
High-Dimensional Separability for One- and Few-Shot Learning

 , ,
, ,  , and
, and 
Abstract
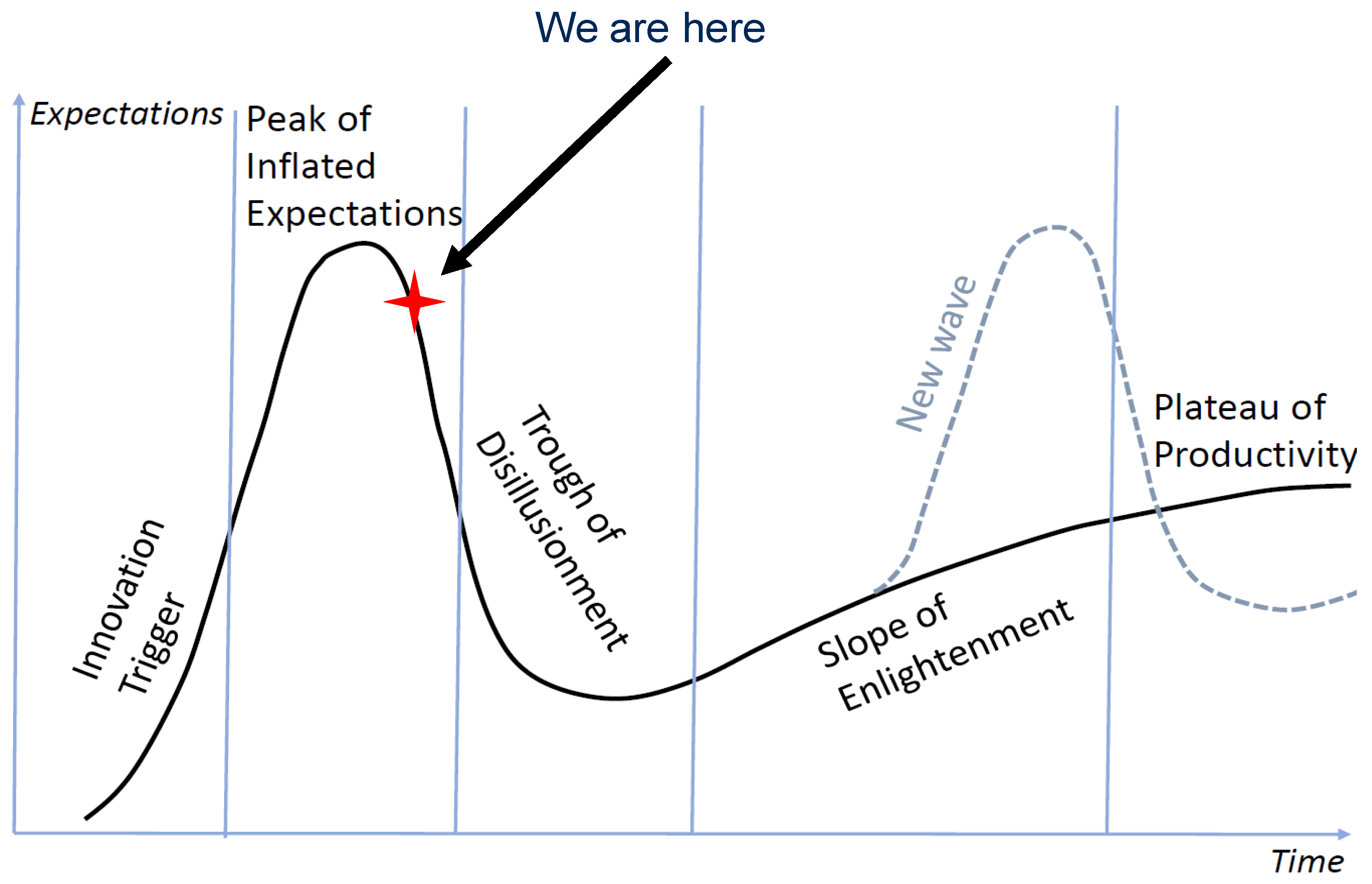
:1. Introduction
1.1. AI Errors and Correctors
- The mistakes can be dangerous;
- Usually, it remains unclear who is responsible for them;
- The types of errors are numerous and often unpredictable;
- The real world is not a good i.i.d. (independent identically distributed) sample;
- We cannot rely on a statistical estimate of the probability of errors in real life.
- To preserve existing skills we must use the full set of training data;
- This approach requires significant computational resources for each error;
- However, new errors may appear in the course of retraining;
- The preservation of existing skills is not guaranteed;
- The probability of damage to skills is a priori unknown.
1.2. One- and Few-Shot Learning
- If the feature space is effectively reduced, then the challenge of large dataset can be mitigated and we can rely on classical linear or non-linear methods of statistical learning.
- If the data points in the latent space form dense clusters, then position of new data with respect to these clusters can be utilised for solving new tasks. We can also expect that new data may introduce new clusters, but persistence of the cluster structure seems to be important. The clusters themselves can be distributed in a multidimensional feature space. This is the novel and more general setting we are going to focus on below in Section 3.
1.3. Bibliographic Comments
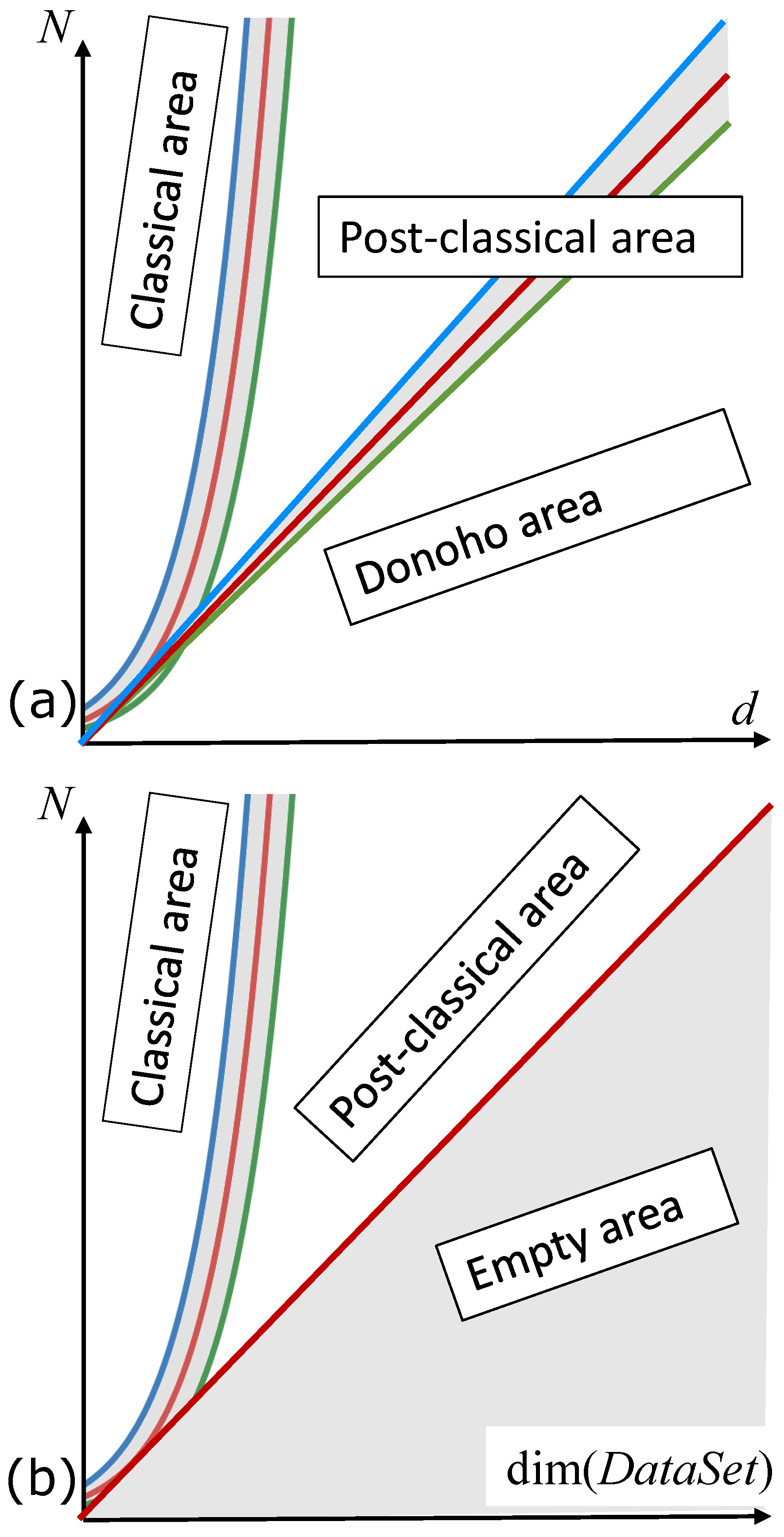
- Blessing of dimensionality. In data analysis, the idea of blessing of dimensionality was formulated by Kainen [27]. Donoho considered the effects of the dimensionality blessing to be the main direction of the development of modern data science [28]. The mathematical backgrounds of blessing of dimensionality are in the measure concentration phenomena. The same phenomena form the background of statistical physics (Gibbs, Einstein, Khinchin—see the review [25]). Two modern books include most of the classical results and many new achievements of concentration of measure phenomena needed in data science [44,45] (but they do not include new stochastic separation theorems). Links between the blessing of dimensionality and the classical central limit theorems are recently discussed in [49].
- AI errors. The problem of AI errors is widely recognised. This is becoming the most important issue of serious concern when trying to use AI in real life. The Council of Europe Study report [10] demonstrates that the inevitability of errors of data-driven AI is now a big problem for society. Many discouraging examples of such errors are published [50,51], collected in reviews [52], and accumulated in a special database, Artificial Intelligence Incident Database (AIID) [53,54]. The research interest to this problem increases as an answer of the scientific community to the request of AI users. There are several fundamental origins of AI errors including uncertainty in training data, uncertainty in training process, and uncertainty of real world—reality can deviate significantly from the fitted model. The systematic manifestations of these deviations are known as concept drift or model degradation phenomena [55].
