
Meta-Strategy for Learning Tuning Parameters with Guarantees



Abstract
:1. Introduction
1.1. Related Works
1.2. Organization of the Paper
2. Notations and Preliminaries
3. Meta-Learning Algorithms
3.1. Special Case: The Gradient of the Meta-Loss Is Available in Closed Form
3.2. The General Case
3.3. Regret Analysis
4. Example: Learning the Tuning Parameters of Online Gradient Descent
4.1. Explicit Meta-Regret Bound
4.2. Special Case: Quadratic Loss
4.3. The General Case
4.4. Experimental Study
4.4.1. Synthetic Regression
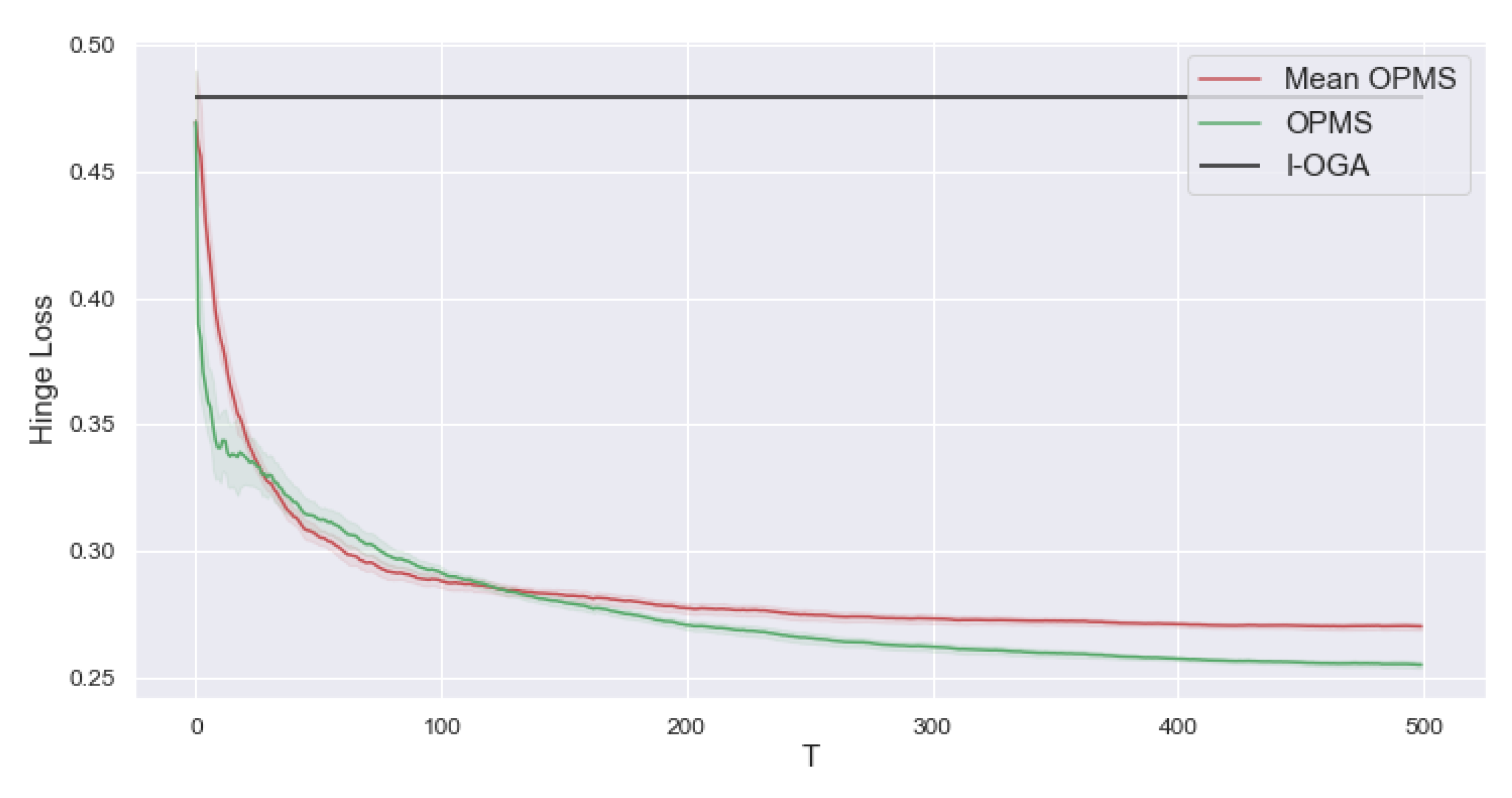
4.4.2. Synthetic Classification
5. Second Example: Learning the Prior or the Learning Rate in Exponentially Weighted Aggregation
5.1. Reminder on EWA
5.2. Learning the Rate
5.3. Learning the Prior
5.4. Discussion on the Continuous Case
6. Proofs
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Thrun, S.; Pratt, L. Learning to Learn; Kluwer Academic Publishers: New York, NY, UK, 1998. [Google Scholar]
- Chollet, F. On the measure of intelligence. arXiv 2019, arXiv:1911.01547. [Google Scholar]
- Cesa-Bianchi, N.; Lugosi, G. Prediction, Learning, and Games; Cambridge University Press: Cambridge, UK, 2006. [Google Scholar]
- Hazan, E. Introduction to online convex optimization. arXiv 2019, arXiv:1909.05207. [Google Scholar]
- Orabona, F. A modern introduction to online learning. arXiv 2019, arXiv:1912.13213. [Google Scholar]
- Shalev-Shwartz, S. Online learning and online convex optimization. Found. Trends Mach. Le. 2012, 4, 107–194. [Google Scholar] [CrossRef]
- Maurer, A. Bounds for linear multi-task learning. J. Mach. Learn. Res. 2006, 7, 117–139. [Google Scholar]
- Romera-Paredes, B.; Aung, H.; Bianchi-Berthouze, N.; Pontil, M. Multilinear multitask learning. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1444–1452. [Google Scholar]
- Yamada, M.; Koh, T.; Iwata, T.; Shawe-Taylor, J.; Kaski, S. Localized lasso for high-dimensional regression. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, PMLR, Fort Lauderdale, FL, USA, 20–22 April 2017; Volume 54, pp. 325–333. [Google Scholar]
- Alquier, P.; Mai, T.T.; Pontil, M. Regret Bounds for Lifelong Learning. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; Volume 54, pp. 261–269. [Google Scholar]
- Amit, R.; Meir, R. Meta-learning by adjusting priors based on extended PAC-Bayes theory. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 205–214. [Google Scholar]
- Baxter, J. Theoretical models of learning to learn. In Learning to Learn; Springer: Berlin, Germany, 1998; pp. 71–94. [Google Scholar]
- Jose, S.T.; Simeone, O.; Durisi, G. Transfer meta-learning: Information-theoretic bounds and information meta-risk minimization. arXiv 2020, arXiv:2011.02872. [Google Scholar]
