Non-Linear Fusion of Observations Provided by Two Sensors


Abstract
:1. Introduction

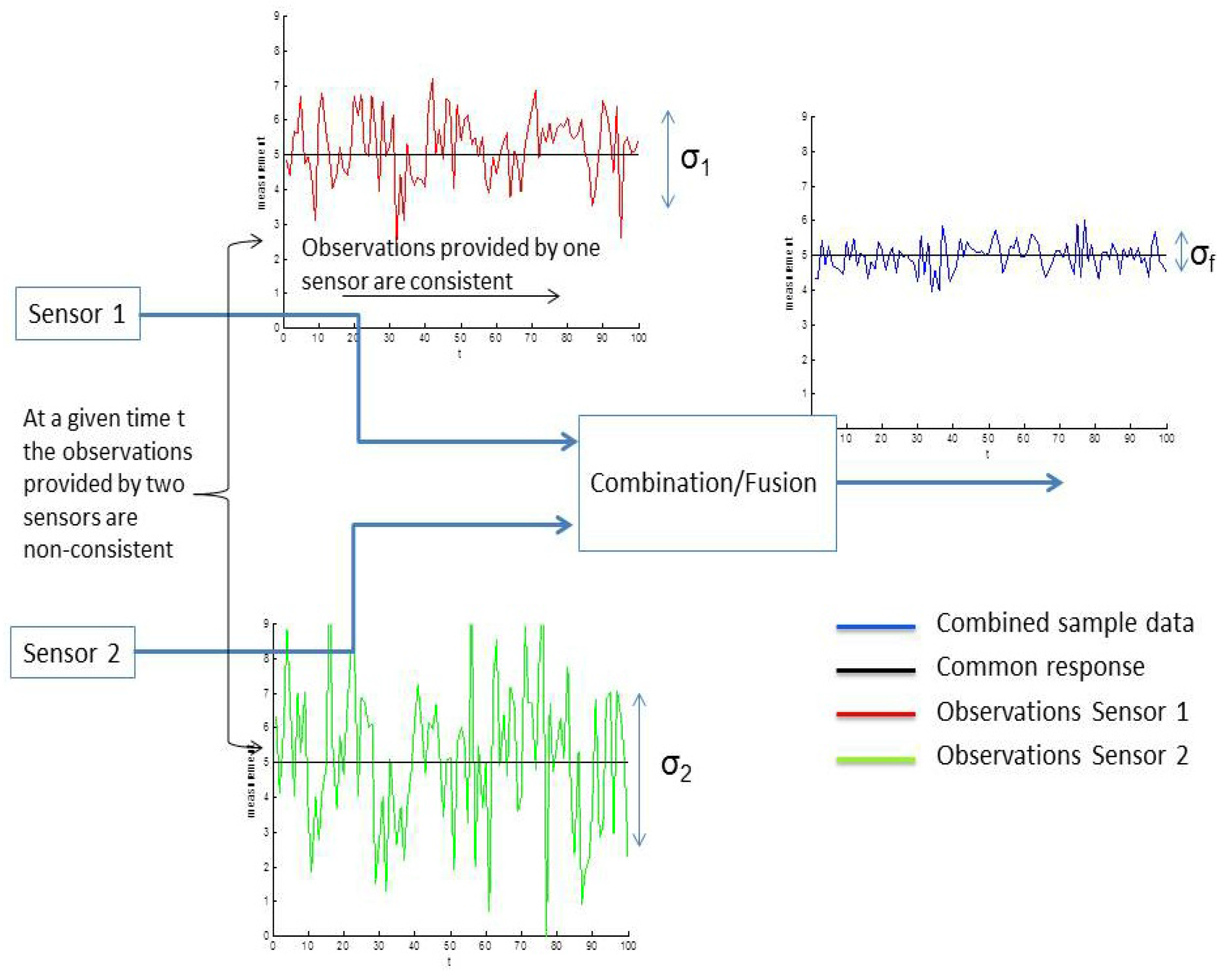
2. Problem Statement
- Realizations situated on both sides of the mean, m, such as and or and .
