1. Introduction
“We now have to look at apparently random time series of data, be they from the stock market, or currency exchanges, or in ecology and ask are we seeing “random walks down Wall street” or deterministic chaos, or, often more likely, some mixture of the two.”
The study of disease dynamics in plant pathology has been dominated by analysis of situations where disease increases monotonically within single growing seasons or over several seasons [
2]. Reflecting this focus, the literature on the use of monotonic growth curve models or, more recently, compartment models consisting of linked differential equations is extensive and the methodology is well developed. In contrast, the literature on how to handle long, oscillating data series for plant pathogen populations is rather thin, with only isolated case studies [
3,
4,
5,
6,
7] employing a range of statistical approaches. To date, there has been no concerted effort in botanical epidemiology to establish general properties of time series data associated with pathogen populations or disease intensity. This is due in part, no doubt, to the fact that time series methods have been considered relevant mostly for multi-season contexts, and multi-season datasets are scarce in plant pathology. However, with the advent of molecular probes for studying the airborne inoculum of plant pathogens, it has become much easier to capture time series data within single growing seasons [
5,
6,
8].
Developments in technology for monitoring airborne inoculum of target species offer a promise of methodological advance to epidemiologists with an interest in creating evidence-based, within-season decision rules for disease management in crops. Given such potential applications for spore traps and quantification of target nucleic acid sequences, it is important that efforts are made to develop an analytical approach which takes into account the relevant statistical properties of the data that these monitoring methods generate. What can experimenters expect to see when they collect such data? What types of dynamical behavior are likely to be apparent, and how should the results be interpreted in relation to the use of the data in disease management?
The work we report here falls into the broad theme on decision-making that runs through several of the contributions to this Special Issue of Entropy. In the case of the current work, our effort is aimed more at understanding the basic properties of the data than in deriving decision rules from them. The work is motivated by our belief that it is important to be aware of any informational limitations inherent in the data, so that efforts to use air sampling as a means of forecasting interventions occur with realistic expectations. The work is intended to be an initial contribution to the literature; one from which we hope a range of further investigations covering a wider range of pathogen systems will develop.
As already noted, airborne concentrations of pathogen inoculum have been monitored using vortex (spinning rod) air samplers combined with species-specific quantitative polymerase chain reaction (qPCR) in a number of situations. In some cases, the approach has already been used commercially for disease management. Carisse and colleagues were pioneers, developing one of the first examples in commercial agriculture; in their case, to manage fungicide applications to control Botrytis leaf blight in onion in Quebec, Canada [
5,
9,
10]. Their work (along with characterization of effective fungicide regimes and conducive weather conditions) helped to improve monitoring and to reduce disease outbreaks.
The use of spore traps linked with qPCR assays has been developed successfully for disease monitoring in several other pathosystems, including monitoring for early season inoculum for grape powdery mildew [
11], where mitigating early season inoculum can reduce yield losses in susceptible varieties. These studies show that managing disease based on the binary presence or absence of pathogen primary inoculum can be quite successful, since what is needed in that situation is to detect the first occurrence of pathogen activity at the start of the growing season. The use of these systems for mitigating the impacts from secondary inoculum is more challenging.
Spinach downy mildew, caused by the obligate oomycete pathogen
Peronospora effusa, is the most important threat to spinach production worldwide. Choudhury et al. [
6] examined several sets of qPCR-based spore trap data collected from the Salinas Valley in California. The resulting time series were analyzed by fitting statistical models to characterize both trend and periodicity. While the approach was successful in producing a description of the observed dynamics, and in linking important statistical features to plausible biological mechanisms, it offered little in the way of general understanding of inoculum dynamics. Analyses of the coefficients of prediction and the Lyapunov exponents of the time series suggested that the datasets were quasi-chaotic. Further analyses of this example dataset could reveal general dynamics of airborne inoculum for plant pathogens.
Recent developments in time series analysis [
12] based on information-theoretic quantities offer some promise in being able to extract more generic properties from the available data. Our objectives in this paper are to revisit the data originally studied by Choudhury et al. [
6] and to apply the methods suggested by Huffaker et al. [
12] in order to describe the dynamics of pathogen airborne inoculum in information theoretic terms. The analyses also place our data from botanical epidemiology in the wider context of the analysis of dynamical systems allowing interdisciplinary comparison. Our primary intended audience is plant pathologists and epidemiologists who might be interested in an introduction to these topics. For that reason, our approach is somewhat pedagogical and does not delve deeply into the underlying technical details.
2. Materials and Methods
2.1. Data Collection
Airborne inoculum of
P. effusa was sampled at four locations in the Salinas Valley of California in 2013 and 2014 using vortex air samplers constructed by Dr. Walt Mahaffee (USDA-ARS Corvallis, Corvallis, OR, USA) and operated by Dr. Steven Klosterman (USDA-ARS Salinas, Salinas, CA, USA). The presence of the inoculum and quantification were achieved using qPCR amplification of a species-specific DNA sequence in the total DNA extract from the sampler rods. Details of the sampling procedure, qPCR primers, reaction conditions, and translation of the qPCR cycle threshold number to daily pathogen DNA copy number are described in Klosterman et al. [
8].
2.2. Data Preparation
Samples were recovered from the air samplers on an irregular sampling interval of two or three days depending on the availability of technical staff. In the original 2016 study [
6], we accommodated the irregular sampling interval by fitting a flexible sine function to the observations, having first removed any temporal trend by linear regression. In the current work, in order to utilize nonlinear methods incorporating information quantities, we interpolated the raw data to produce time series with a regular time step of one day. All nine data series were processed in the same way so that we could compare their statistical properties directly. The interpolation was achieved by linear averaging between the measured data points. The interpolation method will have the effect of smoothing the data to some extent, and the interpretation of the results takes that into account. We avoid overinterpretation of fine-grain aspects of the analyzed series and focus on the major dynamic features that are unlikely to be strongly influenced by the interpolation.