- Maurer, A.; Pontil, M.; Romera-Paredes, B. The benefit of multitask representation learning. J. Mach. Learn. Res. 2016, 17, 1–32. [Google Scholar]
- Pentina, A.; Lampert, C. A PAC-Bayesian bound for lifelong learning. In Proceedings of the 31st International Conference on Machine Learning, Bejing, China, 22–24 June 2014; pp. 991–999. [Google Scholar]
- Rothfuss, J.; Fortuin, V.; Krause, A. Pacoh: Bayes-optimal meta-learning with pac-guarantees. arXiv 2020, arXiv:2002.05551. [Google Scholar]
- Andrychowicz, M.; Denil, M.; Gomez, S.; Hoffman, M.W.; Pfau, D.; Schaul, T.; Shillingford, B.; De Freitas, N. Learning to learn by gradient descent by gradient descent. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 3981–3989. [Google Scholar]
- Ruvolo, P.; Eaton, E. Ella: An efficient lifelong learning algorithm. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 17–19 June 2013; pp. 507–515. [Google Scholar]
- Balcan, M.-F.; Khodak, M.; Talwalkar, A. Provable guarantees for gradient-based meta-learning. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 424–433. [Google Scholar]
- Denevi, G.; Ciliberto, C.; Stamos, D.; Pontil, M. Learning to learn around a common mean. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 10169–10179. [Google Scholar]
- Denevi, G.; Ciliberto, C.; Grazzi, R.; Pontil, M. Learning-to-learn stochastic gradient descent with biased regularization. arXiv 2019, arXiv:1903.10399. [Google Scholar]
- Denevi, G.; Pontil, M.; Ciliberto, C. The advantage of conditional meta-learning for biased regularization and fine tuning. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020; Volume 33. [Google Scholar]
- Fallah, A.; Mokhtari, A.; Ozdaglar, A. On the convergence theory of gradient-based model-agnostic meta-learning algorithms. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Online, 26–28 August 2020; pp. 1082–1092. [Google Scholar]
- Finn, C.; Rajeswaran, A.; Kakade, S.; Levine, S. Online meta-learning. arXiv 2019, arXiv:1902.08438. [Google Scholar]
- Konobeev, M.; Kuzborskij, I.; Szepesvári, C. On optimality of meta-learning in fixed-design regression with weighted biased regularization. arXiv 2020, arXiv:2011.00344. [Google Scholar]
- Zhou, P.; Yuan, X.; Xu, H.; Yan, S.; Feng, J. Efficient meta learning via minibatch proximal update. In Proceedings of the 2019 Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 1534–1544. [Google Scholar]
- Denevi, G.; Stamos, D.; Ciliberto, C.; Pontil, M. Online-within-online meta-learning. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 13110–13120. [Google Scholar]
- Meunier, D. Meta-Learning Meets Variational Inference: Learning Priors with Guarantees. Master’s Thesis, Université Paris Saclay, Paris, France, 2020. Available online: https://dimitri-meunier.github.io/files/RikenReport.pdf (accessed on 26 September 2021).
