
A Quantum Query Expansion Approach for Session Search †


Abstract
:1. Introduction
2. Related Work
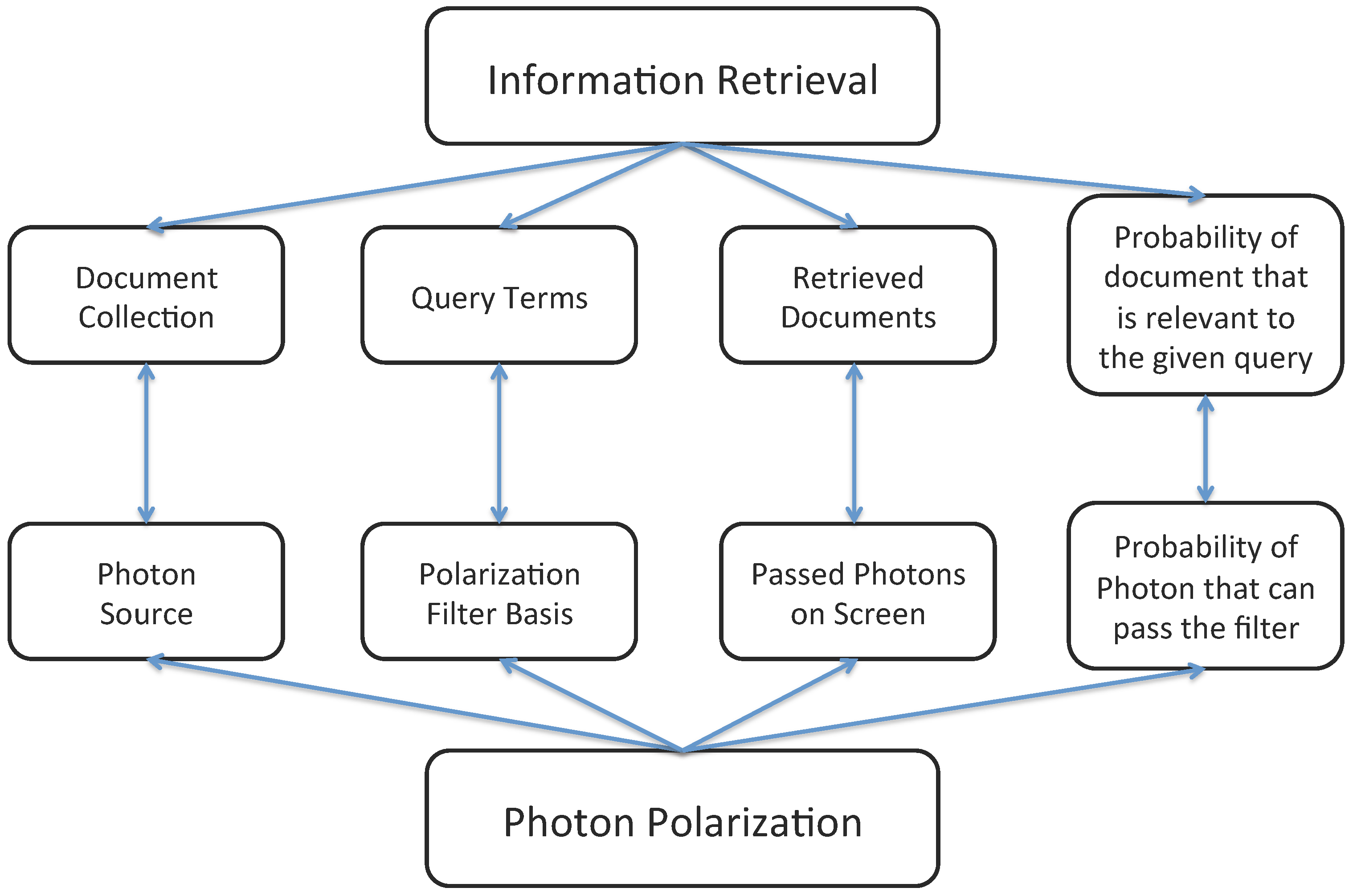
3. Background on Photon Polarization with Its Analogy in IR
3.1. Analogy of Photon Polarization in Document Ranking
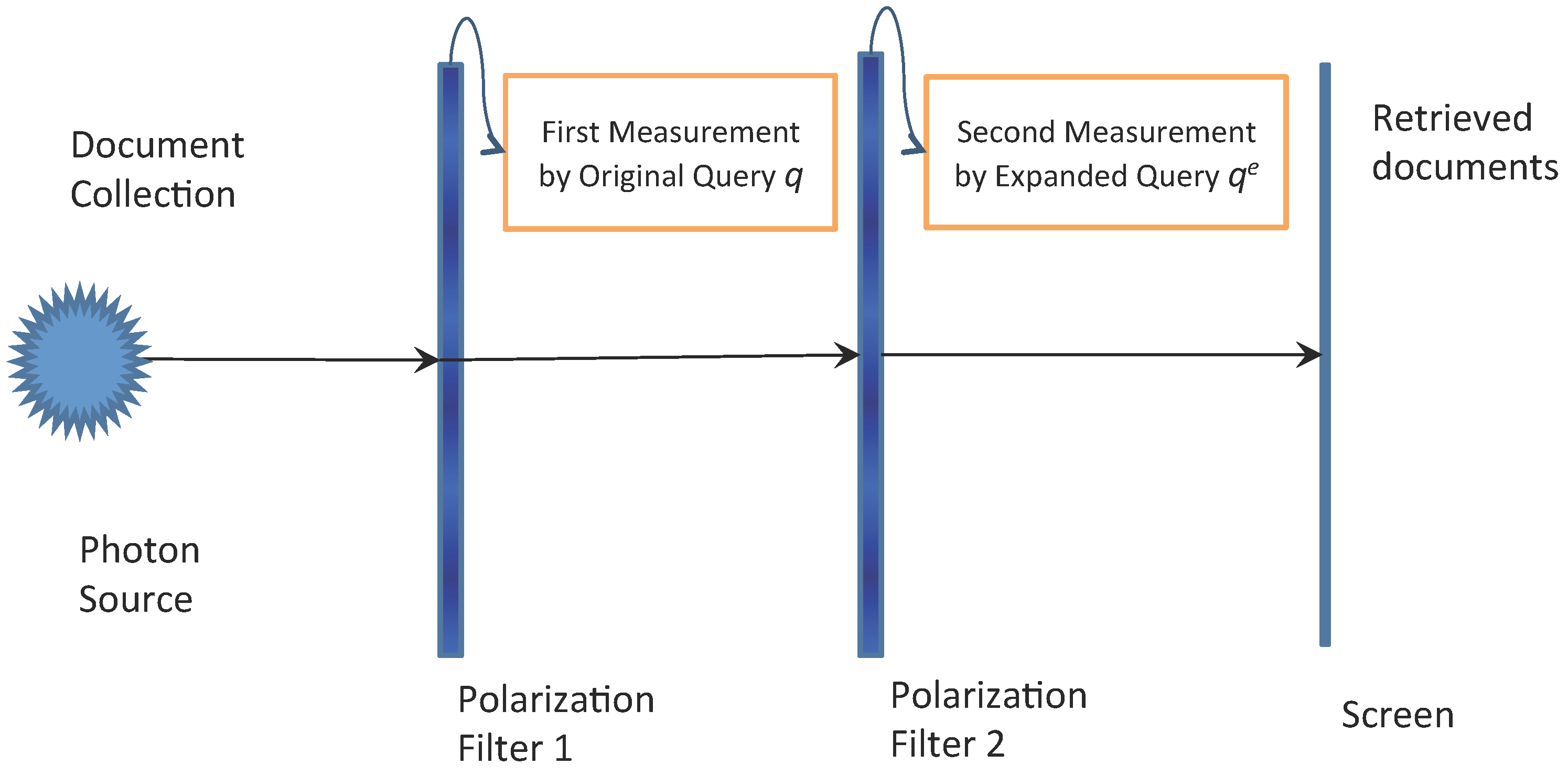
