
Information Theoretical Measures for Achieving Robust Learning Machines

Abstract
:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
2. Learning Machine Problem Definition
2.1. The Components of a Machine Learning Problem
- A source density function with support that needs to be characterized.
- A set of i.i.d. samples generated by . Sometimes, is completely available from the start, i.e., the n samples are readily available for processing. In other cases, the data are acquired incrementally, sample by sample, and data-related processing is performed accordingly.
- A family of density functions that serves as the learning machine. Each of these functions is indexed by the set of parameters , and the parameter vector . The parameter sets differ in that groups all of the parameters not related to metric spaces, i.e., discrete parameters, while groups those that are associated with metric distances, i.e., continuous parameters. As an example, imagine a learning machine that implements a mathematical function defined by a sum of one-dimensional Gaussians. In that case, the , with n the number of Gaussians, and , where , and define the mixing coefficients, means and standard deviations of the Gaussians correspondingly. In machine learning jargon: defines the architecture of the learning machine and those parameters that are adjusted by means of a learning process.
2.2. The Learning Machine Problem
- A physical implementation, which demands:
- (a)
- Available elements that are rich enough to allow the implementation of all possible mathematical functions. This is regarded in the literature as implementing a universal function approximator.
- (b)
- Dependence on existing elements, that is on given physical and economic constraints.
- Its internal organization mainly responds to the constraints imposed by the curse of dimensionality, which normally forces an incremental development:
- (a)
- Subsystems are built incrementally, where modules are added either in series (cascades), in parallel (as in boosting) or connected through feedback.
- (b)
- The entire system needs to be robust to changes in and , i.e., changes in either the product of an inexact fabrication process, or failure while operating, or simply parameter noise when operating, etc.
- The operation of a learning machine, which has two main aspects:
- (a)