2.3. Basic Time Series Analysis
After interpolation of the data to a daily time step, each of the nine time series consisted of 129 observations of the estimated target DNA copy number of P. effusa trapped over the preceding 24 h period. The nine time series were first inspected for evidence of an overall trend in copy number with time. Increasing trends were detected in 7 of the 9 series, and the series were tagged accordingly to indicate their status. Irrespective of whether or not the initial inspection suggested a trend to be present, in order to standardize the pretreatment of the data, a simple linear regression with time (i.e., data point in sequence, t = 1, 2, 3,... 129) was fitted to the natural logarithm of the estimated copy number. The residuals from the regression were then exponentiated to produce the detrended series that were subsequently used analysis. In what follows, we refer to these series as Nt, indicating the (detrended) copy number on day t. When corresponding log-transformed values are analyzed, they are denoted nt.
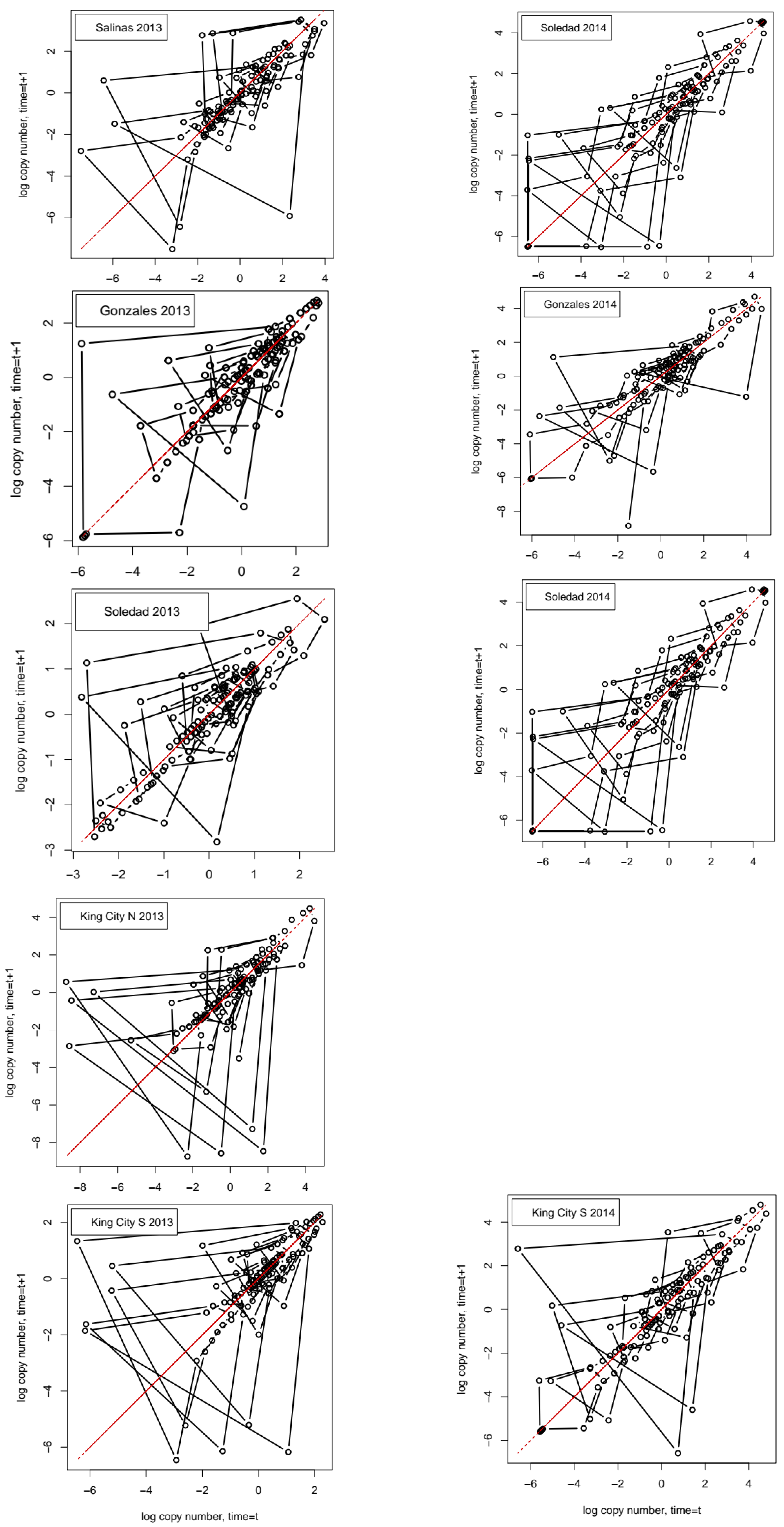
For each series, we obtained the autocorrelation function (ACF), the partial autocorrelation function (PACF), and the phase plot of the log-transformed series with nt+1 = ln(Nt+1) on the ordinate and nt = ln(Nt) on the abscissa. The PACF differs from the standard autocorrelation function in that it considers only the direct effect of observations at one point in the series on observations separated by lag τ, indirect effects, operating through the interposing points in the series that are removed.
2.4. Nonlinear Time Series Analysis
To characterize the time series in terms of nonlinear dynamics, we followed an approach suggested by Huffaker et al. [
12] and by Kantz and Schreiber [
13]. The various quantities estimated for each series were obtained using functions provided in the R packages “
nonlinearTseries” [
14], “
TseriesChaos” [
15], or “
TseriesEntropy” [
16]. Additional calculations to obtain empirical entropy values used the package “
entropy” [
17] or were coded directly in R. As with many other aspects of applied data analysis, for several of the steps in a nonlinear time series analysis, there is no single method that is guaranteed to provide optimal results under every circumstance. For many of the procedures, there are no formal test statistics to indicate that a “significant” result has been obtained; we followed the approaches suggested in the references. We provide R code and data necessary to replicate a full set of analyses for one of the 9 time series analyzed in the repository at the following URL:
https://github.com/robchoudhury/spore_trap_information_theory. The R code is provided as is, and we offer no guarantee that it will work when adapted to other data sets.