- Realizations situated on the same side of the mean, m, such as and or and .
3. Non-Linear Fusion Operator
3.1. The Non-Linear Transformation
3.1.1. Definition of the Non-Linear Transformation
- If and
- If and
- otherwise and or and
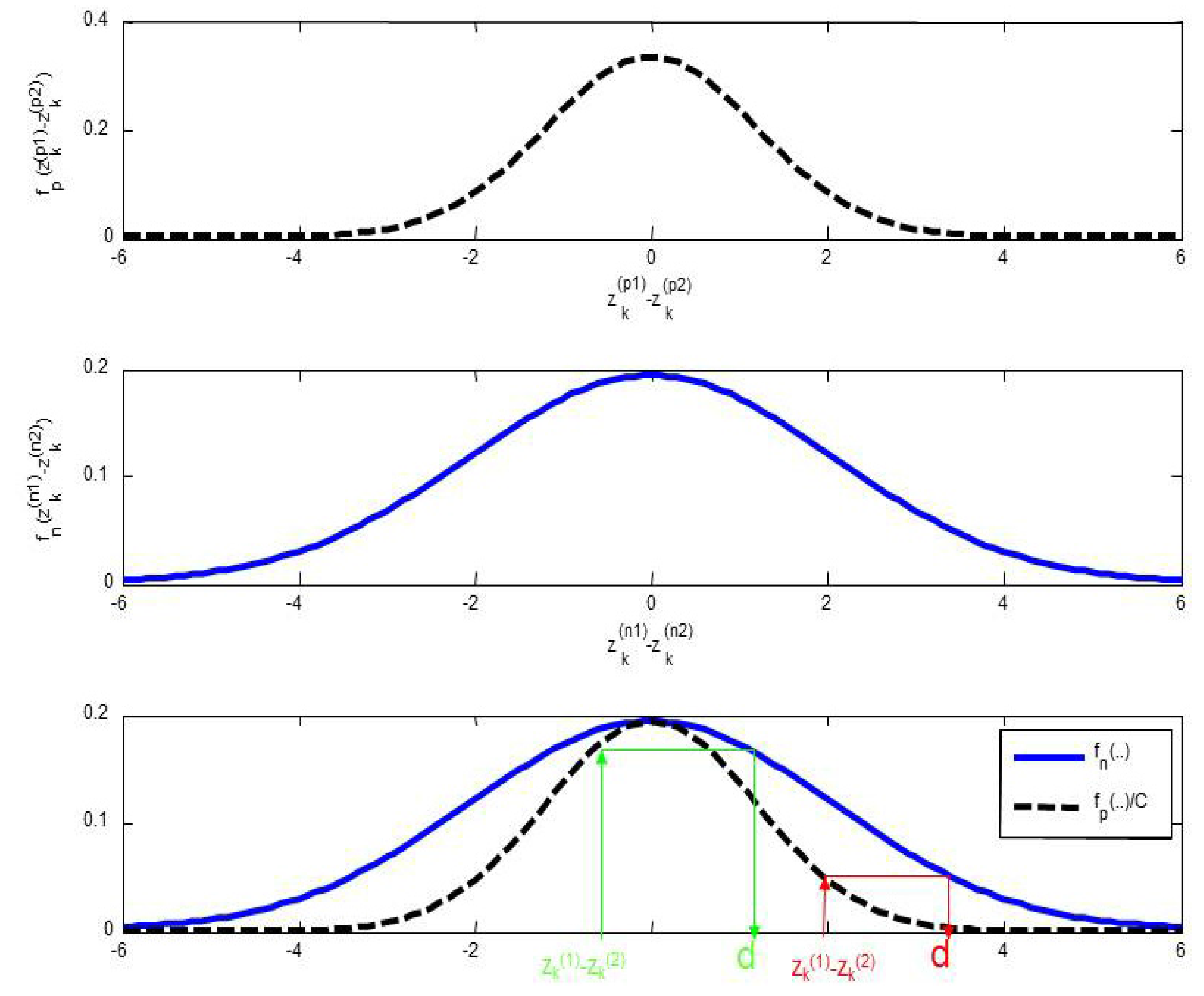
3.1.2. A Condition on the Non-Linear Transformation
- If and or and , we notice , , the respective MSE of the non-linear fusion operator output and of the linear fusion operator output.
