1. Introduction
Recently, in Electronic Warfare (EW) and Electronic Intelligence (ELINT) systems [
1], distributed detection of a non-cooperative target [
2], distributed modulations classification [
3], and specific emitter identification (SEI) have attracted much attention. The SEI technique was first proposed in the mid-1960s for identifying and tracking specific transmitters. This technique discriminates the individual transmitter of a given signal by comparing the features carried by the signal with a library of feature sets, and selecting the most matchable class [
4]. SEI techniques can be used to support the applications of wireless communication security and authentication [
5,
6]. In SEI systems, the identification concerns particular emitter copies of the same type classification, while recognition concerns only emitter types classification and is not as advanced as identification.
The key to any SEI system is the useful feature sets obtained from the signal that make identification possible [
4]. Thus, the most important thing is to extract the valid RF fingerprints of a given signal when implementing an effective SEI system. Generally, SEI techniques can be divided into two broad categories: radar signal-based SEI and communication signal-based SEI, according to different application scenarios and the characteristics of signals. However, some SEI methods can be used in both radar signals and communication signals.
In the case of radar signals, SEI techniques are always based on the intra-pulse analysis [
7], the use of out-of-band radiation [
8], the theory of fractals [
9], the graphical representation of the distribution of radar signal parameters [
10], the use of the agglomerative method of hierarchical radar signal clustering [
11], the Wigner–Ville distribution (WVD) [
12], etc.
In the case of communication signals, SEI techniques can be divided into three categories: transient signal techniques, steady-state signal techniques, and nonlinear techniques. A transient signal is actually a brief radio emission produced while the output power of a transmitter goes from zero to the level required for data communication. A steady state signal is usually defined as the part between the end of the transient and the end of the whole signal.
In transient analysis, the RF fingerprints are always extracted from instantaneous amplitude, phase, and frequency of the received signals due to the difference caused by the idiosyncratic characteristics of power amplifiers, filters, and frequency synthesizers. Recent research has shown that the transient-based SEI techniques have good classification performance [
13,
14]. However, the duration of transient signals are quite short, and there is not enough data for RF fingerprint extraction and identification. The analysis based on the transient signal also needs very high sample rates, which makes the architecture of the receiver complex. The identification of the emitters which are from the same manufacturer may require a high-end receiver to offer a high oversampling rate to detect the transient signals [
15].
In contrast with the works of transient analysis, the steady response approaches are more practical. There are many SEI techniques which are based on the analysis of steady response, including modulation-based method, spectrum-based method, transform-based method, and so on. Recently, Brik et al. developed a modulation-based method to extract the RF fingerprints from a steady-state signal, and achieved the identification accuracy of 99% [
16]. Scanlon et al. applied the spectral averaging technique to the SEI and achieved the identification accuracy of 99.8% [
17]. However, these methods [
16,
17] are performed under the condition that the transmitters and the receivers are located in an anechoic chamber, whereas the receivers are usually as far as several kilometers from the transmitters in practice. The transform-based method (e.g., the method based on the wavelet packet decomposition) has been studied for a long time [
18], but its performance is usually affected by the selection of the basis of the transformation.
The nonlinear techniques can be divided into two groups: the techniques based on nonlinear characteristics and the techniques based on nonlinear modeling. Carroll has demonstrated the validity of exploring the nonlinearity of amplifiers for signal identification [
19]. His method is based on the phase space analysis, and it usually needs a lot of data to obtain reliable results. Huang et al. extracted the normalized permutation entropy (NPE) as the RF fingerprint to identify the unique transmitter, and achieved a relatively good performance [
20]. However, the embedding dimension should be determined first, and the amount of data to calculate the NPE should be large if one wants to obtain a relatively reliable statistic. Polak et al. identified the unique emitter by modeling the nonlinearity of power amplifier (PA) and integral nonlinearity (INL) of the digital-to-analog converter (DAC) with Volterra series and a Brownian Bridge random process, respectively [
21]. Its performance would become worse when these models do not match well with the real signals. Zhang et al. proposed another SEI method based on the nonlinear modeling and the Hilbert–Huang Transform (HHT) [
22] in the case of relaying scenario and single-hop scenario. Obviously, the accuracy of the model will affect the performance of this type of approach.