- AI correctors. The idea of elementary corrector together with statistical foundations was proposed in [30]. First stochastic separation theorems were proved for several simple data distributions (uniform distributions in a ball and product distributions with bounded support) [31]. The collection of results for many practically important classes of distributions, including convex combinations of log-concave distributions is presented in [13]. Kernel version of stochastic separation theorem was proved [36]. The stochastic separation theorems were used for development of correctors tested on various data and problems, from the straightforward correction of errors [32] to knowledge transfer between AI systems [56].
- Data compactness. This is an old and celebrated idea proposed by Braverman in early 1960s [57]. Several methods of measurement compactness of data clouds were invented [58]. The possibility to replace data points by compacta in training of neural networks was discussed [59]. Besides theoretical backgrounds of AI and data mining, data compactness was used for unsupervised outlier detection in high dimensions [60] and other practical needs.
1.4. The Structure of the Paper
- Correlation transformation that maps the dataspace into cross-correlation space between data samples:
- PCA;
- Supervised PCA;
- Semi-supervised PCA;
- Transfer Component Analysis (TCA);
- The novel expectation-maximization Domain Adaptation PCA (‘DAPCA’).
2. Postclassical Data
3. Stochastic Separation for Fine-Grained Distributions
3.1. Fisher Separability
- The probability distribution has no heavy tails;
- The sets of relatively small volume should not have large probability.
- The finite set Y in Theorem 1 is just a finite subset of the ball without any assumption of its randomness. We only used the assumption about distribution of .
- The distribution of may deviate significantly from the uniform distribution in the ball . Moreover, this deviation may grow with dimension n as a geometric progression:where is the density of uniform distribution and under assumption that .
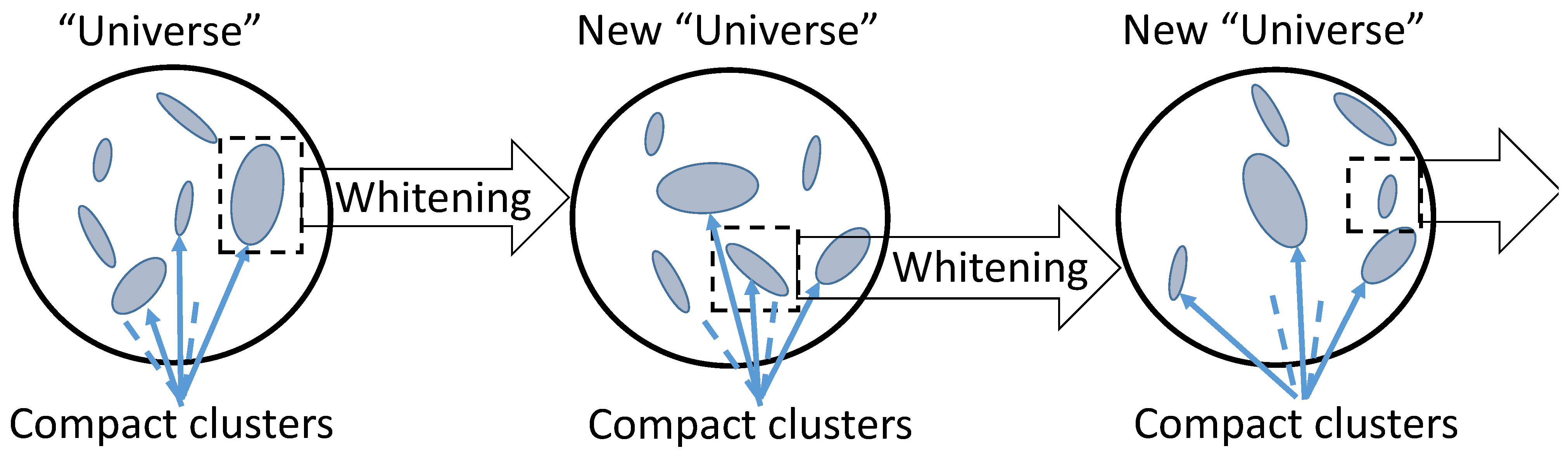
3.2. Granular Models of Clusters
- Volume of a ball with radius is . therefore for probability of belong to this ball, we have
- For every ,
- For every
