1. Introduction
The human visual system (HVS) is important for perceiving the world. As an important medium of information transmission and communication, images play an increasingly vital role in human life. Since distortions can be introduced during image acquisition, compression, transmission and storage, the image quality assessment (IQA) method is widely studied for evaluating the influence of various distortions on perceived image quality [
1,
2].
In principal, subjective assessment is the most reliable way to evaluate the visual quality of images. However, this method is time-consuming, expensive, and impossible to implement in real-world systems. Therefore, objective assessment of image quality has gained growing attention in recent years. Depending on to what extent a reference image is used for quality assessment, existing objective IQA methods can be classified into three categories: full-reference (FR), reduced-reference (RR) and no-reference/blind (NR/B) methods. Accessing all or part of the reference image information is unrealistic in many circumstances [
3,
4,
5,
6,
7,
8], hence it has become increasingly important to develop effective blind IQA (BIQA) methods.
Many NR IQA metrics focus on assessing a specific type of visual artifact, such as blockiness artifacts [
9], blur distortion [
10], ringing distortion [
11] and contrast distortion [
12]. The main limitation is that the distortion type must be known in advance. However, generic NR-IQA metrics have recently become a research hotspot because of their general applicability.
According to the dependency on human opinion scores, the generic NR approaches can be roughly divided into two categories [
13]: distance-based methods and learning-based methods. Distance-based methods express the image distortion as a simple distance between the model statistics of the pristine image and those of the distorted image [
14,
15,
16]. For example, Saha et al. [
