
Multifractal Behaviors of Stock Indices and Their Ability to Improve Forecasting in a Volatility Clustering Period

Abstract
:1. Introduction
2. Materials and Methods
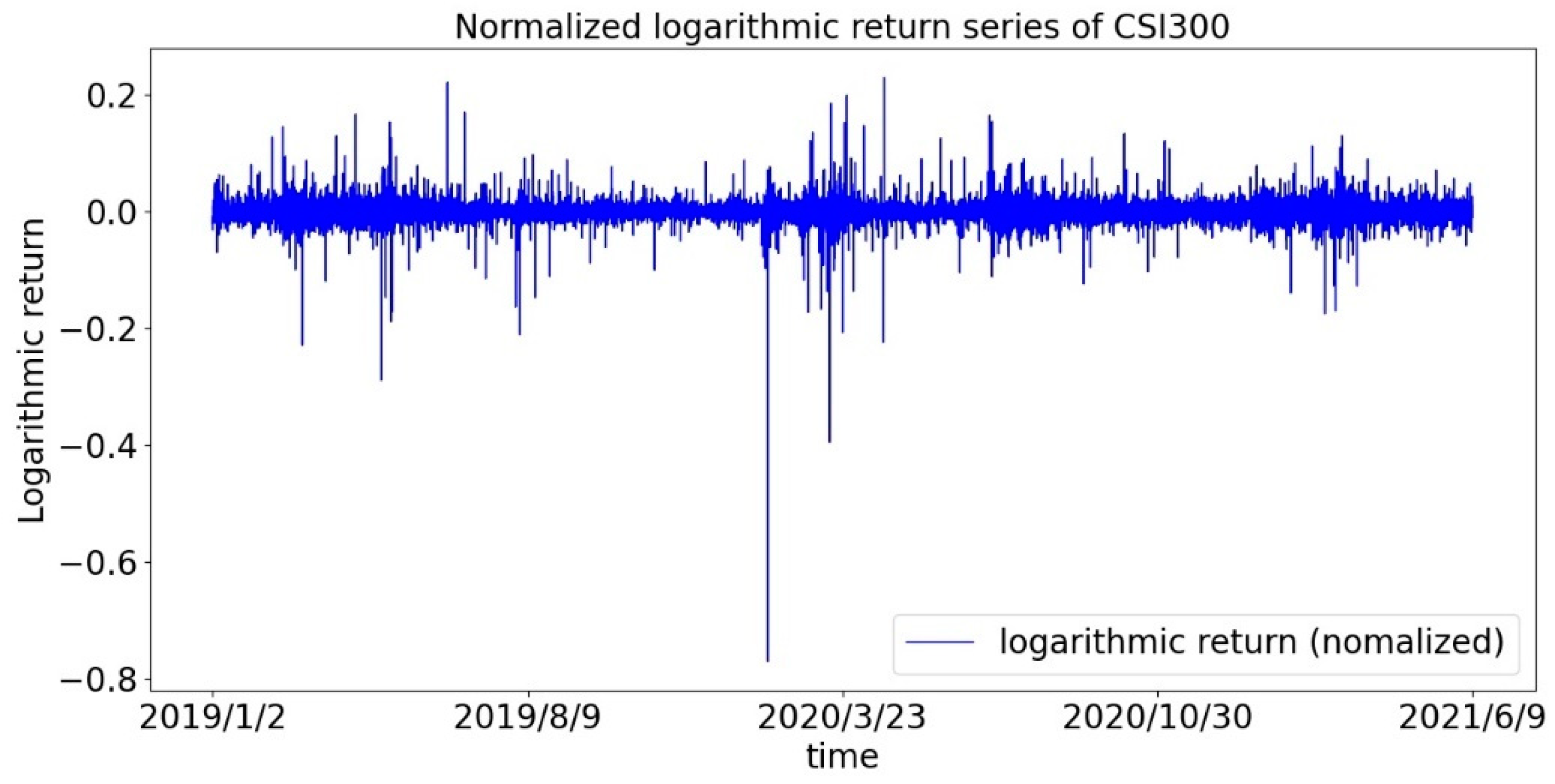
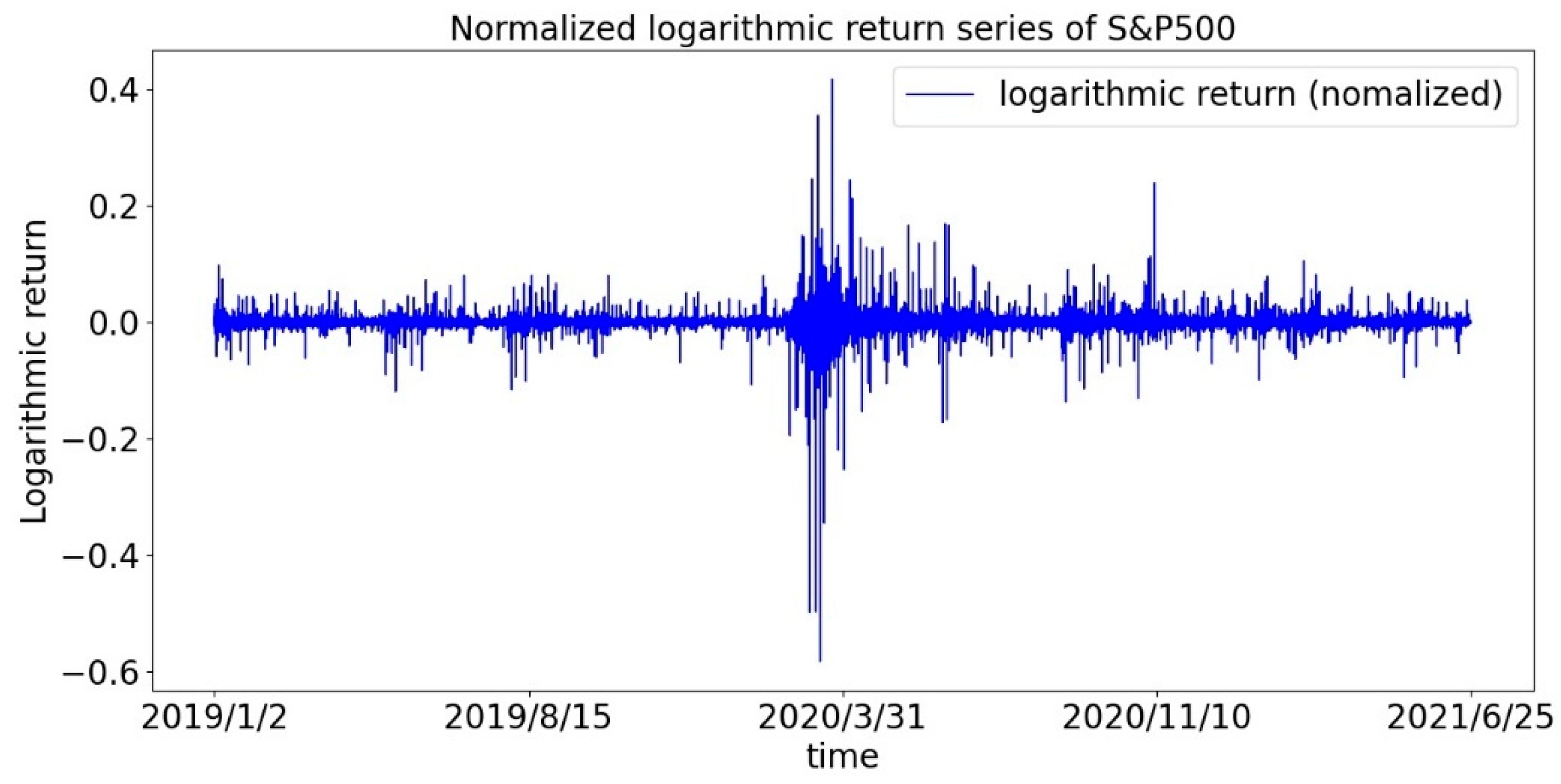
2.1. Data
- Before the pandemic: 1 January 2019–31 December 2019
- Pandemic: 1 January 2020 (the starting point of the pandemic in China)–8 April 2020 (Wuhan unblocked)
- After the first panic period of pandemic: 9 April 2020–9 June 2021
- Before the pandemic: 1 January 2019–14 February 2020 (the starting point of the market plunge)
- Pandemic: 15 February 2020–16 June 2020 (the Fed shrinks its balance sheet for the first time, which means that the policy begins to tighten)
- After the first panic period of pandemic: 17 June 2020–9 June 2021
2.2. Descriptive Statistics
- For the Chinese stock market, represented by the CSI300 Index, at each stage of the pandemic, the kurtosis of the return distribution is significantly greater than the standard value of the standard normal, indicating that the phenomenon of spikes and thick tails in the sequence always exists. Judging from the P-value of the Jarque-Bera test, the hypothesis of the standard normal distribution is strongly rejected, so, we concluded that the stock index market does not conform to the assumption of the traditional financial market, and it is necessary to study market efficiency from a fractal perspective. In addition, the pandemic has indeed had an impact on the market: (1) The coefficient of variation increased significantly during the pandemic, indicating the intensification of dispersion; (2) The skewness becomes smaller, indicating the degree of leftward deviation of the return distribution has increased; (3) kurtosis increases sharply, which indicates that the probability of extreme situations has increased, and the degree of thick tails has deepened; (4) The sum of GARCH (1,1) coefficients becomes larger, indicating that the volatility clustering effect becomes stronger. Above all, it is reasonable to assume that some features of the market have changed.