As demonstrated by Carroll, the amplifiers are inherently nonlinear because they depend on semiconductors [
19]. As a result, one can study the communication transmitters, as they are dynamical systems. The signals from actual communication transmitters can be considered nonlinear, since the nonlinear property of such transmitters will be translated in the signals. Thus, we can extract the RF fingerprints from received signals from the nonlinear point of view. In consideration of the drawbacks of the aforementioned nonlinear SEI approaches [
20,
21,
22], we will propose a novel nonlinear SEI method based on the natural measure of the one-dimensional component of higher dimensional systems. This method does not need any model, and it is effective in the case of a relatively small amount of data and low sample rate.
2. Proposed Method
The method proposed in this letter is based on treating the communication transmitter as a nonlinear dynamical system. Based on this principle, the natural measure of the received signal is extracted and used as an RF fingerprint. In fact, the natural measure is a useful tool that helps us to better understand chaotic maps or systems. Before introducing the concept of the natural measure, another related concept called natural invariant density should be introduced first.
For a one-dimensional chaotic map defined on
, its natural invariant density can be defined as follows. For any given interval
, if the fraction of time that typical orbits fall into the interval
is
, then the function
will be called the natural invariant density of this one-dimensional chaotic map. As an example, the logistic map with
(shown in Equation (
1)) and its natural invariant density
[
23] (shown in Equation (
2)) are shown as follows:
Compared to the natural invariant density, the natural measure is more practical [
23]. For the chaotic attractor of a one-dimensional map, its natural measure can be defined as follows. Let
A be an interval in the phase space; let
be an initial value in the basin of attraction of the chaotic attractor
B; let
be the orbit generated by the initial value
; and let
be the fraction of time that
spends in
A in the time interval
, and assume that the limit in Equation (
3) exists.
If
stays unchanged for every
in
B except for a set of
-values of Lebesgue measure zero, then
is the natural measure of
A and can be denoted as
. For more details about the natural invariant density and the natural measure, please see Ref. [
23]. For a received signal
, its natural measure can be evaluated as follows:
- 1
Normalizing the signal to
:
- 2
Equally dividing the interval into L parts , according to a given length of the inter-cell Δ, where is the integer smaller than or equal to . The midpoint of each inter-cell will be the representative point.
- 3
Calculating the probability
where the data fall into the interval
;
where
represent the number of data in the set;
- 4
Then we can obtain the corresponding natural measure: .
As pointed out by Ott [
23], the natural measures and the natural invariant densities can be proven to exist under fairly general conditions in the case of one-dimensional maps with chaotic attractors; however, it is difficult to prove the existence of a natural measure in the case of higher dimensional systems, although it seems fairly clear that the natural measure exists in such cases. In the present work, we do not try to prove that the natural measure of higher dimensional systems exists, but to show that it exists at least for the one-dimensional component of the higher-dimensional systems. It is meaningful since we can only obtain the one-dimensional signals from the communication transmitters when they are considered nonlinear systems in the case of single antenna. In order to verify the existence of the natural measure of the one-dimensional component of higher-dimensional chaotic systems, we consider the Lorenz, Rössler and Wiem-Type systems, and they are shown in Equations (
6)–(
8).
where
, and
, correspond to a chaotic attractor.
where
, and
, correspond to a chaotic attractor.
where
, and
, correspond to a chaotic attractor, Θ is the Heaviside function.
