
Benchmarking Analysis of the Accuracy of Classification Methods Related to Entropy

 , and
, and 
Abstract
:1. Introduction
- We consider the random classifier and two intuitive classifiers as benchmark classifiers. These classifiers can be considered as simple, intuitive and natural for common sense non-expert decision-makers.
- We define three new performance measures of classifiers based on the Scott’s , the accuracy of classifiers, and the benchmark classifiers.
- We interpret our performance measures of classifiers in terms of proportional reduction of classification error. Therefore, we measure how much a classifier improves the classification made by the benchmark classifiers. This interpretation is interesting because it is easy to understand and, at the same time, we determine the gain in accuracy related to three simple classifiers. In a sense, they provide information on whether the design of the classifier has been worth the effort.
- The three performance measures of classifiers lie in the interval , where means that the classifier in evaluation worsens by the correct classification made by the corresponding benchmark classifier, this corresponds to the classifier assigns incorrectly all observations, and 1 means that the classifier reduces by the incorrect classification made by the corresponding benchmark classifier, this corresponds to the classifier assigns correctly all observations.
- The benchmark classifiers catch the entropy of the dataset. The random classifier and the intuitive classifier measure the entropy of the target attribute, and the intuitive classifier reflects the conditional entropy of the target attribute given the remaining variables in the dataset. Therefore, they allow us to analyze the performance of a classifier taking into account the entropy in the dataset. These measures, particularly that based on the intuitive classifiers, offer different information than other performance measures of the classifiers, which we consider to be interesting. The aim, therefore, is not to substitute for any known performance measure, but to provide a measure of a different aspect of the performance of a classifier.
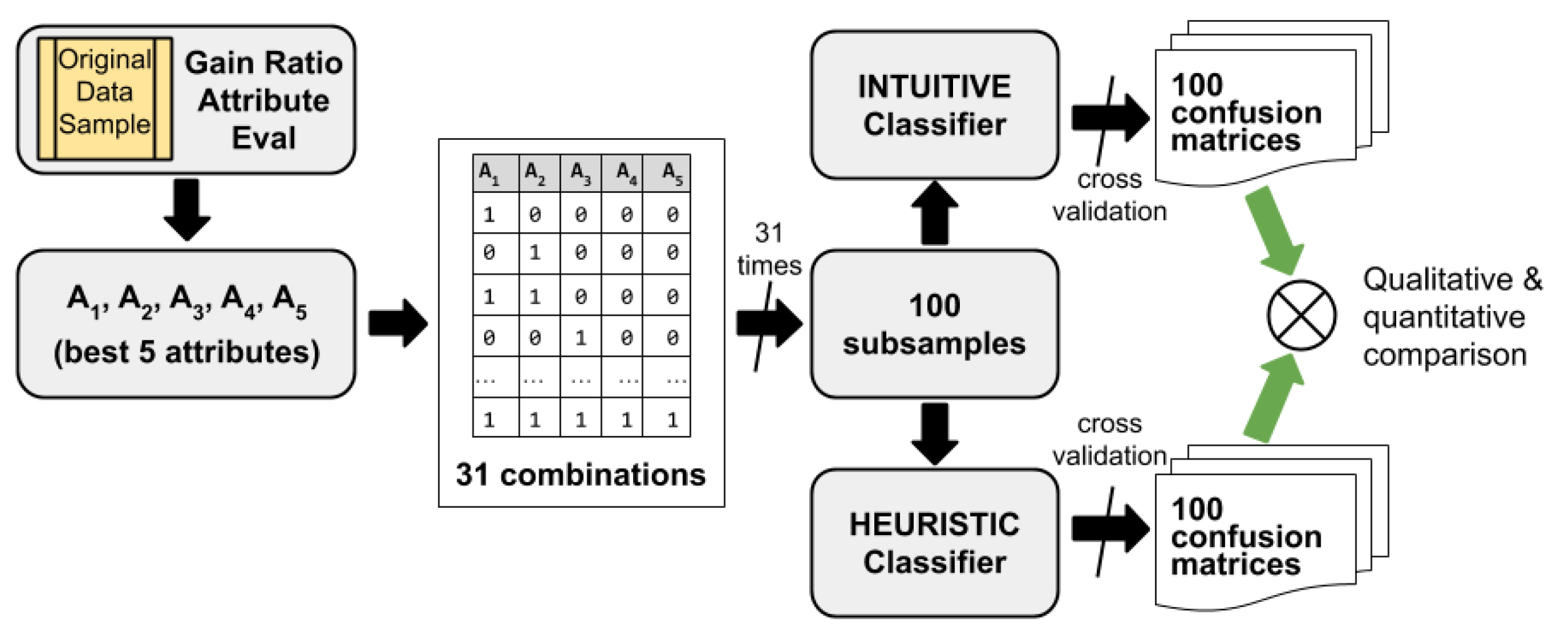
- We carry out an intensive experiment to illustrate how the proposed performance measures works and how the entropy can affect the performance of a classifier. For that we consider a particular dataset and the classification algorithm J48 [78,79,80], an implementation provided by Weka [75,81,82,83], of the classic C4.5 algorithm presented by Quinlan [36,37].
- In order to validate what was observed in the previous experiment, we carried out an extensive experiment using four classifiers implemented in Weka and 11 datasets.
2. Materials and Methods
2.1. Method and Software Used for Feature Selection
2.2. Methodology and Software for the Intuitive Classification Method
| Algorithm 1 Pseudo-code of the algorithm of the intuitive classifier . |
|
| Algorithm 2 Pseudo-code of the algorithm to predict with a CRS model. |
|
2.3. Methodology and Software for the Heuristic Classifiers
2.4. Evaluation Measures
- 1.
- .
- 2.
- .
- 3.
- .
3. Computer-Based Experiments: Design and Results
3.1. Datasets and Scenarios
- Headers have been added and renamed.
- The numeric attributes have been removed and we have left only those which are nominal.
- The class variable has been recoded in positive and negative cases (the original sample has several types of positive instances).
- Number of rows: 9173
- Number of attributes/columns: 23 (all nominal)
- –
- 22 explanatory variables (antecedents)
- –
- 1 target variable (consequent)
- *
- 2401 positive cases
- *
- 6772 negative cases
- In all the datasets that did not have a row with the header, it has been added, taking into account the specifications of the “Attribute Information” section of each of these UCI repository datasets.
- The configuration in Weka to discretize has been with the parameter “bins” = 5 (to obtain 5 groups) and the parameter “UseEqualFrecuency” = true (so that the groups of data obtained were equitable).
- When discretizing in Weka (filter→unsupervised→discretized) the results obtained were numerical intervals, so they were later renamed.