- Its behavior has a two-fold component. One is external and reflects those actions that make the learning machine behave in a way that complies with Equation (1) and its implications, and another that reflects its inner changes in adaptation, also known as the learning process. Even though the current literature normally divides the two types of behavior into two different stages (first train, then use), nothing stops a general learning machine from producing both types of behavior at the same time.
- (b)
- Use with maximum efficiency the spatio-temporal resources upon which the machine is built.
- The behavior of the learning machine is such that:
- (a)
- It hopefully duplicates the source such that:throughout the support .
- (b)
- It is robust to:
- (i)
- Novel changes in the external signals in case they exist. These external changes can be explained by new, unseen data not present in the dataset . When a learning machine is robust in this sense, it is said that it has generalized.
- (ii)
- Noise in the external, if they exist, or internal signals.
3. Robust Information Theoretical Learning
3.1. Basic Information Theoretical Definitions
3.2. The Kullback–Leibler Divergence Is Useful
3.3. Suitable Estimators
3.4. Using Relative Fisher Information to Find a Robust Machine
3.5. Empirical Measurements
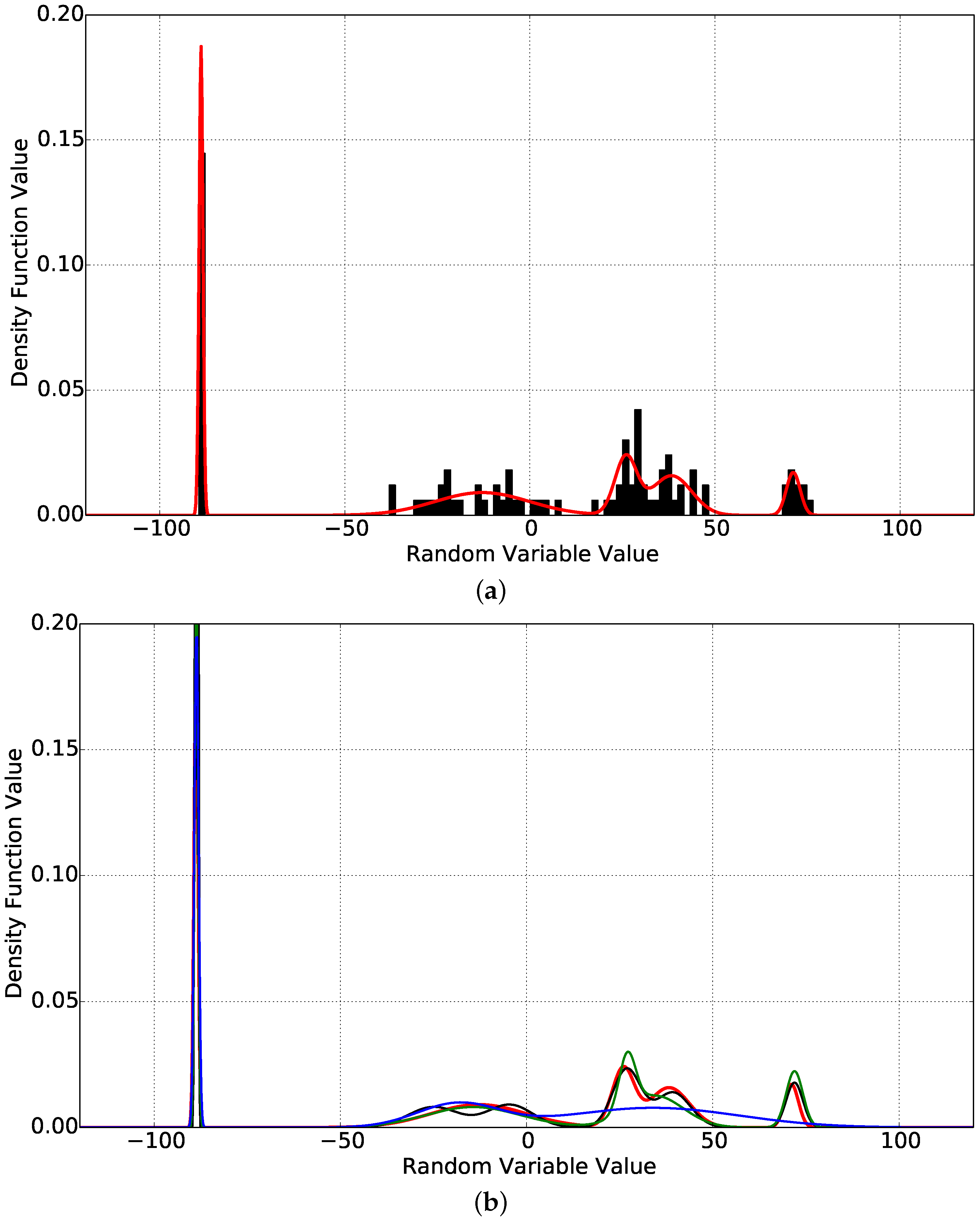
4. A Toy Example
- All density functions can be approximated by a GMM density function up to any desired error level [22]. Thus, all source density functions can be thought of as GMMs.
- What really sets apart the source density function and the learning machine one is that there is no prior knowledge of the correct number of terms . Without this piece of knowledge, it is perfectly possible to end in cases such as , thus crippling the capacity of the estimator, or , which gives space for over fitting and the production of spurious behavior.
- Taking these considerations into account, the experiments that follow are designed to show what happens in the improbable case where and in the more probable case where . The case is a low probability one because it is normally almost impossible to guess this value from the data. Nevertheless, taking advantage of all of the knowledge that is available in this case, the experiment is done to set up a benchmark against which all others can be compared.
