
Reproducibility Probability Estimation and RP-Testing for Some Nonparametric Tests

Abstract
:1. Introduction
2. RP-Estimation and Testing in the Nonparametric Framework
2.1. The General Nonparametric Framework
- (A)
- the exact and asymptotic distributions of are known both under and ;
- (B)
- the exact and asymptotic distributions of are known under . Under , only the asymptotic distribution can be derived.
2.2. Semi-Parametric RP-Estimation and RP-Testing
- under Case (A.1), the semi-parametric RP-estimator is ;
- under Case (A.2) and Case (B.2), the semi-parametric RP-estimator is ;
- under Case (B.1), the semi-parametric RP-estimator is .
- 1.
- the RP-based decision rule defined by exactly replicates the exact test ;
- 2.
- the RP-based decision rule defined by with any estimator for , exactly replicates the exact test .
2.3. Non-Parametric RP-Estimation and RP-Testing: The Non-Parametric Plug-In Approach
3. RP-Estimation and Testing for the Binomial and Sign Test
3.1. Semi-Parametric RP-Estimation and Testing for the Binomial Test
3.2. Non-Parametric RP-Estimation and Testing for the Binomial Test
- 1.
- ;
- 2.
- the support of is , , and.
- 3.
- the decision rule based on the RP-estimator exactly replicates the exact Binomial test .
- 1.
- ;
- 2.
- the support of is , , and.
- 3.
- the decision rule based on the RP-estimator exactly replicates the asymptotic Binomial test .
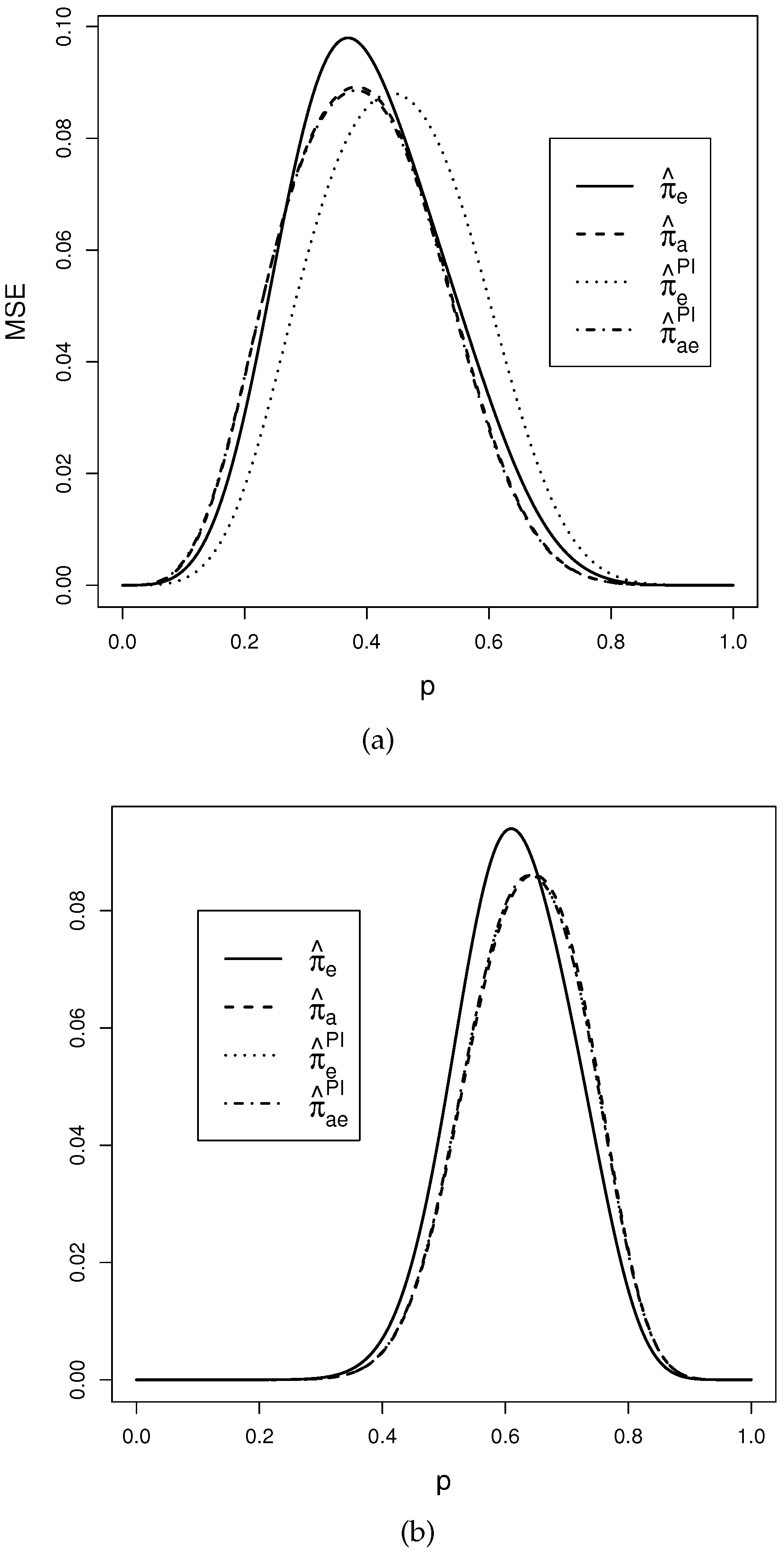
3.3. Evaluating the Performances of the RP-Estimators for the Binomial Test
4. RP-Estimation and Testing for the Wilcoxon Signed Rank Test
4.1. Semi-Parametric RP-Estimation and Testing for the WSR Test
- Analogic estimators:, ,
- Plug-in estimators. In order to introduce the plug-in estimators for p, and , let and be the cumulative distribution function and the density function of . By using this notation, it is easy to note that , , and . Let be the empirical distribution function of the ’s (i.e., of the ’s). By plugging into the above expressions, the following estimators are obtained:
- -
- RP-estimators for the exact test:and ;
- -
- RP-estimators for the asymptotic test:and .
4.2. Non-Parametric RP-Estimation and Testing for the WSR Test
4.3. Evaluating the Performances of the RP-Estimators for the WSR Test
5. RP-Estimation and Testing for the Kendall Test of Monotonic Association
