Kernel Mixture Correntropy Conjugate Gradient Algorithm for Time Series Prediction


 ,
, 



Abstract
:1. Introduction
2. Related Work
2.1. Mixture Correntropy
2.2. Kernel Conjugate Gradient Algorithm
| Algorithm 1 The conjugate gradient (CG) algorithm. |
| Input: Given symmetric positive definite matrix ; Given the vector ; Given the initial iteration value ; Initialization: ; ; repeat fordo ifthen return ; endelse ; ; ; ; ; end end until Stopping_Criterion is met. |
| Algorithm 2 The kernel conjugate gradient (KCG) algorithm. |
| Initialization: ; ; repeat fordo ; ; ifthen ; ; ; ; ; ; ; ; ; ; end end until Stopping_Criterion is met. |
2.3. Sparsification Criterion
3. The Proposed Algorithm
3.1. Half-Quadratic Optimization of the Mixture Correntropy
3.2. Kernel Mixture Correntropy Conjugate Gradient Algorithm
| Algorithm 3 The kernel mixture correntropy conjugate gradient (KMCCG) algorithm. |
| Initialization: ; ; repeat fordo ; ; ifthen ; ; ; ; ; ; ; ; ; ; ; ; end end until Stopping_Criterion is met. |
3.3. Computational Time Complexity Analysis
4. Experimental Results and Discussions
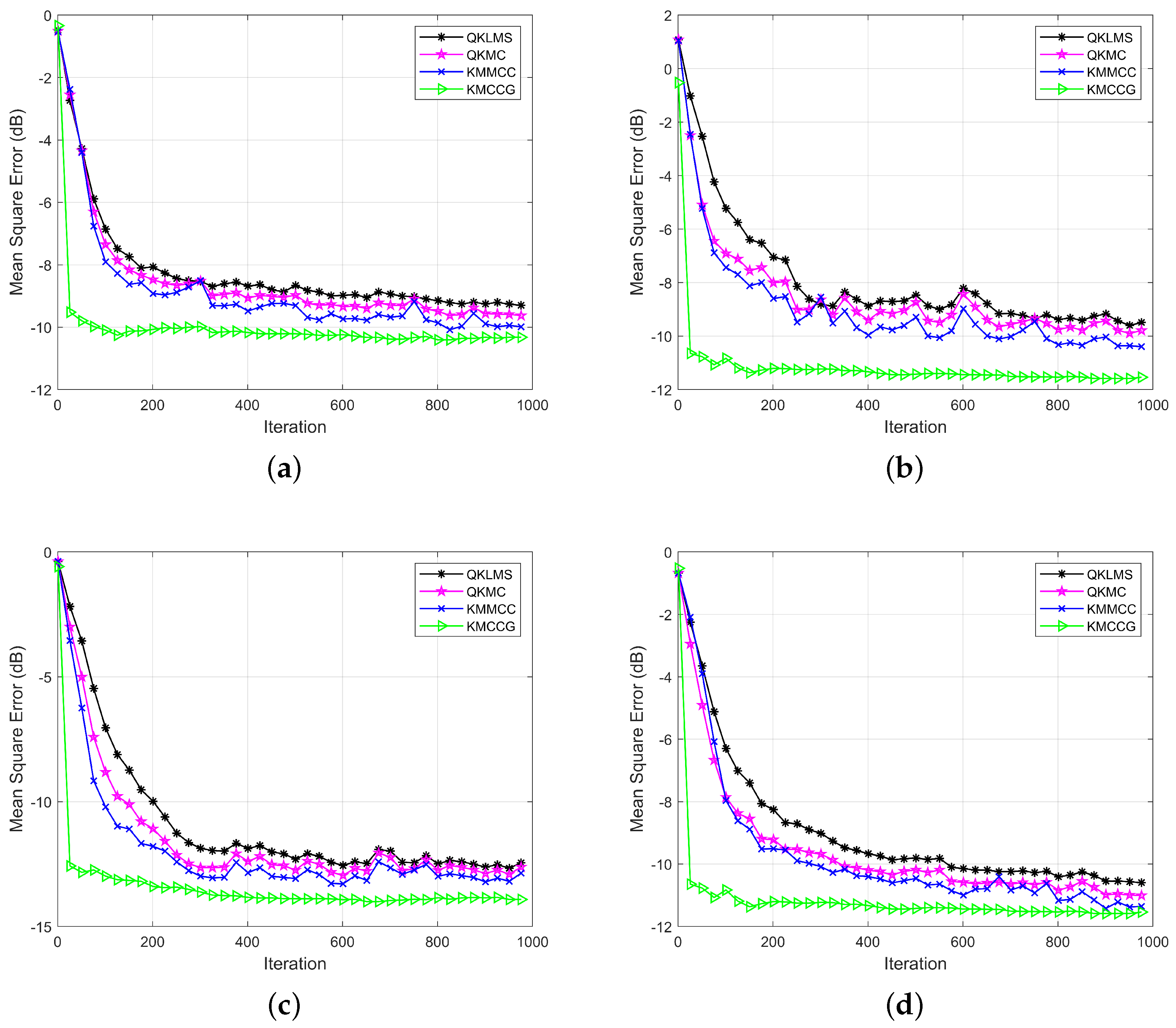
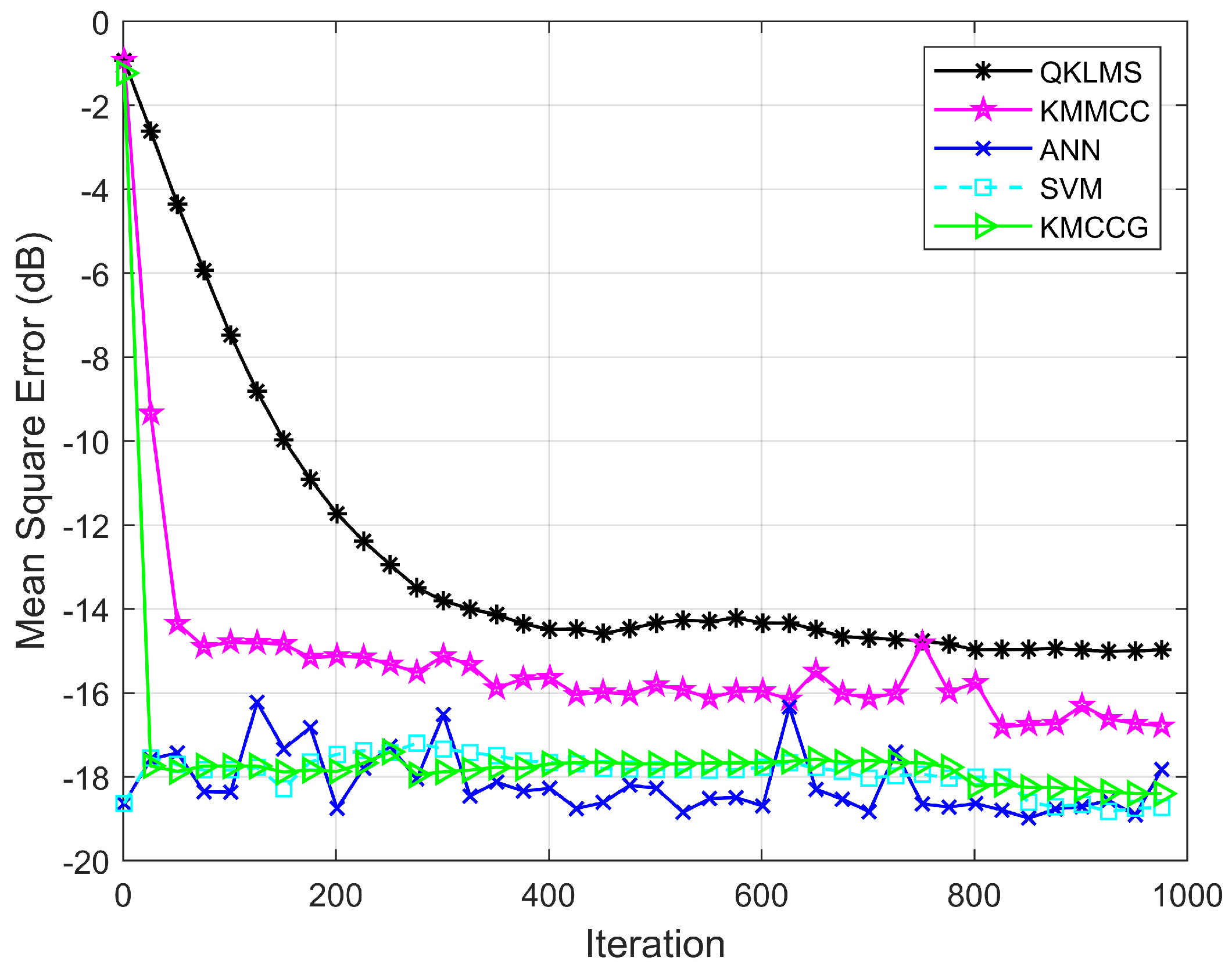
4.1. Mackey–Glass Time Series Prediction
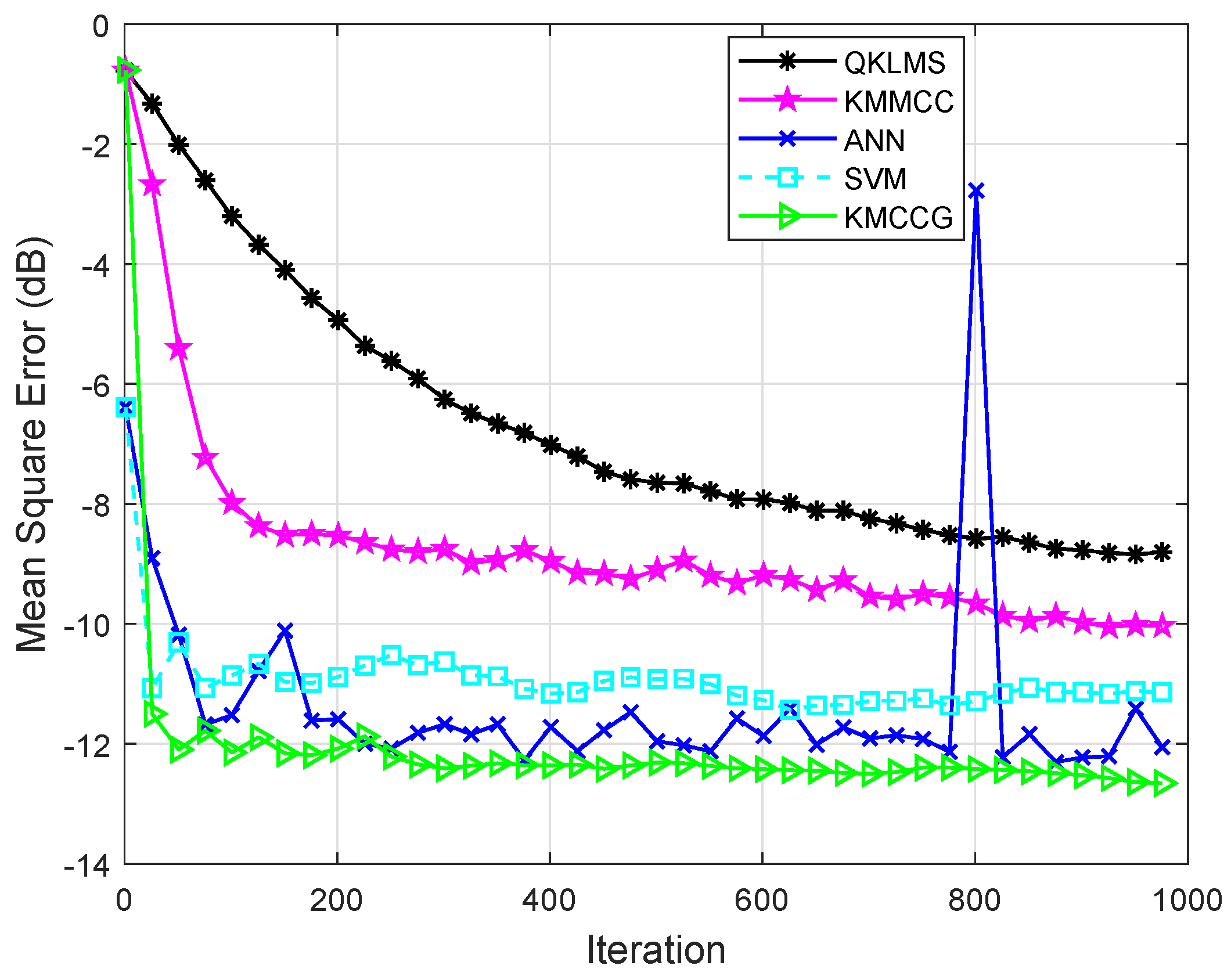