16] proposed a completely training-free model based on the scale invariance of natural images.
Learning-based methods have attracted increasing attention with the development of artificial intelligence. The basic strategy is to learn a regression model that maps the image features directly to a quality score. Various regression methods, including support vector regression (SVR) [
17], neural network [
18,
19,
20], random forest regression [
21] and deep learning framework [
22,
23], are widely used for model learning. More importantly, after pre-processing of image [
24], image features, which are extracted for model learning, are directly related to the accuracy of the IQA. The codebook-based method [
25] aims at extracting Gabor filter-based local features, which describe changes of texture information. Moreover, NSS-based methods are also widely used to extract features [
26,
27,
28,
29,
30,
31,
32,
33]. In [
26,
27], these methods use the difference of NSS histogram of natural and distorted images to extract image features. In [
28,
29,
30,
31,
32,
33], they aim to establish NSS model to extract features. The Laplace model [
28], the Generalized Gaussian distribution (GGD) model [
29,
32,
33], the generalized gamma model [
30] and Gaussian scale mixture model [
31] are widely used as NSS model to extract features in different domains. In addition, Ghadiyaram et al. combined histogram features and NSS model features to achieve good-quality predictions on authentically distorted images [
34].
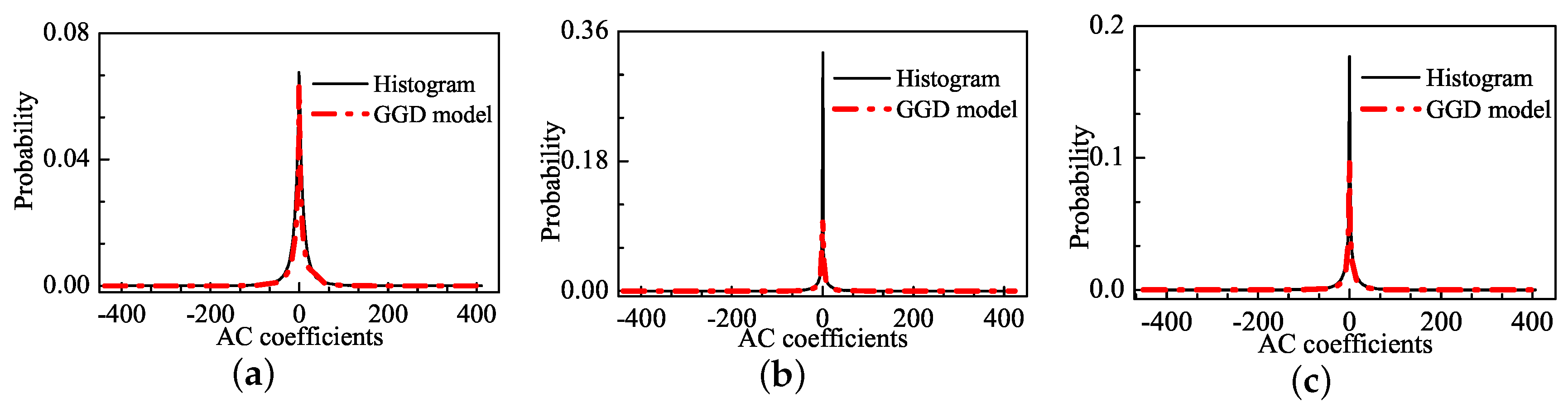
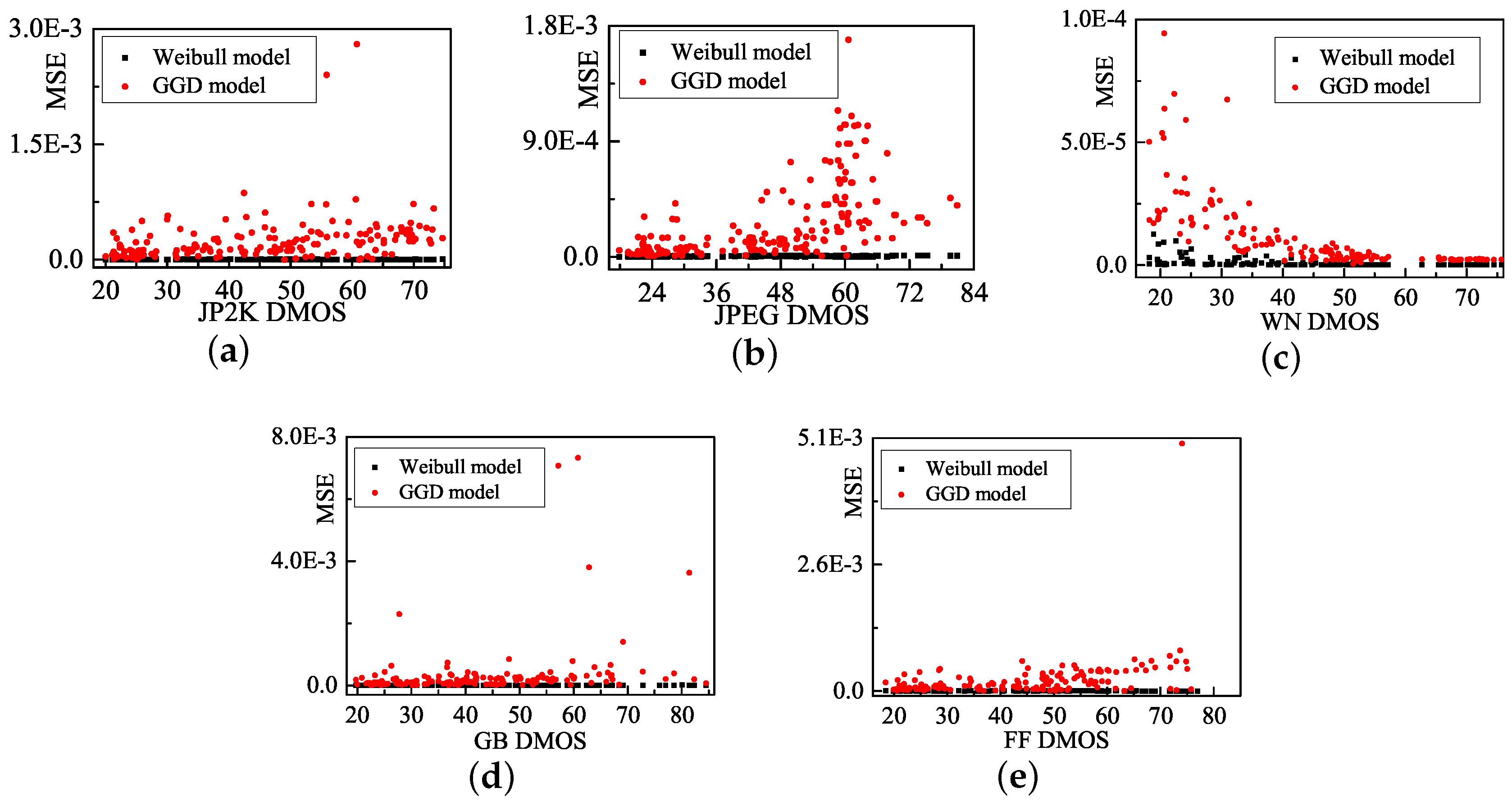
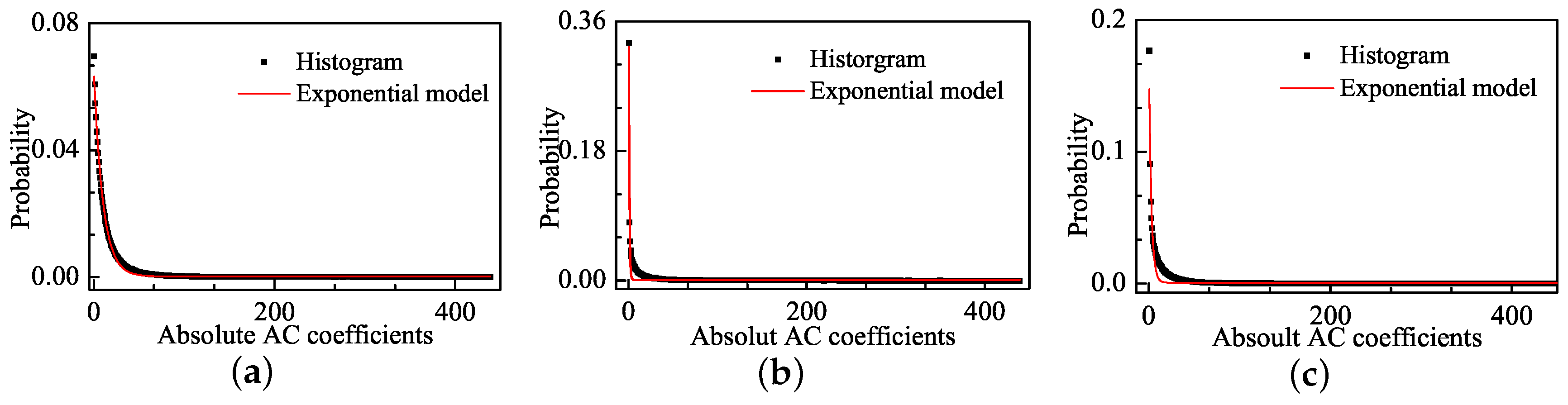
NSS model-based methods have achieved promising results. The NSS model assumes that natural images share certain statistical regularities and various distortions may change these statistics. Therefore, the NSS model is capable of fitting statistics of natural and distorted images. The GGD model is a typical NSS model that is widely studied and applied. The