1. Introduction
In the era of precision medicine, constructing interpretable and accurate predictive models, based on patients’ demographic characteristics, clinical conditions and molecular biomarkers, has been crucial for disease prevention, early diagnosis and targeted therapy [
1]. When the number of predictors is moderate, penalized regression approaches such as least absolute shrinkage and selection operator (LASSO) by [
2] have been used to construct predictive models and explain the impacts of the selected predictors. However, in ultrahigh dimensional settings where
p is in the exponential order of
n, penalized methods may incur computational challenges [
3], may not reach globally optimal solutions and often generate biased estimates [
4]. Sure independence screening (SIS) proposed by [
5] has emerged as a powerful tool for modeling ultrahigh dimensional data. However, the method relies on a partial faithfulness assumption, which stipulates that jointly important variables must be marginally important, an assumption that may not be always realistic. To relieve this condition, some iterative procedures, such as ISIS [
5], have been adopted to repeatedly screen variables based on the residuals from the previous iterations, but with heavy computation and unclear theoretical properties. Conditional screening approaches [see, e.g., [
6]] have, to some extent, addressed the challenge. However, screening methods do not directly generate a final model, and post-screening regularization methods, such as LASSO, are recommended by [
5] to produce a final model.
For generating a final predictive model in ultrahigh dimensional settings, recent years have seen a surging interest of performing forward regression, an old technique for model selection; see [
7,
8,
9], among many others. Under some regularity conditions and with some proper stopping criteria, forward regression can achieve screening consistency and sequentially select variables according to metrics such as AIC, BIC or
. Closely related to forward selection also, is least angle regression (LARS) [
10], a widely used model selection algorithm for high-dimensional models. In the generalized linear model setting [
11,
12], proposed differential geometrical LARS (dgLARS) based on a differential geometrical extension of LARS.
However, these methods have drawbacks. First, once a variable is identified by the forward selection, it is not removable from the list of selected variables. Hence, false positives are unavoidable without a systematic elimination procedure. Second, most of the existing works focus on variable selection and are silent with respect to estimation accuracy.
To address the first issue, some works have been proposed to add backward elimination steps once forward selection is accomplished, as backward elimination may further eliminate false positives from the variables selected by forward selection. For example, ref. [
13,
14] proposed a stepwise selection for linear regression models in high-dimensional settings and proved model selection consistency. However, it is unclear whether the results hold for high-dimensional generalized linear models (GLMs); Ref. [
15] proposed a similar stepwise algorithm in high-dimensional GLM settings, but with no theoretical properties on model selection. Moreover, none of the relevant works have touched upon the accuracy of estimation.
We extend a stepwise regression method to accommodate GLMs with high-dimensional predictors. Our method embraces both model selection and estimation. It starts with an empty model or pre-specified predictors, scans all features and sequentially selects features, and conducts backward elimination once forward selection is completed. Our proposal controls both false negatives and false positives in high dimensional settings: the forward selection steps recruit variables in an inclusive way by allowing some false positives for the sake of avoiding false negatives, while the backward selection steps eliminate the potential false positives from the recruited variables. We use different stopping criteria in the forward and backward selection steps, to control the numbers of false positives and false negatives. Moreover, we prove that, under a sparsity assumption of the true model, the proposed approach can discover all of the relevant predictors within a finite number of steps, and the estimated coefficients are consistent, a property still unknown to the literature. Finally, our GLM framework enables our work to accommodate a wide range of data types, such as binary, categorical and count data.
To recap, our proposed method distinguishes from the existing stepwise approaches in high dimensional settings. For example, it improves [
13,
14] by extending the work to a more broad GLM setting and [
15] by establishing the theoretical properties.
Compared with the other variable selection and screening works, our method produces a final model in ultrahigh dimensional settings, without applying a pre-screening step which may produce unintended false negatives. Under some regularity conditions, the method identifies or includes the true model with probability going to 1. Moreover, unlike the penalized approaches such as LASSO, the coefficients estimated by our stepwise selection procedure in the final model will be consistent, which are useful for gauging the real effect sizes of risk factors.
2. Method
Let
denote
n independently and identically distributed (i.i.d.) copies of
. Here,
is a
-dimensional predictor vector with
corresponding to the intercept term, and
Y is an outcome. Suppose that the conditional density of
Y, given
, belongs to a linear exponential family:
where
is the vector of coefficients;
is the intercept; and
and
are known functions. Model (
1), with a canonical link function and a unit dispersion parameter, belongs to a larger exponential family [
16]. Further,
is assumed twice continuously differentiable with a non-negative second derivative
. We use
and
to denote
and
, i.e., the mean and variance functions, respectively. For example,
in a logistic distribution and
in a Poisson distribution.
