Influence of Technological Innovations on Industrial Production: A Motif Analysis on the Multilayer Network †


Abstract
:1. Introduction
2. Materials and Methods
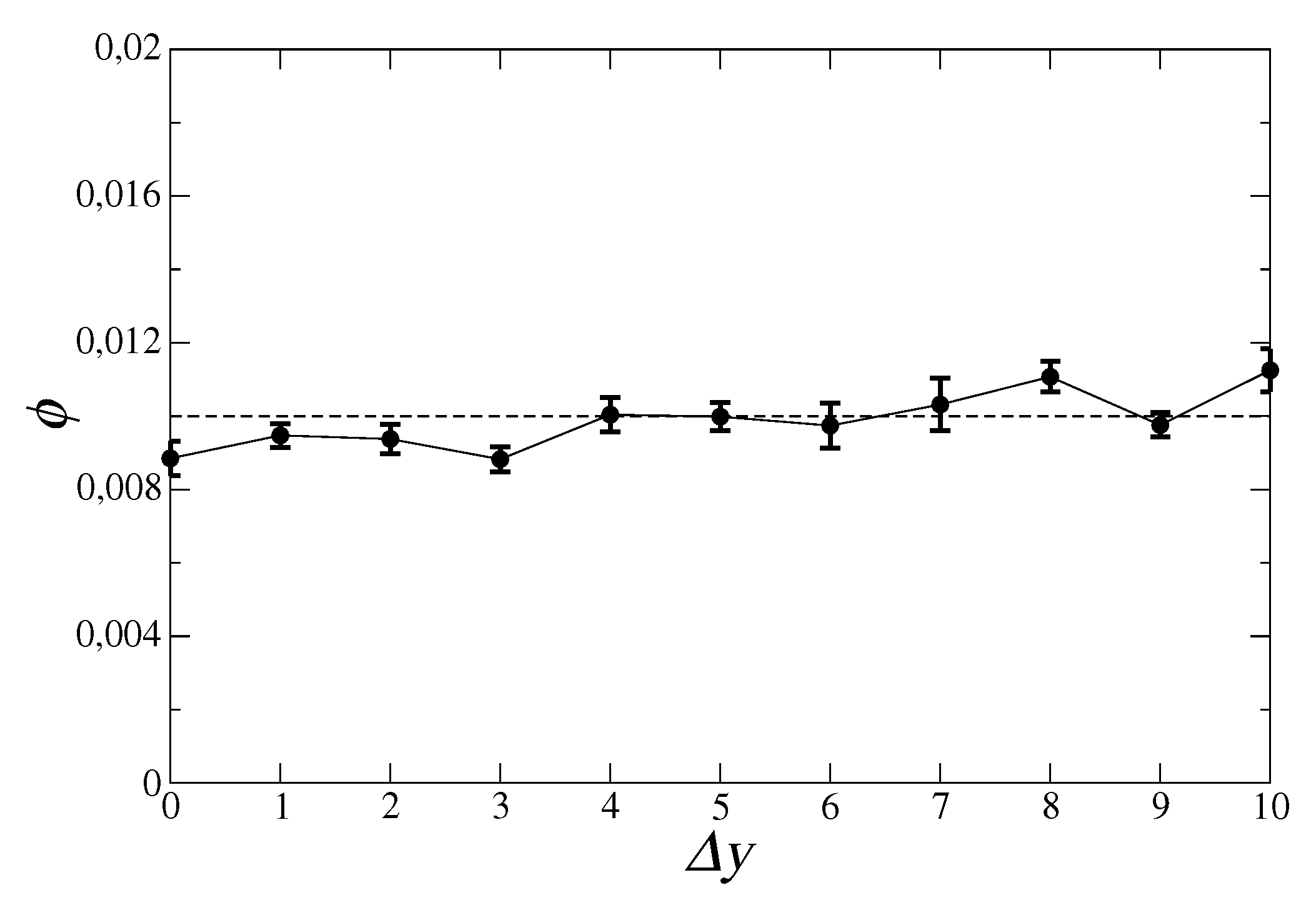
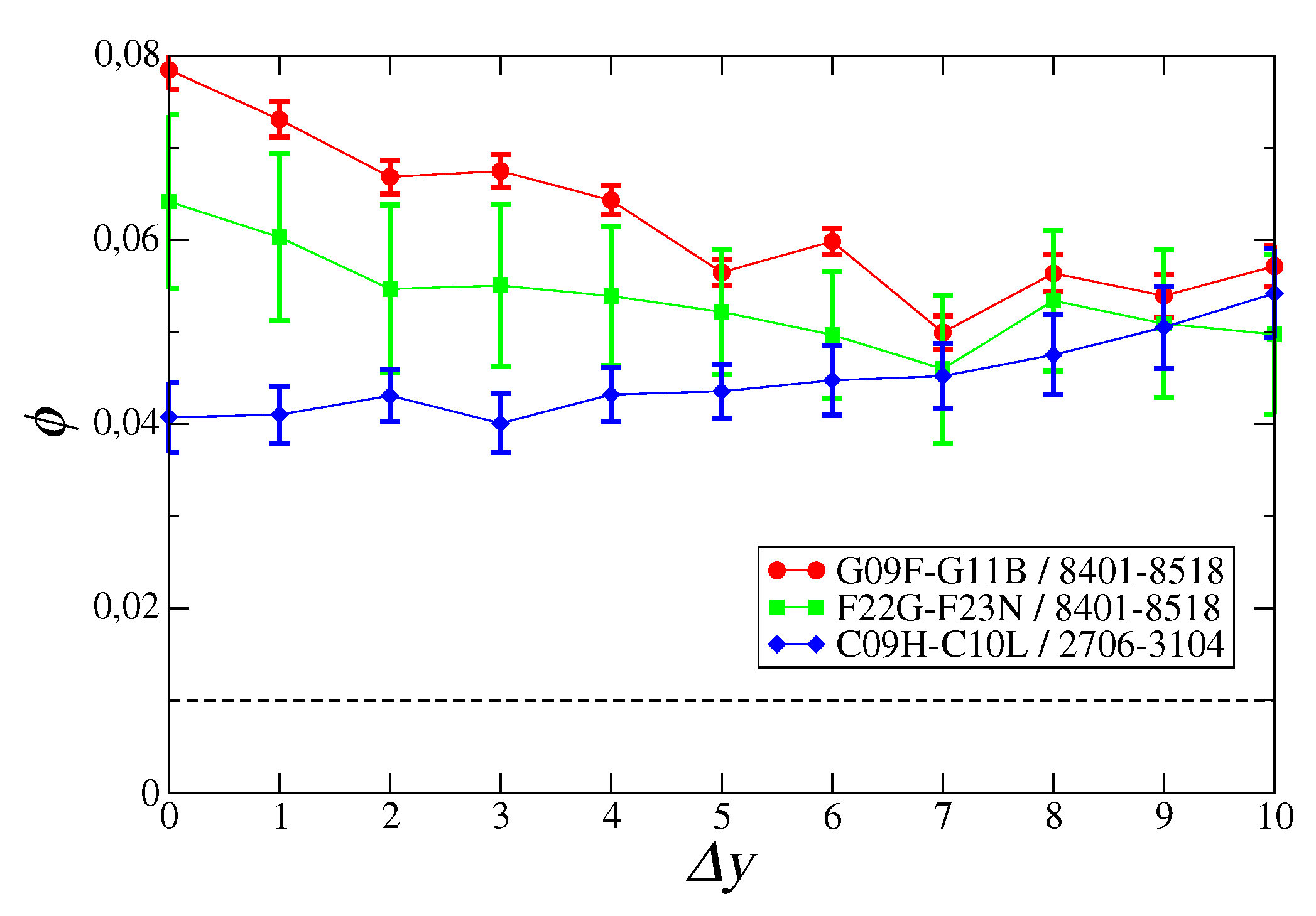
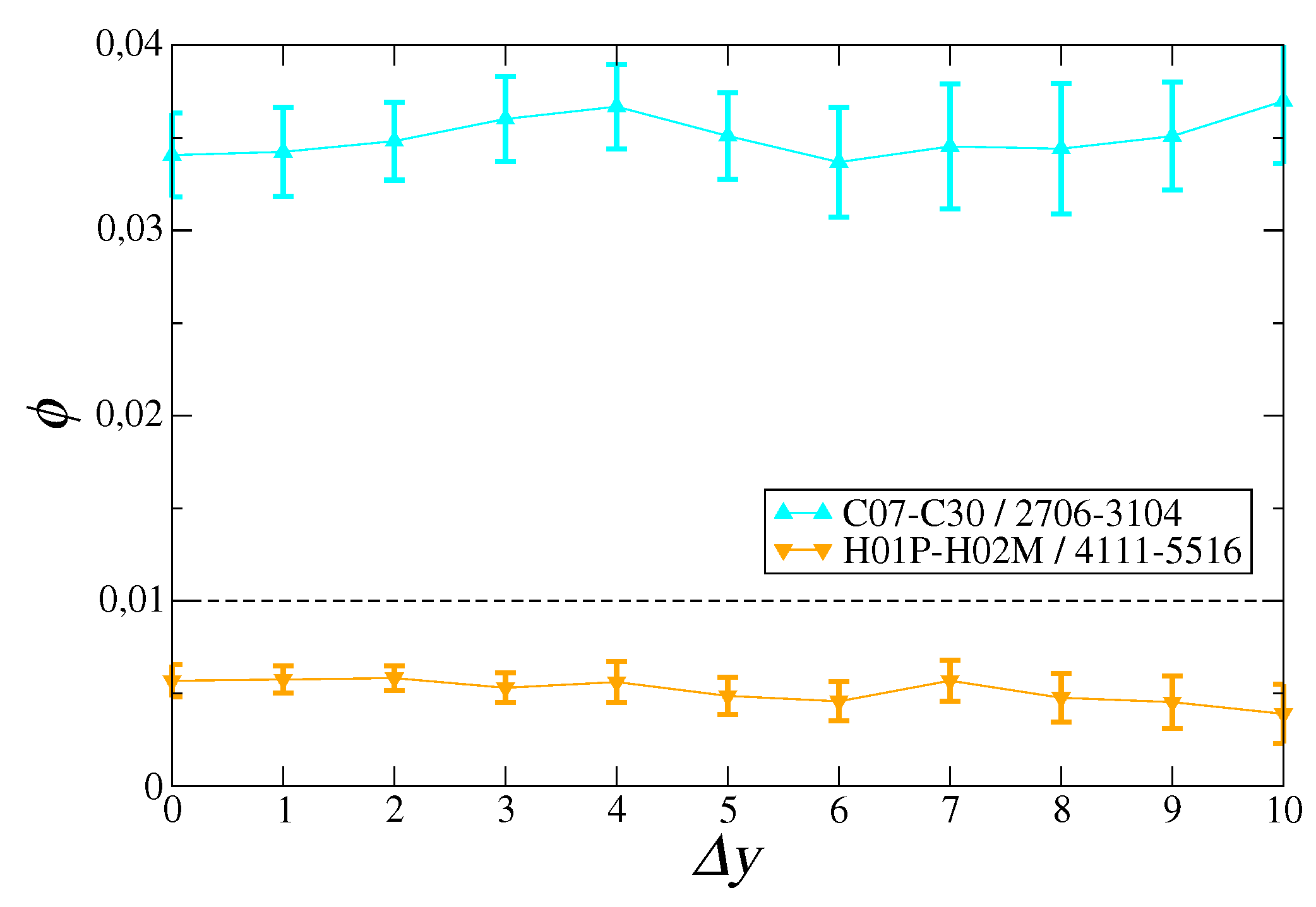
3. Results
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. Bipartite Configuration Model (BiCM) and Assist-Matrix Null Model
- Through a constrained maximum-entropy approach, we define ensemble of bipartite networks that are maximally random, apart from the ensemble average of the node degrees on both layers of the bipartite network that are constrained to generic fixed values. Such an ensemble is thus an instance of an Exponential Random Binary Graph (ERBG).
- In order to determine the ERBG that best represents the empirical bipartite network, we use a maximal-likelihood argument showing that the mean values of the node degrees have to be taken equal to the observed ones in the empirical network [30]: , and , , where we have indicated with k the observed degrees in the real network, and with the degrees in a generic configuration of the null model. We remind that and , and analogously for "tilded" quantities.
