Objective Bayesian Inference in Probit Models with Intrinsic Priors Using Variational Approximations


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- Avoiding manually set ad hoc plugin priors by automatically generating a family of non-informative priors that are less sensible.
- Reference [1,2] do not consider inference of posterior distributions of parameters. Their focus is on model comparison. Although the development of intrinsic priors itself comes from a model selection background, we thought it would be interesting to apply intrinsic priors on inference problems. In fact, some recently developed priors that proposed to solve inference or estimation problems turned out to be also intrinsic priors. For example, the Scaled Beta2 prior [9] and the Matrix-F prior [10].
- Intrinsic priors concentrate probability near the null hypothesis, a condition that is widely accepted and should be required of a prior for testing a hypothesis.
- Also, intrinsic priors have flat tails that prevents finite sample inconsistency [11].
- For inference problems with large data set, variational approximation methods are much faster than MCMC-based methods.
2. Background and Development of Intrinsic Prior Methodology
2.1. Bayes Factor
2.2. Motivation and Development of Intrinsic Prior
3. Objective Bayesian Probit Regression Models
3.1. Bayesian Probit Model and the Use of Auxiliary Variables
3.2. Development of Intrinsic Prior for Probit Models
4. Variational Inference
4.1. Overview of Variational Methods
4.2. Factorized Distributions
