1. Introduction
In recent years, rapid development of electronic technology and the increasing level of global economic integration have fundamentally changed the crude oil markets, both in terms of market structure and market risk exposure. Higher levels of price fluctuations are witnessed in crude oil markets, accompanied by more competitive and risky environments, increasingly dominated by nonlinear multi scale dynamics. Besides, due to the unique characteristics of crude oil markets, such as high storage costs, etc., they exhibit unique features that deserve research attention during the modeling process.
With the volatile crude oil price movement observed in the market, the modeling and forecasting of daily crude oil price movement remains one of the most important and difficult research issues in the energy research field. It attracts significant research interests as its resolution is fundamentally important to some important theoretical issues such as the crude oil derivatives and the energy risk management.
Over the years, numerous approaches have been developed to incorporate nonlinearity, auto correlation and heteroscedasticity data features into the modeling process, aiming at improving the forecasting accuracy further. These models include structural and econometric models, artificial intelligence models, and ensemble models. Equilibrium models analyze the economic relationships among participants in crude oil market and derive analytic equations to model them. For example, Bekiros
et al. [
1] used the time-varying Vector Autoregressive (VAR) model to model the impact of the economic policy uncertainty on the oil price movement and found the improved forecasting performance compared to other more standard univariate models [
1]. Deng and Sakurai [
2] used the multiple kernel learning regression method to forecast the crude oil spot price. They found that information from different time frame is useful in improving the forecasting accuracy of the model [
2]. Chen [
3] found the oil sensitive stock index to be significant predictors for the oil price movement [
3]. Cuaresma
et al. [
4] derived a simple unobserved component model incorporating asymmetric cycles and found it to be superior in performance than the symmetric counterparts and benchmark Auregressive (AR) models [
4]. Interestingly Alquist and Kilian [
5] showed contradictory results: they found Random Walk (RW) model to be by far the best models available [
5]. Meanwhile artificial intelligence models such as the traditional neural network and the more recent support vector regression have achieved significant progress. Empirical work utilizing the power of these models is on the rise, but with mixed results. For example, Godarzi
et al. [
6] found that the proposed dynamic Artificial Neural Network model achieves the improved forecasting accuracy than the time series and static neural network model [
6]. Yu
et al. [
7] found that Artificial Neural Network (ANN) outperforms Autoregressive Moving Average (ARMA) model, but has room for further improvement using ensemble algorithms. Shin
et al. [
8] proposed a semi-supervised learning method to predict the directional movement of oil price. They have found the improved accuracy with the proposed method [
8]. Work by Bildirici and Ersin [
9] show that the multilayer perception type neural network contributes significantly the performance improvement in the proposed model [
9]. Ensemble algorithm aims at combining individual forecasters to produce forecasts which are based on more complete information [
10]. Since the seminal work by Bates and Granger [
10], ensemble forecasts from different models to further reduce forecasting errors have attracted much research attention [
10]. For example, Yu
et al. [
7] proposed the adaptive neural network to ensemble individual forecasts using neural network to model components extracted by Empirical Mode Decomposition (EMD) and observed significant performance improvement [
7].
Recently, data driven computational approaches have emerges to take advantage of the nonlinear data characteristics during the modelling process. Typical nonlinear data features include chaotic, fractal and the multi scale data characteristics revealed by accumulating empirical evidence in the financial literature [
11]. For example, Alvarez-Ramirez
et al. [
12] revealed that the autocorrelation of the crude oil price is sensitive to the price asymmetry and different time scales, which are one form of embodiment of price nonlinearity [
12]. Barkoulas
et al. [
13] used the correlation dimensions test and recurrent plot to test the data generating mechanisms of the crude oil price. They found that the crude oil price contains non nomral nonlinar dynamics, which the current ARMA and Generalized Autoregressive Conditional Heteroskedasticity (GARCH) models provide insufficient modeling capability [
13]. It becomes increasingly clear that the incorporation of the nonlinear and complex dynamics during the modeling process provide the promising alternative to deeper understanding of the market dynamics and higher level of forecasting accuracy, especially when the modeling and forecasting exercises are conducted at the daily frequency level, higher than three weekly and monthly frequency in the literature. Rodriguez
et al. [
14] showed that the level of market efficiency varies across different time scales.