- otherwise, we notice , , the respective MSE for the non-linear fusion operator and for the linear fusion operator.

3.2. Transformation Function
3.2.1. Conditions on the Transformation Function
- Condition 1:
- Condition 2:
3.2.2. Definition of the Transformation Function
- Let be the Gaussian distribution of the difference between the random variables, and . This distribution is a zero-mean, and its variance is given by .
- Let be the Gaussian distribution of the difference between the random variables, and . This distribution is a zero-mean, and its variance is given by .

4. Experimentation
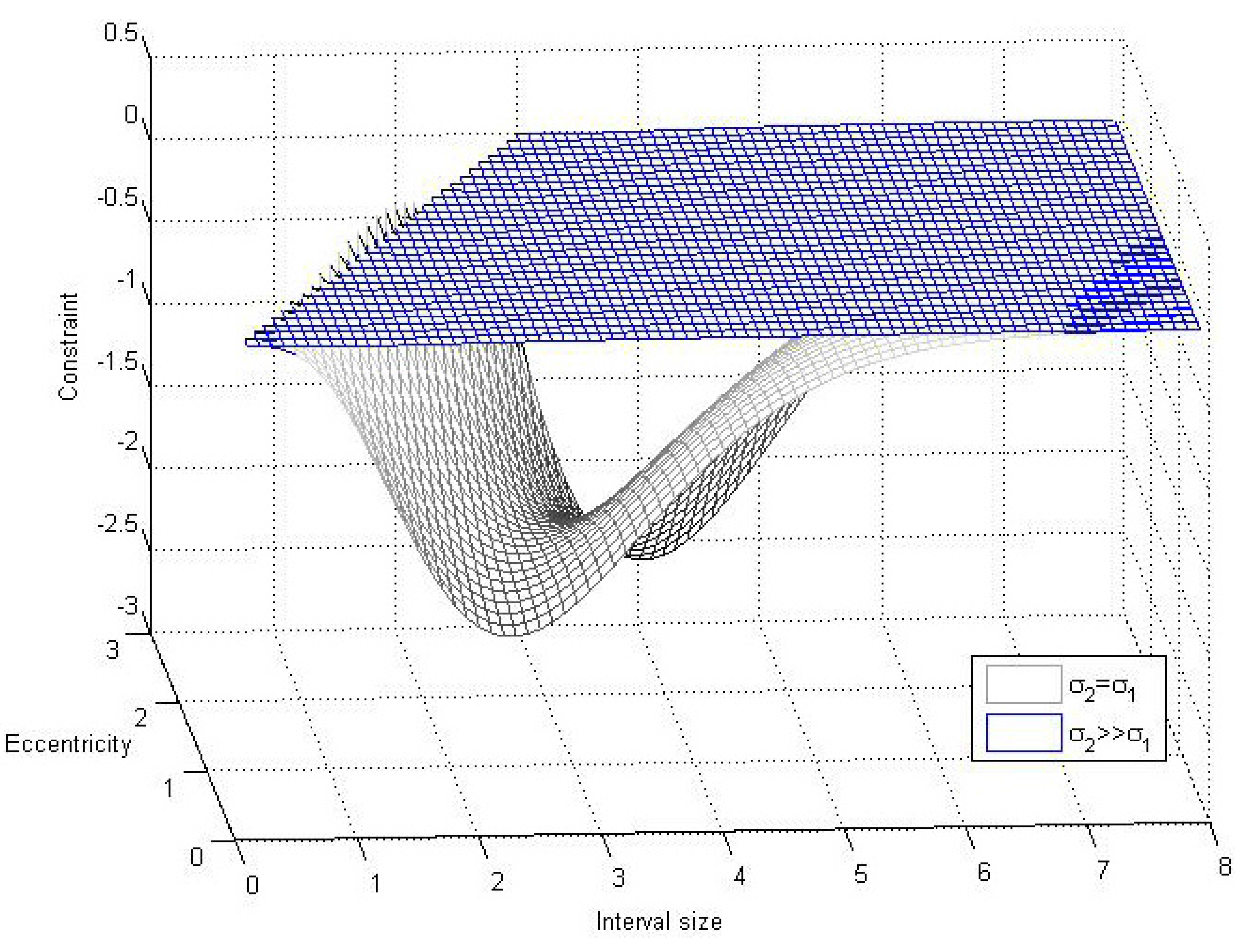