- For the US stock market, which is represented by the S&P500 Index, the spike and thick tail phenomenon and the impact of the pandemic are basically the same as the Chinese stock market, but with different degrees. There are two differences during the pandemic period: (1) The coefficient of variation of S&P 500 index increased faster and was much greater than that of CSI300 index; (2) The average return of the S&P500 index was positive, while that of the CSI300 index fell to negative.
2.3. Method of Testing Fractal: OSW-MF-DFA
- (1)
- Suppose R (i) (i = 1, 2, …, N) is a certain time series, and N is the length of the series. First calculate the mean of the series, and construct the cumulative deviation series Y(j) as follows:
- (2)
- Divide Y(j) into subintervals with a unit length of s. The length of the overlapping part of adjacent intervals is l, which is the only improvement to the original method. Combined with previous experience, the value of l is usually .
- (3)
- For each subinterval, fit the univariate linear equation by the least square method. Then eliminate the local trend of each subinterval v (v = 1,2, … Ns), and get the detrending residual sequence is the local polynomial fitted value and we choose linear univariate polynomials:
- (4)
- Calculate the square mean and -order volatility function of the residual sequence of Ns subintervals, respectively:
- (5)
- Determine the scale index of the volatility function, and get the relationship between Fq (s) and s. If Fq (s) is a power-law distribution, the following formula is satisfied when is constant:
- (a)
- h(q) does not change with the increase or decrease of q, it is a single fractal system, otherwise it is multifractal.
- (b)
- When q < 1, h(q) describes the fractal characteristics of small fluctuations; when q > 1, h(q) describes the fractal characteristics of large fluctuations; when q = 2, h(2) is the classical Hurst index, which measures long memory of the sequence as a whole.
- (c)
- h(q) > 0.5 indicates that the sequence is persistent, 0 < h(q) < 0.5 indicates anti-persistence, h(q) = 0.5 indicates that the sequence is a random walk.
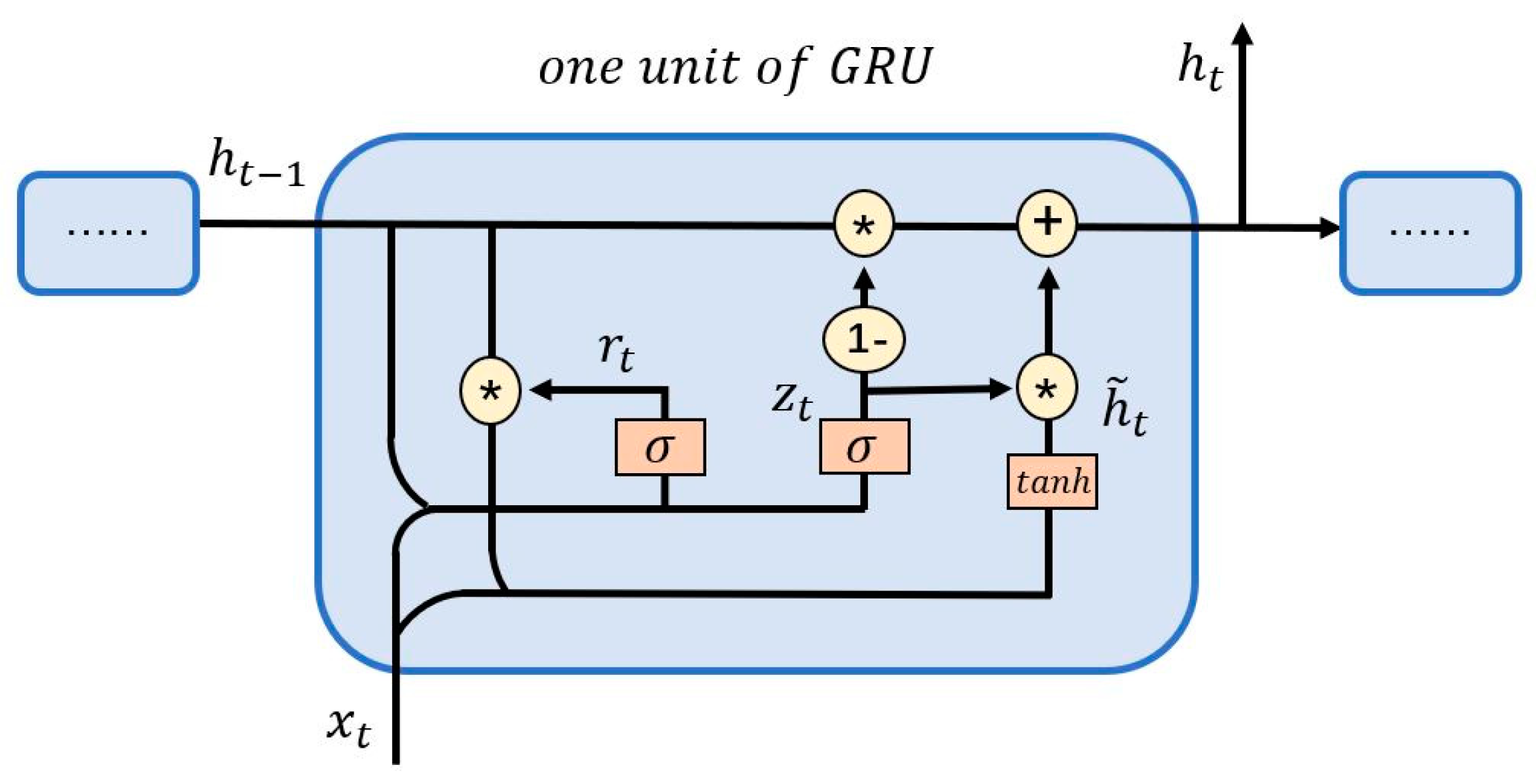
2.4. Price Prediction Model: GRU Neural Network
3. Results
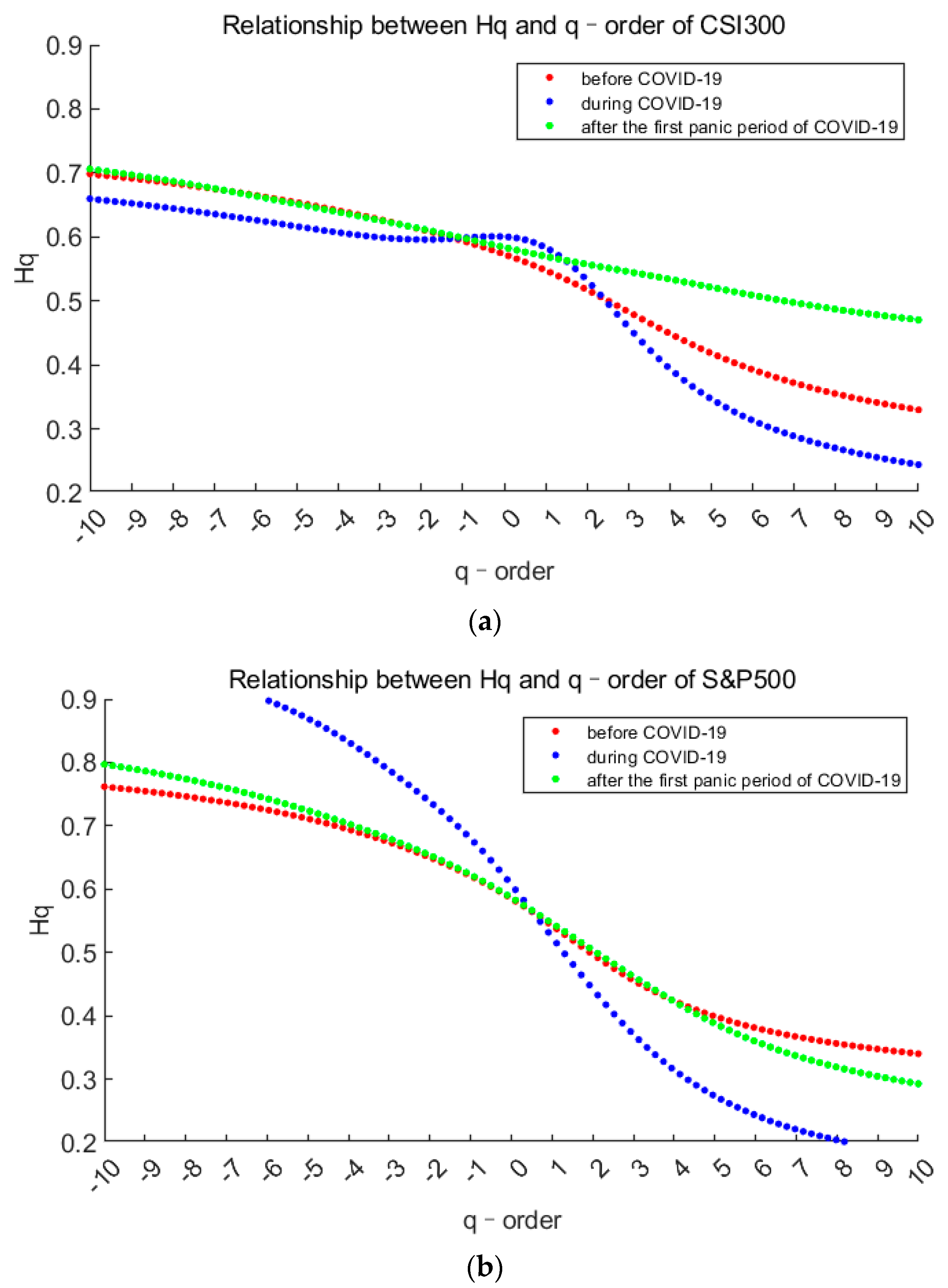
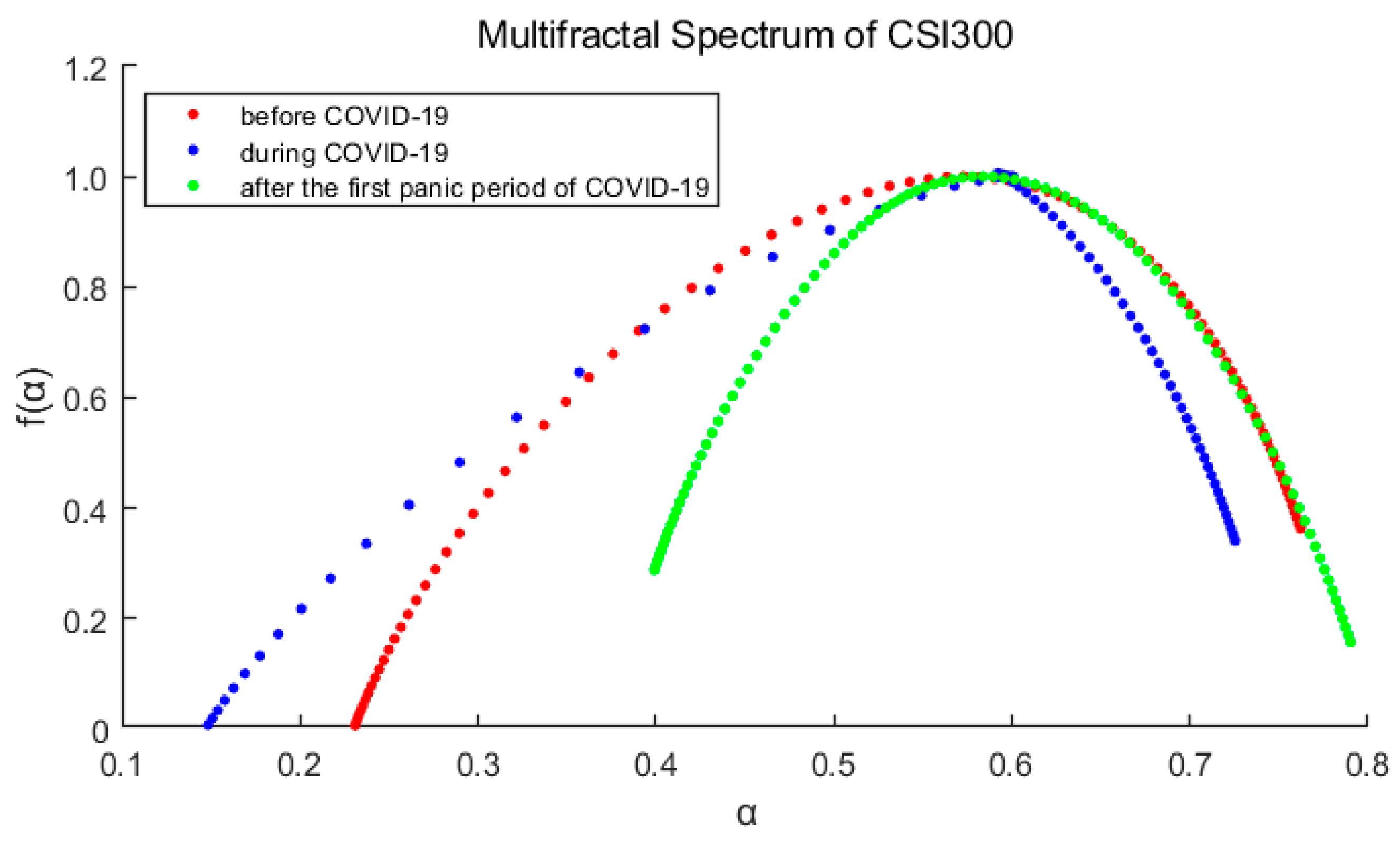
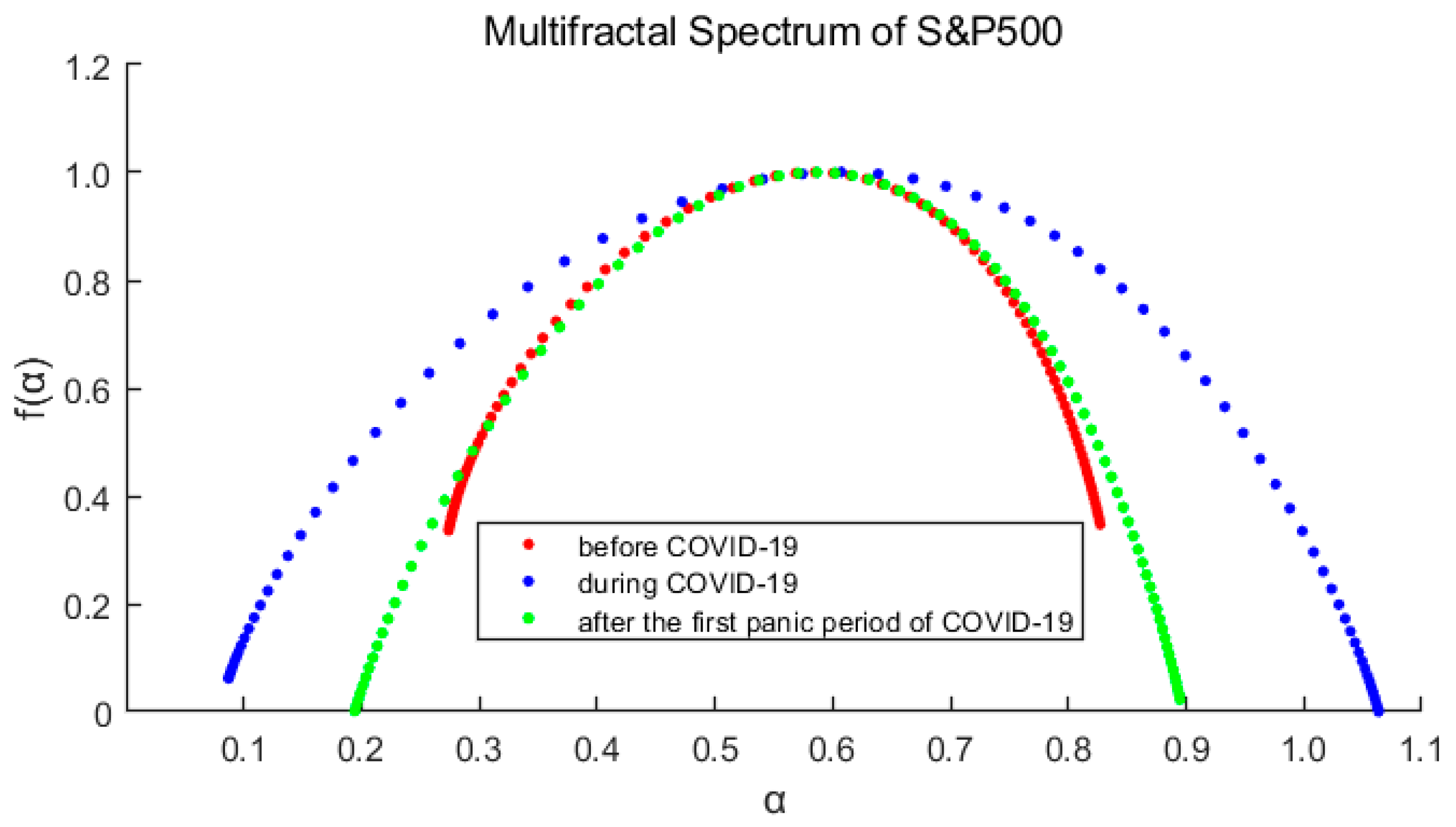