3.2. Experimental Design
3.3. Results
3.4. Extensive Experiment
4. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Tables

{kind=link}
| Comb. | Antecedents | J48 wins | wins | |||||
|---|---|---|---|---|---|---|---|---|
| #1 | 5 | 45 | 10 | 0.3328 | 0.0019 | 0.3316 | −0.0003 | −0.0009 |
| #2 | 4 | 39 | 33 | 0.3326 | 0.0003 | 0.3324 | −0.0004 | −0.0005 |
| #3 | 45 | 56 | 28 | 0.3320 | 0.0022 | 0.3306 | −0.0007 | −0.0014 |
| #4 | 3 | 39 | 16 | 0.3318 | 0.0024 | 0.3301 | −0.0008 | −0.0016 |
| #5 | 35 | 55 | 33 | 0.3314 | 0.0031 | 0.3294 | −0.0010 | −0.0020 |
| #6 | 34 | 57 | 30 | 0.3311 | 0.0029 | 0.3291 | −0.0011 | −0.0021 |
| #7 | 345 | 56 | 34 | 0.3305 | 0.0032 | 0.3284 | −0.0014 | −0.0025 |
| #8 | 2 | 0 | 0 | 0.3333 | 0.0000 | 0.3333 | 0.0000 | 0.0000 |
| #9 | 25 | 45 | 10 | 0.3328 | 0.0019 | 0.3316 | −0.0003 | −0.0009 |
| #10 | 24 | 44 | 28 | 0.3326 | 0.0005 | 0.3322 | −0.0004 | −0.0006 |
| #11 | 245 | 61 | 26 | 0.3321 | 0.0025 | 0.3304 | −0.0006 | −0.0015 |
| #12 | 23 | 47 | 24 | 0.3316 | 0.0021 | 0.3302 | −0.0009 | −0.0016 |
| #13 | 235 | 55 | 36 | 0.3312 | 0.0027 | 0.3294 | −0.0011 | −0.0020 |
| #14 | 231 | 56 | 32 | 0.3307 | 0.0024 | 0.3291 | −0.0013 | −0.0021 |
| #15 | 2345 | 58 | 33 | 0.3303 | 0.0030 | 0.3282 | −0.0015 | −0.0025 |
| #16 | 1 | 0 | 0 | 0.3333 | 0.0000 | 0.3333 | 0.0000 | 0.0000 |
| #17 | 15 | 45 | 10 | 0.3328 | 0.0019 | 0.3316 | −0.0002 | −0.0009 |
| #18 | 14 | 40 | 32 | 0.3326 | 0.0004 | 0.3324 | −0.0004 | −0.0005 |
| #19 | 145 | 57 | 27 | 0.3321 | 0.0023 | 0.3306 | −0.0006 | −0.0014 |
| #20 | 13 | 39 | 16 | 0.3318 | 0.0024 | 0.3301 | −0.0008 | −0.0016 |
| #21 | 135 | 53 | 33 | 0.3312 | 0.0028 | 0.3294 | −0.0011 | −0.0020 |
| #22 | 134 | 55 | 31 | 0.3310 | 0.0028 | 0.3291 | −0.0012 | −0.0021 |
| #23 | 1345 | 58 | 33 | 0.3305 | 0.0032 | 0.3284 | −0.0014 | −0.0025 |
| #24 | 12 | 0 | 0 | 0.3333 | 0.0000 | 0.3333 | 0.0000 | 0.0000 |
| #25 | 125 | 45 | 10 | 0.3328 | 0.0019 | 0.3316 | −0.0003 | −0.0009 |
| #26 | 124 | 44 | 28 | 0.3327 | 0.0007 | 0.3322 | −0.0003 | −0.0006 |
| #27 | 1245 | 62 | 25 | 0.3321 | 0.0025 | 0.3304 | −0.0006 | −0.0015 |
| #28 | 123 | 47 | 24 | 0.3316 | 0.0022 | 0.3302 | −0.0009 | −0.0016 |
| #29 | 1235 | 55 | 35 | 0.3311 | 0.0026 | 0.3294 | −0.0011 | −0.0020 |
| #30 | 1234 | 57 | 31 | 0.3308 | 0.0026 | 0.3291 | −0.0013 | −0.0021 |
| #31 | 12345 | 57 | 34 | 0.3303 | 0.0031 | 0.3282 | −0.0015 | −0.0025 |
| Total | 1427 | 742 | ||||||
| % | 46.03 | 23.94 |
| Comb. | Antecedents | J48 wins | wins | |||||
|---|---|---|---|---|---|---|---|---|
| #1 | 5 | 38 | 35 | 0.2499 | 0.0000 | 0.2498 | −0.0001 | −0.0001 |
| #2 | 4 | 7 | 34 | 0.2526 | −0.0004 | 0.2532 | 0.0034 | 0.0043 |
| #3 | 45 | 35 | 45 | 0.2525 | −0.0003 | 0.2530 | 0.0034 | 0.0041 |
| #4 | 3 | 1 | 12 | 0.2611 | −0.0004 | 0.2617 | 0.0148 | 0.0156 |
| #5 | 35 | 43 | 34 | 0.2604 | −0.0002 | 0.2607 | 0.0139 | 0.0143 |
| #6 | 34 | 6 | 41 | 0.2636 | −0.0008 | 0.2649 | 0.0182 | 0.0198 |
| #7 | 345 | 33 | 54 | 0.2625 | −0.0008 | 0.2638 | 0.0167 | 0.0184 |
| #8 | 2 | 1 | 0 | 0.2500 | 0.0000 | 0.2500 | 0.0000 | 0.0000 |
| #9 | 25 | 38 | 35 | 0.2499 | 0.0000 | 0.2498 | −0.0001 | −0.0001 |
| #10 | 24 | 31 | 34 | 0.2524 | −0.0003 | 0.2529 | 0.0032 | 0.0038 |
| #11 | 245 | 41 | 46 | 0.2523 | −0.0003 | 0.2527 | 0.0030 | 0.0036 |
| #12 | 23 | 9 | 46 | 0.2612 | −0.0007 | 0.2623 | 0.0150 | 0.0163 |
| #13 | 235 | 37 | 48 | 0.2605 | −0.0005 | 0.2612 | 0.0140 | 0.0150 |
| #14 | 231 | 26 | 59 | 0.2636 | −0.0009 | 0.2650 | 0.0181 | 0.0200 |
| #15 | 2345 | 34 | 57 | 0.2628 | −0.0008 | 0.2640 | 0.0171 | 0.0187 |
| #16 | 1 | 0 | 0 | 0.2500 | 0.0000 | 0.2500 | 0.0000 | 0.0000 |
| #17 | 15 | 38 | 35 | 0.2499 | 0.0000 | 0.2498 | −0.0001 | −0.0001 |
| #18 | 14 | 7 | 34 | 0.2525 | −0.0004 | 0.2532 | 0.0034 | 0.0043 |
| #19 | 145 | 33 | 47 | 0.2524 | −0.0004 | 0.2530 | 0.0032 | 0.0041 |
| #20 | 13 | 1 | 12 | 0.2612 | −0.0004 | 0.2617 | 0.0149 | 0.0156 |
| #21 | 135 | 43 | 34 | 0.2605 | −0.0002 | 0.2607 | 0.0140 | 0.0143 |
| #22 | 134 | 6 | 41 | 0.2636 | −0.0008 | 0.2649 | 0.0182 | 0.0198 |
| #23 | 1345 | 36 | 51 | 0.2628 | −0.0007 | 0.2638 | 0.0170 | 0.0184 |
| #24 | 12 | 0 | 0 | 0.2500 | 0.0000 | 0.2500 | 0.0000 | 0.0000 |
| #25 | 125 | 38 | 35 | 0.2499 | 0.0001 | 0.2498 | −0.0001 | −0.0001 |
| #26 | 124 | 31 | 34 | 0.2524 | −0.0003 | 0.2529 | 0.0032 | 0.0038 |
| #27 | 1245 | 41 | 46 | 0.2523 | −0.0002 | 0.2527 | 0.0031 | 0.0036 |
| #28 | 123 | 9 | 45 | 0.2612 | −0.0007 | 0.2623 | 0.0150 | 0.0163 |
| #29 | 1235 | 37 | 48 | 0.2605 | −0.0005 | 0.2612 | 0.0140 | 0.0150 |
| #30 | 1234 | 25 | 60 | 0.2636 | −0.0009 | 0.2650 | 0.0182 | 0.0200 |
| #31 | 12345 | 34 | 57 | 0.2628 | −0.0008 | 0.2640 | 0.0170 | 0.0187 |
| Total | 759 | 1159 | ||||||
| % | 24.48 | 37.39 |
| Comb. | Antecedents | J48 wins | wins | |||||
|---|---|---|---|---|---|---|---|---|
| #1 | 5 | 72 | 1 | 0.0365 | 0.0390 | −0.0026 | 0.0365 | −0.0026 |
| #2 | 4 | 100 | 0 | 0.0076 | 0.0839 | −0.0833 | 0.0076 | −0.0833 |
| #3 | 45 | 33 | 0 | 0.0448 | 0.0173 | 0.0279 | 0.0448 | 0.0279 |
| #4 | 3 | 100 | 0 | 0.0067 | 0.0842 | −0.0846 | 0.0067 | −0.0846 |
| #5 | 35 | 49 | 4 | 0.0417 | 0.0259 | 0.0161 | 0.0417 | 0.0161 |
| #6 | 34 | 100 | 0 | 0.0140 | 0.0833 | −0.0756 | 0.0140 | −0.0756 |
| #7 | 345 | 18 | 5 | 0.0492 | 0.0076 | 0.0419 | 0.0492 | 0.0419 |
| #8 | 2 | 18 | 0 | 0.0323 | 0.0070 | 0.0255 | 0.0323 | 0.0255 |
| #9 | 25 | 100 | 0 | 0.0343 | 0.0797 | −0.0493 | 0.0343 | −0.0493 |
| #10 | 24 | 60 | 11 | 0.0324 | 0.0253 | 0.0074 | 0.0324 | 0.0074 |
| #11 | 245 | 100 | 0 | 0.0436 | 0.0806 | −0.0402 | 0.0436 | −0.0402 |
| #12 | 23 | 57 | 0 | 0.0323 | 0.0235 | 0.0090 | 0.0323 | 0.0090 |