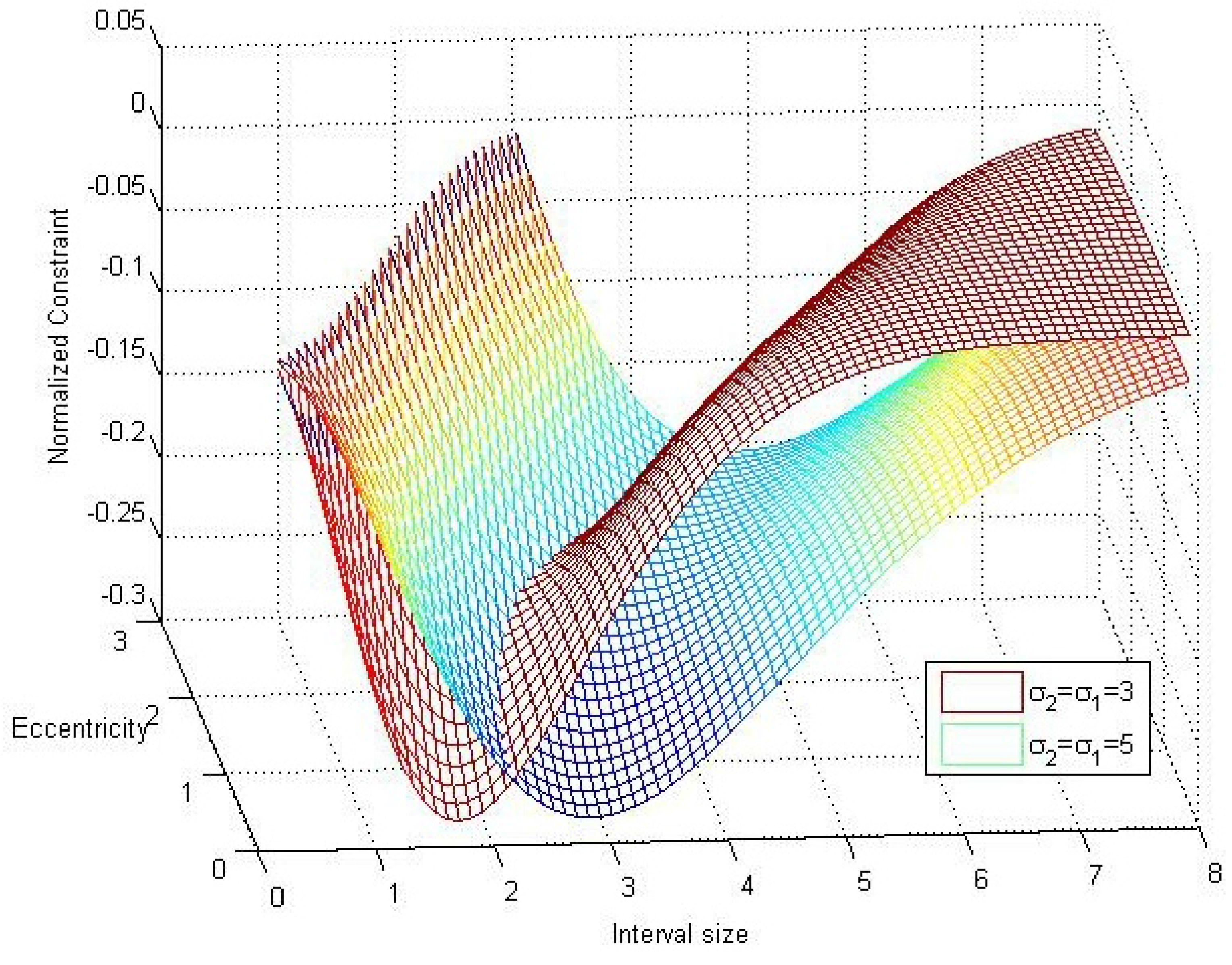
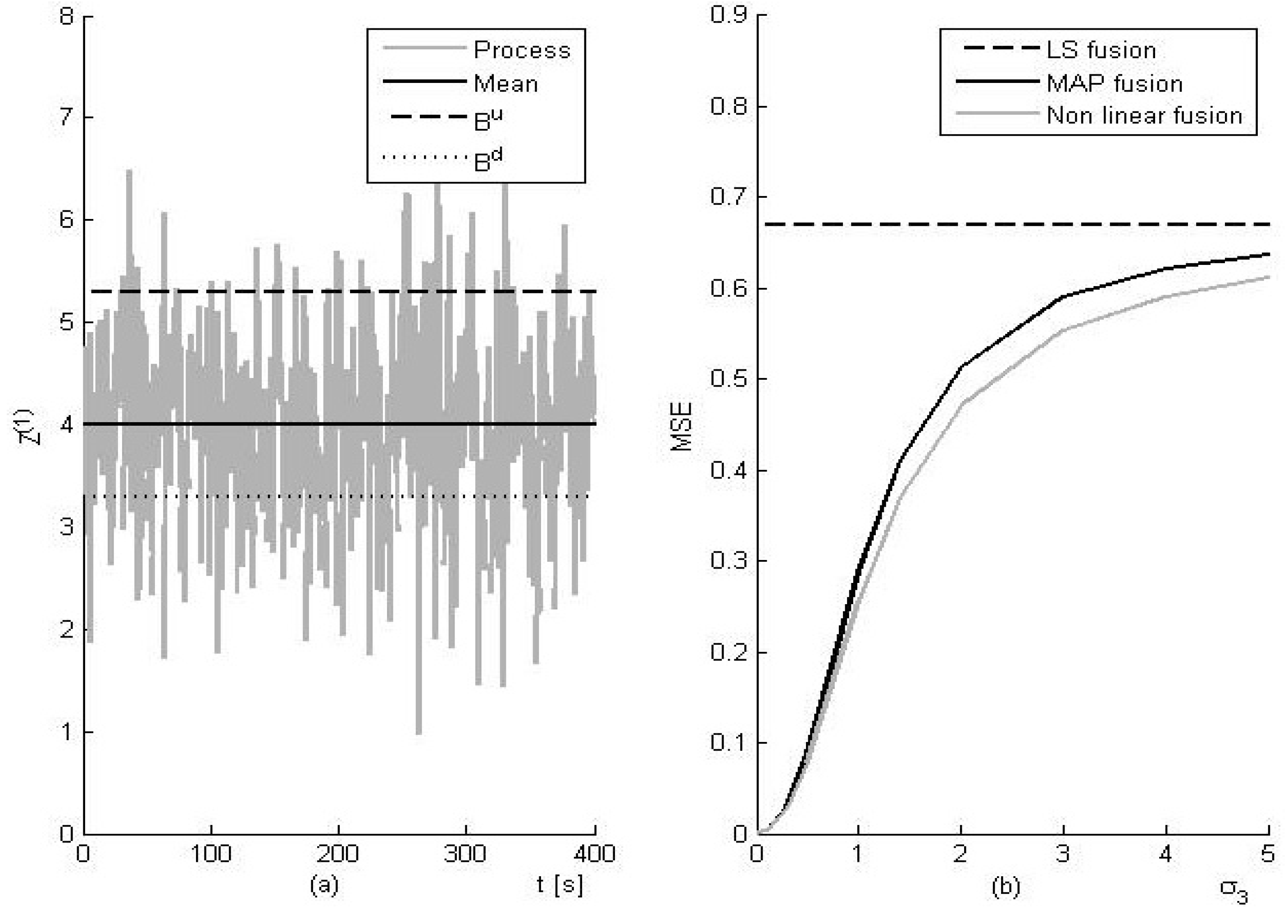
4.1. Verification of the Inequality


4.2. Assessment of the Fusion Operator


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mean | MSE | |
|---|---|---|
| First signal | 4 | 1 |
| Second signal | 4 | 2 |
| Linear fusion | 4 | 0.666 |
| Prior information | Mean Square Error | |
|---|---|---|
| Accuracy σ3 | MAP Fusion | NL Fusion |
| 0.0 | 0.0000 | 0.0000 |
| 0.1 | 0.0030 | 0.0030 |
| 0.3 | 0.0294 | 0.0274 |
| 0.5 | 0.0876 | 0.0779 |
| 1.0 | 0.2884 | 0.2566 |
| 1.4 | 0.4106 | 0.3695 |
| 2.0 | 0.5135 | 0.4711 |
| 3.0 | 0.5902 | 0.5534 |
| 4.0 | 0.6218 | 0.5909 |
| 5.0 | 0.6369 | 0.6114 |
