Ensemble Fuzzy Feature Selection Based on Relevancy, Redundancy, and Dependency Criteria



Abstract
:1. Introduction
2. Relevancy, Redundancy, and Dependency Measures
2.1. Relevancy
2.2. Redundancy
2.3. Dependency
2.4. Example
3. Related Works
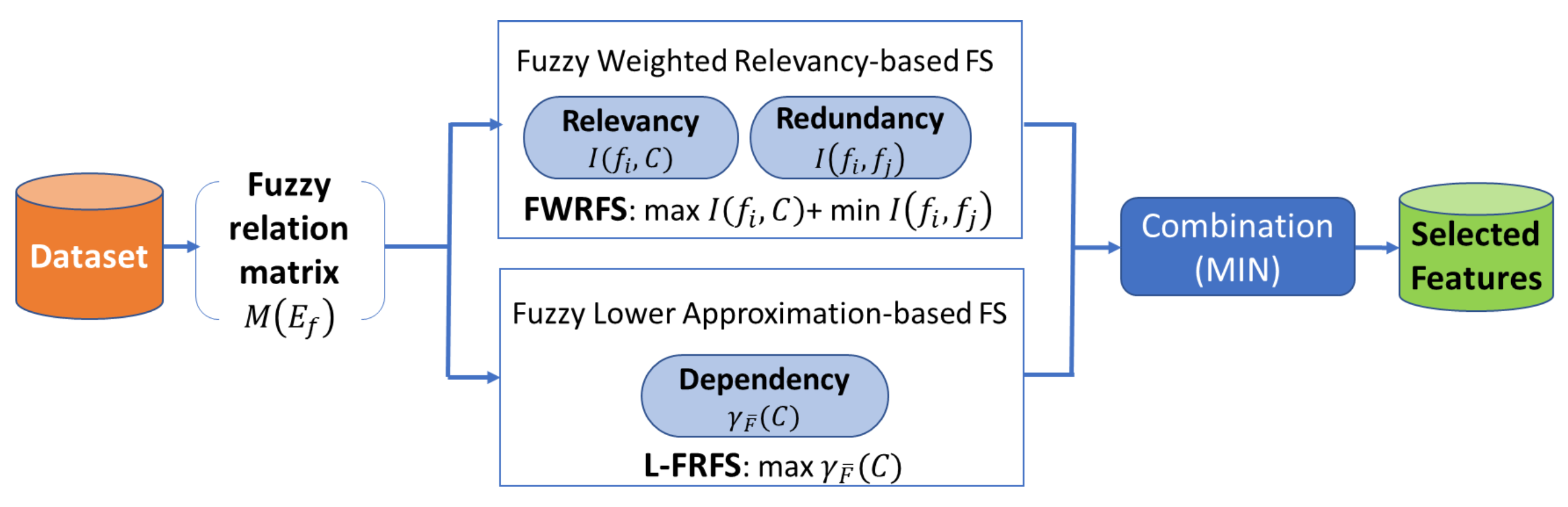
4. Fuzzy Feature Selection Based on Relevancy, Redundancy, and Dependency (FFS-RRD)
| Algorithm 1: FFS-RRD: fuzzy feature selection based relevancy, redundancy, and dependency. |
 |
5. Experiment Setup
5.1. Dataset
5.2. Compared Feature Selection Methods
5.3. Evaluation Metrics
5.3.1. Classification Performance
5.3.2. Stability Evaluation
6. Results Analysis
6.1. Classification Performance
6.1.1. Accuracy
6.1.2. F-Measure
6.1.3. AUC
6.2. Stability
7. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Macedo, F.; Oliveira, M.R.; Pacheco, A.; Valadas, R. Theoretical foundations of forward feature selection methods based on mutual information. Neurocomputing 2019, 325, 67–89. [Google Scholar] [CrossRef] [Green Version]
- Bolón-Canedo, V.; Alonso-Betanzos, A. Ensembles for feature selection: A review and future trends. Inf. Fusion 2019, 52, 1–12. [Google Scholar] [CrossRef]
- Lee, S.; Park, Y.T.; d’Auriol, B.J. A novel feature selection method based on normalized mutual information. Appl. Intell. 2012, 37, 100–120. [Google Scholar]
- Lazar, C.; Taminau, J.; Meganck, S.; Steenhoff, D.; Coletta, A.; Molter, C.; de Schaetzen, V.; Duque, R.; Bersini, H.; Nowe, A. A survey on filter techniques for feature selection in gene expression microarray analysis. IEEE/ACM Trans. Comput. Biol. Bioinform. 2012, 9, 1106–1119. [Google Scholar] [CrossRef]
- Imani, M.B.; Keyvanpour, M.R.; Azmi, R. A novel embedded feature selection method: A comparative study in the application of text categorization. Appl. Artif. Intell. 2013, 27, 408–427. [Google Scholar] [CrossRef]
- Kohavi, R.; John, G.H. Wrappers for feature subset selection. Artif. Intell. 1997, 97, 273–324. [Google Scholar] [CrossRef] [Green Version]
- Hu, L.; Gao, W.; Zhao, K.; Zhang, P.; Wang, F. Feature selection considering two types of feature relevancy and feature interdependency. Expert Syst. Appl. 2018, 93, 423–434. [Google Scholar] [CrossRef]
- Saeys, Y.; Inza, I.; Larrañaga, P. A review of feature selection techniques in bioinformatics. Bioinformatics 2007, 23, 2507–2517. [Google Scholar] [CrossRef] [Green Version]
- Oreski, D.; Oreski, S.; Klicek, B. Effects of dataset characteristics on the performance of feature selection techniques. Appl. Soft Comput. 2017, 52, 109–119. [Google Scholar] [CrossRef]