3.3. Superstatistic Presentation of ‘Granules’
3.4. The Superstatistic form of the Prototype Stochastic Separation Theorem
3.5. Compact Embedding of Patterns and Hierarchical Universe
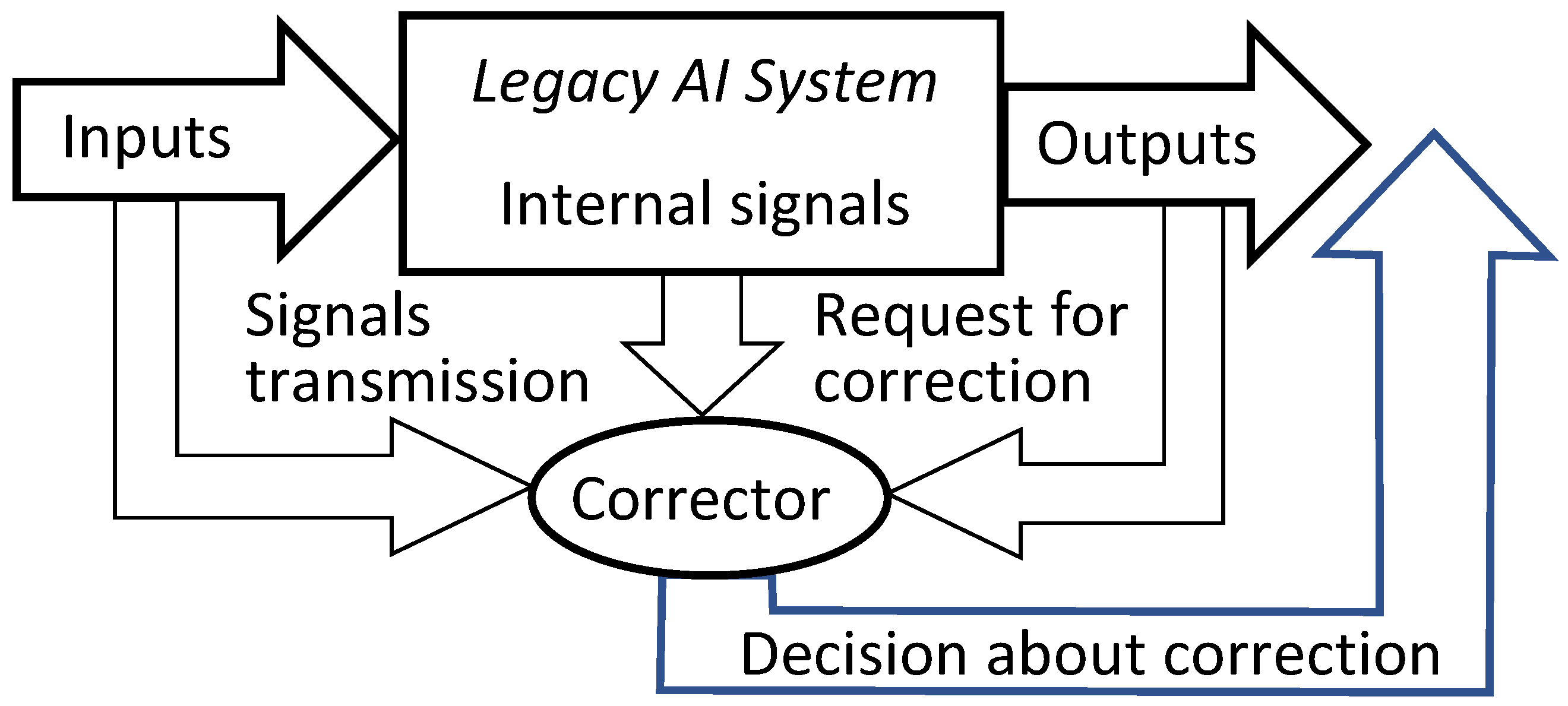
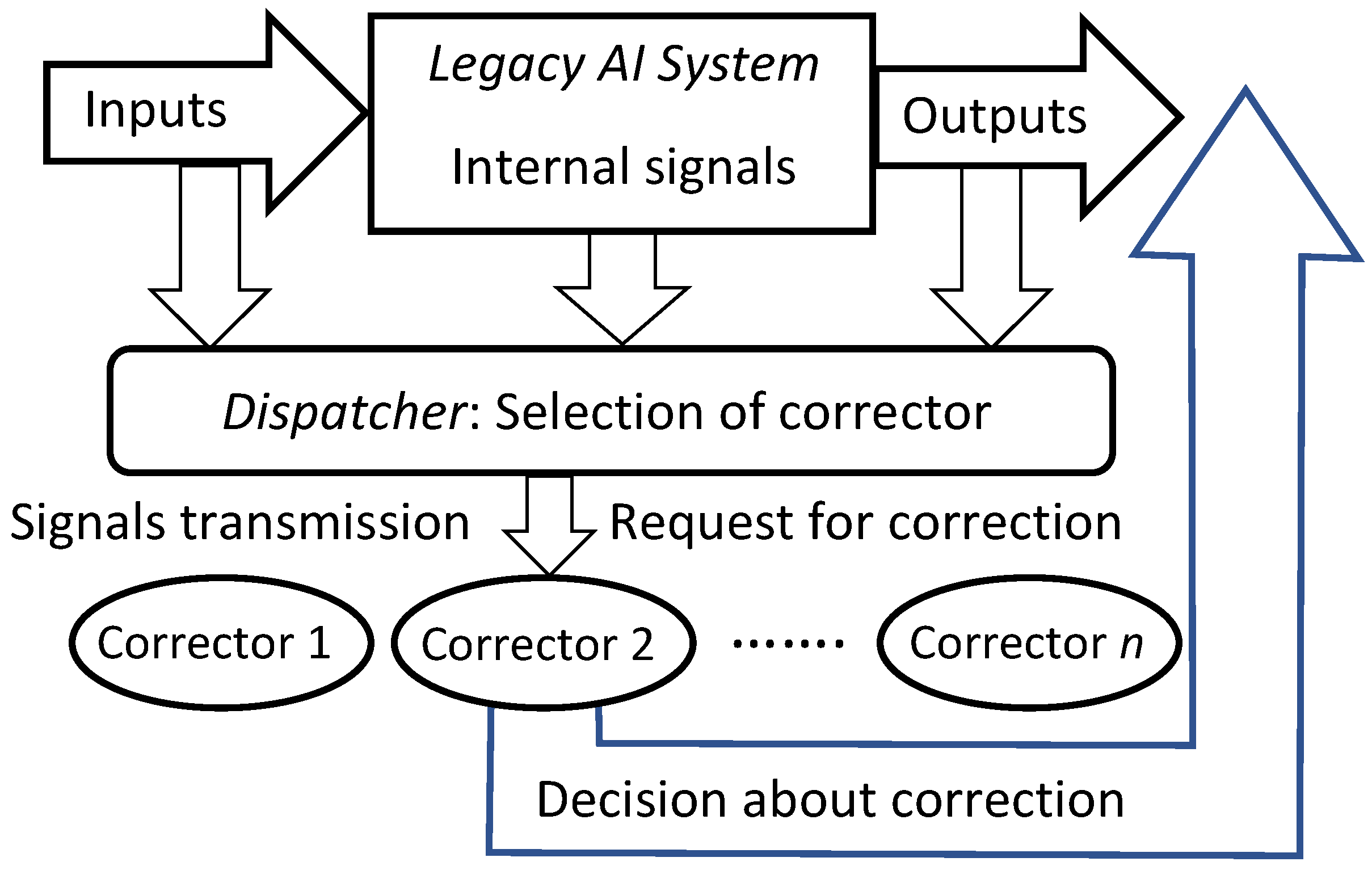
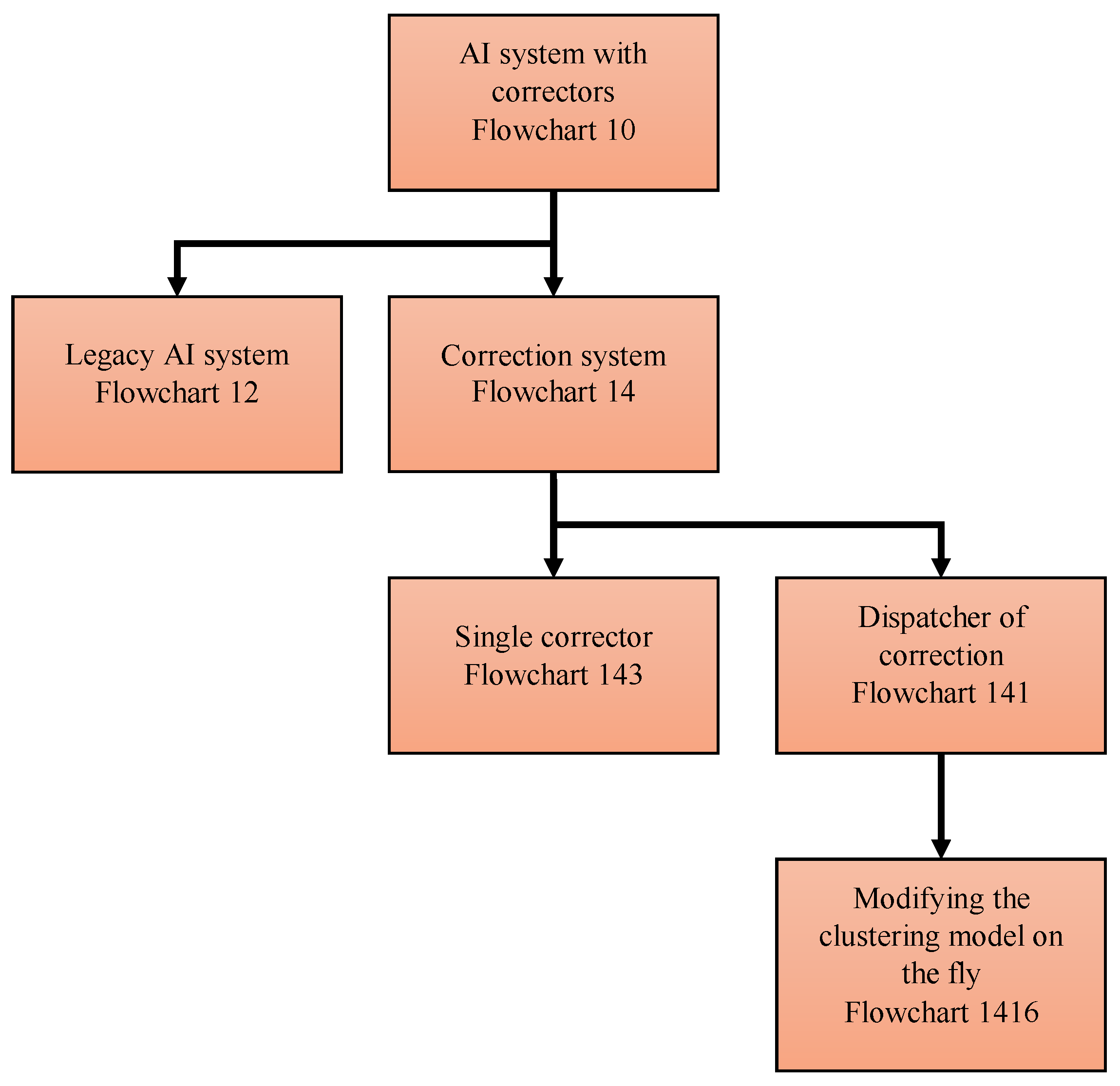
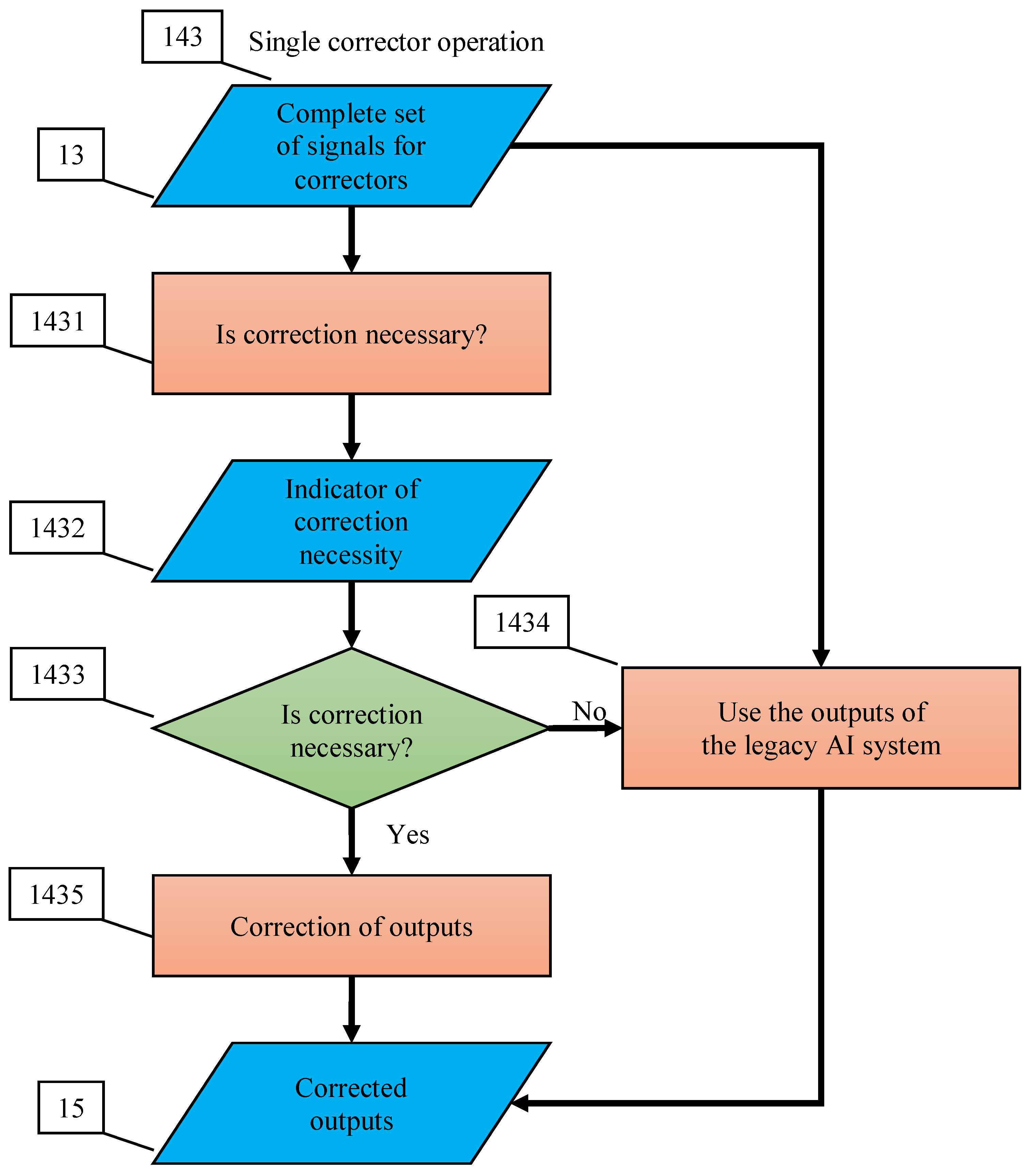
4. Multi-Correctors of AI Systems
4.1. Structure of Multi-Correctors
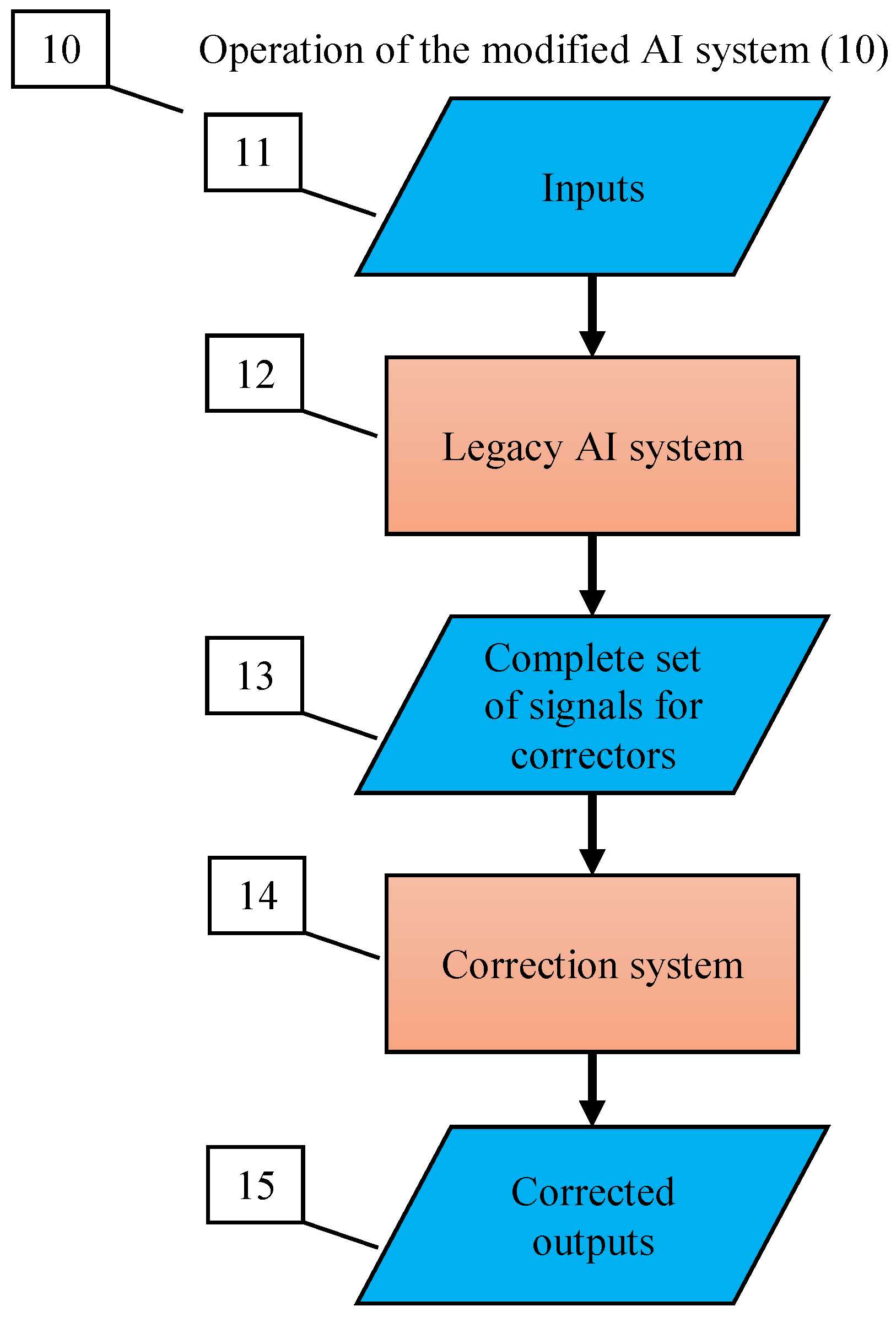
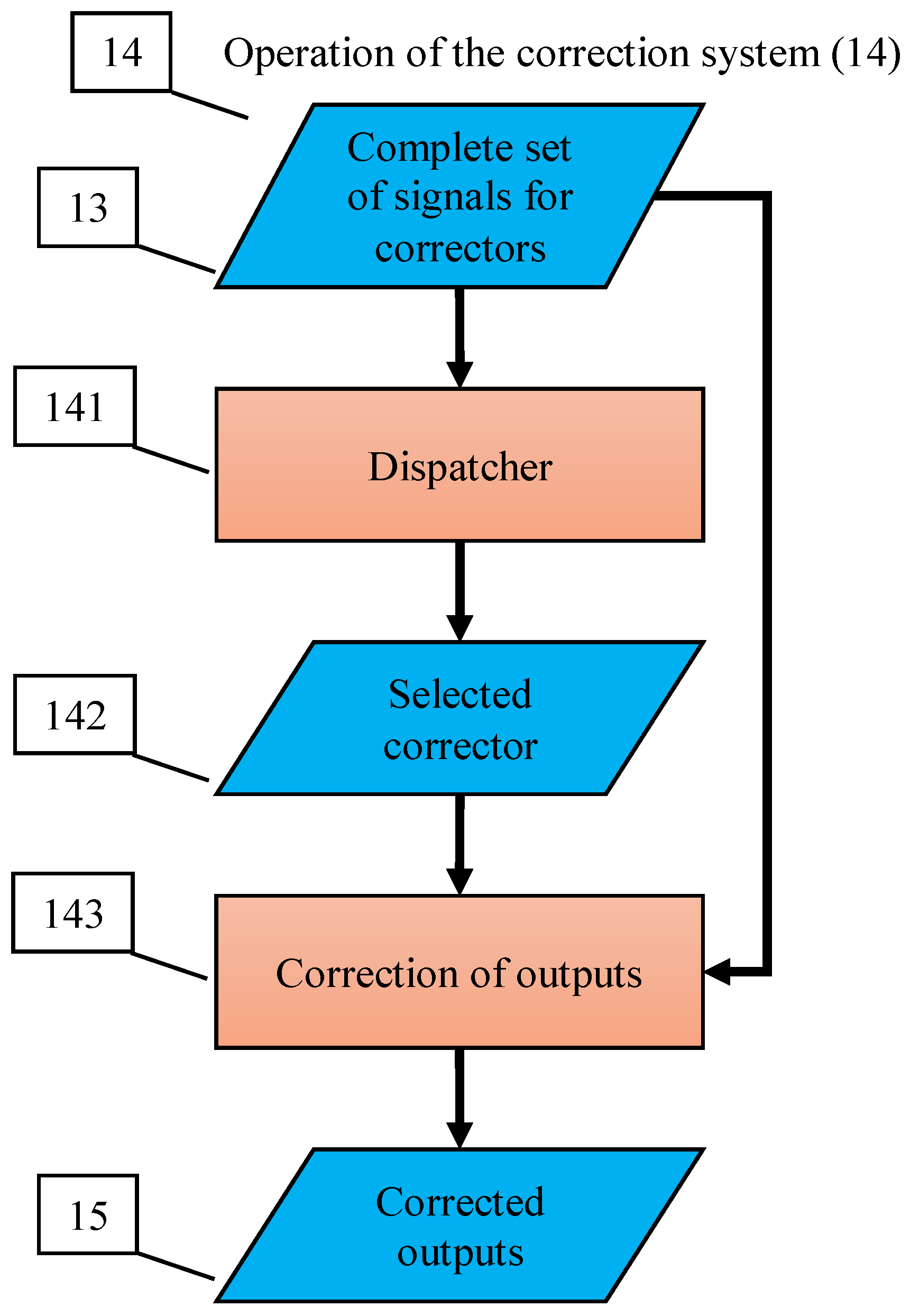
- The correction system is organised as a set of elementary correctors, controlled by the dispatcher;
- Each elementary corrector ‘owns’ a certain class of errors and includes a binary classifier that separates situations with a high risk of these errors, which it owns, from other situations;
- For each elementary corrector, a modified rule is set for operating of the corrected AI system in a situation with a high risk of error diagnosed by the classifier of this corrector;
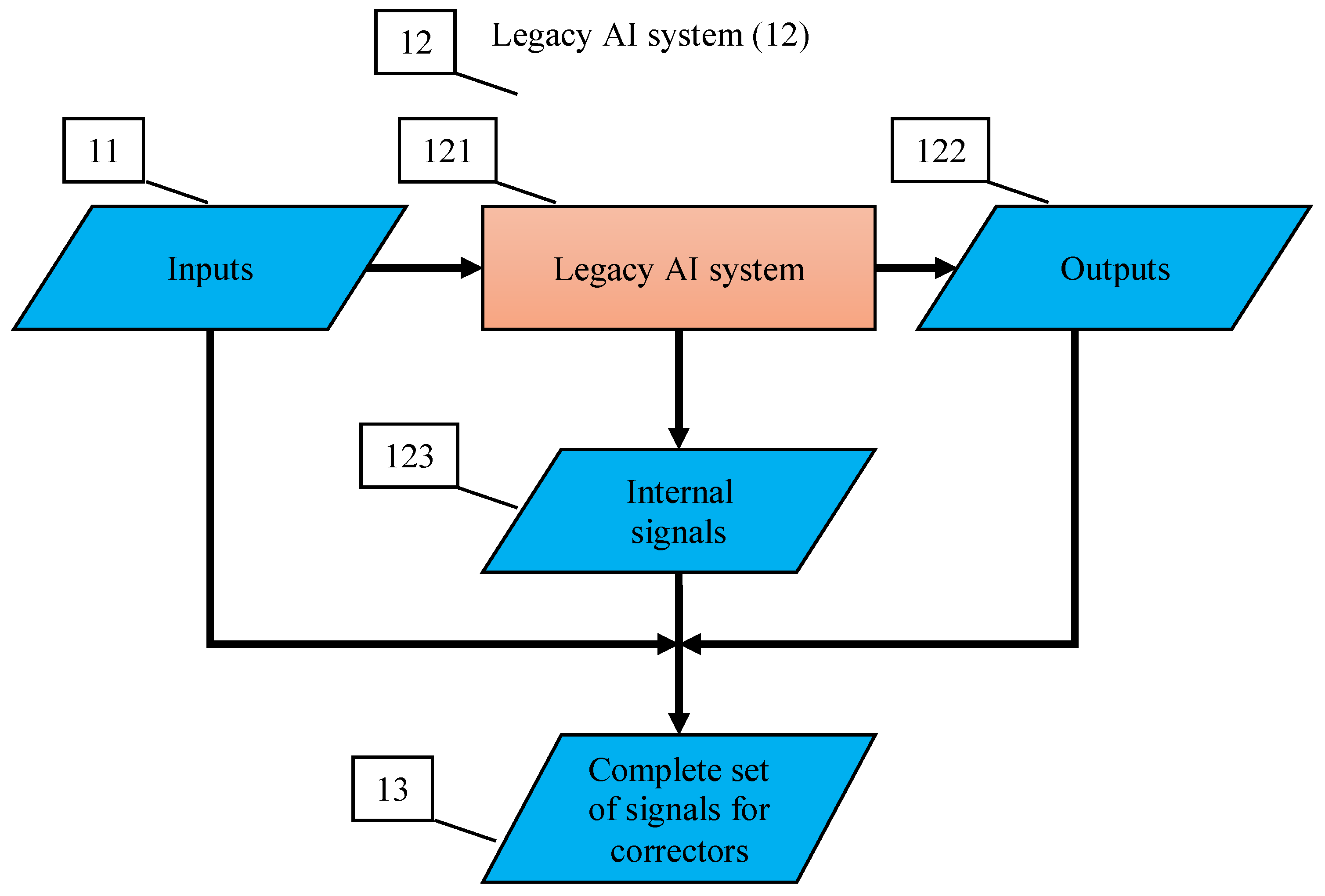