Wavelet analysis as a technique to extract and decompose the multiscale data structure emerged as an important and promising approach to analyze the nonlinear and complex data characteristics in the multiscale domain. There has been more and more empirical evidence of the existence of multi scale data feature in the crude oil price movement and its co-movement with other macroeconomic variables. For example, Shahbaz
et al. [
15] found the relationship between the crude oil price and real exchange rate to be anti-cyclical while work by Jammazi
et al. [
16] suggested that this relationship exists in a asymmetric manner over different time horizons [
15,
16]. Tiwari
et al. [
17] found some interesting economic relationship between share prices and crude oil price when it is viewed in the multiscale domain [
17]. In the meantime, we have found some positive results in wavelet based forecasting exercises for crude oil price movement. For example, He
et al. [
18] proposed a wavelet decomposed ensemble model, which introduces wavelet analysis to analyze the time varying dynamic underlying Data Generating Process, representative of heterogeneous market microstructure at finer time scale domain. Results from empirical studies show the superior performance of the proposed algorithm against the benchmark models [
18]. Jammazi and Aloui [
19] combined the A trous wavelet analysis and neural network in forecasting the crude oil price, and found the improved forecasting performance [
19]. de Souza e Silva
et al. [
20] used the wavelet analysis to remove the high frequency data components for the modeling and forecasting by Hidden Markov Model. Experiment results show positive performance improvement [
20]. Yousefi
et al. [
21] used wavelet analysis to decompose crude oil price and extended them directly to make forecasts [
21]. However, much more positive forecasting results are accumulating in other areas, most notably in the electricity field. For example, Zhang
et al. [
22] used wavelet analysis to extract different data components of interests, where nonlinear component is modeled by neutral network and volatility component is modeled by GARCH model [
22]. Kriechbaumer
et al. [
23] used an improved combined wavelet-autoregressive integrated moving average (ARIMA) to forecast monthly price of aluminum, copper, lead and zinc, and found the improved forecasting accuracy [
23]. Gallegati
et al. [
24] used wavelet analysis to analyze the information content of some interest rate spread for future output growth [
24].
However, one research issue left intact in the literature is the impact of additional parameters introduced by wavelet analysis on modeling and forecasting accuracy. The wavelet based forecasting algorithm introduces the additional parameters including wavelet families and decomposition scales. Previous researches relied on the arbitrarily selected wavelet families to analyze the historical information, leaving their validity under question. When the wavelet analysis is introduced in the economic and financial field, the ultimate aim is to achieve better understanding of the economic and financial relationship among variables, with the improved forecasting accuracy in the end. The determination of these parameters will critically affect the modeling accuracy and the derived policy implications. The wavelet analysis decomposes the data into the multiscale structure which is assumed to represent the true underlying multiscale data structure. Wavelet analysis represents a redundant representation problem, i.e., there are different wavelet models that can replicate the same market price movement. The accuracy of these representations is limited by the constant governed by the uncertainty principle underlying the multi scale analysis. Therefore, there is no analytic solution to the identifications of the exact representations problem, which can be formulated as the optimization problem. This is a less addressed and important literature gap in the application of wavelet analysis in the forecasting field.
As an important information quantification measure, entropy serves as the potential tool to guide the optimization process. The entropy theory has been used to analyze the information content of the wavelet decomposed multiscale data structure in the other engineering literature. Wavelet entropy, relative wavelet entropy, and many other variants have been proposed in the literature to calculate the entropy of the energy distribution in the typical wavelet decomposition, as well as the cost function for the best basis algorithm to choose the optimal basis for wavelet packet transform [
25,
26]. For example, Pascoal and Monteiro [
27] and Kim
et al. [
28] used the entropy measure and the wavelet analysis to analyze the degree of market efficiency and the dynamic correlations in the market respectively [
27,
28]. Xu
et al. [
29] used the modified wavelet entropy measure to differentiate between the normal and hypertension states [
29]. Samui and Samantaray [
30] incorporated the wavelet entropy measure in constructing the measuring index for islanding detection in distributed generation [
30]. Wang
et al. [
31] used best basis based wavelet packet entropy to extract feature in the decomposed structure for the follow-up classification algorithm, which performs well in EEG analysis for patient classification [
31]. Recently we have identified some recent research endeavors in the financial literature to model the multiscal data structure using the multiscale entropy theory. For example, in the energy economics literature, Martina
et al. [
32] introduced the entropy concept to analyze the efficiency of the crude oil markets [
32]. Ortiz-Cruz
et al. [
33] introduced multiscale entropy theory to analyze the multiscale data structure in the crude oil market [
33]. In the stock market, Niu and Wang [
34] introduced a modified multiscale entorpy algorithm and showed its effectiveness in reducing the estimation error in Chinese stock markets [
34]. Yin and Shang [
35] introduced the weighted multiscale permutation entropy method to quantify the amplitude information of both US and Chinese stock markets, to analyze their difference and similarity [
35]. However, the research attempts are limited to this extent so far. In the literature very few research has been identified to explore and tackle various research issues in the modeling and forecasting of the multiscale crude oil data structure using the multiscale entropy framework. Different research issues such as the determination of the appropriate model specifications in the multiscale anlaysis affect the accuracy and generalizability of the multiscale analysis and forecasting models.