References
- Freeman, C. Technology Policy and Economic Performance; Pinter Publishers: London, UK; New York, NY, USA, 1987. [Google Scholar]
- Romer, P.M. Endogenous technological change. J. Polit. Econ. 1990, 98, S71–S102. [Google Scholar] [CrossRef]
- Krugman, P. A model of innovation, technology transfer and the world distributon of income. J. Polit. Econ. 1979, 87, 253–266. [Google Scholar] [CrossRef]
- Soete, L. The impact of technological innovation on international trade patterns: The evidence reconsidered. In Output Measurement in Science and Technology; Elsevier: New York, NY, USA, 1987; pp. 47–76. [Google Scholar]
- Dosi, G.; Pavitt, K.; Soete, L. The Economics of Technical Change and International Trade; Laboratory of Economics and Management (LEM), Sant’Anna School of Advanced Studies: Pisa, Italy, 1990. [Google Scholar]
- Verspagen, B. Uneven Growth Between Interdependent Economies: An Evolutionary View on Technology Gaps, Trade, and Growth; Doctor of Philosophy, Maastricht University: Maastricht, The Netherlands, 1992. [Google Scholar]
- Nelson, R.R. National Innovation Systems: A Comparative Analysis; Oxford University Press: Oxford, UK, 1993. [Google Scholar]
- Griffith, R.; Redding, S.; van Reenen, J. Mapping the two faces of R&D: Productivity growth in a panel of OECD industries. Rev. Econ. Stat. 2004, 86, 883–895. [Google Scholar]
- Bronwyn, H.; Mairesse, H.; Mohnen, P. Measuring the Returns to R&D. In Handbook of the Economics of Innovation; Elsevier: New York, NY, USA, 2010; pp. 1033–1082. [Google Scholar]
- European Commission. 2009. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=celex%3A52009DC0512 (accessed on 27 January 2019).[Green Version]
- Junker, J.C. 2015. Available online: https://ec.europa.eu/commission/sites/beta-political/files/juncker-political-guidelines-speech_en.pdf (accessed on 27 January 2019).
- Devaraj, S.; Kohli, R. Information technology payoff in the health-care industry: A longitudinal study. J. Manag. Inf. Syst. 2000, 16, 41–67. [Google Scholar] [CrossRef]
- Sher, P.J.; Yang, P.Y. The effects of innovative capabilities and R&D clustering on firm performance: The evidence of Taiwan’s semiconductor industry. Technovation 2005, 25, 33–43. [Google Scholar]
- Pugliese, E.; Cimini, G.; Patelli, A.; Zaccaria, A.; Pietronero, L.; Gabrielli, A. Unfolding the innovation system for the development of countries: Co-evolution of Science, Technology and Production. arXiv, 2017; arXiv:1707.05146. [Google Scholar]
- Tacchella, A.; Cristelli, M.; Caldarelli, G.; Gabrielli, A.; Pietronero, L. A new metrics for countries’ fitness and products’ complexity. Sci. Rep. 2012, 2, 723. [Google Scholar] [CrossRef]
- Cristelli, M.; Gabrielli, A.; Caldarelli, G.; Tacchella, A.; Pietronero, L. Measuring the intangibles: A metrics for the economic complexity of countries and products. PLoS ONE 2013, 8, e7072. [Google Scholar] [CrossRef]
- Cimini, G.; Gabrielli, A.; Sylos Labini, F. The scientific competitiveness of nations. PLoS ONE 2014, 9, e113470. [Google Scholar]
- Zaccaria, A.; Cristelli, M.; Tacchella, A.; Pietronero, L. How the taxonomy of products drives the economic development of countries. PLoS ONE 2014, 9, e113770. [Google Scholar] [CrossRef]
- Milo, R.; Shen-Orr, S.; Itzkovitz, S.; Kashtan, N.; Chklovskii, D.; Alon, U. Network motifs: Simple building blocks of complex networks. Science 2002, 298, 824–827. [Google Scholar] [CrossRef]
- Saracco, F.; di Clemente, R.; Gabrielli, A.; Squartini, T. Randomizing bipartite networks: The case of the World Trade Web. Sci. Rep. 2015, 5, 10595. [Google Scholar] [CrossRef] [PubMed]
- Youn, H.; Strumsky, D.; Bettencourt, L.M.; Lobo, J. Invention as a combinatorial process: Evidence from US patents. J. R. Soc. Interface 2015, 12, 20150272. [Google Scholar] [CrossRef] [PubMed]
- Balassa, B. Trade liberalisation and “revealed” comparative advantage. Manch. Sch. 1965, 33, 99. [Google Scholar] [CrossRef]