- Bonev, B. Feature Selection Based on Information Theory; Universidad de Alicante: Alicante, Spain, 2010. [Google Scholar]
- Caballero, Y.; Alvarez, D.; Bello, R.; Garcia, M.M. Feature selection algorithms using rough set theory. In Proceedings of the IEEE Seventh International Conference on Intelligent Systems Design and Applications (ISDA 2007), Rio de Janeiro, Brazilm, 20–24 October 2007; pp. 407–411. [Google Scholar]
- Che, J.; Yang, Y.; Li, L.; Bai, X.; Zhang, S.; Deng, C. Maximum relevance minimum common redundancy feature selection for nonlinear data. Inf. Sci. 2017, 409, 68–86. [Google Scholar] [CrossRef]
- Pawlak, Z. Rough Sets: Theoretical Aspects of Reasoning about Data; Kluwer Academic Publishers: Dordrecht, The Netherlands, 1991. [Google Scholar]
- Hu, Q.; Yu, D.; Xie, Z. Information-preserving hybrid data reduction based on fuzzy-rough techniques. Pattern Recognit. Lett. 2006, 27, 414–423. [Google Scholar] [CrossRef]
- Yu, D.; An, S.; Hu, Q. Fuzzy mutual information based min-redundancy and max-relevance heterogeneous feature selection. Int. J. Comput. Intell. Syst. 2011, 4, 619–633. [Google Scholar] [CrossRef]
- Jensen, R.; Shen, Q. New approaches to fuzzy-rough feature selection. IEEE Trans. Fuzzy Syst. 2008, 17, 824–838. [Google Scholar] [CrossRef] [Green Version]
- Hüllermeier, E. Fuzzy sets in machine learning and data mining. Appl. Soft Comput. 2011, 11, 1493–1505. [Google Scholar] [CrossRef] [Green Version]
- Freeman, C.; Kulić, D.; Basir, O. An evaluation of classifier-specific filter measure performance for feature selection. Pattern Recognit. 2015, 48, 1812–1826. [Google Scholar] [CrossRef]
- Jensen, R.; Shen, Q. Fuzzy-rough sets for descriptive dimensionality reduction. In Proceedings of the 2002 IEEE World Congress on Computational Intelligence. 2002 IEEE International Conference on Fuzzy Systems, FUZZ-IEEE’02, Honolulu, HI, USA, 12–17 May 2002; Proceedings (Cat. No. 02CH37291). Volume 1, pp. 29–34. [Google Scholar]
- Vergara, J.R.; Estévez, P.A. A review of feature selection methods based on mutual information. Neural Comput. Appl. 2014, 24, 175–186. [Google Scholar] [CrossRef]
- Lewis, D.D. Feature selection and feature extraction for text categorization. In Proceedings of the Workshop on Speech and Natural Language; Association for Computational Linguistics: Stroudsburg, PA, USA, 1992; pp. 212–217. [Google Scholar]