Let
and
denote the mean of
for a sequence of i.i.d. random variables
and a non-random function
. Based on the i.i.d. observations, the log-likelihood function is
We use
to denote the true values of
. Then the true model is
, which consists of the intercept and all variables with nonzero effects. Overarching goals of ultra-high dimensional data analysis are to identify
and estimate
for
. While most of the relevant literature [
8,
9] is on estimating
, this work is to accomplish both identification of
and estimation of
.
When
p is in the exponential order of
n, we aim to generate a predictive model that contains the true model with high probability, and provide consistent estimates of regression coefficients. We further introduce the following notation. For a generic index set
and a
-dimensional vector
, we use
to denote the complement of a set
S and
to denote the subvector of
corresponding to
S. For instance, if
, then
. Moreover, denote by
the log-likelihood of the regression model of
Y on
and denote by
the maximizer of
. Under model (
1), we elaborate on the idea of stepwise (details in the
supplementary materials) selection, consisting of the forward and backward stages.
Forward stage: We start with
, a set of variables that need to be included according to some
a priori knowledge, such as clinically important factors and conditions. If no such information is available,
is set to be
, corresponding to a null model. We sequentially add covariates as follows:
where
is the index set of the selected covariates upon completion of the
kth step, with
. At the
th step, we append new variables to
one at a time and refit GLMs: for every
, we let
, obtain
by maximizing
, and compute the increment of log-likelihood,
Then the index of a new candidate variable is determined to be
Additionally, we update
We then need to decide whether to stop at the
kth step or move on to the
th step with
. To do so, we use the following EBIC criterion:
where the second term is motivated by [
17] and
denotes the cardinality of a set
F.
The forward selection stops if . We denote the stopping step by and the set of variables selected so far by .
Backward stage: Upon the completion of forward stage, backward elimination, starting with
, sequentially drops covariates as follows:
where
is the index set of the remaining covariates upon the completion of the
kth step of the backward stage, with
. At the
th backward step and for every
, we let
, obtain
by maximizing
, and calculating the difference of the log-likelihoods between these two nested models:
The variable that can be removed from the current set of variables is indexed by
Let
We determine whether to stop at the
kth step or move on to the (
)th step of the backward stage according to the following BIC criterion:
If , we end the backward stage at the kth step. Let denote the stopping step and we declare the selected model to be the final model. Thus, is the estimate of . As the backward stage starts with the variables selected by forward selection, cannot exceed .
A strength of our algorithm, termed STEPWISE hereafter, is the added flexibility with and in the stopping criteria for controlling the false negatives and positives. For example, a smaller value of close to zero in the forward selection step will likely include more variables, and thus incur more false positives and less false negatives, whereas a larger value of will recruit too few variables and cause too many false negatives. Similarly, in the backward selection step, a large would eliminate more variables and therefore further reduce more false positives, and vice versa for a small . While finding optimal and is not trivial, our numerical experiences suggest a small and a large may well balance the false negatives and positives. When , no variables can be dropped after forward selection; hence, our proposal includes forward selection as a special case.
Moreover, [
8] proposed a sequentially conditioning approach based on offset terms that absorb the prior information. However, our numerical experiments indicate that the offset approach may be suboptimal compared to our full stepwise optimization approach, which will be demonstrated in the simulation studies.
3. Theoretical Properties
With a column vector , let denote the -norm for any . For simplicity, we denote the -norm of by , and denote by . We use to denote some generic constants that do not depend on n and may change from line to line. The following regularity conditions are set.
There exist a positive integer q satisfying and and a constant such that , where is termed the least false value of model S.
. In addition, and for .
Let . There exists a positive constant M such that the Cramer condition holds, i.e., for all .
and is bounded below.
There exist two positive constants, and such that , uniformly in satisfying , where is the collection of all eigenvalues of a square matrix .
for some constants and that satisfies , where .
Condition (1), as assumed in [
8,
18], is an alternative to the Lipschitz assumption [
5,
19]. The bound of the model size allowed in the selection procedure or
q is often required in model-based screening methods see, e.g., [
8,
20,
21,
22]. The bound should be large enough so that the correct model can be included, but not too large; otherwise, excessive noise variables would be included, leading to unstable and inconsistent estimates. Indeed, Conditions (1) and (6) reveal that the range of
q depends on the true model size
, the minimum signal strength,
and the total number of covariates,
p. The upper bound of
q is
, ensuring the consistency of EBIC [
17]. Condition (1) also implies that the parameter space under consideration can be restricted to
, for any model
S with
. Condition (2), as assumed in [
23,
24], reflects that data are often standardized at the pre-processing stage. Condition (3) ensures that
Y has a light tail, and is satisfied by Gaussian and discrete data, such as binary and count data [
25]. Condition (4) is satisfied by common GLM models, such as Gaussian, binomial, Poisson and gamma distributions. Condition (5) represents the sparse Riesz condition [
26] and Condition (6) is a strong "irrepresentable" condition, suggesting that
cannot be represented by a set of variables that does not include the true model. It further implies that adding a signal variable to a mis-specified model will increase the log-likelihood by a certain lower bound [
8]. The signal rate is comparable to the conditions required by the other sequential methods, see, e.g., [
7,
22].