- The input to the corrector is a complete vector of signals, consisting of the input, internal, and output signals of the corrected Artificial Intelligence system, (as well as, if available, any other available attributes of the situation);
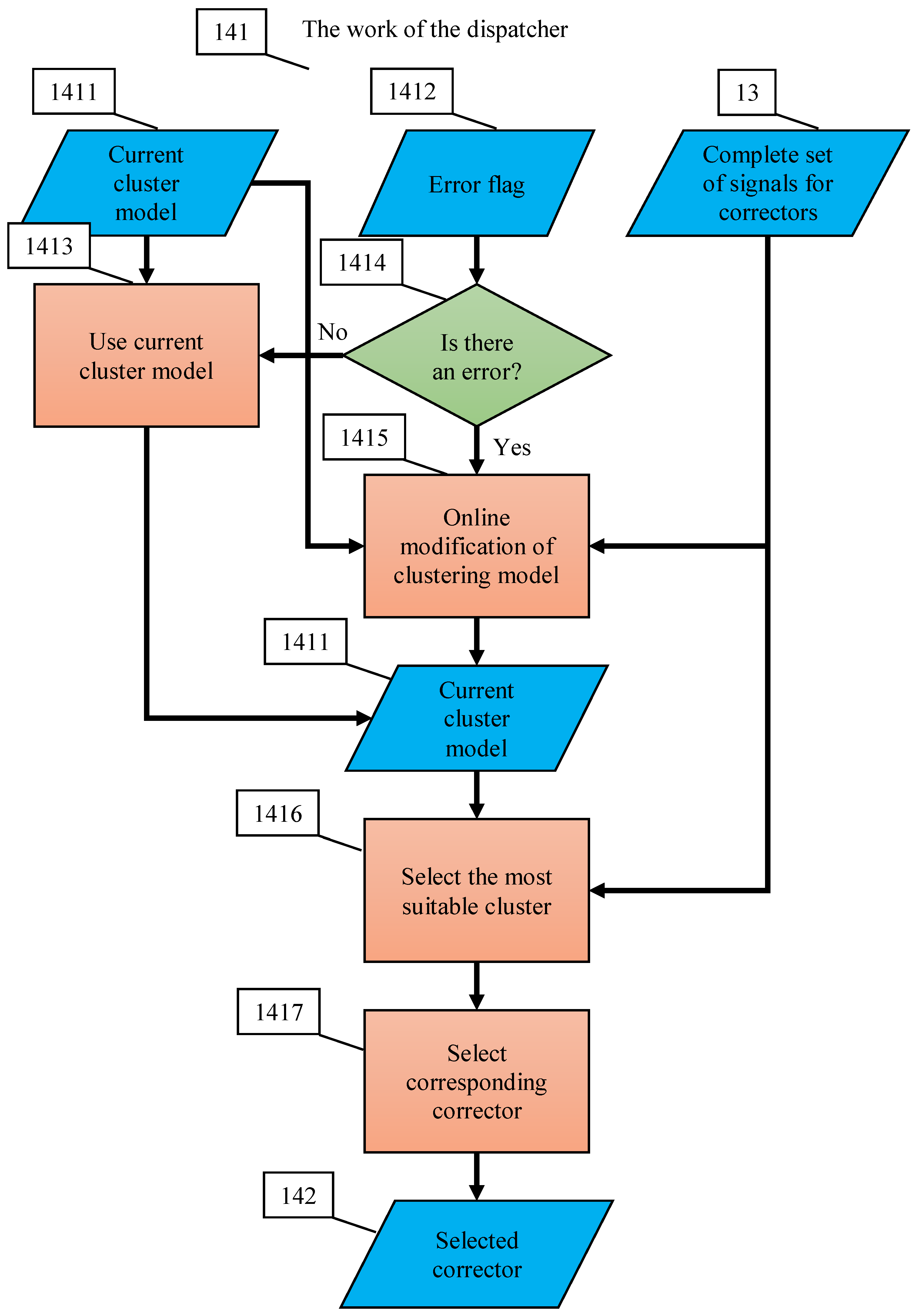
- The dispatcher distributes situations between elementary correctors;
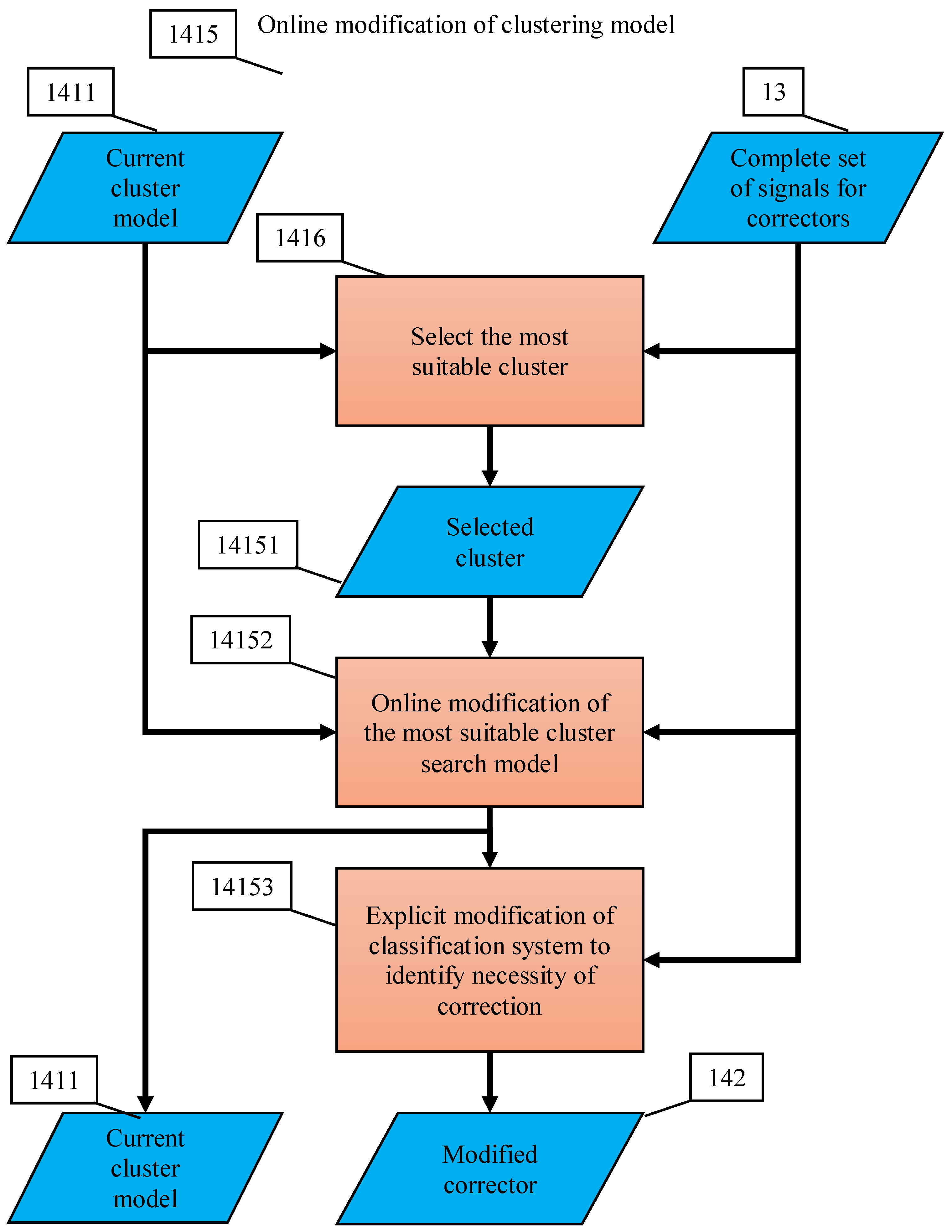
- The decision rule, based on which the dispatcher distributes situations between elementary correctors, is formed as a result of cluster analysis of situations with diagnosed errors;
- Cluster analysis of situations with diagnosed errors is performed using an online algorithm;
- Each elementary corrector owns situations with errors from a single cluster;
- After receiving a signal about the detection of new errors, the dispatcher modifies the definition of clusters according to the selected online algorithm and accordingly modifies the decision rule, on the basis of which situations are distributed between elementary correctors;
- After receiving a signal about detection of new errors, the dispatcher chooses an elementary corrector, which must process the situation, and the classifier of this corrector learns according to a non-iterative explicit rule.