| #13 | 235 | 100 | 0 | 0.0399 | 0.0805 | −0.0441 | 0.0399 | −0.0441 |
| #14 | 231 | 86 | 2 | 0.0324 | 0.0470 | −0.0153 | 0.0324 | −0.0153 |
| #15 | 2345 | 99 | 0 | 0.0487 | 0.0781 | −0.0319 | 0.0487 | −0.0319 |
| #16 | 1 | 100 | 0 | 0.0004 | 0.0832 | −0.0903 | 0.0004 | −0.0903 |
| #17 | 15 | 77 | 0 | 0.0372 | 0.0433 | −0.0064 | 0.0372 | −0.0064 |
| #18 | 14 | 100 | 0 | 0.0075 | 0.0838 | −0.0832 | 0.0075 | −0.0832 |
| #19 | 145 | 37 | 0 | 0.0448 | 0.0190 | 0.0262 | 0.0448 | 0.0262 |
| #20 | 13 | 100 | 0 | 0.0071 | 0.0844 | −0.0845 | 0.0071 | −0.0845 |
| #21 | 135 | 50 | 4 | 0.0417 | 0.0274 | 0.0147 | 0.0417 | 0.0147 |
| #22 | 134 | 100 | 0 | 0.0140 | 0.0832 | −0.0755 | 0.0140 | −0.0755 |
| #23 | 1345 | 19 | 5 | 0.0492 | 0.0081 | 0.0414 | 0.0492 | 0.0414 |
| #24 | 12 | 15 | 45 | 0.0325 | 0.0049 | 0.0277 | 0.0325 | 0.0277 |
| #25 | 125 | 100 | 0 | 0.0345 | 0.0795 | −0.0489 | 0.0345 | −0.0489 |
| #26 | 124 | 55 | 28 | 0.0328 | 0.0216 | 0.0115 | 0.0328 | 0.0115 |
| #27 | 1245 | 100 | 0 | 0.0436 | 0.0811 | −0.0407 | 0.0436 | −0.0407 |
| #28 | 123 | 49 | 23 | 0.0327 | 0.0192 | 0.0138 | 0.0327 | 0.0138 |
| #29 | 1235 | 100 | 0 | 0.0399 | 0.0807 | −0.0443 | 0.0399 | −0.0443 |
| #30 | 1234 | 84 | 10 | 0.0325 | 0.0437 | −0.0117 | 0.0325 | −0.0117 |
| #31 | 12345 | 100 | 0 | 0.0482 | 0.0786 | −0.0331 | 0.0482 | −0.0331 |
| Total | 2278 | 138 | ||||||
| % | 73.48 | 4.45 |
| Comb. | Antecedents | J48 wins | wins | |||||
|---|---|---|---|---|---|---|---|---|
| #1 | 5 | 10 | 19 | 0.2652 | −0.0004 | 0.2659 | 0.0203 | 0.0212 |
| #2 | 4 | 0 | 0 | 0.2500 | 0.0000 | 0.2500 | 0.0000 | 0.0000 |
| #3 | 45 | 13 | 20 | 0.2653 | −0.0004 | 0.2658 | 0.0204 | 0.0211 |
| #4 | 3 | 0 | 0 | 0.2500 | 0.0000 | 0.2500 | 0.0000 | 0.0000 |
| #5 | 35 | 28 | 18 | 0.2651 | −0.0003 | 0.2655 | 0.0202 | 0.0207 |
| #6 | 34 | 0 | 0 | 0.2500 | 0.0000 | 0.2500 | 0.0000 | 0.0000 |
| #7 | 345 | 30 | 20 | 0.2651 | −0.0002 | 0.2655 | 0.0201 | 0.0206 |
| #8 | 2 | 0 | 0 | 0.2686 | 0.0000 | 0.2686 | 0.0248 | 0.0248 |
| #9 | 25 | 23 | 76 | 0.2686 | −0.0022 | 0.2720 | 0.0248 | 0.0293 |
| #10 | 24 | 0 | 38 | 0.2692 | −0.0002 | 0.2695 | 0.0256 | 0.0260 |
| #11 | 245 | 21 | 78 | 0.2691 | −0.0025 | 0.2728 | 0.0254 | 0.0305 |
| #12 | 23 | 76 | 8 | 0.2686 | 0.0004 | 0.2684 | 0.0248 | 0.0245 |
| #13 | 235 | 23 | 76 | 0.2685 | −0.0020 | 0.2715 | 0.0247 | 0.0287 |
| #14 | 231 | 46 | 40 | 0.2692 | 0.0000 | 0.2692 | 0.0256 | 0.0256 |
| #15 | 2345 | 24 | 76 | 0.2690 | −0.0022 | 0.2723 | 0.0254 | 0.0298 |
| #16 | 1 | 0 | 47 | 0.2501 | −0.0002 | 0.2505 | 0.0001 | 0.0006 |
| #17 | 15 | 8 | 28 | 0.2653 | −0.0004 | 0.2660 | 0.0204 | 0.0213 |
| #18 | 14 | 0 | 47 | 0.2501 | −0.0002 | 0.2505 | 0.0001 | 0.0006 |
| #19 | 145 | 11 | 30 | 0.2653 | −0.0004 | 0.2659 | 0.0204 | 0.0212 |
| #20 | 13 | 0 | 47 | 0.2501 | −0.0002 | 0.2505 | 0.0001 | 0.0006 |
| #21 | 135 | 24 | 25 | 0.2651 | −0.0003 | 0.2656 | 0.0202 | 0.0208 |
| #22 | 134 | 0 | 47 | 0.2501 | −0.0002 | 0.2505 | 0.0001 | 0.0006 |
| #23 | 1345 | 27 | 27 | 0.2651 | −0.0003 | 0.2656 | 0.0202 | 0.0207 |
| #24 | 12 | 0 | 47 | 0.2687 | −0.0002 | 0.2691 | 0.0250 | 0.0254 |
| #25 | 125 | 21 | 76 | 0.2686 | −0.0023 | 0.2721 | 0.0247 | 0.0295 |
| #26 | 124 | 0 | 69 | 0.2693 | −0.0004 | 0.2699 | 0.0257 | 0.0266 |
| #27 | 1245 | 18 | 80 | 0.2689 | −0.0026 | 0.2729 | 0.0253 | 0.0306 |
| #28 | 123 | 41 | 47 | 0.2687 | −0.0001 | 0.2688 | 0.0250 | 0.0251 |
| #29 | 1235 | 22 | 76 | 0.2685 | −0.0020 | 0.2716 | 0.0247 | 0.0288 |
| #30 | 1234 | 24 | 69 | 0.2693 | −0.0002 | 0.2697 | 0.0257 | 0.0262 |
| #31 | 12345 | 22 | 77 | 0.2691 | −0.0022 | 0.2724 | 0.0254 | 0.0299 |
| Total | 512 | 1308 | ||||||
| % | 16.52 | 42.19 |
| Comb. | Antecedents | J48 wins | wins | |||||
|---|---|---|---|---|---|---|---|---|
| #1 | 5 | 59 | 41 | 0.3336 | 0.0013 | 0.3327 | 0.0191 | 0.0179 |
| #2 | 4 | 81 | 0 | 0.3339 | 0.0016 | 0.3328 | 0.0181 | 0.0165 |
| #3 | 45 | 59 | 41 | 0.3234 | 0.0012 | 0.3226 | −0.0003 | −0.0007 |
| #4 | 3 | 81 | 0 | 0.3288 | 0.0016 | 0.3277 | 0.0090 | 0.0074 |
| #5 | 35 | 59 | 41 | 0.3209 | 0.0012 | 0.3201 | −0.0022 | −0.0026 |
| #6 | 34 | 81 | 0 | 0.3187 | 0.0016 | 0.3176 | −0.0037 | −0.0043 |
| #7 | 345 | 59 | 41 | 0.3310 | 0.0012 | 0.3302 | 0.0141 | 0.0129 |
| #8 | 2 | 73 | 10 | 0.3187 | 0.0012 | 0.3179 | −0.0039 | −0.0043 |
| #9 | 25 | 59 | 41 | 0.3234 | 0.0012 | 0.3226 | −0.0003 | −0.0007 |
| #10 | 24 | 73 | 10 | 0.3338 | 0.0012 | 0.3330 | 0.0190 | 0.0178 |
| #11 | 245 | 59 | 41 | 0.3209 | 0.0012 | 0.3201 | −0.0020 | −0.0024 |
| #12 | 23 | 74 | 9 | 0.3263 | 0.0012 | 0.3254 | 0.0041 | 0.0028 |
| #13 | 235 | 59 | 41 | 0.3109 | 0.0012 | 0.3101 | −0.0087 | −0.0091 |
| #14 | 231 | 74 | 9 | 0.3313 | 0.0013 | 0.3305 | 0.0146 | 0.0133 |
| #15 | 2345 | 59 | 41 | 0.3234 | 0.0012 | 0.3226 | −0.0006 | −0.0010 |
| #16 | 1 | 80 | 1 | 0.3462 | 0.0015 | 0.3452 | 0.0377 | 0.0363 |
| #17 | 15 | 89 | 10 | 0.3331 | 0.0023 | 0.3316 | 0.0112 | 0.0089 |
| #18 | 14 | 93 | 1 | 0.3438 | 0.0020 | 0.3425 | 0.0319 | 0.0300 |
| #19 | 145 | 89 | 9 | 0.3384 | 0.0026 | 0.3366 | 0.0220 | 0.0194 |
| #20 | 13 | 75 | 4 | 0.3424 | 0.0014 | 0.3414 | 0.0291 | 0.0277 |
| #21 | 135 | 93 | 5 | 0.3397 | 0.0026 | 0.3380 | 0.0239 | 0.0214 |
| #22 | 134 | 89 | 4 | 0.3246 | 0.0016 | 0.3235 | −0.0018 | −0.0024 |
| #23 | 1345 | 95 | 3 | 0.3398 | 0.0027 | 0.3380 | 0.0240 | 0.0214 |
| #24 | 12 | 74 | 9 | 0.3541 | 0.0013 | 0.3532 | 0.0524 | 0.0512 |
| #25 | 125 | 89 | 8 | 0.3232 | 0.0024 | 0.3215 | −0.0026 | −0.0034 |
| #26 | 124 | 84 | 9 | 0.3336 | 0.0015 | 0.3326 | 0.0124 | 0.0109 |
| #27 | 1245 | 89 | 8 | 0.3308 | 0.0026 | 0.3290 | 0.0070 | 0.0044 |
| #28 | 123 | 70 | 13 | 0.3347 | 0.0010 | 0.3341 | 0.0141 | 0.0131 |
| #29 | 1235 | 91 | 5 | 0.3346 | 0.0025 | 0.3330 | 0.0144 | 0.0119 |
