
Speech Watermarking Method Using McAdams Coefficient Based on Random Forest Learning


Abstract
:1. Introduction
2. Speech Processing Using McAdams Coefficient
3. Proposed Method
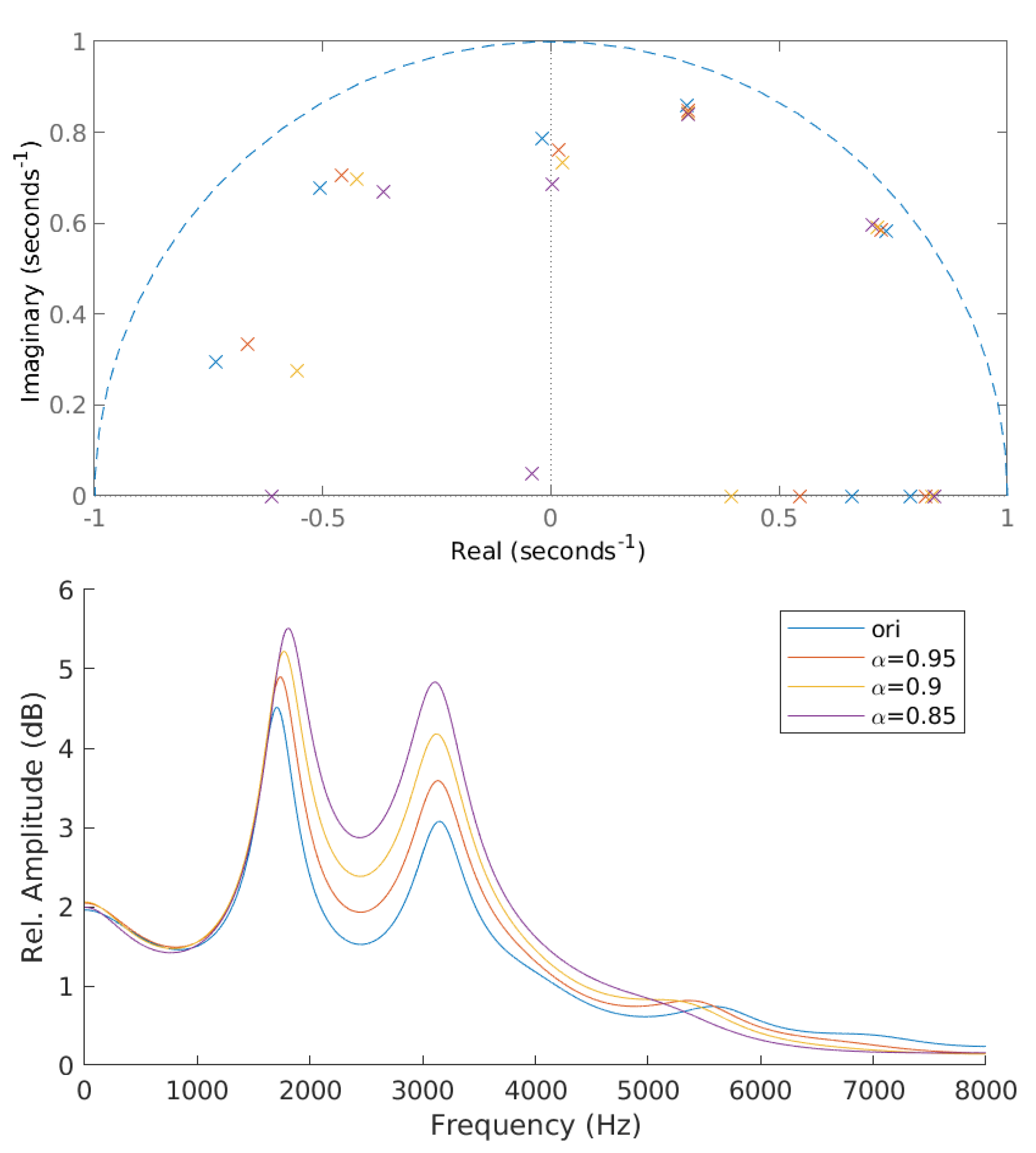
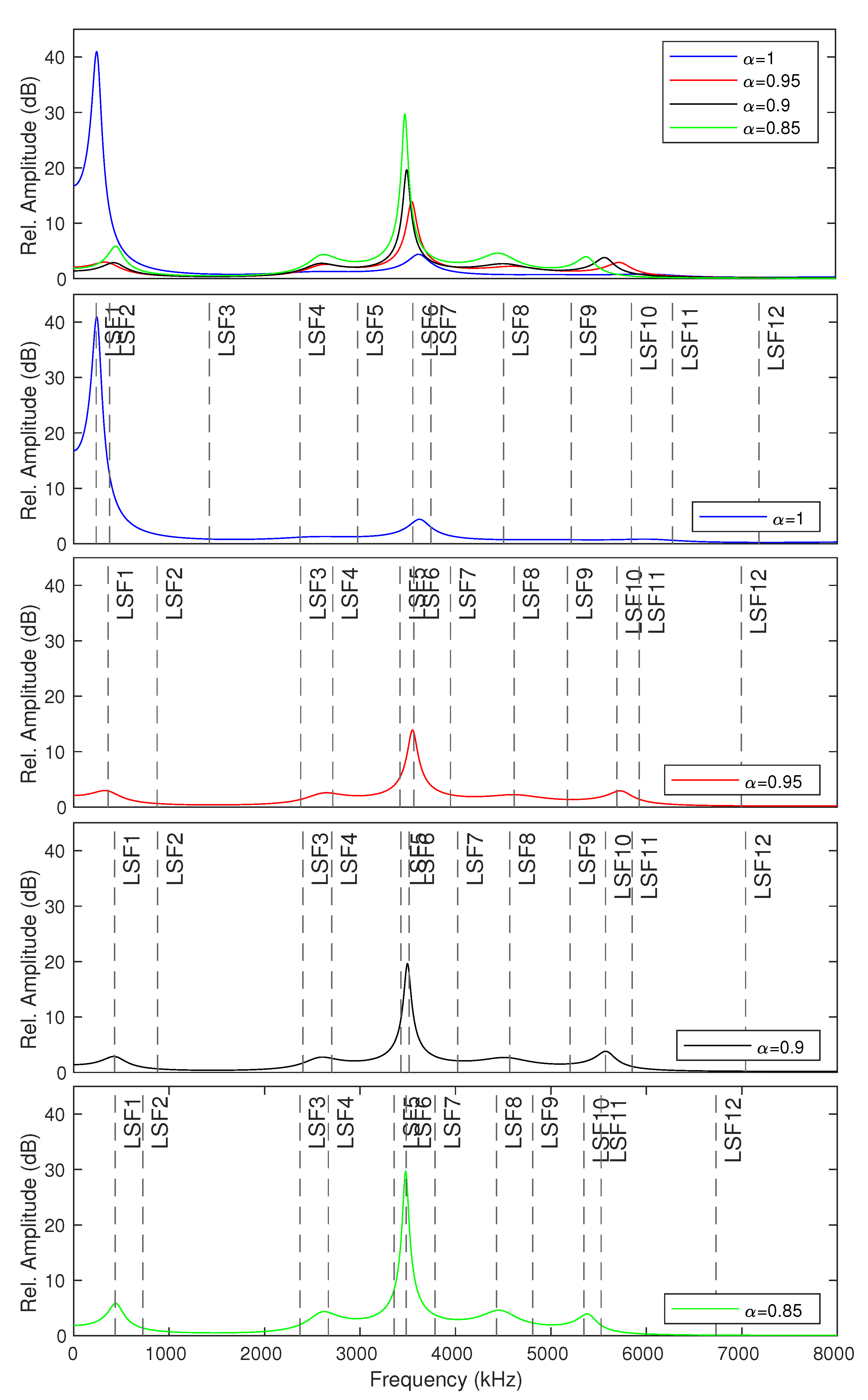
3.1. McAdams Coefficient Manipulation
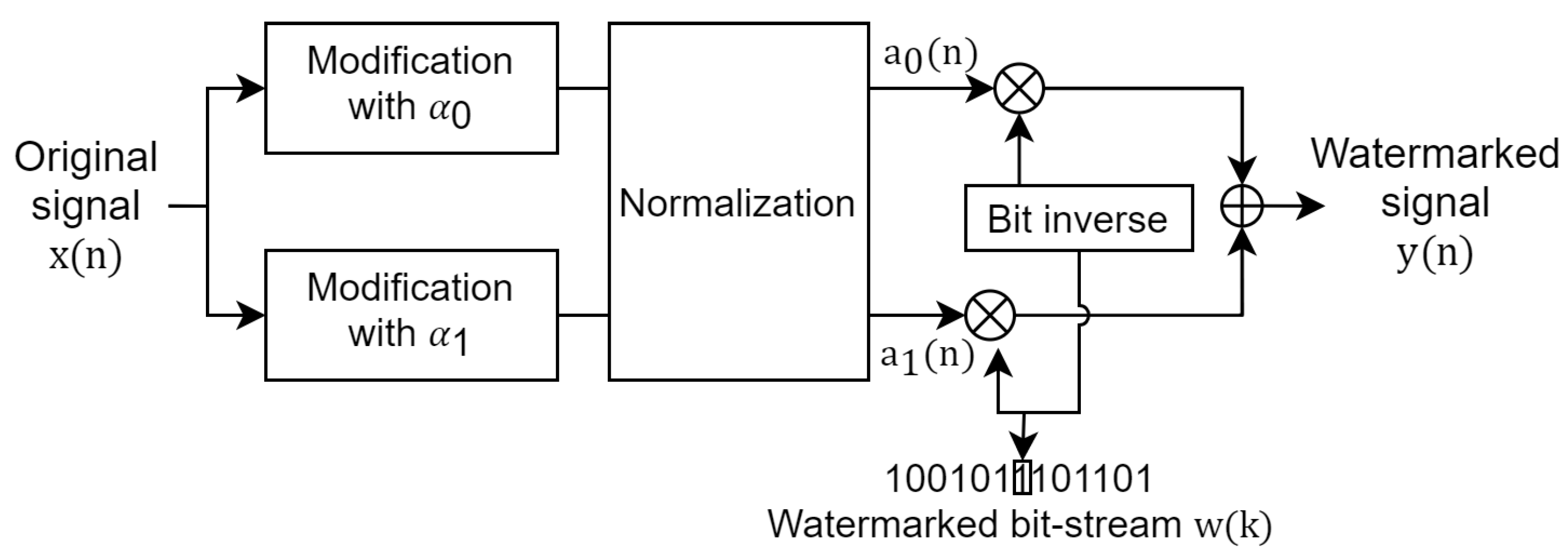
3.2. Data-Embedding Process
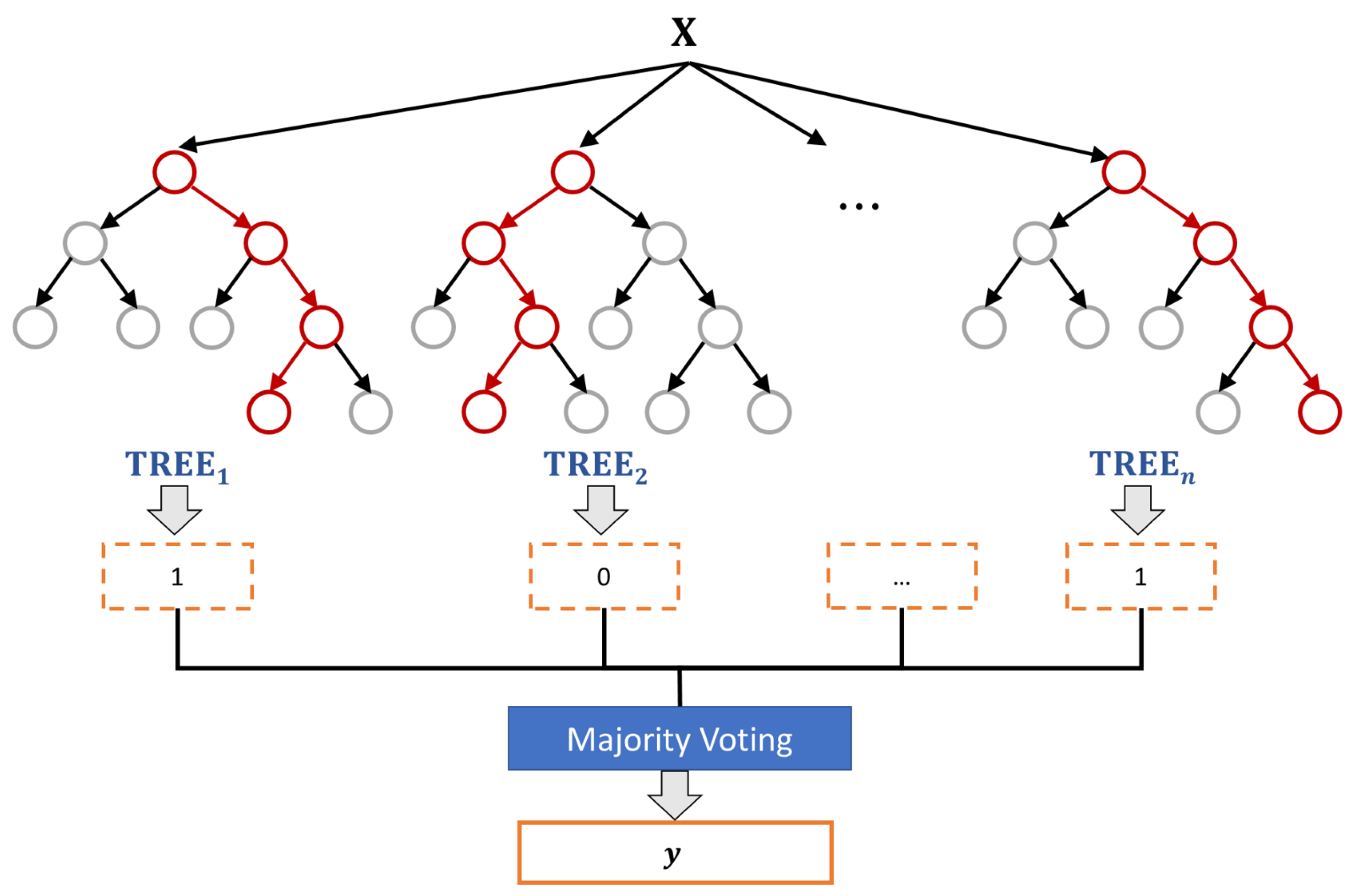
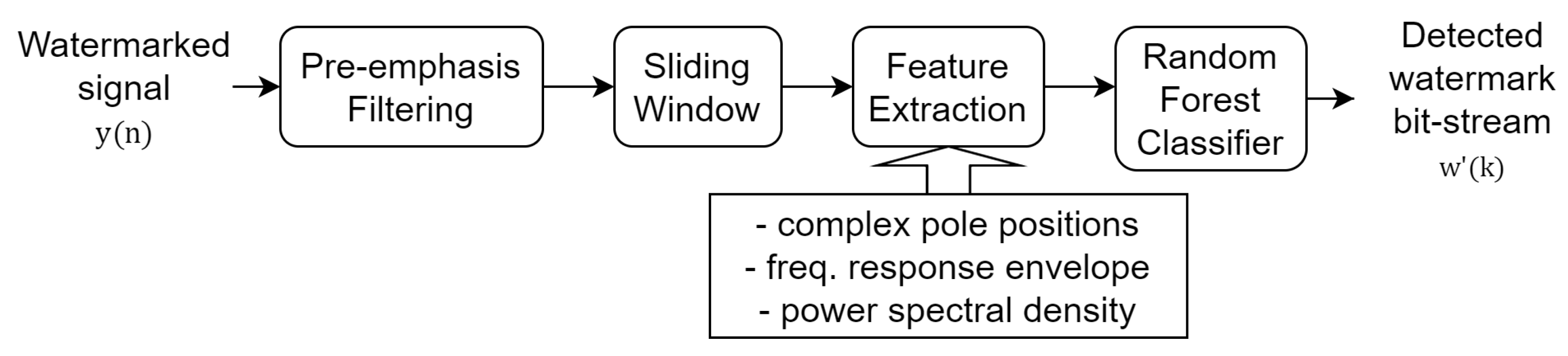
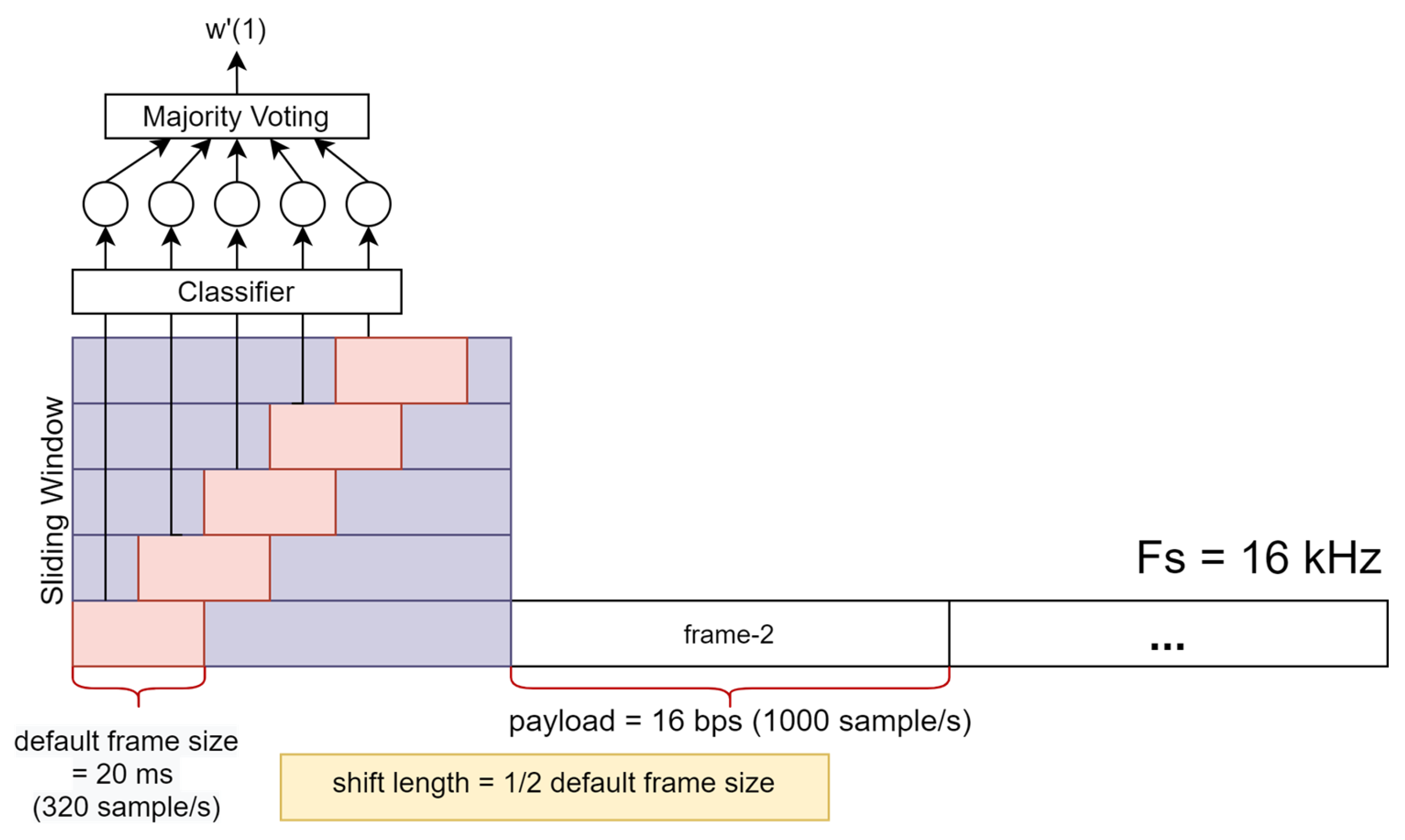
3.3. Data-Detection Process
4. Experimental Setup
4.1. Dataset
4.2. Evaluation Setting
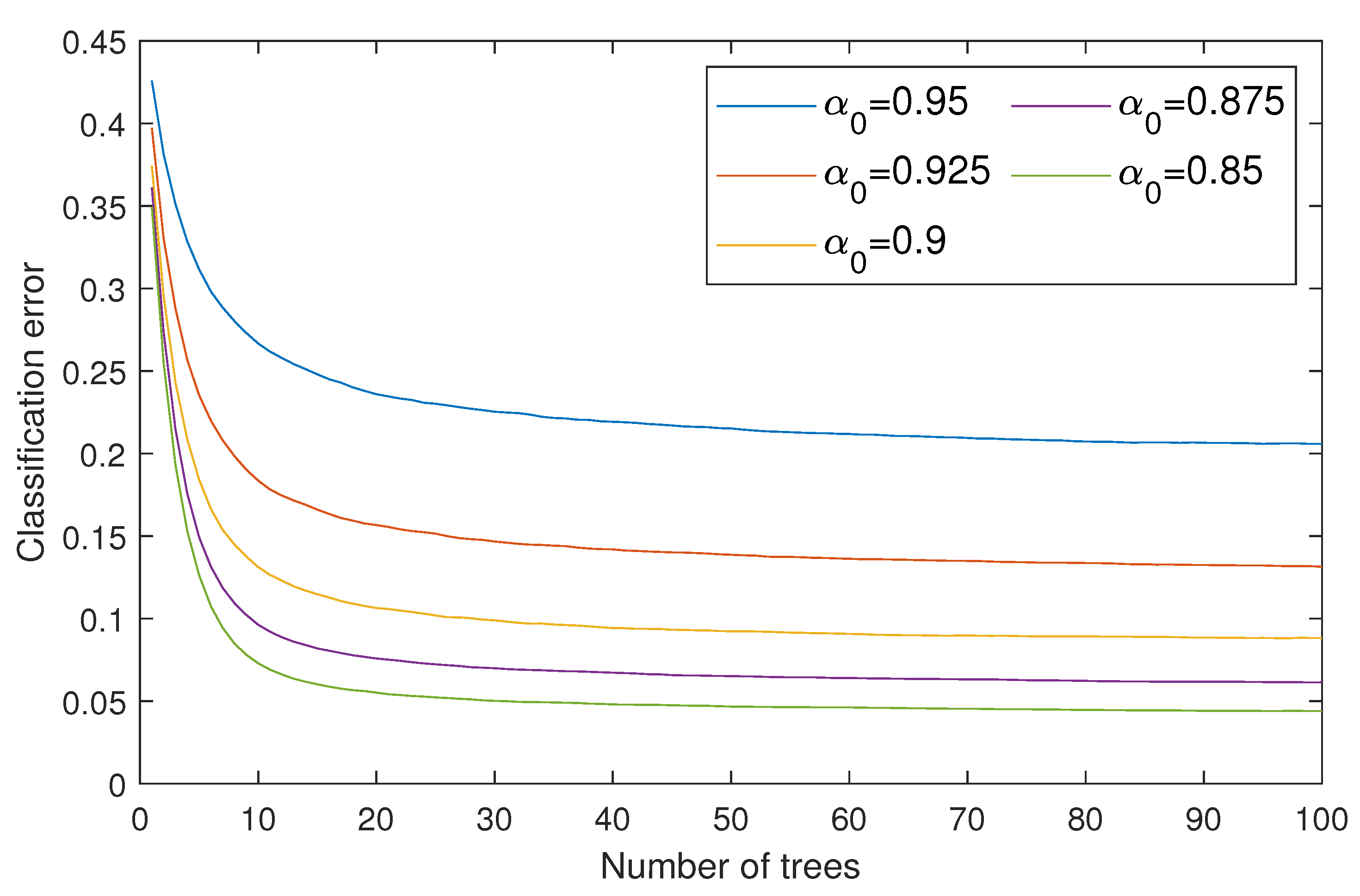
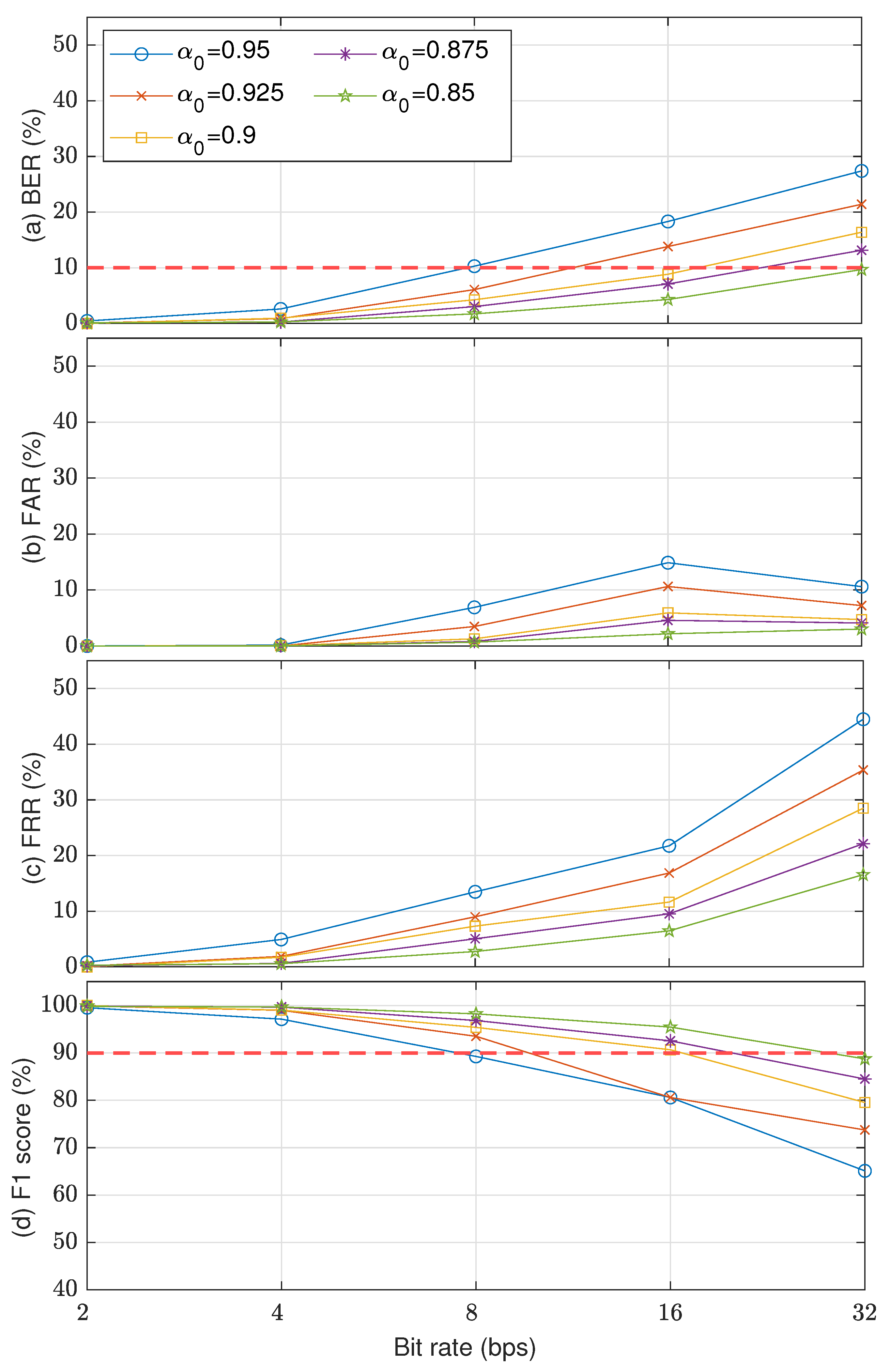
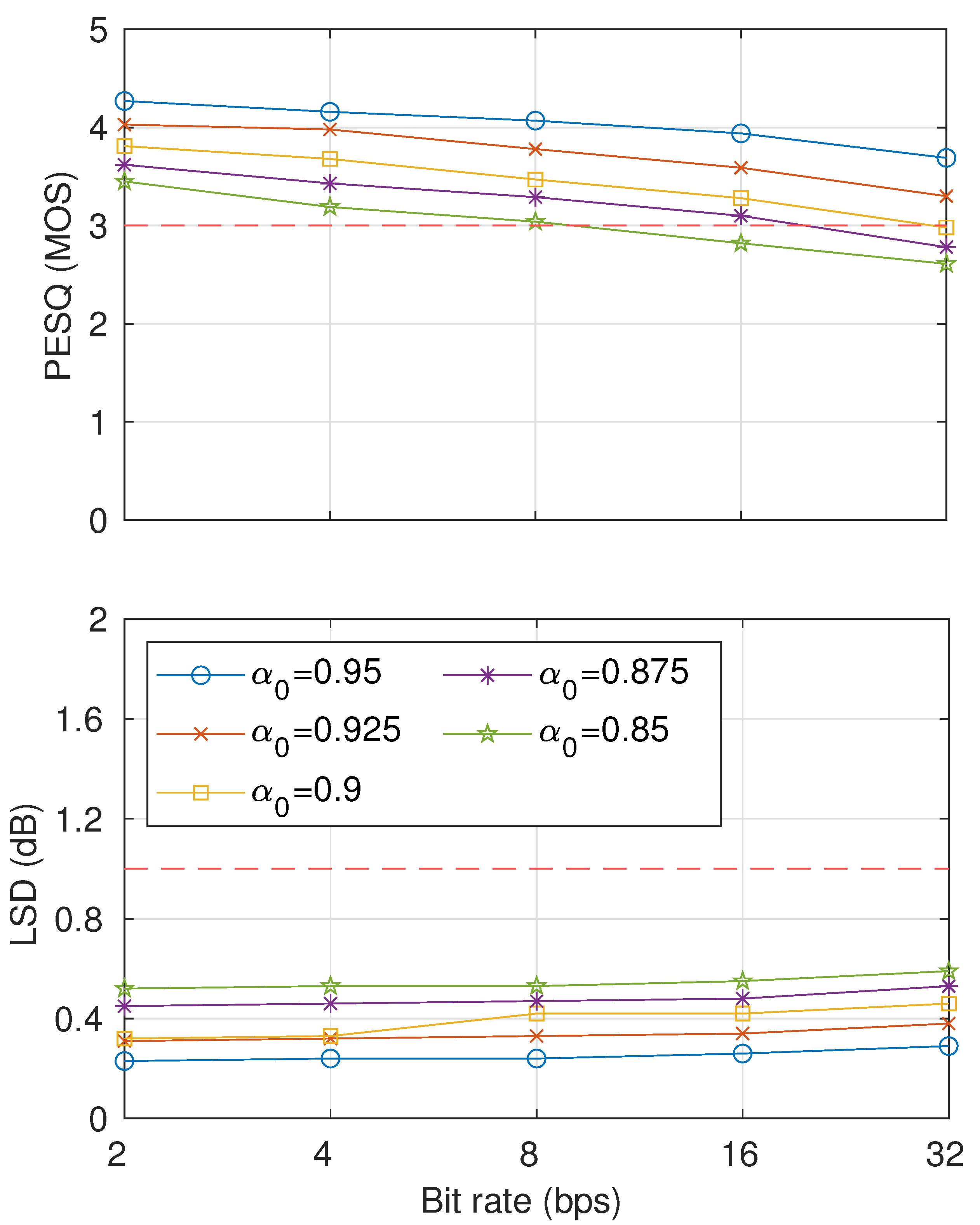