Theorem 1 develops a lower bound of the increment of the log-likelihood if the true model is not yet included in a selected model S.
Theorem 1. Suppose Conditions (1)–(6) hold. There exists some constant such that with probability at least 1–6, Theorem 1 shows that, before the true model is included in the selected model, we can append a variable which will increase the log-likelihood by at least
with probability tending to 1. This ensures that in the forward stage, our proposed STEPWISE approach will keep searching for signal variables until the true model is contained. To see this, suppose at the
kth step of the forward stage that
satisfies
and
, and let
r be the index selected by STEPWISE. By Theorem 1, we obtain that, for any
, when
n is sufficiently large,
with probability at least
, where the last inequality is due to Condition (6). Therefore, with high probability the forward stage of STEPWISE continues as long as
. We next establish an upper bound of the number of steps in the forward stage needed to include the true model.
Theorem 2. Under the same conditions as in Theorem 1 and ifthen there exists some constant such that , for some in the forward stage of STEPWISE and , with probability at least . The "max" condition, as assumed in Section 5.3 of [
27], relaxes the partial orthogonality assumption that
are independent of
, and ensures that with probability tending to 1, appending a signal variable increases log-likelihood more than adding a noise variable does, uniformly over all possible models
S satisfying
. This entails that the proposed procedure is much more likely to select a signal variable, in lieu of a noise variable, at each step. Since EBIC is a consistent model selection criterion [
28,
29], the following theorem guarantees termination of the proposed procedure with
for some
k.
Theorem 3. Under the same conditions as in Theorem 2 and if and , the forward stage stops at the kth step with probability going to .
Theorem 3 ensures that the forward stage of STEPWISE will stop within a finite number of steps and will cover the true model with probability at least . We next consider the backward stage and provide a probability bound of removing a signal from a set in which the set of true signals is contained.
Theorem 4. Under the same conditions as in Theorem 2, uniformly over and S satisfying and , with probability at least .
Theorem 4 indicates that with probability at , BIC would decrease when removing a signal variable from a model that contains the true model. That is, with high probability, back elimination is to reduce false positives.
Recall that
denotes the model selected at the end of the forward selection stage. By Theorem 2,
with probability at least
. Then Theorem 4 implies that at each step of the backward stage, a signal variable will not be removed from the model with probability at least
. By Theorem 2,
. Thus, the backward elimination will carry out at most
steps. Combining results from Theorems 2 and 3 yields that
with probability at least
. Let
be the estimate of
in model (
1) at the termination of STEPWISE. By convention, the estimates of the coefficients of the unselected covariates are 0.
Theorem 5. Under the same conditions as in Theorem 2, we have that andin probability. The theorem warrants that the proposed STEPWISE yields consistent estimates, a property not shared by many regularized methods, including LASSO. Our later simulations verified this. Proof of main theorems and lemmas are provided in
Appendix A.
4. Simulation Studies
We compared the proposal with the other competing methods, including the penalized methods, such as least absolute shrinkage and selection operator (LASSO); the differential geometric least angle regression (dgLARS) [
11,
12]; the forward regression (FR) approach [
7]; the sequentially conditioning (SC) approach [
8]; and the screening methods, such as sure independence screening (SIS) [
5], which is popular in practice. As SIS does not directly generate a predictive model, we applied LASSO for the top
variables chosen by SIS and denoted the procedure by SIS+LASSO. As the FR, SC and STEPWISE approaches involve forward searching and to make them comparable, we applied the same stopping rule, for example, Equation (
3) with the same
, to their forward steps. In particular, the STEPWISE approach, with
and
, is equivalent to FR and asymptotically equivalent to SC. By varying
in FR and SC between
and
, we explored the impact of
on inducing false positives and negatives. In our numerical studies, we fixed
and set
. To choose
and
in (
3) and (
4) in STEPWISE, we performed 5-fold cross-validation to minimize the mean squared prediction error (MSPE), and reported the results in
Table 1. Since the proposed STEPWISE algorithm uses the (E)BIC criterion, for a fair comparison we chose the tuning parameter in dgLARS by using the BIC criterion as well, and coined the corresponding approach as dgLARS(BIC). The regularization parameter in LASSO was chosen via the following two approaches: (1) giving the smallest BIC for the models on the LASSO path, denoted by LASSO(BIC); (2) using the one-standard-error rule, denoted by LASSO(1SE), which chooses the most parsimonious model whose error is no more than one standard error above the error of the best model in cross-validation [
30].
Denote by and , the covariate vector for subject and the true coefficient vector. The following five examples generated , the inner product of the coefficient and covariate vectors for each individual, which were used to generate outcomes from the normal, binomial and Poisson models.