| #30 | 1234 | 81 | 11 | 0.3398 | 0.0013 | 0.3390 | 0.0236 | 0.0223 |
| #31 | 12345 | 94 | 4 | 0.3447 | 0.0025 | 0.3431 | 0.0343 | 0.0319 |
| Total | 2384 | 470 | ||||||
| % | 76.90 | 15.16 |
References
- Aggarwal, C.C. Data Mining: The Textbook; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Kelleher, J.D.; Namee, B.M.; D’Arcy, A. Machine Learning for Predictive Data Analytics: Algorithms, Worked Examples, and Case Studies; The MIT Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Kubat, M. An Introduction to Machine Learning, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Skiena, S.S. The Data Science Design Manual; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Rényi, A. On measures of entropy and information. In Proceedings of the 4th Berkeley Symposium on Mathematics, Statistics and Probability, Berkeley, CA, USA, 20 June–30 July 1960; Neyman, J., Ed.; University of California Press: Berkeley, CA, USA, 1961; pp. 547–561. [Google Scholar]
- Tsallis, C. Possible generalization of Boltzmann—Gibbs statistics, J. Stat. Phys. 1988, 52, 479–487. [Google Scholar] [CrossRef]
- Amigó, J.M.; Balogh, S.G.; Hernández, S. A Brief Review of Generalized Entropies. Entropy 2018, 20, 813. [Google Scholar] [CrossRef] [Green Version]
- Orenes, Y.; Rabasa, A.; Pérez-Martín, A.; Rodríguez-Sala, J.J.; Sánchez-Soriano, J. A Computational Experience For Automatic Feature Selection On Big Data Frameworks. Int. J. Des. Nat. Ecodynamics 2016, 11, 168–177. [Google Scholar] [CrossRef]
- Fu, K.S.; Cardillo, G.P. An Optimum Finite Sequential Procedure For Feature Selection Furthermore, Pattern Classification. IEEE Trans. Autom. Control 1967, AC12, 588. [Google Scholar] [CrossRef]
- Cardillo, G.P.; Fu, K.S. Divergence Furthermore, Linear Classifiers For Feature Selection. IEEE Trans. Autom. Control. 1967, AC12, 780. [Google Scholar] [CrossRef]
- Chien, Y.T. Adaptive strategies of selecting feature subsets in pattern recognition. In Proceedings of the IEEE Symposium on Adaptive Processes (8th) Decision and Control, University Park, PA, USA, 17–19 November 1969; p. 36. [Google Scholar]
- Jurs, P.C.; Kowalski, B.R.; Isenhour, T.L.; Reilley, C.N. Computerized learning machines applied to chemical problems. Convergence rate and predictive ability of adaptive binary pattern classifiers. Anal. Chem. 1969, 41, 690–695. [Google Scholar] [CrossRef]
- Jurs, P.C. Mass spectral Feature Selection and structural correlations using computerized learning machines. Anal. Chem. 1970, 42, 1633–1638. [Google Scholar] [CrossRef]
- Narendra, P.; Fukunaga, K. Branch and bound algorithm for Feature subset Selection. IEEE Trans. Comput. 1977, 26, 917–922. [Google Scholar] [CrossRef]
- Pudil, P.; Novovicova, J.; Kittler, J. Floating Search Methods in Feature-Selection. Pattern Recognit. Lett. 1994, 15, 1119–1125. [Google Scholar] [CrossRef]
- Siedlecki, W.; Sklansky, J. A note on genetic algorithms for largescale Feature-Selection. Pattern Recognit. Lett. 1989, 10, 335–347. [Google Scholar] [CrossRef]
- Leardi, R.; Boggia, R.; Terrile, M. Genetic algorithms as a strategy for Feature-Selection. J. Chemom. 1992, 6, 267–281. [Google Scholar] [CrossRef]
- Yang, J.H.; Honavar, V. Feature subset Selection using a genetic algorithm. IEEE Intell. Syst. Appl. 1998, 13, 44–49. [Google Scholar] [CrossRef] [Green Version]
- John, G.; Kohavi, R.; Pfleger, K. Irrelevant features and the subset selection problem. In Proceedings of the Fifth International Conference on Machine Learning, New Brunswick, NJ, USA, 10–13 July 1994; pp. 121–129. [Google Scholar]
- Kohavi, R.; John, G.H. Wrappers for Feature subset Selection. Artif. Intell. 1997, 97, 273–324. [Google Scholar] [CrossRef] [Green Version]
- Mitra, P.; Murthy, C.A.; Pal, S.K. Unsupervised feature selection using feature similarity. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 301–312. [Google Scholar] [CrossRef]
- Yu, L.; Liu, H. Efficient Feature Selection via analysis of relevance and redundancy. J. Mach. Learn. Res. 2004, 5, 1205–1224. [Google Scholar]
- Peng, H.C.; Long, F.H.; Ding, C. Feature Selection based on mutual information: Criteria of max-dependency, max-relevance, and minredundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef] [PubMed]
- Trabelsia, M.; Meddouria, N.; Maddourib, M. A New Feature Selection Method for Nominal Classifier based on Formal Concept Analysis. Procedia Comput. Sci. 2017, 112, 186–194. [Google Scholar] [CrossRef]
- Meddouri, N.; Khoufi, H.; Maddouri, M. Parallel learning and classification for rules based on formal concepts. Procedia Comput. Sci. 2014, 35, 358–367. [Google Scholar] [CrossRef] [Green Version]
- Cohen, S.; Dror, G.; Ruppin, G. Feature Selection via Coalitional Game Theory. Neural Comput. 2007, 19, 1939–1961. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Afghah, F.; Razi, A.; Soroushmehr, R.; Ghanbari, H.; Najarian, K. Game Theoretic Approach for Systematic Feature Selection; Application in False Alarm Detection in Intensive Care Units. Entropy 2018, 20, 190. [Google Scholar] [CrossRef] [Green Version]
- Duch, W.; Wieczorek, T.; Biesiada, J.; Blachnik, M. Comparison of feature ranking methods based on information entropy. In Proceedings of the 2004 IEEE International Joint Conference on Neural Networks (IEEE Cat. No.04CH37541), Budapest, Hungary, 25–29 July 2004; Volume 2, pp. 1415–1419. [Google Scholar]
- Aremu, O.O.; Cody, R.A.; Hyland-Wood, D.; McAree, P.R. A relative entropy based feature selection framework for asset data in predictive maintenance. Comput. Ind. Eng. 2020, 145, 106536. [Google Scholar] [CrossRef]