The wavelet denoising and multiscale sample projection serves as the valuable tools to reveal and model the hidden multiscale data structure in the multiscale domain. These constituent data structures correspond to various main influencing factors for the crude oil price movement, such as basic supply and demand for crude oil, the macroeconomic factors, and major events in the market.
In this paper, we are motivated by the fact that the market has a heterogeneous underlying structure, where investors have different investment concerns and strategies. During the modeling process some of the components are more important as the main driving forces while other components have less significant impacts and can be classified as the noises. The separation and modeling of these constituent data structure are critical to more accurate modeling and forecasting of the crude oil price movement. Thus, in this paper, we assume the crude oil price is dominated by one component at one scale. We introduce the wavelet entropy theory to identify it and use it as the main driving factors to forecast the future movement of the crude oil price.
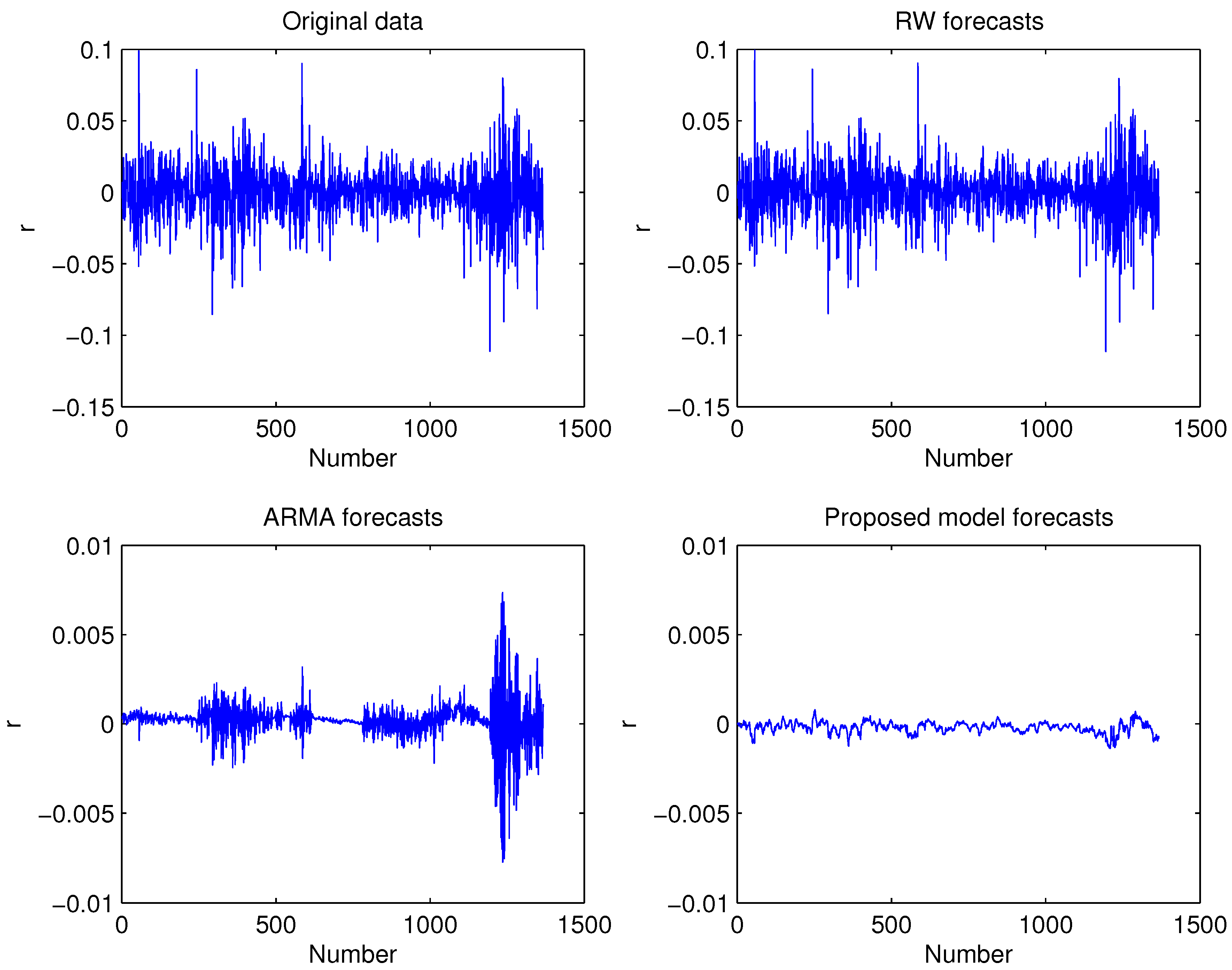
In this paper, we propose the wavelet entropy theory to identify the multiscale model structure and construct the effective forecasting algorithm. The wavelet entropy theory as well as entropy measure are introduced to measure the information energy distribution using the historical data and construct a two stage model selection procedure. Empirical studies in the benchmark crude oil markets confirm the statistically significant performance improvement from using the more appropriate multi scale model specification with the proposed wavelet entropy method.