3.1. Multifractal Test
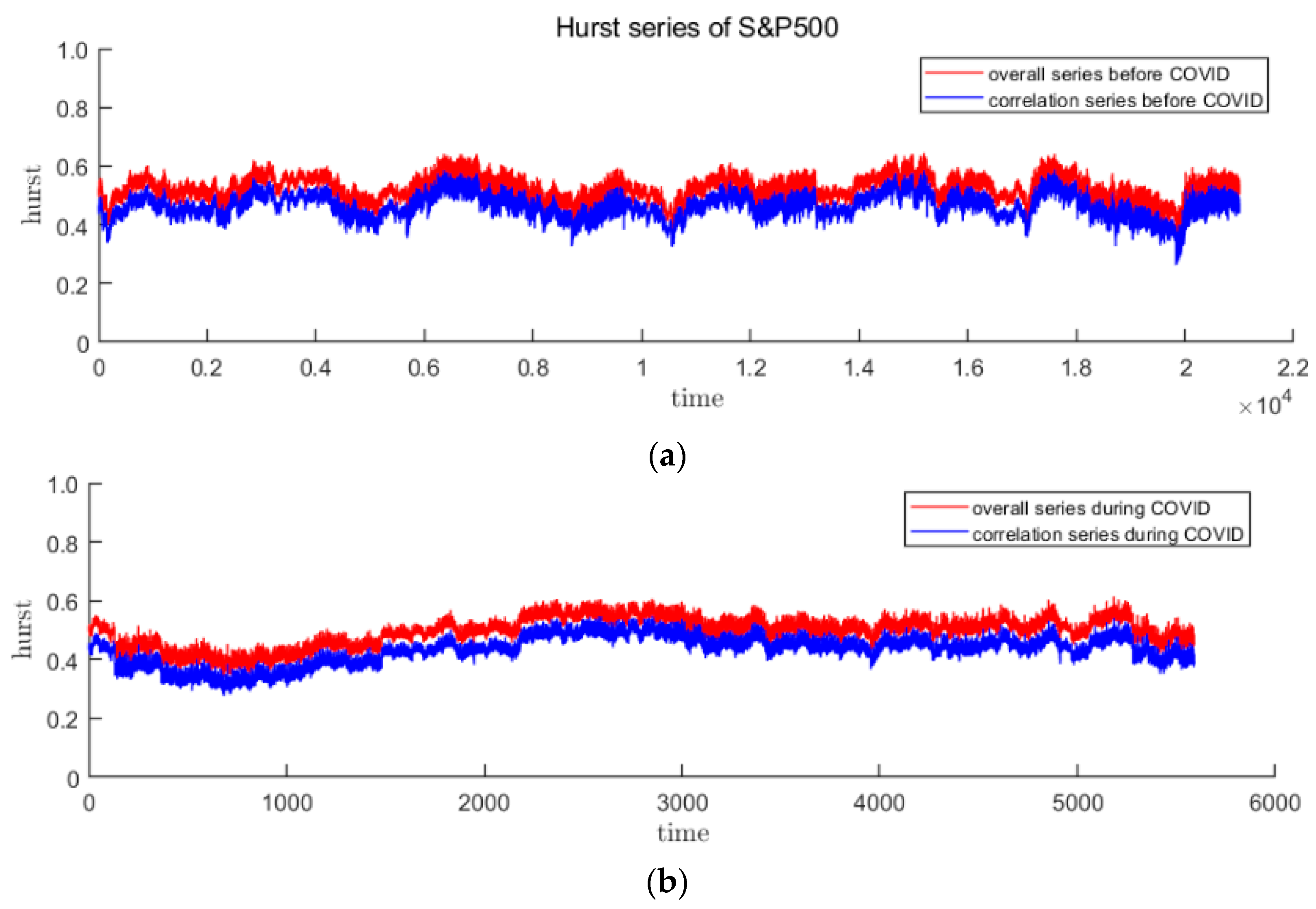
- For each market, ∆α is the largest of the three periods during the pandemic, indicates that the pandemic has intensified the multifractal degree of the market. And ∆α of S&P500 is correspondingly larger than that of CSI300, which means the higher fractal degrees of US stock market (it also means more inefficient).
- The spectrum shape of S&P500 is more symmetrical with and R closing to 0, while those of CSI300 indicate an obvious tailing phenomenon. It shows the time variability and imbalance of large and small returns in China’s stock market. Especially after the first panic period of pandemic, the long right tail of CSI300 should be paid more attention, which indicating that the proportion of large yields has increased and occupied a dominant position.
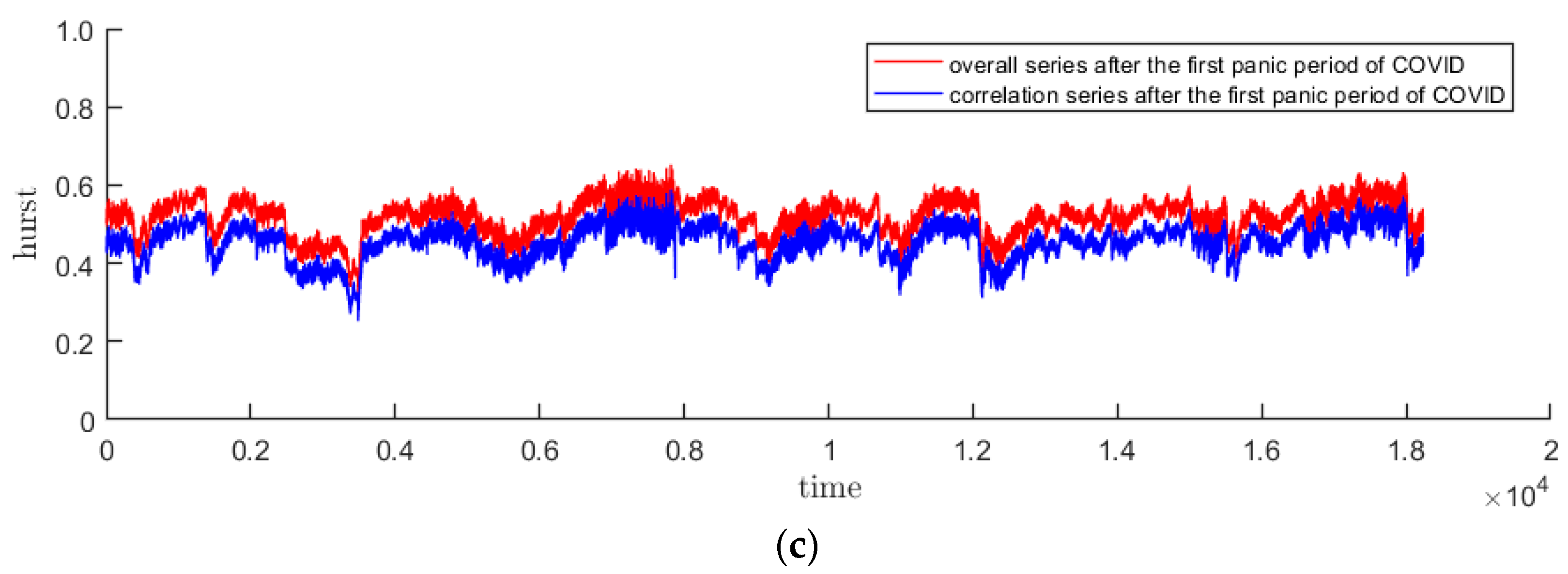
- From the above analysis, we find that the US market was more deeply impacted by the pandemic. After the first panic period of pandemic, the fractal degrees of both markets have partially recovered, which indicates that the impacts of the pandemic on the markets have not subsided, although the indices have rebounded.