2.4.1. Surrogate Testing for Nonlinear Dependence
Since nonlinear analysis (NLTS) can be time-consuming, an initial step should be to test for lack of linear dependence in the observed data. An agreed approach for performing this is to perform surrogate tests [
12,
14]. Different versions of the surrogate test are implemented in
nonlinearTseries and
TseriesChaos. The basic idea in both cases is to construct an empirical hypothesis test by resampling from the observed data, with the test statistic being a suitable property of the data that will hold under linear dependence but not otherwise. One of the simplest approaches, the one implemented in
nonlinearTseries, relies on the idea that a Gaussian linear process will show time reversibility. Randomized permutations are obtained using a method in which the phases of the Fourier transform of the observed data are randomized. A two-sided hypothesis test is implemented to examine whether there is evidence that the value calculated from the observed data differs from the set of surrogates generated in the data resampling routine. We set the “significance level” option at 0.02, which results in the observed data being treated as one observation in a set of 100, with the two-sided test examining whether the observed data are in the
p = 0.02 upper or lower tail of the sample. The supplied function includes a built-in diagnostic plot of the resampling test, but we implemented our own diagnostic graphical representation of the outcome for the test.
TseriesEntropy implements a more complex surrogate testing procedure. First, the best-fitting linear autoregressive (AR) model is selected on the basis of the Akaike Information Criterion (AIC). The residuals of the best AR model are resampled (with replacement). For each resampled series, a metric entropy measure (the Bhattacharya–Matusita–Hellinger measure,
Sp) [
18] is calculated at different lags. Based on the relevant properties of the resampled data, the 95% confidence band for
Sp can be calculated and the values for the observed series are compared with the confidence band. If
Sp for the observed series falls outside the band, the series can be considered to show nonlinear as opposed to linear dependence at the relevant lags. The entropy-based approach in
TseriesEntropy is computationally more demanding than the expectation-based approach in
nonlinearTseries. In the initial work, we examined both approaches. The results reported here are for the time-reversibility approach implemented in
nonlinearTseries. The code supplied in the
Supplemental Materials includes an example of the regression-based approach, deactivated by comment markers.
2.4.2. Characterizing Nonlinear Properties
Assuming that the surrogate tests indicate sufficient reason to proceed with NLTS, characterization of the dynamics in terms of their tendency to chaotic versus stochastic uncertainty is an important component of the ensuing effort. Following the pioneering work of Takens [
19], one widely accepted approach to NLTS proceeds by attempting to reconstruct important features of the complete (and only partially observed) phase space of the whole system, using the methods of time delay embedding to characterize the time series of a single observed component of the system.
In the current context, where the ultimate motivation is the hope of using similar series in disease management, the capacity to reconstruct the phase portrait of the whole system is of secondary importance to characterizing the dynamics of the observed series. However in this initial study the focus is on understanding the dynamics rather than immediate practical application, and the time delay embedding approach may be valuable because the features of the dynamics it reveals are informative.
Three properties of the series are important in NLTS, these being (i) the average mutual information (AMI), I(Nt,; Nt-τ), of the time series data at successive lags, τ = 0, 1, 2, … τmax; (ii) the Theiler Window, tw; and (iii) the embedding dimension, m.
The AMI Function
The AMI function is calculated by binning observations and by calculating the mutual information obtained about observation Nt being in the ith bin from knowing observation Nt-τ is in the jth bin. The results are averaged over all of the available data to produce the average mutual information. A graphical plot of I(Nt,; Nt-τ) against lag, τ = 0, 1, 2, … τmax produces an information-theoretic analogue of the ACF plot, but one in which the AMI’s general measure of lagged association, as opposed to the linear lagged dependence captured by ACF, is visualized. The first minimum, or the first occurrence of a value below an empirical threshold, of the AMI function is taken to be an indication of the embedding time delay, d, of the series, since this value indicates a time lag at which observations have, in a general sense, low correlation.
The Theiler Window (tw)
The Theiler Window [
20,
21] is used to define the minimum separation along the time series that two points must have in order to be included in procedures used to find the embedding dimension,
m (see below). Theiler’s review [
21] gives a detailed and technical account of the issues and the various approaches suggested (up to that time) for finding the embedding dimension.
For long time series, both
TseriesChaos and
nonlinearTseries offer functions to generate a space-time plot [
22] from which
tw can be selected by choosing a value at which there is a low probability of points being close in the phase space for a given time lag separation. For short time series, such as what we have in the present study, the space-time plot approach may not give usable results and other options may be needed; this was the case with our datasets which consist of 129 observations.
As an easily obtained first approximation, Huffaker et al. [
12] suggested using the first minimum of the standard autocorrelation function (ACF). Since ACF is a linear function, there are risks in using it to estimate correlation structure of nonlinear data [
23]; indeed, this issue was one of the motivations for Theiler’s review [
21] of methods for identifying the dimensionality of nonlinear attractors. The problem, in general, appears to be that nonlinear correlation may occur at a larger lag separation that would be suggested by the ACF.
In the current case, lacking a reasonable alternative, we opted for a trial-and-error approach. With both the AMI function and the ACF available, we had estimates of both general association and linear correlation with lag, while the original time series and the corresponding phase plots also help to indicate suitable values of tw. For each series, we started with the value suggested by the first minimum of the ACF, noting also whether this lag separation was longer or shorter than the value suggested by the AMI. Where the AMI reached its first minimum at longer lag than the ACF, we used a range of estimates for tw and examined the effect of changing tw on the estimated embedding dimension, m.
The Embedding Dimension, m
Options for estimating,
m, are either the method of False Nearest Neighbors (FNN) offered in
TseriesChaos (Huffaker et al. [
12] pp. 67–69) or Cao’s [
24] algorithm implemented in
nonlinearTseries. Briefly, the motivation for the FNN approach comes from the idea that (in the current case), the observed time series of pathogen DNA copies represent only one dimension of a higher-order dynamical system. We can think of the observed series as representing the whole higher-order dynamical system projected onto a single dimension. With this perspective, points that appear close to one another may actually be widely separated in the full dimensional space of the dynamical system. The idea of FNN computation is to select a subset of points within a given “radius” of each other but separated by at least the value of
tw and to track whether they remain as neighbors as the dimensionality of the assumed attractor is incrementally increased. If the proportion of FNN is plotted against the number of dimensions,
m, the first value of
m at which the proportion of FNN is minimized provides an estimate of the embedding dimension.
