1. Introduction
Since a few years ago, the segmentation of farmland based on remote sensing images has been studied extensively owing to the development of deep learning technology, making intelligent farmland a hot trend. Based on their shooting distance, satellites and unmanned aerial vehicles are two common photographing tools. Satellite-based remote sensing images are mainly used in the segmentation of farmland forest areas such as Han Lin Aung, Burak Uzkent, etc., using space–time convolution networks to circle the farmland plots [
1]. Guang Wang, Fan Yu, and others used the segmentation models of farmland and woodland with the help of remote sensing images to segment the farmland and woodland [
2]. Ganchenko et al. used convolutional neural networks based on agricultural vegetation monitoring image semantic segmentation [
3]. Drone-based remote sensing images are mainly used in specific scene analysis of a field, such as Yang’s [
4] deep semantic segmentation techniques, Fully Convolutional Networks (FCN), SegNet, etc., which segment the farmland covered by plastic mulch to study environmental and soil contamination. There are crop and weed segmentations studied by Lei F. Tian and Heping Zhu et al. [
5] using drones to capture low-altitude images of crops for crop morphological segmentation [
6].
Wheat is the world’s largest ration crop; it has high economic, medicinal, and nutritional value, according to the Journal of Experimental Botany [
7]. Therefore, we take wheat crops as an example to study.
The satellite image monitoring used previously is a very macro means of observation. Many problems are often faced in the early stages of wheat cultivation. Many factors can make wheat crops grow poorly in the early stages. The main factors leading to their initial dysplasia can be classified as environmental factors and their own factors. Environmental factors mainly include weather, pests and diseases, soil, and other such external factors. In the previous application, the use of semantic segmentation techniques for early development monitoring of wheat included wheat insect identification [
8] and wheat field weed segmentation [
5], combined with sensor equipment to measure soil acidity and alkalinity, detect nutrients, monitor weather [
9], and so on. During the study, it was found that a small proportion of wheat planted in the field could be stunted or lodged, or even directly died due to these influencing factors. This leads to a common phenomenon: the creation of vacancies in farmland. This performance is a direct reflection and manifestation of the poor growth of wheat. Therefore, we propose a method of segmenting wheat vacancies in the early stages, as it is an important factor in the growth of wheat, making it easy to consider in estimating yield.
This paper mainly studies the problems prevailing in the application of existing semantic segmentation technologies in farmland vacancy segmentation, analyzes the advantages and disadvantages of each method according to the comparison of training process and experimental results, and proposes a new semantic segmentation network based on encoder–decoder architecture. At the same time, according to the characteristics of the dataset, the algorithm is improved adaptively. This paper is divided into six parts. The background section introduces several mainstream semantic segmentation techniques and summarizes the contribution of this paper, followed by the dataset section, and the methods used in this paper and the training process are described later. The validity of the new model is then proved by experimental results.
2. Related Work
The introduction mentions that semantic segmentation technology has developed rapidly in recent years, which makes its application scope gradually expand and gradually cover all areas of life. However, in the field of agricultural application, the research on farmland vacancy segmentation is rarely involved. Therefore, we first study the development process and basic principles of the semantic segmentation algorithm, explore the application of these technologies in similar scenes, and analyze their advantages and disadvantages. According to these algorithms, we redesign and improve the algorithms in order to get the optimal algorithm for the scene.
As we all know, the FCN model [
10] opens a new path for semantic segmentation research and solves the semantic-level image segmentation, and the U-Net [
11] has achieved significant results in the field of biomedical segmentation, which mainly solves the problem of small sample training to extract detailed texture features, such as using it for yellow embroidery surveillance in wheat fields [
12] and retinal vessel segmentation [
13]. Thus, the semantic segmentation algorithm has made a leap forward. Both algorithms originate from the Convolutional Neural Network.
The Convolutional Neural Network (CNN) gained popularity because AlexNet [
14] had achieved a higher score than traditional methods in an ImageNet image recognition competition. However, as it defines every pixel, the relationship between pixels cannot be fully considered, and the lack of spatial unity leads to poor performance in semantic level segmentation. Thus, the Full Convolutional Network (FCN) [
10] was born, which changed the entire connection layer in the last layer of the earlier classification network. It thus changed the previous result of the output one-dimensional probability vector and realized output characteristic graph. At the same time, a combined deconvolution, upsampling, and skip structure method was used to achieve end-to-end training results. Similarly, combined with deconvolution, the method of upper sampling and jump structure was used, and it achieved pioneering results of end-to-end training.
