Introducing the Ensemble-Based Dual Entropy and Multiobjective Optimization for Hydrometric Network Design Problems: EnDEMO


Abstract
:1. Introduction
- (1)
- Evaluate the existing hydrometric networks by applying the entropy-based transinformation analysis;
- (2)
- Identify potential station locations in the study area and define the simulated time series for each station;
- (3)
- Apply the traditional, deterministic, entropy-based hydrometric network design approach to find the optimal networks;
- (4)
- Apply the proposed ensemble-based design approach;
- (5)
- Compare the optimal networks and suggest the locations where the additional monitoring is recommended.
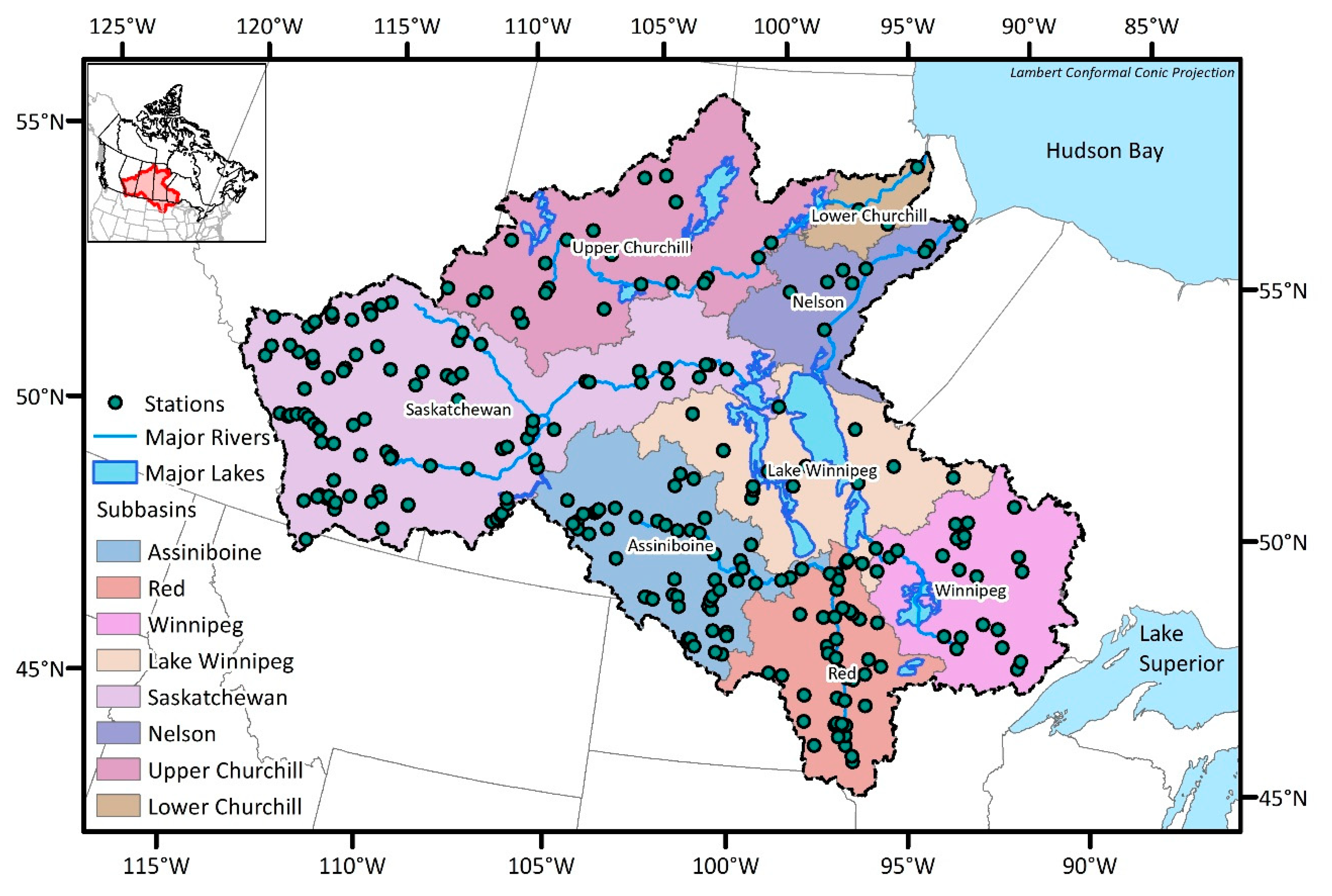
2. Study Area and Data Preparation
3. Background
3.1. Information Theory
3.2. Transinformation Analysis
3.3. Dual Entropy and Multiobjective Optimization (DEMO)
4. Methodology
- (1)
- Obtain daily observed streamflow time series from the existing stations. In this study, the HYDAT database of Environment and Climate Change Canada (ECCC) and the National Water Information System (NWIS) database of the United States Geological Survey (USGS) were used [23].
