1. Introduction
Product design is a complex and dynamic process, and its duration is affected by a number of factors, most of which are of fuzzy, random and uncertain characteristics. As product design tasks occur in different companies, uncertain characteristics may vary from product to product. The heteroscedasticity thus constitutes another important feature of product design. The mapping from the factors to design time is highly nonlinear, and it is impossible to describe this mapping relationship by definite mathematical models. The degree of reasonability of the supposed distribution of product design time is a key factor in product development control and decisions [
1,
2,
3].
The triangular probability distribution was chosen by Cho and Eppinger [
1] to represent design task durations, and a process modeling and analysis technique for managing complex design projects was proposed by using advanced simulation. However, if the assumed distribution of design activity durations does not reflect the true state, the proposed algorithm may fail to obtain ideal results. Yan and Wang [
2] proposed a time-computing model with its corresponding design activities in concurrent product development process. Yang and Zhang [
3] presented an evolution and sensitivity design-structure matrix to reflect overlapping and their impact on the degree of activity sensitivity and evolution in the process model, and the model can be used for better project planning and control by identifying overlapping and risk for process improvements, but with the two algorithms mentioned above, normal duration of each design activity should be determined before the algorithm is executed, and if activity durations are incompatible with the actual ones, the proposed algorithm may fail to function well. Apparently, the accuracy of predetermined design time is crucial to the planning and controlling of product development processes.
Traditionally, approximate design time is analyzed by means of qualitative approaches. With the rapid development of computer and regression techniques, new forecast methods keep emerging. Bashir and Thomson [
4] came up with a modified Norden model to estimate project duration in conjunction with the effort-estimation model. Griffin [
5] related the length of the product development cycle to project, process and team structure factors by a statistical method, and quantified the impact of project newness and complexity on the increasing length of development cycle, but with no proposal for design time forecasts. Jacome and Lapinskii [
6] developed a model to forecast electronic product design efforts based on a structure and process decomposition approach. Only a small portion of the time factors, however, are taken into account by the model. Xu and Yan [
7] proposed a design-time forecast model based on a fuzzy neural network, which exhibits good performance when the sample data are sufficient. However, only a small number of design cases are available to a company, which weakens the validity of the fuzzy neural network. Therefore, a novel approach should be adopted.
Recently, kernel methods have been identified as one of the leading means for pattern classification and function approximation, and successfully applied in various fields [
8,
9,
10,
11,
12,
13,
14]. Support vector machine (SVM), initially developed by Vapnik for pattern classification, is one of the most used models. With the introduction of the
ε-insensitive loss function, SVM has been extended in use to solve nonlinear regression problems, and thus is also called support vector regression (SVR).
ε-insensitive loss functions contribute to the sparseness property of SVR, but the value of
ε, chosen a priori, is hard to determine. A new parameter
v was then introduced and
v-SVR proposed, whereby
v controls the number of support vectors and training errors [
11].
v-SVR has overcome the difficulty of
ε determination. In recent years, much research has been done on kernel methods. Kivinen
et al. considered online learning in a reproducing kernel Hilbert space in [
15]. Liu
et al. [
16] proved that the kernel least-mean-square algorithm can be well posed in reproducing kernel Hilbert spaces without adding an extra regularization term to penalize solution norms as was suggested by [
15]. Chen
et al. developed a quantized kernel least mean square algorithm based on a simple online vector quantization method in [
17], and proposed the quantized kernel least squares regression in [
18]. Wu
et al. [
19] derived the kernel recursive maximum correntropy in kernel space and under the maximum correntropy. Furthermore, by combining fuzzy theory with
v-SVR, Yan and Xu [
20] proposed F
v-SVM to forecast the design time, which could be used to solve regression problems with uncertain input variables. However, both F
v-SVM and
v-SVR assume that the noise level is uniform throughout the domain, or at least, its functional dependency is known beforehand [
21]. It is thus clear that the time forecast of product design based on F
v-SVM is deficient simply due to the heteroscedasticity of product design. For better planning and controlling of product development process, any good forecast method is expected to yield not only highly precise forecast values, but also valid forecast intervals.