Example 1. For each i,where = (4/ + ), for and 0 otherwise was a binary random variable with and was generated by a standard normal distribution; ; s were independently generated from a standardized exponential distribution, that is, . Here and also in the other examples, c (specified later) controls the signal strengths. Example 2. This scenario is the same asExample 1except that was independently generated from a standard normal distribution.
Example 3. For each i,where = 2j for 1 and . We simulated every component of = () ∈ and = () ∈ independently from a standard normal distribution. Next, we generated according to = for 1 and for . Example 4. For each i,where the first 500 s were generated from the multivariate normal distribution with mean and a covariance matrix with all of the diagonal entries being 1 and = for . The remaining s were generated through the autoregressive processes with ∼ Unif(-2, 2), = 0.5 + 0.5, for , where ∼ Unif(-2, 2) were generated independently. The coefficients for were generated from (4/ + ), where was a binary random variable with and was from a standard normal distribution. The remaining were zeros. Example 5. For each i,where were generated from a multivariate normal distribution with mean and a covariance matrix with all of the diagonal entries being 1 and = for 1 ≤ j, j’ ≤ p. All of the coefficients were zero except for , and . Examples 1 and 3 were adopted from [
7], while
Examples 2 and 4 were borrowed from [
5,
15], respectively. We then generated the responses from the following three models.
Normal model: with .
Binomial model: Bernoulli( .
Poisson model: Poisson( ).
We considered
n = 400 and
p = 1000 throughout all of the examples. We specified the magnitude of the coefficients in the GLMs with a constant multiplier,
c. For Examples 1–5, this constant was set, respectively for the normal, binomial and Poisson models, to be: (1, 1, 0.3), (1, 1.5, 0.3), (1, 1, 0.1), (1, 1.5, 0.3) and (1, 3, 2). For each parameter configuration, we simulated 500 independent data sets. We evaluated the performances of the methods by the criteria of true positives (TP), false positives (FP), the estimated probability of including the true models (PIT), the mean squared error (MSE) of
and the mean squared prediction error (MSPE). To compute the MSPE, we randomly partitioned the samples into the training (75%) and testing (25%) sets. The models obtained from the training datasets were used to predict the responses in the testing datasets.
Table 2,
Table 3 and
Table 4 report the average TP, FP, PIT, MSE and MSPE over 500 datasets along with the standard deviations. The findings are summarized below.
First, the proposed STEPWISE method was able to detect all the true signals with nearly zero FPs. Specifically, in all of the Examples, STEPWISE outperformed the other methods by detecting more TPs with fewer FPs, whereas LASSO, SIS+LASSO and dgLARS included much more FPs.
Second, though a smaller in FR and SC led to the inclusion of all TPs with a PIT close to 1, it incurred more FPs. On the other hand, a larger may eliminate some TPs, resulting in a smaller PIT and a larger MSPE.
Third, for the normal model, the STEPWISE method yielded an MSE close to 0, the smallest among all the competing methods. The binary and Poisson data challenged all of the methods, and the MSEs for all the methods were non-negligible. However, the STEPWISE method still produced the lowest MSE. The results seemed to verify the consistency of , which distinguished the proposed STEPWISE method from the other regularized methods and highlighted its ability to provide a more accurate means to characterize the effects of high dimensional predictors.
5. Real Data Analysis
5.1. A Study of Gene Regulation in the Mammalian Eye
To demonstrate the utility of our proposed method, we analyzed a microarray dataset from [
35] with 120 twelve-week male rats selected for eye tissue harvesting. The dataset contained more than 31,042 different probe sets (Affymetric GeneChip Rat Genome 230 2.0 Array); see [
35] for a more detailed description of the data.
Although our method was applicable to the original 31,042 probe sets, many probes turned out to have very small variances and were unlikely to be informative for correlative analyses. Therefore, using variance as the screening criterion, we selected 5000 genes with the largest variances in expressions and correlated them with gene
TRIM32 that has been found to cause Bardet–Biedl syndrome, a genetically heterogeneous disease of multiple organ systems including the retina [
36].
We applied the proposed STEPWISE method to the dataset with and , and treated the TRIM32 gene expression as the response variable and the expressions of 5000 genes as the predictors. With no prior biological information available, we started with the empty set. To choose and , we carried out 5-fold cross-validation to minimize the mean squared prediction error (MSPE) by using the following grid search: and , and set and . We also performed the same procedure to choose the for FR and SC. The regularization parameters in LASSO and dgLARS were selected to minimize BIC values.
In the forward step, STEPWISE selected the probes of 1376747_at, 1381902_at, 1382673_at and 1375577_at, and the backward step eliminated probe 1375577_at. The STEPWISE procedure produced the following final predictive model:
TRIM32 = 4.6208 + 0.2310 × (
1376747_at) + 0.1914 × (
1381902_at) + 0.1263 × (
1382673_at).
Table A1 in
Appendix B presents the numbers of overlapping genes among competing methods. It shows that the two out of three probes,
1381902_at and
1376747_at, selected from our method are also discovered by the other methods, except for dgLARS.