- Khodak, M.; Balcan, M.-F.; Talwalkar, A. Adaptive Gradient-Based Meta-Learning Methods. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 5917–5928. [Google Scholar]
- Li, L.; Jamieson, K.; DeSalvo, G.; Rostamizadeh, A.; Talwalkar, A. Hyperband: A novel bandit-based approach to hyperparameter optimization. J. Mach. Learn. Res. 2017, 18, 6765–6816. [Google Scholar]
- Shang, X.; Kaufmann, E.; Valko, M. A simple dynamic bandit algorithm for hyper-parameter tuning. In Proceedings of the 6th ICML Workshop on Automated Machine Learning, Long Beach, CA, USA, 14–15 June 2019. [Google Scholar]
- Kivinen, J.; Warmuth, M.K. Exponentiated gradient versus gradient descent for linear predictors. Inf. Comput. 1997, 132, 1–63. [Google Scholar] [CrossRef]
- Kulis, B.; Bartlett, P.L. Implicit online learning. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 575–582. [Google Scholar]
- Parikh, N.; Boyd, S. Proximal algorithms. Found. Trends Optim. 2014, 1, 127–239. [Google Scholar] [CrossRef]
- Nesterov, Y. Introductory Lectures on Convex Optimization: A Basic Course; Springer Science & Business Media: Berlin, Germany, 2004; Volume 87. [Google Scholar]
- Alquier, P. Approximate Bayesian Inference. Entropy 2020, 22, 1272. [Google Scholar] [CrossRef] [PubMed]
- Mai, T.T. On continual single index learning. arXiv 2021, arXiv:2102.12961. [Google Scholar]
- Lin, W.; Khan, M.E.; Schmidt, M. Fast and simple natural-gradient variational inference with mixture of exponential-family approximations. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 3992–4002. [Google Scholar]
- Chérief-Abdellatif, B.-E.; Alquier, P.; Khan, M.E. A generalization bound for online variational inference. In Proceedings of the Eleventh Asian Conference on Machine Learning, PMLR, Nagoya, Japan, 17–19 November 2019; Volume 101, pp. 662–677. [Google Scholar]