In terms of Gaussian margin machines [
22], the weight vector of binary classifier maintains a Gaussian distribution, and what should be struck for is the least information distribution that classifieds training samples with a high probability. Gaussian margin machines provide the probability that a sample belongs to a certain class. The idea given by Gaussian margin machines is extend to the regression for the forecast of product design time. Shang and Yan [
23] proposed Gaussian margin regression (GMR) on the basis of combining Gaussian margin machines and kernel-based regression. However, GMR assumes that the forecast variances are same, which is inconsistent with the heteroscedasticity that exits in design time forecast. Like F
v-SVM, GMR also fails to provide valid forecast intervals. By combining Gaussian margin machine and extreme learning machine [
24,
25], a confidence-weighted extreme learning machine was proposed for regression problems of large samples [
26].
The present study adopts the kernel-based regression with Gaussian distribution weights (GDW-KR) by combining Gaussian margin machines with the kernel-based regression, aiming to solve problems of small samples and heteroscedastic noise in design time forecasting, providing both forecast values and intervals. Inheriting the merits of Gaussian margin machines, GDW-KR maintains a Gaussian distribution over weight vectors, seeking the least information distribution that will make each target be included in its corresponding confidence interval. The optimization problem of GDW-KR is simplified, and an approximate solution of the simplified problem is obtained by using the results of regularized kernel-based regression. On the basis of this model, a forecast method for product design time and its relevant parameter-determining algorithm are then put forward.
The rest of this paper is organized as follows: Gaussian margin machines are introduced in
Section 2. GDW-KR and the method for solving the optimization problem are described in
Section 3. In
Section 4, the application in injection mold design is presented, and GDW-KR is then compared with other models. An extended application of GDW-KR is also given.
Section 5 draws the final conclusions.
2. Gaussian Margin Machines
Suppose the samples
, where
is a column vector and
is a scalar output. The weight vector
of a linear classifier is supposed to follow a multivariable normal distribution
with mean
and covariance matrix
. For the sample
, we get the normal distribution:
The linear classifier is designed to properly classify each sample with a high probability, that is:
where
is the confidence value.
By combining Equations (1) and (2), we get:
GMM aims to seek the least informative distribution that classifies the training set with high probability, which is achieved by seeking a multivariable normal distribution
with minimum Kullback-Leibler divergence with respect to an isotropic distribution
. The Kullback-Leibler divergence between
and
is denoted by
(the subscript KL is the abbreviation of Kullback-Leibler and D is the abbreviation of divergence), and is obtained by calculating:
The optimization problem of GMM is described as:
After omitting the constant terms in the objective function and transforming the constraints of Equation (5), we get:
where
is the inverse cumulative distribution function of a standard normal distribution.
is further equal to
, where
denotes the inverse Gauss error function.
Theorem 1. The training samples are given, and a prior distribution over the weight vector is set. Then, for any and any posterior distribution , the following holds with the probability of at least where , is loss function, , , and is the distribution of [
22,
27].
5. Conclusions
The control and decision of product development are based on the reasonable degree of the distribution of product design time. In design time forecasting, the problems of small samples and heteroscedastic noise ought to be considered.
