1. Introduction
Many time series show seasonal patterns that, according to [
1] for example, cannot be modeled appropriately using seasonal dummies because they exhibit a slowly trending behavior typical for unit root processes.
To model such processes in the vector autoregressive (VAR) framework, Ref. [
2] (abbreviated as JS in the following) extend the error correction representation for seasonally integrated autoregressive processes pioneered by [
3] to the multivariate case. This vector error correction formulation (VECM) models the yearly differences of a process observed
S times per year. The model includes systems having unit roots at some or all of the possible locations
of seasonal unit roots. In JS all unit roots are assumed to be simple such that the process of yearly differences is stationary.
In this setting JS propose an estimator for the autoregressive polynomial subject to restrictions on its rank (the so-called cointegrating rank) at the unit roots based on an iterative scheme focusing on a pair of complex-conjugated unit roots (or the unit roots or respectively) at a time. The main idea here is the reformulation of the model using the so called vector error correction representation. Beside estimators JS also derived likelihood ratio tests for the cointegrating rank at the various unit roots.
Refs. [
4,
5] propose simpler estimation schemes based on complex reduced rank regression (cRRR in the following). They also show that their numerically simpler algorithm leads to test statistics for the cointegrating rank that are asymptotically equivalent to the quasi maximum likelihood tests of JS. These schemes still typically alternate between cRRR problems corresponding to different unit roots until convergence, although a one step version estimating only once at each unit root exists. Ref. [
6] provides updating equations for quasi maximum likelihood estimation in situations where constraints on the parameters prohibit focusing on one unit root at a time.
The leading case here is that of quarterly data () where potential unit roots are located at and , implying that the VECM representation contains four potentially rank restricted matrices. However, increasingly time series of much higher sampling frequency such as hourly, daily or weekly observations are available. In such cases it is unrealistic that all unit roots are present. If a unit root is not present, the corresponding matrix in the VECM is of full rank. Therefore in situations with only a few unit roots being present, the VECM requires a large number of parameters to be estimated. Also in cases with a long period length (such as for example hourly data with yearly cycles) usage of the VECM involves the estimation of all coefficient matrices for lags for at least one year.
In general, for processes of moderate to large dimension the VAR framework involves estimation of a large number of parameters which potentially can be avoided by using the more flexible vector autoregressive moving average (VARMA) or the—in a sense—equivalent state space framework. This setting has been used in empirical research for the modeling of electricity markets, see the survey [
7] for a long list of contributions. In particular, ref. [
8] use the model described below without formal verification of the asymptotic theory for the quasi maximum likelihood estimation.
Recently, ref. [
9] show that in the setting of dynamic factor models, typically used for observation processes of high dimension, the common assumption that the factors are generated using a vector autoregression jointly with the assumption that the idiosyncratic component is white noise (or more generally generated using a VAR or VARMA model independent of the factors) leads to a VARMA process. Also a number of papers (see for example [
10,
11,
12]) show that in their empirical application the usage of VARMA models instead of approximations using the VAR model leads to superior prediction performance. This, jointly with the fact that the linearization of dynamic stochastic general equilibrium models (DSGE) leads to state space models, see e.g., [
13], has fuelled recent interest in VARMA—and thus state space—modeling in particular in macroeconomics, see for example [
14].
In this respect, quasi maximum likelihood estimation is the most often used approach for inference. Due to the typically highly non-convex nature of the quasi likelihood function (using the Gaussian density) in the VARMA setting, the criterion function shows many local maxima where the optimization can easily get stuck. Randomization alone does not solve the problem efficiently, as typically the parameter space is high-dimensional causing problems of the curse of dimensionality type.
Moreover, VARMA modeling requires a full specification of the state space unit root structure of the process, see [
15]. The state space unit root structure specifies the number of common trends at each seasonal frequency (see below for definitions). For data of weekly or higher sampling frequency it is unlikely that the state space unit root structure is known prior to estimation. Testing all possible combinations is numerically infeasible in many cases.
As an attractive alternative in this respect the class of subspace algorithms is investigated in this paper. One particular member of this class, the so called canonical variate analysis (
CVA) introduced by [
16] (in the literature the algorithm is often called canonical correlation analysis;
CCA), has been shown to provide system estimators which (under the assumption of known system order) are asymptotically equivalent to quasi maximum likelihood estimation (using the Gaussian likelihood) in the stationary case [
17].
CVA shares a number of robustness properties in the stationary case with VAR estimators: [
18] shows that
CVA produces consistent estimators of the underlying transfer function in situations where the innovations are conditionally heteroskedastic processes of considerable generality. Ref. [
19] shows that
CVA provides consistent estimators of the transfer function even for stationary fractionally integrated processes, if the order of the system tends to infinity as a function of the sample size at a sufficient rate.
In the I(1) case [
20] introduce a heuristic adaptation of the algorithm using the assumption of known cointegrating rank in order to show consistency for the corresponding transfer function estimators. However, the specification of the cointegrating rank is no easy task in itself. In case of misspecification of the cointegrating rank the properties of this approach are unclear. Ref. [
21] states without proof that also the original
CVA algorithm delivers consistent estimates in the I(1) case without the need to impose the true cointegrating rank.
Furthermore for I(1) processes [
20] proposed various tests for the cointegrating rank and compared them to tests in the Johansen framework showing superior finite sample performance in particular for multivariate data sets with a large dimension of the modeled process.
This paper builds on these results and shows that CVA can also be used in the seasonally integrated case. The main contributions of the paper are:
- (i)
It is shown that the original
CVA algorithm in the seasonally integrated case provides strongly consistent system estimators under the assumption of known system order (thus delivering the currently unpublished proof of the claim in the I(1) case in [
21]).
- (ii)
Upper bounds for the order of convergence for the estimated system matrices are given, establishing the familiar superconsistency for the estimation of the cointegrating spaces at all unit roots.
- (iii)
Several tests for separate (that is for each unit root irrespective of the specification at the other potential unit roots) determination of the seasonal cointegrating ranks are proposed which are based on the estimated systems and are simple to implement.
The derivation of the asymptotic properties of the estimators is complemented by a simulation study and an application, both demonstrating the potential of CVA and one of the suggested tests. Jointly our results imply that CVA constitutes a very reasonable initial estimate for subsequent quasi likelihood maximization in the VARMA case. Moreover the method provides valuable information on the number of unit roots present in the process, which can be used for subsequent investigation at the very least by providing upper bounds on the number of common trends present at each unit root frequency. Contrary to the JS approach in the VAR framework these tests can be performed in parallel for all unit roots, eliminating the interdependence of the results inherent in the VECM representation. Moreover, they do not use the VECM representation involving a large number of parameters in the case of high sampling rates.
These properties make CVA a useful tool in automatic modeling of multivariate (with a substantial number of variables) seasonally (co-)integrated processes.
The paper is organized as follows: in the next section the model set and the main assumptions of the paper are presented. The estimation methods are described in
Section 3.
Section 4 states the consistency results. Inference on the cointegrating ranks is proposed in
Section 5. Data preprocessing is discussed in
Section 6. The simulations are contained in
Section 7, while
Section 8 discusses an application to real world data.
Section 9 concludes the paper.
Appendix A contains supporting material,
Appendix C provides the proofs of the main results of this paper, which are based on preliminary results presented in
Appendix B.
Throughout the paper we will use the symbols and to denote orders of almost sure convergence where T denotes the sample size, i.e., if almost surely and if is bounded almost surely for large enough T (that is there exists a constant such that a.s.). Furthermore, denote the corresponding in probability versions.
2. Model Set and Assumptions
In this paper state space processes
are considered which are defined as the solutions to the following equations for given white noise
:
Here
denotes the unobserved state and
and
define the state space system typically written as the tuple
.
In this paper we consider without restriction of generality only minimal state space systems in innovations representation. For a minimal system the integer
n is called the order of the system. As is well known (cf. e.g., [
22]) minimal systems are only identified up to the choice of the basis of the state space. Two minimal systems
and
are observationally equivalent if and only if there exists a nonsingular matrix
such that
. For two observationally equivalent systems the impulse response sequences
coincide.
Ref. [
15] shows that the structure of the Jordan normal form of the matrix
A determines the properties (such as stationarity) of the solutions to (
1) for
. Eigenvalues of
A on the unit circle lead to unit root processes in the sense of [
15] who also define a
state space unit root structure indicating the location and multiplicity of unit roots. A process
with state space unit root structure
for some even integer
S is called multi frequency I(1) (in short MFI(1)). Even
S is chosen because it simplifies the notation by implying that
also is an integer and
is a seasonal unit root. By adjusting the notation appropriately all results hold true for odd
S as well).
If, moreover, such a process is observed for
S periods per year, it is called
seasonal MFI(1). In this case the canonical form in [
15] takes the following form:
where
denote the unit root frequencies and
where
. Furthermore for
it holds that
and
is of full row rank and positive upper triangular (
), see [
15] for details. Finally
, where
denotes an eigenvalue of the matrix
with maximal modulus. The stable subsystem
is assumed to be in echelon canonical form (see [
22]).
Using this notation the assumptions on the data generating process (dgp) in this paper can be stated as follows:
Assumption 1. has a minimal state space representation of the form (2) with minimal in echelon canonical form where . Furthermore the stability assumption and the strict minimum-phase condition hold.
The state at time is given by where (for and else) is deterministic and is such that is stationary.
The noise process is assumed to be a strictly stationary ergodic martingale difference sequence with respect to the filtration with zero conditional mean , deterministic conditional variance and finite fourth moments.
Due to the block diagonal form of
A the state equations are in a convenient form such that partitioning the state vector accordingly as
the blocks
for
are unit root processes with state space unit root structure
. Finally
is assumed to be stationary due to the assumptions on
. If
denotes a different solution to the state space equations corresponding to
then (for
)
Note that
(for appropriate vectors
),
Therefore the sum can be modeled using a constant and seasonal dummies. The term tends to zero with an exponential rate as and hence does not influence the asymptotics.
Assumption 1 implies that the yearly difference
is a stationary VARMA process where
since
. Thus the process according to Assumption 1 is a unit root process in the sense of [
15]. Note that we do not assume that all unit roots are contained such that the spectral density of the stationary process
may contain zeros due to overdifferentiation and hence the process potentially is not stably invertible. The special form of
implies that
processes are a special case of our dgp while
processes are not allowed for.
3. Canonical Variate Analysis
The main idea of
CVA is that, given the state, the system equations (
1) are linear in the system matrices. Therefore, based on an estimate of the state sequence, the system can be estimated using least squares regression. The estimate of the state is based on the following equation (for details see for example [
17]):
Let
denote the vector of stacked observations for some integer
and let
. Further define
. Then (for
)
where
for
and
. The strict minimum-phase assumption implies
for
.
Let
for sequences
and
. Then an estimate of
is obtained from the reduced rank regression (RRR)
under the rank constraint
. This results in the estimate
of
using the singular value decomposition (SVD)
Here
denotes the unrestricted least squares estimate of
and
Here the symmetric matrix square root is used. The definition is, however, not of importance and other square roots such as Cholesky factors could be used.
denotes the matrix whose columns are the left singular vectors to the
n largest singular values which are the diagonal entries in
and
contains the corresponding right singular vectors as its columns.
denotes the approximation error.
The system estimate is then obtained using the estimated state via regression in the system equations.