- Bai, L.; Han, Z.; Ren, J.; Qin, X. Research on feature selection for rotating machinery based on Supervision Kernel Entropy Component Analysis with Whale Optimization Algorithm. Appl. Soft Comput. 2020, 92, 106245. [Google Scholar] [CrossRef]
- Qu, Y.; Li, R.; Deng, A.; Shang, C.; Shen, Q. Non-unique decision differential entropy-based feature selection. Neurocomputing 2020, 393, 187–193. [Google Scholar] [CrossRef]
- Revanasiddappa, M.B.; Harish, B.S. A New Feature Selection Method based on Intuitionistic Fuzzy Entropy to Categorize Text Documents. Int. J. Interact. Multimed. Artif. Intell. 2018, 5, 106–117. [Google Scholar] [CrossRef] [Green Version]
- Zhao, J.; Liang, J.; Dong, Z.; Tang, D.; Liu, Z. Accelerating information entropy-based feature selection using rough set theory with classified nested equivalence classes. Pattern Recognit. 2020, 107, 107517. [Google Scholar] [CrossRef]
- Liu, H.; Yu, L. Toward integrating Feature Selection algorithms for classification and clustering. IEEE Trans. Knowl. Data Eng. 2005, 17, 491–502. [Google Scholar]
- Quinlan, J.R. Induction of decision tree. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Quinlan, J.R. C4.5: Programs for Machine Learning, 1st ed.; Morgan Kaufmann Publishers: San Mateo, CA, USA, 1992. [Google Scholar]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Wadsworth International Group: Belmont, CA, USA, 1984. [Google Scholar]
- Ho, T.K. Random Decision Forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, USA, 14–16 August 1995; pp. 278–282. [Google Scholar]
- Ho, T.K. The Random Subspace Method for Constructing Decision Forests’. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Cover, T.M.; Hart, P.E. Nearest neighbor pattern classification. Inst. Electr. Electron. Eng. Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Dasarathy, B.V. Nearest-Neighbor Classification Techniques; IEEE Computer Society Press: Los Alomitos, CA, USA, 1991. [Google Scholar]
- Aha, D.W.; Kibler, D.; Albert, M.K. Instance-based learning algorithms. Mach. Learn. 1991, 6, 37–66. [Google Scholar] [CrossRef] [Green Version]
- Cortes, C.; Vapnik, V. Support vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Ben-Hur, A.; Horn, D.; Siegelmann, H.; Vapnik, V.N. Support vector clustering. J. Mach. Learn. Res. 2001, 2, 125–137. [Google Scholar] [CrossRef]
- McLachlan, G.J. Discriminant Analysis and Statistical Pattern Recognition; Wiley Interscience: New York, NY, USA, 2004. [Google Scholar]
- Langley, W.I.; Thompson, K. An analysis of Bayesian classifiers. In Proceedings of the AAAI-94, Seattle, WA, USA, 1–4 August 1994; MIT Press: Cambridge, MA, USA, 1994; pp. 223–228. [Google Scholar]
- John, G.H.; Langley, P. Estimating Continuous Distributions in Bayesian Classifiers. In Proceedings of the Eleventh Conference on Uncertainty in Artificial Intelligence, San Mateo, CA, USA, 18–20 August 1995; pp. 338–345. [Google Scholar]
- Ramírez-Gallego, S.; García, S.; Herrera, F. Online entropy-based discretization for data streaming classification. Future Gener. Comput. Syst. 2018, 86, 59–70. [Google Scholar] [CrossRef]
- Rahman, M.A.; Khanam, F.; Ahmad, M. Multiclass EEG signal classification utilizing Rényi min-entropy-based feature selection from wavelet packet transformation. Brain Inform. 2020, 7, 7. [Google Scholar] [CrossRef]
- Wang, J.; Xu, S.; Duan, B.; Liu, C.; Liang, J. An Ensemble Classification Algorithm Based on Information Entropy for Data Streams. Neural Process. Lett. 2019, 50, 2101–2117. [Google Scholar] [CrossRef] [Green Version]
- Mannor, S.; Peleg, D.; Rubinstein, R. The cross entropy method for classification. In Proceedings of the 22nd International Conference on Machine Learning (ICML ’05), Association for Computing Machinery, New York, NY, USA, 11–13 August 2005; pp. 561–568. [Google Scholar]
- Lee, H.M.; Chen, C.M.; Chen, J.M.; Jou, Y.L. An efficient fuzzy classifier with feature selection based on fuzzy entropy. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2001, 31, 426–432. [Google Scholar]
- Cleary, J.G.; Trigg, L.E. K*: An Instance-based Learner Using an Entropic Distance Measure. In Machine Learning Proceedings 1995; Prieditis, A., Russell, S., Eds.; Morgan Kaufmann: Burlington, MA, USA, 1995; pp. 108–114. [Google Scholar]
- Holub, A.; Perona, P.; Burl, M.C. Entropy-based active learning for object recognition. In Proceedings of the 2008 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Fujino, A.; Ueda, N.; Saito, K. Semisupervised Learning for a Hybrid Generative/Discriminative Classifier based on the Maximum Entropy Principle. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 424–437. [Google Scholar] [CrossRef]
- Fan, Q.; Wang, Z.; Li, D.; Gao, D.; Zha, H. Entropy-based fuzzy support vector machine for imbalanced datasets. Knowl. Based Syst. 2017, 115, 87–99. [Google Scholar] [CrossRef]
- Ramos, D.; Franco-Pedroso, J.; Lozano-Diez, A.; Gonzalez-Rodriguez, J. Deconstructing Cross-Entropy for Probabilistic Binary Classifiers. Entropy 2018, 20, 208. [Google Scholar] [CrossRef] [Green Version]
- Berezinski, P.; Jasiul, B.; Szpyrka, M. An Entropy-Based Network Anomaly Detection Method. Entropy 2015, 17, 2367–2408. [Google Scholar] [CrossRef]
- Fukunaga, K. Introduction to Statistic al Pattern Recognition, 2nd ed.; Academic Press: Cambridge, MA, USA, 1990. [Google Scholar]
- Tumer, K.; Ghosh, J. Estimating the Bayes error rate through classifier combining. In Proceedings of the 13th International Conference on Pattern Recognition, Vienna, Austria, 25–29 August 1996; Volume 2, pp. 695–699. [Google Scholar]