4.2. Minimum Daily Temperatures Time Series Prediction
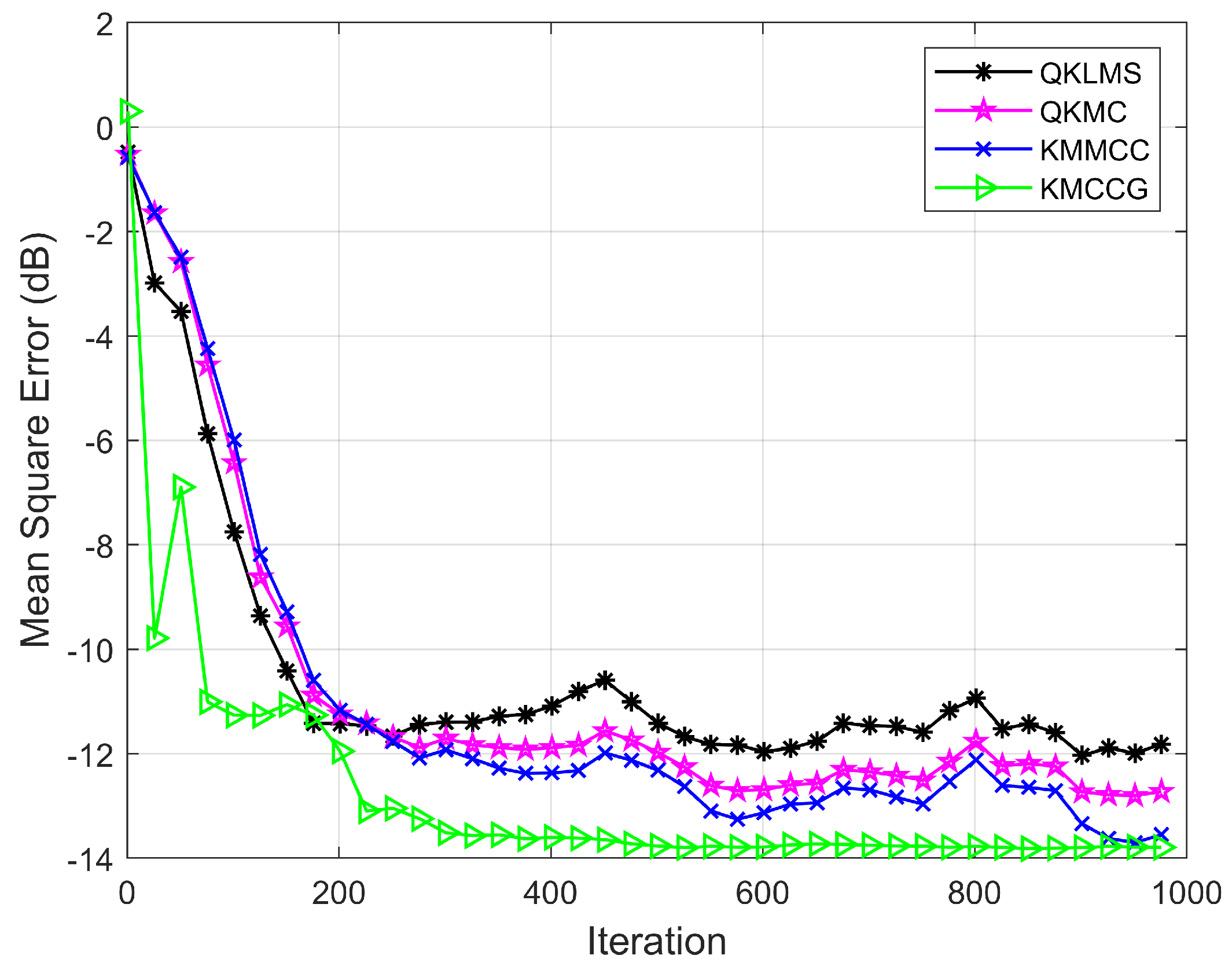
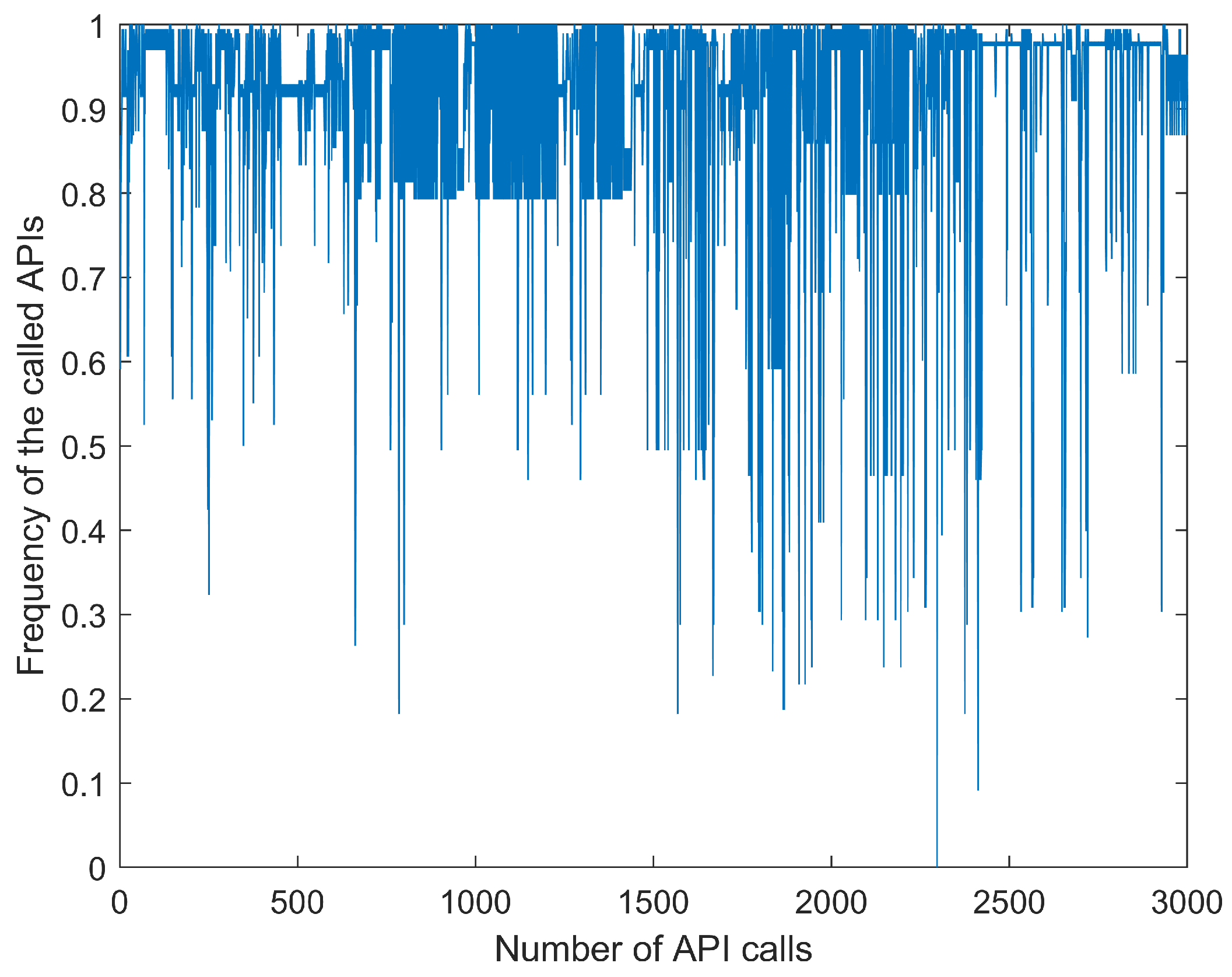
4.3. Malware API Call Sequence Prediction
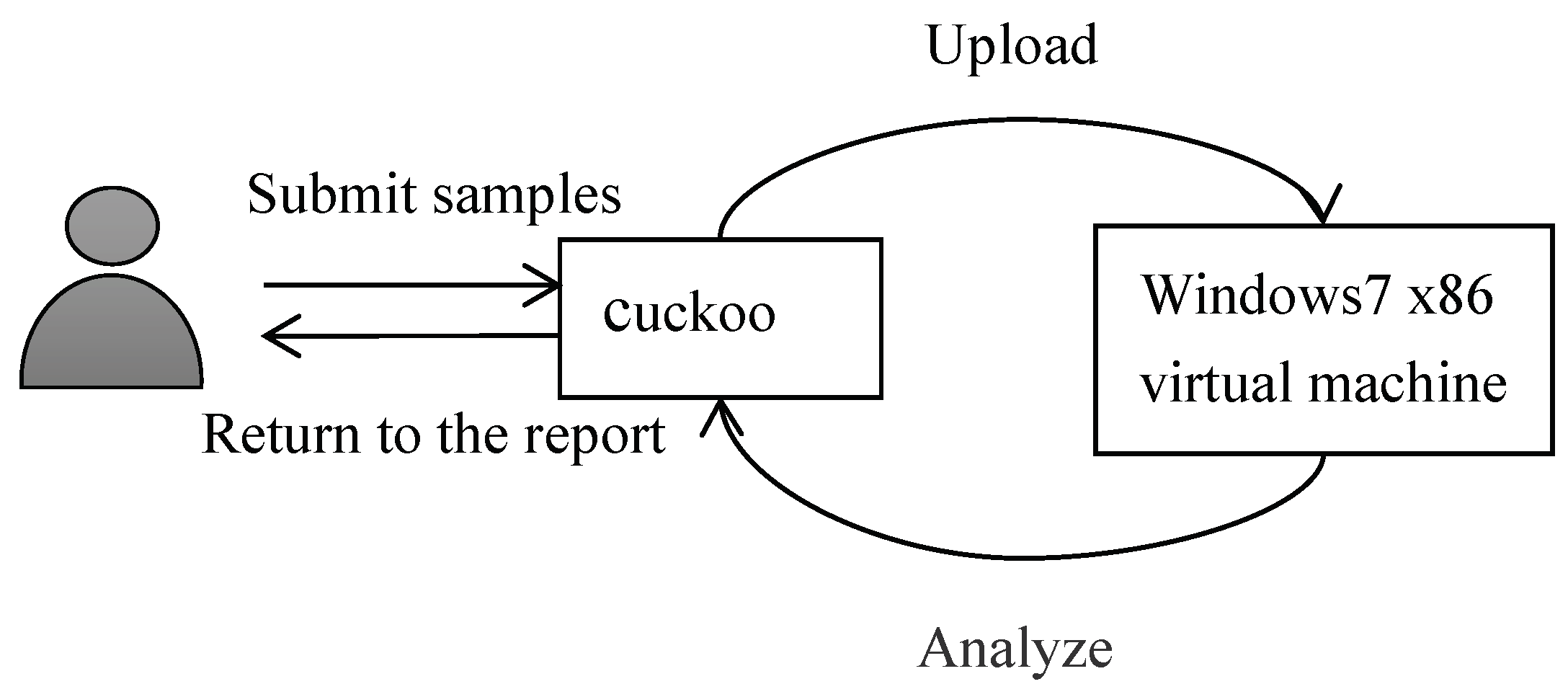
4.3.1. Background
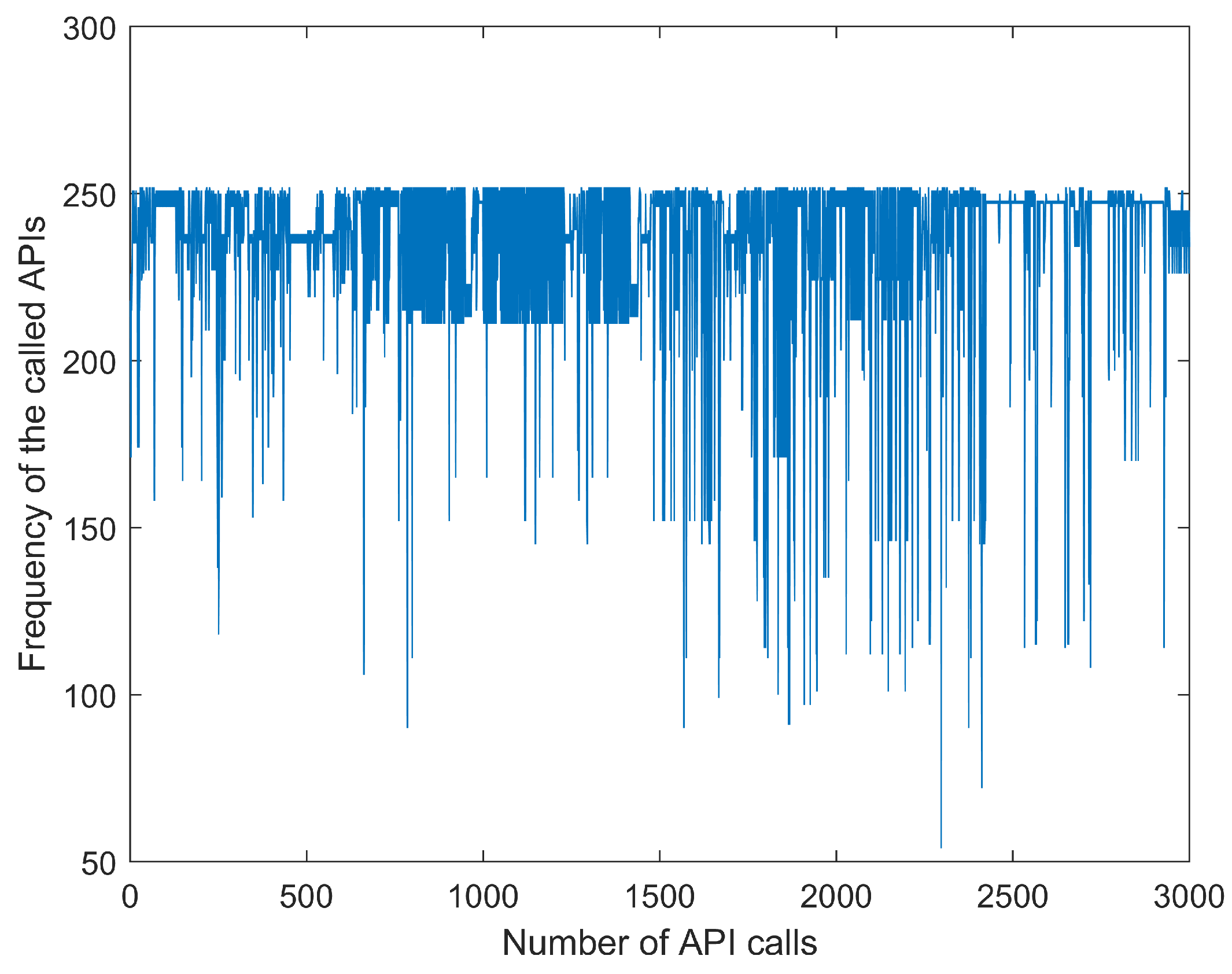
4.3.2. Experimental Result
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Firdausi, I.; Lim, C.; Erwin, A.; Nugroho, A.S. Analysis of machine learning techniques used in behavior-based malware detection. In Proceedings of the Second International Conference on Advances in Computing, Control, and Telecommunication Technologies, Jakarta, Indonesia, 2–3 December 2010; pp. 201–203. [Google Scholar]
- Xiao, X.; Zhang, S.; Mercaldo, F.; Hu, G.; Sangaiah, A.K. Android malware detection based on system call sequences and LSTM. Multimed. Tools Appl. 2019, 78, 3979–3999. [Google Scholar] [CrossRef]
- Luo, X.; Jiang, C.; Wang, W.; Xu, Y.; Wang, J.H.; Zhao, W. User behavior prediction in social networks using weighted extreme learning machine with distribution optimization. Future Gener. Comput. Syst. 2019, 93, 1023–1035. [Google Scholar] [CrossRef]