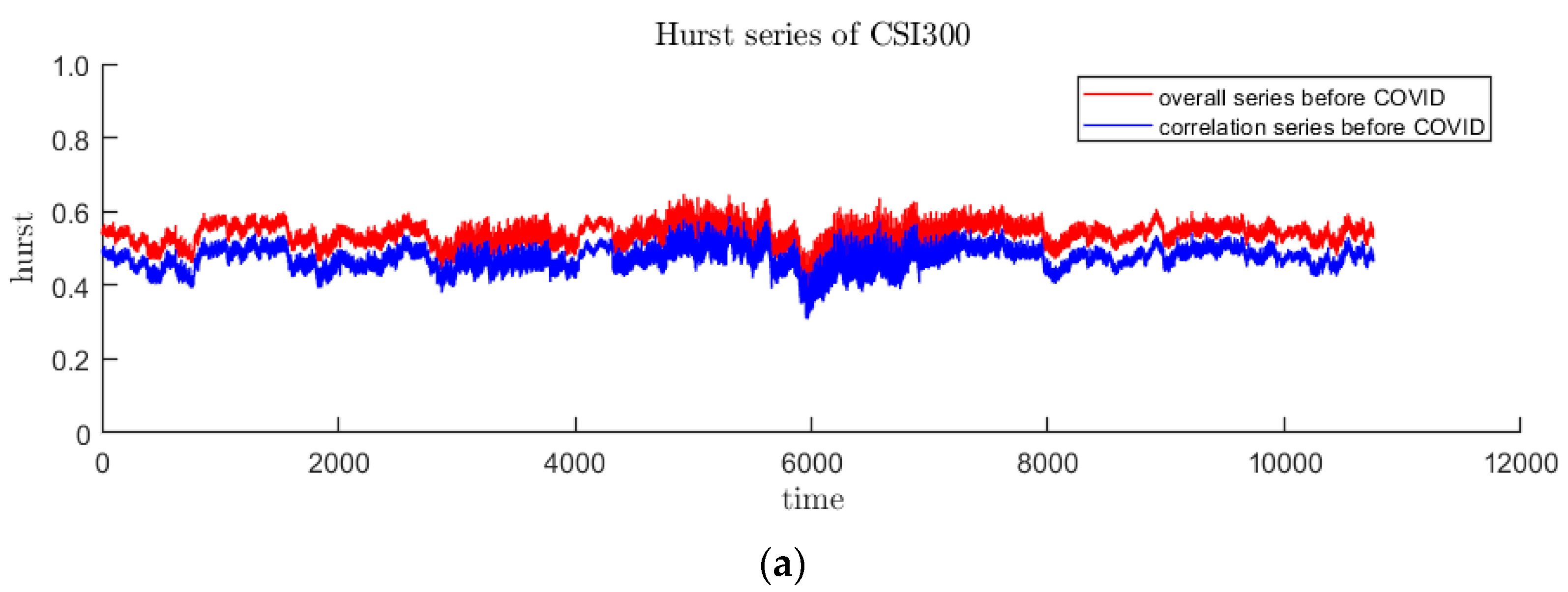
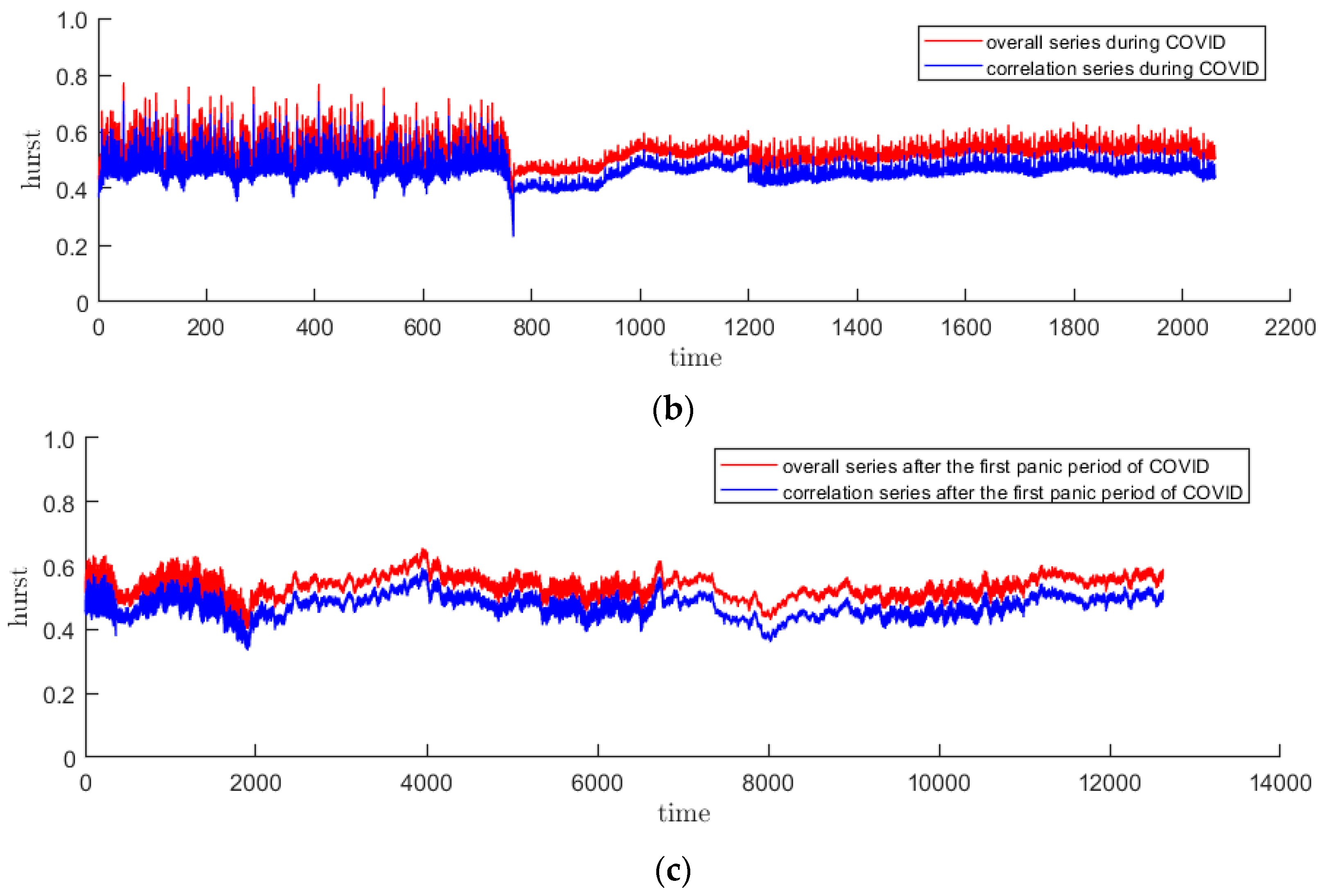
3.2. Time-Varying Hurst Sequence
3.3. Price Forecast Analysis
3.3.1. Divide the Data Sets
3.3.2. Set Parameters
3.3.3. Select Input Variables
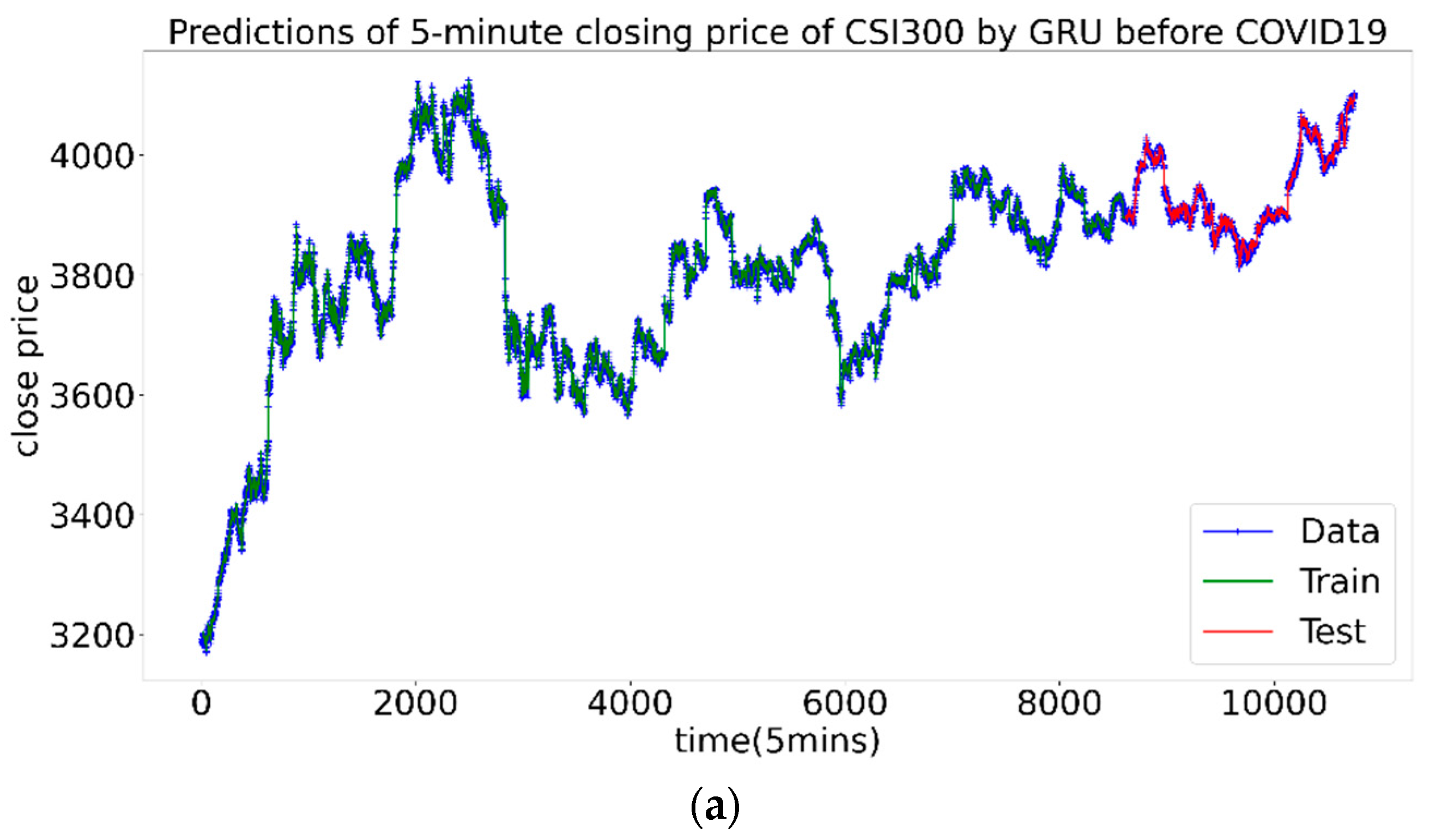
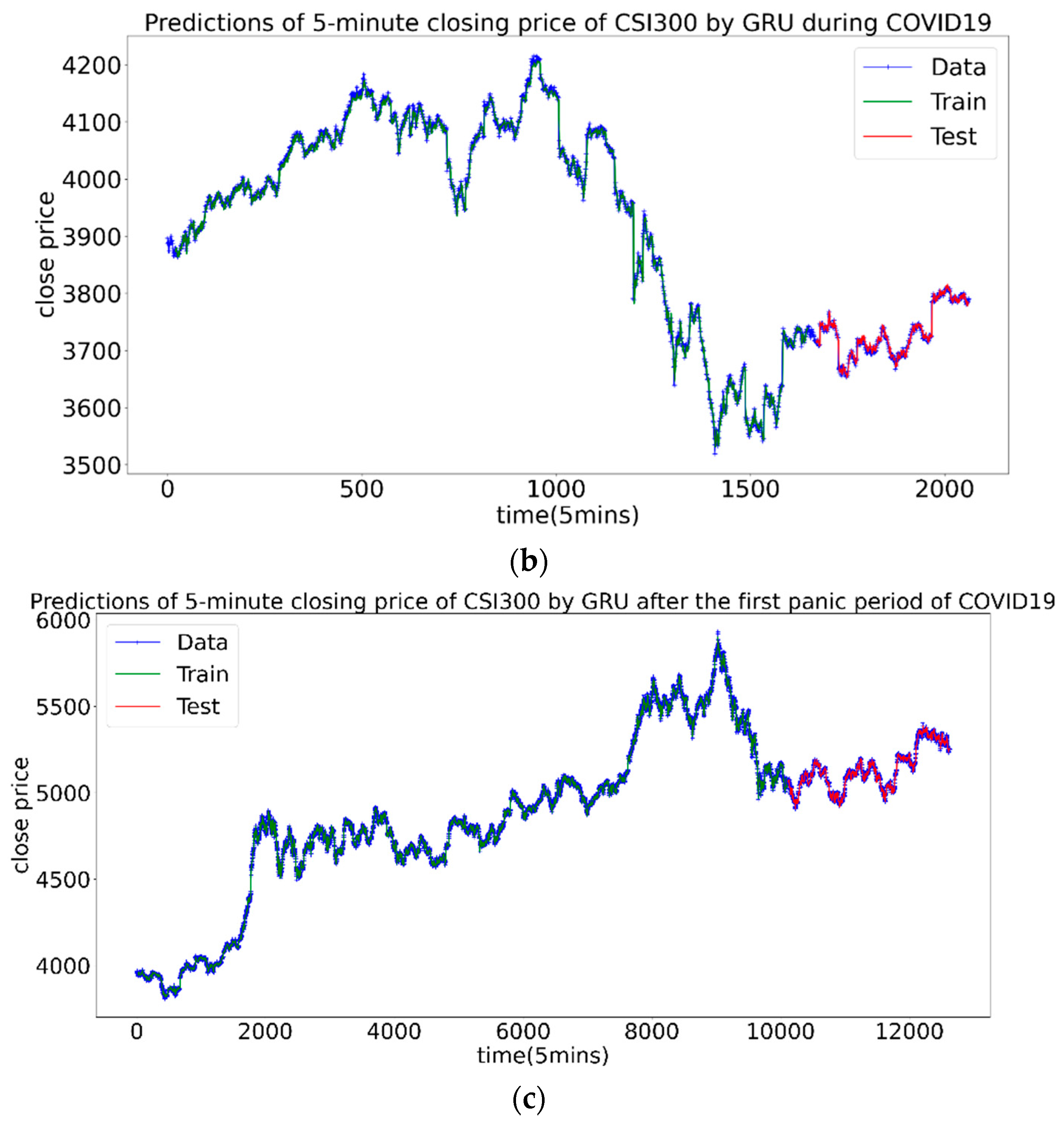
3.3.4. Forecast of CSI300 Index
- Num 1: closing price, opening price, highest price, lowest price, volatility
- Num 2: closing price, opening price, highest price, lowest price, Hurst
- Num 3: closing price, opening price, highest price, lowest price,
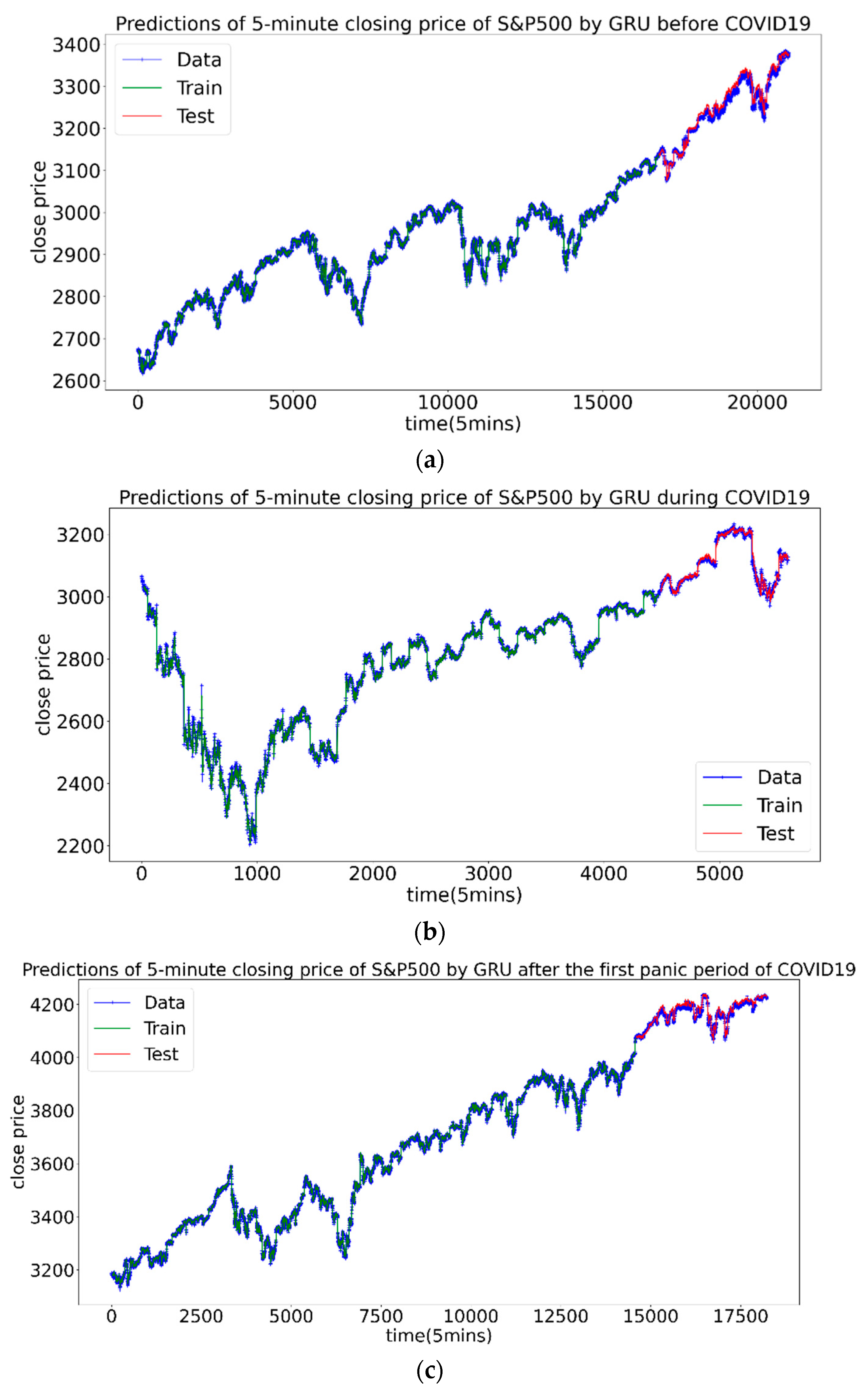
3.3.5. Forecast of S&P500 Index
4. Conclusions and Discussion
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fama, E.F. Efficient capital markets: A review of theory and empirical Work. J. Financ. 1970, 25, 383–417. [Google Scholar] [CrossRef]
- Daniel, K.; Titman, S. Market efficiency in an irrational world. Financ Anal. J. 1999, 55, 28–40. [Google Scholar] [CrossRef] [Green Version]
- Hou, K.; Moskowitz, T.J. Market frictions, price delay, and the cross-section of expected returns. Rev. Financ. Stud. 2005, 18, 981–1020. [Google Scholar] [CrossRef]
- Lee, S.; El Meslmani, N.; Switzer, L.N. Pricing Efficiency and Arbitrage in the Bitcoin Spot and Futures Markets. Res. Int. Bus. Finance 2020, 53, 101200. [Google Scholar] [CrossRef]
- Bos, J.W.D. Stock market efficiency the evidence from FTA indices of eleven major stock markets. De Econ. 1994, 142, 455–473. [Google Scholar] [CrossRef]
- Van Der Sar, N.L. Calendar effects on the Amsterdam stock exchange. De Econ. 2003, 151, 271–292. [Google Scholar]
- Bae, H.-O.; Ha, S.-Y.; Kim, Y.; Lim, Y.; Yoo, J. Volatility flocking by cucker–smale mechanism in financial markets. Asia-Pac. Financ. Mark. 2020, 27, 387–414. [Google Scholar] [CrossRef]
- Moskowitz, T.J.; Grinblatt, M. Do industries explain momentum? J. Financ. 1999, 54, 1249–1290. [Google Scholar] [CrossRef]
- Louis, H. Earnings management and the market performance of acquiring firms. J. Financ. Econ. 2004, 74, 121–148. [Google Scholar] [CrossRef]
- Peters, E. Fractal Market Analysis. Applying Chaos Theory to Investment and Analysis; Wiley: Ney York, NY, USA, 1994. [Google Scholar]
- Hurst, H.E. Long term storage capacity of reservoirs. Trans. Am. Soc. Civ. Eng. 1951, 116, 770–808. [Google Scholar] [CrossRef]
- Peng, C.-K.; Buldyrev, S.; Havlin, S.; Simons, M.; Stanley, H.E.; Goldberger, A.L. Mosaic organization of DNA nucleotides. Phys. Rev. E 1994, 49, 1685–1689. [Google Scholar] [CrossRef] [Green Version]
- Kantelhardt, J.W.; Zschiegner, S.A.; Koscielny-Bunde, E.; Havlin, S.; Bunde, A.; Stanley, H.E. Multifractal detrended fluctuation analysis of nonstationary time series. Phys. A Stat. Mech. Its Appl. 2002, 316, 87–114. [Google Scholar] [CrossRef] [Green Version]
- Thompson, J.R.; Wilson, J.R. Multifractal detrended fluctuation analysis: Practical applications to financial time series. Math. Comput. Simul. 2016, 126, 63–88. [Google Scholar] [CrossRef]