Next, we performed Leave-One-Out Cross-Validation (LOOCV) to obtain the distribution of the model size (MS) and MSPE for the competing methods.
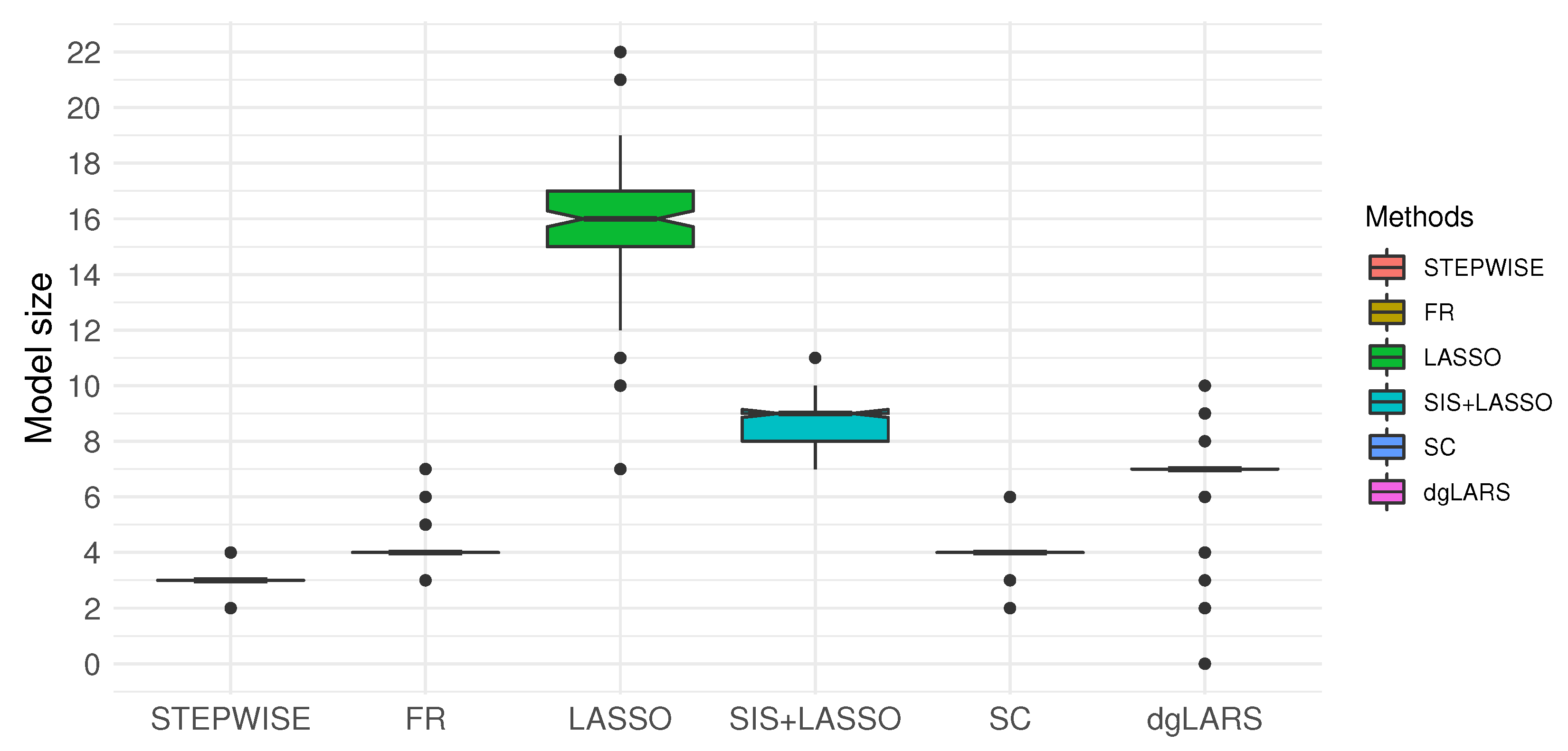
As reported in
Table 5 and
Figure 1, LASSO, SIS+LASSO and dgLARS tended to select more variables than the forward approaches and STEPWISE. Among all of the methods, STEPWISE selected the fewest variables but with almost the same MSPE as the other methods.
5.2. An Esophageal Squamous Cell Carcinoma Study
Esophageal squamous cell carcinoma (ESCC), the most common histological type of esophageal cancer, is known to be associated with poor overall survival, making early diagnosis crucial for treatment and disease management [
37]. Several studies have investigated the roles of circulating microRNAs (miRNAs) in diagnosis of ESCC [
38].
Using a clinical study that investigated the roles of miRNAs on the ESCC [
39], we aimed to use miRNAs to predict ESCC risks and estimate their impacts on the development of ESCC. Specifically, with a dataset of serum profiling of 2565 miRNAs from 566 ESCC patients and 4965 controls without cancer, we demonstrated the utility of the proposed STEPWISE method in predicting ESCC with miRNAs.