- Han, M.; Zhang, S.; Xu, M.; Qiu, T.; Wang, N. Multivariate chaotic time series online prediction based on improved kernel recursive least squares algorithm. IEEE Trans. Cybern. 2019, 49, 1160–1172. [Google Scholar] [CrossRef]
- Sahoo, D.; Hoi, S.C.H.; Li, B. Large scale online multiple kernel regression with application to time-series prediction. ACM Trans. Knowl. Discov. Data 2019, 13, 9. [Google Scholar] [CrossRef]
- Liu, W.; Príncipe, J.C.; Haykin, S. Kernel Adaptive Filtering; Wiley: Hoboken, NJ, USA, 2011. [Google Scholar]
- Liu, W.; Pokharel, P.P.; Príncipe, J.C. The kernel least-mean-square algorithm. IEEE Trans. Signal Process. 2008, 56, 543–554. [Google Scholar] [CrossRef]
- Engel, Y.; Mannor, S.; Meir, R. The kernel recursive least-squares algorithm. IEEE Trans. Signal Process. 2004, 52, 2275–2285. [Google Scholar] [CrossRef]
- Luo, X.; Deng, J.; Liu, J.; Wang, W.; Ban, X.; Wang, J.H. A quantized kernel least mean square scheme with entropy-guided learning for intelligent data analysis. China Commun. 2017, 14, 127–136. [Google Scholar] [CrossRef]
- Ahmad, N.A. A globally convergent stochastic pairwise conjugate gradient-based algorithm for adaptive filtering. IEEE Signal Process. Lett. 2008, 15, 914–917. [Google Scholar] [CrossRef]
- Zhang, M.; Wang, X.; Chen, X.; Zhang, A. The kernel conjugate gradient algorithms. IEEE Trans. Signal Process. 2018, 66, 4377–4387. [Google Scholar] [CrossRef]