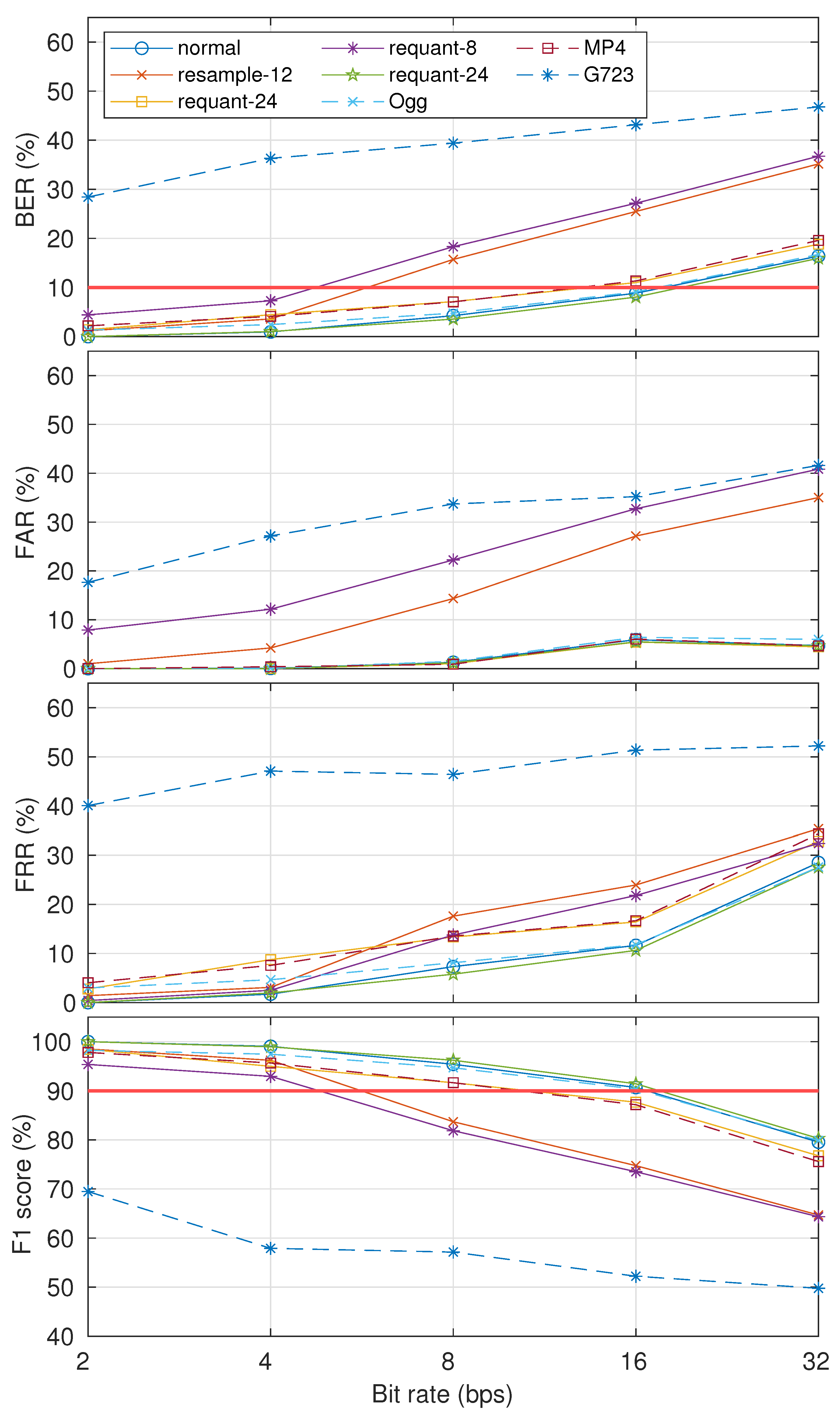
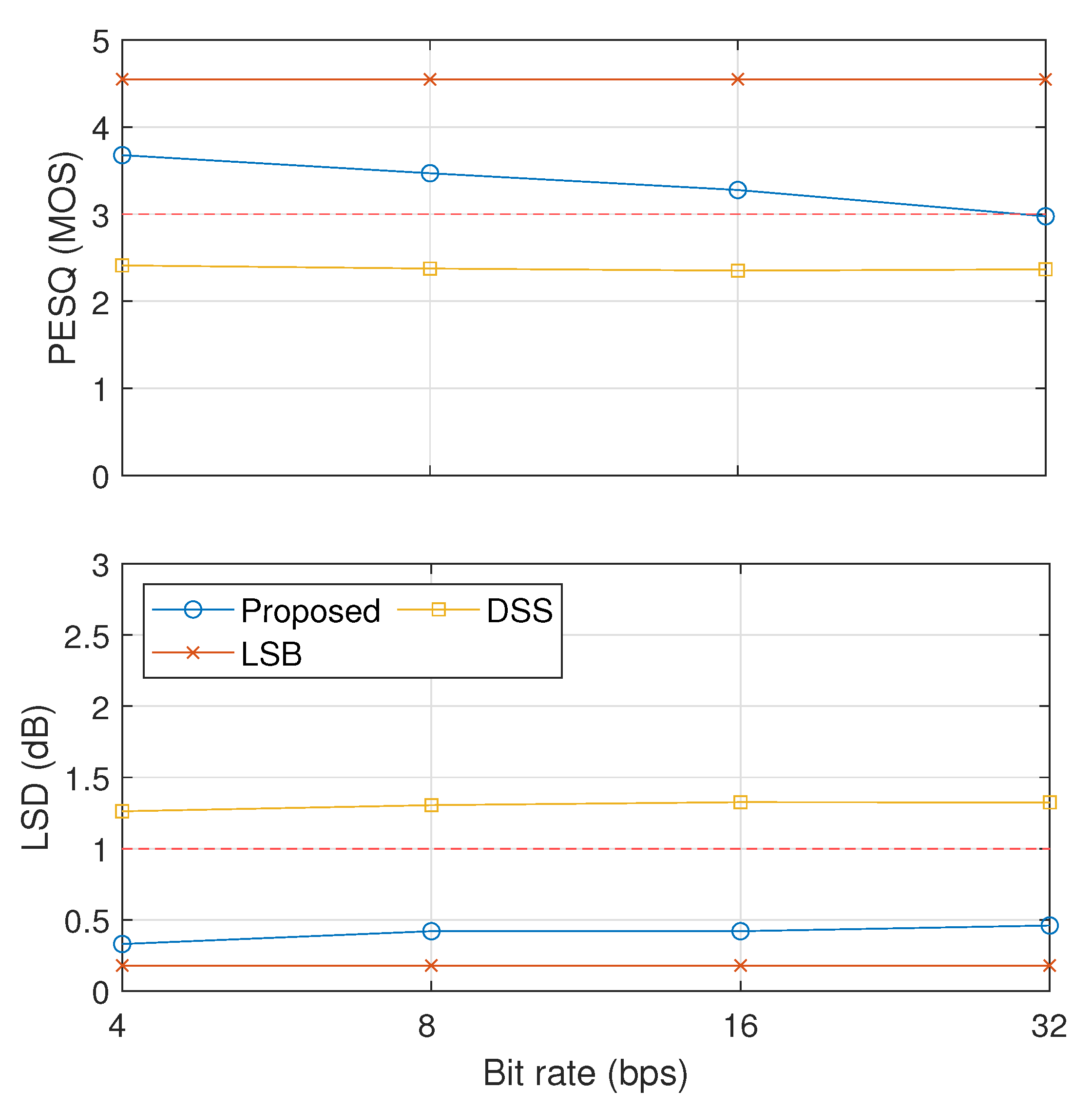
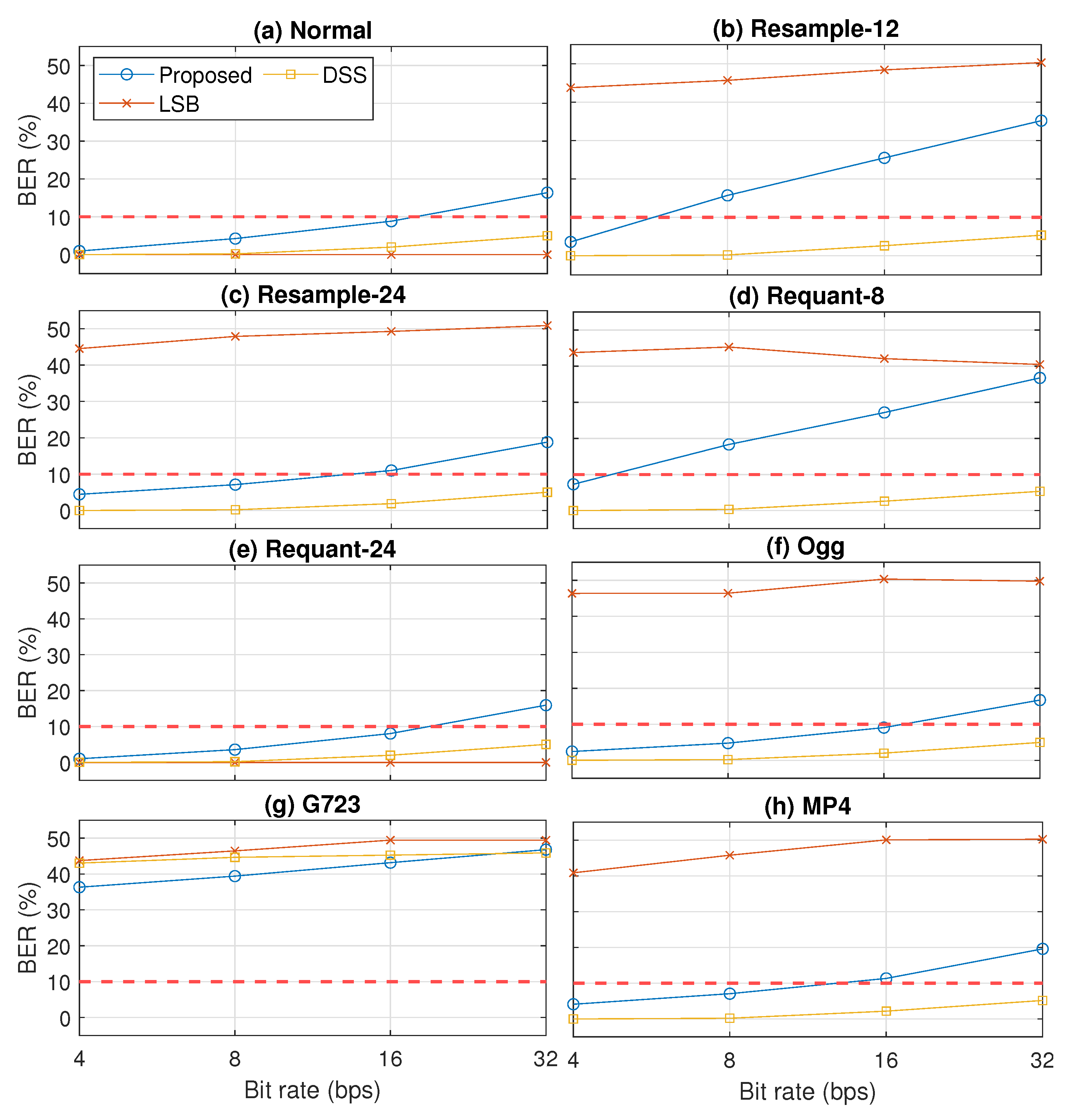
5. Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Todisco, M.; Wang, X.; Vestman, V.; Sahidullah, M.; Delgado, H.; Nautsch, A.; Yamagishi, J.; Evans, N.W.D.; Kinnunen, T.H.; Lee, K.A. ASVspoof 2019: Future Horizons in Spoofed and Fake Audio Detection. In Proceedings of the 20th Annual Conference of the International Speech Communication Association (INTERSPEECH 2019), Graz, Austria, 15–19 September 2019; pp. 1008–1012. [Google Scholar] [CrossRef] [Green Version]
- Wu, Z. Information Hiding in Speech Signals for Secure Communication, 1st ed.; Syngress Publishing: Rockland, MA, USA, 2014. [Google Scholar]