In the algorithm a specific decomposition of the rank n matrix into the two factors and is given such that . It is obvious that every other decomposition of produces an estimated state sequence in a different coordinate system, leading to a different observationally equivalent representation of the same transfer function estimator. Therefore, with respect to consistency of the transfer function estimator it is sufficient to show that there exists a factorization of leading to convergent system matrix estimators , even if this factorization cannot be used in actual computations, as it requires information not known at the time of estimation.
In order to generate a consistent initial guess for subsequent quasi likelihood optimization in the set of all state space systems corresponding to processes with state space unit root structure
, however, we will derive a realizable (for known integers
and matrices
such that
) consistent system estimate. To this end note that consistency of the transfer function implies (see for example [
23]) that the eigenvalues
of
converge (in a specific sense) to the eigenvalues
of
. Therefore transforming
into complex Jordan normal form (where
is almost surely diagonalizable), ordering the eigenvalues such that groups of eigenvalues
converging to
are grouped together, we obtain a realizable system
where the diagonal blocks of the block diagonal matrix
corresponding to the unit roots converge to a diagonal matrix with the eigenvalues
on the diagonal:
Replacing
by the limit
and transforming the estimates to the real Jordan normal form, we obtain estimates
corresponding to unit root processes with state space unit root structure
.
Note, however, that this representation not necessarily converges as perturbation analysis only implies convergence of the eigenspaces. Therefore in the final step the estimate
is converted such that we obtain convergence of the system matrix estimates. In the class of observationally equivalent systems with the matrix
block diagonal transformations of the form
do not change the matrix
. Here the basis of the stable subsystem can be chosen such that the corresponding transformed
is uniquely defined using an overlapping echelon form (see [
22], Section 2.6). The impact of such transformations on the blocks of
C is given by
. Therefore, if for each
a matrix
is known such that
is nonsingular, the restriction
picks a unique representative
of the class of systems observationally equivalent to
.
Note that this estimate is realizable if the integers (needed to identify the eigenvalues of closest to ), the matrices (needed to fix a basis for ) and the index corresponding to the overlapping echelon form for the stable part are known. Furthermore, this estimate corresponds to a process with state space unit root structure and hence can be used as a starting value for quasi likelihood maximization.
Finally in this section it should be noted that the estimate of the state here mainly serves the purpose of obtaining an estimator for the state space system. Based on this estimate, Kalman filtering techniques can be used to obtain different estimates of the state sequence. The relation between these different estimates is unclear and so is their usage for inference. For this paper the state estimates are only an intermediate step in the CVA algorithm.
4. Asymptotic Properties of the System Estimators
As follows from the last section, the central step in the
CVA procedure is a RRR problem involving stationary and nonstationary components. The asymptotic properties of the solution to such RRR problems are derived in Theorem 3.2. of [
24]. Using these results the following theorem can be proved (see
Appendix C.1):
Theorem 1. Let the process be generated according to Assumption 1. Let denote theCVAestimators of the system matrices using the assumption of correctly specified order n with not depending on the sample size and finite and for some real for some where . Let be in the form given in (2) where is in echelon canonical form and for each there exists a row selector matrix such that is non-singular. Then for some integer a: - (I)
for each .
- (II)
Using where we have for some integer .
- (III)
If the noise is assumed to be an iid sequence, then results (I) and (II) hold almost surely.
Beside stating consistency in the seasonal integration case, the theorem also improves on the results of [
20] in the I(1) case by showing that no adaptation of
CVA is needed in order to obtain consistent estimators of the impulse response sequence or the system matrices. Note that this consistency result for the impulse response sequence concerns both the short and the long-run dynamics. In particular it implies that short-run prediction coefficients are consistent. Moreover the theorem establishes strong consistency rather than weak consistency as opposed to [
20]. (II) establishes orders of convergence which, however, apply only to a transformed system that requires knowledge of the integers
and matrices
to be realized. No tight bounds for the integer
a are derived, since they do not seem to be of much value.
Note that the assumptions on the innovations rule out conditionally heteroskedastic processes. However, since the proof mostly relies on convergence properties for covariance estimators for stationary processes and continuous mapping theorems for integrated processes, it appears likely that the results can be extended to conditionally heteroskedastic processes as well. For the stationary cases this follows directly from the arguments in [
18], while for integrated processes results (using different assumptions on the innovations) given for example in [
25] can be used. The conditions of [
25] hold for example in a large number of GARCH type processes, see [
26]. The combination of the different sets of assumptions on the innovations is not straightforward, however, and hence would further complicate the proofs. We refrain from including them.
It is worth pointing out that due to the block diagonal structure of
the result
implies consistency of the blocks
corresponding to unit root
(or the corresponding complex pair) of order almost
. Using the complex valued canonical form this implies consistent estimation of
by the corresponding
. In the canonical form this matrix determines the cointegrating relations (both the static as well as the dynamic ones, for details see [
15]) as the unitary complement to this matrix. It thus follows that
CVA delivers estimators for the cointegrating relations at the various unit roots that are (super-)consistent. In fact, the proof can be extended to show convergence in distribution of
. This distribution could be used in order to derive tests for cointegrating relations. However, preliminary simulations indicate that these estimates and hence the corresponding tests are not optimal and can be improved upon by quasi maximum likelihood estimation in the VARMA setting initialized by the
CVA estimates. Therefore we refrain from presenting these results.
Note that the assumptions impose the restriction
excluding VAR systems. This is done solely for stating a uniform lower bound on the increase of
p as a function of
T. This bound is related to the lag length selection achieved using BIC, see [
27]. In the VAR case the lag length estimator using BIC will converge to the true order and thus remain finite. All results hold true if in the VAR case a fixed (that is independent of the sample size)
is used.
5. Inference Based on the Subspace Estimators
Beside consistency of the impulse response sequence also the specification of the integers
is of interest. First, following [
20] this information can be obtained by detecting the unity singular values in the RRR step of the procedure. Second, from the system representation (
2) it is clear that the location of the unit roots is determined by the eigenvalues of
on the unit circle: The integers
denote the number of eigenvalues at the corresponding locations on the unit circle (provided the eigenvalues are simple). Due to perturbation theory (see for example Lemma A2) we know that the eigenvalues of
will converge (for
) to the eigenvalues of
and the distribution of the mean of all eigenvalues of
converging to an eigenvalue of
can be derived based on the distribution of the estimation error
. This can be used to derive tests on the number of eigenvalues at a particular location on the unit circle. Third, if
the state process is a VAR(1) process and hence in some cases allows for inference on the number of cointegrating relations and thus also on the integers
as outlined in [
4]. Tests based on these three arguments will be discussed below.
Theorem 2. Under the assumptions of Theorem 1 the test statistic converges in distribution to the random variablewhere (for definition of and see the proof in Appendix C.2) and where denotes a c-dimensional Brownian motion with variancewith denoting the heading submatrix of and denoting the submatrix of composed of the first c rows such that denotes the unstable subsystem. The theorem is proved in
Appendix C.2, where also the many nuisance parameters of the limiting random variable are explained and defined. The proof also corrects an error in Theorem 4 of [
20], where the wrong distribution is given since the second order terms were neglected.
As the distribution is not pivotal and in particular contains information that is unknown when performing the RRR step, it is not of much interest for direct application. Nevertheless the order of convergence allows for the derivation of simple consistent estimators of the number of common trends: Let
denote the number of singular values calculated in the RRR that exceed
for arbitrary
for
. Then it is a direct consequence of Theorem 2 in combination with
, that
in probability, implying consistent estimation of
c. Based on these results also estimators for
c could be derived, for example along the lines of [
28]. However, as [
29] shows, such estimators have not performed well in simulations and thus are not considered subsequently.
The singular values do not provide information on the location of the unit roots. This additional information is contained in the eigenvalues of the matrix :
Theorem 3. Under the assumptions of Theorem 1 let denote the eigenvalues of closest to the unit root . Then defining we obtainwhere denotes a -dimensional Brownian motion with zero expectation and variance for and a complex Brownian motion with expectation zero and variance equal to the identity matrix else. Further if using the true state and where denote the eigenvalues of closest to , then
Therefore the estimated eigenvalues can be used in order to obtain a test on the number of common trends at a particular frequency for each frequency separately. The test distribution is obtained as the limit to
where
. The distribution thus does not depend on the presence of other unit roots or stationary components of the state. Furthermore it can be seen that it is independent of the noise variance or the matrix
. Hence critical values are easily obtained from simulations. Also note that the limiting distribution is identical for all complex unit roots.
Therefore, for each seasonal unit root location we can order the eigenvalues of the estimated matrix with increasing distance to . Then starting from the assumption of (for a reasonable obtained, e.g., from a plot of the eigenvalues) one can perform the test with statistic . If the test rejects, then the hypothesis is tested, until the hypothesis is not rejected anymore, or is reached. This is then the last test. If is rejected again, no unit root is found at this location. Otherwise we do not have evidence against . In any case, the system needs to be estimated only once and the calculation of the test statistics is easy even for all seasonal unit roots jointly.
The third option for obtaining tests is to use the tests derived in [
4] based on the JS framework for VARs. In the case
the state process
is a seasonally integrated VAR(1) process (for
the noise variance is singular). The corresponding VECM representation equals
where
and
Note that in this VAR(1) setting no additional stationary regressors of the form
occur. Also no seasonal dummies are needed but could be added to the equation. In this setting [
4] suggests to use the eigenvalues
(ordered with increasing modulus) of the matrix (the superscript
denotes the residuals with respect to the remaining regressors
)
as the basis for a test statistic
where
for complex unit roots and
for real unit roots. In the
case this leads to the familiar Johansen trace test, for seasonal unit roots a different asymptotic distribution is obtained.
Theorem 4. Under the assumptions of Theorem 1 let be calculated based on the estimated state and let denote the same statistic based on the true state. Then for it holds that andwhere is a real Brownian motion for or a complex Brownian motion else. Thus again under the null hypothesis the test statistic based on the estimated state and the one based on the true state reject jointly asymptotically with probability one. Therefore for the tests of JS can be used to obtain information on the number of common cycles, ignoring the fact that the estimated state is used in place of the true state process.
After presenting three disjoint ideas for providing information on the number and location of unit roots, the question arises, which one to use in practice. In the following a number of ideas are given in this respect.
The criterion based on the singular values given in Theorem 2 is of limited information as it only provides the overall number of unit roots. Since the limiting distribution is not pivotal it cannot be used for tests and the choice of the cutoff value is somewhat arbitrary. Nevertheless, using a relatively large value one obtains a useful upper bound on c which can be included in the typical sequential procedures for tests for .
Using the results of Theorem 4 has the advantage of using a framework that is well known to many researchers. It is remarkable that in terms of the asymptotic distributions there is no difference involved in using the estimated state in place of the true state. The assumption , however, is somewhat restrictive except in situations with a large s.
Finally the results of Theorem 3 provide simple to use tests for all unit roots, independently of the specification of the model for the remaining unit roots. Again it is remarkable that, under the null, inference is identical for known and for estimated state.