- Costa, E.P.; Lorena, A.C.; Carvalho, A.C.; Freitas, A.A. A Review of Performance Evaluation Measures for Hierarchical Classifiers. In Proceedings of the AAAI-07 Workshop Evaluation Methods for Machine Learning II, Vancouver, BC, Canada, 22–23 July 2007. [Google Scholar]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Ferri, C.; Hernández-Orallo, J.; Modroiu, R. An experimental comparison of performance measures for classification. Pattern Recognit. Lett. 2009, 30, 27–38. [Google Scholar] [CrossRef]
- Parker, C. An Analysis of Performance Measures for Binary Classifiers. In Proceedings of the 2011 IEEE 11th International Conference on Data Mining, Vancouver, BC, Canada, 11–14 December 2011; pp. 517–526. [Google Scholar]
- Labatut, V.; Cherifi, H. Evaluation of Performance Measures for Classifiers Comparison, Computer Science, Machine Learning. arXiv 2011, arXiv:1112.4133. [Google Scholar]
- Jiao, Y.; Du, P. Performance measures in evaluating machine learning based bioinformatics predictors for classifications. Quant. Biol. 2016, 4, 320–330. [Google Scholar] [CrossRef] [Green Version]
- Valverde-Albacete, F.J.; Peláez-Moreno, C. Two information-theoretic tools to assess the performance of multi-class classifiers. Pattern Recognit. Lett. 2010, 31, 1665–1671. [Google Scholar] [CrossRef] [Green Version]
- Valverde-Albacete, F.J.; Peláez-Moreno, C. 100% Classification Accuracy Considered Harmful: The Normalized Information Transfer Factor Explains the Accuracy Paradox. PLoS ONE 2014, 9, e84217. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Valverde-Albacete, F.J.; Peláez-Moreno, C. The evaluation of data sources using multivariate entropy tools. Expert Syst. Appl. 2017, 78, 145–157. [Google Scholar] [CrossRef]
- Valverde-Albacete, F.J.; Peláez-Moreno, C. A Framework for Supervised Classification Performance Analysis with Information-Theoretic Methods. IEEE Trans. Knowl. Data Eng. 2020, 32, 2075–2087. [Google Scholar] [CrossRef]
- Cohen, J. A Coefficient of Agreement for Nominal Scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Scott, W.A. Reliability of Content Analysis: The Case of Nominal Scale Coding. Public Opin. Q. 1955, 19, 321–325. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E. Data Mining: Practical Machine Learning Tools and Techniques with Java Implementations; Elsevier: Amsterdam, The Netherlands, 2005. [Google Scholar]
- Goodman, L.A.; Kruskal, W.H. Measures of Association for Cross Classifications. J. Am. Stat. Assoc. 1954, XLIX, 732–764. [Google Scholar]
- Williams, P.L.; Beer, R.D. Nonnegative Decomposition of Multivariate Information. arXiv 2010, arXiv:1004.2515v1. [Google Scholar]
- Yadav, A.K.; Chandel, S.S. Solar energy potential assessment of western Himalayan Indian state of Himachal Pradesh using J48 algorithm of WEKA in ANN based prediction model. Renew. Energy 2015, 75, 675–693. [Google Scholar] [CrossRef]
- Alloghani, M.; Aljaaf, A.; Hussain, A.; Baker, T.; Mustafina, J.; Al-Jumeily, D.; Khalaf, M. Implementation of machine learning algorithms to create diabetic patient re-admission profiles. BMC Med. Inform. Decis. Mak. 2019, 19, 253. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Romeo, V.; Cuocolo, R.; Ricciardi, C.; Ugga, L.; Cocozza, S.; Verde, F.; Stanzione, A.; Napolitano, V.; Russo, D.; Improta, G.; et al. Prediction of Tumor Grade and Nodal Status in Oropharyngeal and Oral Cavity Squamous-cell Carcinoma Using a Radiomic Approach. Anticancer. Res. 2020, 40, 271–280. [Google Scholar] [CrossRef]
- Frank, E.; Hall, M.A.; Witten, I.H. “The WEKA Workbench,” Online Appendix for “Data Mining: Practical Machine Learning Tools and Techniques”, 4th ed.; Morgan Kaufmann Publishers: Burlington, MA, USA, 2016. [Google Scholar]
- Weka. Available online: http://ocw.uc3m.es/ingenieria-informatica/herramientas-de-la-inteligencia-artificial/contenidos/transparencias/TutorialWeka.pdf (accessed on 9 March 2020).
- Waikato Environment for Knowledge Analysis (Weka). Available online: http://www.cs.waikato.ac.nz/ml/weka (accessed on 15 June 2021).
- Platt, J. Fast Training of Support Vector Machines using Sequential Minimal Optimization. In Advances in Kernel Methods—Support Vector Learning; Schoelkopf, B., Burges, C., Smola, A., Eds.; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Keerthi, S.S.; Shevade, S.K.; Bhattacharyya, C.; Murthy, K.R.K. Improvements to Platt’s SMO Algorithm for SVM Classifier Design. Neural Comput. 2001, 13, 637–649. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R. Classification by Pairwise Coupling. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Dua, D.; Graff, C. UCI Machine Learning Repository. University of California, Irvine, School of Information and Computer Sciences. 2019. Available online: http://archive.ics.uci.edu/ml (accessed on 23 April 2021).
- Available online: http://archive.ics.uci.edu/ml/datasets/Thyroid+disease (accessed on 23 April 2021).
- Shinmoto Torres, R.L.; Ranasinghe, D.C.; Shi, Q.; Sample, A.P. Sensor enabled wearable RFID technology for mitigating the risk of falls near beds. In Proceedings of the 2013 IEEE International Conference on RFID, Johor Bahru, Malaysia, 30 April–2 May 2013; pp. 191–198. [Google Scholar]
- Available online: https://archive.ics.uci.edu/ml/datasets/Activity+recognition+with+healthy+older+people+using+a+batteryless+wearable+sensor (accessed on 23 April 2021).
- de Stefano, C.; Maniaci, M.; Fontanella, F.; di Freca, A.S. Reliable writer identification in medieval manuscripts through page layout features: The “Avila” Bible case. Eng. Appl. Artif. Intell. 2018, 72, 99–110. [Google Scholar] [CrossRef]
- Available online: https://archive.ics.uci.edu/ml/datasets/Avila (accessed on 23 April 2021).