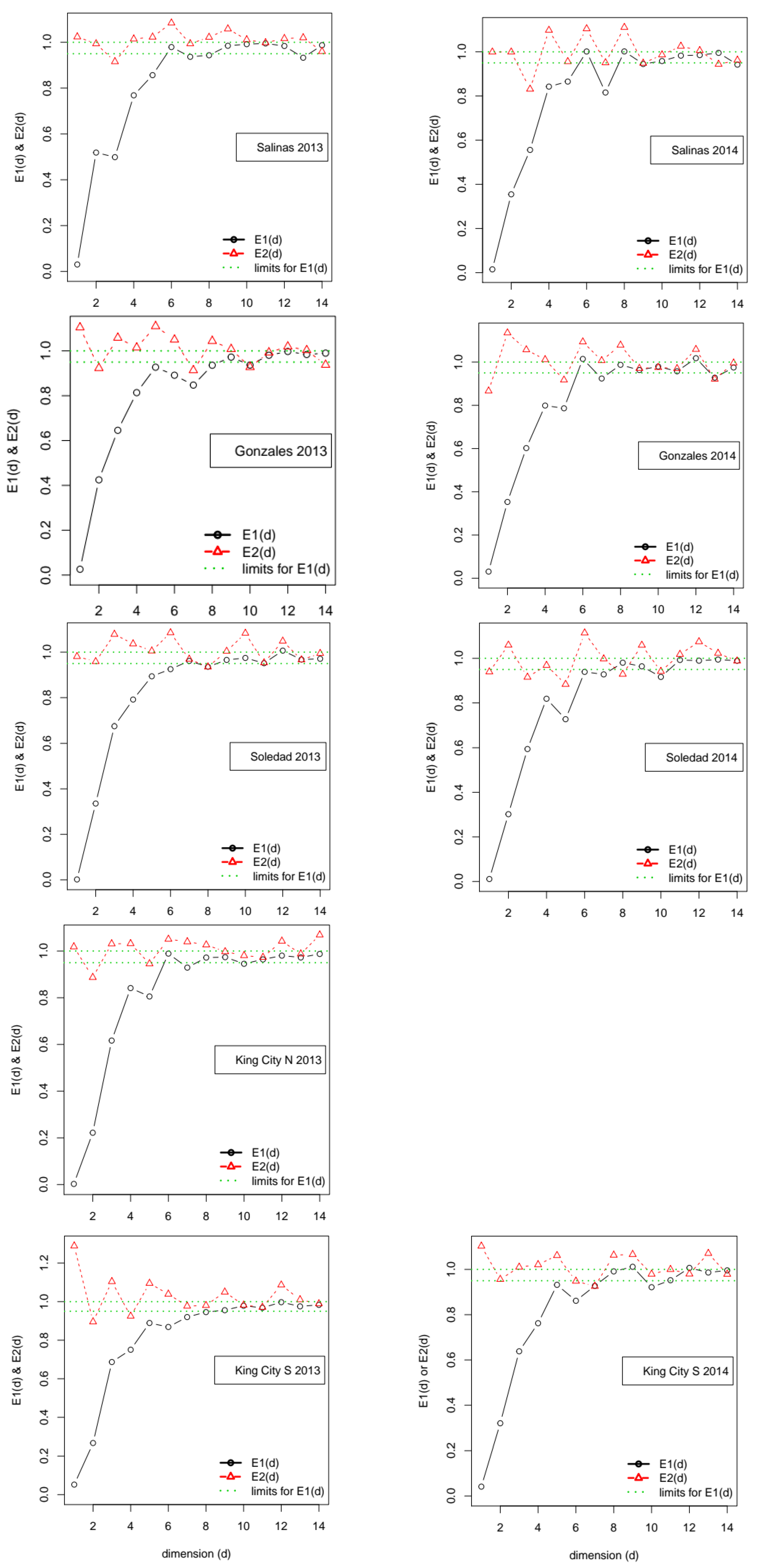
In the approach suggested by Cao [
24], the embedding dimension is identified by calculating a pair of functions, referred to as
E1(
m) and
E2(
m), of putative values for the embedding dimension,
m. Note that Cao’s original notation used d in place of
m. Cao’s method starts by calculating an overall Euclidean distance measure between pairs of points on time delay vectors for successively larger assumed values of
m. Function
E1(
m) calculates the ratio of the distance measure at successive pairs of values, (
m+1,
m). Cao’s insight was that this ratio stabilizes close to 1 if the data are generated by an attractor. The second function,
E2(
m), focuses on the distance between only the nearest neighbors in the time delay vectors and operates on the distance measure based only on those. As with
E1(
m), the function returns the ratio between successive pairs (
m+1,
m). If the data are generated by a deterministic attractor,
E2(
m) has the property that, at some value
m*,
E2(
m*)! = 1, whereas if the data are generated by a process dominated by stochastic noise,
E2(
m) ≅ 1, ∀
m. Thus, in addition to providing an estimate of the relevant embedding dimension, Cao’s method offers the advantage over the FNN approach of providing an indication of whether the data-generating process is characterized by deterministic or stochastic uncertainty.