In order to reduce the cost of computing in the process of network training, researchers propose a dense network architecture called DenseNet [
15]. DenseNets are built from dense block sand pooling operations, where each dense block is an iterative concatenation of previous feature maps. This structure extension is also applied to FCN to form FC-DenseNet [
16]. It exploits the feature reuse by extending the more complex DenseNet architecture by skipping connections in the original FCNs, while avoiding feature overflow on the sampling path on the network. Later, in order to better apply the semantic segmentation algorithm to the segmentation of complex scenes, PSPNet [
17] was born. PSPNet, with an atrous convolution of FCN as a baseline, focusing on the three aspects of mismatched relations, confusion categories, and inconspicuous classes, designed a hierarchical global priority containing information on different scales between different sub-regions, called the pyramid pooling module. The module incorporates four different pyramid-scale features using a feature chart, which is pooled with four sizes of pooled cores, resulting in four different scales of the feature map. To maintain the weight of the global feature, we use a 1 × 1 convolution layer to reduce the dimension. Then a bilinear interpolation method is used to restore the size of the feature map and concatenate four different levels of features, and finally, the global features of the pyramid pool are obtained.
The idea of dense connection is applied to atrous spatial pyramid pooling (ASPP) to increase the receptive field. DenseASPP [
18] has revealed that atrous convolution becomes less and less effective and gradually loses the modeling ability as the dilation rate of ASPP increases. Therefore, it is very important to find a network structure that can encode multi-scale information while obtaining a large enough receiving domain. DenseASPP combines the advantages of parallel and cascading using atrous convolution to map multi-scale features on a larger scale. Through a series of feature connections, neurons on each intermediate feature map encode semantic information from multiple scales, and different intermediate feature maps encode multi-scale information from different scales. Through a series of atrous convolutions, the neurons at later levels can obtain larger receptive fields, as there is no degeneration of the convolution kernel of ASPP. Thus, the final output of the DenseASPP model is a feature map that covers a wide range of semantic information in a very dense way.
DeepLabv3+ is an improved version of the DeepLab series [
19,
20,
21]. After a series of developments, it is a mature algorithm for scene segmentation at present. DeepLabv3+ [
22] added a decoder considering the problem of reduced feature map resolution and reduced prediction accuracy caused by the network layer with stride=2 in the ResNet network structure. The original DeepLabv3 as an encoder of the network structure, unlike the direct bilinear downsampling recovery feature map, has features that are first bilinearly upsampled by a factor of 4 and then concatenated with the corresponding low-level features from the network backbone that have the same spatial resolution. In addition, because of this improvement, the parameter volume increases. Here, Xception is used instead of ResNet as the backbone for training.
Through the development of these algorithms, we find that most researchers are improving their accuracy in some specific data sets, so that they can be applied to large scene analysis, automatic driving, and other fields. However, for some unique scenarios, these algorithms may not be able to show their advantages well. Of course, the development of these technologies also drives the research on the application of semantic segmentation algorithm in some specific scenes. Among them, the most similar to the research field of this paper is crack segmentation.
The rapid emergence of this technology has also led to the development of semantic segmentation in the field of crack segmentation. Mark David Jenkins, Thomas Arthur Carr [
23], and others proposed a deep convolutional neural network for the semantic pixel-wise segmentation of road and pavement surface cracks, which also considered the cost of data acquisition and chose to conduct training in a small sample dataset. It finally achieved good results in a dataset with only 80 images. Similarly, Henrique Oliveira, Paulo Lobato Correia et al. [
24] applied improved segmentation methods based on pixel refinement to pave the way for crack detection. Additionally, Martin Mayr, Mathis Hoffmann [
25] used the improved ResNet50 network to segment the cracks in the EL image of the solar cell.