- Fang, W.; Wang, J. Statistical properties and multifractal behaviors of market returns by ising dynamic systems. Int. J. Mod. Phys. C 2012, 23, 1250023–1250037. [Google Scholar] [CrossRef]
- Pascoal, R.; Monteiro, A.M. Market efficiency, roughness and long memory in PSI20 index returns: Wavelet and entropy analysis. Entropy 2014, 16, 2768–2788. [Google Scholar] [CrossRef] [Green Version]
- Han, C.Y.; Wang, Y.M.; Ning, Y. Analysis and comparison of the multifractality and efficiency of Chinese stock market: Evidence from dynamics of major indexes in different boards. Phys. A Stat. Mech. Its Appl. 2019, 528, 121305. [Google Scholar] [CrossRef]
- Tiwari, A.K.; Aye, G.C.; Gupta, R. Stock market efficiency analysis using long spans of Data: A multifractal detrended fluctuation approach. Financ. Res. Lett. 2019, 28, 398–411. [Google Scholar] [CrossRef] [Green Version]
- Ge, X.; Lin, A. Multiscale multifractal detrended partial cross-correlation analysis of Chinese and American stock markets. Chaos Solitons Fractals 2021, 145, 110731. [Google Scholar] [CrossRef]
- Wang, H.Y.; Wang, T.T. Multifractal analysis of the Chinese stock, bond and fund markets. Phys. A Stat. Mech. Appl. 2018, 512, 280–292. [Google Scholar] [CrossRef]
- Fang, W.; Tian, S.; Wang, J. Multiscale fluctuations and complexity synchronization of Bitcoin in China and US markets. Phys. A Stat. Mech. Appl. 2018, 512, 109–120. [Google Scholar] [CrossRef]
- Bashan, A.; Bartsch, R.; Kantelhardt, J.W.; Havlin, S. Comparison of detrending methods for fluctuation analysis. Phys. A Stat. Mech. Appl. 2008, 387, 5080–5090. [Google Scholar] [CrossRef] [Green Version]
- Tang, Y.; Zhu, P.F. Research of long memory, risk and efficiency of bull and bear based on CSI300 index futures: From the perspective of multifractality. Mange. Rev. 2019, 8, 59–70. [Google Scholar]
- Rak, R.; Zieba, P. Multifractal flexibly detrended fluctuation analysis. Acta Phys. Pol. B 2015, 46, 1925. [Google Scholar] [CrossRef] [Green Version]
- Aslam, F.; Mohti, W.; Ferreira, P. Evidence of intraday multifractality in european stock markets during the recent Coronavirus (COVID-19) outbreak. Int. J. Financial Stud. 2020, 8, 31. [Google Scholar] [CrossRef]
- Naeem, M.A.; Farid, S.; Ferrer, R.; Shahzad, S.J.H. Comparative efficiency of green and conventional bonds pre- and during COVID-19: An asymmetric multifractal detrended fluctuation analysis. Energy Policy 2021, 153, 112285. [Google Scholar] [CrossRef]
- Mnif, E.; Jarboui, A. COVID-19, bitcoin market efficiency, herd behavior. Rev. Behav. Financ. 2021, 13, 69–84. [Google Scholar] [CrossRef]
- Okorie, D.I.; Lin, B. Stock markets and the COVID-19 fractal contagion effects. Financ. Res. Lett. 2021, 38, 101640. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural. Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Fischer, T.; Krauss, C. Deep learning with long short-term memory networks for financial market predictions. Eur. J. Oper. Res. 2018, 270, 654–669. [Google Scholar] [CrossRef] [Green Version]