- Gunduz, A.; Príncipe, J.C. Correntropy as a novel measure for nonlinearity tests. Signal Process. 2009, 89, 14–23. [Google Scholar] [CrossRef]
- Chen, M.; Li, Y.; Luo, X.; Wang, W.; Wang, L.; Zhao, W. A novel human activity recognition scheme for smart health using multilayer extreme learning machine. IEEE Internet Things J. 2019, 6, 1410–1418. [Google Scholar] [CrossRef]
- Sun, J.; Wang, Z.; Luo, X.; Shi, P.; Wang, W.; Wang, L.; Wang, J.H.; Zhao, W. A parallel recommender system using a collaborative filtering algorithm with correntropy for social networks. IEEE Trans. Netw. Sci. Eng. 2018. [Google Scholar] [CrossRef]
- Chen, B.; Wang, X.; Lu, N.; Wang, S.; Cao, J.; Qin, J. Mixture correntropy for robust learning. Pattern Recogn. 2018, 79, 318–327. [Google Scholar] [CrossRef]
- Fan, H.; Song, Q. A linear recurrent kernel online learning algorithm with sparse updates. Neural Netw. 2014, 50, 142–153. [Google Scholar] [CrossRef]
- Platt, J. A Resource-allocating Network for Function Interpolation; MIT Press: Cambridge, MA, USA, 1991. [Google Scholar]
- Liu, W.; Park, I.; Príncipe, J.C. An information theoretic approach of designing sparse kernel adaptive filters. IEEE Trans. Neural Netw. 2009, 20, 1950–1961. [Google Scholar] [CrossRef]