| Algorithm 1 Iterative procedure for obtaining the optimal densities under factorized density restriction (16). The updates are based on the solutions given by (19). |
|
5. Incorporate Intrinsic Prior with Variational Approximation to Bayesian Probit Models
5.1. Derivation of Intrinsic Prior to Be Used in Variational Inference
5.2. Variational Inference for Probit Model with Intrinsic Prior
5.2.1. Iterative Updates for Factorized Distributions


| Algorithm 2 Iterative procedure for updating parameters to reach optimal factor densities and in Bayesian probit regression model. The updates are based on the solutions given by (26) and (27). |
|
5.2.2. Evaluation of the Lower Bound
Part 1:
Part 2:
Part 3:
Part 4:
5.3. Model Comparison Based on Variational Approximation
6. Modeling Probability of Default Using Lending Club Data
6.1. Introduction
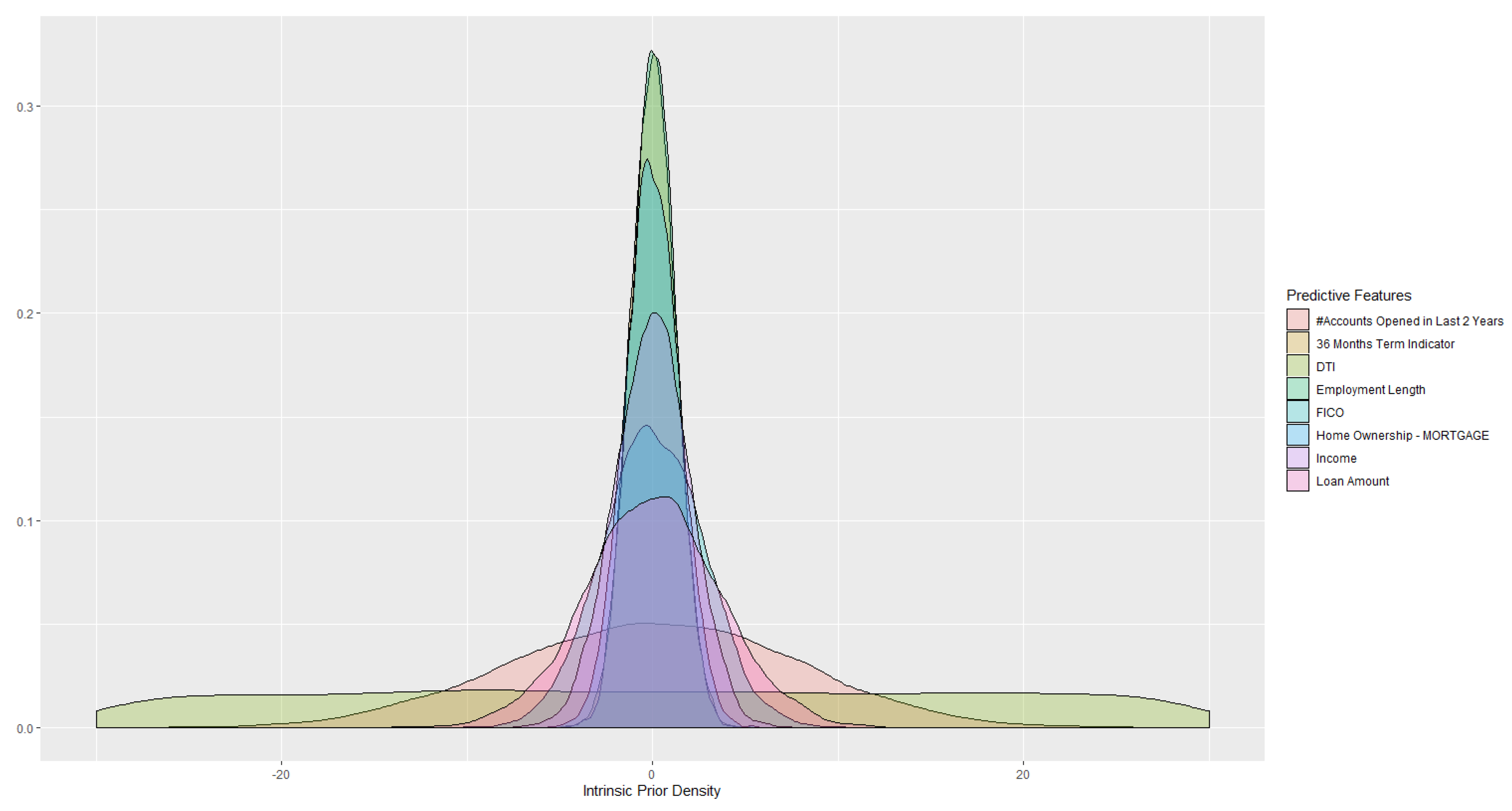
6.2. Modeling Probability of Default—Target Variable and Predictive Features
- Loan term in months (either 36 or 60)
- FICO
- Issued loan amount
- DTI (Debt to income ratio, i.e., customer’s total debt divided by income)
- Number of credit lines opened in past 24 months
- Employment length in years
- Annual income
- Home ownership type (own, mortgage, of rent)
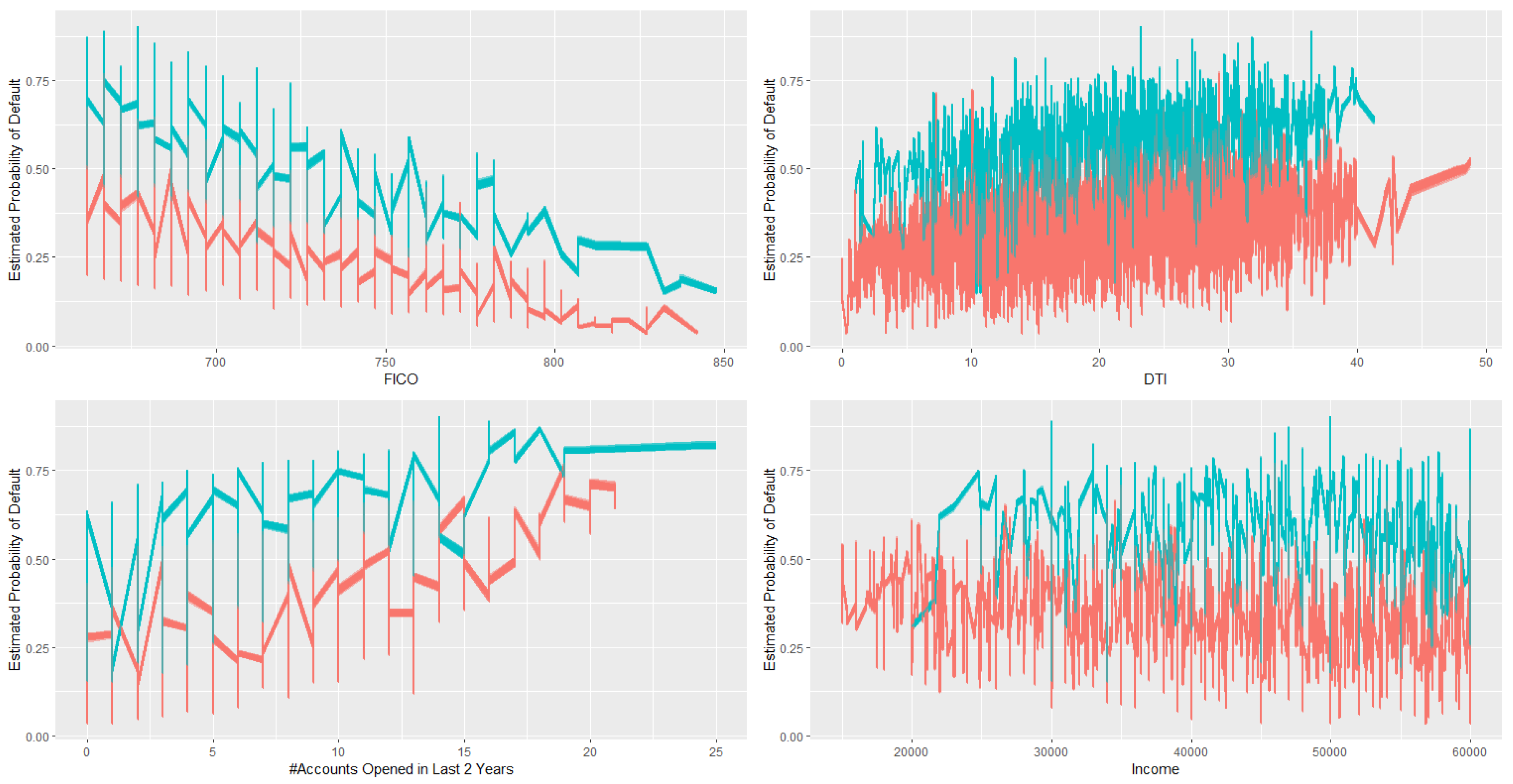
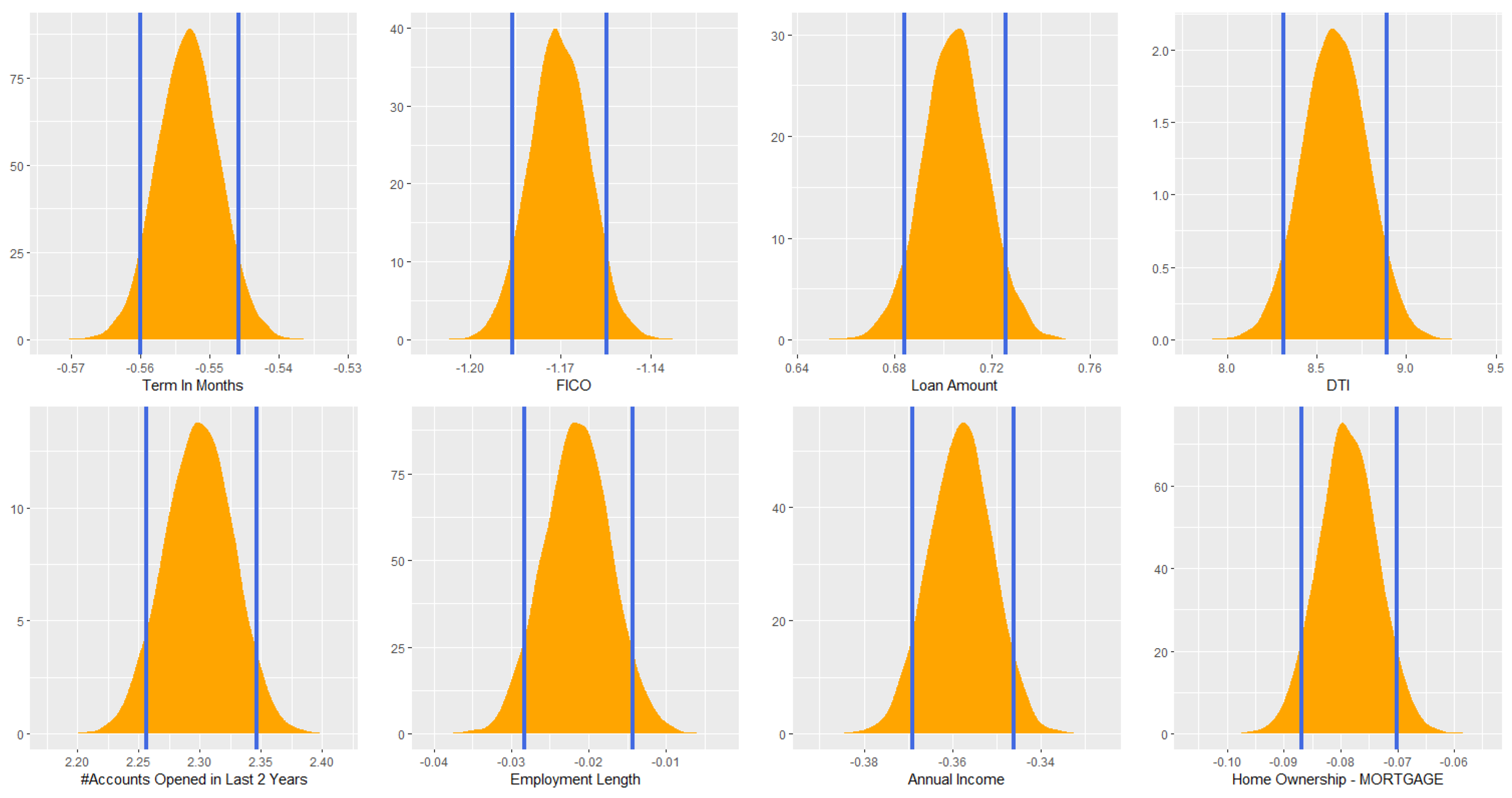
6.3. Addressing Uncertainty of Estimated Probit Model Using Variational Inference with Intrinsic Prior
- In general, 60 months loans have higher risk of default.
- Given loan term months, there is a clear trend showing that high FICO means lower risk.
- Given loan term months, there is a trend showing that high DTI indicating higher risk.