- (2)
- Estimate the transinformation (TI) index for each existing station to evaluate the current network.
- (3)
- Draw the TI index maps by spatially interpolating the values from (2).
- (4)
- Select a regionalization method or a hydrologic model to generate estimated (or synthetic) time series data at potential station locations. In this study, simulated time series from HYPE model by Stadnyk and Bajracharya (2019) were used.
- (5)
- Obtain the daily estimated runoff time series data for potential stations from (4).
- (6)
- Run the dual entropy and multiobjective optimization (DEMO) tool.
- (7)
- Determine the optimal networks and analyze the networks by creating maps of the station selection frequency.
- (8)
- Generate ensemble runoff time series to account for the model uncertainty in runoff estimation.
- (9)
- Run ensemble-based DEMO (EnDEMO) with the ensemble time series. Ten ensemble members were applied in this study.
- (10)
- Analyze the optimal networks from the EnDEMO application and draw maps of the station selection frequency.
- (11)
- Compare the DEMO with the EnDEMO results and make recommendations.
4.1. Ensemble-Based DEMO (EnDEMO)
- Daily estimated flows from each subcatchment are aggregated to monthly streamflow time series. The monthly historical streamflows are log-transformed and then normalized by the sample mean and the standard deviation values, so that the resulting standardized log-transformed monthly streamflow time series follow a standard normal distribution.
- Then synthetic ensembles are randomly populated from the standardized log-transformed monthly flows that satisfy its statistics.
- Additional requirements are set when randomly sampling the synthetic ensemble time series. The method of Cholesky matrix decomposition is used to populate monthly synthetic flows that preserve the month-to-month and year-to-year historical autocorrelation matrix of the raw log-transformed streamflow time series.
- The ensemble standardized log-transformed flows are transformed back to real space, ensemble, monthly streamflows by de-standardizing and log-inversing.
- The k-nearest neighbor is estimated for each ensemble month from all estimated monthly values collected from the surrounding subcatchments using the real space Euclidean distance.
- The k-nearest neighbors in each month are ranked from the nearest to the furthest sites.
- Using a Kernel estimator, the probability of selecting a neighbor is estimated for each site that has an estimated daily time series and the closest neighbor is selected accordingly.
- The final step is to proportionally disaggregate the ensemble monthly streamflow to daily time series using the selected neighboring site.
