Multi-Scale Feature Fusion for Coal-Rock Recognition Based on Completed Local Binary Pattern and Convolution Neural Network



Abstract
:1. Introduction
2. Overview of the Proposed MFFCRR Model
3. Multi-Scale Feature Extraction, Fusion and Recognition
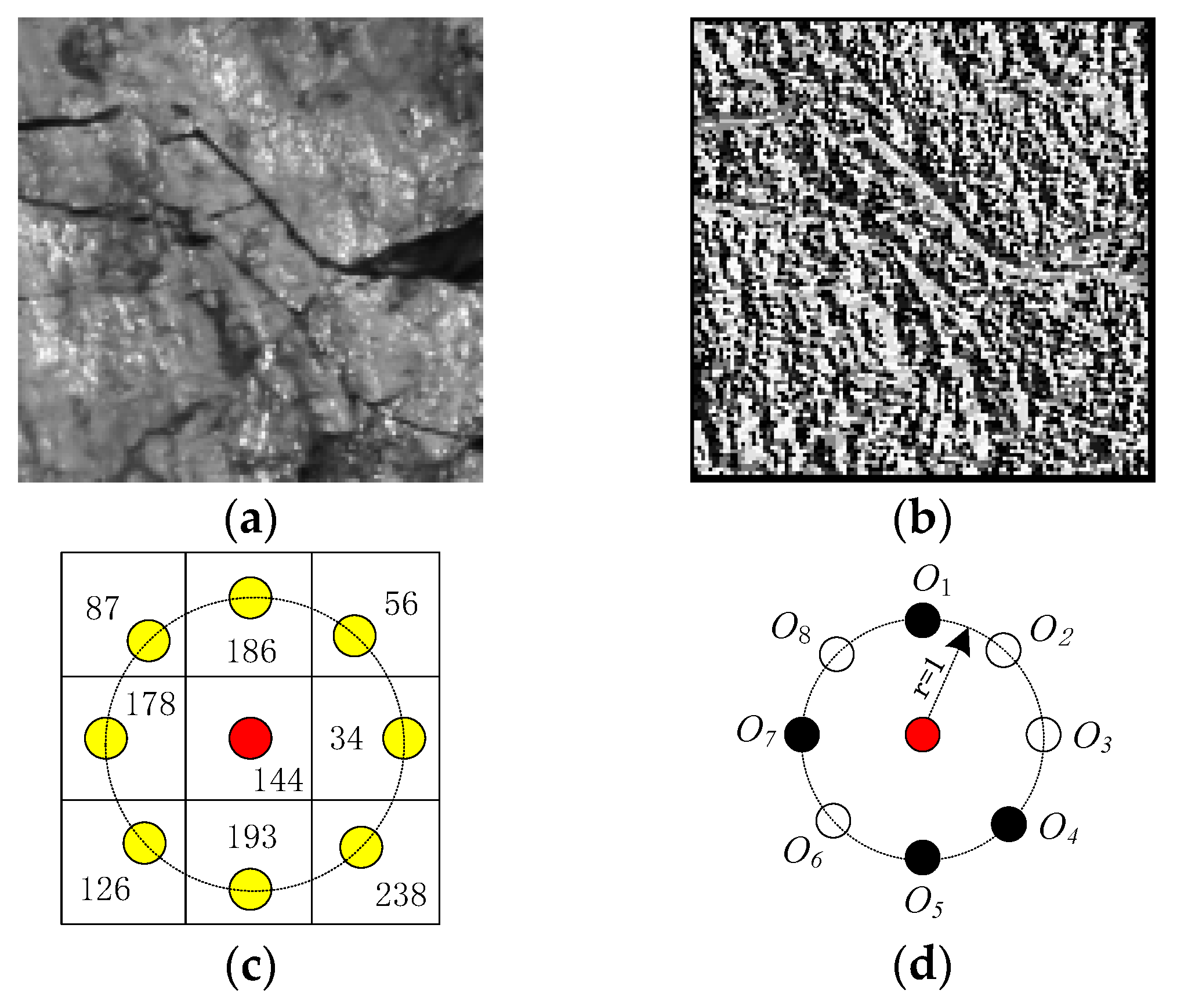
3.1. Texture Feature Extraction Sub-Model (TFE Sub-Model)
3.2. Deep Feature Extraction Sub-Model (DFE Sub-Model)
3.2.1. The Architecture of the DFE Sub-Model
3.2.2. Reducing Overfitting
3.3. Multi-Scale Feature Fusion and Recognition
4. Experimental Results and Discussion
4.1. Dataset
4.2. Evaluation Metrics
- True Positive (TP) denotes the number of correctly recognized examples that belong to the class.