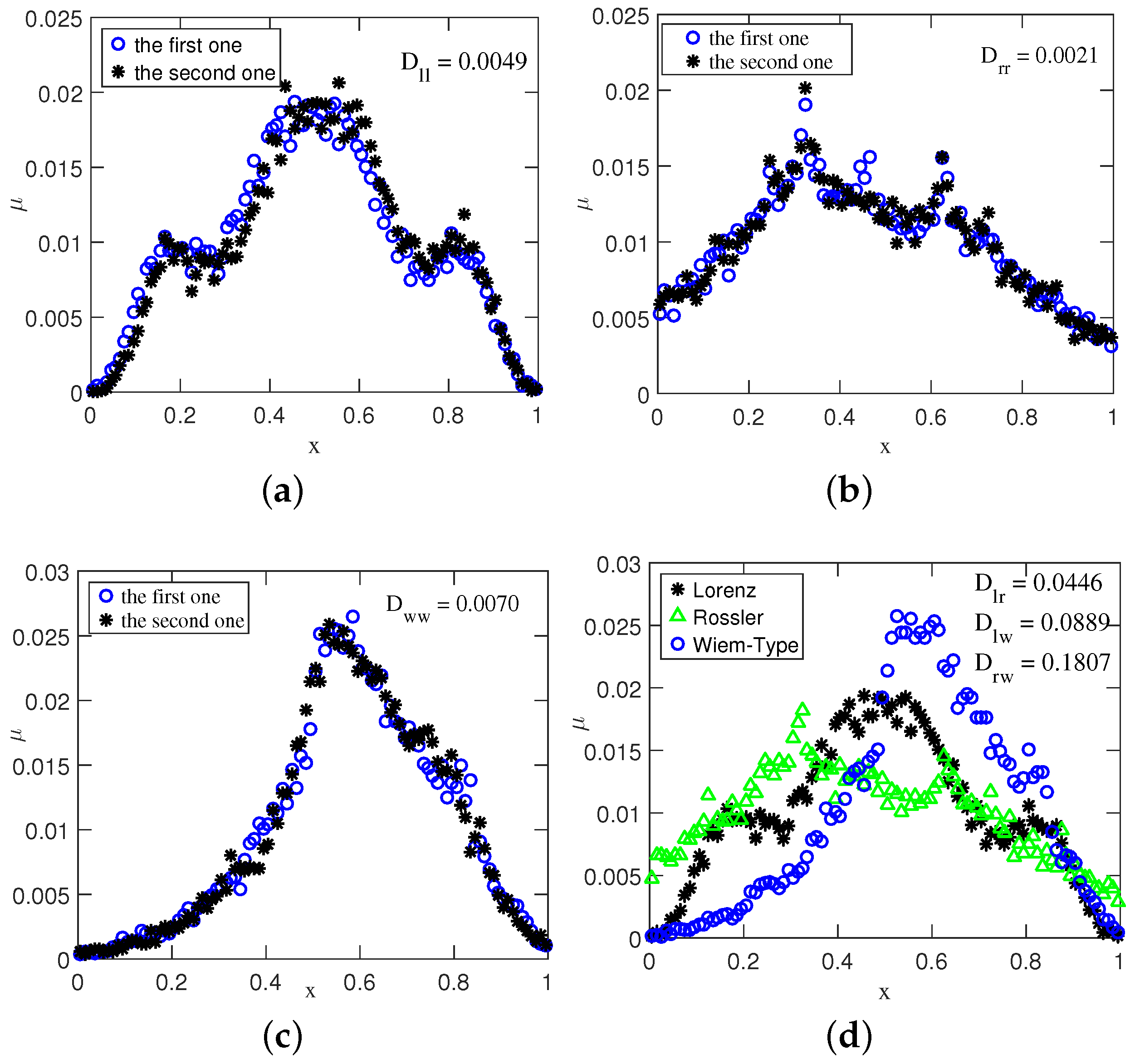
In this letter, the
x-coordinates of the above systems are used. The histograms of the Lorenz series from different typical initial conditions [
23] are made, and two of them that are randomly selected are shown in
Figure 1a. There are 20,000 data points being used, and the length of inter-cell for the histogram is 0.01.