- Wu, D.; Wang, X.; Su, J.; Tang, B.; Wu, S. A Labeling method for financial time series prediction based on trends. Entropy 2020, 22, 1162. [Google Scholar] [CrossRef]
- Nabipour, M.; Nayyeri, P.; Jabani, H.; Mosavi, A.; Salwana, E.; Shahab, S. Deep learning for stock market prediction. Entropy 2020, 22, 840. [Google Scholar] [CrossRef]
- Yu, S.L.; Li, Z. Forecasting Stock Price Index Volatility with LSTM Deep Neural Network. In Proceedings of the 11th International Conference on Modelling, Identification and Control, Tianjin, China, 13–15 July 2019; Wang, R., Chen, Z., Eds.; Springer: Singapore, 2019. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP 2014), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Luo, L.-X. Network text sentiment analysis method combining LDA text representation and GRU-CNN. Pers. Ubiquitous Comput. 2018, 23, 405–412. [Google Scholar] [CrossRef]
- Zhao, J.; Zeng, D.; Liang, S.; Kang, H.; Liu, Q. Prediction model for stock price trend based on recurrent neural network. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 745–753. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, Y.; Lu, S.; Wang, S. Tracking and forecasting milepost moments of the pandemic in the early-outbreak: Framework and applications to the COVID-19. F1000research 2020, 9, 333. [Google Scholar] [CrossRef]
- Cox, J.D.L.; Greenwald, S.C.L. What explains the COVID-19 stock market? NBER Work. Pap. Ser. 2020, 53, 1689–1699. [Google Scholar]
- Mandelbrot, B. The variation of some other speculative prices. J. Bus. 1967, 40, 393. [Google Scholar] [CrossRef]
- Engle, R.F. Autoregressive conditional heteroskedasticity with estimates of the variance of UK. inflation. Econom. J. Econom. Soc. 1982, 50, 987–1007. [Google Scholar]
- Bollerslev, T.; Chou, R.Y.; Kroner, K.F. ARCH modeling in finance: A review of the theory and empirical evidence. J. Econ. 1992, 52, 5–59. [Google Scholar] [CrossRef]
- Cheong, C.W. Modeling and forecasting crude oil markets using ARCH-type models. Energy Policy 2009, 37, 2346–2355. [Google Scholar] [CrossRef]
- Bentes, S.R.; Menezes, R.; Mendes, D.A. Long memory and volatility clustering: Is the empirical evidence consistent across stock markets? Phys. A Stat. Mech. Appl. 2008, 387, 3826–3830. [Google Scholar] [CrossRef] [Green Version]
- Ihlen, E.A.F.E. Introduction to multifractal detrended fluctuation analysis in matlab. Front. Physiol. 2012, 3, 141. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wood, A.; Wood, R.; Charnley, M. Through-the-wall radar detection using machine learning. Results Appl. Math. 2020, 7, 100106. [Google Scholar] [CrossRef]
- Manu, K.S.; Kalra, R.; Shubhika, M. Stock index prediction using artificial neural network and econometric model: The case of nifty 50. Int. J. Adv. Sci. Technol. 2020, 29, 3425–3437. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Before the Pandemic | During the Pandemic | After the First Panic Period | |||
|---|---|---|---|---|---|---|
| market | CSI300 | S&P500 | CSI300 | S&P500 | CSI300 | S&P500 |
| Mean | −2.50 × 10−19 | −4.11 × 10−19 | −4.75 × 10−19 | 7.22 × 10−19 | 2.40 × 10−18 | 4.48 × 10−19 |