3.2. Analogy of Photon Polarization in Query Expansion
4. An Advanced Quantum-Inspired Query Expansion Approach
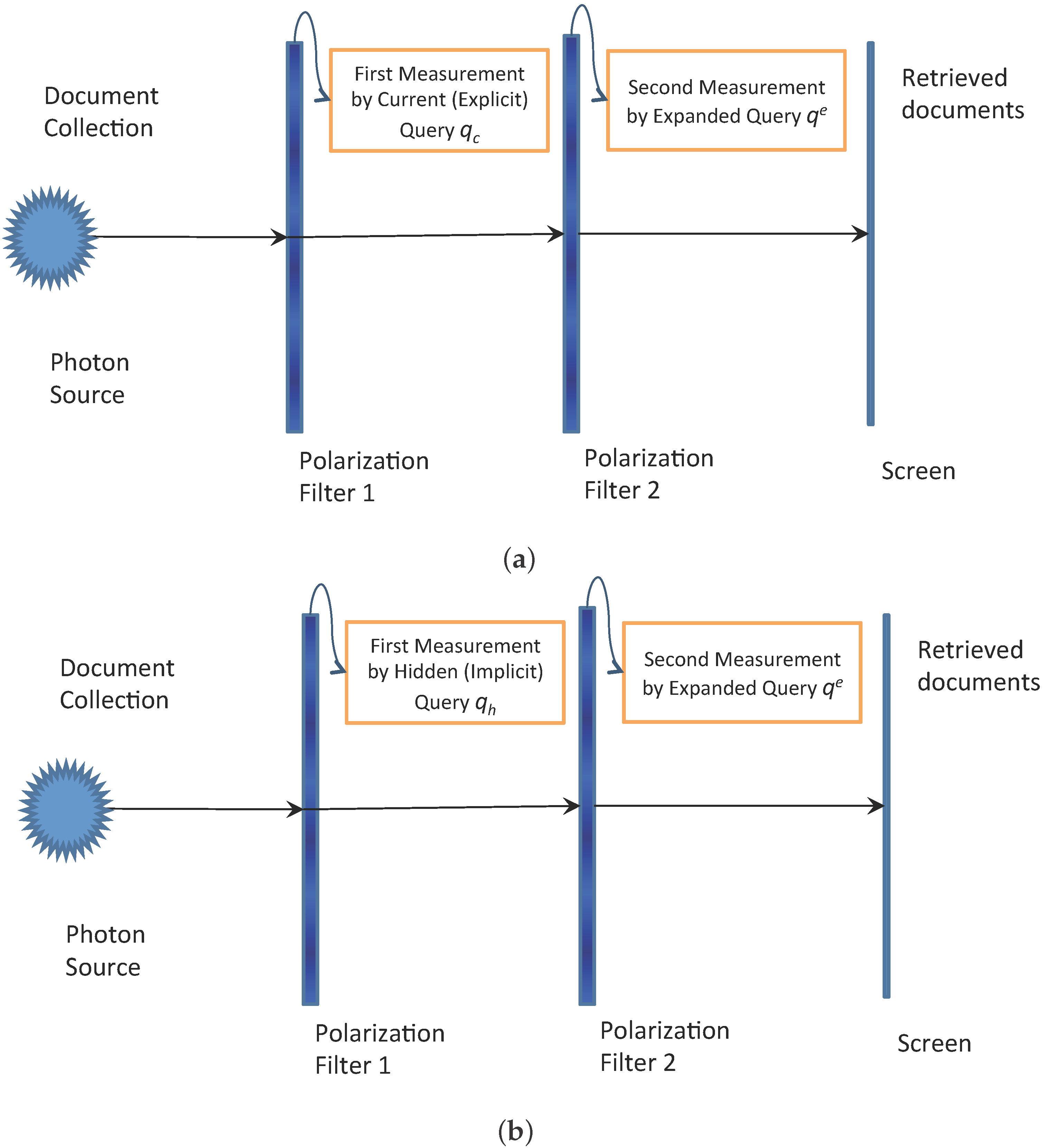
4.1. Limitations of Quantum Fusion Model
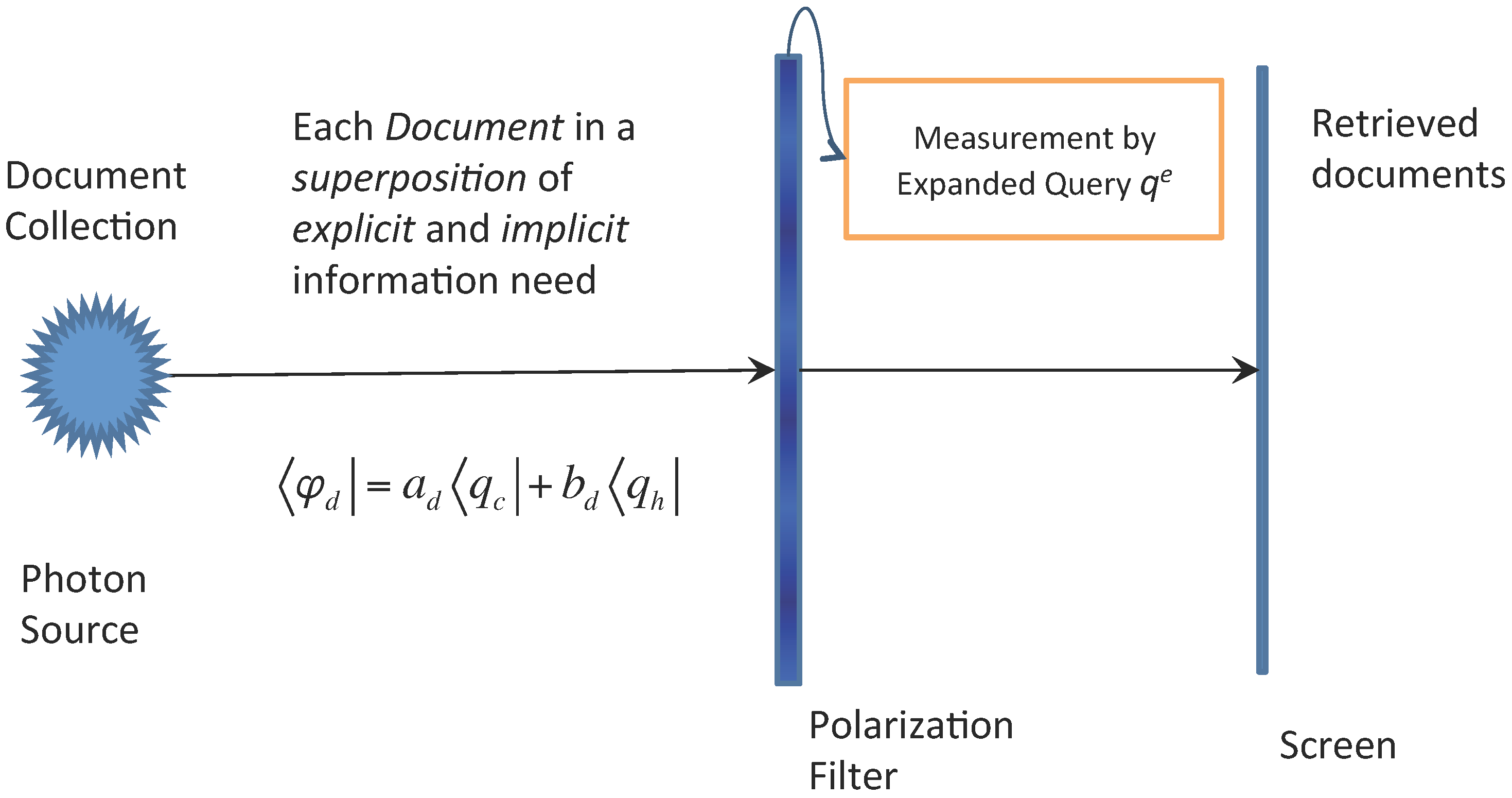
4.2. A Superposition State of the Document in Information Need Space
4.3. A Quantum Interference Inspired Query Expansion Approach
5. Empirical Evaluation
5.1. Data Set
5.2. Experimental Set-Up
5.2.1. Descriptions for Tested Models
- -CH, using Cosine similarity to estimate and , and Historical queries as hidden queries.
- -CS, using Cosine similarity to estimate and , and historical queries and clicked Snippets as hidden queries.
- -PH, tuning Parameters (), and using Historical queries as hidden queries.
- -PS, tuning Parameters (), and using historical queries and clicked Snippets as hidden queries.