2.5. Additional Entropy Measures
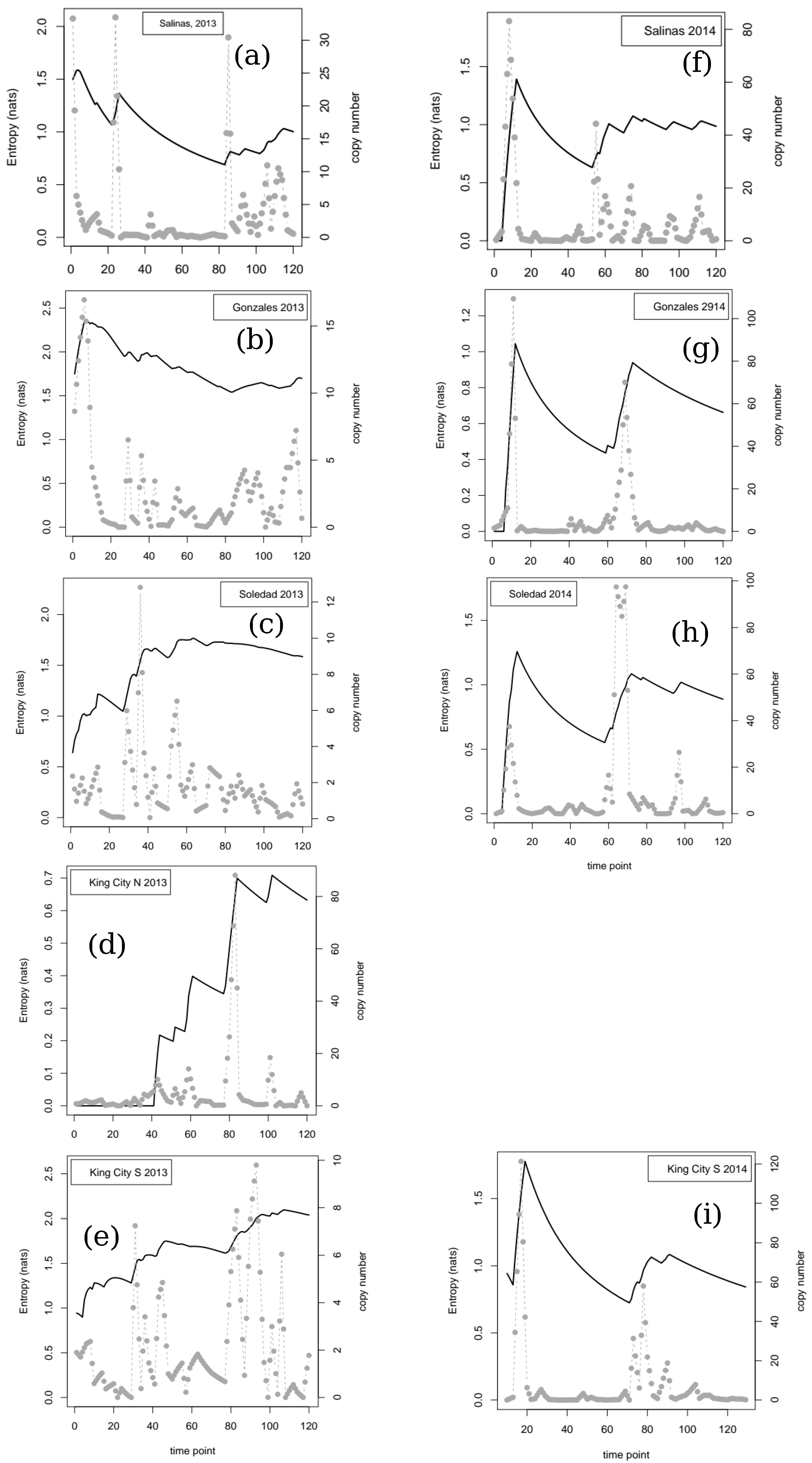
In addition to the characterization of the dynamics provided by the time-delay-embedding approach, we calculated two empirical entropy values to help in understanding the uncertainty in the data for airborne pathogen DNA. The first approach worked directly on the DNA copy number time series (following detrending if necessary, see above). The entropy () function from the R package entropy was used to calculate empirical estimates of the entropy in the data at each time point by iteratively adding the datum for each time point to the entropy calculation. Calculation using this approach starts by constructing a binning structure for the data and then by estimating the entropy based on the frequencies of observation in each bin. We started the iterative process at the 10th time point, so that the first estimate of entropy was based on the first 10 observations of each series. The calculation then proceeded as just outlined, with the second estimate being based on the first 11 data points and so on. The maximum likelihood option for the entropy function was used throughout.
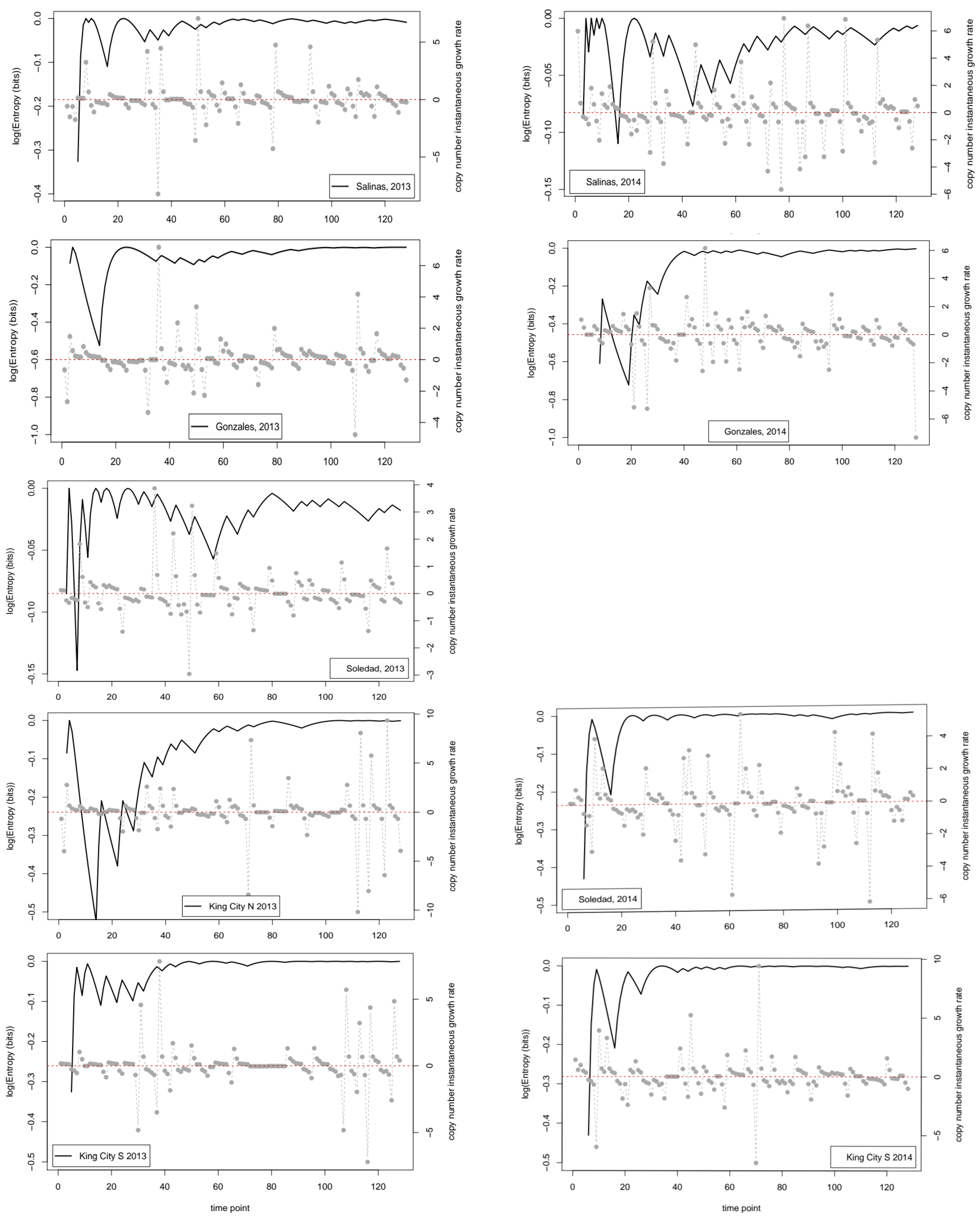
As a second approach to characterize uncertainty in the time series data in relation to decision making, we first transformed each series into a binary string of length (tmax-1). First differences between successive pairs of values were calculated, and if the resulting difference was greater than 0 (indicating Nt+1 > Nt), then 1 was entered for the corresponding value of the string; Nt+1 ≤ Nt resulted in 0. The calculation then proceeded along similar lines to those outlined for the entropy of the copy number, iteratively increasing the size of the dataset by one time point and calculating a new entropy value. In the current case, at each time point, we calculated the proportion of the data that were 1s and then used Shannon’s equation for expected information to give an entropy value in bits for the string at each time point (including all data up to that time). The calculation was coded directly in R. We initiated the calculation with the first two observations and then iterated the calculation one time point at a time.