5.1. Semi-Parametric RP-Estimation and Testing for the Kendall Test
- Analogic estimators: Remembering Expression (14), the analogic estimator for results: where.
- Plug-in estimators: In order to introduce these estimators, the following alternative expression for is useful: where .Now, let , and be the ecdfs of X, Y and , respectively. The plug-in estimators for results: where .
5.2. Non-Parametric RP-Estimation and Testing for the Kendall Test
5.3. Evaluating the Performances of the RP-Estimators for the Kendall Test
6. Example of Applications
7. Conclusions
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Goodman, S.N. A comment on replication, p-values and evidence. Stat. Med. 1992, 11, 875–879. [Google Scholar] [CrossRef] [PubMed]
- Chow, S.C.; Shao, J.; Wang, H. Sample Size Calculation in Clinical Research; Marcel Dekker: New York, NY, USA, 2003. [Google Scholar]
- De Martini, D. Stability Criteria for the Outcomes of Statistical Tests to Assess Drug Effectiveness with a Single Study. Pharm. Stat. 2012, 11, 273–279. [Google Scholar] [CrossRef] [PubMed]
- De Martini, D. Success Probability Estimation with Applications to Clinical Trials; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Hsieh, T.C.; Chow, S.C.; Yang, L.Y.; Chi, E. The evaluation of biosimilarity index based on reproducibility probability for assessing follow-on biologics. Stat. Med. 2013, 32, 406–414. [Google Scholar] [CrossRef] [PubMed]
- Shao, J.; Chow, S.C. Reproducibility Probability in Clinical Trials. Stat. Med. 2002, 21, 1727–1742. [Google Scholar] [CrossRef] [PubMed]
- De Capitani, L. An introduction to RP-testing. Epidemiol. Biostat. Public Health 2013, 10. [Google Scholar] [CrossRef]
- De Martini, D. Reproducibility Probability Estimation for Testing Statistical Hypotheses. Stat. Probab. Lett. 2008, 78, 1056–1061. [Google Scholar] [CrossRef]
- Berger, J. Could Fisher, Jeffreys and Neyman Have Agreed on Testing? Stat. Sci. 2003, 18, 1–12. [Google Scholar] [CrossRef]
- Berger, J.; Sellke, T. Testing a point null hypothesis: The irreconcilability of P-values and evidence. J. Am. Stat. Assoc. 1987, 82, 112–122. [Google Scholar] [CrossRef]
- Hubbard, R.; Bayarri, M.J. Confusion over measures of evidence (ps) versus errors (αs) in classical statistical testing. Am. Stat. 2003, 57, 171–178. [Google Scholar] [CrossRef]