Since our estimators are not quasi maximum likelihood estimators the question of a comparison with the usual likelihood ratio tests arises. For VAR models simulation exercises documented in
Section 7 below demonstrate that there are situations where the proposed tests outperform tests in the VAR framework. Comparisons with tests in the state space framework (or equivalently in the VARMA framework) are complicated by the fact that no results are currently available in the literature of this framework. One difference, however, is given by the fact that quasi likelihood ratio tests in the VARMA setting require a full specification of the
values for all unit roots. This introduces interdependencies such that the tests for one unit root depend on the specification of the cointegrating rank at the other roots. The interdependencies can be broken by performing tests based on alternative specifications for each unit root. The test based on Theorem 3 does not require this but can be performed based on the same estimate
. This is seen as an advantage.
The question of the comparison of the empirical size in finite samples as well as power to local alternatives between the CVA based tests and tests based on quasi-likelihood ratios is left as a research question.
7. Simulations
The estimation of the seasonal cointegration ranks and spaces is usually carried out via quasi maximum likelihood methods that originated from the VAR model class. Typical estimators in this setting are those of [
2,
4,
5,
31]. In the first two experiments we focus on the estimation of the cointegrating spaces and the specification of the cointegration ranks in the classical situation of quarterly data and show that there are certain situations in which
CVA estimators and the test in Theorem 3 possess finite sample properties superior to those of the methods above. In a third experiment the test performance is evaluated for a daily sampling rate. Moreover, the prediction accuracy of
CVA is investigated as well as its robustness to innovations exhibiting behaviors often encountered at such higher sampling rates. All simulations are carried out using 1000 replications.
To investigate the practical usefulness of the proposed procedures we generate quarterly data using two VAR dgps of dimension
first and then two more general VARMA dgps with
. Each pair contains dgps with different state space unit root structures
From all four dgps samples of size
are generated with initial values set to zero. Although none of the dgps contains deterministics, the data is adjusted for a constant and quarterly seasonal dummies as in [
5]. For reasons of comparability, the adjustment for deterministic terms is done before estimation.
In the third experiment we generate daily data with dimension from a state space system including unit roots corresponding to weekly frequencies (that is a period length of seven days). In the simulations we use several years of data (excluding new year’s day to account for 52 weeks of seven days each). The first 200 observations are discarded to include the effects of different starting values. In this example the focus lies on a comparison of the prediction accuracy. Furthermore we investigate the robustness of the test procedures to conditional heteroskedasticity of the GARCH type as well as to non-normality of the innovations.
To assess the performance of specifying the cointegrating rank at unit root
z using
CVA, the following test statistic is constructed from the results in Theorem 3
Here
are the eigenvalues of
ordered increasingly according to the distance from
z. Note that a similar test in [
20] only uses the
c-th largest eigenvalue, whereas here the average over the nearest
c eigenvalues is taken. Critical values have been obtained by simulation using large sample sizes (sample size 2000 (JS) and 5000 (
CVA), 10,000 replications).
In our first two experiments usage of
is compared with variants of the likelihood ratio test from [
2] (JS), [
4] (
), and [
5] (
,
).
is Cubadda’s trace test for complex-valued data,
takes the information at frequency
into account when the analysis is carried out at frequency
, and
iterates between
and
in the alternating reduced rank regression (ARR) of [
5]. For the procedure of [
2] the likelihood maximization at frequency
is carried out using numerical optimization (BFGS) with initial values obtained from an unrestricted regression.
All tests are evaluated by comparing the percentages of correctly detected common trends, or hit rates, with , the hit rate to be expected from a nominal significance level of . The testing procedure employed for all tests is the same: at each of the frequencies it is started from a null hypothesis of s unit roots against less than s unit roots. In case of rejection, unit roots are tested versus less than and so on, until there are zero unit roots under the alternative.
For the first two experiments the estimation performance of
CVA for the simultaneous estimation of the seasonal cointegrating spaces is compared with the maximum likelihood estimates of [
2,
4,
31] (cRRR), and also with an iterative procedure (Generalized ARR or GARR) of [
5]. The comparison is carried out by means of the gap metric, measuring the distance between the true and the estimated cointegrating space as in [
32]. The smaller the mean gap over all replications, the better is the estimation performance. Throughout a difference between two mean gaps or two hit rates is considered statistically significant if it is larger than twice the Monte Carlo standard error.
For all procedures used in this section, an AR lag length has to be chosen first. For
CVA this can be done using the AIC as in ([
33],
Section 5), as is done in the third experiment.
In the first two experiments where sample sizes are rather small, we estimate the lag length via minimization of the corrected AIC (AICc) ([
34], p. 432),
, benefitting the simulation results. For larger sample sizes the two criteria lead to the same choices. Due to the quarterly data we work with, the lag length is then chosen to be
.
Other information criteria could be chosen here. An anonymous referee also suggested the application of the Modified Akaike Information Criterion (MAIC) of [
35], proposed there for the I(1)-case. In an attempt to apply it to the seasonally integrated case considered here, it performed considerably worse than the AICc. Thus we refrain from using the MAIC in the following and also omit the results of that attempt. They can be obtained from the authors upon request.
For
CVA the truncation indices
f and
p are chosen as
([
33], Section 5). The system order
n is estimated by minimizing ([
33], Section 5)
Here
denotes the
i-th largest singular value from the singular value decomposition of
(Step 2 of
CVA). Note that selecting the number of states by
is made less influential insofar as
, where
denotes the SVC estimated system order.
In
Section 7.1 we start with the two VAR dgps and find that the likelihood-based procedures are mostly superior. Continuing with the VARMA dgps in
Section 7.2,
CVA performs better and is superior for the smaller sample sizes in terms of size and gap and better for all sample sizes in terms of power.
Section 7.3 evaluates the performance of the tests for unit roots for larger sample sizes together with the prediction performance in this setting. We find that the tests are robust to the distribution of the innovations as well as to conditional heteroskedasticity of the GARCH type. Furthermore the empirical size of the tests lies close to the size already for moderate sample sizes, where the tests also show almost perfect power properties.
7.1. VAR Processes
The VAR dgps considered in this paper are given by,
where
is white noise and the coefficient matrices are
This dgp is adopted from [
5] with a slight adjustment to
. The corresponding VECM representation in the notation of [
5] equals
As can be seen from
Table 1, the dgps possess unit roots at frequencies 0,
, and
, where
for
, respectively. Note that in all cases the order of integration equals 1, while the number of common cycles at
is varied.
Table 2 exhibits the hit rates from the application of the different test statistics. At frequencies 0 and
,
is compared with the trace test of Johansen (J; based on [
31] for unit roots
), whereas at
it is competing with JS,
, and
. All competitors are likelihood-based tests which is the term we are referring to when we compare
to them as a whole.
The results for 0 and are very similar for both dgps in that scores more hits than the likelihood-based tests when the sample size is small, . Convergence of its finite sample distribution is slower than for the other test statistics, however, as J is closer to from on. For the distribution of only seems to have converged to its asymptotic distribution when at frequency 0, whereas convergence of the likelihood-based tests has occurred in all cases.
At
the likelihood ratio test of JS strictly dominates all implementations of [
5] for all sample sizes and both dgps. It strictly dominates the
CVA-based test procedure as well, except for one case, it seems: when
and
scores slightly, but significantly, more hits than the likelihood ratio test of JS. Surprisingly,
is drastically worse when
with only
, only to be up at
for
.
The behavior of
is explained by
and
being close to
when
, cf.
Table 1. For future reference we will call the corresponding roots
false unit roots.
For
the estimates of eigenvalues corresponding to actual unit roots are rather not very close to
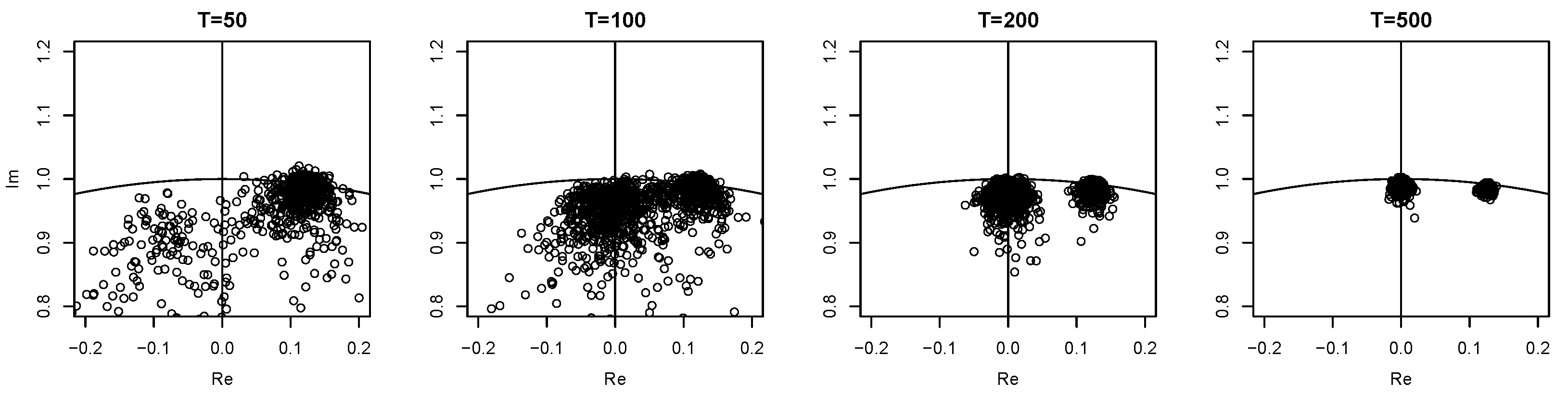
in contrast to the false unit roots. Thus the latter are mistaken for actual unit roots (cf. the first panel in
Figure 1), leading to a hit rate of
, one that is even larger than the rates at 0 and
. As the sample size increases, the eigenvalue estimates of the true unit roots become more and more accurate, visible from the second and third panel in
Figure 1. Accordingly they can be detected correctly more often. Unfortunately however, for
the false unit roots remain to be detected such that often two instead of just one unit root are found by
, resulting in a hit rate of only
. For
is able to distinguish the false unit roots from the true ones and the detection rate is getting closer to the asymptotic rate,
and
, respectively.
When the VAR dgp without false unit roots and
is considered, it is visible that the hit rates of
at
are monotonously increasing in the sample size again. The rates are smaller than those of the likelihood-based tests, however, and also clearly worse than those of
at 0 and
, cf.
Table 2 again.
Taken together, at frequencies 0 and which correspond to real-valued unit roots, the use of was advantageous for . It also scored more hits for and . For higher sample sizes the likelihood-based tests clearly dominate at these two frequencies. At this superiority of the likelihood-based tests for all sample sizes and both dgps continues. The example also points to a general weakness: if the sample size is low and false unit roots are present, it can be difficult for to distinguish them from actual unit roots.
7.2. VARMA Processes
The second setup consists of VARMA data generated by a state space system
, as in (
1), where the matrices
and
are constructed as in (
2) and are taken to be
These two choices yield the same state space unit root structures as those of the two VAR dgps with
and
for
and
, respectively. The other two system matrices
and
with
are drawn randomly from a standard normal distribution in each replication and
is multivariate normal white noise with an identity covariance matrix.
Note that these systems are within the VARMA model class such that the dgp is contained in the VAR setting only by increasing the lag length as a function of the sample size. While superiority of the CVA approach in such a setting might be expected, this is far from obvious. Moreover, using a long VAR approximation is the industry norm in such situations.