- True Negative (TN) represents the number of correctly recognized examples which do not belong to the class.
- False Positive (FP) denotes the number of incorrectly recognized examples that belong to the class.
- False Negative (FN) represents the number of incorrectly recognized examples which do not belong to the class.
4.3. Parameter Settings
4.3.1. Parameters of the TFE Sub-Model
4.3.2. Parameters of the DFE Sub-Model
4.3.3. Parameters of the Multi-Scale Feature Fusion
4.4. Implementation Details
4.4.1. Activations
4.4.2. ROC Curve
4.4.3. White Gaussian Noise
4.5. Comparison with State-of-the-Art Methods
5. Conclusions and Outlook
Author Contributions
Funding
Conflicts of Interest
References
- Dai, S.; Ren, D.; Chou, C.; Finkelman, R.B.; Seredin, V.V.; Zhou, Y. Geochemistry of trace elements in Chinese coals: A review of abundances, genetic types, impacts on human health, and industrial utilization. Int. J. Coal Geol. 2012, 94, 3–21. [Google Scholar] [CrossRef]
- Dai, S.; Finkelman, R.B. Coal as a promising source of critical elements: Progress and future prospects. Int. J. Coal Geol. 2018, 186, 155–164. [Google Scholar] [CrossRef]
- Seredin, V.V.; Finkelman, R.B. Metalliferous coals: A review of the main genetic and geochemical types. Int. J. Coal Geol. 2008, 76, 253–289. [Google Scholar] [CrossRef]
- Wang, J. Development and prospect on fully mechanized mining in Chinese coal mines. Int. J. Coal Sci. Technol. 2014, 1, 153–260. [Google Scholar] [CrossRef]
- Zheng, K.; Du, C.; Li, J.; Qiu, B.; Yang, D. Metalliferous coals: A review of the main genetic and geochemical types. Poeder Technol. 2015, 278, 223–233. [Google Scholar] [CrossRef]
- Hargrave, C.O.; James, C.A.; Ralston, J.C. Infrastructure-based localisation of automated coal mining equipment. Int. J. Coal Sci. Technol. 2017, 4, 252–261. [Google Scholar] [CrossRef]
- Sun, J.; She, J. Wavelet-based coal-rock image feature extraction and recognition. J. China Coal Soc. 2013, 38, 1900–1904, (in Chinese with English abstract). [Google Scholar]
- Sun, J.; Chen, B. A coal-rock recognition algorithm using wavelet-domain asymmetric generalized Gaussian models. J. China Coal Soc. 2015, 40, 568–575, (in Chinese with English abstract). [Google Scholar]
- Wu, Y.; Tian, Y. Method of coal-rock image feature extraction and recognition based on dictionary learning. J. China Coal Soc. 2016, 41, 3190–3196, (in Chinese with English abstract). [Google Scholar]