- Hubbard, R.; Lindsay, R.M. Why p-values are not a useful measure of evidence in statistical significance testing. Theory Psychol. 2008, 18, 69–88. [Google Scholar] [CrossRef]
- Schervish, M.J. p-values: What they are and what they are not. Am. Stat. 1996, 50, 203–206. [Google Scholar] [CrossRef]
- De Capitani, L.; De Martini, D. On stochastic orderings of the Wilcoxon Rank Sum test statistic—with applications to reproducibility probability estimation testing. Stat. Probab. Lett. 2011, 81, 937–946. [Google Scholar] [CrossRef]
- De Capitani, L.; De Martini, D. Reproducibility probability estimation and testing for the Wilcoxon rank-sum test. J. Stat. Comput. Simul. 2015, 85, 468–493. [Google Scholar] [CrossRef]
- Van de Wiel, M.A.; Di Bucchianico, A.; van der Laan, A. Exact distributions of nonparametric test statistics and computer algebra. J. R. Stat. Soc. Series D 1999, 48, 507–551. [Google Scholar] [CrossRef]
- Efron, B.; Tibshirani, R.J. An Introduction to the Bootstrap; Chapman & Hall: New York, NY, USA, 1993. [Google Scholar]
- De Martini, D. Conservative Sample Size Estimation in Nonparametrics. J. Biopharm. Stat. 2011, 21, 24–41. [Google Scholar] [CrossRef] [PubMed]
- Lehmann, E.L. Nonparametrics: Statistical Methods Based on Ranks; Chapman & Hall: New York, NY, USA, 1998. [Google Scholar]
- Noether, G.E. Sample size determination for some common non-parametric tests. J. Am. Stat. Assoc. 1987, 82, 645–647. [Google Scholar] [CrossRef]
- Kaarsemaker, L.; van Wijngaarden, A. Tables for use in rank correlation. Stat. Neerlandica 1953, 7, 41–54. [Google Scholar] [CrossRef]
- Gibbons, J.D.; Chakraborti, S. Nonparametric Statistical Inference; Dekker: New York, NY, USA, 2003. [Google Scholar]
- The R Project for Statistical Computing. Available online: http://www.R-project.org/ (accessed on 8 April 2016).
- Wheeler, B. SuppDists: Supplementary Distributions. Available online: http://CRAN.R-project.org/package=SuppDists (accessed on 8 April 2016).
- Best, D.J.; Gipps, P.G. Algorithm AS 71: The Upper Tail Probabilities of Kendall’s Tau. J. R. Stat. Soc. 1974, 23, 98–100. [Google Scholar] [CrossRef]
- Hollander, M.; Wolfe, D.A. Nonparametric Statistical Methods, 2nd ed.; Wiley: Weinheim, Germany, 1999. [Google Scholar]
- De Capitani, L.; De Martini, D. Improving Reproducibility Probability estimation, preserving RP-testing. Available online: https://boa.unimib.it/handle/10281/105595 (accessed on 14 April 2016).