It is worth noting that farmland vacancy segmentation is more difficult as compared to cracks segmentation, because the vacancies are comprised of various sizes and shapes. Therefore, in most of the above-mentioned work, there are some drawbacks in the application of vacancy segmentation. Our work is mainly to improve the existing algorithm in this field to be suitable for the precise segmentation of crops and vacancies. Inspired by the DeepLabv3+ model [
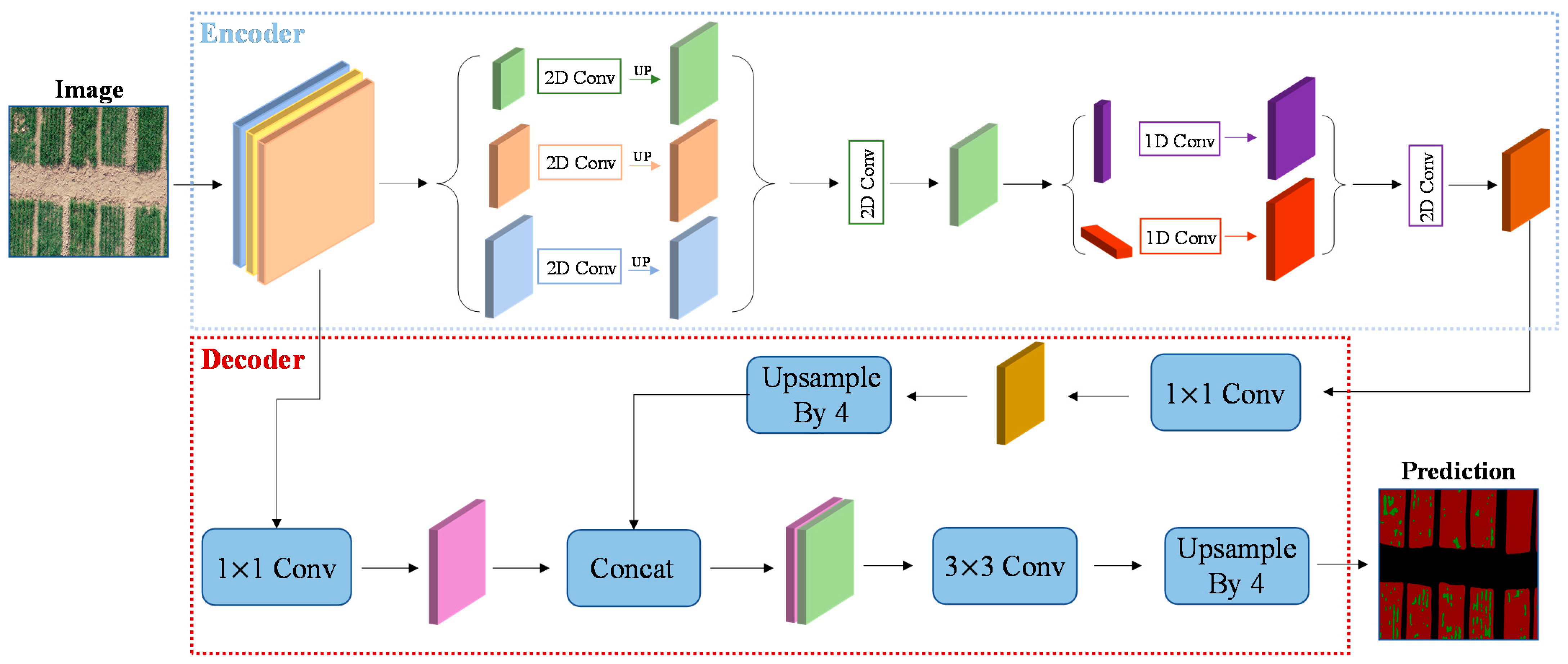
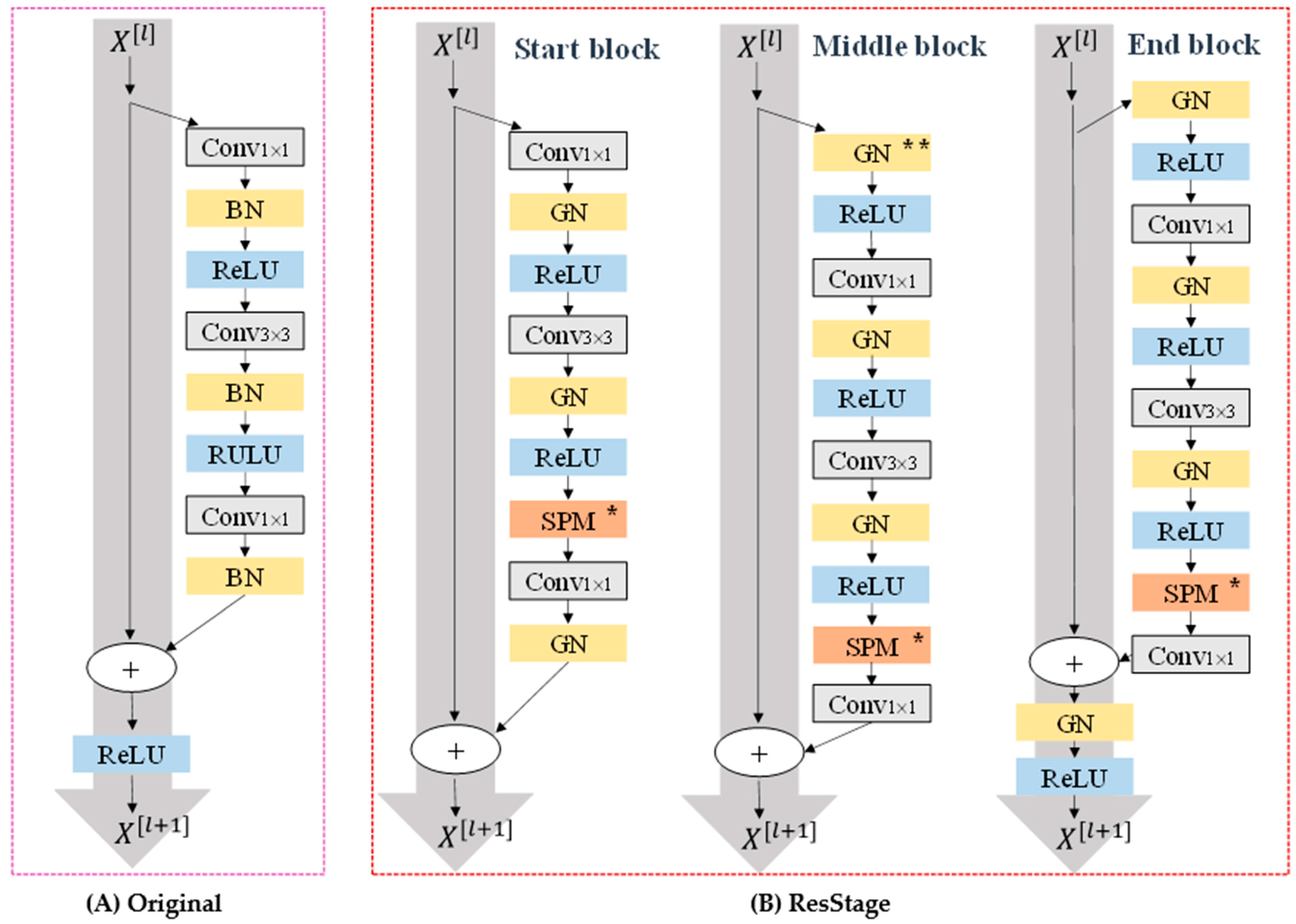
22], we used the encoder–decoder’s network architecture to better recover image information. At the same time, we leveraged a combination of strip pooling and spatial pyramid pooling to achieve a better segmentation of vacancies and crops. SPINet, the end-to-end method proposed by us, uses an improved ResNet network as an encoder and combines SPM and MPM modules to establish a self-attention mechanism. The decoder concatenates the output of the last layer of encoder and the output of the middle layer, and obtains the prediction graph by sampling up and recovering pixels.
Our contributions can be summarized as follows:
- (1)
We propose a semantic segmentation network, based on encoder–decoder architecture, which takes IResNet network as the backbone and integrates SPM and MPM modules to build the model self-attention mechanism.