2.6. Linear Autoregressive Models
In discussing the analysis of time series data for biological populations, Royama [
25] noted that for autoregressive (AR) models where an instantaneous growth rate is modeled as a function of lagged population sizes, there is a qualitative difference in the types of behavior that a second-order lag model can display compared with a first-order model. Further, given the capacity for second-order linear models to generate quite complex oscillatory patterns, even when completely deterministic, Royama [
25] suggested they could be expected to approximate the behavior of simple nonlinear models. Since the main aim of our investigation is to look at the utility of nonlinear methods, the linear AR models included here were fitted for the purpose of illustrating the extent to which a linear model can account for the observed behavior of the data collected from air samplers.
We followed a conceptual approach that draws on the work of Royama [
25] and Turchin [
26] in fitting the AR linear models. The process starts with the log-transformed (
loge) time series, denoted
nt. The instantaneous log growth rate
Rt is defined as
nt+1 −
nt, and the estimated linear AR model is then
in which a
0, a
1, etc. are parameters to be estimated; ε is an error term; and
τ is an index indicating lag dependence. Selection of the order of lag dependence (i.e., the value
τmax) to use in fitting the AR models in each case was guided by the estimates of ACF and AMI functions (see
Section 2.4.2 above). Parameter estimation was achieved by the standard least-squares approach implemented in the lm () function in the R base statistics package. For the selected model in each case, we noted the percent variance accounted for by the model in form of the standard adjusted-R
2 and a coefficient of prediction similar to the one proposed by Turchin [
26]. The coefficient was obtained as follows: We fitted a model consisting of only the mean value of the dependent variable and captured the residual sum of squares, (RSS
mn). Next, we calculated 1−(RSS
mod/RSS
mn), in which RSS
mod is the residual sum of squares from the selected model. When RSS
mod > RSS
mn, the coefficient has a negative value and indicates that the model fits noise. Values approaching 1 occur when the observed series has a pattern of oscillations that can be captured reasonably well in simple autoregressive models. Finally, values in the region of 0 indicate that the series is dominated by noise and, possibly, too short and complex to be characterized well.
4. Discussion
The quotation from the late Sir Robert May’s introduction to the Landmark edition [
1] of his monograph
Stability and Complexity in Model Ecosystems was chosen deliberately and for more than one reason. First, May’s point that the dynamics of real systems are likely to be a mixture of stochastic and deterministic processes applies directly to our observations on the time series of spore trap DNA copy numbers for
P. effusa in the Salinas Valley of California. Secondly, May was an advocate of the idea that models can and should be used in biology in a strategic way to try to understand broad types of behavior without necessarily considering immediate questions of application or numerical accuracy in any specific case, while our analyses are predominantly statistical in nature, they are nonetheless carried out from a strategic perspective. Our aim in this study was not so much to produce accurate predictive models of any of the series as it was to use the tools of nonlinear time series analysis, together with some linear methods, to investigate the broad properties of pathogen DNA copy data collected from vortex air samplers.