- Jaynes, E.T. Information theory and statistical mechanics. Phys. Rev. 1957, 106, 620–630. [Google Scholar] [CrossRef]
- Park, J.; Newman, M.E. Statistical mechanics of networks. J. Phys. Rev. E 2004, 70, 066117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cimini, G.; Squartini, T.; Saracco, F.; Garlaschelli, D.; Gabrielli, A.; Caldarelli, G. The statistical physics of real-world networks. Nat. Rev. Phys. 2019, 1, 58–71. [Google Scholar] [CrossRef]
- Gualdi, S.; Cimini, G.; Primicerio, K.; di Clemente, R.; Challet, D. Statistically validated network of portfolio overlaps and systemic risk. Sci. Rep. 2016, 6, 39467. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Saracco, F.; Straka, M.J.; di Clemente, R.; Gabrielli, A.; Squartini, T. Inferring monopartite projections of bipartite networks: An entropy-based approach. New J. Phys. 2017, 19, 053022. [Google Scholar] [CrossRef]
- Zweig, K.; Kaufmann, M. A systematic approach to the one-mode projection of bipartite graphs. Soc. Netw. Anal. Min. 2011, 1, 187–218. [Google Scholar] [CrossRef]
- Neal, Z. The backbone of bipartite projections: Inferring relationships from co-authorship, co-sponsorship, co-attendance and other co-behaviors. Soc. Netw. 2014, 39, 84–97. [Google Scholar] [CrossRef]
- Squartini, T.; Caldarelli, G.; Cimini, G.; Gabrielli, A.; Garlaschelli, D. Reconstruction methods for networks: The case of economic and financial systems. Phys. Rep. 2018, 757, 1–47. [Google Scholar] [CrossRef]
- Huang, K. Statistical Mechanics; John Wiley & Sons: New York, NY, USA, 1987. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| p-Value | p, t, |
|---|---|
| 4701: Wood pulp. | |
| C05B: Lime; magnesia; slag; cements. | |
| C09K: Materials for applications not otherwise provided for. | |
| 2605: Mineral products. | |
| C21D: Modifying the physical structure of ferrous metals. | |
| F04F: Pumping of fluid by direct contact of another fluid or by using inertia of fluid to be pumped. | |
| 2605: Mineral products. | |
| C21D: Modifying the physical structure of ferrous metals. | |
| F04F: Working metallic powder. | |
| 8443: Printing machine. | |
| D02H: Mechanical methods or apparatus in the manufacture of artificial filaments. | |
| G01T Measurement of nuclear or x-radiation. | |
| 4703: Chemical wood pulp. | |
| D21F: Decorating textiles | |
| B27C: Planing, drilling, milling, turning, or universal machines. | |
| 2605: Mineral products. | |
| C21D: Modifying the physical structure of ferrous metals. | |
| FF15B: Systems acting by means of fluids in general. | |
| 4703: Chemical wood pulp. | |
| D21F: Paper-making machines. | |
| F03D: Wind motors. | |
| 4703: Chemical wood pulp. | |
| D21F: Paper-making machines. | |
| D06Q: Decorating textiles. | |
| 8519: Sound recording or reproducing apparatus. | |
| G10K: Sound-producing devices. | |
| G01T: Capacitors, rectifiers, detectors, switching devices. | |
| 8519: Sound recording or reproducing apparatus. | |
| G10K: Sound-producing devices. | |
| G04f: Time-interval measuring. |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Formichini, M.; Cimini, G.; Pugliese, E.; Gabrielli, A. Influence of Technological Innovations on Industrial Production: A Motif Analysis on the Multilayer Network. Entropy 2019, 21, 126. https://doi.org/10.3390/e21020126
Formichini M, Cimini G, Pugliese E, Gabrielli A. Influence of Technological Innovations on Industrial Production: A Motif Analysis on the Multilayer Network. Entropy. 2019; 21(2):126. https://doi.org/10.3390/e21020126
Chicago/Turabian StyleFormichini, Martina, Giulio Cimini, Emanuele Pugliese, and Andrea Gabrielli. 2019. "Influence of Technological Innovations on Industrial Production: A Motif Analysis on the Multilayer Network" Entropy 21, no. 2: 126. https://doi.org/10.3390/e21020126
APA StyleFormichini, M., Cimini, G., Pugliese, E., & Gabrielli, A. (2019). Influence of Technological Innovations on Industrial Production: A Motif Analysis on the Multilayer Network. Entropy, 21(2), 126. https://doi.org/10.3390/e21020126