- (2)
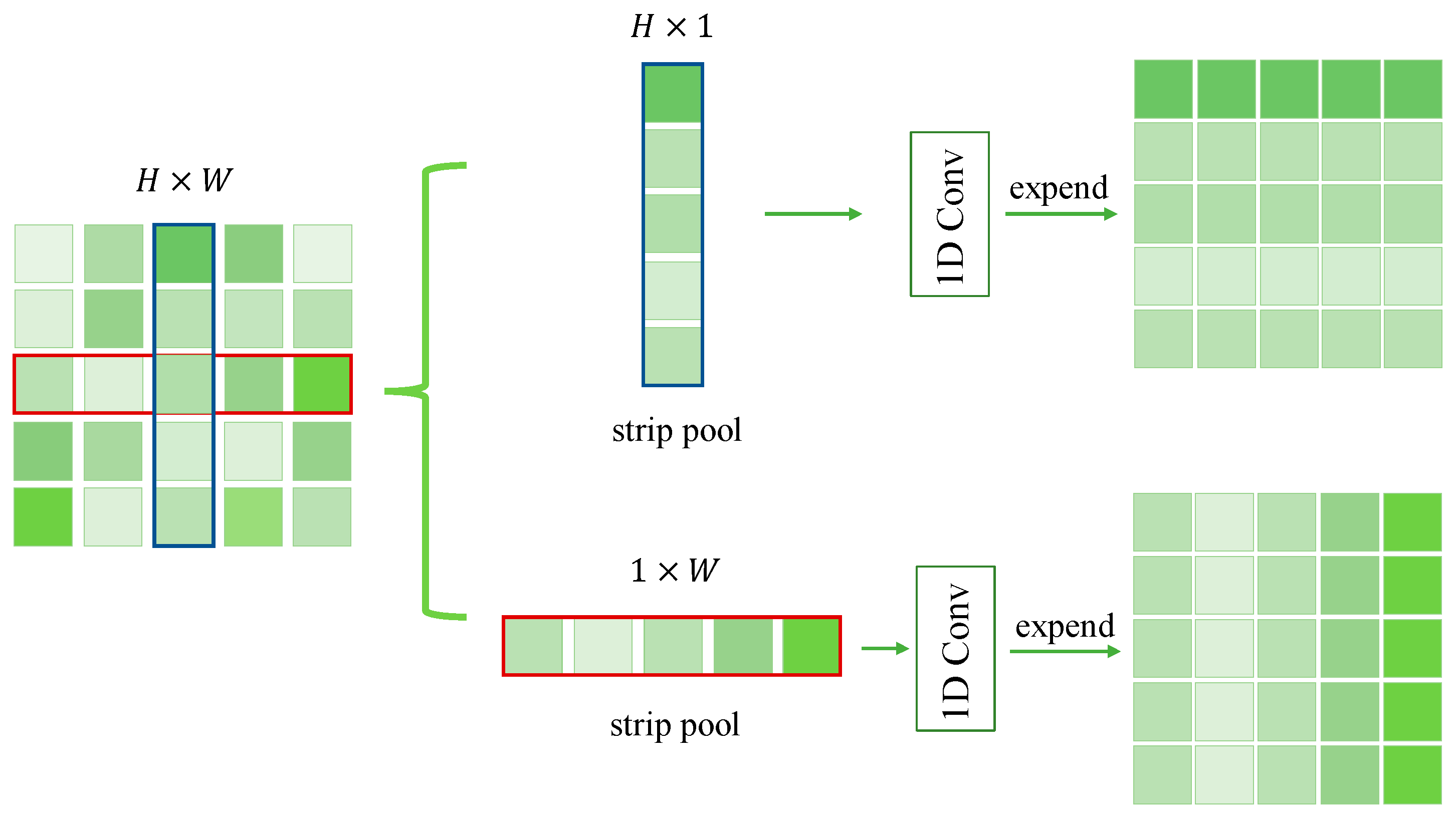
We take advantage of strip pooling to capture vacancies with greater precision.
- (3)
We provide a farmland dataset taken by Unmanned Aerial Vehicle, containing 320 pieces of training data, 80 pieces of test data, and 40 pieces of verification data.