- Teng, H.; Liu, Y.; Liu, A.; Xiong, N.N.; Cai, Z.; Wang, T.; Liu, X. A novel code data dissemination scheme for Internet of Things through mobile vehicle of smart cities. Future Gener. Comput. Syst. 2019, 94, 351–367. [Google Scholar] [CrossRef]
- Rhode, M.; Burnap, P.; Jones, K. Early-stage malware prediction using recurrent neural networks. Comput. Secur. 2018, 77, 578–594. [Google Scholar] [CrossRef]
- Onwuzurike, L.; Mariconti, E.; Andriotis, P.; De Cristofaro, E.; Ross, G.; Stringhini, G. Mamadroid: Detecting android malware by building Markov chains of behavioral models. ACM Trans. Priv. Secur. 2019, 22, 14. [Google Scholar] [CrossRef]
- Príncipe, J.C. Information Theoretic Learning: Renyi’s Entropy and Kernel Perspectives; Springer: New York, NY, USA, 2010. [Google Scholar]
- Zhang, J.F.; Qiu, T.S. A robust correntropy based subspace tracking algorithm in impulsive noise environments. Digital Signal Process. Rev. J. 2017, 62, 168–175. [Google Scholar] [CrossRef]
- Luo, X.; Xu, Y.; Wang, W.; Yuan, M.; Ban, X.; Zhu, Y.; Zhao, W. Towards enhancing stacked extreme learning machine with sparse autoencoder by correntropy. J. Franklin Inst. 2018, 355, 1945–1966. [Google Scholar] [CrossRef]