5.2.2. Evaluation Metrics
5.2.3. Parameter Settings
5.3. Evaluation Results
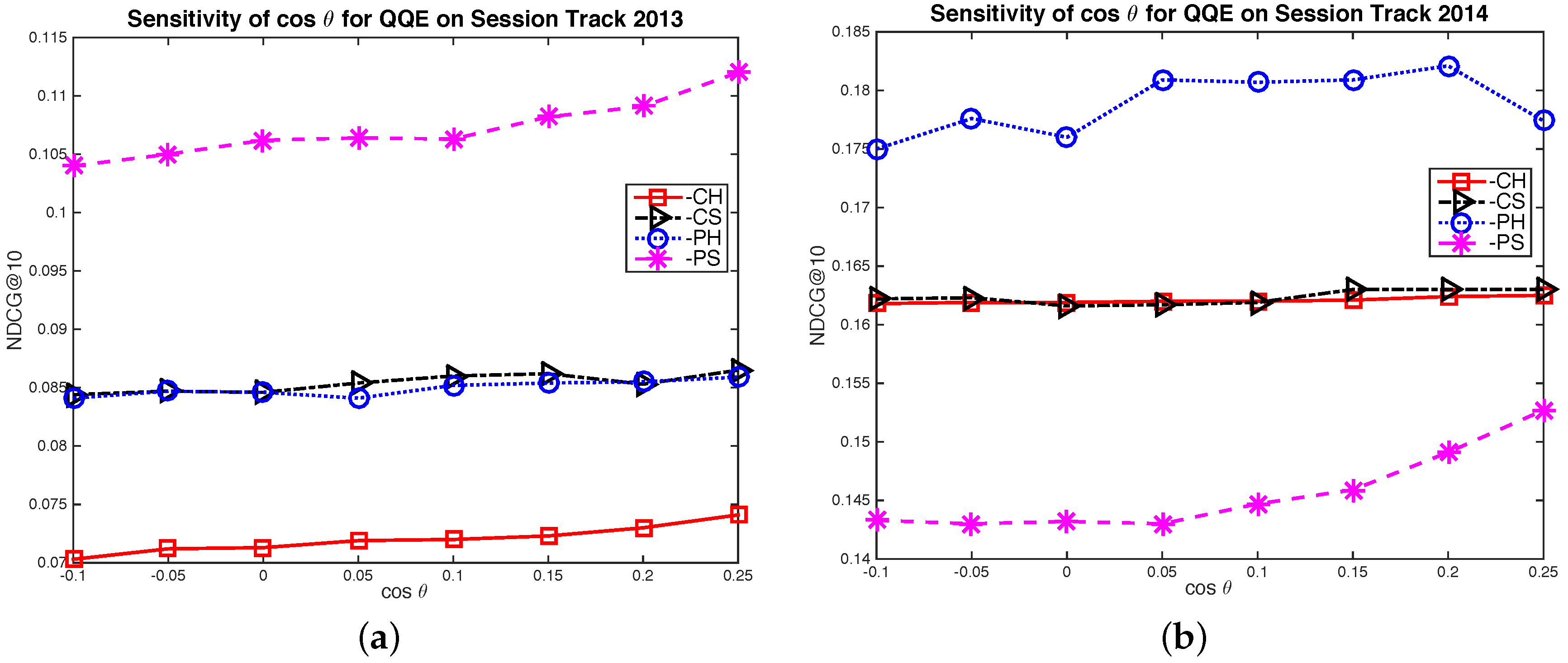
5.4. Study on the Quantum Interference Term
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A
Appendix A.1. Derivation of Quantum Fusion Approach
Appendix A.2. Re-Formulation of Quantum Fusion Model’s Solution in Inner-Product Forms
References
- Van Rijsbergen, C.J. The Geometry of Information Retrieval; Cambridge University Press: New York, NY, USA, 2004. [Google Scholar]
- Piwowarski, B.; Frommholz, I.; Lalmas, M.; van Rijsbergen, C.J. What can Quantum Theory Bring to Information Retrieval. In Proceedings of the CIKM 2010, Toronto, ON, Canada, 26–30 October 2010; pp. 59–68.
- Zhao, X.; Zhang, P.; Song, D.; Hou, Y. A Novel Re-ranking Approach Inspired by Quantum Measurement. In Proceedings of the ECIR 2011, Dublin, Ireland, 18–21 April 2011; pp. 721–724.
- Sordoni, A.; Nie, J.Y.; Bengio, Y. Modeling term dependencies with quantum language models for IR. In Proceedings of the SIGIR 2013, Dublin, Ireland, 28 July–1August 2013; pp. 653–662.