4.2. Hydrological Prediction for the Environment (HYPE) Model
5. Results and Discussions
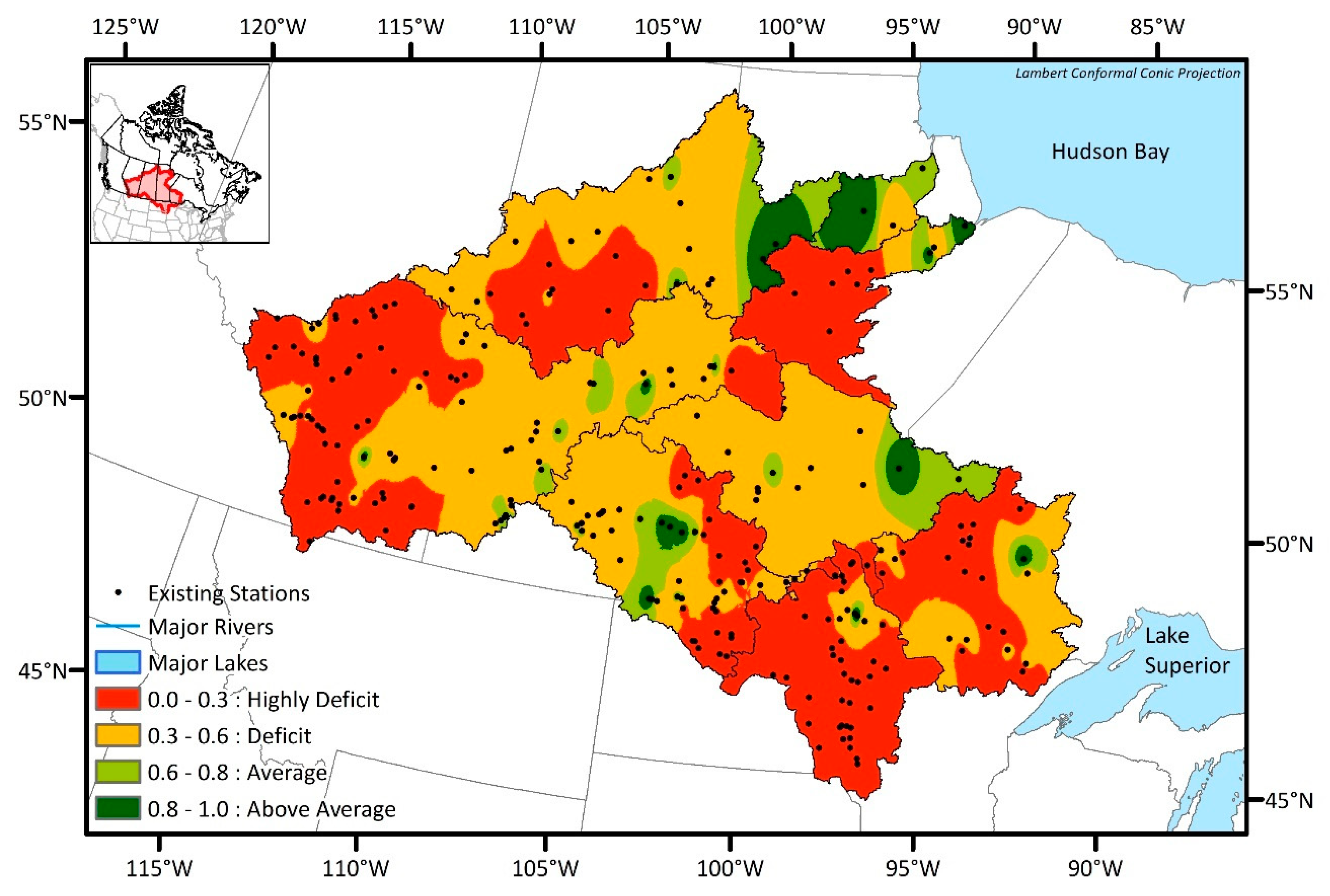
5.1. TI Index Map
- Highly Deficit: TI index of 0.0 to 0.3;
- Deficit: TI index of 0.3 to 0.6;
- Average: TI index of 0.6 to 0.8;
- Above Average: TI index of 0.8 to 1.0.