- Battiti, R. Using mutual information for selecting features in supervised neural net learning. IEEE Trans. Neural Netw. 1994, 5, 537–550. [Google Scholar] [CrossRef] [Green Version]
- Kwak, N.; Choi, C.H. Input feature selection for classification problems. IEEE Trans. Neural Netw. 2002, 13, 143–159. [Google Scholar] [CrossRef]
- Peng, H.; Long, F.; Ding, C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Onpattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef]
- Yang, H.; Moody, J. Feature selection based on joint mutual information. In Proceedings of the International ICSC Symposium on Advances in Intelligent Data Analysis, Genova, Italy, 1–4 June 1999; pp. 22–25. [Google Scholar]
- Fleuret, F. Fast binary feature selection with conditional mutual information. J. Mach. Learn. Res. 2004, 5, 1531–1555. [Google Scholar]
- Bennasar, M.; Hicks, Y.; Setchi, R. Feature selection using joint mutual information maximisation. Expert Syst. Appl. 2015, 42, 8520–8532. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Wei, J.M.; Yang, Z.; Wang, S.Q. Feature selection by maximizing independent classification information. IEEE Trans. Knowl. Data Eng. 2017, 29, 828–841. [Google Scholar] [CrossRef]
- Zhang, P.; Gao, W.; Liu, G. Feature selection considering weighted relevancy. Appl. Intell. 2018, 48, 4615–4625. [Google Scholar] [CrossRef]
- Hassanien, A.E.; Suraj, Z.; Slezak, D.; Lingras, P. Rough Computing: Theories, Technologies and Applications; IGI Global Hershey: Hershey, PA, USA, 2008. [Google Scholar]
- Chouchoulas, A.; Shen, Q. Rough set-aided keyword reduction for text categorization. Appl. Artif. Intell. 2001, 15, 843–873. [Google Scholar] [CrossRef]
- Han, J.; Hu, X.; Lin, T.Y. Feature subset selection based on relative dependency between attributes. In International Conference on Rough Sets and Current Trends in Computing; Springer: Berlin, Germany, 2004; pp. 176–185. [Google Scholar]
- Zhong, N.; Dong, J.; Ohsuga, S. Using rough sets with heuristics for feature selection. J. Intell. Inf. Syst. 2001, 16, 199–214. [Google Scholar] [CrossRef]
- Jensen, R.; Shen, Q. Fuzzy–rough attribute reduction with application to web categorization. Fuzzy Sets Syst. 2004, 141, 469–485. [Google Scholar] [CrossRef] [Green Version]
- Ziarko, W. Variable precision rough set model. J. Comput. Syst. Sci. 1993, 46, 39–59. [Google Scholar] [CrossRef] [Green Version]
- Zhang, M.; Yao, J. A rough sets based approach to feature selection. In Proceedings of the IEEE Annual Meeting of the Fuzzy Information, Banff, AB, Canada, 27–30 June 2004; Processing NAFIPS’04. Volume 1, pp. 434–439. [Google Scholar]