- Given loan term months, there is a trend showing that more credit lines opened in past 24 months indicating higher risk.
- There is no clear pattern regarding income. This is probably because we only included customers with income between $15,000 and $60,000 in our training data, which may not representing the true income level of the whole population.
- with a conjugate prior and following the Gibbs sampling scheme proposed by [17], it took 89.86 s to finish 100 simulations for the Gibbs sampler;
- following our method proposed in Section 5.2, it took 58.38 s to get the approximated posterior distribution and sampling 10,000 times from that posterior.
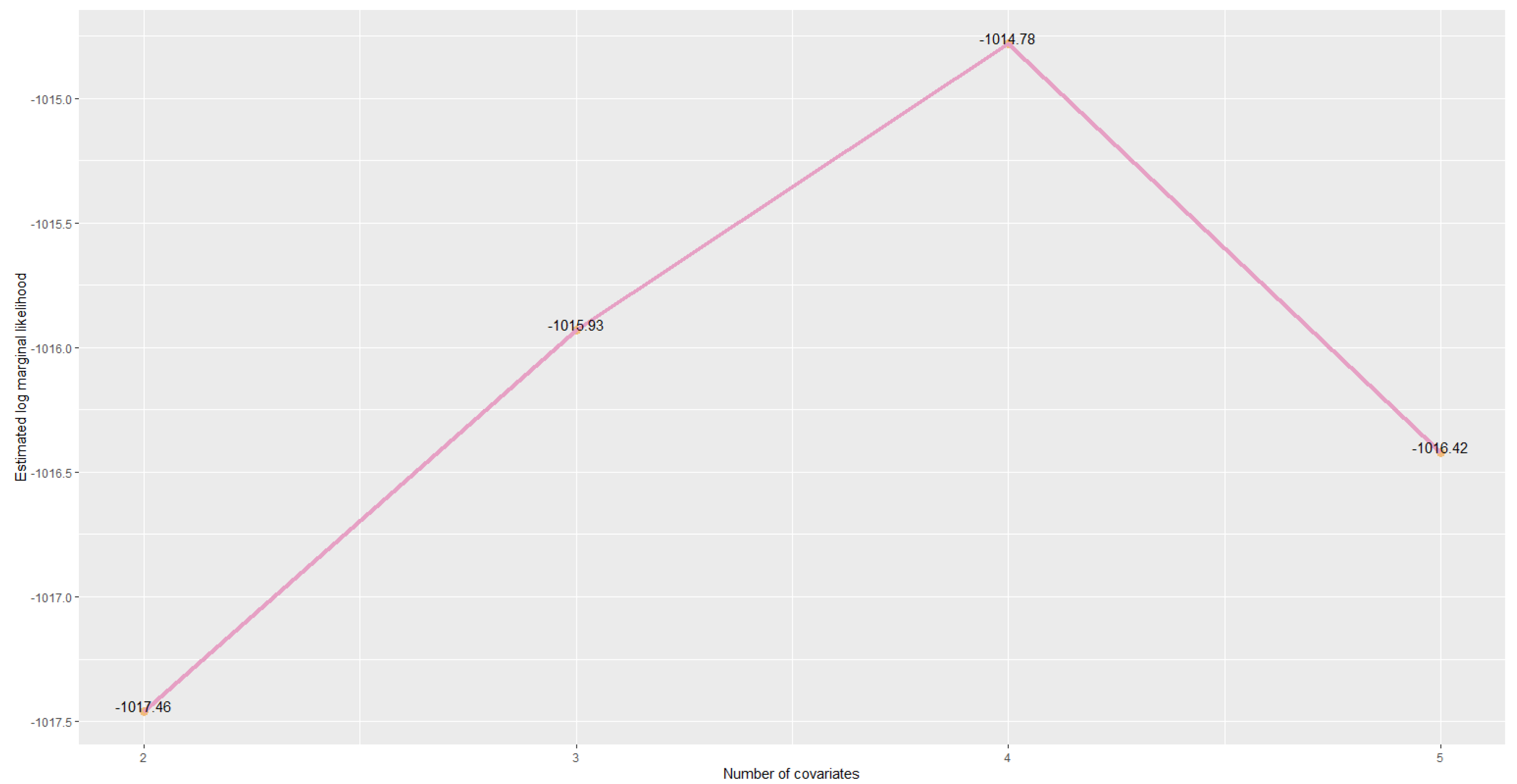
6.4. Model Comparison
- : FICO + Term 36 Indicator
- : FICO + Term 36 Indicator + Loan Amount
- : FICO + Term 36 Indicator + Loan Amount + Annual Income
- : FICO + Term 36 Indicator + Loan Amount + Annual Income + Mortgage Indicator
7. Further Work
Author Contributions
Funding
Conflicts of Interest
Appendix A. Density Function
Appendix B. Moments and Entropy
References
- Salmeron, D.; Cano, J.A.; Robert, C.P. Objective Bayesian hypothesis testing in binomial regression models with integral prior distributions. Stat. Sin. 2015, 25, 1009–1023. [Google Scholar] [CrossRef]
- Leon-Novelo, L.; Moreno, E.; Casella, G. Objective Bayes model selection in probit models. Stat. Med. 2012, 31, 353–365. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jaakkola, T.S.; Jordan, M.I. Bayesian parameter estimation via variational methods. Stat. Comput. 2000, 10, 25–37. [Google Scholar] [CrossRef]