- Du, B.; Tang, X.; Wang, Z.; Zhang, L.; Tao, D. Robust graph-based semisupervised learning for noisy labeled data via maximum correntropy criterion. IEEE Trans. Cybern. 2019, 49, 1440–1453. [Google Scholar] [CrossRef]
- Luo, X.; Sun, J.; Wang, L.; Wang, W.; Zhao, W.; Wu, J.; Wang, J.H.; Zhang, Z. Short-term wind speed forecasting via stacked extreme learning machine with generalized correntropy. IEEE Trans. Ind. Inf. 2018, 14, 4963–4971. [Google Scholar] [CrossRef]
- Chen, B.; Xing, L.; Liang, J.; Zheng, N.; Príncipe, J.C. Steady-state mean-square error analysis for adaptive filtering under the maximum correntropy criterion. IEEE Signal Process. Lett. 2014, 21, 880–884. [Google Scholar]
- Wu, Z.Z.; Peng, S.Y.; Chen, B.D.; Zhao, H.Q. Robust Hammerstein adaptive filtering under maximum correntropy criterion. Entropy 2015, 17, 7149–7166. [Google Scholar] [CrossRef]
- Peng, S.; Chen, B.; Sun, L.; Ser, W.; Lin, Z. Constrained maximum correntropy adaptive filtering. Signal Process. 2017, 140, 116–126. [Google Scholar] [CrossRef] [Green Version]
- Lu, L.; Zhao, H. Active impulsive noise control using maximum correntropy with adaptive kernel size. Mech. Syst. Signal Process. 2017, 87, 180–191. [Google Scholar] [CrossRef]