- Ching, J.Y.; Wong, A.K.; Chan, K.C.C. Class-dependent discretization for inductive learning from continuous and mixed-mode data. IEEE Trans. Pattern Anal. Mach. Intell. 1995, 17, 641–651. [Google Scholar] [CrossRef]
- Kwak, N.; Choi, C.H. Input feature selection by mutual information based on Parzen window. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 1667–1671. [Google Scholar] [CrossRef] [Green Version]
- Garcia, S.; Luengo, J.; Sáez, J.A.; Lopez, V.; Herrera, F. A survey of discretization techniques: Taxonomy and empirical analysis in supervised learning. IEEE Trans. Knowl. Data Eng. 2012, 25, 734–750. [Google Scholar] [CrossRef]
- Herman, G.; Zhang, B.; Wang, Y.; Ye, G.; Chen, F. Mutual information-based method for selecting informative feature sets. Pattern Recognit. 2013, 46, 3315–3327. [Google Scholar] [CrossRef]
- Shen, Q.; Jensen, R. Selecting informative features with fuzzy-rough sets and its application for complex systems monitoring. Pattern Recognit. 2004, 37, 1351–1363. [Google Scholar] [CrossRef]
- Dua, D.; Graff, C. UCI Machine Learning Repository; University of California, School of Information and Computer Science: Irvine, CA, USA, 2017. [Google Scholar]
- Lin, D.; Tang, X. Conditional infomax learning: An integrated framework for feature extraction and fusion. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2006; pp. 68–82. [Google Scholar]
- Sechidis, K.; Azzimonti, L.; Pocock, A.; Corani, G.; Weatherall, J.; Brown, G. Efficient feature selection using shrinkage estimators. Mach. Learn. 2019, 108, 1261–1286. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Guo, B.; Shen, Y.; Zhou, C.; Duan, X. Input Feature Selection Method Based on Feature Set Equivalence and Mutual Information Gain Maximization. IEEE Access 2019, 7, 151525–151538. [Google Scholar] [CrossRef]
- Dougherty, J.; Kohavi, R.; Sahami, M. Supervised and unsupervised discretization of continuous features. In Machine Learning Proceedings 1995; Elsevier: Amsterdam, The Netherlands, 1995; pp. 194–202. [Google Scholar]
- Li, Y.; Si, J.; Zhou, G.; Huang, S.; Chen, S. FREL: A stable feature selection algorithm. IEEE Trans. Neural Networks Learn. Syst. 2014, 26, 1388–1402. [Google Scholar] [CrossRef]
- Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. Ijcai 1995, 14, 1137–1145. [Google Scholar]
- Pes, B.; Dessì, N.; Angioni, M. Exploiting the ensemble paradigm for stable feature selection: A case study on high-dimensional genomic data. Inf. Fusion 2017, 35, 132–147. [Google Scholar] [CrossRef]