- Girolami, M.; Rogers, S. Variational Bayesian multinomial probit regression with Gaussian process priors. Neural Comput. 2006, 18, 1790–1817. [Google Scholar] [CrossRef]
- Consonni, G.; Marin, J.M. Mean-field variational approximate Bayesian inference for latent variable models. Comput. Stat. Data Anal. 2007, 52, 790–798. [Google Scholar] [CrossRef] [Green Version]
- Ormerod, J.T.; Wand, M.P. Explaining variational approximations. Am. Stat. 2010, 64, 140–153. [Google Scholar] [CrossRef] [Green Version]
- Grimmer, J. An introduction to Bayesian inference via variational approximations. Political Anal. 2010, 19, 32–47. [Google Scholar] [CrossRef]
- Blei, D.M.; Kucukelbir, A.; McAuliffe, J.D. Variational inference: A review for statisticians. J. Am. Stat. Assoc. 2017, 112, 859–877. [Google Scholar] [CrossRef] [Green Version]
- Pérez, M.E.; Pericchi, L.R.; Ramírez, I.C. The Scaled Beta2 distribution as a robust prior for scales. Bayesian Anal. 2017, 12, 615–637. [Google Scholar] [CrossRef]
- Mulder, J.; Pericchi, L.R. The matrix-F prior for estimating and testing covariance matrices. Bayesian Anal. 2018, 13, 1193–1214. [Google Scholar] [CrossRef]
- Berger, J.O.; Pericchi, L.R. Objective Bayesian Methods for Model Selection: Introduction and Comparison. In Model Selection; Institute of Mathematical Statistics: Beachwood, OH, USA, 2001; pp. 135–207. [Google Scholar]
- Pericchi, L.R. Model selection and hypothesis testing based on objective probabilities and Bayes factors. Handb. Stat. 2005, 25, 115–149. [Google Scholar]
- Scott, J.G.; Berger, J.O. Bayes and empirical-Bayes multiplicity adjustment in the variable-selection problem. Ann. Stat. 2010, 38, 2587–2619. [Google Scholar] [CrossRef] [Green Version]