- Simplicity of construction;
- Correction should not damage the existing skills of the system;
- Speed (fast non-iterative learning);
- Correction of new errors without destroying previous corrections.
- Kernel versions of non-iterative linear discriminants extend the area of application of the proposed systems, their separability properties were quantified and tested [36];
- Decision trees of mentioned elementary discriminants with bounded depth. These algorithms require small (bounded) number of iterations.
4.2. Multi-Correctors in Clustered Universe: A Case Study
4.2.1. Datasets
4.2.2. Tasks and Approach
- (Task 1) devise an algorithm to learn a new class without catastrophic forgetting and retraining, and;
- (Task 2) develop an algorithm to predict classification errors in the legacy classifier.
| Algorithm 1: (Few-shot AI corrector [83]: 1NN version. Training). Input: sets , ; the number of clusters, k; threshold, (or thresholds ). |
|
| Algorithm 2: (Few-shot AI corrector [83]: 1NN version. Deployment). Input: a data vector , the set’s centroid vector , matrices H, W, the number of clusters, k, cluster centroids , threshold, (or thresholds ), discriminant vectors, , . |
|
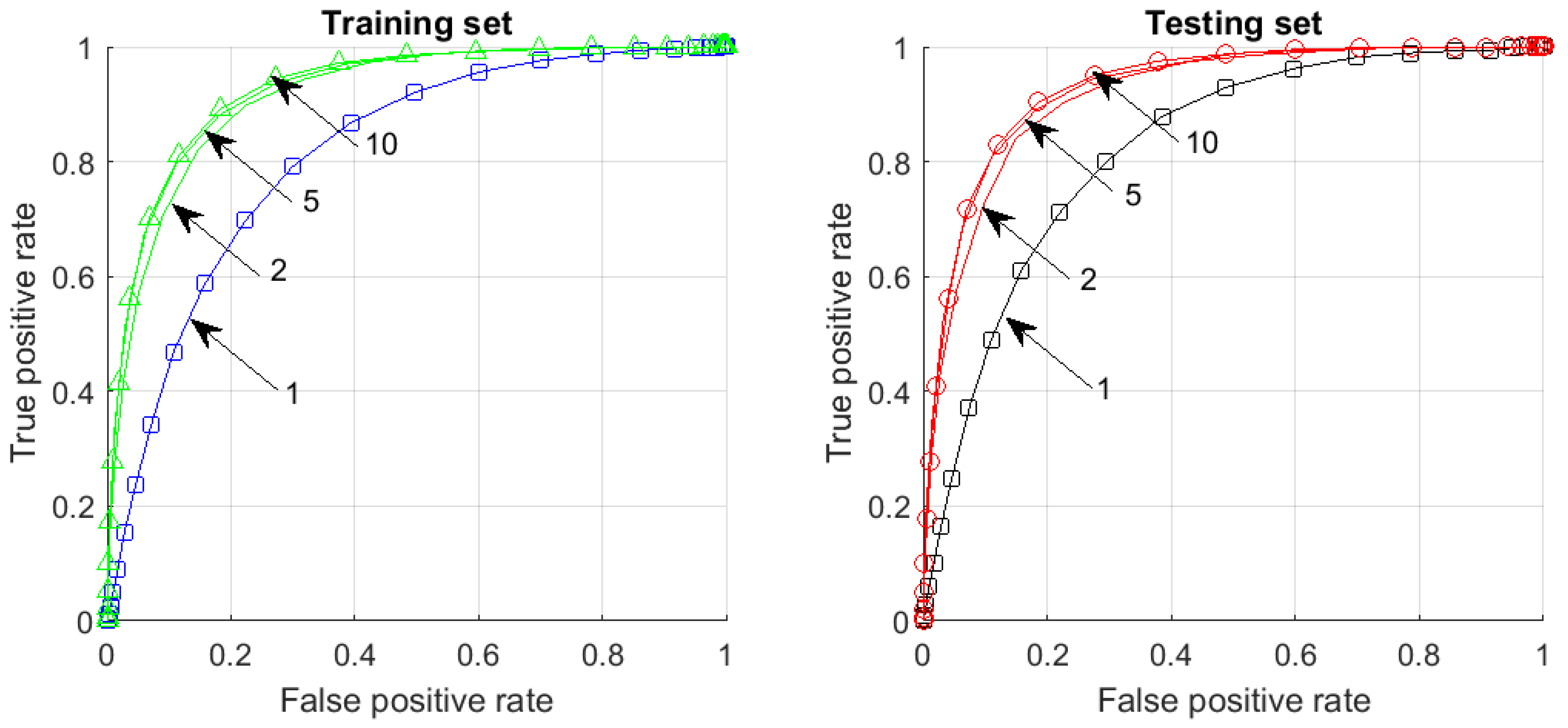
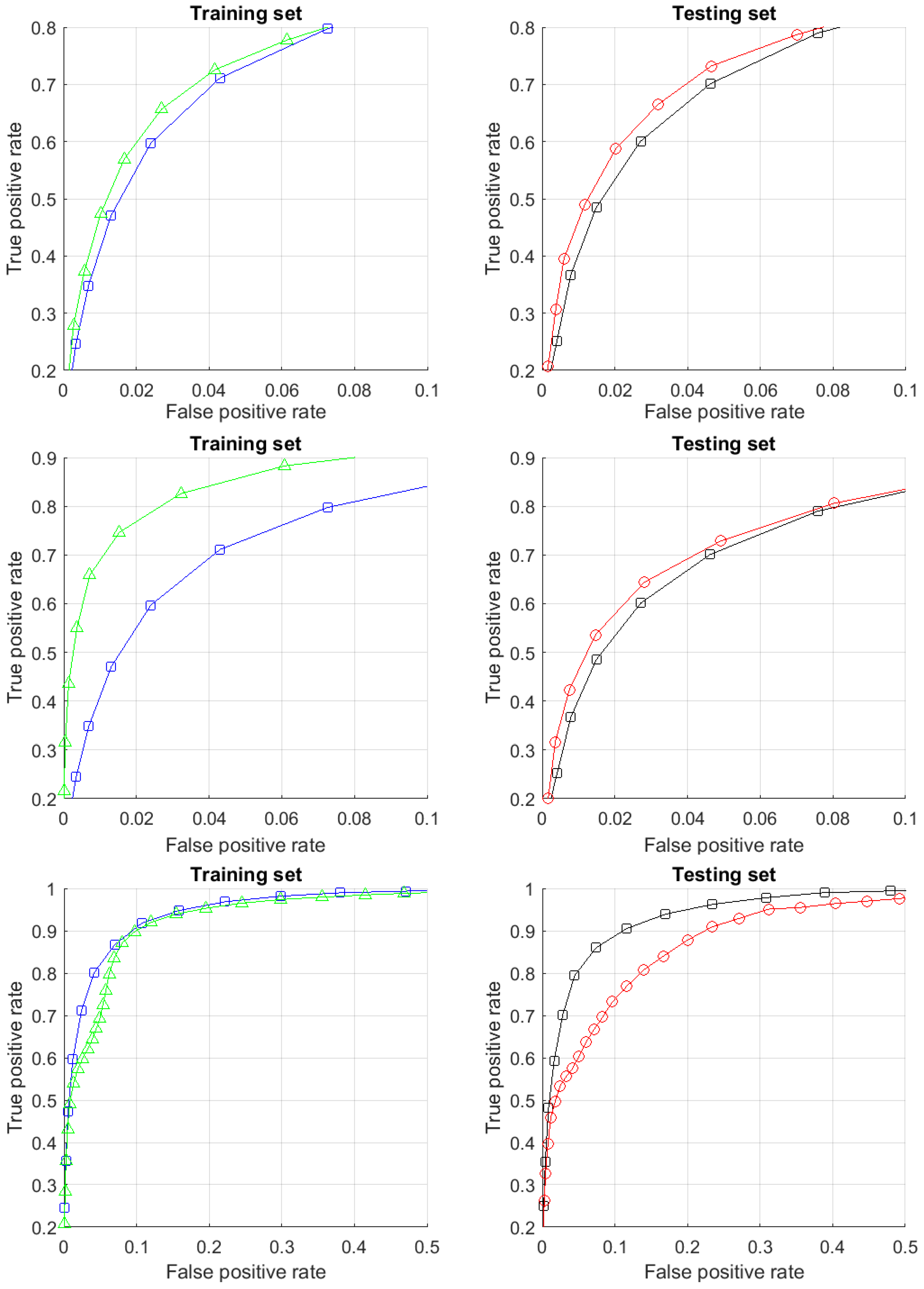
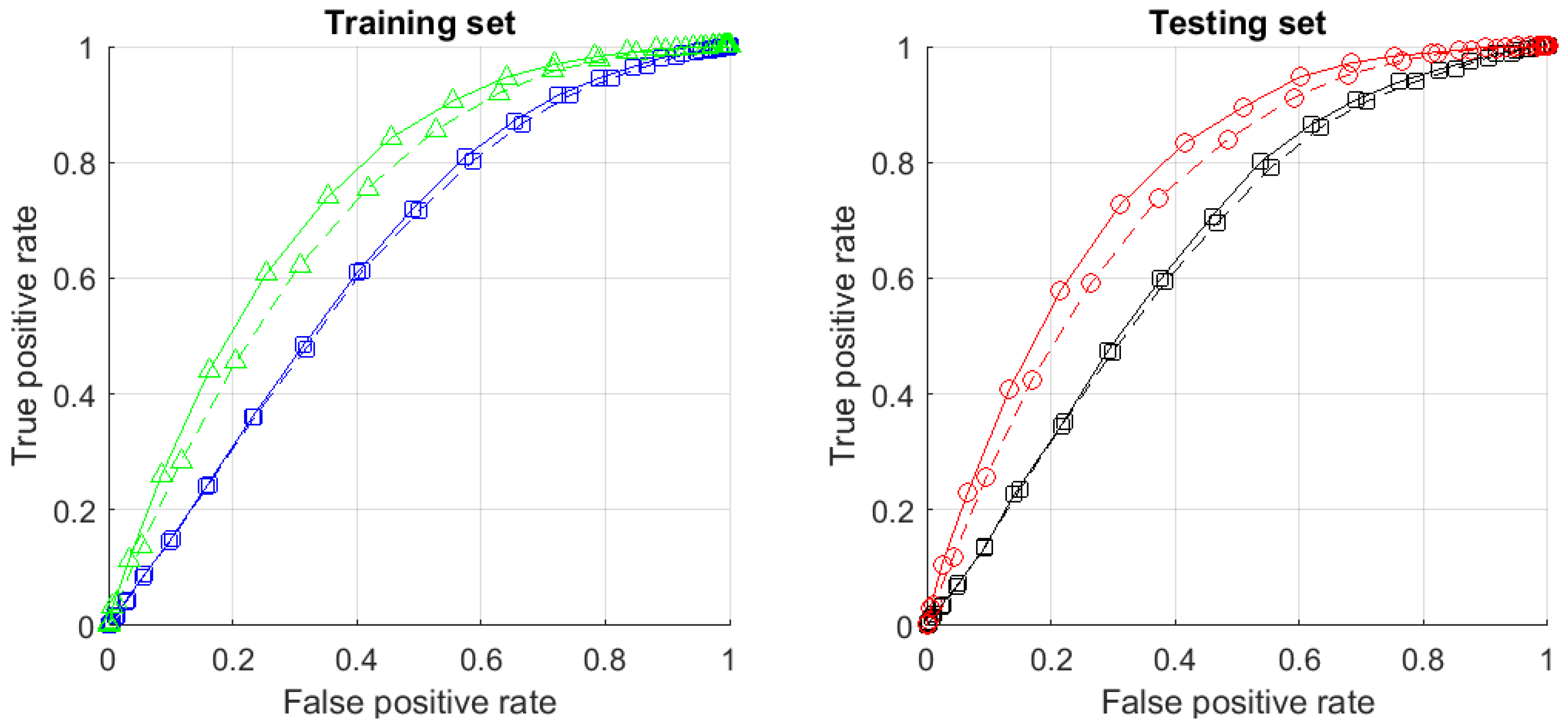
4.2.3. Results
4.2.4. Dimensionality and Multi-Corrector Performance
5. Conclusions
6. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| i.i.d. | independent identically distributed |
| ML | Machine Learning |
| PCA | Principal Component Analysis |
| TCA | Transfer Component Analysis |
| DAPCA | Domain Adaptation PCA |
Appendix A. Elementary Preprocessing of Postclassical Data
Appendix A.1. Measure Examples by Examples and Reduce the Number of Attributes to dim(DataSet)
- Centralize data (subtract the mean);
- Delete coordinates with vanishing variance; (Caution: signals with small variance may be important, whereas signals with large variance may be irrelevant for the target task! This standard operation can help but can also impair the results).
- Standardise data (normalise to unit standard deviations in coordinates), or use another normalisation, if this is more appropriate; (Caution: transformation to the dimensionless variables is necessary but selection of the scale (standard deviation) affects the relative importance of the signals and can impair the results).
- Normalise the data vectors to unit length: (Caution: this simple normalisation is convenient but deletes one attribute, the length. If this attribute is expected to be important than it could be reasonable to use the mean value of that gives normalisation to the unit average length).
- Introduce coordinates in the subspace spanned by the dataset, using projections on .
- Each new data point will be represented by a N-dimensional vector of inner products with coordinates .
Appendix A.2. Unsupervised, Supervised, and Semisupervised PCA
- Classical PCA, ;
- Supervised PCA for classification tasks [104,105]. The dataset is split into several classes, . Follow the strategy ‘attract similar and repulse dissimilar’. If and belong to the same class, then (attraction). If and belong to different classes, then (repulsion). This preprocessing can substitute several layers of feature extraction deep learning network [93].
- Supervised PCA for any supervising task. The dataset for supervising tasks is augmented by labels (the desired outputs). There is proximity (or distance, if possible) between these desired outputs. The weight is defined as a function of this proximity. The closer the desired outputs are, the smaller the weights should be. They can change sign (from classical repulsion, to attraction, ) or simply change the strength of repulsion.
- Semi-supervised PCA was defined for a mixture of labelled and unlabelled data [106]. The data are labelled for classification task. For the labelled data, weights are defined as above for supervised PCA. Inside the set of unlabelled data the classical PCA repulsion is used.
Appendix A.3. DAPCA—Domain Adaptation PCA
- Select a family of classifiers in data space;
- Choose the best classifier from this family for separation the source domain samples from the target domain samples;
- The error of this classifier is an objective function for maximisation (large classification error means that the samples are indistinguishable by the selected family of classifiers).
- If then (the source samples from one class, attraction);
- If () then (the source samples from different classes, repulsion);
- then (the target samples, repulsion);
- For each target sample find k closest source samples in . Denote this set . For each , (the weight for connections of a target sample and the k closest source samples, attraction).