- Coolen, F.P.; Bin Himd, S. Nonparametric predictive inference for reproducibility of basic nonparametric tests. J. Stat. Theory Pract. 2014, 8, 591–618. [Google Scholar] [CrossRef]


{kind=link}
| Case (A) | Case (B) | |||
|---|---|---|---|---|
| Exact Test | Asymptotic Test | Exact Test | Asymptotic Test | |
| Computation of the | Possible | Possible | Not | Not |
| exact power | Case (A.1) | (not considered) | Possible | Possible |
| Computation of the | Possible | Possible | Possible | Possible |
| approximated power | (not considered) | Case (A.2) | Case (B.1) | Case (B.2) |
| RP-estimation and Testing for the Asymptotic WSR Test | ||||||||||||||
| RP-est. | MSE | D | MSE | D | MSE | D | MSE | D | MSE | D | ||||
| 0.0684 | 0.0286 | 0.0678 | 0.0073 | 0.0686 | 0.0045 | 0.0688 | 0.0018 | 0.0683 | 0.0012 | |||||
| 0.0664 | 0.0131 | 0.0669 | 0.0057 | 0.0682 | 0.0025 | 0.0686 | 0.0010 | 0.0682 | 0.0008 | |||||
| 0.0652 | 0.0000 | 0.0664 | 0.0000 | 0.0680 | 0.0000 | 0.0685 | 0.0000 | 0.0681 | 0.0000 | |||||
| 0.0636 | 0.0122 | 0.0656 | 0.0034 | 0.0676 | 0.0019 | 0.0683 | 0.0009 | 0.0680 | 0.0004 | |||||
| 0.0793 | 0.0000 | 0.0734 | 0.0000 | 0.0713 | 0.0000 | 0.0702 | 0.0000 | 0.0690 | 0.0000 | |||||
| 0.0735 | 0.0122 | 0.0702 | 0.0034 | 0.0697 | 0.0019 | 0.0693 | 0.0009 | 0.0685 | 0.0004 | |||||
| 0.0718 | 0.0180 | 0.0698 | 0.0142 | 0.0696 | 0.0136 | 0.0695 | 0.0133 | 0.0687 | 0.0129 | |||||
| 0.0717 | 0.0164 | 0.0696 | 0.0111 | 0.0694 | 0.0097 | 0.0693 | 0.0093 | 0.0686 | 0.0091 | |||||
| 0.0716 | 0.0156 | 0.0695 | 0.0091 | 0.0694 | 0.0072 | 0.0692 | 0.0068 | 0.0685 | 0.0065 | |||||
| RP-estimation and Testing for the Exact WSR Test | ||||||||||||||
| RP-est. | MSE | D | MSE | D | MSE | D | MSE | D | MSE | D | ||||
| 0.0677 | 0.0200 | 0.0678 | 0.0082 | 0.0686 | 0.0040 | 0.0688 | 0.0018 | 0.0683 | 0.0011 | |||||
| 0.0657 | 0.0045 | 0.0668 | 0.0033 | 0.0682 | 0.0020 | 0.0686 | 0.0010 | 0.0682 | 0.0006 | |||||
| 0.0647 | 0.0000 | 0.0664 | 0.0000 | 0.0680 | 0.0000 | 0.0685 | 0.0000 | 0.0681 | 0.0000 | |||||
| 0.0631 | 0.0066 | 0.0655 | 0.0036 | 0.0675 | 0.0018 | 0.0683 | 0.0009 | 0.0680 | 0.0005 | |||||
| 0.0797 | 0.0000 | 0.0734 | 0.0000 | 0.0713 | 0.0000 | 0.0702 | 0.0000 | 0.0690 | 0.0000 | |||||
| 0.0739 | 0.0066 | 0.0703 | 0.0036 | 0.0697 | 0.0018 | 0.0693 | 0.0009 | 0.0685 | 0.0005 | |||||
| 0.0722 | 0.0211 | 0.0698 | 0.0143 | 0.0696 | 0.0137 | 0.0695 | 0.0133 | 0.0687 | 0.0130 | |||||
| 0.0721 | 0.0200 | 0.0697 | 0.0113 | 0.0694 | 0.0099 | 0.0693 | 0.0093 | 0.0686 | 0.0092 | |||||
| 0.0720 | 0.0193 | 0.0696 | 0.0091 | 0.0694 | 0.0073 | 0.0692 | 0.0068 | 0.0685 | 0.0066 | |||||
| RP-estimation and Testing for the Asymptotic Kendall’s Test | |||||||||||
| RP-est. | MSE | D | MSE | D | MSE | D | MSE | D | |||
| 0.0759 | 0.0551 | 0.0751 | 0.0281 | 0.0752 | 0.0133 | 0.0748 | 0.0070 | ||||
| 0.0689 | 0.0000 | 0.0721 | 0.0000 | 0.0738 | 0.0000 | 0.0741 | 0.0000 | ||||