- Jeffreys, H. The Theory of Probability; OUP: Oxford, UK, 1961. [Google Scholar]
- Berger, J.O.; Pericchi, L.R. The intrinsic Bayes factor for model selection and prediction. J. Am. Stat. Assoc. 1996, 91, 109–122. [Google Scholar] [CrossRef]
- Leamer, E.E. Specification Searches: Ad Hoc Inference with Nonexperimental Data; Wiley: New York, NY, USA, 1978; Volume 53. [Google Scholar]
- Albert, J.H.; Chib, S. Bayesian analysis of binary and polychotomous response data. J. Am. Stat. Assoc. 1993, 88, 669–679. [Google Scholar] [CrossRef]
- Tanner, M.A.; Wong, W.H. The calculation of posterior distributions by data augmentation. J. Am. Stat. Assoc. 1987, 82, 528–540. [Google Scholar] [CrossRef]
- Berger, J.O.; Pericchi, L.R. The intrinsic Bayes factor for linear models. Bayesian Stat. 1996, 5, 25–44. [Google Scholar]
- Casella, G.; Moreno, E. Objective Bayesian variable selection. J. Am. Stat. Assoc. 2006, 101, 157–167. [Google Scholar] [CrossRef]
- Moreno, E.; Bertolino, F.; Racugno, W. An intrinsic limiting procedure for model selection and hypotheses testing. J. Am. Stat. Assoc. 1998, 93, 1451–1460. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Jordan, M.I.; Ghahramani, Z.; Jaakkola, T.S.; Saul, L.K. An introduction to variational methods for graphical models. Mach. Learn. 1999, 37, 183–233. [Google Scholar] [CrossRef]
- Parisi, G.; Shankar, R. Statistical field theory. Phys. Today 1988, 41, 110. [Google Scholar] [CrossRef]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Berger, J.; Pericchi, L. Training samples in objective Bayesian model selection. Ann. Stat. 2004, 32, 841–869. [Google Scholar] [CrossRef] [Green Version]
