ. Plann. A 2013, 45, 532–552. [Google Scholar] [CrossRef]
- Evans, A.W. The property market: Ninety per cent efficient? Urban Stud. 1995, 32, 5–29. [Google Scholar] [CrossRef]
- Rossi, P.H. Why Families Move: A Study in the Social Psychology of Urban Residential Mobility; Free Press: Glencoe, IL, USA, 1955. [Google Scholar]
- Batty, M.; Longley, P.A.; Fotheringham, A.S. Urban growth and form: Scaling, fractal geometry, and diffusion-limited-aggregation. Environ. Plann. A 1989, 21, 1447–1472. [Google Scholar] [CrossRef]
- Liu, J.; Dietz, T.; Carpenter, S.R.; Alberti, M.; Folke, C.; Moran, E.; Pell, A.N.; Deadman, P.; Kratz, T.; Lubchenco, J.; et al. Complexity of coupled human and natural systems. Science 2007, 317, 1513–1516. [Google Scholar] [CrossRef] [PubMed]
- Bussière, R. The Spatial Distribution of Urban Populations; International Federation for Housing and Planning and Le Centre de Recherche d'Urbanisme: The Hague and Paris, France, 1968. [Google Scholar]
- Hess, P.; Moudon, A.; Snyder, M.; Stanilov, K. Site design and pedestrian travel. Transp. Res. Rec.: J. Transp. Res. Board 1999, 1674, 9–19. [Google Scholar] [CrossRef]
- Agrawal, A.W.; Schimek, P. Extent and correlates of walking in the USA. Transp. Research Part D: Trans. Environ. 2007, 12, 548–563. [Google Scholar] [CrossRef]
- Riebsame, W.E.; Gosnell, H.; Theobald, D.M. Land use and landscape change in the colorado mountains i: Theory, scale, and pattern. Mt. Res. Dev. 1996, 16, 395–405. [Google Scholar] [CrossRef]
- Cervero, R. America’s Suburban Centers: The Land-Use Transportation Link; Unwin-Hyman: Winchester, MA, USA, 1989. [Google Scholar]
- Zou, Y.; Kevrekidis, I.G.; Ghanem, R.G. Equation-free particle-based computations: Coarse projective integration and coarse dynamic renormalization in 2d. Ind. Engin. Chem. Res. 2006, 45, 7002–7014. [Google Scholar] [CrossRef]
- Gottmann, J. Megalopolis: The Urbanized Northeastern Seaboard of the United States; MIT Press: Cambridge, MA, USA, 1967. [Google Scholar]
- Walker, R.; Ellis, M.; Barff, R. Linked migration systems: Immigration and internal labor flows in the united states. Econ. Geogr. 1992, 68, 234–248. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Liao, D.; Yip, S. Coupling continuum to molecular-dynamics simulation: Reflecting particle method and the field estimator. Phys. Rev. E 1998, 57, 7259. [Google Scholar] [CrossRef]
- Tesfatsion, L. Agent-Based Computational Economics: Growing Economies from the Bottom up; Iowa State University: Ames, IA, USA, 2002. [Google Scholar]
- Torrens, P.M. Moving agent pedestrians through space and time. Ann. Assoc. Am. Geogr. 2012, 102, 35–66. [Google Scholar] [CrossRef]
- Benguigi, L.; Czamanski, D.; Marinov, M. City growth as a leap-frogging process: An application to the tel-aviv metropolis. Urban Stud. 2001, 38, 1819–1839. [Google Scholar] [CrossRef]
- Monserud, R.A.; Leemans, R. Comparing global vegetation maps with the kappa statistic. Ecolo. Modell. 1992, 62, 275–293. [Google Scholar] [CrossRef]
- Schelling, T.C. Models of segregation. Am. Econ. Rev. 1969, 59, 488–493. [Google Scholar]
- Crooks, A.; Castle, C.; Batty, M. Key challenges in agent-based modelling for geo-spatial simulation. Comput. Environ. Urban Syst. 2008, 32, 417–430. [Google Scholar] [CrossRef]
- Albrecht, J. A new age for geosimulation. Trans. Geogr. Inf. Sci. 2005, 9, 451–454. [Google Scholar] [CrossRef]
- Benenson, I.; Torrens, P.M. Special issue: Geosimulation: Object-based modeling of urban phenomena. Comput., Environ. Urban Syst. 2004, 28, 1–8. [Google Scholar] [CrossRef]
- Mandl, P. Geo-simulation—Experimentieren und problemlösen mit gis-modellen. In Angewandte Geographische Informationsverarbeitung XII: Beiträge zum Agit-Symposium, Salzburg; Strobl, J., Blaschke, T., Griesebner, G., Eds.; Herbert Wichmann Verlag: Heidelberg, Germany, 2000; pp. 345–356. [Google Scholar]