| 0.0778 | 0.0000 | 0.0735 | 0.0000 | 0.0709 | 0.0000 | 0.0693 | 0.0000 | ||||
| 0.0591 | 0.0000 | 0.0581 | 0.0000 | 0.0577 | 0.0000 | 0.0570 | 0.0000 | ||||
| 0.0881 | 0.0551 | 0.0765 | 0.0281 | 0.0720 | 0.0133 | 0.0697 | 0.0070 | ||||
| 0.0617 | 0.0551 | 0.0589 | 0.0281 | 0.0579 | 0.0133 | 0.0571 | 0.0070 | ||||
| 0.0736 | 0.0000 | 0.0741 | 0.0000 | 0.0747 | 0.0000 | 0.0745 | 0.0000 | ||||
| 0.0695 | 0.0769 | 0.0687 | 0.0595 | 0.0685 | 0.0448 | 0.0680 | 0.0329 | ||||
| 0.0694 | 0.0775 | 0.0685 | 0.0597 | 0.0683 | 0.0451 | 0.0679 | 0.0327 | ||||
| 0.0693 | 0.0779 | 0.0684 | 0.0596 | 0.0683 | 0.0455 | 0.0678 | 0.0329 | ||||
| RP-estimation and Testing for the Exact Kendall’s Test | |||||||||||
| RP-est. | MSE | D | MSE | D | MSE | D | MSE | D | |||
| 0.0906 | 0.1411 | 0.0847 | 0.1063 | 0.0829 | 0.0955 | 0.0819 | 0.0882 | ||||
| 0.0672 | 0.0000 | 0.0713 | 0.0000 | 0.0734 | 0.0000 | 0.0739 | 0.0000 | ||||
| 0.0780 | 0.0000 | 0.0738 | 0.0000 | 0.0711 | 0.0000 | 0.0693 | 0.0000 | ||||
| 0.0590 | 0.0000 | 0.0580 | 0.0000 | 0.0577 | 0.0000 | 0.0570 | 0.0000 | ||||
| 0.1064 | 0.1411 | 0.0876 | 0.1063 | 0.0803 | 0.0955 | 0.0769 | 0.0882 | ||||
| 0.0764 | 0.1411 | 0.0680 | 0.1063 | 0.0651 | 0.0955 | 0.0634 | 0.0882 | ||||
| 0.0732 | 0.0000 | 0.0739 | 0.0000 | 0.0746 | 0.0000 | 0.0745 | 0.0000 | ||||
| 0.0738 | 0.0781 | 0.0715 | 0.0601 | 0.0707 | 0.0457 | 0.0696 | 0.0324 | ||||
| 0.0737 | 0.0784 | 0.0714 | 0.0604 | 0.0706 | 0.0461 | 0.0695 | 0.0326 | ||||
| 0.0736 | 0.0791 | 0.0713 | 0.0607 | 0.0705 | 0.0463 | 0.0694 | 0.0323 | ||||
| 1.83 | 0.878 |
| 0.50 | 0.647 |
| 1.62 | 0.598 |
| 2.48 | 2.050 |
| 1.68 | 1.060 |
| 1.88 | 1.290 |
| 1.55 | 1.060 |
| 3.06 | 3.140 |
| 1.30 | 1.290 |
| Sign Test | ||||
| standard results | α | |||
| 0.1 | 6 | 0.7905 | 0.6781 | |
| 0.05 | 7 | 0.5 | 0.3719 | |
| 0.01 | 8 | 0.1683 | 0.1042 | |
| WSR Test | ||||
| standard results | α | |||
| 0.1 | 34 | 0.7614 | 0.8835 | |
| 0.05 | 36 | 0.6822 | 0.7435 | |
| 0.01 | 41 | 0.4528 | 0.4505 | |
| Kendall Test | ||||
| standard results | α | |||
| 0.1 | 0.3333 | 0.6979 | 0.6930 | |
| 0.05 | 0.4444 | 0.5685 | 0.5495 | |
| 0.01 | 0.6111 | 0.3648 | 0.2615 | |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
De Capitani, L.; De Martini, D. Reproducibility Probability Estimation and RP-Testing for Some Nonparametric Tests. Entropy 2016, 18, 142. https://doi.org/10.3390/e18040142
De Capitani L, De Martini D. Reproducibility Probability Estimation and RP-Testing for Some Nonparametric Tests. Entropy. 2016; 18(4):142. https://doi.org/10.3390/e18040142
Chicago/Turabian StyleDe Capitani, Lucio, and Daniele De Martini. 2016. "Reproducibility Probability Estimation and RP-Testing for Some Nonparametric Tests" Entropy 18, no. 4: 142. https://doi.org/10.3390/e18040142
APA StyleDe Capitani, L., & De Martini, D. (2016). Reproducibility Probability Estimation and RP-Testing for Some Nonparametric Tests. Entropy, 18(4), 142. https://doi.org/10.3390/e18040142