- Melucci, M. A basis for information retrieval in context. ACM Trans. Inf. Syst. 2008, 26. [Google Scholar] [CrossRef]
- Zuccon, G.; Azzopardi, L. Using the Quantum Probability Ranking Principle to Rank Interdependent Documents. In Proceedings of the ECIR 2010, Milton Keynes, UK, 28–31 March 2010; pp. 357–369.
- Zhang, P.; Song, D.; Zhao, X.; Hou, Y. Investigating Query-Drift Problem from a Novel Perspective of Photon Polarization. In Proceedings of the ICTIR 2011, Bertinoro, Italy, 12–14 September 2011; pp. 332–336.
- Rieffel, E.G.; Polak, W. An introduction to quantum computing for non-physicists. ACM Comput. Surveys 2000, 32, 300–335. [Google Scholar] [CrossRef]
- Feynman, R.; Leighton, R.; Sands, M. The Feynman Lectures on Physics: Quantum Mechanics; Addison-Wesley: Boston, MA, USA, 1965. [Google Scholar]
- Monroe, C.; Meekhof, D.M.; King, B.E.; Wineland, D.J. A “Schrödinger Cat” Superposition State of an Atom. Science 1996, 272, 1131–1136. [Google Scholar] [CrossRef] [PubMed]
- Text REtrieval Conference. Available online: http://trec.nist.gov/ (accessed on 12 April 2016).
- Clueweb12. Available online: http://lemurproject.org/clueweb12/ (accessed on 12 April 2016).
- Gleason, A.M. Measures on the closed subspaces of a Hilbert space. J. Math. Mech. 1957, 6, 885–893. [Google Scholar] [CrossRef]
- Song, D.; Lalmas, M.; van Rijsbergen, C.J.; Frommholz, I.; Piwowarski, B.; Wang, J.; Zhang, P.; Zuccon, G.; Bruza, P.D.; Arafat, S.; et al. How Quantum Theory is Developing the Field of Information Retrieval. In Proceedings of AAAI Fall Symposium 2010, Arlington, VA, USA, 11–13 November 2010; pp. 105–108.
- Melucci, M. Introduction to Information Retrieval and Quantum Mechanics; Springer: Berlin, Germany, 2015; Volume 35. [Google Scholar]
- Costa, A.; Buccio, E.D.; Melucci, M. A Document Retrieval Model Based on Digital Signal Filtering. ACM Trans. Inf. Syst. 2015, 34. [Google Scholar] [CrossRef]
- Busemeyer, J.R.; Wang, Z.; Lambert-Mogiliansky, A. Empirical comparison of Markov and quantum models of decision making. J. Math. Psychol. 2009, 53, 423–433. [Google Scholar] [CrossRef]
- Busemeyer, J.; Bruza, P.D. Quantum Models of Cognition and Decision; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Bruza, P.D.; Wang, Z.; Busemeyer, J.R. Quantum cognition: A new theoretical approach to psychology. Trends Cognit. Sci. 2015, 19, 383–393. [Google Scholar] [CrossRef] [PubMed]
- Khrennivov, A. Classical and quantum mechanics on information spaces with applications to cognitive, psychological, social, and anomalous phenomena. Found. Phys. 1999, 29, 1065–1098. [Google Scholar] [CrossRef]
- Khrennikov, A. On quantum-like probabilistic structure of mental information. Open Syst. Inf. Dyn. 2004, 11, 267–275. [Google Scholar] [CrossRef]
- Khrennikov, A.Y. Information Dynamics in Cognitive, Psychological, Social, and Anomalous Phenomena; Springer: Dordrecht, The Netherlands, 2013; Volume 138. [Google Scholar]
- Khrennikov, A.Y. Ubiquitous Quantum Structure; Springer: Berlin, Germany, 2014. [Google Scholar]
- Haven, E.; Khrennikov, A. Quantum Social Science; Cambridge University Press: Cambridge, UK, 2013. [Google Scholar]
- Conte, E.; Khrennikov, A.; Todarello, O.; Federici, A.; Zbilut, J.P. On the Existence of Quantum Wave Function and Quantum Interference Effects in Mental States: An Experimental Confirmation during Perception and Cognition in Humans. 2008; arXiv:0807.4547. [Google Scholar]
- Conte, E. On the Possibility that we think in a Quantum Probabilistic Manner. NeuroQuantology 2010, 8, S3–S47. [Google Scholar] [CrossRef]
- Zhang, P.; Song, D.; Hou, Y.; Wang, J.; Bruza, P. Automata Modeling for Cognitive Interference in Users’ Relevance Judgment. In Proceedings of the AAAI-QI 2010, Washington, DC, USA, 11–13 November 2010; pp. 125–133.