Appendix B. ‘Almost Always’ in Infinite-Dimensional Spaces
- The sets of measure zero are negligible.
- The sets of Baire first category are negligible.
- A union of countable family of thin sets should be thin.
- Any subset of a thin set should be thin.
- The whole space is not thin.
- Almost always a function has nowhere dense set of zeros (the set of exclusions is completely thin in ).
- Almost always a function has only one point of global maximum.
Appendix C. Flowchart of Multi-Corrector Operation








References
- Armstrong, S.; Sotala, K.; Ó hÉigeartaigh, S.S. The errors, insights and lessons of famous AI predictions and what they mean for the future. J. Exp. Theor. Artif. Intell. 2014, 26, 317–342. [Google Scholar] [CrossRef] [Green Version]
- Perez Cruz, L.; Treisman, D. AI Turning points and the road ahead. In Computational Intelligence: Proceedings of the 10th International Joint Conference on Computational Intelligence (IJCCI 2018); Sabourin, C., Merelo, J.J., Barranco, A.L., Madani, K., Warwick, K., Eds.; Springer: Cham, Switzerland, 2021; Volume 893, pp. 89–107. [Google Scholar] [CrossRef]
- John, W.; Lloyd, J.W. Surviving the AI winter. In Logic Programming: The 1995 International Symposium; MIT Press: Cambridge, MA, USA, 1995; pp. 33–47. [Google Scholar] [CrossRef]
- Hendler, J. Avoiding another AI winter. IEEE Intell. Syst. 2008, 23, 2–4. [Google Scholar] [CrossRef]
- Floridi, L. AI and its new winter: From myths to realities. Philos. Technol. 2020, 33, 1–3. [Google Scholar] [CrossRef] [Green Version]
- Bowman, C.E.; Grindrod, P. Trust, Limitation, Conflation and Hype. ResearchGate Preprint. Available online: https://www.researchgate.net/publication/334425107_Trust_Limitation_Conflation_and_Hype (accessed on 12 August 2021).
- Gartner Hype Cycle for Artificial Intelligence. 2019. Available online: https://www.gartner.com/smarterwithgartner/toptrends-on-the-gartner-hype-cycle-for-artificial-intelligence-2019/ (accessed on 12 August 2021).
- Gartner Hype Cycle for Emerging Technologies. 2020. Available online: https://www.gartner.com/en/newsroom/pressreleases/2020-08-18-gartner-identifies-five-emerging-trends-that-will-drive-technology-innovation-for-the-next-decade (accessed on 12 August 2021).
- Gorban, A.N.; Grechuk, B.; Tyukin, I.Y. Augmented Artificial Intelligence: A Conceptual Framework. arXiv 2018, arXiv:1802.02172. [Google Scholar]
- Yeung, K. Responsibility and AI: Council of Europe Study DGI(2019)05. Prepared by the Expert Committee on Human Rights Dimensions of Automated Data Processing and Different forms of Artificial Intelligence. Council of Europe. 2019. Available online: https://rm.coe.int/responsability-and-ai-en/168097d9c5 (accessed on 12 August 2021).
- Cucker, F.; Smale, S. On the mathematical foundations of learning. Bull. Am. Math. Soc. 2002, 39, 1–49. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.; Hastie, T.; Tibshirani, R. The Elements of Statistical Learning; Springer: New York, NY, USA, 2009. [Google Scholar]
- Grechuk, B.; Gorban, A.N.; Tyukin, I.Y. General stochastic separation theorems with optimal bounds. Neural Netw. 2021, 138, 33–56. [Google Scholar] [CrossRef]
- Rosenblatt, F. Principles of Neurodynamics: Perceptrons and the Theory of Brain Mechanisms; Spartan Books: New York, NY, USA, 1962. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Talvitie, E. Model regularization for stable sample rollouts. In Proceedings of the 30th Conference on Uncertainty in Artificial Intelligence, Lancaster, PA, USA, 23–27 July 2014; pp. 780–789. [Google Scholar]
- Venkatraman, A.; Hebert, M.; Bagnell, J.A. Improving multistep prediction of learned time series models. In Proceedings of the 29th AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–29 January 2015; pp. 3024–3030. [Google Scholar]
- Talvitie, E. Self-correcting models for model-based reinforcement learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Kavukcuoglu, K.; Wierstra, D. Matching networks for one shot learning. In Proceedings of the NIPS’16: 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5 December 2016; pp. 3637–3645. [Google Scholar] [CrossRef]
- Zhang, C.; Bengio, S.; Hardt, M.; Recht, B.; Vinyals, O. Understanding deep learning (still) requires rethinking generalization. Commun. ACM 2021, 64, 107–115. [Google Scholar] [CrossRef]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical networks for few-shot learning. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4 December 2017; pp. 4080–4090. Available online: https://proceedings.neurips.cc/paper/2017/file/cb8da6767461f2812ae4290eac7cbc42-Paper.pdf (accessed on 12 August 2021).