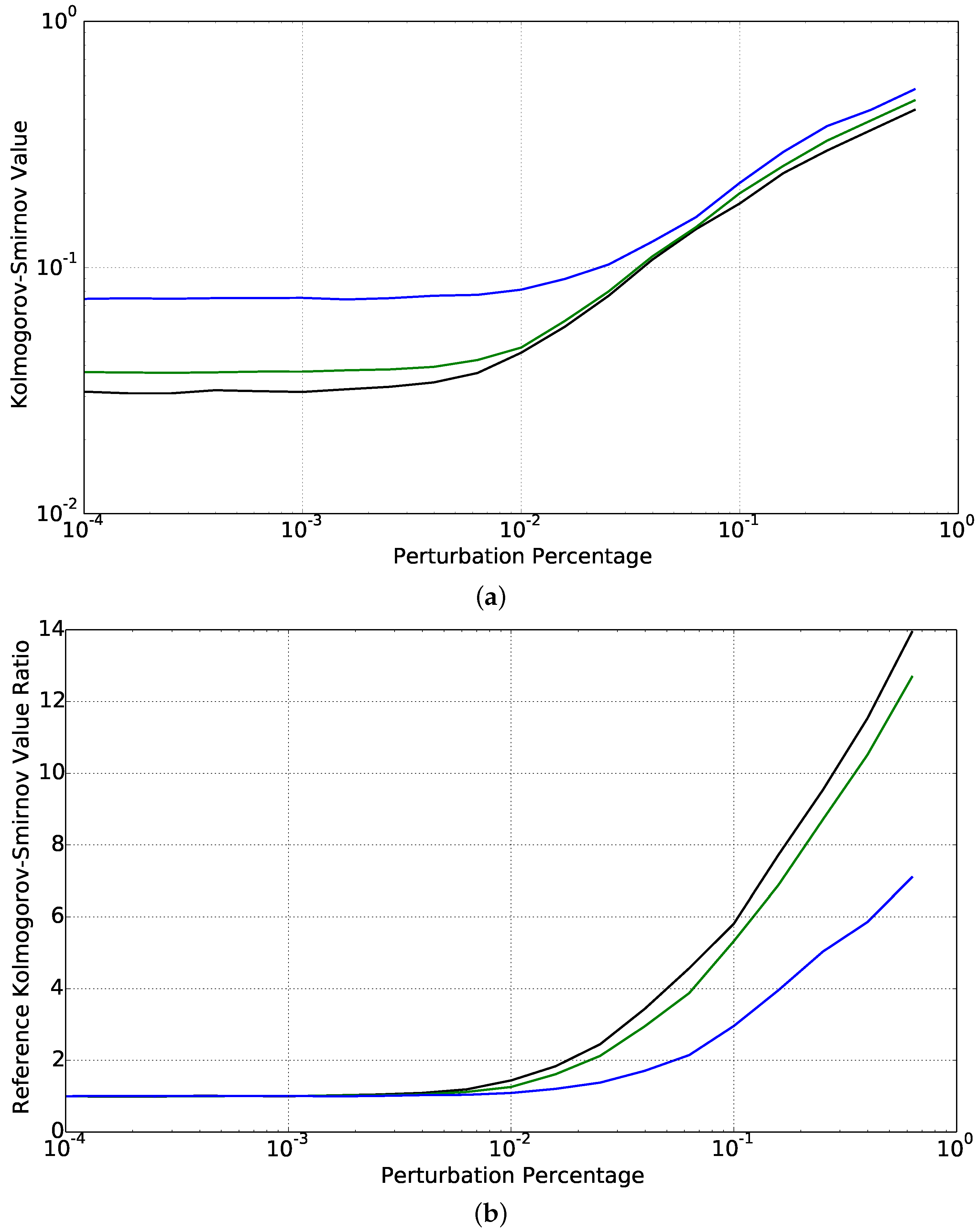
4.1. Optimal Learning Case: Abundant Data, Strong Learning Machine
- Enforcing some robustness on the learning machine, using the compound information theoretical objective stated in Equation (44) is at the expense of some precision in the final result.
- Using effectively produces a slightly more robust machine at the expense of a small departure from the desired solution.
- Using smaller values of produces even more robust output curves, but at the price of unacceptably high error in these curves, as indicated by higher KS values.