- Guan, D.; Zhang, S.; Yang, H. Utilizing query change for session search. In Proceedings of the SIGIR 2013, Dublin, Ireland, 28 July–1 August 2013; pp. 453–462.
- Zhang, S.; Guan, D.; Yang, H. Query change as relevance feedback in session search. In Proceedings of the SIGIR 2013, Dublin, Ireland, 28 July–1 August 2013; pp. 821–824.
- Luo, J.; Zhang, S.; Yang, H. Win-win search: Dual-agent stochastic game in session search. In Proceedings of the SIGIR 2014, Gold Coast, Australia, 6–11 July 2014; pp. 587–596.
- Zhang, S.; Luo, J.; Yang, H. A POMDP model for content-free document re-ranking. In Proceedings of the SIGIR 2014, Gold Coast, Australia, 6–11 July 2014; pp. 1139–1142.
- Lavrenko, V.; Croft, W.B. Relevance-Based Language Models. In Proceedings of the SIGIR 2001, New Orleans, LA, USA, 9–12 September 2001; pp. 120–127.
- Zighelnic, L.; Kurland, O. Query-drift prevention for robust query expansion. In Proceedings of the SIGIR 2008, Singapore, Singapore, 20–24 July 2008; pp. 825–826.
- Zhang, P.; Song, D.; Wang, J.; Zhao, X.; Hou, Y. On modeling rank-independent risk in estimating probability of relevance. In Proceedings of the AIRS 2011, Dubai, United Arab Emirates, 18–20 December 2011; pp. 13–24.
- Sordoni, A.; Nie, J.Y. Looking at Vector Space and Language Models for IR Using Density Matrices. In Proceedings of the Quantum Interaction 2014, Leicester, UK, 25–27 July 2013; pp. 147–159.
- Indri toolkit. Available online: http://sourceforge.net/p/lemur/wiki/Indri/ (accessed on 12 April 2016).
- Zhai, C.; Lafferty, J.D. Model-based Feedback in the Language Modeling Approach to Information Retrieval. In Proceedings of the CIKM 2001, McLean, VA, USA, 6–11 November 2000; pp. 403–410.
- Burges, C.; Shaked, T.; Renshaw, E.; Lazier, A.; Deeds, M.; Hamilton, N.; Hullender, G. Learning to Rank Using Gradient Descent. In Proceedings of ICML 2005, New York, NY, USA; 2005; pp. 89–96. [Google Scholar]
- Chapelle, O.; Metlzer, D.; Zhang, Y.; Grinspan, P. Expected reciprocal rank for graded relevance. In Proceedings of the CIKM 2009, Hong Kong, China, 2–6 November 2009; pp. 621–630.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Rank Score for Each Document d |
|---|---|
| LM | |
| RM | |
| RM-HS | |
| combMNZ | |
| interpolation | |
| QFM1 | |
| QFM2 | |
| QQE |
| Model | Parameters for TREC 2013 | Parameters for TREC 2014 |
|---|---|---|
| LM | - | - |
| RM | , | , |
| RM-HS | , | , |
| combMNZ | - | - |
| interpolation | ||
| QFM1 | - | - |
| QFM2 | ||
| QQE-CH | ||
| QQE-CS | ||
| QQE-PH | , | , |
| QQE-PS | , | , |
| Models | NDCG@10 | NDCG@100 | ERR@10 | ERR@100 |
|---|---|---|---|---|
| LM | 0.0552(0.00%) | 0.0579(0.00%) | 0.0285(0.00%) | 0.0356(0.00%) |