- (4)
The model that we designed can adapt to the training of small samples and reach a good level.
5. Discussion
Vacancy segmentation is a branch of semantic segmentation and has a huge potential for its application in image crack detection (e.g., road crack detection). Farmland vacancies are handled in a different way than in previous datasets because of their relatively large randomness and irregularity. In this paper, a method of semantic segmentation of farmland vacancies is proposed, which is more accurate than several existing typical semantic segmentation methods. Based on this, our discussion is as follows:
5.1. Contribution to Cracks Segmentation
The difference between crack segmentation and general semantic segmentation application is that the image of crack segmentation has subtle features and small targets, making the segmentation method unsuitable for all kinds of traffic and character scenes. The segmentation model, described in this paper, based on farmland vacancy, can better solve this problem. Firstly, we analyze the differences and relation between vacancy segmentation and cracks segmentation. Although farmland vacancy and crack both belong to vacancy segmentation, it is obvious that farmland vacancy has more randomness in shape and size and is denser in distribution than ordinary cracks, which can also be confirmed from the actual images. Therefore, algorithms suitable for simple crack segmentation cannot be well applied in this field. Compared with other methods, the method proposed by us has proved by experiments that all indices have been significantly improved, especially by nearly 4% on mIoU. This method provides an idea for complex cracks segmentation and can be directly transferred to the field for use.
5.2. Contribution to Estimate of Crop Growth and Yield
As mentioned in the Introduction section, the growth process of crops is accompanied by considerable randomness, and all stages from germination to seedling to maturity may be affected by various environmental factors. Therefore, in order to analyze and understand the crop growth situation in time, scientific researchers have put forward many methods. Huilin Tao, Liangji Xu et al. [
33], using a hyperspectral sensor installed on an Unmanned Aerial Vehicle (UAV), obtained vegetation index and red edge parameters and their combination. Using stepwise regression (SWR) the partial least squares regression (PLSR) method, above ground biomass (AGB), and the leaf area index (LAI), two kinds of plant growth parameters were estimated. In addition, Thomas Moeckel, Supriya Dayananda et al. [
34] used UAV to collect images for 3D point cloud analysis of crop phenotypes. Yi Ma, Shenghui Fang et al. [
35] used hyperspectral data to collect dry AGB, because it is an important parameter in assessing crop growth and predicting the yield. Vacancy ratios are not only meaningful in long-term estimation, but also an important indicator in crop growth analysis. At the same time, the segmentation of crops can be derived from the actual planting area of crops in the area, so that it can be directly applied to the crop yield estimate and also combined with the long-potential estimate and other data to carry out the yield estimate.
From the macro point of view, dividing crops and vacancies directly to obtain crop planting vacancy ratio can obtain not only the theoretical crop cover area, but also the actual crop area, which is a direct, effective, and simple way to estimate crop growth. It can be seen from our research that vacancy rate is important in growth estimation and is an important indicator in crop growth analysis. At the same time, the segmentation of crops in this paper can obtain the actual planting area of crops in this area. It can thus be directly used in crop yield estimation or combined with growth prediction and other data for yield estimation.
5.3. Different from Existing Methods
Based on the thin, long, and narrow characteristics of most cracks and vacancies, our model adopts the strip pooling idea of deploying a narrow kernel shape along a spatial dimension, to capture long-distance distributions of isolated areas. This is also, in fact, conducive to capturing the characteristics of cracks. At the same time, integration of the spatial pyramid module allows the model to detect effectively and split when other shapes appear in the crack. However, because the crack edge information is too low, in the normal upper sampling process, it is easy to lose its original information.
5.3.1. Effects of Strip Pooling and Decoder
In order to verify the actual effect of the improved method proposed by us, we conducted detailed comparative experiments, and the results are presented in
Table 2. SPNet101 is kept constant here. With the improved ResNet as backbone, mIoU increased by about 1% in the validation set. If only the decoder layer is added, the original SPNet101 as the encoder layer increases in accuracy by approximately 0.6% and mIoU by about 2%. When both are added, the accuracy improvement is small compared to just adding the decoder, but mIoU increases by nearly 1%. Hence, we believe that our improvements are effective, especially in the pixel recovery of feature maps, which can accurately restore the information on the vacancy edge of the crop and correctly split out the larger vacancies in the crop.