GGD model in the DCT domain is able to follow the heavy-tail and sharp-peak characteristics of natural images. By using the GGD features, the distorted image quality can be estimated. However, the GGD model has some shortcomings in fitting the statistics of distorted images because the distribution of DCT coefficients shows a pulse-shape phenomenon for distorted images, which is described as the rapid increase of discontinuity. The discontinuity is derived from the differences between the high- and low-frequency coefficients of distorted images. Thus, the pulse-shape phenomenon cannot be fitted by the GGD model, which leads to inaccurate quality assessments.
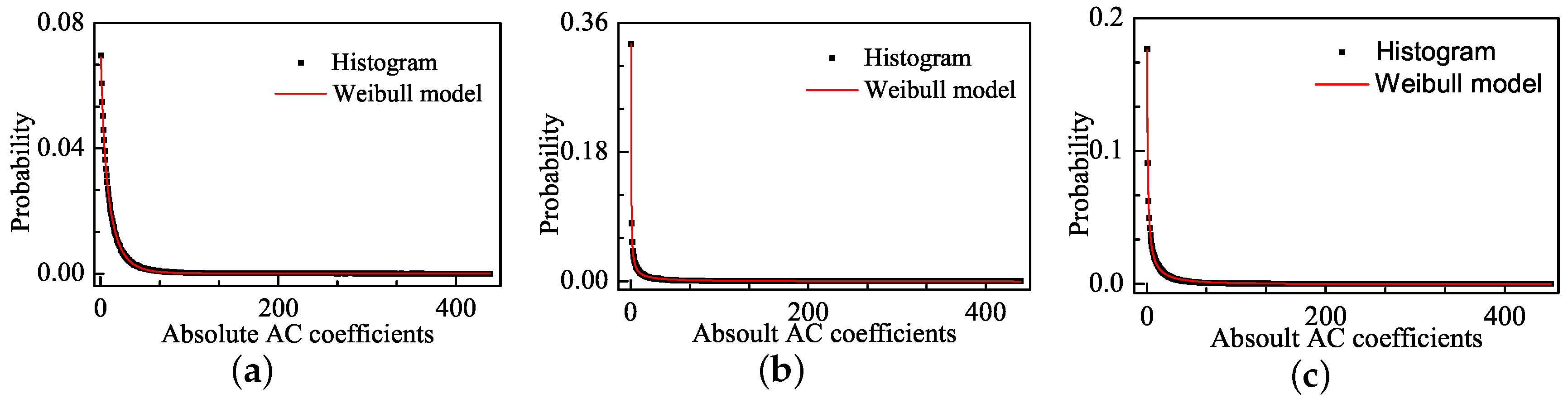
In this paper, an effective blind IQA approach of natural scenes related to entropy differences is developed in the DCT domain. The differences of entropy can be described by probability distribution in distorted images. We find the DCT coefficients’ distribution of distorted images shows a pulse-shape phenomenon in addition to the heavy-tail and sharp-peak phenomena. Since the pulse-shape phenomenon is often neglected in NSS model, image structure cannot be fully presented by image entropy. Therefore, the performance of the IQA methods based on such NSS model can be affected to some extent. To this end, the Weibull model is proposed in this paper to overcome the under-fit caused by the pulse shape phenomenon of traditional GGD model. Furthermore, we prove that the Weibull model correlates well with the human visual perception. Based on the Weibull model, corresponding features are extracted in different scales and the prediction model is derived using the SVR method. Experimental results show that the Weibull statistics (BWS) method consistently outperforms the state-of-the-art NR and FR IQA methods over different image databases. Moreover, the BWS method is a generic image quality algorithm, which is applicable to multiple distortion types.