From the hit rates in
Table 3 it can be seen that the combination of large
s, small
T, and a minimal lag length of four render the likelihood-based tests useless at all frequencies with hit rates below ten percent for
.
in contrast does not suffer from this problem and is already close to
for this sample size. Only when
do the likelihood-based tests appear to work, exhibiting hit rates close to
.
For all tests alike, however, it is striking that hit rates move away from
when
. This behavior is most pronounced for
, e.g., from
to
its hit rate drops from
to
at 0 when
is used. This phenomenon is a consequence of the fact that
f and
k in the algorithm are chosen data dependent. An inspection of how the hit rates depend on
f and
k and a comparison with the actually selected
reveals that for
too large values of
f and
k are chosen too often and leave room for improvement in the hit rates, cf.
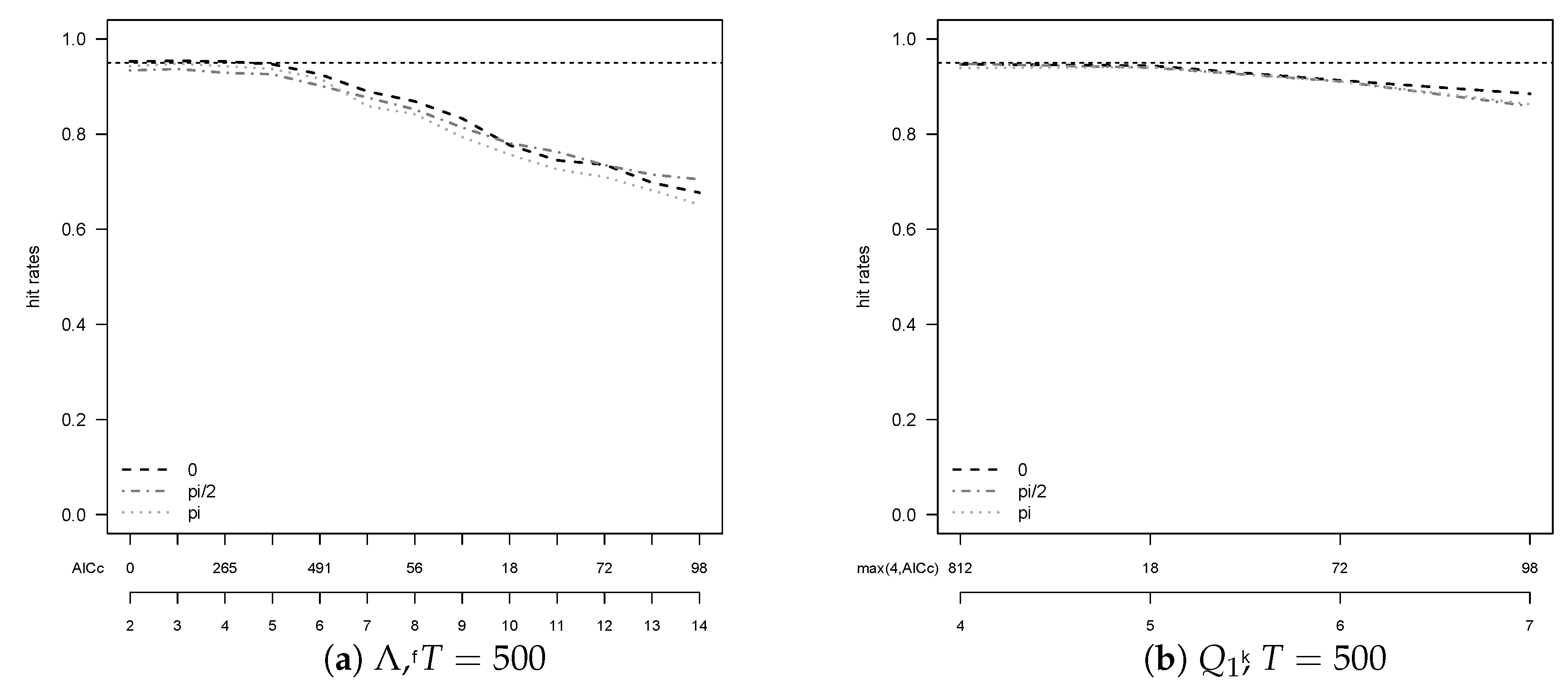
Figure 2. The figure stresses an important point: The performance of the unit root tests is heavily influenced by the selected lag lengths for all procedures. We tested a number of different information criteria in this respect.
AICc turned out to be the best criterion overall, but not uniformly.
Figure 2 indicates advantages for this example of
BIC over
AIC as it on average selects smaller lag lengths, associated here with higher hit rates.
To study the power of the different procedures, the transition dynamics
in (
9) are multiplied by
so that the systems do not contain unit roots at any of the frequencies. Here empirical power is defined as the frequency of choosing zero common trends. This is why for
, when there are in fact common trends present in our specifications, the empirical power values plotted in
Figure 3 are not equal to the actual size we could define as one minus the hit rate: our measure of empirical power in this situation only counts the false test conclusion of zero common trends, but there are of course multiple ways the testing procedure could conclude falsely.
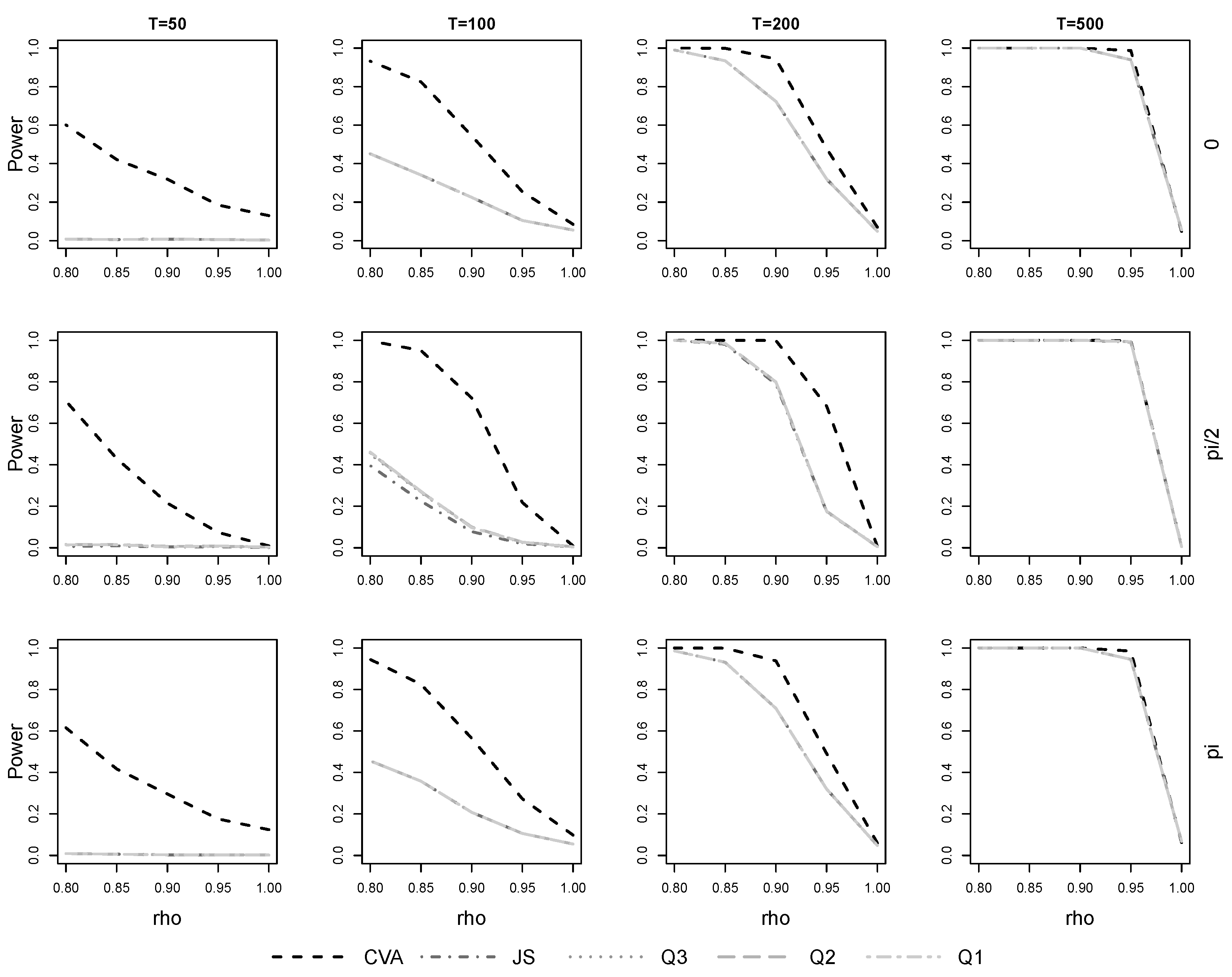
As expected, rejection of the null hypothesis is easiest when
is small and is very difficult when it is close to 1, cf.
Figure 3 for the case of
.
Further, there are almost no differences among the likelihood-based tests over all combinations of sample size and frequency, only for is JS significantly worse than the at . It is also clearly visible at all frequencies that the likelihood-based tests possess no or only very limited power when and , respectively. , in contrast, is clearly more powerful in these cases. As the sample size increases to , the power of each test improves, still remains the most powerful option. Only for have the differences almost vanished with small, but significant, advantages for at 0 and .
The results are the same when is used and and all of the differences described here are statistically significant.
Next the estimation performance of
CVA is evaluated by calculation of the gaps between the true and the estimated cointegrating spaces. At all frequencies these gaps are compared with the GARR procedure of [
5] which cycles through frequencies. At
CVA and GARR are also compared with our implementation of JS and cRRR of [
4], whereas it is also compared with the usual Johansen procedure at 0 and
. All estimates are conditional on the true state space unit root structure in the sense that the minimal number of states used is larger or equal to the number of unit roots over all frequencies. Other than imposing a minimum state dimension, the estimation of the order using
is not influenced. The likelihood-based procedures, on the other hand, take the unit root structure as given, i.e., do not perform CI rank testing for this estimation exercise.
From the results in
Table 4 it can be noted first that the likelihood-based procedures show mostly equal mean gaps. Only for
and
and both dgps does JS possess significantly larger gaps than cRRR and GARR and other differences are not statistically significant. Thus it does not matter in our example whether the iterative procedure is used or not.
Second, CVA is again superior for where it exhibits mean gaps that are significantly smaller than those of the other estimators at all frequencies. This advantage is turned around for higher sample sizes, though: mean gaps are smaller for the likelihood-based procedures when and is used, if only slightly. When is used instead, mean gaps do not differ significantly from each other at when and at when and those of CVA are only very modestly worse when at .
Thus, when it comes to estimating the cointegrating spaces, CVA is superior for and equally good or only slightly worse than the likelihood-based procedures for higher sample sizes. For the systems analyzed, decreasing leads to gaps that are smaller for all methods and these improvements are slightly larger for CVA than for the other estimators.
7.3. Robustness of Unit Root Tests for Daily Data
In this last simulation example we examine the robustness of the proposed procedures with regard to test performance and prediction accuracy with respect to the innovation distribution and the existence of conditional heteroskedasticity of the GARCH-type, as these features are often observed in data of higher frequency, for example in financial applications. While our asymptotic results do not depend on the distribution of the innovations (subject to the assumptions), the assumptions do not include GARCH effects. Nevertheless, the theory in [
25,
26] suggests that the tests might be robust also in this respect.