- Zhang, Z.Y.; Qiu, J.Z.; Ma, W.T. Adaptive extended Kalman filter with correntropy loss for robust power system state estimation. Entropy 2019, 21, 293. [Google Scholar] [CrossRef]
- He, Y.; Wang, F.; Wang, S.; Cao, J.; Chen, B. Maximum correntropy adaptation approach for robust compressive sensing reconstruction. Inf. Sci. 2019, 480, 381–402. [Google Scholar] [CrossRef]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Chen, B.; Zhao, S.; Zhu, P.; Príncipe, J.C. Quantized kernel least mean square algorithm. IEEE Trans. Neural Netw. Learn. Sys. 2012, 23, 22–32. [Google Scholar] [CrossRef]
- Wang, S.; Zheng, Y.; Duan, S.; Wang, L.; Tan, H. Quantized kernel maximum correntropy and its mean square convergence analysis. Digital Signal Process. Rev. J. 2017, 63, 164–176. [Google Scholar] [CrossRef]
- Gil-Alana, L. Long memory behaviour in the daily maximum and minimum temperatures in Melbourne, Australia. Meteorol. Appl. 2004, 11, 319–328. [Google Scholar] [CrossRef]
- FireEye Inc. Out of Pocket: A Comprehensive Mobile Threat Assessment of 7 Million iOS and Android Apps. Available online: https://www.itsecurity-xpert.com/whitepapers/1043-out-of-pocket-a-comprehensive-mobile-threat-assessment-of-7-million-ios-and-android-apps (accessed on 10 July 2019).