| Max | 0.43313 | 0.40504 | 0.20563 | 0.41758 | 0.48440 | 0.63640 |
| Min | −0.56687 | −0.59450 | −0.794374 | −0.58241 | −0.51560 | −0.36360 |
| C.V. 1 | 81.00000 | 84.00000 | 247.00000 | 380.00000 | 84.50000 | 57.50000 |
| Skewness | −0.912033 | −0.942465 | −11.88979 | −3.37300 | 0.06833 | 1.38635 |
| Kurtosis | 49.79279 | 70.36161 | 365.45870 | 123.23470 | 16.13560 | 78.50269 |
| p-value 2 | 0.00000 *** | 0.00000 *** | 0.00000 *** | 0.00000 *** | 0.00000 *** | 0.00000 *** |
| GARCH (1,1) 3 | 0.98075 *** | 0.91218 *** | 1.00000 *** | 0.96622 *** | 0.97298 *** | 0.88691 *** |
| Stage | |||||||
|---|---|---|---|---|---|---|---|
| before | 0.2214 | 0.7490 | 0.5276 | −0.0599 | 0.3761 | 0.4360 | −0.1852 |
| during | 0.1433 | 0.7210 | 0.5777 | −0.0524 | 0.3508 | 0.4032 | −0.3213 |
| after | 0.4186 | 0.7799 | 0.3613 | 0.3628 | 0.1756 | −0.1872 | 0.0317 |
| Stage | |||||||
|---|---|---|---|---|---|---|---|
| before | 0.2738 | 0.8271 | 0.5532 | 0.3364 | 0.3474 | 0.0110 | −0.0719 |
| during | 0.0870 | 1.0660 | 0.9792 | 0.0615 | −0.0248 | −0.0863 | −0.0610 |
| after | 0.1863 | 0.8948 | 0.7084 | −0.0634 | 0.0228 | 0.0862 | −0.0917 |
| Parameters | History | Units | Optimizer | Epoch | Batch Size | Activation |
|---|---|---|---|---|---|---|
| value | 20 | 12 | Adam | 500 | 100 | Relu |
| Stage | Num | MAE-Train | RMSE-Train | MAE-Test | RMSE-Test |
|---|---|---|---|---|---|
| before | 1 | 4.74 | 7.22 | 3.13 | 4.29 |
| 2 | 4.67 | 7.06 | 3.11 | 4.23 | |
| 3 | 4.68 | 7.08 | 3.13 | 4.25 | |
| during | 1 | 6.42 | 12.20 | 8.86 | 12.7 |
| 2 | 7.12 | 11.08 | 5.18 | 11.08 | |
| 3 | 7.36 | 11.25 | 4.96 | 7.50 | |
| after | 1 | 6.77 | 9.57 | 5.76 | 7.84 |
| 2 | 7.01 | 9.83 | 6.02 | 8.13 | |
| 3 | 6.96 | 9.78 | 5.94 | 8.04 |
| Stage | Num | MAE-Train | RMSE-Train | MAE-Test | RMSE-Test |
|---|---|---|---|---|---|
| before | 1 | 1.51 | 2.60 | 8.36 | 9.85 |
| 2 | 1.65 | 2.69 | 11.55 | 13.68 | |
| 3 | 1.61 | 2.66 | 12.39 | 14.69 | |
| during | 1 | 5.94 | 11.05 | 18.13 | 22.76 |
| 2 | 6.98 | 11.88 | 8.32 | 11.56 | |
| 3 | 6.94 | 11.89 | 6.13 | 9.55 | |
| after | 1 | 3.00 | 4.72 | 7.10 | 8.43 |
| 2 | 2.73 | 4.49 | 19.49 | 21.04 | |
| 3 | 2.72 | 4.48 | 24.28 | 25.76 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, S.; Fang, W. Multifractal Behaviors of Stock Indices and Their Ability to Improve Forecasting in a Volatility Clustering Period. Entropy 2021, 23, 1018. https://doi.org/10.3390/e23081018
Zhang S, Fang W. Multifractal Behaviors of Stock Indices and Their Ability to Improve Forecasting in a Volatility Clustering Period. Entropy. 2021; 23(8):1018. https://doi.org/10.3390/e23081018
Chicago/Turabian StyleZhang, Shuwen, and Wen Fang. 2021. "Multifractal Behaviors of Stock Indices and Their Ability to Improve Forecasting in a Volatility Clustering Period" Entropy 23, no. 8: 1018. https://doi.org/10.3390/e23081018
APA StyleZhang, S., & Fang, W. (2021). Multifractal Behaviors of Stock Indices and Their Ability to Improve Forecasting in a Volatility Clustering Period. Entropy, 23(8), 1018. https://doi.org/10.3390/e23081018