We generate a state space system of order
using the matrix
where
and
else. This implies that the eigenvalues of this matrix are
. Therefore the corresponding process has state space unit root structure
The entries of the matrices
C and
K are chosen as independent standard normally distributed random variables as before.
A process is generated from filtering an independent identically distributed innovation process through the system . The first 200 observations are discarded, the last are used for validation purposes. A total of 1000 replications are generated where in each replication a different system is chosen.
With the generated data three different estimates are obtained: An autoregressive model (called AR in the following) is estimated with lag length chosen using AIC of maximal lag length equal to . Second, an autoregressive model with large lag length (called ARlong) is estimated. This estimate is used to hint at the behavior of an autoregression using the lag length equal to a full year. This would correspond to estimating a VECM without rank restrictions, when accounting for yearly differences. The third method consists of the CVA estimates, where is chosen. The order is estimated by minimizing SVC. However, we correct for orders smaller than which would limit the possibilities of finding all unit roots.
First, we compare the prediction accuracy for the three methods for two different distributions of the innovations: Beside the standard normal distribution also the student t-distribution with degrees of freedom (scaled to unit variance) is used. This distribution shows considerably heavier tails than the normal distribution but nevertheless is covered by our assumptions.
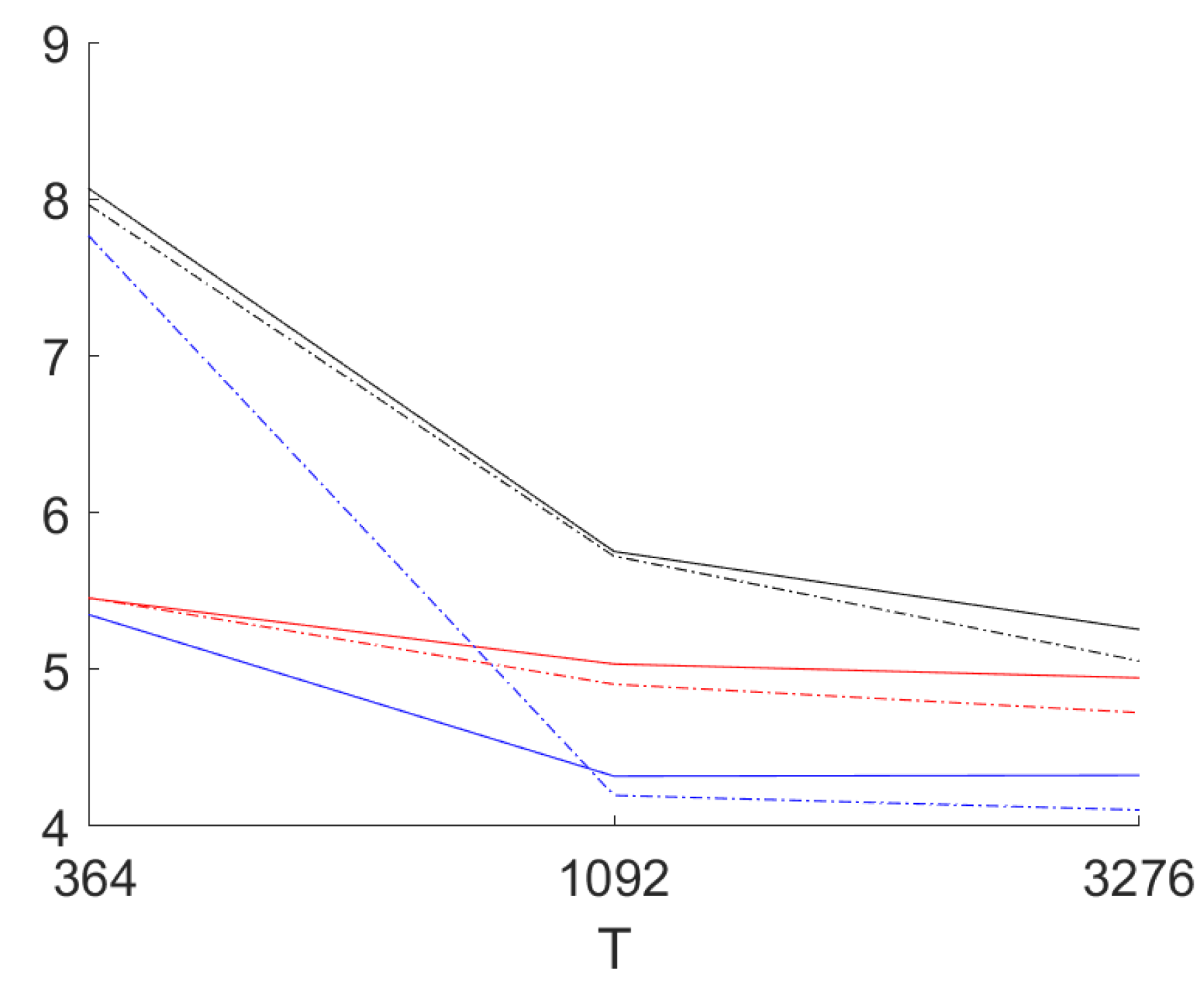
Figure 4 provides the results for out-of-sample one day ahead mean absolute prediction error (over all coordinates) for the sample sizes
days (one year),
(3 years) and
(nine years). The long AR model is estimated with lag lengths of 8 weeks for the smallest sample size, 10 weeks for the medium sample size and 12 weeks for the largest sample size.
In the figure the results for the normally distributed innovations are presented as well as the ones for the t-distributed residuals (scaled to unit variance). It can be seen that for the two larger sample sizes the mean absolute error for the residuals for CVA is smaller in all cases. For the smallest sample size, by contrast, results are mixed. For CVA the results for the heavy tailed distribution in this case are much worse than for the normal distribution. For the larger sample sizes the differences are small. The maximal standard error of the estimated means over 1000 replications for and amounts to 0.05. This allows the conclusion that CVA performs better for the two larger sample sizes. For there are no statistically significant differences between the performance of the three methods: CVA seems to suffer more from few very large errors (using the root mean square errors the CVA results are worse for in comparison; if one uses the 95% percentiles CVA performs best also for the smallest sample size). This results in a standard error over the replications of the mean absolute error for of 0.18 for normally distributed innovations and 3.4 for t-distributed innovations. The long AR models are clearly worse than the two other approaches. This happens even if we are still far from using a full year as the lag length.
With regard to the unit root tests we investigate results for the tests of the hypotheses versus at all frequencies . The data generating process features unit roots with at the seven frequencies . Therefore the tests should not reject at these frequencies, but should reject at all others.
Consequently we compare the minimum of the non-rejection rates for the seven unit roots (called empirical size below) as well as the maximum of the non-rejection rates for the non-unit root frequencies (called empirical power below).
For the larger sample sizes the empirical size is practically 95% while the empirical power is 100%. For we obtain an empirical size of 90% for the normal distribution and 91.5% for the t-distribution. The worst empirical power equals 89.3% (normal) and 87.6% (t-distribution). Hence even for one year of data the discrimination properties of the unit root tests are good and we do not observe differences between the normal distribution for the innovations and the heavy tailed t-distribution.
Finally we compare the empirical size and power of the tests for the various unit roots for smaller sample sizes . For the experiments we consider univariate GARCH models of the form
where
is independent and identically standard normally distributed.
are reals. It follows that the component processes
show conditional heteroskedasticity, the persistence of which is governed by
. Here
implies stationarity while
implies persistent conditional heteroskedasticity usually termed I-GARCH. We include five different processes for the innovations:
For the five different sample sizes 1000 replications of the estimates using the CVA algorithm are obtained. For each estimate we calculate the test statistic for testing versus for corresponding to the unit roots . This set of unit roots contains all seven unit roots .
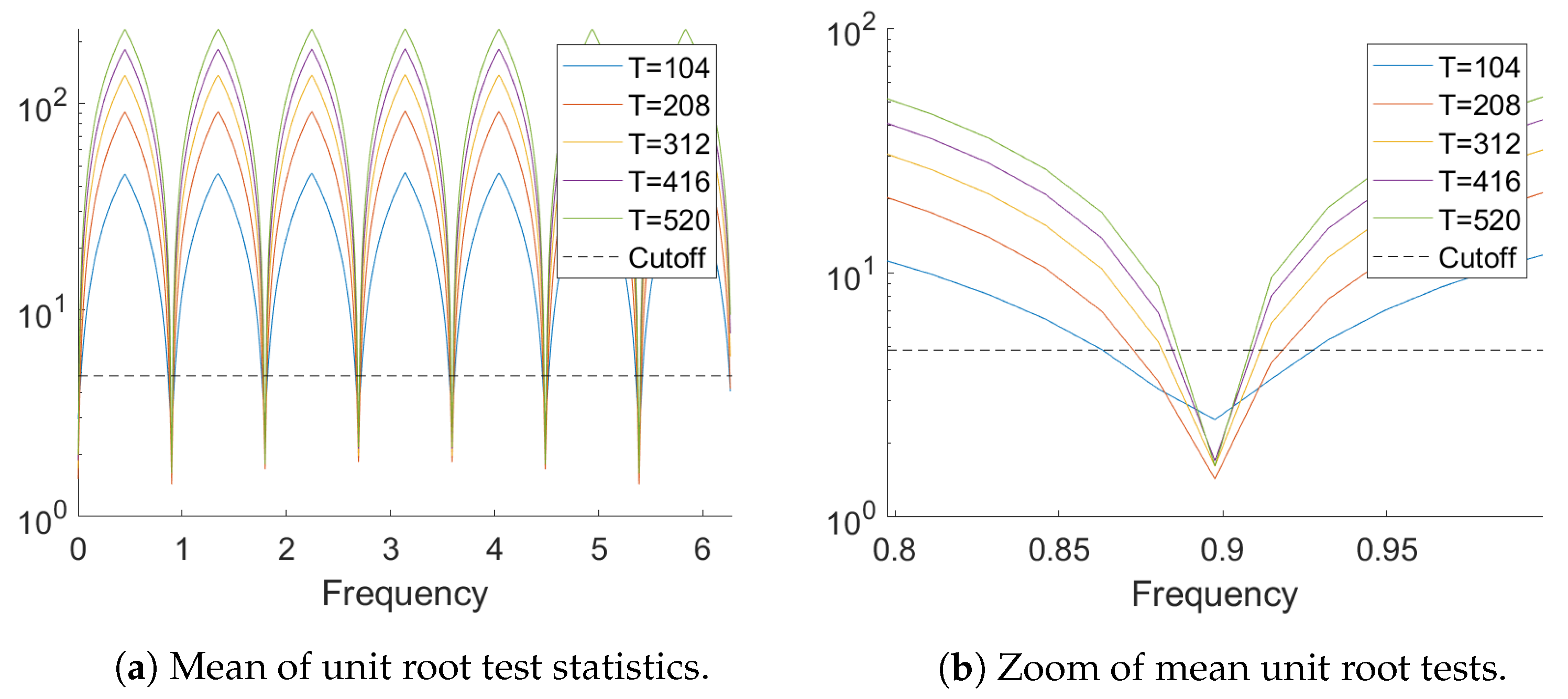
Figure 5 provides the mean over the 1000 replications of the test statistics
for
and the five sample sizes. It can be seen that the test
is able to pinpoint the seven unit roots present in the data generating process fairly accurately even for sample size
. The zoom on the region around the unit root frequency
shows that the mean value is larger than the cutoff value of the test (the dashed horizontal line) for the adjacent frequency
already for
.