To proceed, we used a balance sampling scheme (283 cases and 283 controls) in the training dataset. The design of yielding an equal number of cases and controls in the training set has proved to be useful [
39] for handling imbalanced outcomes as we encountered here. To validate our findings, samples were randomly divided into a training (
,
) and testing set (
,
).
The training set consisted of 283 patients with ESCC (median age of 65 years, 79% male) and 283 control patients (median age of 68 years, 46.3% male), and the testing set consisted of 283 patients with ESCC (median age of 67 years, 85.7% male) and 4682 control patients (median age of 67.5 years, 44.5% male). Control patients without ESCC came from three sources: 323 individuals from National Cancer Center Biobank (NCCB); 2670 individuals from the Biobank of the National Center for Geriatrics and Gerontology (NCGG); and 1972 individuals from Minoru Clinic (MC). More detailed characteristics of cases and controls in the training and testing sets are given in
Table 6.
We defined the binary outcome variable to be 1 if the subject was a case and 0 otherwise. As age and gender (0 = female, 1 = male) are important risk factors for ESCC [
40,
41] and it is common to adjust for them in clinical models, we set the initial set in STEPWISE to be
{age, gender}. With
and
that were also chosen from 5-fold CV, our procedure recruited three miRNAs. More specifically,
miR-4783-3p,
miR-320b,
miR-1225-3p and
miR-6789-5p were selected among 2565 miRNAs by the forward stage from the training set, and then the backward stage eliminated
miR-6789-5p.
In comparison, with
, both FR and SC selected four miRNAs,
miR-4783-3p,
miR-320b,
miR-1225-3p and
miR-6789-5p. The list of selected miRNAs by different methods are given in
Table A2 in
Appendix B.