- Available online: https://archive.ics.uci.edu/ml/datasets/adult (accessed on 23 April 2021).
- Available online: https://archive.ics.uci.edu/ml/datasets/nursery (accessed on 23 April 2021).
- Moro, S.; Cortez, P.; Rita, P. A Data-Driven Approach to Predict the Success of Bank Telemarketing. Decis. Support Syst. 2014, 62, 22–31. [Google Scholar] [CrossRef] [Green Version]
- Available online: https://archive.ics.uci.edu/ml/datasets/Bank+Marketing (accessed on 23 April 2021).
- RLyon, J.; Stappers, B.W.; Cooper, S.; Brooke, J.M.; Knowles, J.D. Fifty Years of Pulsar Candidate Selection: From simple filters to a new principled real-time classification approach. Mon. Not. R. Astron. Soc. 2016, 459, 1104–1123. [Google Scholar]
- Lyon, R.J. HTRU2. Available online: https://doi.org/10.6084/m9.figshare.3080389.v1 (accessed on 23 April 2021).
- Available online: https://archive.ics.uci.edu/ml/datasets/HTRU2 (accessed on 23 April 2021).
- Available online: https://archive.ics.uci.edu/ml/datasets/Connect-4 (accessed on 23 April 2021).
- Available online: https://archive.ics.uci.edu/ml/datasets/Tic-Tac-Toe+Endgame (accessed on 23 April 2021).
- Available online: https://archive.ics.uci.edu/ml/datasets/Credit+Approval (accessed on 23 April 2021).
- Available online: https://archive.ics.uci.edu/ml/datasets/mushroom (accessed on 23 April 2021).
- Brown, G.; Pocock, A.; Zhao, M.-J.; Luján, M. Conditional Likelihood Maximisation: A Unifying Framework for Information Theoretic Feature Selection. J. Mach. Learn. Res. 2012, 13, 27–66. [Google Scholar]

| Scenario | Positive | Negative | Total | Ratio Positive/Negative | Consequent’s Entropy |
|---|---|---|---|---|---|
| S1 | 2400 | 800 | 3200 | 3:1 | 0.811 |
| S2 | 2400 | 1200 | 3600 | 2:1 | 0.918 |
| S3 | 2400 | 2400 | 4800 | 1:1 | 1.000 |
| S4 | 2000 | 4000 | 6000 | 1:2 | 0.918 |
| S5 | 2000 | 6000 | 8000 | 1:3 | 0.811 |
| Dataset | # Rows | # Attributes | # Classes | Distribution of the Classes |
|---|---|---|---|---|
| Thyroid | 9173 | 23 2 categorical 21 binary | 2 | 2401, 6772 |
| Healthy | 75,128 | 10 8 real 1 binary 1 categorical | 4 | 16406, 4911, 51520, 2291 |
| Avila | 20,867 | 11 10 real 1 categorical | 12 | 8572, 10, 206, 705, 2190, 3923, 893, 1039, 1663, 89, 1044, 533 |
| Adult | 32,561 | 12 3 real 1 integer 6 categorical 2 binary | 2 | 7841, 24720 |
| Nursery | 12,960 | 9 8 categorical 1 binary | 5 | 4320, 4266, 24044, 328 |
| Bank | 45,211 | 11 1 real 1 integer 5 categorical 4 binary | 2 | 39922, 5289 |
| HTRU2 | 17,898 | 9 8 real 1 binary | 2 | 16259, 1639 |
| Connect-4 | 67,557 | 43 43 categorical | 3 | 6449, 16635, 44473 |
| Tic-tac-toe | 958 | 10 9 categorical 1 binary | 2 | 332, 626 |
| Credit | 690 | 10 5 categorical 5 binary | 2 | 383, 307 |
| Mushroom | 8124 | 23 17 categorical 6 binary | 2 | 4208, 3916 |
| Attributes | S1 | S2 | S3 | S4 | S5 |
|---|---|---|---|---|---|
| 0.036 | 0.050 | 0.083 | 0.122 | 0.102 | |
| 0.037 | 0.037 | 0.082 | 0.076 | 0.134 | |
| 0.033 | 0.034 | 0.028 | 0.020 | 0.016 | |
| 0.034 | 0.032 | 0.028 | 0.015 | 0.013 | |
| 0.029 | 0.022 | 0.026 | 0.013 | 0.010 |
| Comb. | Antecedents | Comb. | Antecedents | Comb. | Antecedents |
|---|---|---|---|---|---|
| #1 | #12 | #23 | |||
| #2 | #13 | #24 | |||
| #3 | #14 | #25 | |||
| #4 | #15 | #26 | |||
| #5 | #16 | #27 | |||
| #6 | #17 | #28 | |||
| #7 | #18 | #29 | |||
| #8 | #19 | #30 | |||
| #9 | #20 | #31 | |||
| #10 | #21 | ||||
| #11 | #22 |
| Scenario | ||||
|---|---|---|---|---|
| S1 | 0.6250 | 0.7500 ± 0.2500 | 0.7489 ± 0.3739 | 0.7481 ± 0.2519 |
| S2 | 0.5556 | 0.6667 ± 0.3333 | 0.6724 ± 0.4358 | 0.6729 ± 0.3271 |
| S3 | 0.5000 | 0.5000 ± 0.5000 | 0.5241 ± 0.4856 | 0.4835 ± 0.5165 |
| S4 | 0.5556 | 0.6667 ± 0.3333 | 0.6751 ± 0.4366 | 0.6766 ± 0.3234 |
| S5 | 0.6250 | 0.7465 ± 0.2535 | 0.7543 ± 0.3734 | 0.7537 ± 0.2487 |
| Scenario | J48 wins | wins | J48 wins | wins | wins | wins |
|---|---|---|---|---|---|---|
| S1 | 10.42 | 41.71 | 46.03 | 23.94 | 18.39 | 58.13 |
| S2 | 67.65 | 15.65 | 24.48 | 37.39 | 74.90 | 13.29 |
| S3 | 97.55 | 0.16 | 73.48 | 4.45 | 32.52 | 66.90 |
| S4 | 78.13 | 0.26 | 16.52 | 42.19 | 84.52 | 0.00 |
| S5 | 98.03 | 1.23 | 76.90 | 15.16 | 97.29 | 2.00 |
| Average % | 70.36 | 11.80 | 47.48 | 24.63 | 61.52 | 28.06 |
| Scenario | |||||
|---|---|---|---|---|---|
| S1 | 0.3303–0.3333 | 0.3282–0.3333 | −0.0015–0.0000 | −0.0025–0.0000 | 0.0000–0.0032 |
| S2 | 0.2499–0.2636 | 0.2498–0.2650 | −0.0001–0.0182 | −0.0001–0.0200 | −0.0009–0.0001 |
| S3 | 0.0004–0.0492 | −0.0903–0.0419 | 0.0004–0.0492 | −0.0903–0.0419 | 0.0049–0.0844 |
| S4 | 0.2500–0.2693 | 0.2500–0.2729 | 0.0000–0.0257 | 0.0000–0.0306 | −0.0026–0.0004 |
| S5 | 0.3134–0.3635 | 0.3125–0.3627 | −0.0087–0.0524 | −0.0091–0.0512 | 0.0010–0.0027 |
| # | Dataset | 1st | 2nd | 3rd | 4th | 5th |
|---|---|---|---|---|---|---|