In order to better illustrate this point, we chose an actual picture. From the original picture in
Figure 7, it can be found that there are many vacancy distributions in crops, and part of the vacancy is long, in the shape of strips. Therefore, in the segmentation results of SPNet101 model, these vacancies can be well segmented. However, compared with ground truth, its excessive ability to predict vacancy leads to more wrong categories that should not be predicted. In comparison, the model proposed by us achieves a balance in this process, with neither excessive prediction nor little prediction, the prediction result is very similar to the ground truth.
5.3.2. Comparison with Other Methods
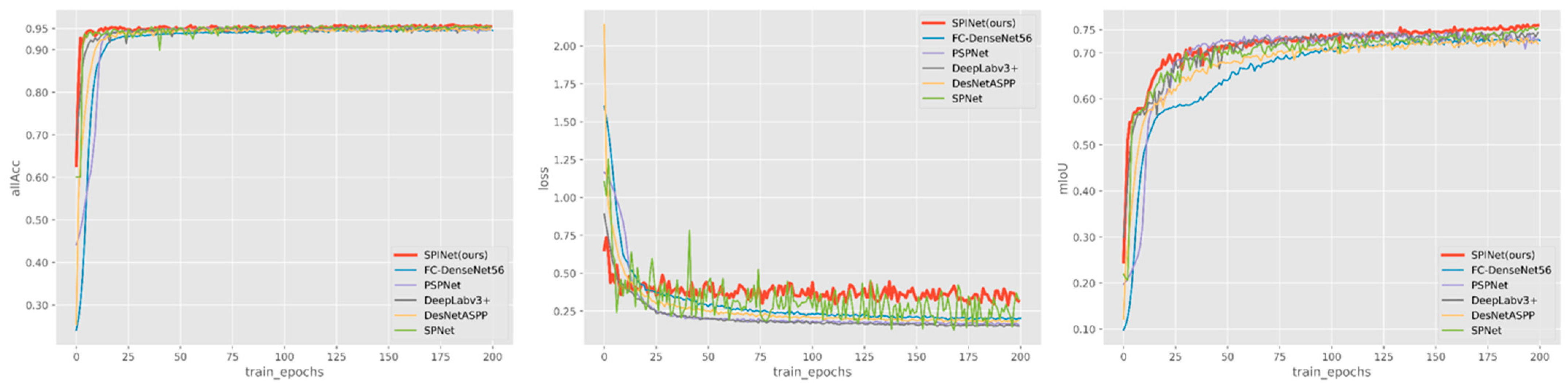
During the experiment, we compared the application of FC-DenseNet56, PSPNet, and other methods in the dataset and obtained the experimental results of each method. In this section, we discuss each method along with the experimental results and the experimental process.
Here, we will macroscopically analyze the parameters of different methods used in this paper. As we all know, DenseNet structure benefits from the design of a dense block, which makes the network narrower (that is, fewer channels) and reduces parameters to a certain extent. The parameters of the two models (FC-DenseNet56 and DenseASPP) derived from this are relatively small. However, as we will discuss later, the DenseNet network is not suitable for this application field, especially as there are large defects in the visualization results. In contrast, PSPNet has increased parameters on the basis of FCN, but the application effect is not good. DeepLabv3+ increases the number of parameters in a series of improvements, but it designs the depthwise separable convolution, which drastically reduces computation complexity, and its application effect is also worthy of praise. However, it is worth noting that the number of additional parameters added in SPM and MPM in this paper is only about half of that of the pyramid pooling module (PSPNet). Moreover, the increase of parameters brought by a simple and effective decoder is almost negligible. At the same time, the information transmission mode is improved for ResNet, but the number of parameters is not increased. Therefore, by comprehensive comparison, the model achieves good results under the condition of limited parameter increase.