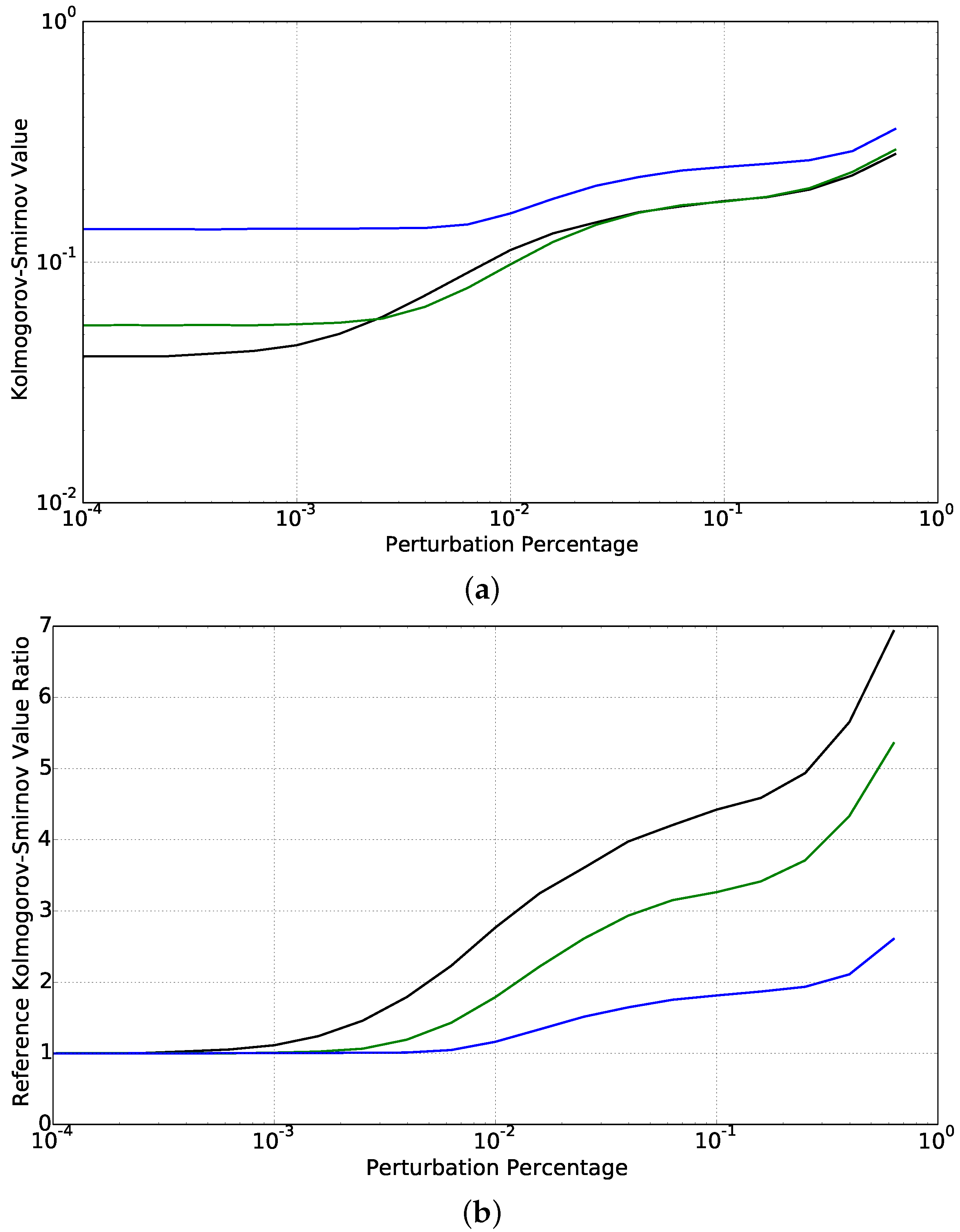
4.2. Worst Case Learning Problem: Small Dataset, Strong Learning Machine
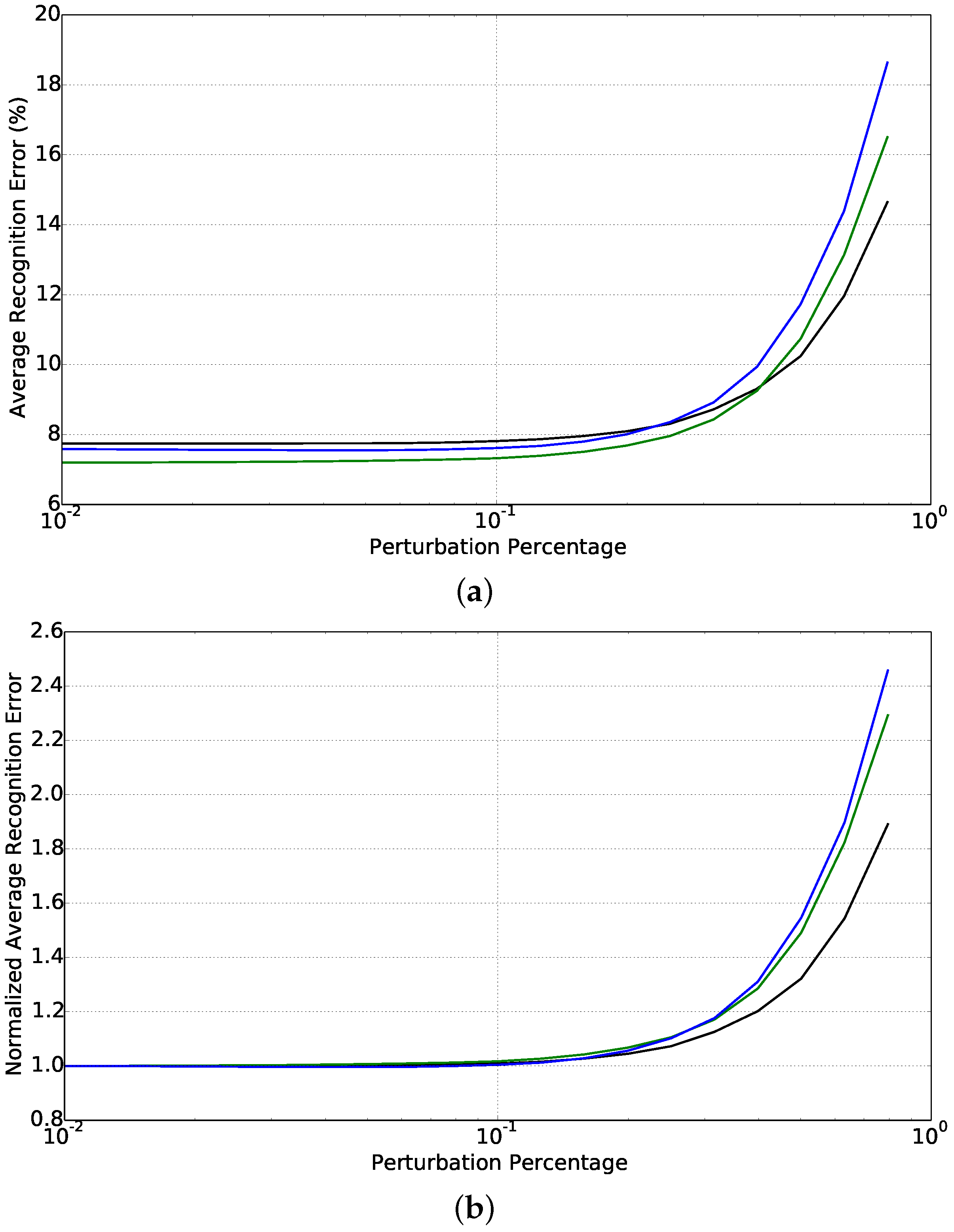
5. An Application in Handwritten Digit Recognition
6. Discussion
6.1. Implications for Learning Machines
6.2. Connections to Other Frameworks
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer: Heidelberg/Berlin, Germany, 1999. [Google Scholar]
- Devroye, L.; Lugosi, G. Combinatorial Methods in Density Estimation; Springer: Heidelberg/Berlin, Germany, 2001. [Google Scholar]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A Training Algorithm for Optimal Margin Classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992.