The novelty of our work lies in that we find the pulse-shape phenomenon when using existing GGD model to characterize image distortions. Then, we propose a useful Weibull model to overcome under-fit the pulse-shape phenomenon and extract features related to visual perception from the Weibull model to evaluated image quality. Furthermore, the proposed method has the advantage of high prediction accuracy and high generalization ability.
The rest of the paper is organized as follows.
Section 2 presents the NSS model based on entropy differences.
Section 3 presents the proposed BWS algorithm in details.
Section 4 evaluates the performance of the BWS algorithm from various aspects.
Section 5 concludes the paper.
3. Proposed BWS Method
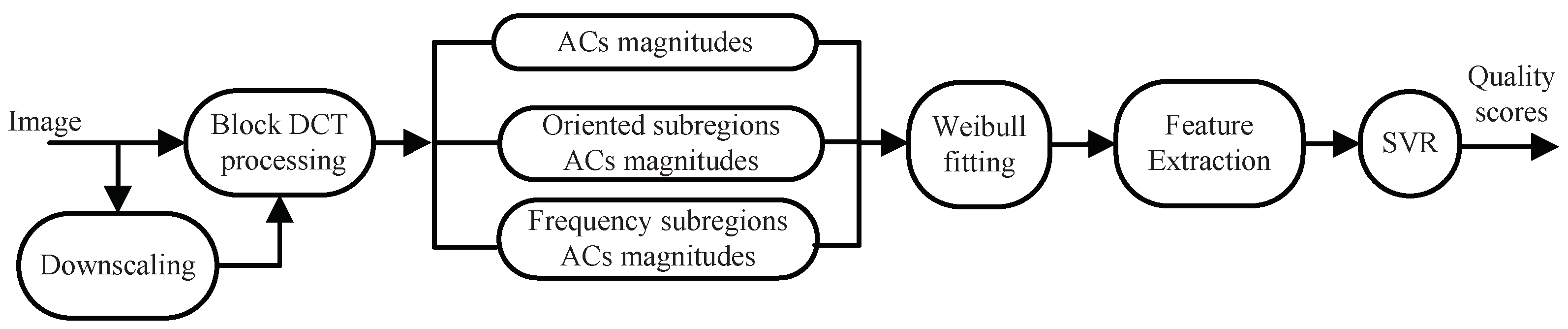
In this section, we describe the proposed BWS method in detail. The framework is illustrated in
Figure 6. First, block DCT processing is applied to images of different scales. The goal is not only to conform to the decomposition process of local information in the HVS [
40] but also to reflect the image structure correlation [
4]. In the DCT domain, the magnitudes of the block AC coefficients and those in the orientation and frequency sub-regions are extracted to describe HVS characteristics. Then, a Weibull model is employed to fit these values. From the Weibull model, the following four perceptive features are extracted: the shape-scale parameter feature, the coefficient of variation feature, the frequency sub-band feature, and the directional sub-band feature. Finally, by using the SVR learning method, the relationship between the image features and subjective quality scores in high-dimensional space is obtained.
One advantage of this approach is that we consider only the change of luminance information in the BWS algorithm because neuroscience research shows that the HVS is highly sensitive to changes in image luminance information [
37]. In addition, DCT processing is useful in IQA. The presentation of features can be enhanced by treating different frequency components with different distortion levels. The computational convenience is another advantage [
41].
3.1. Relationship Between HVS and Perceptual Features
IQA modeling must be able to satisfy human perceptual requirements, which are closely related to HVS. Designing an HVS-based model for directly predicting image quality is infeasible because of the complexity. Therefore, in this paper, the features related to the HVS are extracted from the Weibull model and used to predict perceptual image quality scores by a learning method.