- Shen, Z.; Kawakami, M.; Kawamura, I. Geosimulation model using geographic automata for simulating land-use patterns in urban partitions. Environ. Plann. B: Plann. Des. 2009, 36, 802–823. [Google Scholar] [CrossRef]
- Zhao, Y.; Murayama, Y. A new method to model neighborhood interaction in cellular automata-based urban geosimulation. In Lecture Notes in Computer Science 4488: Computational Science (ICCS 2007); Shi, Y., Albada, G.D., Dongarra, J., Eds.; Springer: Berlin, Germany, 2007; pp. 550–557. [Google Scholar]
- Batty, M.; Torrens, P.M. Modeling complexity: The limits to prediction. CyberGeo 2001, 201. [Google Scholar] [CrossRef]
- Blikstein, P.; Abrahamson, D.; Wilensky, U. Netlogo: Where We Are, Where We’re Going, In the Proceedings of Annual Meeting of Interaction Design & Children, Boulder, CO, USA, 8–10 June, 2005; Eisenberg, M., Eisenberg, A., Eds.; Boulder, CO, USA, 2005. [Google Scholar]
- North, M.J.; Collier, N.T.; Vos, J.R. Experiences creating three implementations of the repast agent modeling toolkit. ACM Trans. Model. Comput. Simul. 2006, 16, 1–25. [Google Scholar] [CrossRef]
- Masson, V. Urban surface modeling and the meso-scale impact of cities. Theor. Applied Climatol. 2006, 84, 35–45. [Google Scholar] [CrossRef]
- Oke, T.R. Towards better scientific communication in urban climate. Theor. Appl. Climatol. 2006, 84, 179–190. [Google Scholar] [CrossRef]
- Kiehl, J.; Hack, J.; Bonan, G.; Boville, B.; Williamson, D.; Rasch, P. The national center for atmospheric research community climate model: Ccm3. J. Clim. 1998, 11, 1131–1149. [Google Scholar] [CrossRef]
- Chen, L.; Debenedetti, P.; Gear, C.; Kevrekidis, I. From molecular dynamics to coarse self-similar solutions: A simple example using equation-free computation. J. Non-Newt. Flu. Mech. 2004, 120, 215–223. [Google Scholar] [CrossRef]
- Erban, R.; Kevrekidis, I.G.; Adalsteinsson, D.; Elston, T.C. Gene regulatory networks: A coarse-grained, equation-free approach to multiscale computation. 2005; arXiv preprint physics/0508112. [Google Scholar]
- G Makeev, A.; G Kevrekidis, I. Equation-free multiscale computations for a lattice-gas model: Coarse-grained bifurcation analysis of the no+ co reaction on pt (100). Chem. Engin. Sci. 2004, 59, 1733–1743. [Google Scholar] [CrossRef]
- Hummer, G.; Kevrekidis, I.G. Coarse molecular dynamics of a peptide fragment: Free energy, kinetics, and long-time dynamics computations. 2002; arXiv preprint physics/0212108. [Google Scholar]
- Daoutidis, P.; Soroush, M.; Kravaris, C. Feedforward/feedback control of multivariable nonlinear processes. AIChE J. 1990, 36, 1471–1484. [Google Scholar] [CrossRef]
© 2013 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Torrens, P.M.; Kevrekidis, Y.; Ghanem, R.; Zou, Y. Simple Urban Simulation Atop Complicated Models: Multi-Scale Equation-Free Computing of Sprawl Using Geographic Automata. Entropy 2013, 15, 2606-2634. https://doi.org/10.3390/e15072606
Torrens PM, Kevrekidis Y, Ghanem R, Zou Y. Simple Urban Simulation Atop Complicated Models: Multi-Scale Equation-Free Computing of Sprawl Using Geographic Automata. Entropy. 2013; 15(7):2606-2634. https://doi.org/10.3390/e15072606
Chicago/Turabian StyleTorrens, Paul M., Yannis Kevrekidis, Roger Ghanem, and Yu Zou. 2013. "Simple Urban Simulation Atop Complicated Models: Multi-Scale Equation-Free Computing of Sprawl Using Geographic Automata" Entropy 15, no. 7: 2606-2634. https://doi.org/10.3390/e15072606
APA StyleTorrens, P. M., Kevrekidis, Y., Ghanem, R., & Zou, Y. (2013). Simple Urban Simulation Atop Complicated Models: Multi-Scale Equation-Free Computing of Sprawl Using Geographic Automata. Entropy, 15(7), 2606-2634. https://doi.org/10.3390/e15072606