From
Figure 1a, we can easily observe that the histograms derived from different
x-coordinates (i.e., the orbits from different typical initial conditions) of the Lorenz system are almost the same. It should be noted that similar results are also obtained for the Rössler and Wiem-Type system, as shown in
Figure 1b,c, respectively.
On the other hand, in
Figure 1d we plot the histograms obtained from the
x-coordinates of the Lorenz, Rössler, and Wiem-Type system, respectively. It can be easily seen from
Figure 1d that the histograms obtained from the one-dimensional component of different systems are quite diverse. Although the difference can be perceived by human eyes, it can be better detected statistically. In the present work, the well-known Kullback–Leibler divergence (KLD) [
24] is used to detect this difference, and here we are interested in the discrete type of the KLD. Generally speaking, given two discrete distributions
and
with domain
, the KLD
is defined as follows:
The KLD is null if and only if
, and positive otherwise. In information theory, the KLD is also called the relative entropy and is widely used to measure the distance (similarity) between two distributions [
25]. The KLD is also widely used in biological systems [
26]. The KLD obtained from different natural measures is always larger than zero due to the finite data length. Nevertheless, a relatively small KLD means that the two natural measures are almost the same. It should be noted that two distributions
and
may not have the same supports (i.e., if
, or
for some value
m). As a common procedure [
27], we introduce a bias of order
, where
N is the length of the signal. More precisely, the vanishing frequencies are replaced with
, and the new frequency histogram is normalized appropriately. Given two natural measures
and
, according to the evaluation of the natural measure,
and
are both defined on
,
is the probability where the data fall into the interval
. The calculation of the KLD
can be implemented as follows:
Step 1: Processing the vanishing frequencies:
where
with
and
being the length of data
P and data
Q, respectively.
Step 2: Normalizing
and
:
Step 3: Calculating the
:
In order to verify the results in
Figure 1, we have computed the KLDs between different chaotic systems, the average values which are carried out with 1000 Monte-Carlo experiments are shown in
Table 1. In addition, the
shown in
Figure 1a is the average KLD between the histograms obtained from two orbits of the Lorenz system,
in
Figure 1b and
in
Figure 1c are similar with
.
shown in
Figure 1d is the average KLD between the histograms obtained from the orbits of the Lorenz and Rössler system,
and
are similar with
.
It can be seen from
Table 1 that the values of KLD between different histograms of the same system are quite small, which means that they are almost the same. On the other hand, the values of KLD between the histograms of the diverse systems are relatively large, which means that they are quite different. In
Figure 2 we also plot the natural measures obtained from the
y and
z-coordinates of these systems. From
Figure 2 we can easily observe that for each system, the histograms derived from
y-coordinates (or
z-coordinates) with different initial values are almost the same, which means that the natural measure obtained from the
y-coordinate (or
z-coordinate) exists. It should be pointed out that for Rössler and Wiem-Type systems, the corresponding histograms derived from the
z-coordinates are quite different from those of the
y-coordinates and the
x-coordinates, which means that the natural measures obtained from different components are not the same—even for the same chaotic system.
The natural invariant density and the natural measure are usually defined on the one-dimensional chaotic maps. In this letter, we extend these concepts to the chaotic systems, and find that even for the same chaotic system, the natural measures derived from different coordinates are quite different. Nevertheless, the natural measure exists for any coordinates of a chaotic system, and can be used as an RF fingerprint since they are different for diverse systems.
From the results shown in
Figure 1 and
Figure 2 and
Table 1, we find that the natural measures of the one-dimensional component of higher dimensional systems exists, and the KLD between these natural measures can be exploited to classify the unique transmitter. In what follows we will exploit the natural measure obtained from the real data as the RF fingerprint to classify the unique transmitter. An obvious advantage of the natural measure is that the amount of data one needs can naturally increase because the natural measure will not change if one puts different orbits together, which makes the proposed method very effective—even in the case of a relatively small amount of data.