- Beal, M.J. Variational Algorithms for Approximate Bayesian Inference; University College London: London, UK, 2003. [Google Scholar]
- Kruschke, J. Doing Bayesian Data Analysis: A Tutorial with R, JAGS, and Stan; Academic Press: Cambridge, MA, USA, 2014. [Google Scholar]
- McElreath, R. Statistical Rethinking: A Bayesian Course with Examples in R and Stan; Chapman and Hall/CRC: Boca Raton, FL, USA, 2018. [Google Scholar]
- Giordano, R.J.; Broderick, T.; Jordan, M.I. Linear response methods for accurate covariance estimates from mean field variational Bayes. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, USA, 7–12 December 2015; pp. 1441–1449. [Google Scholar]




© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, A.; Pericchi, L.; Wang, K. Objective Bayesian Inference in Probit Models with Intrinsic Priors Using Variational Approximations. Entropy 2020, 22, 513. https://doi.org/10.3390/e22050513
Li A, Pericchi L, Wang K. Objective Bayesian Inference in Probit Models with Intrinsic Priors Using Variational Approximations. Entropy. 2020; 22(5):513. https://doi.org/10.3390/e22050513
Chicago/Turabian StyleLi, Ang, Luis Pericchi, and Kun Wang. 2020. "Objective Bayesian Inference in Probit Models with Intrinsic Priors Using Variational Approximations" Entropy 22, no. 5: 513. https://doi.org/10.3390/e22050513
APA StyleLi, A., Pericchi, L., & Wang, K. (2020). Objective Bayesian Inference in Probit Models with Intrinsic Priors Using Variational Approximations. Entropy, 22(5), 513. https://doi.org/10.3390/e22050513