- Tomashenko, N.; Srivastava, B.M.L.; Wang, X.; Vincent, E.; Nautsch, A.; Yamagishi, J.; Evans, N.; Patino, J.; Bonastre, J.F.; Noé, P.G.; et al. The VoicePrivacy 2020 Challenge Evaluation Plan. 2020. Available online: https://www.voiceprivacychallenge.org/docs/VoicePrivacy_2020_Eval_Plan_v1_3.pdf (accessed on 10 June 2021).
- Hua, G.; Huang, J.; Shi, Y.Q.; Goh, J.; Thing, V.L.L. Twenty years of digital audio watermarking—A comprehensive review. Signal Process. 2016, 128, 222–242. [Google Scholar] [CrossRef]
- Lin, Y.; Abdulla, W. Audio Watermark: A Comprehensive Foundation Using MATLAB; Springer International Publishing: Cham, Switzerland, 2015. [Google Scholar]
- Unoki, M.; Hamada, D. Method of digital-audio watermarking based on cochlear delay characteristics. Int. J. Innov. Comput. Inf. Control. 2010, 6, 29. [Google Scholar]
- Djebbar, F.; Ayad, B. Comparative study of digital audio steganography techniques. EURASIP J. Audio Speech Music. Process. 2012, 2012, 25. [Google Scholar] [CrossRef] [Green Version]
- Mawalim, C.O.; Wang, S.; Unoki, M. Speech Information Hiding by Modification of LSF Quantization Index in CELP Codec. In Proceedings of the Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA 2020), Auckland, New Zealand, 7–10 December 2020; pp. 1321–1330. [Google Scholar]
- Wang, S.; Unoki, M. Watermarking of speech signals based on formant enhancement. In Proceedings of the 22nd