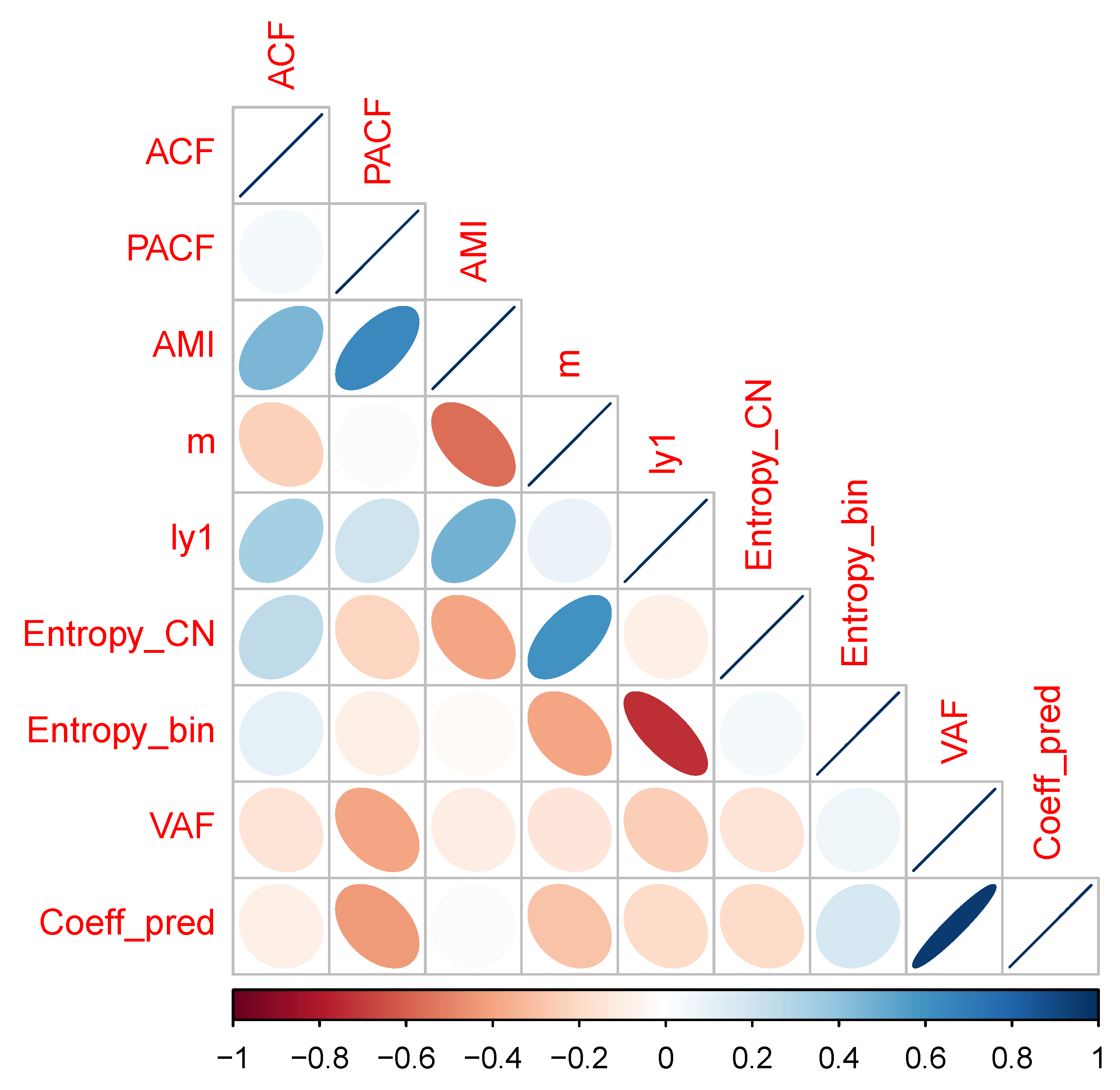
A correlation matrix plot for the numerical data in
Table 1 is given as
Figure A2 in
Appendix A. Summarizing the results for the diagnosis of time series properties, a mixture of findings resulted. In some cases, there were indications of deterministic chaos—i.e., positive estimated values for the Lyapunov coefficient, failure of time reversibility test in surrogates—while others were indicative of stochastic noise, i.e., in 5 out of 9 cases, the surrogate test failed to reject the hypothesis of time reversibility, and the first minimum values of the ACF and AMI functions were generally similar, indicating that the more general information-theoretic test of association based on average mutual information did not detect dependence in the series beyond the linear association measured by the ACF.
All of the series had positive Lyapunov exponents, indicating a tendency for deterministic sensitivity to initial conditions [
26]. On the other hand, application of Cao’s approach [
24] indicated that the series were stochastic. The surrogate (bootstrap) test of time reversibility indicated that five series were compatible with the hypothesis that they were generated by a stochastic linear process while four were not. Relatively low values for the coefficient of prediction and adjusted-R
2 calculated from linear autoregressive models, ranging from a minimum of 3.6% (Gonzales, 2013) to a maximum of 26.4% (King City, N, 2013), also suggested that the series were strongly influenced by stochastic noise. Taken together, these results indicated that the series lie in the transition between stochastic and deterministic uncertainty in what Turchin [
26] refers to as
quasi-chaotic territory at the boundary between the two types of dynamics.
It seems reasonable, based on the dependence of oomycete pathogens such as
P. effusa on suitable weather for spore production and release, that the copy number on air sampler traps would show appreciable stochasticity. Not only is the number of DNA copies detected dependent on the response of the pathogen to uncertain weather conditions, the physical processes of dispersal, and transport in air, together with the vortex sampling process itself, meaning that there are multiple sources of stochasticity between the release of spores and subsequent trapping events. However, at the same time, crop management practices such as planting and harvesting salad spinach happen on cycles of between 21 and 45 days, and may be a source of deterministic forcing in the data complicating the dynamics. If the data are predominantly stochastic in nature, then traditional statistical models should be able to describe the pattern and to characterize the uncertainty. Similarly, Turchin [
26] argues that dynamic patterns generated by low-dimensional attractors can also successfully be described by relatively simple models. Our analyses indicate that, at least in the case of
P. effusa in the Salinas Valley in California, the observed dynamics may fall between these two preferred situations, making characterization of the dynamics difficult and leading to low overall predictability. The estimated embedding dimension for the series (after detrending) ranged from 6 to 9, indicating that they did not have dynamics compatible with a low-dimensional attractor.