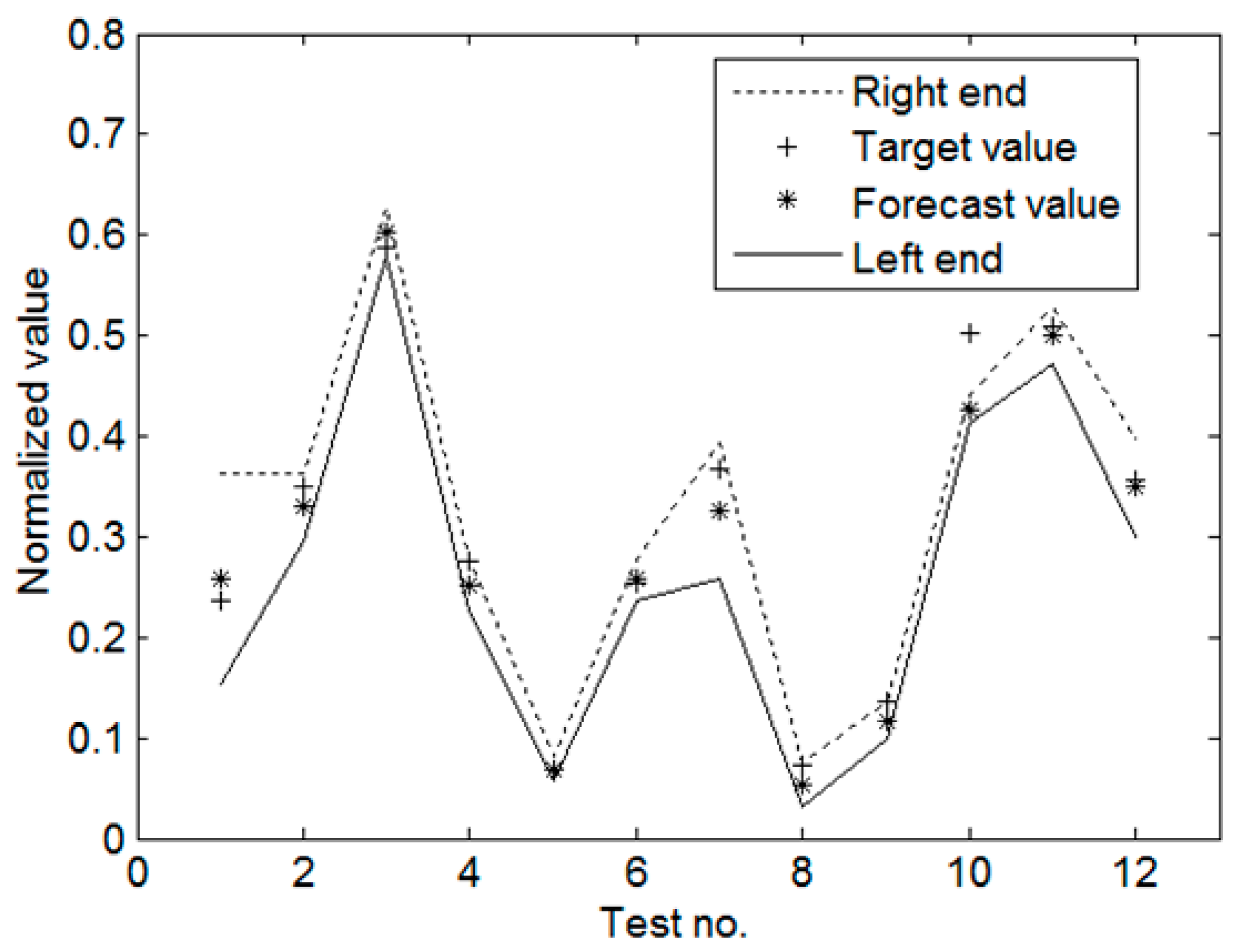
This paper has presented a new model of kernel-based regression with Gaussian distribution weights for product-design time forecasts, which combines Gaussian margin machines with kernel-based regression. The kernel method performs well for the problem of small samples. Unlike GMR, which assumes that the covariance matrix of the forecast values in the training set is an identity matrix multiplied by a positive scalar, GDW-KR assumes that this matrix is a positive definite diagonal matrix. GDW-KR is more suitable for addressing the problem of heteroscedastic noise than GMR, and has the advantage of providing both point forecasts and confidence intervals simultaneously.
The plastic injection mold was studied before modeling. For convincing evaluation, experiments with 72 real samples were conducted. Results from them have verified that GDW-KR promises not only as high forecast accuracy as Fv-SVM and v-SVR but forecast intervals crucial to the control and decision of product development. Undoubtedly, GDW-KR benefits from the merits of Gaussian margin machines.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}