- Ma, Z.; Ge, H.; Liu, Y.; Zhao, M.; Ma, J. A combination method for android malware detection based on control flow graphs and machine learning algorithms. IEEE Access 2019, 7, 21235–21245. [Google Scholar] [CrossRef]
- Makandar, A.; Patrot, A. Malware analysis and classification using artificial neural network. In Proceedings of the International Conference on Trends in Automation, Communication and Computing Technologies, Bangalore, India, 21–22 December 2015; p. 7492653. [Google Scholar]
- Miao, Q.; Liu, J.; Cao, Y.; Song, J. Malware detection using bilayer behavior abstraction and improved one-class support vector machines. Int. J. Inf. Secur. 2016, 15, 361–379. [Google Scholar] [CrossRef]
- Tobiyama, S.; Yamaguchi, Y.; Shimada, H.; Ikuse, T.; Yagi, T. Malware detection with deep neural network using process behavior. In Proceedings of the IEEE 40th Annual Computer Software and Applications Conference Workshops, Atlanta, GA, USA, 10–14 June 2016; pp. 577–582. [Google Scholar]
- Xu, W.; Qi, Y.; Evans, D. Automatically evading classifiers. In Proceedings of the Network and Distributed Systems Symposium, San Diego, CA, USA, 21–24 February 2016; pp. 21–24. [Google Scholar]
- Biggio, B.; Nelson, B.; Laskov, P. Poisoning attacks against support vector machines. In Proceedings of the 29th International Coference on Machine Learning, Edinburgh, Scotland, 26 June–1 July 2012; pp. 1467–1474. [Google Scholar]
- Sami, A.; Yadegari, B.; Rahimi, H.; Peiravian, N.; Hashemi, S.; Hamze, A. Malware detection based on mining API calls. In Proceedings of the ACM Symposium on Applied Computing, Sierre, Switzerland, 22–26 March 2010; pp. 1020–1025. [Google Scholar]
- Qiao, Y.; Yang, Y.; Ji, L.; He, J. Analyzing malware by abstracting the frequent itemsets in API call sequences. In Proceedings of the 12th IEEE International Conference on Trust, Security and Privacy in Computing and Communications, Melbourne, VIC, Australia, 16–18 July 2013; pp. 265–270. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Additions | Multiplications | Divisions |
|---|---|---|---|
| KLMS | 0 | ||
| KRLS | 1 | ||
| KCG | 3 | ||
| KMCCG | 5 |
| Algorithm | Time (s) | MSE (dB) |
|---|---|---|
| QKLMS | 39.03 | −12.9139 |
| KMMCC | 52.46 | −15.4081 |
| ANN | 841.41 | −18.1565 |
| SVM | 106.21 | −17.8825 |
| KMCCG | 2.24 | −17.8421 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xue, N.; Luo, X.; Gao, Y.; Wang, W.; Wang, L.; Huang, C.; Zhao, W. Kernel Mixture Correntropy Conjugate Gradient Algorithm for Time Series Prediction. Entropy 2019, 21, 785. https://doi.org/10.3390/e21080785
Xue N, Luo X, Gao Y, Wang W, Wang L, Huang C, Zhao W. Kernel Mixture Correntropy Conjugate Gradient Algorithm for Time Series Prediction. Entropy. 2019; 21(8):785. https://doi.org/10.3390/e21080785
Chicago/Turabian StyleXue, Nan, Xiong Luo, Yang Gao, Weiping Wang, Long Wang, Chao Huang, and Wenbing Zhao. 2019. "Kernel Mixture Correntropy Conjugate Gradient Algorithm for Time Series Prediction" Entropy 21, no. 8: 785. https://doi.org/10.3390/e21080785
APA StyleXue, N., Luo, X., Gao, Y., Wang, W., Wang, L., Huang, C., & Zhao, W. (2019). Kernel Mixture Correntropy Conjugate Gradient Algorithm for Time Series Prediction. Entropy, 21(8), 785. https://doi.org/10.3390/e21080785