Table 5 lists the minimum of the achieved percentages of non-rejections of the test statistic for the seven unit root frequencies as well as the maximum over all non-unit root frequencies. It can be seen that for all GARCH models for
the test rejects unit roots at all non unit root frequencies every time, while the empirical size is close to the nominal 5%. For small sample sizes the tests are slightly undersized while for
a slight oversizing is observed. The two larger sample sizes are omitted as the tests perform perfectly there.
It follows from the examples presented in this subsection that the test is robust also in small samples with respect to heavy tailed distributions of the innovations (subject to the assumptions). Furthermore also a remarkable robustness with respect to GARCH-type conditional heteroskedasticity is observed.
8. Application
In this section we apply
CVA to the modeling of electricity consumption using a data set from [
36]. The dataset contains hourly consumption data (in megawatts) from a number of US regions, scraped from the webpage of PJM Interconnection LLC, a regional transmission organization. The number of regions have changed over time, thus the data set contains many missing values. It also contains data aggregated into regions called east and west, which are not used subsequently.
In order to avoid problems with missing values, we restrict the analysis to four regions, for which data over the same time period is available: American Electric Power (AEP; in the following printed in blue), the Dayton Power and Light Company (DAYTON; black), Dominion Virginia Power (DOM; red) and Duquesne Light Co. (DUQ; green). We use data from 1 May 2005 until 31 July 2018. In this period only 3 data points are missing for the four regions and their imputation is handled by interpolation of the corresponding previous values. One observation in this sample is an obvious outlier which is corrected for analogously.
The data is split into an estimation sample covering observations up to the end of 2016 (102,291 observations on 4263 days) and a validation sample containing data in 2017 and 2018 (13,845 observations on 577 days). Data is equally sampled, but contains two hour segments when switching from winter to summer time or back.
Table 6 contains some summary statistics.
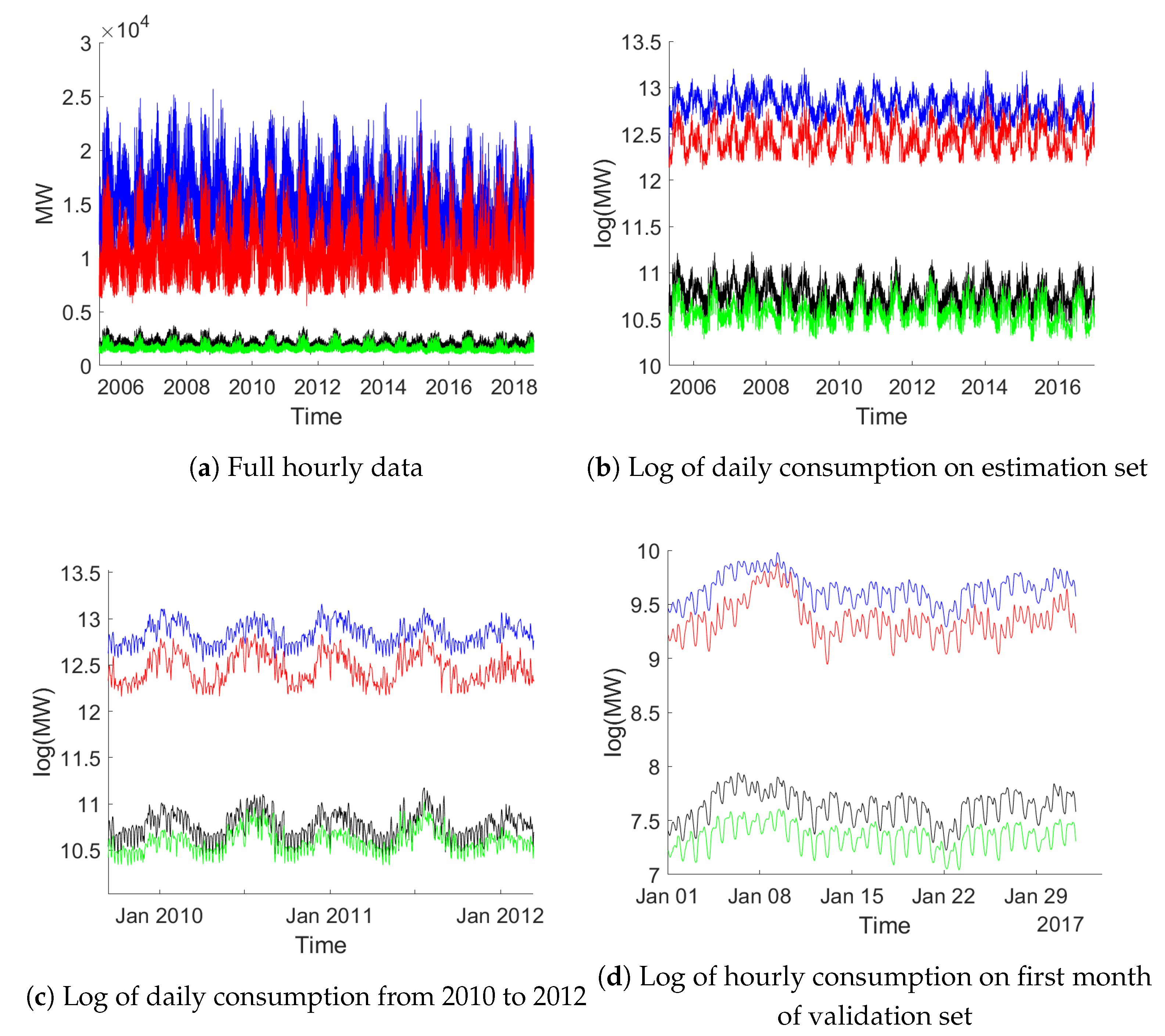
Figure 6 provides an overview of the data: Panel (a) shows the full data on an hourly basis, while (b) presents aggregation to daily frequency. Panel (c) zooms in on a two year stretch of daily consumption. Panel (d) finally provides hourly data for the first month in the validation data. The figures clearly document strong daily, weekly and yearly patterns. From these figures it appears that these seasonal fluctuations are somewhat regular with changes throughout time. It is hence not clear whether a fixed seasonal pattern is appropriate. Also note that the sampling frequency is on an hourly basis such that a year roughly covers 8760 observations.
In the following we estimate (on the estimation part) and compare (on the validation part) a number of different models, first for the full hourly data set and afterwards for the aggregated daily data. As a benchmark we will use univariate AR models including deterministic seasonal patterns for daily, weekly and yearly variations. Subsequently we estimate models using CVA including different sets of such seasonal patterns.
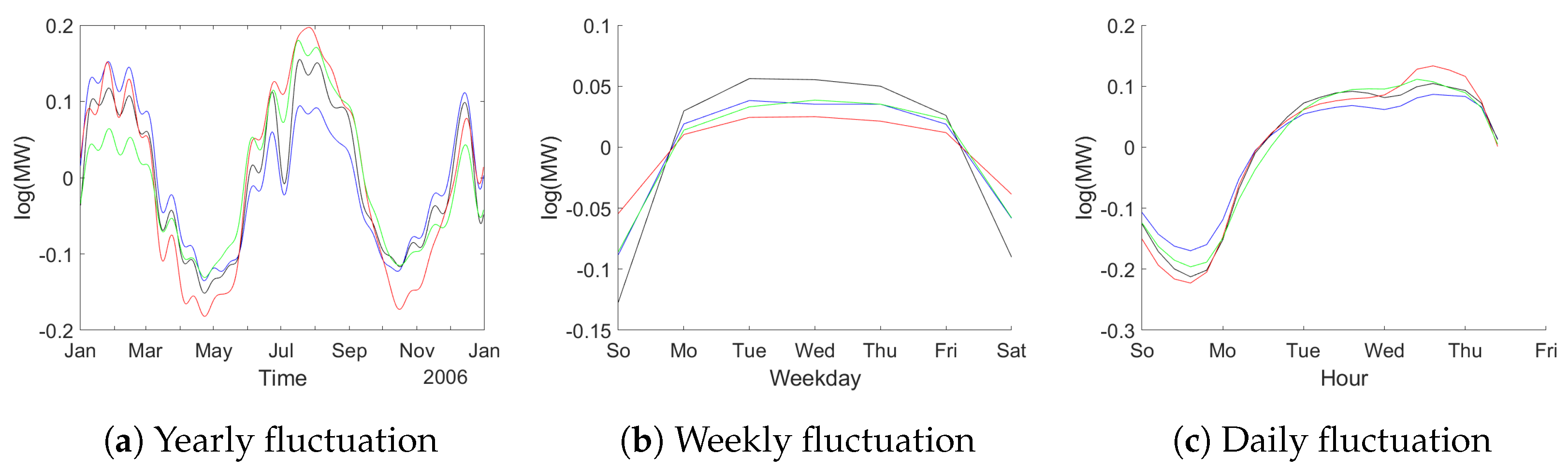
First in the analysis using dummy variables fixed periodic patterns have been estimated. We model the natural logarithm of consumption (to reduce problems due to heteroskedasticity) and include dummies for weekdays, hours and sine and cosine terms corresponding to the first 20 Fourier frequencies with respect to annual periodicity. The corresponding results can be viewed in
Figure 7. It is obvious that there is quite some periodic variation. Also the four data sets show very similar patterns as expected.
After the extraction of these deterministic terms the next step is univariate autoregressive (AR) modeling.