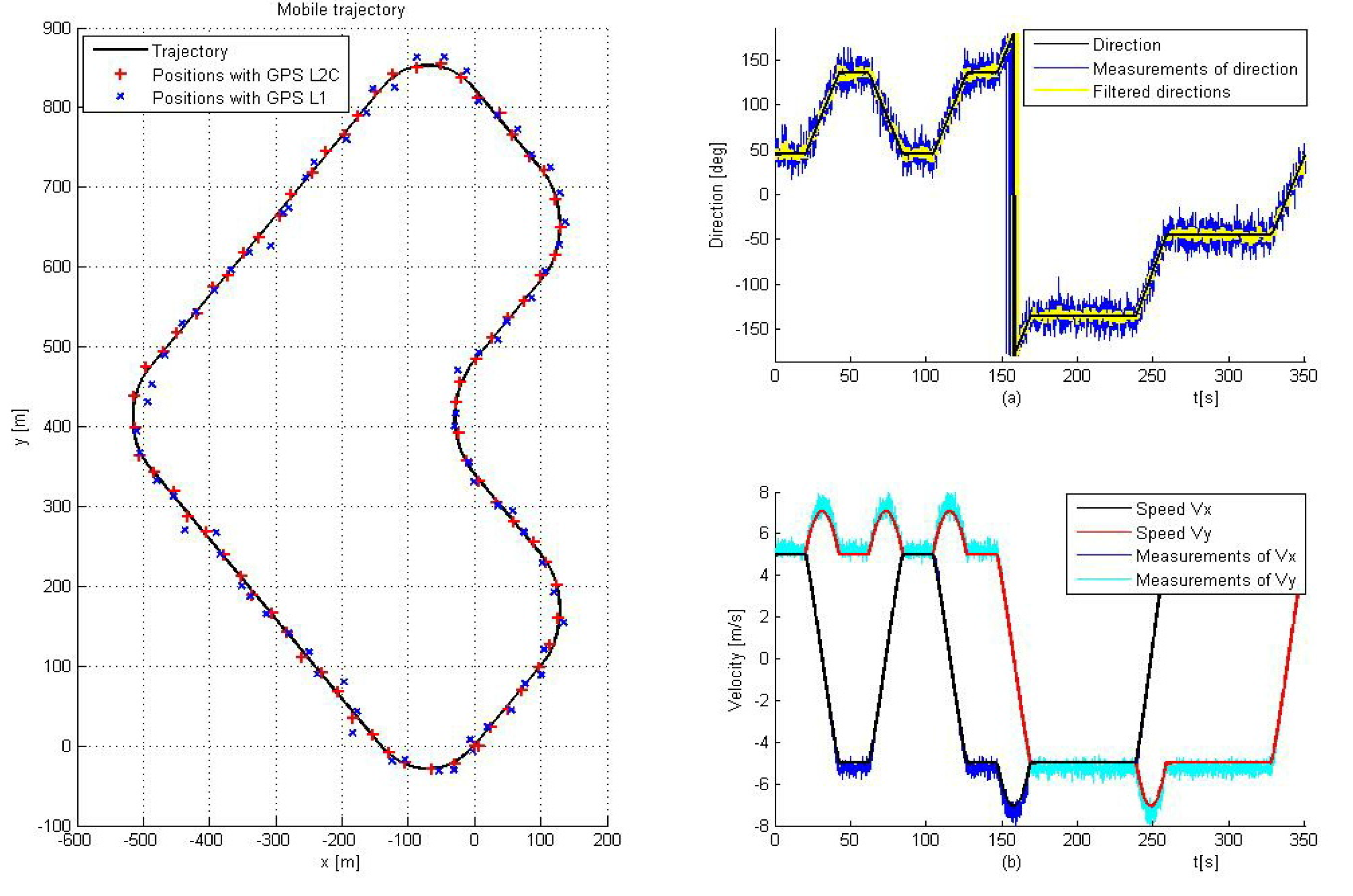
4.3. Multi-Sensor Estimation

| Statistical parameter | MSE x | MSE y | RMS error |
|---|---|---|---|
| GPS L1 | 2.0549 | 2.0141 | 2.0169 |
| ML fusion | 1.3565 | 1.4039 | 1.6612 |
| MAP fusion | 0.2524 | 0.2556 | 0.7128 |
| non-linear fusion | 0.2350 | 0.2365 | 0.6867 |
5. Conclusions
Conflict of Interest
References
- Cochran, W.G. Problem arising in the analysis of a series of similar experiments. J. R. Stat. Soc. 1937, 4, 102–118. [Google Scholar] [CrossRef]
- Cochran, W.G.; Carroll, S.P. A sampling investigation of the efficiency of weighting inversely as the estimated variance. Biometrics 1953, 9, 447–459. [Google Scholar] [CrossRef]