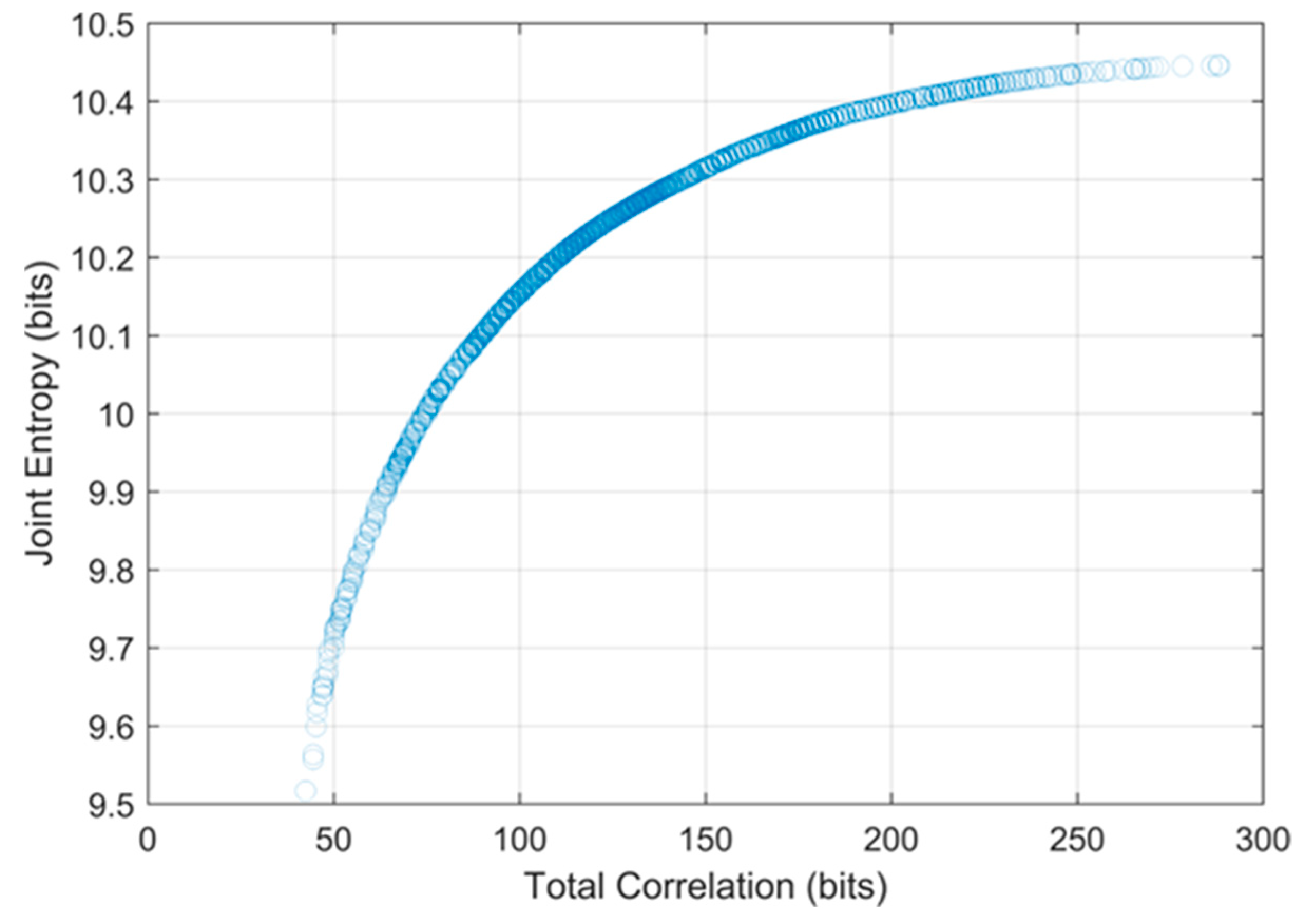
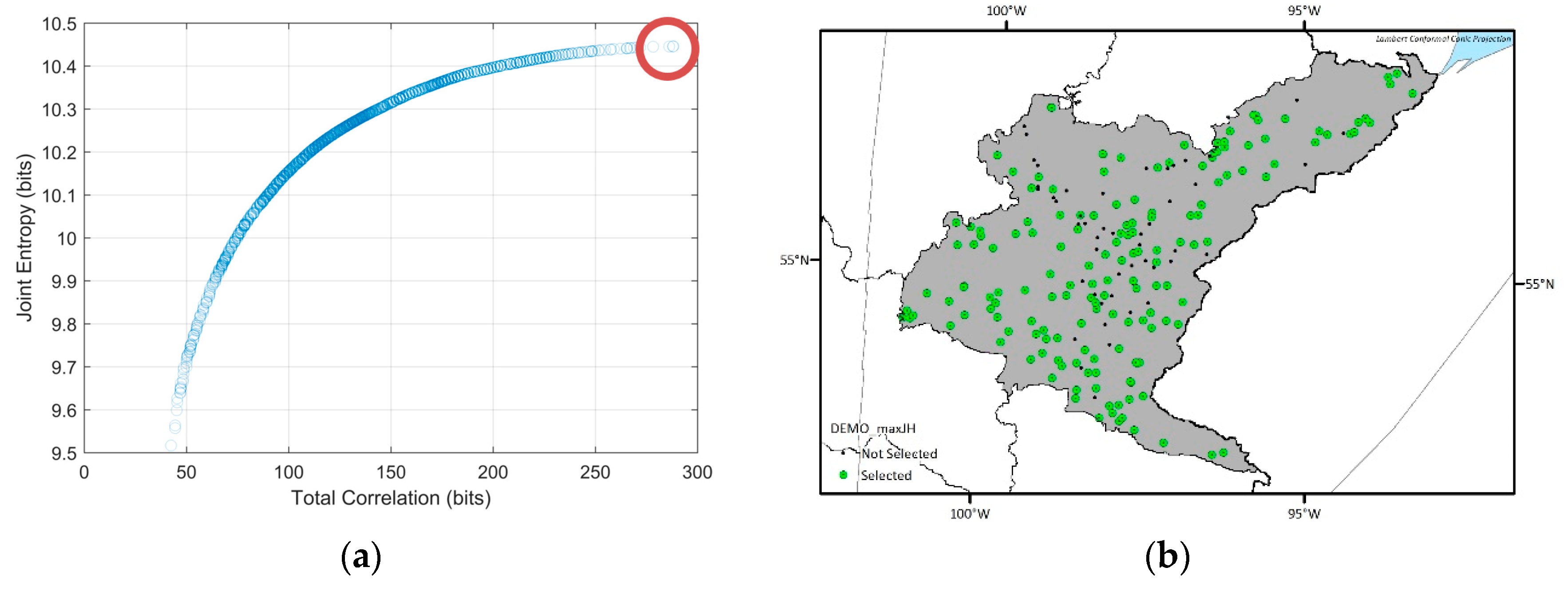
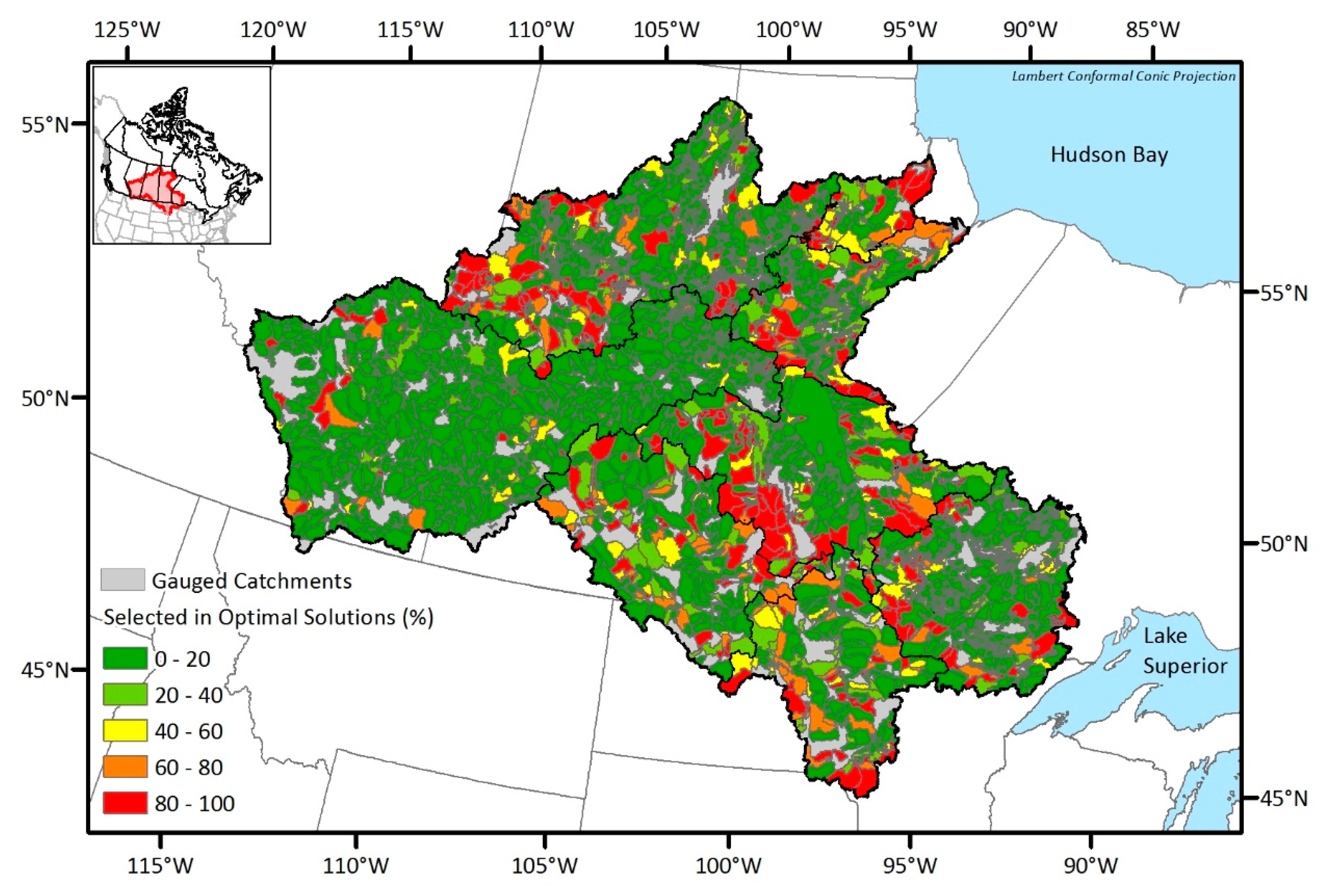
5.2. DEMO Results
5.3. Uncertainty Considerations using EnDEMO
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Langbein, W.B. Overview of Conference on Hydrologic Data Networks. Water Resour. Res. 1979, 15, 1867–1871. [Google Scholar] [CrossRef]
- Herschy, R.W. Hydrometry: Principles and Practice, 2nd ed.; John Wiley & Sons: Chichester, UK, 1999; ISBN 978-0-471-97350-8. [Google Scholar]
- Boiten, W. Hydrometry; A.A. Balkema Publishers: Lisse, The Netherlands, 2003. [Google Scholar]
- Keum, J.; Kornelsen, K.; Leach, J.; Coulibaly, P. Entropy Applications to Water Monitoring Network Design: A Review. Entropy 2017, 19, 613. [Google Scholar] [CrossRef]
- Keum, J.; Coulibaly, P. Information theory-based decision support system for integrated design of multi-variable hydrometric networks. Water Resour. Res. 2017, 53, 6239–6259. [Google Scholar] [CrossRef]
- Pilon, P.J.; Yuzyk, T.R.; Hale, R.A.; Day, T.J. Challenges Facing Surface Water Monitoring in Canada. Can. Water Resour. J. 1996, 21, 157–164. [Google Scholar] [CrossRef]
- Babbit, B.; Groat, C.G. Streamflow Information for the Next Century—A Plan for the National Streamflow Information Program of the U.S. Geological Survey; U.S. Geological Survey: Reston, VA, USA, 1999; pp. 99–456. Available online: https://pubs.usgs.gov/of/1999/ofr99456/ (accessed on 26 September 2019).