- Wu, Y.; Meng, X. Locality-constrained self-taught learning for coal-rock recognition. J. China Coal Soc. 2018, 43, 2639–2646, (in Chinese with English abstract). [Google Scholar]
- Ojala, T.; Pietikainen, M.; Maeenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Zhao, G.; Pietikainen, M. Dynamic texture recognition using local binary patterns with an application to facial expressions. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 27, 915–928. [Google Scholar] [CrossRef] [PubMed]
- Lei, Z.; Pietikainen, M.; Li, S. Learning discriminant face descriptor. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 289–302. [Google Scholar] [PubMed]
- Guo, Z.; Zhang, L.; Zhang, D. A completed modeling of local binary pattern operator for texture classification. IEEE Trans. Image Process. 2010, 19, 1657–1663. [Google Scholar]
- Cheng, J.; Wang, P.S.; Gang, L.I. Recent advances in efficient computation of deep convolutional neural networks. Front. Inf. Technol. Electron. Eng. 2018, 19, 64–77. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. Proc. Eur. Conf. Comput. Vis. 2014, 8691, 346–361. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, L.; Li, H.; Zhang, Q.; Sun, Z. Dynamic Feature Learning for Partial Face Recognition. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7054–7063. [Google Scholar]
- Li, G.; Yu, Y. Deep contrast learning for salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 478–487. [Google Scholar]
- Wen, Z.; Li, Z.; Peng, Y.; Ying, S. Virus image classification using multi-scale completed local binary pattern features extracted from filtered images by multi-scale principal component analysis. Pattern Recogn. Lett. 2016, 79, 25–30. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.B.; Lee, H.; Learned-Miller, E. Learning hierarchical representations for face verification with convolutional deep belief networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2518–2525. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1026–1034. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 26th Annual Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Sokolova, M.; Guy, L. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Powers, D.M.W. Evaluation: From Precision, Recall and F-Factor to ROC, Informedness, Markedness and Correlation. J. Mach. Learn. Technol. 2011, 2, 2229–3981. [Google Scholar]
- Goferman, S.; Zelnik-Manor, L.; Tal, A. Context-aware saliency detection. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1915–1926. [Google Scholar] [CrossRef] [PubMed]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Wu, Y.; Zhang, H. Recognition method of coal-rock images based on curvelet transform and compressed sensing. J. China Coal Soc. 2017, 42, 1331–1338, (in Chinese with English abstract). [Google Scholar]