- Nogueira, S.; Brown, G. Measuring the stability of feature selection. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2016; pp. 442–457. [Google Scholar]
- Tsai, Y.S.; Yang, U.C.; Chung, I.F.; Huang, C.D. A comparison of mutual and fuzzy-mutual information-based feature selection strategies. In Proceedings of the 2013 IEEE International Conference on Fuzzy Systems (FUZZ), Hyderabad, India, 7–10 July 2013; pp. 1–6. [Google Scholar]
- Kuncheva, L.I. A stability index for feature selection. In Proceedings of the 25th IASTED International Multi-Conference Artificial Intelligence and Applications, Innsbruck, Austria, 12–14 February 2007; pp. 421–427. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| C | ||
|---|---|---|
| 0.2 0.8 0.4 0.6 0.2 | 0.1 0.5 0.3 0.4 0.1 | 1 0 1 0 1 |
| Dataset | Brief | # Instances | # Features | # Classes |
|---|---|---|---|---|
| Breast Cancer Wisconsin (Prognostic) | BCW Prognostic | 198 | 33 | 2 |
| Breast Cancer Wisconsin (Diagnostic) | BCW Diagnostic | 569 | 31 | 2 |
| Climate Model Simulation Crashes | CMSC | 540 | 18 | 2 |
| Credit Approval | Credit Approval | 690 | 15 | 2 |
| Dermatology | Dermatology | 336 | 34 | 6 |
| Diabetic Retinopathy Debrecen | DRD | 1151 | 19 | 2 |
| Fertility | Fertility | 100 | 9 | 2 |
| Statlog (Heart) | Heart | 270 | 13 | 2 |
| Ionosphere | Ionosphere | 351 | 34 | 2 |
| Iris | Iris | 150 | 4 | 3 |
| Libras Movement | Libras Movement | 360 | 90 | 15 |
| QSAR biodegradation | QSAR | 1055 | 41 | 2 |
| Zoo | Zoo | 101 | 16 | 7 |
| Ref. | FS Group | FS Method | Discriminative Ability | |
|---|---|---|---|---|
| Individually | Dependency | |||
| [43] | Probability-based | CIFE | ✓ | |
| [25] | JMI | ✓ | ||
| [27] | JMIM | ✓ | ||
| [29] | WRFS | ✓ | ||
| [44] | CMIM3 | ✓ | ||
| [44] | JMI3 | ✓ | ||
| [45] | MIGM | ✓ | ||
| [16] | Fuzzy-based | L-FRFS | ✓ | |
| Proposed | FFS-RRD | ✓ | ✓ | |
| Dataset | CIFE | JMI | JMIM | WRFS | CMIM3 | JMI3 | MIGM | L-FRFS | FFS-RRD |
|---|---|---|---|---|---|---|---|---|---|
| BCW Prognostic | 73.9 | 69.5 | 73.8 | 65.4 | 68.6 | 68.8 | 67.7 | 71.3 | 69.8 |
| BCW Diagnostic | 92.0 | 93.4 | 93.4 | 93.6 | 93.2 | 92.4 | 92.9 | 85.9 | 93.6 |
| CMSC | 91.9 | 93.8 | 91.9 | 94.1 | 93.6 | 92.8 | 93.8 | 93.7 | 93.8 |
| Credit Approval | 85.6 | 83.5 | 83.7 | 86.9 | 82.4 | 83.7 | 84.8 | 76.8 | 85.4 |
| Dermatology | 96.1 | 93.9 | 95.3 | 93.1 | 98.0 | 94.6 | 95.3 | 96.2 | 96.1 |
| DRD | 57.6 | 60.3 | 57.6 | 57.5 | 57.7 | 60.6 | 60.3 | 57.6 | 57.5 |