The main contribution of this paper is the introduction of wavelet entropy based two stage model selection procedure to identify the appropriate model specification. This approach is built on the information theoretic approach other than the traditional MSE minimization. At the macro level, we use the wavelet entropy theory to measure the information energy distribution of the entire wavelet coefficients based on different wavelet families. At the micro level, the entropy is used to measure the information distribution of wavelet coefficients of wavelet decomposed data for different wavelet families at different scales. To the best of our knowledge, the work in this paper represents the first attempt to introduce wavelet entropy for the model specification identification for the construction of effective wavelet based forecasting algorithm.
The rest of this paper is organized as follows.
Section 2 proposes the wavelet entropy based approach for estimating VaR. We conducted empirical studies in the benchmark crude oil markets and reported the results in
Section 3. Finally, some concluding remarks are drawn in
Section 4.
2. Methodology
2.1. Entropy and Wavelet Entropy Theory
To measure quantitatively the randomness of data, the entropy can be defined statistically for a stochastic time series system. Given random variables
generated with unknown parameters, the entropy is defined as in Equation (
1) [
36].
where
refers to the probability density function (PDF). The value of entropy lies between 0 and 1. The higher the entropy is, the higher the level of disorder and uncertainty are.
If the data contain mixture of data features, the entropy may be biased in estimating the uncertainty and disorder levels in the data, potentially underestimating the randomness in data. The Wavelet Entropy offers an important alternative. It calculated the entropy value of the probability density function of the energy distribution of the wavelet coefficients in the wavelet transformed domain, as in (
2) [
37].
The smaller the wavelet entropy value is, the more organized the data are. The higher the wavelet entropy value is, the more disordered and uncertain the data are. However, different from the case of the entropy value, the wavelet entropy value size reflects not the total probability density of the data, but the average level of probability density of the data across different scales. For example, the significant cyclical information at smaller set of scales may be disputed by the noise information. The calculated entropy value may biased towards lower value, ignoring the frequency and cyclical data pretend at particular scales. The wavelet entropy value would take into account the structural distribution of randomness across scales and recognize the preserved of data at different scales.
2.2. Wavelet Entropy based Multiscale Forecasting Methodology
To model the crude oil price movement, we make some simplifying assumptions as follows:
- (1)
Data Generating Processes can be classified into several main groups with unique features and particular patterns, etc.
- (2)
Different Data Generating Processes are mutually independent across different scales.
- (3)
Different Data Generating Processes (DGPs) follow the same stochastic processes with different parameters.
With these assumptions, the data structure can be approximated with the combination and mixture of data generating processes at different scales. However, since there are different models of the underlying DGPs, for the observed market price movement, this represents an identification problem of the redundant representation during the modeling process. One approach is to resort to the traditional forecasting error as the criteria to identify the appropriate model specifications, which assumes that the small error corresponds to the maximum level of information or patterns extracted from the historical data. This was traditionally done using the error minimization, as evidenced in the recent researches.
Since the determination of the exact decomposition structure has the bounding limits governed by the uncertainty principle in the multi scale analysis, we would not expect the traditional approaches, such as the Minimization of MSE, to identify the optimal data structure among redundant representations. In practice, the optimal data structure may be the combinations of decomposition structure with different wavelet families at different scales.