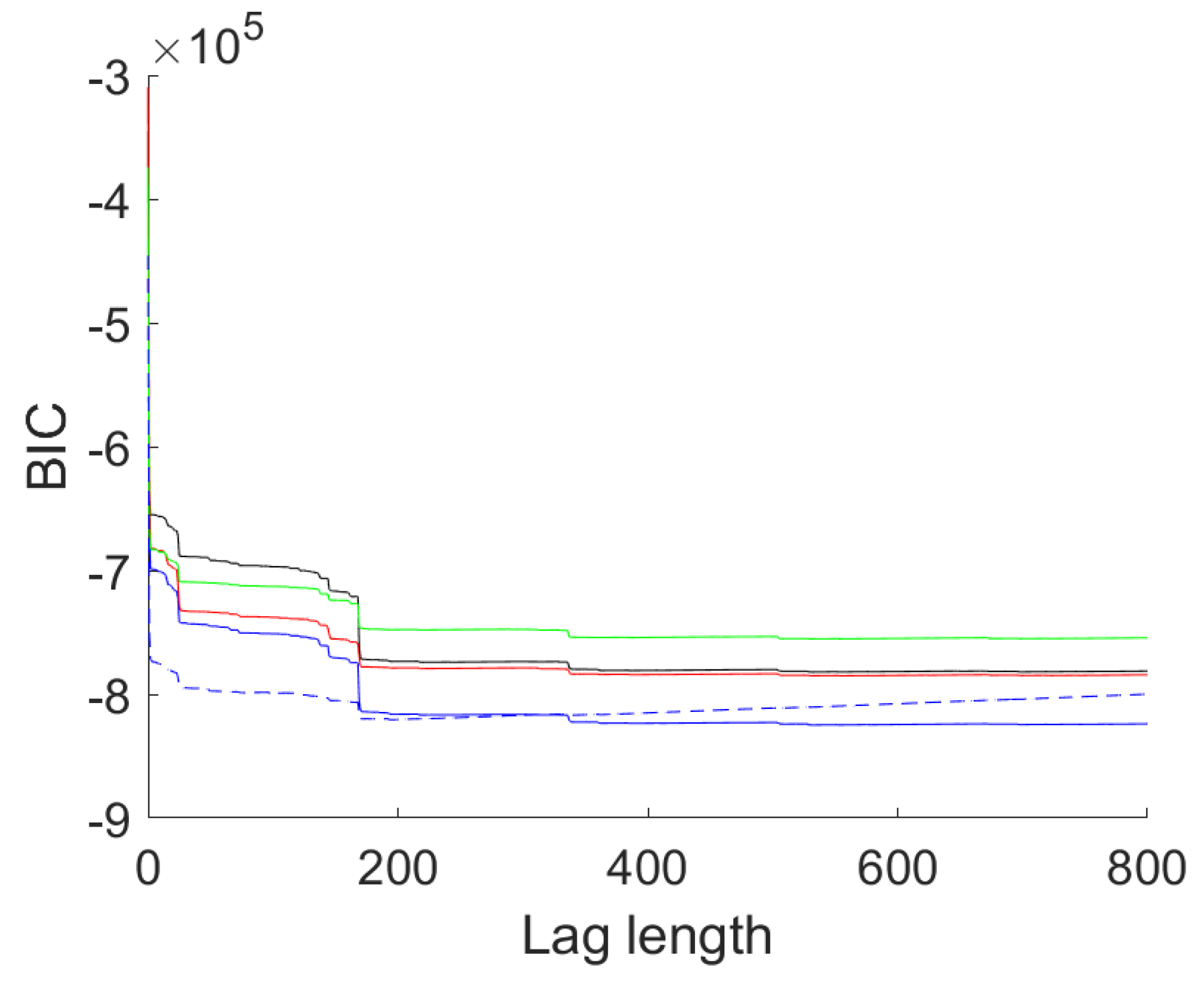
Figure 8 shows the BIC values of AR models of lag lengths zero to 800 for the four series as well as the BIC of a multivariate AR model for the same number of lags. The chosen values are given in
Table 6.
The BIC curve is extremely flat for the univariate models. Noticeable drops in BIC occur around lag 24 (one day), 144 (six days), 168 (one week), 336 (two weeks), 504 (three weeks). BIC selects large lag lengths from 529 (DUQ) up to 554 (DOM). AIC selects lag lengths close to the maximum allowed with a minimum at 772 lags. The BIC pattern of the multivariate model differs in that the two drops at two and three weeks are missing. Instead, the optimal BIC value is obtained at lag 194, well below the optimal lag lengths in the univariate cases. AIC here opts for lag length 531, just over 22 days.
Subsequently CVA is applied with as estimated for the multivariate model. This differs from the usual recommendation of in order to avoid numerical problems with huge matrices. The order is chosen according to SVC, resulting in . The corresponding model is termed Mod 1 in the following. Note that this configuration of does not fulfill the requirements of our asymptotic theory. The bound ensures that the matrix has full column rank. Generically this will be the case for leading to a less restrictive assumption. In practice too low values of f will be detected by estimated close to the maximum, which is not the case here.
As a second model we only use weekday dummies but neglect the other deterministics. Again AIC () and BIC () are used to determine the optimal lag length in the multivariate AR model. The corresponding CVA estimated model uses according to SVC, resulting in Mod 2.
The third model uses only a constant as deterministic term. Again similar AIC (555) and BIC (195) values are selected. A state space model, Mod 3, using CVA is estimated with .
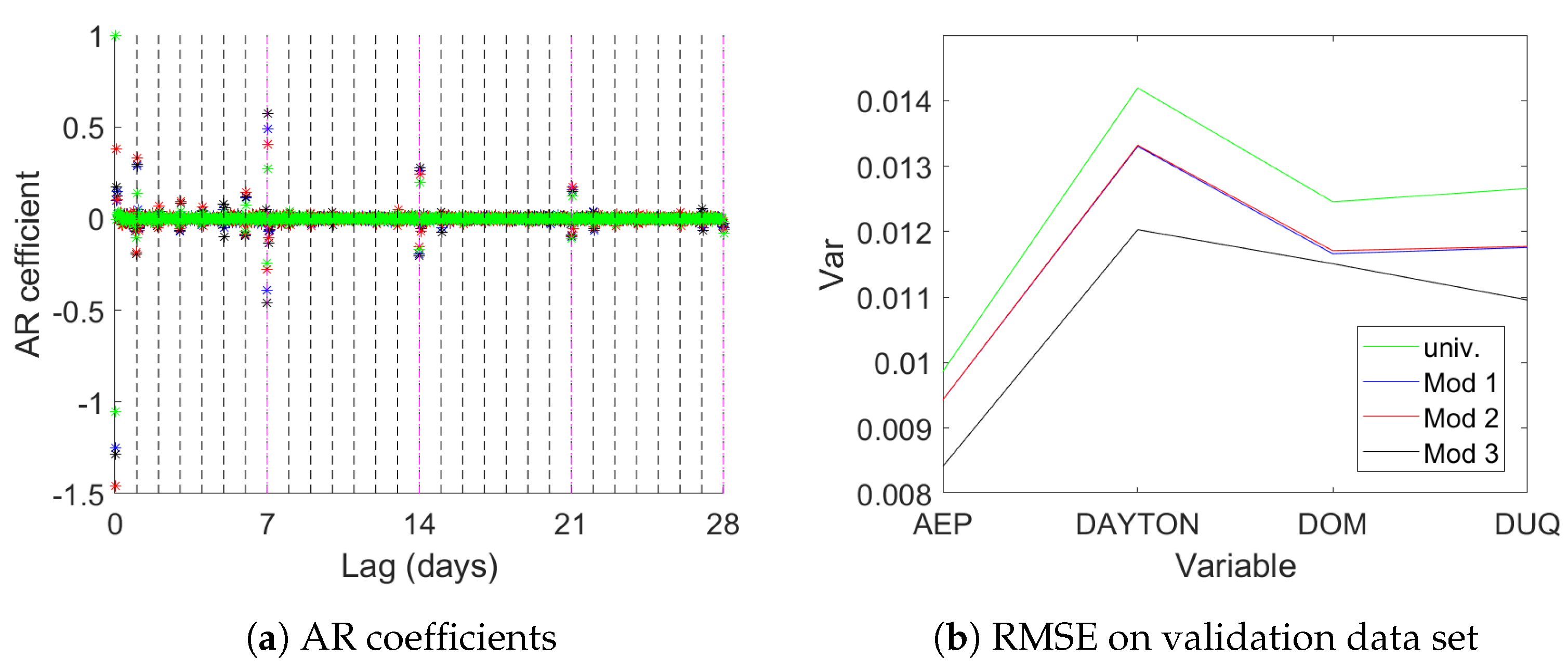
Figure 9 provides information on the results. Panel (a) shows the coefficients of the univariate AR models. It can be seen that lags around one day and one to three weeks play the biggest role for all four datasets. Panel (b) shows that the multivariate models lead to better one step ahead predictions in terms of the root mean square error (RMSE).
Mod 1 and
Mod 2 show practically equivalent out of sample prediction error for all four data sets, while
Mod 3 delivers the best out of sample fit for all four regions.
In particular in financial applications data of high sampling frequency shows persistent behaviour, also in terms of conditional heteroskedasticity, as well as heavy tailed distributions of the innovations. For our data sets
Figure 10 below provides some information in this respect for the residuals according to
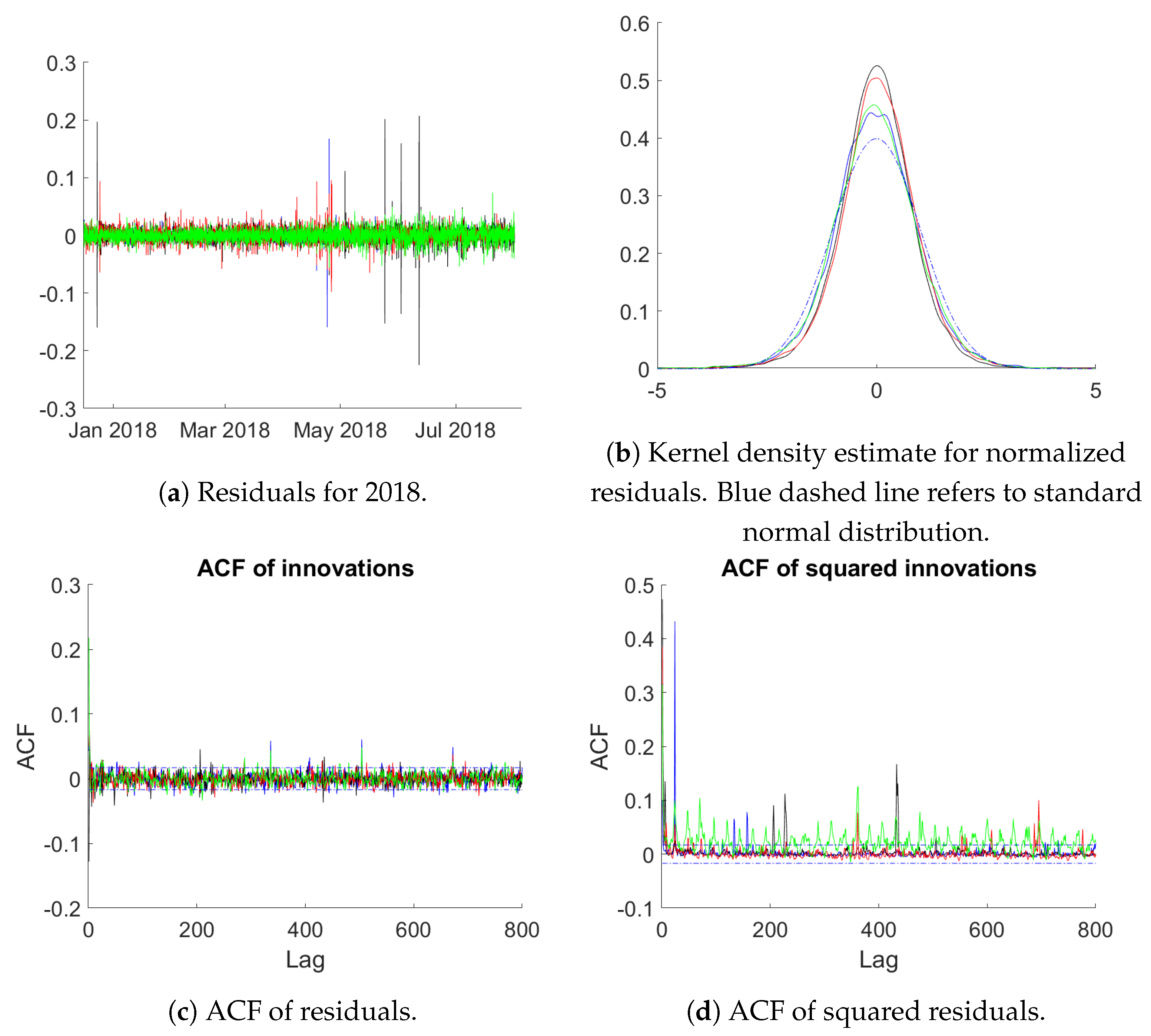
Mod 3. Panel (a) provides a plot of the residuals in the year 2018 (contained in the validation period). It can be seen that large deviations occur occasionally, while else residuals vary in a tight band around 0. The kernel density estimates for the normalized (to unit variance) residuals on the full validation data set in panel (b) show the typical heavy tailed distributions. Panel (c) contains an ACF plot for the four regions again calculated using the full validation sample. It demonstrates that the model successfully eliminates all autocorrelations with only a few ACF values occurring outside the confidence interval. Panel (d) provides the ACF plot for the squared innovations to examine GARCH-type effects. While GARCH-effects are clearly visible, the ACF drops to zero fast with occasional positive values (except maybe for the Duquesne data).