| Fertility | 87.9 | 87.9 | 88.0 | 88.0 | 88.0 | 88.0 | 87.9 | 88.0 | 88.0 |
| Heart | 80.1 | 83.0 | 81.0 | 84.1 | 83.0 | 83.9 | 80.1 | 75.1 | 81.5 |
| Ionosphere | 77.0 | 82.6 | 86.2 | 80.8 | 84.8 | 84.8 | 77.4 | 89.8 | 89.0 |
| Iris | 94.6 | 94.6 | 94.6 | 94.6 | 93.5 | 93.5 | 93.5 | 95.0 | 95.0 |
| Libras Movement | 51.4 | 61.7 | 60.8 | 50.5 | 59.0 | 59.0 | 59.4 | 61.0 | 60.0 |
| QSAR | 78.2 | 78.7 | 77.1 | 78.5 | 78.7 | 78.1 | 77.6 | 77.7 | 80.0 |
| Zoo | 94.2 | 95.1 | 96.0 | 96.0 | 96.1 | 96.0 | 96.9 | 93.5 | 94.9 |
| Average | 81.6 | 82.9 | 83.0 | 81.8 | 82.8 | 82.8 | 82.1 | 81.7 | 83.4 |
| Dataset | CIFE | JMI | JMIM | WRFS | CMIM3 | JMI3 | MIGM | L-FRFS | FFS-RRD |
|---|---|---|---|---|---|---|---|---|---|
| BCW Prognostic | 76.3 | 76.8 | 77.9 | 76.3 | 76.4 | 77.7 | 76.6 | 76.3 | 77.5 |
| BCW Diagnostic | 96.3 | 97.3 | 97.3 | 97.5 | 96.9 | 95.0 | 95.6 | 88.4 | 96.3 |
| CMSC | 91.5 | 92.0 | 91.5 | 93.2 | 91.9 | 91.6 | 91.9 | 92.1 | 91.9 |
| Credit Approval | 85.5 | 85.5 | 85.5 | 85.5 | 85.5 | 85.5 | 85.5 | 73.7 | 85.5 |
| Dermatology | 95.8 | 95.5 | 95.8 | 94.2 | 98.2 | 96.8 | 95.7 | 96.8 | 96.5 |
| DRD | 68.0 | 67.2 | 68.0 | 67.7 | 67.5 | 67.0 | 67.2 | 68.0 | 67.7 |
| Fertility | 88.0 | 88.0 | 88.0 | 88.0 | 88.0 | 88.0 | 88.0 | 88.0 | 88.0 |
| Heart | 79.7 | 84.3 | 84.3 | 84.2 | 81.3 | 83.7 | 79.7 | 76.3 | 82.5 |
| Ionosphere | 76.6 | 79.0 | 78.5 | 81.2 | 81.7 | 82.9 | 78.0 | 86.7 | 87.6 |
| Iris | 95.7 | 95.7 | 95.7 | 95.9 | 93.9 | 93.9 | 93.9 | 94.5 | 95.0 |
| Libras Movement | 72.2 | 76.1 | 74.7 | 67.6 | 75.5 | 74.9 | 74.5 | 76.5 | 75.3 |
| QSAR | 84.2 | 84.3 | 84.5 | 82.3 | 84.2 | 83.7 | 84.4 | 83.8 | 84.1 |
| Zoo | 92.8 | 95.3 | 88.7 | 93.3 | 93.9 | 89.5 | 94.1 | 92.0 | 95.3 |
| Average | 84.8 | 85.9 | 85.4 | 85.1 | 85.8 | 85.4 | 85.0 | 84.1 | 86.4 |
| Dataset | CIFE | JMI | JMIM | WRFS | CMIM3 | JMI3 | MIGM | L-FRFS | FFS-RRD |
|---|---|---|---|---|---|---|---|---|---|
| BCW Prognostic | 75.2 | 75.0 | 77.1 | 76.6 | 73.5 | 74.1 | 76.9 | 74.0 | 77.0 |
| BCW Diagnostic | 93.3 | 93.5 | 97.1 | 95.4 | 95.1 | 94.6 | 95.2 | 87.5 | 94.8 |
| CMSC | 90.1 | 92.3 | 90.1 | 92.0 | 90.9 | 92.4 | 92.6 | 93.4 | 93.0 |
| Credit Approval | 84.7 | 83.9 | 85.1 | 85.5 | 84.4 | 85.3 | 85.1 | 76.4 | 84.6 |
| Dermatology | 95.0 | 95.9 | 95.6 | 93.7 | 97.7 | 96.9 | 96.1 | 96.1 | 96.3 |
| DRD | 64.3 | 63.7 | 64.3 | 64.1 | 62.3 | 63.7 | 63.6 | 64.7 | 64.1 |
| Fertility | 88.7 | 88.7 | 87.2 | 86.7 | 84.0 | 90.5 | 88.7 | 85.0 | 89.4 |
| Heart | 77.7 | 79.1 | 79.1 | 81.7 | 79.3 | 77.7 | 77.6 | 71.7 | 78.2 |