| RM | 0.0366(-34.00%) | 0.0581(0.35%) | 0.0125(-56.00%) | 0.0190(-46.63%) |
| RM-HS | 0.0600(9.00%†) | 0.0592(2.25%) | 0.0280(-2.00%) | 0.0349(-1.97%) |
| combMNZ | 0.0514(-7.00%) | 0.0546(-5.70%) | 0.0263(-8.00%) | 0.0334(-6.18%) |
| Interpolation | 0.0497(-10.00%) | 0.0566(-2.25%) | 0.0250(-12.00%) | 0.0352(-1.12%) |
| QFM1 | 0.0506(-8.00%) | 0.0534(-7.77%) | 0.0254(-11.00%) | 0.0325(-8.71%) |
| QFM2 | 0.0523(-5.00%) | 0.0571(-1.38%) | 0.0275(-4.00%) | 0.0349(-1.97%) |
| QQE-CH | 0.0741(34.00% ‡) | 0.0695(20.03% ‡) | 0.0374(31.00% ‡) | 0.0453(27.25% ‡) |
| QQE-CS | 0.0921(67.00% ‡) | 0.0741(27.98% ‡) | 0.0564(98.00% ‡) | 0.0636(78.65% ‡) |
| QQE-PH | 0.0859(56.00% ‡) | 0.0875(51.12% ‡) | 0.0439(54.00% ‡) | 0.0515(44.66% ‡) |
| QQE-PS | 0.1120(103.00% ‡) | 0.0991(71.16% ‡) | 0.0689(142.00% ‡) | 0.0808(126.97% ‡) |
| Models | NDCG@10 | NDCG@100 | ERR@10 | ERR@100 |
|---|---|---|---|---|
| LM | 0.1445 (0.00%) | 0.1185(0.00%) | 0.0846 (0.00%) | 0.0951(0.00%) |
| RM | 0.1073 (-26.00%) | 0.1699(43.38%) | 0.0501 (-41.00%) | 0.0717(-24.61%) |
| RM-HS | 0.1393 (-4.00%) | 0.1105(-6.75%) | 0.0844 (0.00%) | 0.0946(-0.53%) |
| combMNZ | 0.1421 (-2.00%) | 0.1163(-1.86%) | 0.0821 (-3.00%) | 0.0928(-2.42%) |
| Interpolation | 0.1427 (-1.00%) | 0.1173(-1.01%) | 0.0826 (-2.00%) | 0.0934(-1.79%) |
| QFM1 | 0.1415 (-2.00%) | 0.1151(-2.87%) | 0.0804 (-5.00%) | 0.0914(-3.89%) |
| QFM2 | 0.1427 (-1.00%) | 0.1175(-0.84%) | 0.0830 (-2.00%) | 0.0937(-1.47%) |
| QQE-CH | 0.1625 (12.00%†) | 0.1292(9.03%†) | 0.0939 (11.00%†) | 0.1043(9.67%†) |
| QQE-CS | 0.1630 (13.00%†) | 0.1234(4.14%) | 0.0940 (11.00%†) | 0.1043(9.67%†) |
| QQE-PH | 0.1824 (26.00% ‡) | 0.1824(53.92% ‡) | 0.0972 (15.00%†) | 0.1105(16.19%†) |
| QQE-PS | 0.1527 (6.00%†) | 0.1516(27.93% ‡) | 0.0739 (-13.00%) | 0.0866(-8.94%) |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, P.; Li, J.; Wang, B.; Zhao, X.; Song, D.; Hou, Y.; Melucci, M. A Quantum Query Expansion Approach for Session Search. Entropy 2016, 18, 146. https://doi.org/10.3390/e18040146
Zhang P, Li J, Wang B, Zhao X, Song D, Hou Y, Melucci M. A Quantum Query Expansion Approach for Session Search. Entropy. 2016; 18(4):146. https://doi.org/10.3390/e18040146
Chicago/Turabian StyleZhang, Peng, Jingfei Li, Benyou Wang, Xiaozhao Zhao, Dawei Song, Yuexian Hou, and Massimo Melucci. 2016. "A Quantum Query Expansion Approach for Session Search" Entropy 18, no. 4: 146. https://doi.org/10.3390/e18040146
APA StyleZhang, P., Li, J., Wang, B., Zhao, X., Song, D., Hou, Y., & Melucci, M. (2016). A Quantum Query Expansion Approach for Session Search. Entropy, 18(4), 146. https://doi.org/10.3390/e18040146