Our findings were biologically meaningful, as the selected miRNAs had been identified by other cancer studies as well. Specifically,
miR-320b was found to promote colorectal cancer proliferation and invasion by competing with its homologous
miR-320a [
42]. In addition, serum levels of
miR-320 family members were associated with clinical parameters and diagnosis in prostate cancer patients [
43]. Reference [
44] showed that
miR-4783-3p was one of the miRNAs that could increase the risk of colorectal cancer death among rectal cancer cases. Finally,
miR-1225-5p inhibited proliferation and metastasis of gastric carcinoma through repressing insulin receptor substrate-1 and activation of
-catenin signaling [
45].
Aiming to identify a final model without resorting to a pre-screening procedure that may miss out on important biomarkers, we applied STEPWISE to reach the following predictive model for ESCC based on patients’ demographics and miRNAs:
, where .
In the testing dataset, the model had an area under the receiver operating curve (AUC) of 0.99 and achieved a high accuracy of 0.96, with a sensitivity and specificity of 0.97 and 0.95, respectively. Additionally, using the testing cohort, we evaluated the performances of the models sequentially selected by STEPWISE. Starting with a model containing age and gender, STEPWISE selected
miR-4783-3p,
miR-320b and
miR-1225-3p in turn.
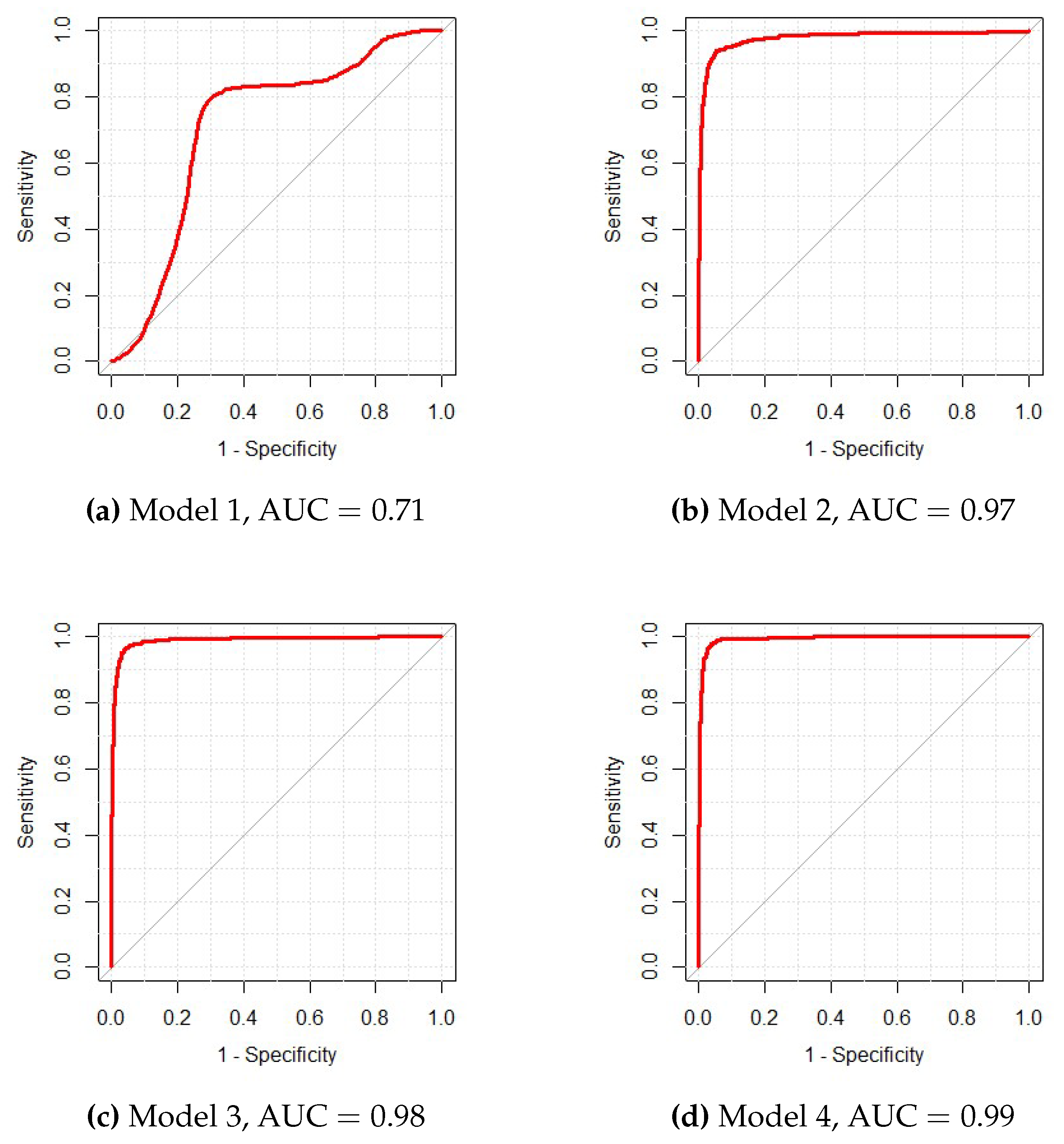
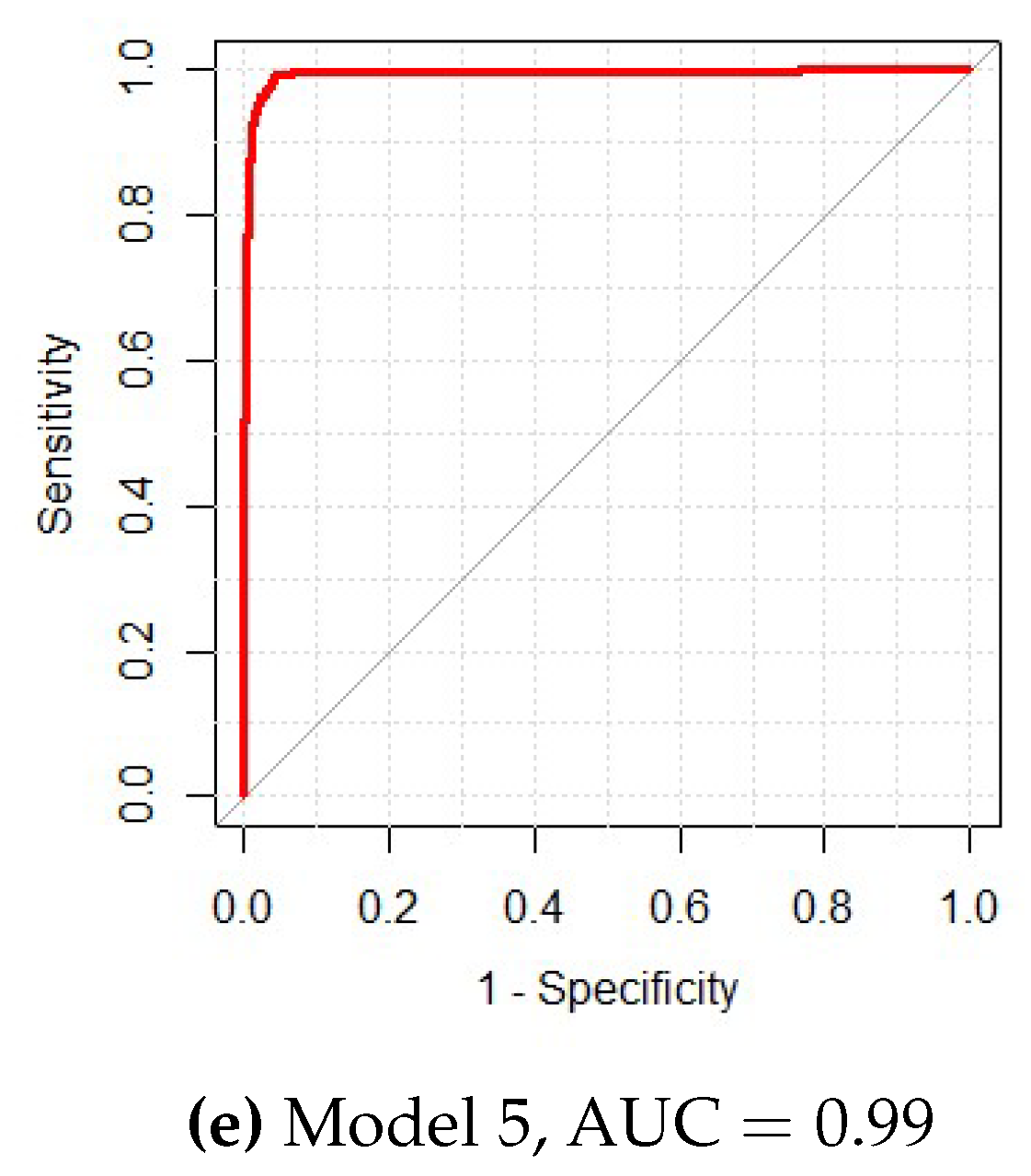
Figure 2, showing the corresponding receiver operating curves (ROC) for these sequential models, revealed the improvement by sequentially adding predictors to the model and justified the importance of these variables in the final model. In addition,
Figure 2e illustrated that adding an extra miRNA selected by FR and SC made little improvement of the model’s predictive power.