3. Results
The aim of this letter is to extract a valid RF fingerprint from the given signal and implement an effective recognition. We will check the performance of the proposed method by utilizing the data obtained from real applications. The data are derived from the Automatic Identification System (AIS) signals emitted from ships. The center frequency of AIS burst signal is 161.975 MHz or 162.025 MHz. The data bits are modulated with Gaussian Minimum Shift Keying (GMSK) with a bandwidth of 25 KHz, and the data rate is 9600 bits per second. The signals are collected by an antenna and a signal monitoring system located near a port in China. The interest signal is down-converted and digitized with an analog-to-digital converter. The signal-to-noise ratio (SNR) for all data samples is about 18 dB, and the oversampling rate is 40.
In the experiment, we have four different transmitters that are produced by four diverse manufacturers, which means that measure sets come from different emitter types and the process of their recognition is based only on type classification. In other words, we have four classes of data, which are denoted as
, and there are 40 bursts in each class. After obtaining the data, we then extract the transient part of each burst by using a method similar to that in [
28] and normalize these transients to
. Since the number of bursts is small and the transient part of each burst is very short (about 0.83 milliseconds), we will do the experiment just as the sampling with replacement. In each run, the experiment is implemented as follows:
Step 1: Randomly choosing three normalized transients from each class and serially connecting them to form a big transient. This big transient will be regarded as the testing data;
Step 2: Serially connecting the remaining normalized transients in each class to form another big transient and regarding it as the training data;
Step 3: Calculating the corresponding natural measures; i.e., four natural measures for the testing data, denoted as , and four natural measures for the training data, denoted as ;
Step 4: Calculating the KLD between and , ;
Step 5: Identifying each testing data; i.e., finding the smallest for a given t. For example, if is the smallest when , then the first testing data belong to the fourth class.
In each run, after the above steps, the testing data will be put back to the corresponding data sets and the above steps will be repeated until 100 runs are completed. The classification confusion matrix obtained from 100 trials is shown in
Table 2.
We can observe from
Table 2 that above 98% identification accuracy is achieved for all the emitters, which means that the proposed method can classify these transmitters successfully. It is important to point out that there are only 320 data points in the transient part of each burst, which means that the amount of data in each trial is very small. The results shown in
Table 2 demonstrate that the proposed method based on the natural measure is very effective for SEI, even though the amount of data is quite small and the sample rate is low.
The SEI method based on the normalized permutation entropy (NPE) [
20] is similar to the proposed method. Hence, the NPE-based SEI method is used as a gold standard in this letter. In order to make a comparison between the NPE-based method and the proposed method, the classification confusion matrix of the NPE-based method is calculated and the results are shown in
Table 3. It should be noted that 40 Monte Carlo runs are implemented for each transmitter since there are only 40 bursts in each class. In this experiment, a
k-nearest neighbor discriminatory classifier [
29] with
is employed. To derive the NPE, the transient part of each burst is used and the embedding dimension
D is set to three, since the transient is quite short. As can be seen from
Table 3, the NPE-based method achieves high classification accuracy for T2 and T3, it achieves low classification accuracy for T1, and classifies T4 incorrectly. From
Table 3 we can also observe that T4 can be easily recognized as T1 and vice versa. The parameters of the amplifiers in these transmitters may be very close, which will lead to the similar permutations [
20]. However, the proposed method is not affected by this, and it still identifies T4 and T1 correctly. Comparing
Table 2 and
Table 3, it can be easily observed that the performance of the proposed method is better than that of the NPE-based method.
In practice, the time consumption of a method is also an important consideration. In order to check the time consumption of the proposed method, the average time consumption via 160 Monte Carlo runs (40 runs for each class) of the NPE-based method and the proposed method for different data lengths are shown in
Table 4. The embedding dimensions of the NPE-based method for the two data lengths are 3 and 5, respectively. It can be seen from
Table 4 that the time consumptions of the proposed method are smaller than those of the NPE-based method—at least in the case of a small amount of data. The experiments are run on a computer with a 3.40 GHz Intel Core i7-2600K CPU and 8.00 GB RAM. The release of MATLAB is 2016b.







{kind=link}
{kind=link}