European Signal Processing Conference (EUSIPCO 2014), Lisbon, Portugal, 1–5 September 2014; pp. 1257–1261. [Google Scholar]
- Wang, S.; Yuan, W.; Wang, J.; Unoki, M. Speech Watermarking Based on Robust Principal Component Analysis and Formant Manipulations. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2018), Calgary, AB, Canada, 15–20 April 2018; pp. 2082–2086. [Google Scholar] [CrossRef]
- Mcadams, S. Spectral Fusion, Spectral Parsing and the Formation of Auditory Images. Ph.D. Thesis, Stanford University, Stanford, CA, USA, 1984. [Google Scholar]
- Dodge, C.; Jerse, T.A. Computer Music: Synthesis, Composition, and Performance; Cengage Learning: Boston, MA, USA, 1997. [Google Scholar]
- Cohen, J.; Kamm, T.M.; Andreou, A. Vocal tract normalization in speech recognition: Compensating for systematic speaker variability. J. Acoust. Soc. Am. 1995, 97, 3246–3247. [Google Scholar] [CrossRef]
- Patino, J.; Tomashenko, N.A.; Todisco, M.; Nautsch, A.; Evans, N.W.D. Speaker anonymisation using the McAdams coefficient. arXiv 2020, arXiv:2011.01130. [Google Scholar]
- Mawalim, C.O.; Unoki, M. Improving Security in McAdams Coefficient-Based Speaker Anonymization by Watermarking Method. arXiv 2021, arXiv:2107.07223. [Google Scholar]
- Baluja, S. Hiding Images in Plain Sight: Deep Steganography. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 2069–2079. [Google Scholar]
- Zhu, J.; Kaplan, R.; Johnson, J.; Fei-Fei, L. HiDDeN: Hiding Data with Deep Networks. In Computer Vision—ECCV 2018; Springer International Publishing: Cham, Switzerland, 2018; pp. 682–697. [Google Scholar] [CrossRef] [Green Version]
- Kreuk, F.; Adi, Y.; Raj, B.; Singh, R.; Keshet, J. Hide and Speak: Towards Deep Neural Networks for Speech Steganography. In Proceedings of the 21st Annual Conference of the International Speech Communication Association, Virtual Event (INTERSPEECH 2020), Shanghai, China, 25–29 October 2020; pp. 4656–4660. [Google Scholar] [CrossRef]
- Voice Privacy Organisers. Voice Privacy Challenge 2020. Available online: https://github.com/Voice-Privacy-Challenge/Voice-Privacy-Challenge-2020 (accessed on 21 September 2021).