Furthermore, we conducted subgroup analysis within the testing cohort to study how the sensitivity of the final model differed by cancer stage, one of the most important risk factors. The sensitivities for stages 0, i.e., non-invasive cancer, 9 (), 1 (), 2 (), 3 () and 4 () were 1.00, 0.98, 0.97, 0.97 and 1.00, respectively. We next evaluated how the specificity varied across controls coming from different data sources. The specificities for the various control groups, namely, NCCB (), NCGG () and MC (), were 0.99, 0.99 and 0.98, respectively. The results indicated the robust performance of the miRNA-based model toward cancer stages and data sources.
Finally, to compare STEPWISE with the other competing methods, we repeatedly applied the aforementioned balance sampling procedure and split the ESCC data into the training and testing sets 100 times. We obtained MSPE and the average of accuracy, sensitivity, specificity, and AUC.
Figure 3 reported the model size of each method. Though STEPWISE selected fewer variables compared to the other variable selection methods (for example, LASSO selected 11-31 variables and dgLARS selected 12–51 variables), it achieved comparable prediction accuracy, specificity, sensitivity and AUC (see
Table 7), evidencing the utility of STEPWISE for generating parsimonious models while maintaining competitive predictability.
We used
R software [
46] to obtain the numerical results in
Section 4 and
Section 5 with following packages:
ggplot2 [
47],
ncvreg [
32],
glmnet [
31],
dglars [
34] and
screening [
33].
6. Discussion
We have proposed to apply STEPWISE to produce final models in ultrahigh dimensional settings, without resorting to a pre-screening step. We have shown that the method identifies or includes the true model with probability going to 1, and produces consistent coefficient estimates, which are useful for properly interpreting the actual impacts of risk factors. The theoretical properties of STEPWISE were established under mild conditions, which are worth discussing. As in practice covariates are often standardized for various reasons, Condition (2) is assumed without loss of generality. Conditions (3) and (4) are generally satisfied under common GLM models, including Gaussian, binomial, Poisson and gamma distributions. Condition (5) is also often satisfied in practice. Proposition 2 in [
26] may be used as a tool to verify Condition (5) as well. Conditions (1) and (6) are in good faith with the unknown true model size
and minimum signal strength
in practice. The "irrepresentable" condition (6) is strong and may not hold in some real datasets, see, e.g., [
48,
49]. However, the condition holds under some commonly used covariance structures, including AR(1) and compound symmetry structure [
48].
As shown in simulation studies and real data analyses, STEPWISE tends to generate models as predictive as the other well-known methods, with fewer variables (
Figure 3). Parsimonious models are useful for biomedical studies as they explain data with a small number of important predictors, and offer practitioners a realistic list of biomarkers to investigate. With categorical outcome data frequently observed in biomedical studies (e.g., histology types of cancer), STEPWISE can be extended to accommodate multinomial classification, with more involved notation and computation. We will pursue this elsewhere.
There are several open questions. First, our final model was determined by using (E)BIC, which involves two extra parameters and . In our numerical experiments, we used cross-validation to choose them, which seemed to work well. However, more in-depth research is needed to find their optimal values to strike a balance between false positives and false negatives. Second, despite our consistent estimates, drawing inferences based on them remains challenging. Statistical inference, which accounts for uncertainty in estimation, is key for properly interpreting analysis results and drawing appropriate conclusions. Our asymptotic results, nevertheless, are a stepping stone toward this important problem.





{kind=link}
{kind=link}
{kind=link}
{kind=link}