Thus in this paper we resort to the wavelet entropy and the entropy theory in this paper. The entropy value, as the measurement of the disorder in data, is introduced to analyze the historical data at two levels, i.e., both microscope and macroscope. At the macro scale level, the wavelet entropy is used to measure the randomness of the data, taking into account the distribution of randomness across different scales. The measurement calculated with wavelet entropy would more accurately reflect the contribution of some orderly DGPs at some scales revealed in the particular wavelet families. When the wavelet entropy is calculated with different wavelet families at the same maximum scale, the wavelet family with the lowest wavelet entropy valued is retained as it implies the data with the most orderly organization. At the microscale level, the entropy of the individual coefficients at different scales is calculated and used to quantify the information content at different scales and compare their randomness directly. At each scale, the wavelet family with the lowest entropy value is retained as it is assume to contain the most orderly information and is the most suitable for ARMA modeling.
The numerical procedure for the wavelet entropy based forecasting algorithm is laid out as follows.
Firstly we use the wavelet algorithm to decompose the in-sample training data into different sub-data series at different scales up to the maximum scales
J, using different wavelet families.
Wavelet analysis possesses the ability to project data into time-scale domain and to conduct multiscale analysis [
38]. This capability stems from the high energy concentration over a short interval of time in wavelets functions used, which is in direct contrast to the globally time invariant sinusoid functions used in more traditional spectrum analysis tools such as Fourier analysis [
39]. Mathematically, wavelets are continuous functions that satisfy admissibility conditions as in Equation (
4).
And unit energy condition as in Equation (
5):
where Ψ is the Fourier transform of
ψ. Together these two conditions guarantee that the wavelets functions have zero vanishing moments and improved localization in time scale domain during the analysis.
There are different families of wavelets designed, each with their own special characteristics [
39]. The Haar wavelet is the simplest symmetric discontinuous wavelet that has characteristics of orthogonality and compact support. It is defined mathematically as in Equation (
6):
Daubechies wavelets are generalizable beyond the Haar wavelets. They are continuous orthogonal wavelets with compact support. Symlet wavelets are continuous orthogonal wavelets with compact support and are designed to be nearly symmetric. Coiflets are also designed to be nearly symmetric wavelets.
The wavelets can be translated over time and dilated by scales as in Equation (
7):
where
and
. Unlike sinusoids used in Fourier transform, wavelets are characterized by two parameters: location
u and scale
s. Thus, wavelets of different shapes and lengths are formed by adjusting these two parameters.
The original signal can be projected into time scale domain by means of convolving the translated or dilated wavelets to the original signal [
39]. Thus, the wavelet transform is a function of these two variables as in Equation (
8):
The inverse operation could also be performed as in Equation (
9):
Since the original signal can be decomposed by wavelet analysis and reconstructed perfectly by wavelet synthesis, together they form the basis for multi-resolution analysis as in Equation (
10):
where
refers to smooth signals and equals
.
refers to detail signals and equals
. The multi-resolution analysis decomposes the complicated data structure into the underlying influencing factors by applying wavelet analysis.
Secondly, we calculate the entropy of the coefficients at different scales with different families. We group them at different scales. For each scale, we select one wavelet family with the lowest entropy value. In the end, we determine wavelet family
for
n scale. The entropy is calculated as follows. For a stochastic time series system, given random variables
generated with unknown parameters, the shannon entropy is defined as in Equation (
11) [
36].
where
refers to the PDF. The value of entropy lies between 0 and 1. The higher the entropy value is, the higher the level of disorder and uncertainty is.
Thirdly we calculate the wavelet entropy for all the chosen wavelet families at the maximum scales J. Among them, we choose the one particular wavelet family at the scale , that has the minimum wavelet entropy value. The decomposed data component at the scale using the wavelet family are supposed to represent the main underlying DGP for the original crude oil data.
Fourthly the decomposed data component
is assumed to follow ARMA processes. We estimate the conditional means using the ARMA models.
Fifthly as the main underlying DGP of the crude oil dynamics, there is very strong correlation between the estimated DGP and the original crude oil data estimated. The variance of the decomposed data component is assumed to contribute to the total variance off the original data r. Thus we use the linear regression model to determine the intercept and coefficients with the model tuning data set.
Sixthly with the calculated parameters, we repeat step 1 to step 5 to calculate the forecasts.





{kind=link}
{kind=link}