The visual perception system has been shown to be highly hierarchical [
42]. Visual properties are processed in areas V1 and V2 of the primate neocortex, which occupies a large region of the visual cortex. V1 is the first visual perception cortical area, and the neurons in V1 can achieve succinct descriptions of images in terms of the local structural information pertaining to the spatial position, orientation, and frequency [
43]. Area V2 is also a major visual processing area in the visual cortex [
44], and the neurons in V2 have the property of the scale invariance [
45]. Therefore, our proposed model is related to the properties of the HVS.
3.2. Shape-Scale Parameter Feature
Before extracting features, we divide the image into
blocks with a two-pixel overlap between adjacent blocks to remove the redundancy of image blocks and better reflect the correlation information among blocks. For each block, DCT is performed to extract the absolute AC coefficients. Then, the Weibull model is used to fit the magnitudes of the AC coefficients of each block. Theories in fragmentation posit that the scale parameter
m and shape parameter
a in the Weibull distribution are strongly correlated with brain responses. The experiments on brain responses showed that
a and
m explain up to 71 % of variance of the early electroencephalogram signal [
39]. These parameters can also be estimated from the outputs of X-cells and Y-cells [
46]. In addition, the two parameters can accurately describe the image structure correlation because a difference in the image distribution of quality degradation, which depends on the image structural information, results in a different shape of the Weibull distribution, thereby resulting in different values of
a and
m. In other words, the response of the brain to external image signals is highly correlated with the parameters
a and
m of the Weibull distribution. Thus, we defined the shape-scale parameter feature
. The parameters that directly determine the form of the Weibull distribution are
a and
, as shown in Equation (
3). The Equation (
3) is the deformation of Weibull distribution. Because the human subjects are viewing natural images that are correlated with
a and
m, considering only the influence of
a while ignoring the effect of
m on the Weibull distribution does not produce accurate results. Therefore, we chose
as feature