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An ASR corpus based on public domain audio books. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2015), South Brisbane, QLD, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar] [CrossRef]
- Veaux, C.; Yamagishi, J.; Macdonald, K. CSTR VCTK Corpus: English Multi-speaker Corpus for CSTR Voice Cloning Toolkit. 2017. Available online: https://doi.org/10.7488/ds/2645 (accessed on 21 September 2021).
- IHC Committee. IHC Evaluation Criteria and Competition. Available online: https://www.ieice.org/iss/emm/ihc/IHC_criteriaVer6.pdf (accessed on 8 June 2021).
- Gray, A.; Markel, J. Distance measures for speech processing. IEEE Trans. Acoust. Speech Signal Process. 1976, 24, 380–391. [Google Scholar] [CrossRef]
- Rix, A.W.; Beerends, J.G.; Hollier, M.P.; Hekstra, A.P. Perceptual evaluation of speech quality (PESQ)—A new method for speech quality assessment of telephone networks and codecs. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2001), Salt Lake City, UT, USA, 7–11 May 2001; pp. 749–752. [Google Scholar] [CrossRef]
- Mawalim and Unoki. Demo Speech of Paper Titled: Speech Watermarking Method Using McAdams Coefficient Based on Random Forest Learning. Available online: http://www.jaist.ac.jp/~s1920436/Entropy2021/demo/demo.html (accessed on 21 September 2021).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
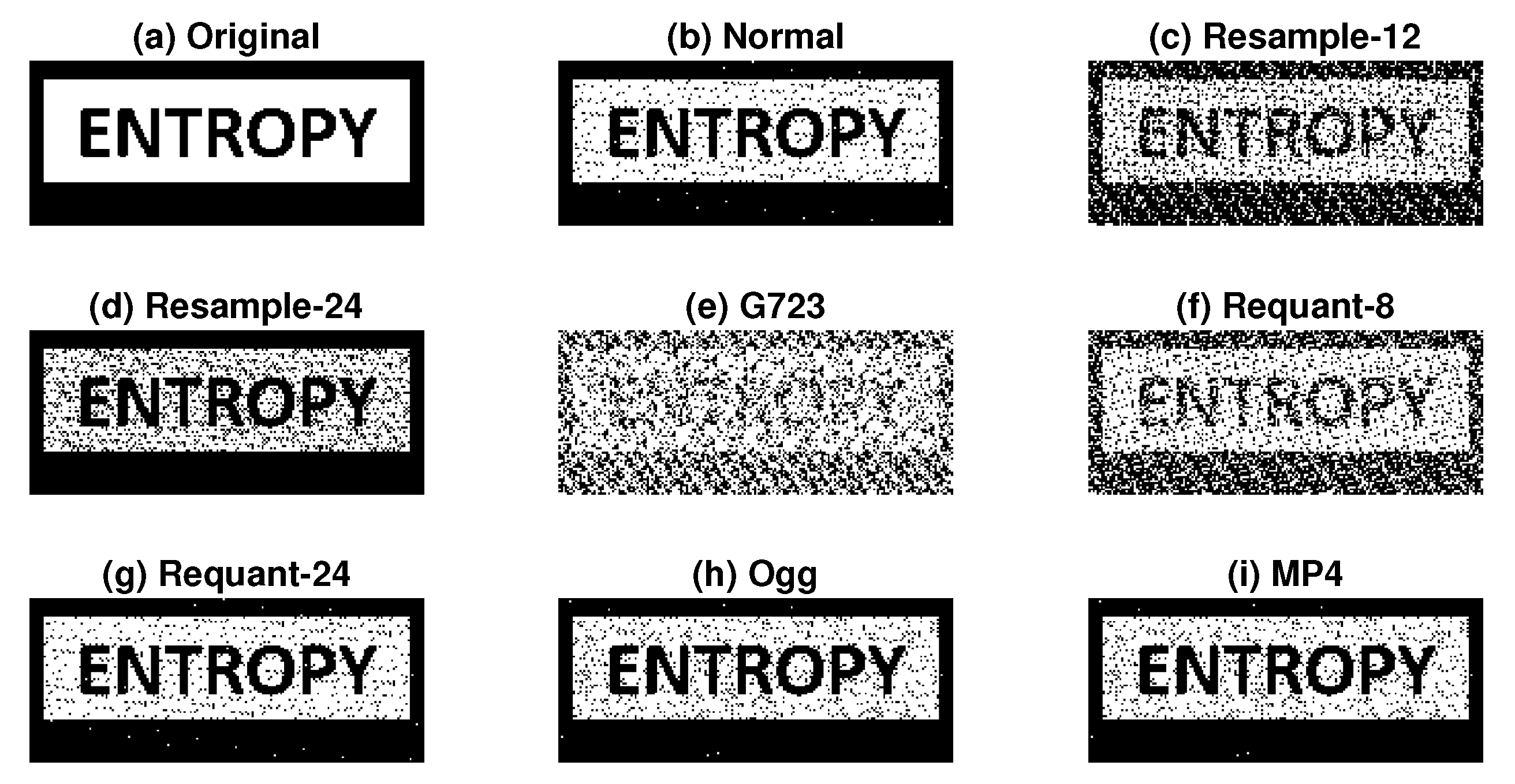{kind=link}
| Subset | Number of Speakers | Number of Utterances | ||
|---|---|---|---|---|
| Male | Female | Total | ||
| LibriSpeech (train) | 4 | 4 | 8 | 225 |
| LibriSpeech (test) | 2 | 2 | 4 | 25 |
| VCTK (train) | 1 | 1 | 2 | 225 |
| VCTK (test) | 1 | 1 | 2 | 25 |
| Total | 8 | 8 | 8 | 500 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mawalim, C.O.; Unoki, M. Speech Watermarking Method Using McAdams Coefficient Based on Random Forest Learning. Entropy 2021, 23, 1246. https://doi.org/10.3390/e23101246
Mawalim CO, Unoki M. Speech Watermarking Method Using McAdams Coefficient Based on Random Forest Learning. Entropy. 2021; 23(10):1246. https://doi.org/10.3390/e23101246
Chicago/Turabian StyleMawalim, Candy Olivia, and Masashi Unoki. 2021. "Speech Watermarking Method Using McAdams Coefficient Based on Random Forest Learning" Entropy 23, no. 10: 1246. https://doi.org/10.3390/e23101246
APA StyleMawalim, C. O., & Unoki, M. (2021). Speech Watermarking Method Using McAdams Coefficient Based on Random Forest Learning. Entropy, 23(10), 1246. https://doi.org/10.3390/e23101246