- Mishra, A.K.; Coulibaly, P. Developments in Hydrometric Network Design: A Review. Rev. Geophys. 2009, 47, RG2001. [Google Scholar] [CrossRef]
- Li, S.; Heng, S.; Siev, S.; Yoshimura, C.; Ly, S. Multivariate interpolation and information entropy for optimizing raingauge network in the Mekong River Basin. Hydrol. Sci. J. 2019, 1–14. [Google Scholar] [CrossRef]
- Ridolfi, E.; Rianna, M.; Trani, G.; Alfonso, L.; Di Baldassarre, G.; Napolitano, F.; Russo, F. Advances in Water Resources A new methodology to define homogeneous regions through an entropy based clustering method. Adv. Water Resour. 2016, 96, 237–250. [Google Scholar] [CrossRef]
- Mahmoudi-Meimand, H.; Nazif, S.; Abbaspour, R.A.; Sabokbar, H.F. An algorithm for optimisation of a rain gauge network based on geostatistics and entropy concepts using GIS. J. Spat. Sci. 2016, 61, 233–252. [Google Scholar] [CrossRef]
- Werstuck, C.; Coulibaly, P. Assessing Spatial Scale Effects on Hydrometric Network Design Using Entropy and Multi-objective Methods. J. Am. Water Resour. Assoc. 2018, 54, 275–286. [Google Scholar] [CrossRef]
- Leach, J.M.; Kornelsen, K.C.; Samuel, J.; Coulibaly, P. Hydrometric network design using streamflow signatures and indicators of hydrologic alteration. J. Hydrol. 2015, 529, 1350–1359. [Google Scholar] [CrossRef]
- Keum, J.; Coulibaly, P. Sensitivity of Entropy Method to Time Series Length in Hydrometric Network Design. J. Hydrol. Eng. 2017, 22, 04017009. [Google Scholar] [CrossRef]
- Keum, J.; Coulibaly, P.; Razavi, T.; Tapsoba, D.; Gobena, A.; Weber, F.; Pietroniro, A. Application of SNODAS and hydrologic models to enhance entropy-based snow monitoring network design. J. Hydrol. 2018, 561, 688–701. [Google Scholar] [CrossRef]
- Keum, J.; Coulibaly, P.; Pietroniro, A. Assessing the Effect of Streamflow Estimation at Potential Station Locations in Entropy-Based Hydrometric Network Design. In EPiC Series in Engineering (HIC 2018); La Loggia, G., Freni, G., Puleo, V., De Marchis, M., Eds.; 2018; Volume 3, pp. 1048–1054. [Google Scholar]
- Samuel, J.; Coulibaly, P.; Kollat, J.B. CRDEMO: Combined Regionalization and Dual Entropy-Multiobjective Optimization for Hydrometric Network Design. Water Resour. Res. 2013, 49, 8070–8089. [Google Scholar] [CrossRef]
- Alfonso, L.; Lobbrecht, A.; Price, R. Information theory-based approach for location of monitoring water level gauges in polders. Water Resour. Res. 2010, 46, W03528. [Google Scholar] [CrossRef]
- Alfonso, L.; Lobbrecht, A.; Price, R. Optimization of water level monitoring network in polder systems using information theory. Water Resour. Res. 2010, 46, W12553. [Google Scholar] [CrossRef]
- Alfonso, L.; Ridolfi, E.; Gaytan-Aguilar, S.; Napolitano, F.; Russo, F. Ensemble Entropy for Monitoring Network Design. Entropy 2014, 16, 1365–1375. [Google Scholar] [CrossRef] [Green Version]
- Zubrycki, K.; Roy, D.; Osman, H.; Lewtas, K.; Gunn, G.; Grosshans, R. Large Area Planning in the Nelson-Churchill River Basin (NCRB): Laying a foundation in northern Manitoba; International Institute for Sustainable Development (IISD): Winnipeg, MB, Canada, 2016. [Google Scholar]
- World Meteorological Organization. Guide to Hydrological Practices, Volume I Hydrology—From Measurement to Hydrological Information; WMO: Geneva, Switzerland, 2008; Volume WMO-No. 168; Sixth; ISBN 978-92-63-10168-6. [Google Scholar]
- Stadnyk, T.; Bajracharya, A.R. HYPE Model Output for NCRB using Hydro-GFD Reanalysis Dataset. Unpublished work. 2019. [Google Scholar]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Krstanovic, P.F.; Singh, V.P. Evaluation of Rainfall Networks using Entropy: I. Theoretical Development. Water Resour. Manag. 1992, 6, 279–293. [Google Scholar] [CrossRef]