Applying the eigenvalue based test for and all Fourier frequencies we find that for Mod 2 and Mod 3 the largest p-value is obtained for corresponding to a period length of one day with 0.0187 for Mod 2 (test statistic 6.6) and 0.02 for Mod 3 (with a statistic of 6.5). This implies that the unit root at frequency is not rejected for a significance level of 1%, but is rejected for 5%. All other unit roots are rejected at every usual significance level. For Mod 1 the test statistic for equals 41.2 corresponding to a p-value of practically 0. This implies that on top of a deterministic daily pattern the series show strong persistence at the daily period. Excluding the hourly dummies pulls the roots closest to closer to the unit circle resulting in insignificant unit root tests and improves the one step ahead forecasts. Including the dummies weakens the evidence of a unit root while leading to worse predictions.
The analysis is repeated with data aggregated to daily sampling frequency. The aggregation reduces the required lag lengths, as is visible from
Table 6 in the univariate case, and hence we use
CVA with the recommended
. Beside the univariate models, in this case also a naive model of predicting the consumption for today as yesterday’s consumption is used. Three multivariate models are estimated:
Mod 1 contains weekday dummies and sine and cosine terms for the first twenty Fourier frequencies corresponding to a period of one year.
Mod 2 only contains the weekday dummies, while
Mod 3 only uses the constant.
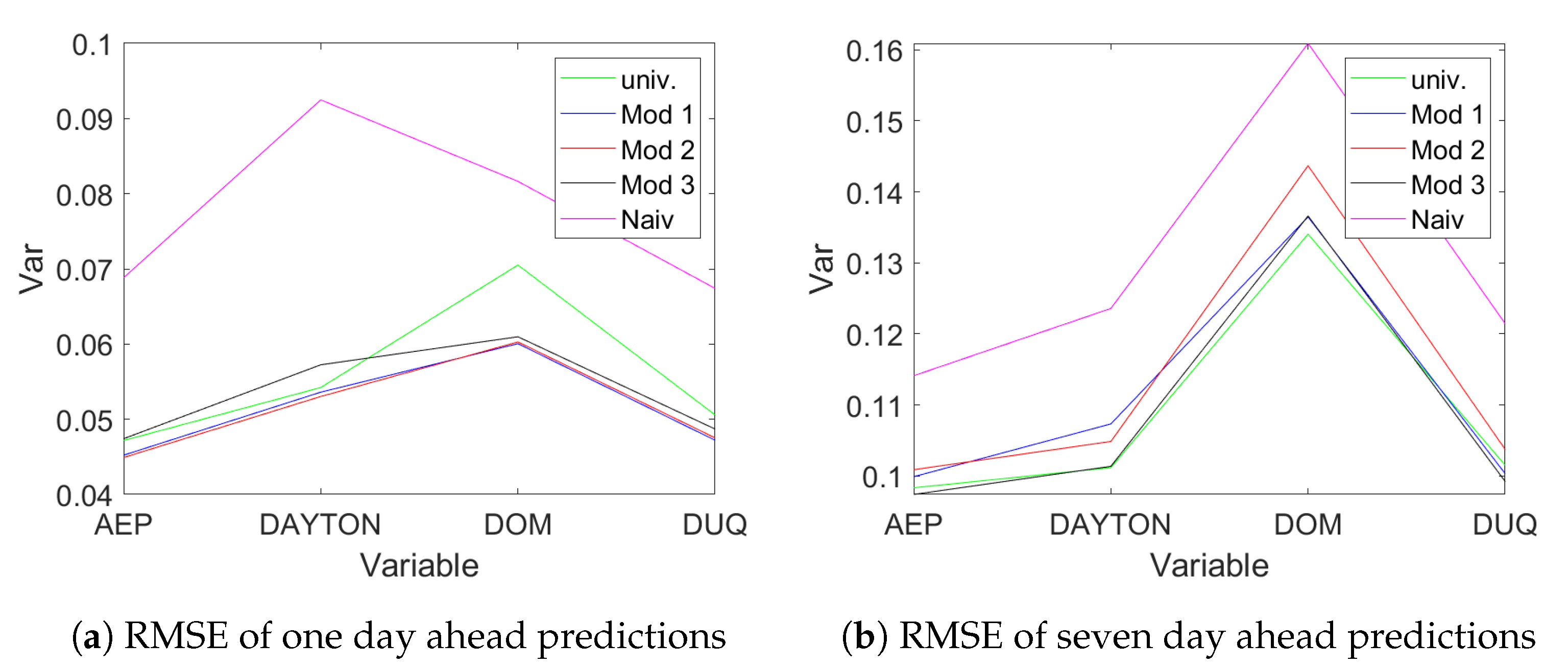
Figure 11 provides the out-of-sample RMSE for one day ahead predictions (panel (a)) and seven days ahead predictions (panel (b)).
It can be seen that both
Mod 1 and
Mod 2 beat the univariate AR models in terms of one step ahead prediction error, while
Mod 3 performs better for seven days ahead prediction.
Mod 1 performs on par with
Mod 2 for one step ahead prediction but performs better in predicting seven steps ahead. In
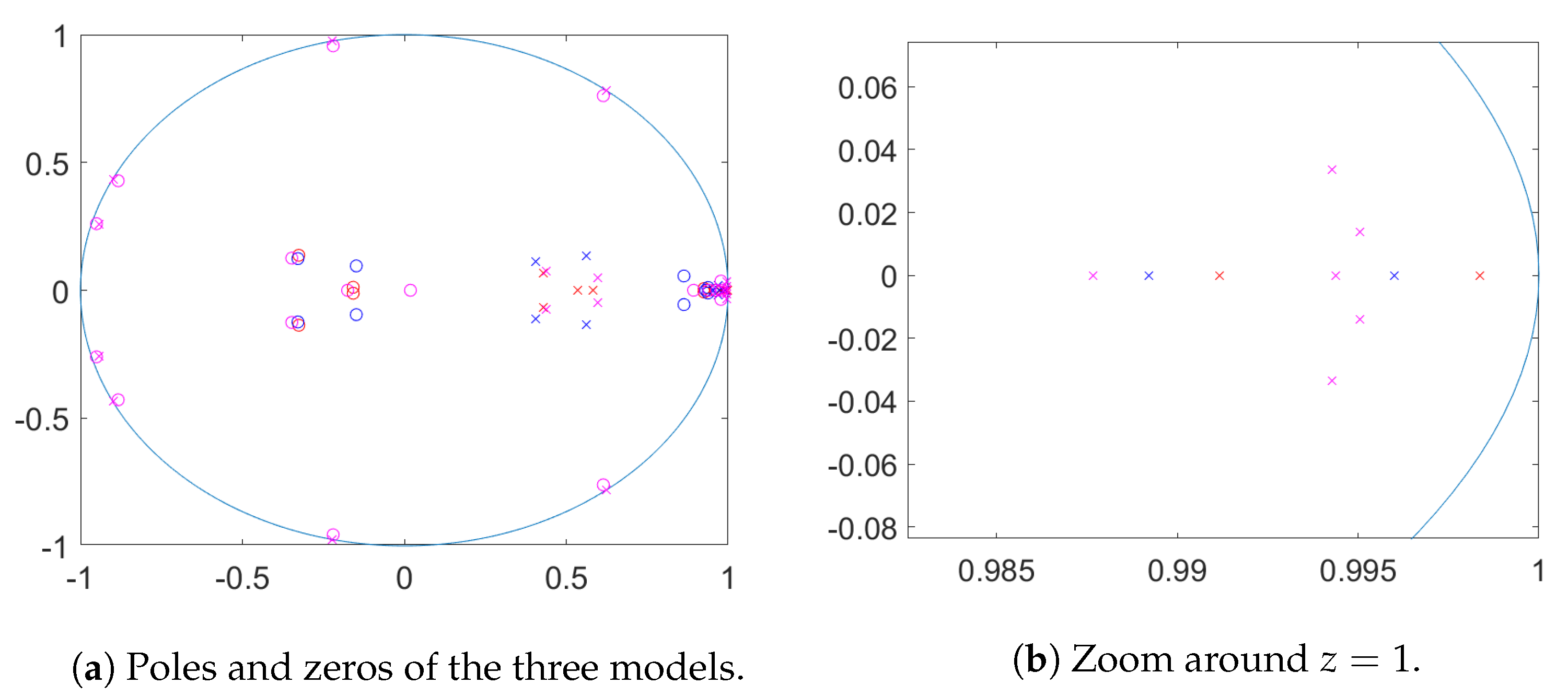
Figure 12 poles and zeros for the three estimated state space models are plotted. Here the poles (marked with ‘x’) are the eigenvalues of the matrix
A. These are the inverses of the determinantal roots of the autoregressive matrix polynomial in the equivalent VARMA representation. The zeros are the inverses of zeros of the determinant of the MA polynomial. We can see that for
Mod 3 with only a constant, poles close to
arise to capture the weekly pattern. The other two models only show one pole close to the unit circle, a real pole of almost
. The pole corresponding to
Mod 1 is closer to the unit circle than the one for
Mod 2 (see (b)).
For
Mod 3 we obtain
p-values for the tests of three complex unit roots of 0.05 (
), 0.165 (
) and 0.01 (
), which are hence all not statistically significant for significance level
. The corresponding test for
shows a
p-value of 0.004. This provides evidence against the null hypothesis of the root being present. For
Mod 1 the
p-value for the test of
is 0.28 and hence we cannot reject the null.
Mod 2 provides a
p-value of 0.023 and hence weak evidence for the presence of the unit root. This can be seen from the distance of the nearest pole from the point
in
Figure 12.
Jointly this indicates that the location and strength of persistence due to the estimated roots is influenced by the presence of deterministic terms: if the deterministic terms are not included in the model, the cyclical patterns are generated by poles situated close to the unit circle.
The decision whether on top of the deterministic seasonality unit roots exist, is not easy in all cases: for the daily data the locations of the poles indicate that deterministic seasonality is enough to capture weekly fluctuations while a unit root at
appears to be needed to capture yearly variations. For hourly data there is evidence that the daily cycle is best captured with a unit root at frequency
. This leads to the best predictive fit. Finally note that temporal aggregation from hourly data to daily data implies that the frequency
for hourly data aliases to the frequency
in the daily data. Therefore the higher evidence of a unit root at
found in daily data might be a consequence of the unit root at frequency
found for hourly data, compare [
37].
The system matrix estimates as well as the evidence in support of unit roots at for hourly data and for daily data that we obtain from the CVA modeling can be taken as starting points in subsequent quasi maximum likelihood estimation.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}