| Ionosphere | 81.8 | 80.9 | 80.3 | 83.0 | 82.3 | 83.3 | 83.5 | 82.7 | 84.2 |
| Iris | 93.9 | 93.9 | 93.9 | 93.9 | 91.8 | 91.8 | 91.8 | 92.7 | 92.7 |
| Libras Movement | 70.7 | 76.8 | 77.9 | 70.4 | 77.1 | 74.7 | 78.3 | 75.8 | 78.3 |
| QSAR | 84.0 | 84.7 | 83.3 | 81.5 | 83.8 | 84.4 | 83.6 | 82.5 | 83.0 |
| Zoo | 90.1 | 94.1 | 91.6 | 93.1 | 92.1 | 92.1 | 91.2 | 89.7 | 94.3 |
| Average | 83.8 | 84.8 | 84.8 | 84.4 | 84.2 | 84.7 | 84.9 | 82.5 | 85.4 |
| Dataset | CIFE | JMI | JMIM | WRFS | CMIM3 | JMI3 | MIGM | L-FRFS | FFS-RRD |
|---|---|---|---|---|---|---|---|---|---|
| BCW Prognostic | 73.8 | 73.7 | 73.1 | 72.5 | 72.8 | 73.0 | 73.0 | 76.6 | 73.2 |
| BCW Diagnostic | 93.7 | 94.5 | 94.1 | 94.2 | 94.0 | 93.5 | 93.5 | 88.6 | 94.6 |
| CMSC | 89.6 | 91.2 | 89.6 | 90.3 | 91.4 | 91.2 | 91.3 | 91.3 | 91.6 |
| Credit Approval | 85.5 | 85.5 | 85.7 | 86.3 | 84.8 | 85.7 | 85.3 | 75.3 | 86.3 |
| Dermatology | 93.6 | 92.3 | 92.2 | 91.3 | 93.5 | 94.1 | 92.5 | 94.3 | 94.9 |
| DRD | 68.0 | 65.8 | 68.0 | 67.7 | 65.0 | 66.8 | 65.9 | 67.7 | 67.6 |
| Fertility | 87.1 | 87.1 | 87.1 | 87.6 | 86.6 | 86.6 | 87.1 | 87.5 | 87.5 |
| Heart | 73.9 | 80.3 | 81.3 | 80.6 | 76.3 | 77.6 | 74.0 | 74.3 | 75.5 |
| Ionosphere | 88.4 | 88.4 | 88.4 | 89.7 | 88.8 | 88.4 | 88.0 | 88.6 | 89.0 |
| Iris | 90.8 | 90.8 | 90.8 | 90.8 | 91.9 | 91.9 | 91.9 | 91.7 | 91.7 |
| Libras Movement | 60.4 | 66.0 | 65.6 | 61.3 | 64.7 | 64.3 | 67.5 | 66.0 | 66.4 |
| QSAR | 83.2 | 83.7 | 82.5 | 83.5 | 82.9 | 83.5 | 82.3 | 82.3 | 82.9 |
| Zoo | 91.9 | 94.0 | 92.3 | 92.9 | 93.4 | 92.1 | 94.1 | 96.0 | 97.1 |
| Average | 83.1 | 84.1 | 83.9 | 83.7 | 83.5 | 83.7 | 83.6 | 83.1 | 84.5 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salem, O.A.M.; Liu, F.; Chen, Y.-P.P.; Chen, X. Ensemble Fuzzy Feature Selection Based on Relevancy, Redundancy, and Dependency Criteria. Entropy 2020, 22, 757. https://doi.org/10.3390/e22070757
Salem OAM, Liu F, Chen Y-PP, Chen X. Ensemble Fuzzy Feature Selection Based on Relevancy, Redundancy, and Dependency Criteria. Entropy. 2020; 22(7):757. https://doi.org/10.3390/e22070757
Chicago/Turabian StyleSalem, Omar A. M., Feng Liu, Yi-Ping Phoebe Chen, and Xi Chen. 2020. "Ensemble Fuzzy Feature Selection Based on Relevancy, Redundancy, and Dependency Criteria" Entropy 22, no. 7: 757. https://doi.org/10.3390/e22070757
APA StyleSalem, O. A. M., Liu, F., Chen, Y. -P. P., & Chen, X. (2020). Ensemble Fuzzy Feature Selection Based on Relevancy, Redundancy, and Dependency Criteria. Entropy, 22(7), 757. https://doi.org/10.3390/e22070757