- Mishra, A.K.; Coulibaly, P. Hydrometric Network Evaluation for Canadian Watersheds. J. Hydrol. 2010, 380, 420–437. [Google Scholar] [CrossRef]
- Mishra, A.K.; Coulibaly, P. Variability in Canadian Seasonal Streamflow Information and Its Implication for Hydrometric Network Design. J. Hydrol. Eng. 2014, 19, 05014003. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef] [Green Version]
- Quinn, J.D.; Reed, P.M.; Giuliani, M.; Castelletti, A. Rival framings: A framework for discovering how problem formulation uncertainties shape risk management trade-offs in water resources systems. Water Resour. Res. 2017, 53, 7208–7233. [Google Scholar] [CrossRef]
- Kirsch, B.R.; Characklis, G.W.; Zeff, H.B. Evaluating the Impact of Alternative Hydro-Climate Scenarios on Transfer Agreements: Practical Improvement for Generating Synthetic Streamflows. J. Water Resour. Plan. Manag. 2013, 139, 396–406. [Google Scholar] [CrossRef]
- Nowak, K.; Prairie, J.; Rajagopalan, B.; Lall, U. A nonparametric stochastic approach for multisite disaggregation of annual to daily streamflow. Water Resour. Res. 2010, 46. [Google Scholar] [CrossRef]
- Lindstrom, G.; Pers, C.; Rosberg, J.; Stromqvist, J.; Arheimer, B. Development and testing of the HYPE (Hydrological Predictions for the Environment) water quality model for different spatial scales. Hydrol. Res. 2010, 41, 295–319. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sub-Basins | Numbers of Existing Stations | Numbers of Potential Stations |
|---|---|---|
| Assiniboine | 54 | 271 |
| Red | 41 | 218 |
| Winnipeg | 25 | 377 |
| Lake Winnipeg | 14 | 294 |
| Saskatchewan | 98 | 695 |
| Nelson | 9 | 219 |
| Upper Churchill | 23 | 556 |
| Lower Churchill | 3 | 61 |
| Model Parameters | Parameter Value |
|---|---|
| Population Size | 3000 |
| Maximum Generations | 6000 |
| Number of Decision Variables | Number of Potential Stations (N) |
| Crossover Operator | Single Point Crossover |
| Crossover Probability | 1.0 |
| Mutation Operator | Bit String Mutation |
| Mutation Probability | 2/N |
| Variable Type | Binary |
| Sub-Basins | Numbers of Optimal Networks | Numbers of Selected Station Range | Joint Entropy Range (bits) | Total Correlation Range (bits) |
|---|---|---|---|---|
| Assiniboine | 1343 | 29–219 | 10.57–11.39 | 37.76–227.91 |
| Red | 1191 | 19–179 | 9.22–10.78 | 19.03–158.54 |
| Winnipeg | 1134 | 34–228 | 10.95–11.47 | 57.31–333.89 |
| Lake Winnipeg | 1415 | 60–262 | 10.87–11.63 | 65.66–344.52 |
| Saskatchewan | 685 | 22–162 | 11.47–11.82 | 70.80–235.38 |
| Nelson | 1205 | 33–190 | 9.52–10.45 | 42.45–288.14 |
| Upper Churchill | 1036 | 70–319 | 10.99–11.54 | 82.35–456.01 |
| Lower Churchill | 454 | 6–57 | 5.24–7.25 | 5.13–76.48 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Keum, J.; Awol, F.S.; Ursulak, J.; Coulibaly, P. Introducing the Ensemble-Based Dual Entropy and Multiobjective Optimization for Hydrometric Network Design Problems: EnDEMO. Entropy 2019, 21, 947. https://doi.org/10.3390/e21100947
Keum J, Awol FS, Ursulak J, Coulibaly P. Introducing the Ensemble-Based Dual Entropy and Multiobjective Optimization for Hydrometric Network Design Problems: EnDEMO. Entropy. 2019; 21(10):947. https://doi.org/10.3390/e21100947
Chicago/Turabian StyleKeum, Jongho, Frezer Seid Awol, Jacob Ursulak, and Paulin Coulibaly. 2019. "Introducing the Ensemble-Based Dual Entropy and Multiobjective Optimization for Hydrometric Network Design Problems: EnDEMO" Entropy 21, no. 10: 947. https://doi.org/10.3390/e21100947
APA StyleKeum, J., Awol, F. S., Ursulak, J., & Coulibaly, P. (2019). Introducing the Ensemble-Based Dual Entropy and Multiobjective Optimization for Hydrometric Network Design Problems: EnDEMO. Entropy, 21(10), 947. https://doi.org/10.3390/e21100947