- Sun, J.; Chen, B. Coal-rock recognition approach based on CLBP and support vector guided dictionary learning. J. China Coal Soc. 2017, 42, 3338–3348, (in Chinese with English abstract). [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
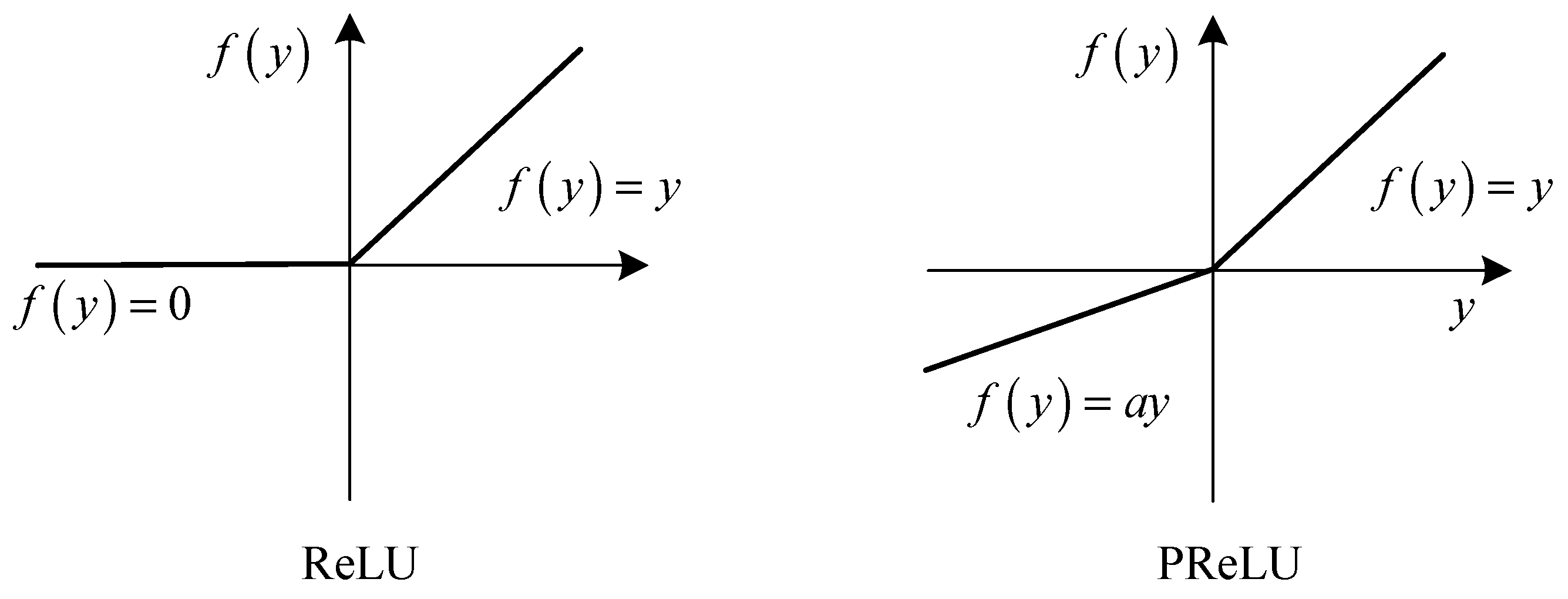{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| P,R | Accuracy (%) | Macro-Average F1 (%) |
|---|---|---|
| 8,1 | 94.3374 | 94.1669 |
| 16,2 | 94.6715 | 94.5173 |
| 24,3 | 94.7917 | 94.6957 |
| 8,1 + 16,2 | 95.8947 | 95.0391 |
| 8,1 + 24,3 | 97.9167 | 97.3333 |
| 16,2 + 24,3 | 95.4169 | 95.1033 |
| 8,1 + 16,2 + 24,3 | 96.7359 | 96.3152 |
| Parameter | Optimization |
|---|---|
| Batch Size | 32 |
| Epochs | 100 |
| Dropout | 0.5 |
| Learning Rate | 0.001 |
| Activation | Accuracy (%) | Macro-Average F1 (%) |
|---|---|---|
| ReLU | 93.3174 | 92.6117 |
| PReLU | 97.9167 | 97.3333 |
| SNR | Accuracy (%) | Macro-Average F1 (%) |
|---|---|---|
| Noiseless | 97.9167 | 97.3333 |
| 25 dB | 93.3171 | 93.1049 |
| 20 dB | 90.1733 | 90.0476 |
| 15 dB | 87.3810 | 86.8947 |
| 10 dB | 75.6349 | 75.1428 |
| 5 dB | 70.8095 | 70.2381 |
| Method | Accuracy (%) | Macro-average F1 (%) |
|---|---|---|
| CT–CS | 93.7513 | 92.9374 |
| CLBP–SVGDL | 94.0526 | 93.9524 |
| LCSL | 95.2857 | 94.7619 |
| CLBP | 93.9168 | 93.1905 |
| CNN | 89.4737 | 89.2281 |
| MFFCRR | 97.9167 | 97.3333 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Jing, W.; Zhou, M.; Li, Y. Multi-Scale Feature Fusion for Coal-Rock Recognition Based on Completed Local Binary Pattern and Convolution Neural Network. Entropy 2019, 21, 622. https://doi.org/10.3390/e21060622
Liu X, Jing W, Zhou M, Li Y. Multi-Scale Feature Fusion for Coal-Rock Recognition Based on Completed Local Binary Pattern and Convolution Neural Network. Entropy. 2019; 21(6):622. https://doi.org/10.3390/e21060622
Chicago/Turabian StyleLiu, Xiaoyang, Wei Jing, Mingxuan Zhou, and Yuxing Li. 2019. "Multi-Scale Feature Fusion for Coal-Rock Recognition Based on Completed Local Binary Pattern and Convolution Neural Network" Entropy 21, no. 6: 622. https://doi.org/10.3390/e21060622
APA StyleLiu, X., Jing, W., Zhou, M., & Li, Y. (2019). Multi-Scale Feature Fusion for Coal-Rock Recognition Based on Completed Local Binary Pattern and Convolution Neural Network. Entropy, 21(6), 622. https://doi.org/10.3390/e21060622