- Bement, T.R.; Williams, J.S. Variance of weighted regression estimators when sampling errors are independent and heteroscedastic. J. Am. Stat. Assoc. 1969, 64, 1369–1382. [Google Scholar] [CrossRef]
- Neyman, J.; Scott, E. Consistent estimators based on partially consistent observations. Econometrica 1948, 16, 1–32. [Google Scholar] [CrossRef]
- Rao, J.N.K. Estimating the common mean of possibly different normal populations: A simulation study. J. Am. Stat. Assoc. 1980, 75, 447–453. [Google Scholar] [CrossRef]
- Tsao, M.; Wu, C. Empirical likelihood inference for a common mean in the presence of heteroscedasticity. Can. J. Stat. 2006, 34, 45–59. [Google Scholar] [CrossRef]
- Gustafsson, F. Adaptative Filtering and Change Detection; Wiley: New York, NY, USA, 2001. [Google Scholar]
- Shin, V.; Lee, Y.; Choi, T.S. Generalized Millman’s formula and its application for estimation problems. Signal Process. 2006, 86, 257–266. [Google Scholar] [CrossRef]
- Kacemi, J.; Reboul, S.; Benjelloun, M. Information Fusion in a Multi-Frequencies GPS Receiver. In Proceedings of the IEEE International Conference on Aerospace And Electronics Systems Society (IEEE, AESS), Position Location and Navigation Symposium (PLANS), Monterey, CA, USA, 26–29 April 2004; pp. 399–404.