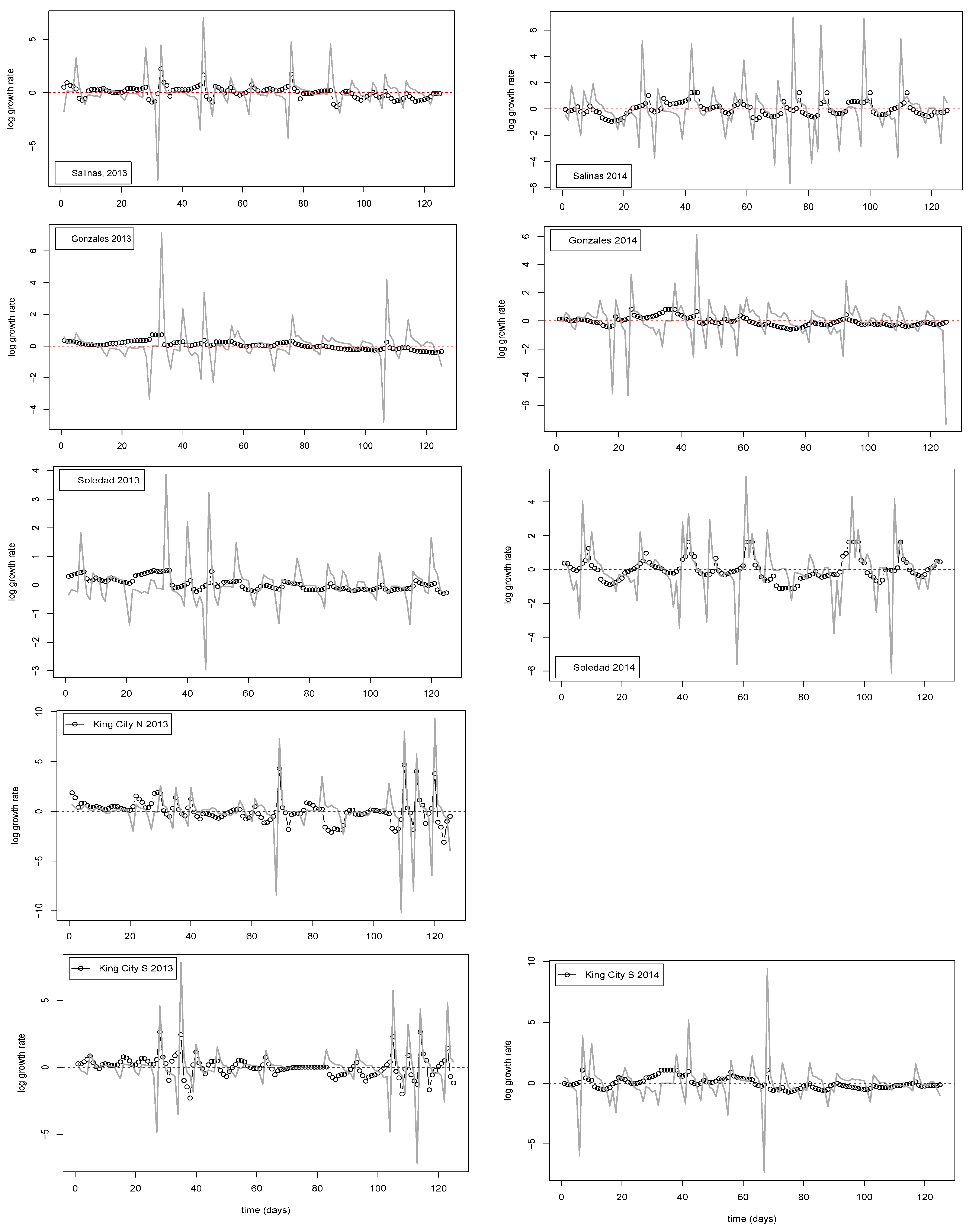
If we consider the data in relation to variability in time and space, there are clear implications for making robust inferences about the quantity of pathogen inoculum in the air. For example, at three of the four locations where samplers were deployed in two successive years, the dynamics were classed as linear in one year and not linear in the other. The four locations sampled span a linear distance of approximately 80 km from Salinas in the north to King City in the south. In 2014, a year with relatively little pathogen activity, peaks in trap counts, and corresponding time series of entropy values showed relatively good agreement. In contrast, in 2013, when inoculum pressure was higher, generally, there was much less agreement between locations, and extrapolation from one location to another would not necessarily have yielded robust conclusions about the dynamics of the pathogen. The most striking example is the contrast between Salinas and King City S. In Salinas between day 20 and day 80, trap catches were relatively low and the cumulative value of the entropy showed a steady decline from approximately 1.5 nats to under 1 nat. In contrast, over the same period in King City, multiple peaks in trap catches were noted and entropy in the catch data rose from approximately 1 nat to approximately 2 nats.
Inevitably, in a first use of a new methodology in a specific field of application, there are numerous things that could have been done that were not. The focus of our analyses was on the dynamics and properties of the times series when analyzed on a daily time step. It is probably not surprising that the binary series indicating the direction of change was close to its maximum entropy value over much of the season in both years at most locations. This result suggests that, on average on any given day, a sample from the next day is as likely to be higher as it is to be lower than the sample from the current day. Technical advances in sample preparation are reducing the time it takes to process nucleic acid samples from spore traps. As a consequence, the apparent possibility of real-time forecasting of disease risk on a daily basis is increasing. One possible interpretation of our findings is, however, that the usefulness of such forecasts may be limited by the inherent uncertainty of the data. Is there predictive value for decision making in knowing today’s trap value if tomorrow’s value may be higher or lower with equal probability? The results obtained here indicate that the binary strings derived from the time series data are close to being simple sequences of independent Bernoulli trials with a probability of 0.5 determining the outcome. As Grünwald [
27] points out, model selection and fitting can be considered as analogous to data compression, and when a string of bits is essentially random, it is difficult to achieve an accurate description (i.e., compression) of the data that is more concise than simply writing the data out.
Aggregating results to form moving averages over longer runs of days would perhaps lead to information values that were more easily linked to disease outcomes, but the detailed work to examine this issue lies beyond the scope of this study. The objective of our work was not to explore whether entropy values can be used as a predictive indicator for disease risk but to characterize the uncertainty of time series data from spore traps to give practitioners a richer perspective on the level and nature of the uncertainty inherent in the data they collect.
Looking at the entropy values for the two seasons retrospectively, it is clear (
Figure 1) that the cumulative entropy values have a qualitatively different nature in the two seasons. Moving from consideration of uncertainty within a season to differences in uncertainty between seasons, the results presented here suggest that information quantities might provide an alternative means of classifying growing seasons, but the extra value to epidemiology (compared with what can be learned from direct comparison of the trap data themselves, for example) that might be gained from long-term comparative analyses is not known at this time. We hope others will be encouraged to further analyze the open questions raised here; this is a new field for future research.
Our analyses suggest that there may be quite severe practical limitations to being able to characterize pathogen dynamics using the combination of vortex air sampling and DNA target amplification. There are clear cases where detection of primary inoculum helps to improve disease management [
9,
11], but the situation regarding season-long disease management based on measuring secondary inoculum is much less clear. There are few, if any, other published datasets for comparison so the potential remains uncertain. However, even with data series extending to over 100 data points, the fact that the coefficient of prediction for autoregressive models was close to zero is an indication that the time series may be so noisy that extracting a useful, succinct model of the dynamics may be difficult. While our results point to restrictions in the utility of dynamical analysis for helping with practical problems in disease risk forecasting, at the same time, they suggest a great deal of interesting investigative research on inoculum dynamics and their positions on the continuum form pure deterministic complexity to pure stochastic noise.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}