First of all, with DenseNet as the backbone, we found that its features of dense jump connections are not suitable for applications in this field. In this field, only two categories need to be separated, crops and vacancies, where crops are the big targets and vacancies are the small ones. Multi-scale fusion and feature reuse in DenseNet grasps the characteristics of crop categories but does not distinguish between the vacant part of crops during subsampling, which leads to negligence of vacant part in the process of upsampling and image recovery. FC-DenseNet56’s fully connected approach mitigates this shortcoming, but makes the prediction of vacancies very messy and learning less effective. As DenseNet, the backbone of DenseASPP, can generate a very large range of receiver field features by using atrous spatial pyramid pooling (ASPP), due to the particularity of the vacancy features, can lose more information in the process of final upsampling and recovery. Similarly, for PSPNet, in the training process, we found that the spatial pyramid pooling network is not good at vacancy segmentation, and the prediction of a big vacancy is often wrong in the background. Instead, DeepLabV3 constructed with an encoder–decoder structure shows better adaptability in this dataset and obtains a better model with faster training effect. It also uses multiple sampling rates to expand convolution. The encoder–decoder structure captures clear target boundaries by gradually restoring spatial information. In these training processes, we have summarized the following points, which are the direct sources of our improvement:
The limited amount of information learned in the early stages of the backbone model, as a model of ResNet, leads us to wonder if much information was lost during the original transmission of ResNet.
The encoder–decoder structure recovers the target boundary information satisfactorily, especially the prediction accuracy of the vacant edge. This prompts us to think about building a network model of an overall encoder–decoder architecture.
As a single loss equation is used for all the previous training processes, training in small samples of those methods will quickly drop to a relatively low value, and the ability to learn new features of pictures will significantly reduce. In this regard, we use the method of loss reuse to improve this effect. The value of loss in Layer1 is added to the final calculation of loss with a certain proportion so that the value of loss will not be reduced to the point that it cannot be learned, but will be repeatedly learned in the process of oscillation. This is also determined by the characteristics of small-sample training.
5.4. Limitations and Future Work
The manual labeling of the vacancy segmentation of farmland images is very tedious and requires a lot of effort, which is also the reason why we chose the small sample training network. Moreover, it is difficult for the naked eye to distinguish between the vacant categories that are not obvious, making the results obtained by training and manually marked results erroneous. Such errors are not due to the model itself, but due to the fact that the two measures of vacancy are not exactly the same (mainly for a small vacancy). Therefore, we also propose an evaluation method that can better reflect the effect of the model to alleviate this problem. Additionally, this study is aimed at the training of a small sample of farmland in a certain region. Although the training speed is fast and the training effect is good for particular farmland, to be applied to other farmlands, their information needs to be collected for further training to achieve generalization. Therefore, in the future, farmland data of different regions and different terrains will be collected, and further enhancement in the adaptability and application range of the model through data augmentation training will be made.
Secondly, this paper considers the improvement of prediction accuracy and analyzes the problem of increasing parameters macroscopically, but does not calculate it in detail. In the future, more detailed studies will be made on this point to optimize the algorithm to reduce the number of parameters as much as possible.
6. Conclusions
Earlier, satellite image or aerial image labeling was directly used for farmland segmentation. However, it was too complicated for farmland segmentation in small areas and could not directly highlight the crop growth situation of farmland in such areas. Direct and rapid observation of crop growth in a certain region plays a significant role in rational planting density, crop growth prediction, crop growth analysis, and other aspects. Hence, we establish a semantic segmentation module based on encoder–decoder architecture, where SPINet as an encoder can automatically extract in-depth crop and vacancy information, set-up the decoder to recover extracted feature information, realize end-to-end training and prediction, and achieve good segmentation effect. Thus, from our experiments and comparative analysis, we draw the following conclusions:
Firstly, we construct a dataset of field crop and vacancy segmentation, which provides a new idea for studying field crop segmentation.
Secondly, the application effect of strip pooling in vacancy segmentation is very significant, which can adaptively capture the useful information of vacancy and then conduct accurate segmentation. Meanwhile, the encoder–decoder network structure is very effective for boundary pixel recovery of segmented targets.
Finally, the farmland segmentation method proposed in this paper reached 95.6%-pixel accuracy, and the mIoU value reached 77.6%, reaching the level of practical application. This method can be applied to crop growth analysis, assessment of crop growth, yield estimation, and other practical fields.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}