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A. Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Csiszar, I. I-Divergence Geometry of Probability Distributions and Minimization Problems. Ann. Probab. 1975, 3, 146–158. [Google Scholar] [CrossRef]
- Csiszar, I. Sanov Property, Generalized I-Projection and A Conditional Limit Theorem. Ann. Probab. 1984, 12, 768–793. [Google Scholar] [CrossRef]
- Csiszar, I.; Cover, T.; Choi, B.S. Conditional Limit Theorem under Markov Conditioning. IEEE Trans. Inf. Theory 1987, 33, 788–801. [Google Scholar] [CrossRef]
- Da Veiga, S. Global Sensitivity Analysis with Dependence Measures. J. Stat. Comput. Simul. 2015, 85, 1283–1305. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.E.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Shannon, C. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Jaynes, E.T. Information Theory and Statistical Mechanics. Phys. Rev. 1957, 106, 620. [Google Scholar] [CrossRef]
- Rényi, A. Probability Theory; Dover Publications: Mineola, NY, USA, 2007. [Google Scholar]
- Ackley, D.H.; Hinton, G.E.; Sejnowski, T.J. A Learning Algorithm for Boltzmann Machines. Cognit. Sci. 1985, 9, 147–169. [Google Scholar] [CrossRef]
- Tishby, N.; Pereira, F.C.; Bialek, W. The information bottleneck method. In Proceedings of the 37th Annual Allerton Conference on Communication, Control and Computing, Monticello, IL, USA, 22–24 September 1999.
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Principe, J. Information Theoretical Learning; Springer: Heidelberg/Berlin, Germany, 2010. [Google Scholar]
- Kullback, S.; Leibler, R.A. On Information and Sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Kullback, S. Information Theory and Statistics; John Wiley & Sons: New York, NY, USA, 1959. [Google Scholar]
- Cover, T.; Thomas, J. Elements of Information Theory, 2nd ed.; John Wiley & Sons: New York, NY, USA, 2006. [Google Scholar]
- Zegers, P.; Fuentes, A.; Alarcón, C.E. Relative Entropy Derivative Bounds. Entropy 2013, 15, 2861–2873. [Google Scholar] [CrossRef]
- Zegers, P. Fisher Information Properties. Entropy 2015, 17, 4918–4939. [Google Scholar] [CrossRef]
- Li, J.Q.; Barron, A.R. Mixture density estimation. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2000; Volume 12, pp. 279–285. [Google Scholar]
- Bergstra, J.; Breuleux, O.; Bastien, F.; Lamblin, P.; Pascanu, R.; Desjardins, G.; Turian, J.; Warde-Farley, D.; Bengio, Y. Theano: A CPU and GPU Math Expression Compiler. In Proceedings of the Python for Scientific Computing Conference, Austin, TX, USA, 28 June–3 July 2010.
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Ciresan, D.; Meier, U.; Schmidhuber, J. Multi-column Deep Neural Networks for Image Classification. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012.
- Frieden, B.R. Science from Fisher Information: A Unification; Cambridge University Press: Cambridge, UK, 1998. [Google Scholar]






© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zegers, P.; Frieden, B.R.; Alarcón, C.; Fuentes, A. Information Theoretical Measures for Achieving Robust Learning Machines. Entropy 2016, 18, 295. https://doi.org/10.3390/e18080295
Zegers P, Frieden BR, Alarcón C, Fuentes A. Information Theoretical Measures for Achieving Robust Learning Machines. Entropy. 2016; 18(8):295. https://doi.org/10.3390/e18080295
Chicago/Turabian StyleZegers, Pablo, B. Roy Frieden, Carlos Alarcón, and Alexis Fuentes. 2016. "Information Theoretical Measures for Achieving Robust Learning Machines" Entropy 18, no. 8: 295. https://doi.org/10.3390/e18080295
APA StyleZegers, P., Frieden, B. R., Alarcón, C., & Fuentes, A. (2016). Information Theoretical Measures for Achieving Robust Learning Machines. Entropy, 18(8), 295. https://doi.org/10.3390/e18080295