for assessing image quality. The advantage of this feature is that it provides an intuitive expression of the Weibull equation as well as a monotonic function of distortion, which can be used to represent the levels of distortion in images.
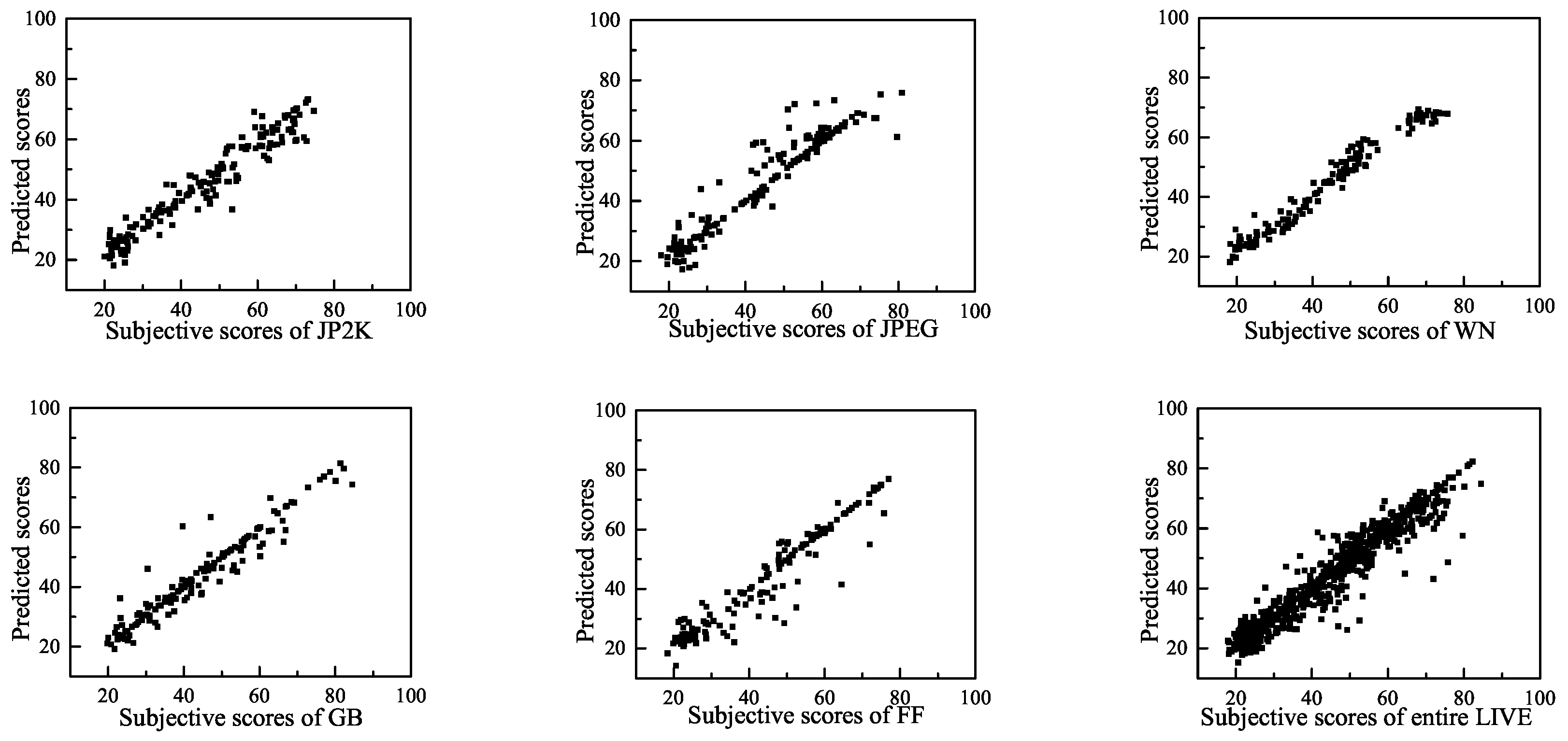
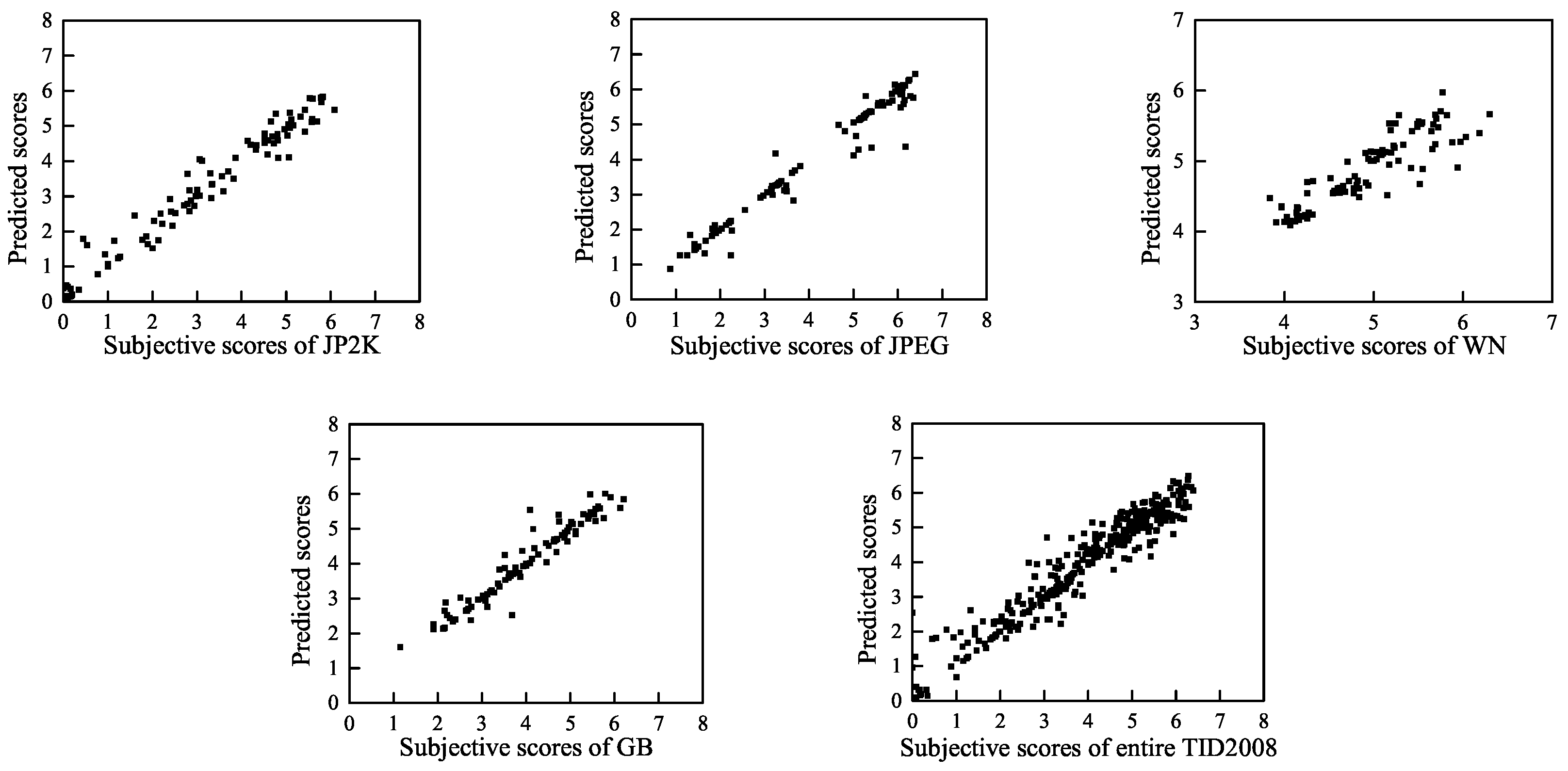
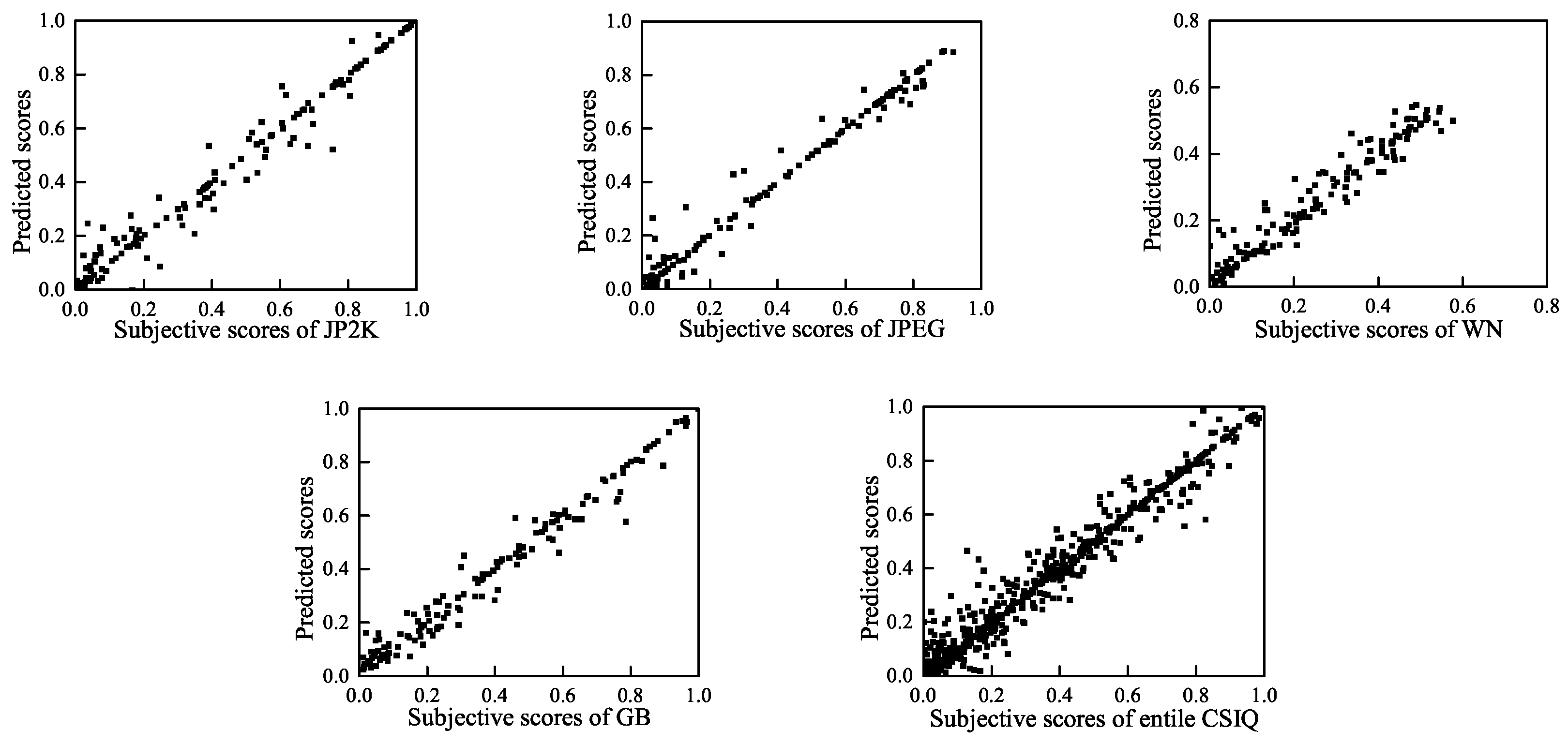
The efficiency of the features is verified in the LIVE database. We extracted the average value of the highest 10% and 100% (all block coefficients) of the shape-scale parameter features
in all blocks of the image. These two percentages correspond to image distortion of the local worst regions and the global regions, respectively. It may be inappropriate to only focus on distortion of local worst regions or the overall regions [
47,
48,
49]. Thus, it is necessary to combine the local distortion with the global distortion.
Table 2 shows the Spearman Rank Order Correlation Coefficient (SROCC) values between the DMOS scores and the average values of the highest 10% of
as well as the DMOS values and the average values of the 100% of
in LIVE database. The SROCC value is larger than 0.7, which indicates a significant correlation with the subjective scores [
50]. Therefore, these features can be effectively used as perceptual features for IQA.