- Domke, J. Provable smoothness guarantees for black-box variational inference. In Proceedings of the 37th International Conference on Machine Learning, Online, 12–18 July 2021; Volume 119, pp. 2587–2596. [Google Scholar]
- Alquier, P. Non-exponentially weighted aggregation: Regret bounds for unbounded loss functions. In Proceedings of the 38th International Conference on Machine Learning, Online, 18–24 July 2021; Volume 139, pp. 207–218. [Google Scholar]
- Knoblauch, J.; Jewson, J.; Damoulas, T. Generalized variational inference: Three arguments for deriving new posteriors. arXiv 2019, arXiv:1904.02063. [Google Scholar]
- Campolongo, N.; Orabona, F. Temporal variability in implicit online learning. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; Volume 33. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
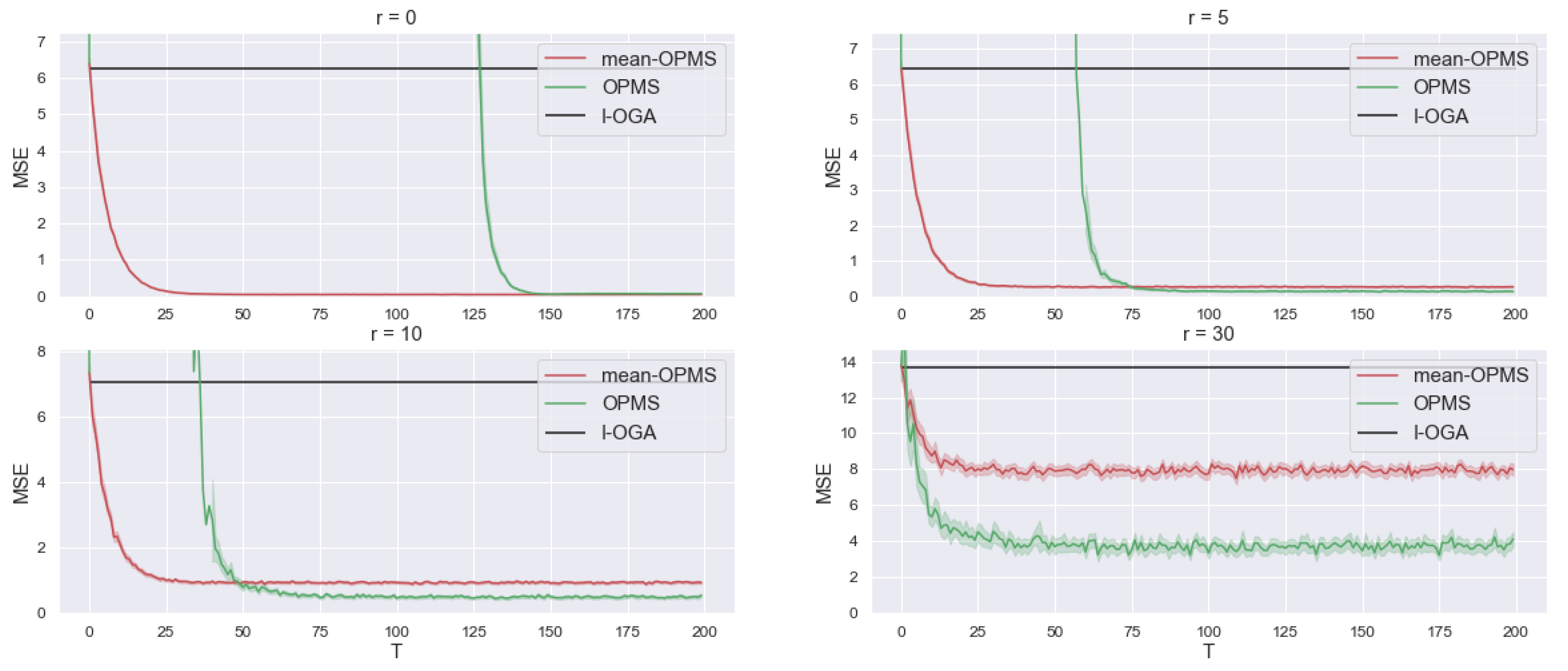
| r = 0 | r = 5 | r = 10 | r = 30 | |
|---|---|---|---|---|
| I-OGA | 6.24 | 6.44 | 7.06 | 13.60 |
| mean OPMS | 0.05 | 0.27 | 0.93 | 7.93 |
| OPMS | 0.07 | 0.15 | 0.49 | 3.72 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meunier, D.; Alquier, P. Meta-Strategy for Learning Tuning Parameters with Guarantees. Entropy 2021, 23, 1257. https://doi.org/10.3390/e23101257
Meunier D, Alquier P. Meta-Strategy for Learning Tuning Parameters with Guarantees. Entropy. 2021; 23(10):1257. https://doi.org/10.3390/e23101257
Chicago/Turabian StyleMeunier, Dimitri, and Pierre Alquier. 2021. "Meta-Strategy for Learning Tuning Parameters with Guarantees" Entropy 23, no. 10: 1257. https://doi.org/10.3390/e23101257
APA StyleMeunier, D., & Alquier, P. (2021). Meta-Strategy for Learning Tuning Parameters with Guarantees. Entropy, 23(10), 1257. https://doi.org/10.3390/e23101257