- Lavielle, M.; Lebarbier, E. An application of MCMC methods for the multiple change-points problem. Signal Process. 2001, 81, 39–53. [Google Scholar] [CrossRef]
- Robert, C.P. The Bayesian Choice, 2nd ed.; Springer: New York, NY, USA, 2001. [Google Scholar]
- Stienne, G.; Reboul, S.; Azmani, M.; Boutoille, S.; Choquel, J.B.; Benjelloun, M. Bayesian change-points estimation applied to GPS signal tracking. ISRN Signal Process. 2011. [Google Scholar] [CrossRef]
- Boutoille, S.; Reboul, S.; Benjelloun, M. A hybrid fusion system applied to off-line detection and change-points estimation. Inf. Fusion 2010, 11, 325–337. [Google Scholar] [CrossRef]
- Reboul, S.; Benjelloun, M. Joint segmentation of the wind speed and direction. Signal Process. 2006, 86, 744–759. [Google Scholar] [CrossRef]
- Mitchell, H.B. Multi-Sensor Data Fusion, An Introduction; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Zhu, Y.; You, Z.; Zhao, J.; Zhang, K.; Li, X.R. The optimality for the distributed kalman filtering fusion with feedback. Automatica 2001, 37, 1489–1493. [Google Scholar] [CrossRef]
- Bar-Shalom, Y.; Campo, L. The effect of the common process noise on the two-sensor fused-track covariance. IEEE Trans. Aerosp. Electron. Syst. 1986, 22, 803–805. [Google Scholar] [CrossRef]
- Gao, J.B.; Harris, C.J. Some remarks on kalman filters for the multisensor fusion. Inf. Fusion 2002, 3, 191–201. [Google Scholar] [CrossRef]
- Chen, H.; Kirubarajan, T.; Bar-Shalom, Y. Performance limits of track-to-track fusion vs. centralized estimation: Theory and application. IEEE Trans. Aerosp. Electron. Syst. 2003, 39, 386–400. [Google Scholar] [CrossRef]
- Azmani, M.; Reboul, S.; Choquel, J.-B.; Benjelloun, M. A Recursive Fusion Filter for Angular Data. In Proceedings of the IEEE International Conference on Robotics and Biomimetics, Guilin, China, 19–23 December 2009; pp. 882–887.
Appendix 1
Appendix 2
© 2013 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Azmani, M.; Reboul, S.; Benjelloun, M. Non-Linear Fusion of Observations Provided by Two Sensors. Entropy 2013, 15, 2698-2715. https://doi.org/10.3390/e15072698
Azmani M, Reboul S, Benjelloun M. Non-Linear Fusion of Observations Provided by Two Sensors. Entropy. 2013; 15(7):2698-2715. https://doi.org/10.3390/e15072698
Chicago/Turabian StyleAzmani, Monir, Serge Reboul, and Mohammed Benjelloun. 2013. "Non-Linear Fusion of Observations Provided by Two Sensors" Entropy 15, no. 7: 2698-2715. https://doi.org/10.3390/e15072698
APA StyleAzmani, M., Reboul, S., & Benjelloun, M. (2013). Non-Linear Fusion of Observations Provided by Two Sensors. Entropy, 15(7), 2698-2715. https://doi.org/10.3390/e15072698