3.3. Coefficient of Variation Feature
Natural images are known to be highly correlated [
36,
37]. The correlation can be affected by distortions in different forms. In the DCT domain, distortions change the distribution of the AC coefficients. For JP2K, JPEG, GB, and FF [
38], the distortion increases the differences among low-, middle- and high-frequency information. Then, the standard deviation becomes larger under the unit mean than that in the natural image. Thus, the large variation of the standard deviation represents a large distortion. In contrast, for WN distortions, the increased random noise causes high-frequency information to increase rapidly, thereby reducing the differences among different frequency information. Thus, a small variation of the standard deviation corresponds to a large distortion.
Therefore, we define the coefficient of variation feature
, which describes the variation of the standard deviation under the unit mean as follows:
where the mean
and variance
of the Weibull model can be obtained as follows:
where
denotes the gamma function. This parameter is defined as follows:
We calculated the average value of the highest 10% of
and the average value of 100% of
in all blocks across the image.
Table 3 shows the SROCC values, which are verified in the LIVE database. The correlation is also significant in most distortion types. Thus, the features can be used to assess image quality.
3.4. Frequency Sub-Band Feature
Natural images are highly structured in the frequency domain. Image distortions often modify the local spectral properties of an image so that these properties are dissimilar to those of in natural images [
29]. For JP2K, JPEG, GB, and FF distortions, distortions trigger a rapid increase of differences among the coefficients of variation of the frequency sub-bands coefficients. A large difference represents a large distortion. However, with the WN distortion type, the opposite change trend is observed.
To measure this difference, we defined the frequency sub-band feature
f. According to the method in [
29], we divided each
image block into three different frequency sub-bands, as shown in
Table 4. Then, the Weibull fit was obtained for each of the sub-regions, and the coefficient of variation
was calculated using Equation (
4) in the three sub-bands. Finally, the variance of
was calculated as the frequency sub-band feature
f.
The feature was pooled by calculating the average value of the highest 10% of
f, and the average value of 100% of
f in all blocks across the image in the LIVE database. In
Table 5, we report how well the features are correlated with the subjective scores. The SROCC is clearly related to the subjective scores, which means that these features can be used to describe subjective perception.
3.5. Directional Sub-Band Feature
The HVS also has different sensitivities to sub-bands in different directions [
40]. Image distortion often changes the correlation information of sub-bands in different directions, which makes the HVS highly sensitive to this change. For the JP2K, JPEG, GB, and FF distortion types, distortions modify the inconsistencies among coefficients of variation in sub-bands in different directions. A large inconsistency reflects a large distortion. Note that this effect has a reverse relationship to the WN distortion.
Therefore, this inconsistency can be described by the orientation sub-band feature
. We divided sub-bands into three different orientations for each block, as shown in
Table 6. This decomposition approach is similar to the approach in [
29]. Then, the Weibull model was fitted to the absolute AC coefficients within each shaded region in the block. The coefficient of variation
was also calculated, as shown in Equation (
4), in three directional sub-bands. Finally, the directional sub-band feature
can be obtained from the variance of
.
The average values of the highest 10% and 100% of
for all blocks across images were collected. We report the SROCC values between DMOS scores and features in
Table 7 and demonstrate an obvious correlation with human perception.
3.6. Multi-Scale Feature Extraction
Previous research has demonstrated that the incorporation of multi-scale information can enhance the prediction accuracy [
5]. The statistical properties of a natural image are the same at different scales, whereas distortions affect the image structure across different scales. The perception of image details depends on the image resolution, the distance from the image plane to the observer and the acuity of the observer’s system [
40]. A multi-scale evaluation accounts for these variable factors. Therefore, we extracted 24 perceptual features across three scales. In addition to the original-scale image, the second-scale image was constructed by low-pass filtering and down-sampling the original image by a factor of two. Then, the third-scale image was obtained in the same way from the second-scale image. As listed in
Table 8, each scale includes eight features. The extraction process is as described in
Section 3.2,
Section 3.3,
Section 3.4 and
Section 3.5.
3.7. Prediction Model
After extracting features in three scales, we learned the relationship between image features and subjective scores. In the literature, SVR is widely adopted as the mapping function for learning this relationship [
51,
52]. Considering a set of training data
, where
is the extracted image feature and
is the corresponding DMOS, a regression function can be learned to map the feature to the quality score, i.e.,
. We used the LIBSVM package [
53] to implement the SVR with a Radial Basis Function (RBF) kernel in our metric. Once the regression model was learned, we could use it to estimate the perceptual quality of any input image.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}