| 1 | Thyroid | hypopit. | pregnant | psych | goitre | referral_ |
| source | ||||||
| 2 | Healthy | C4 | C3 | C6 | C5 | C7 |
| 3 | Avila | F5 | F1 | F9 | F3 | F7 |
| 4 | Adult | Mar.Sta. | Relat. | Sex | Age | Educ |
| 5 | Nursery | F2 | F1 | F7 | F5 | F4 |
| 6 | Bank | poutcome | contact | housing | month | loan |
| 7 | HTRU2 | A3 | A1 | A4 | A6 | A5 |
| 8 | Connect-4 | g6 | d3 | f6 | d2 | b6 |
| 9 | Tic-tac-toe | m-m-s | b-l-s | t-l-s | t-r-s | b-r-s |
| 10 | Credit | A9 | A10 | A4 | A5 | A6 |
| 11 | Mushroom | odor | gill-size | stalk-surface- | spore-print- | ring-type |
| above-ring | color |
| # | Dataset | J48 | SMO | Naïve Bayes | Random Forest | |
|---|---|---|---|---|---|---|
| 1 | Thyroid | 0.743 ± 0.257 | 0.744 ± 0.381 | 0.743 ± 0.257 | 0.741 ± 0.373 | 0.743 ± 0.374 |
| 2 | Healthy | 0.953 ± 0.024 | 0.963 ± 0.030 | 0.949 ± 0.255 | 0.935 ± 0.042 | 0.963 ± 0.028 |
| 3 | Avila | 0.653 ± 0.058 | 0.666 ± 0.074 | 0.600 ± 0.141 | 0.610 ± 0.087 | 0.657 ± 0.069 |
| 4 | Adult | 0.825 ± 0.175 | 0.824 ± 0.250 | 0.818 ± 0.182 | 0.763 ± 0.240 | 0.824 ± 0.236 |
| 5 | Nursery | 0.508 ± 0.197 | 0.548 ± 0.224 | 0.508 ± 0.265 | 0.531 ± 0.233 | 0.508 ± 0.224 |
| 6 | Bank | 0.885 ± 0.115 | 0.894 ± 0.186 | 0.893 ± 0.107 | 0.890 ± 0.175 | 0.893 ± 0.167 |
| 7 | HTRU2 | 0.971 ± 0.029 | 0.971 ± 0.049 | 0.969 ± 0.031 | 0.969 ± 0.050 | 0.971 ± 0.048 |
| 8 | Connect-4 | 0.658 ± 0.228 | 0.665 ± 0.313 | 0.665 ± 0.318 | 0.663 ± 0.318 | 0.665 ± 0.311 |
| 9 | Tic-tac-toe | 0.801 ± 0.193 | 0.794 ± 0.258 | 0.753 ± 0.247 | 0.753 ± 0.374 | 0.840 ± 0.209 |
| 10 | Credit | 0.859 ± 0.141 | 0.862 ± 0.220 | 0.858 ± 0.142 | 0.861 ± 0.193 | 0.848 ± 0.199 |
| 11 | Mushroom | 1.000 ± 0.000 | 1.000 ± 0.000 | 0.999 ± 0.001 | 0.999 ± 0.020 | 1.000 ± 0.000 |
| # | Dataset | Entropy | |||||
|---|---|---|---|---|---|---|---|
| 1 | Thyroid | 0.829 | 0.335 | 0.338 | 0.335 | 0.330 | 0.335 |
| 2 | Healthy | 0.632 | 0.901 | 0.922 | 0.893 | 0.864 | 0.922 |
| 3 | Avila | 0.737 | 0.549 | 0.566 | 0.480 | 0.493 | 0.554 |
| 4 | Adult | 0.796 | 0.521 | 0.519 | 0.502 | 0.352 | 0.519 |
| 5 | Nursery | 0.739 | 0.279 | 0.338 | 0.279 | 0.313 | 0.279 |
| 6 | Bank | 0.521 | 0.443 | 0.487 | 0.482 | 0.468 | 0.482 |
| 7 | HTRU2 | 0.442 | 0.826 | 0.826 | 0.814 | 0.814 | 0.826 |
| 8 | Connect-4 | 0.769 | 0.312 | 0.326 | 0.326 | 0.322 | 0.326 |
| 9 | Tic-tac-toe | 0.931 | 0.561 | 0.545 | 0.455 | 0.455 | 0.647 |
| 10 | Credit | 0.991 | 0.715 | 0.721 | 0.713 | 0.719 | 0.692 |
| 11 | Mushroom | 0.999 | 1.000 | 1.000 | 0.998 | 0.998 | 1.000 |
| # | Dataset | acc() | |||||
|---|---|---|---|---|---|---|---|
| 1 | Thyroid | 0.738 | 0.018 | 0.022 | 0.018 | 0.011 | 0.018 |
| 2 | Healthy | 0.686 | 0.850 | 0.882 | 0.838 | 0.793 | 0.882 |
| 3 | Avila | 0.411 | 0.411 | 0.433 | 0.321 | 0.338 | 0.418 |
| 4 | Adult | 0.759 | 0.273 | 0.269 | 0.244 | 0.016 | 0.269 |
| 5 | Nursery | 0.333 | 0.262 | 0.322 | 0.262 | 0.297 | 0.262 |
| 6 | Bank | 0.883 | 0.017 | 0.094 | 0.085 | 0.060 | 0.085 |
| 7 | HTRU2 | 0.908 | 0.683 | 0.683 | 0.661 | 0.661 | 0.683 |
| 8 | Connect-4 | 0.658 | 0.000 | 0.020 | 0.020 | 0.014 | 0.020 |
| 9 | Tic-tac-toe | 0.653 | 0.426 | 0.406 | 0.287 | 0.287 | 0.538 |
| 10 | Credit | 0.555 | 0.683 | 0.690 | 0.681 | 0.688 | 0.658 |
| 11 | Mushroom | 0.518 | 1.000 | 1.000 | 0.998 | 0.998 | 1.000 |
| # | Dataset | ||||
|---|---|---|---|---|---|
| 1 | Thyroid | 0.004 | 0.000 | −0.003 | 0.000 |
| 2 | Healthy | 0.213 | −0.004 | −0.019 | 0.213 |
| 3 | Avila | 0.037 | −0.081 | −0.066 | 0.012 |
| 4 | Adult | −0.001 | −0.008 | −0.075 | −0.001 |
| 5 | Nursery | 0.081 | 0.000 | 0.047 | 0.000 |
| 6 | Bank | 0.078 | 0.070 | 0.043 | 0.070 |
| 7 | HTRU2 | 0.000 | −0.002 | −0.002 | 0.000 |
| 8 | Connect-4 | 0.020 | 0.020 | 0.015 | 0.020 |
| 9 | Tic-tac-toe | −0.009 | −0.060 | −0.060 | 0.196 |
| 10 | Credit | 0.021 | −0.001 | 0.014 | −0.013 |
| 11 | Mushroom | 0.000 | −0.001 | −0.001 | 0.000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Orenes, Y.; Rabasa, A.; Rodriguez-Sala, J.J.; Sanchez-Soriano, J. Benchmarking Analysis of the Accuracy of Classification Methods Related to Entropy. Entropy 2021, 23, 850. https://doi.org/10.3390/e23070850
Orenes Y, Rabasa A, Rodriguez-Sala JJ, Sanchez-Soriano J. Benchmarking Analysis of the Accuracy of Classification Methods Related to Entropy. Entropy. 2021; 23(7):850. https://doi.org/10.3390/e23070850
Chicago/Turabian StyleOrenes, Yolanda, Alejandro Rabasa, Jesus Javier Rodriguez-Sala, and Joaquin Sanchez-Soriano. 2021. "Benchmarking Analysis of the Accuracy of Classification Methods Related to Entropy" Entropy 23, no. 7: 850. https://doi.org/10.3390/e23070850
APA StyleOrenes, Y., Rabasa, A., Rodriguez-Sala, J. J., & Sanchez-Soriano, J. (2021). Benchmarking Analysis of the Accuracy of Classification Methods Related to Entropy. Entropy, 23(7), 850. https://doi.org/10.3390/e23070850