- Ravi, S.; Larochelle, H. Optimization as a model for few-shot learning. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017; Available online: https://openreview.net/pdf?id=rJY0-Kcll (accessed on 12 August 2021).
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a few examples: A survey on few-shot learning. ACM Comput. Surv. (CSUR) 2020, 53, 1–34. [Google Scholar] [CrossRef]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.; Hospedales, T.M. Learning to Compare: Relation Network for Few-Shot Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 1199–1208. Available online: https://openaccess.thecvf.com/content_cvpr_2018/html/Sung_Learning_to_Compare_CVPR_2018_paper.html (accessed on 12 August 2021).
- Gorban, A.N.; Tyukin, I.Y. Blessing of dimensionality: Mathematical foundations of the statistical physics of data. Philos. Trans. R. Soc. A 2018, 376, 20170237. [Google Scholar] [CrossRef] [Green Version]
- Tyukin, I.Y.; Gorban, A.N.; Alkhudaydi, M.H.; Zhou, Q. Demystification of few-shot and one-shot learning. arXiv 2021, arXiv:2104.12174. [Google Scholar]
- Kainen, P.C. Utilizing geometric anomalies of high dimension: When complexity makes computation easier. In Computer-Intensive Methods in Control and Signal Processing: The Curse of Dimensionality; Warwick, K., Kárný, M., Eds.; Springer: New York, NY, USA, 1997; pp. 283–294. [Google Scholar] [CrossRef]
- Donoho, D.L. High-Dimensional Data Analysis: The Curses and Blessings of Dimensionality. In Proceedings of the Invited Lecture at Mathematical Challenges of the 21st Century, AMS National Meeting, Los Angeles, CA, USA, 6–12 August 2000; Available online: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.329.3392 (accessed on 12 August 2021).
- Anderson, J.; Belkin, M.; Goyal, N.; Rademacher, L.; Voss, J. The More, the Merrier: The Blessing of Dimensionality for Learning Large Gaussian Mixtures. In Proceedings of the 27th Conference on Learning Theory, Barcelona, Spain, 13–15 June 2014; Balcan, M.F., Feldman, V., Szepesvári, C., Eds.; PMLR: Barcelona, Spain, 2014; Volume 35, pp. 1135–1164. [Google Scholar]
- Gorban, A.N.; Tyukin, I.Y.; Romanenko, I. The blessing of dimensionality: Separation theorems in the thermodynamic limit. IFAC-PapersOnLine 2016, 49, 64–69. [Google Scholar] [CrossRef]
- Gorban, A.N.; Tyukin, I.Y. Stochastic separation theorems. Neural Netw. 2017, 94, 255–259. [Google Scholar] [CrossRef] [Green Version]
- Gorban, A.N.; Golubkov, A.; Grechuk, B.; Mirkes, E.M.; Tyukin, I.Y. Correction of AI systems by linear discriminants: Probabilistic foundations. Inf. Sci. 2018, 466, 303–322. [Google Scholar] [CrossRef] [Green Version]
- Gorban, A.N.; Makarov, V.A.; Tyukin, I.Y. The unreasonable effectiveness of small neural ensembles in high-dimensional brain. Phys. Life Rev. 2019, 29, 55–88. [Google Scholar] [CrossRef]
- Flury, B. Principal points. Biometrika 1990, 77, 33–41. [Google Scholar] [CrossRef]
- Gorban, A.N.; Zinovyev, A.Y. Principal graphs and manifolds. In Handbook of Research on Machine Learning Applications and Trends: Algorithms, Methods and Techniques; Olivas, E.S., Guererro, J.D.M., Sober, M.M., Benedito, J.R.M., Lopes, A.J.S., Eds.; IGI Global: Hershey, PA, USA, 2010; pp. 28–59. [Google Scholar] [CrossRef] [Green Version]
- Tyukin, I.Y.; Gorban, A.N.; Grechuk, B.; Green, S. Kernel Stochastic Separation Theorems and Separability Characterizations of Kernel Classifiers. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019. [Google Scholar] [CrossRef]
- Jolliffe, I. Principal Component Analysis; Springer: Berlin/Heidelberg, Germany, 1993. [Google Scholar]
- Gorban, A.N.; Kégl, B.; Wunsch, D.; Zinovyev, A. (Eds.) Principal Manifolds for Data Visualisation and Dimension Reduction; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar] [CrossRef] [Green Version]
- Schölkopf, B. Nonlinear Component Analysis as a Kernel Eigenvalue Problem. Neural Comput. 1998, 10, 1299–1319. [Google Scholar] [CrossRef] [Green Version]
- Gorban, A.N.; Zinovyev, A. Principal manifolds and graphs in practice: From molecular biology to dynamical systems. Int. J. Neural Syst. 2010, 20, 219–232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kramer, M.A. Nonlinear principal component analysis using autoassociative neural networks. AIChE J. 1991, 37, 233–243. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 28, 504–507. [Google Scholar] [CrossRef] [Green Version]
- Gorban, A.N.; Makarov, V.A.; Tyukin, I.Y. High-Dimensional Brain in a High-Dimensional World: Blessing of Dimensionality. Entropy 2020, 22, 82. [Google Scholar] [CrossRef] [Green Version]
- Vershynin, R. High-Dimensional Probability: An Introduction with Applications in Data Science; Cambridge Series in Statistical and Probabilistic Mathematics; Cambridge University Press: Cambridge, UK, 2018. [Google Scholar]
- Wainwright, M.J. High-Dimensional Statistics: A Non-Asymptotic Viewpoint; Cambridge University Press: Cambridge, UK, 2019. [Google Scholar]
- Giannopoulos, A.A.; Milman, V.D. Concentration property on probability spaces. Adv. Math. 2000, 156, 77–106. [Google Scholar] [CrossRef] [Green Version]
- Gromov, M. Isoperimetry of waists and concentration of maps. Geom. Funct. Anal. 2003, 13, 178–215. [Google Scholar] [CrossRef] [Green Version]
- Ledoux, M. The Concentration of Measure Phenomenon; Number 89 in Mathematical Surveys & Monographs; AMS: Providence, RI, USA, 2005. [Google Scholar]
- Kreinovich, V.; Kosheleva, O. Limit Theorems as Blessing of Dimensionality: Neural-Oriented Overview. Entropy 2021, 23, 501. [Google Scholar] [CrossRef]
- Foxx, C. Face Recognition Police Tools Staggeringly Inaccurate. BBC News Technol. 2018, 15. Available online: http://www.bbc.co.uk/news/technology-44089161 (accessed on 12 August 2021).
- Strickland, E. IBM Watson, heal thyself: How IBM overpromised and underdelivered on AI health care. IEEE Spectr. 2019, 56, 24–31. [Google Scholar] [CrossRef]
- Banerjee, D.N.; Chanda, S.S. AI Failures: A Review of Underlying Issues. arXiv 2020, arXiv:2008.04073. [Google Scholar]
- Artificial Intelligence Incident Database (AIID). Available online: https://incidentdatabase.ai/ (accessed on 12 August 2021).
- PartnershipOnAI/aiid. Available online: https://github.com/PartnershipOnAI/aiid (accessed on 12 August 2021).
- Tsymbal, A. The Problem of Concept Drift: Definitions and Related Work. Technical Report TCD-CS-2004-15. 2004. Available online: https://www.scss.tcd.ie/publications/tech-reports/reports.04/TCD-CS-2004-15.pdf (accessed on 12 August 2021).
- Tyukin, I.Y.; Gorban, A.N.; Sofeykov, K.I.; Romanenko, I. Knowledge transfer between Artificial Intelligence systems. Front. Neurorobot. 2018, 12, 49. [Google Scholar] [CrossRef] [Green Version]
- Arkad’ev, A.G.; Braverman, E.M. Computers and Pattern Recognition; Thompson Book Company: Washington, DC, USA, 1967. [Google Scholar]
- Duin, R.P.W. Compactness and complexity of pattern recognition problems. In Proceedings of the International Symposium on Pattern Recognition “In Memoriam Pierre Devijver”; Perneel, C., Ed.; Royal Military Academy: Brussels, Belgium, 1999; pp. 124–128. [Google Scholar]
- Kainen, P.C. Replacing points by compacta in neural network approximation. J. Frankl. Inst. 2004, 341, 391–399. [Google Scholar] [CrossRef]
- ur Rehman, A.; Belhaouari, S.B. Unsupervised outlier detection in multidimensional data. J. Big Data 2021, 8, 80. [Google Scholar] [CrossRef]
- Kainen, P.; Kůrková, V. Quasiorthogonal dimension of Euclidian spaces. Appl. Math. Lett. 1993, 6, 7–10. [Google Scholar] [CrossRef] [Green Version]
- Kainen, P.; Kůrková, V. Quasiorthogonal dimension. In Beyond Traditional Probabilistic Data Processing Techniques: Interval, Fuzzy etc. Methods and Their Applications; Kosheleva, O., Shary, S.P., Xiang, G., Zapatrin, R., Eds.; Springer: Cham, Switzerland, 2020; pp. 615–629. [Google Scholar] [CrossRef]
- Gorban, A.N.; Tyukin, I.; Prokhorov, D.; Sofeikov, K. Approximation with random bases: Pro et contra. Inf. Sci. 2016, 364–365, 129–145. [Google Scholar] [CrossRef] [Green Version]
- Camastra, F. Data dimensionality estimation methods: A survey. Pattern Recognit. 2003, 36, 2945–2954. [Google Scholar] [CrossRef] [Green Version]
- Bac, J.; Zinovyev, A. Lizard brain: Tackling locally low-dimensional yet globally complex organization of multi-dimensional datasets. Front. Neurorobot. 2020, 13, 110. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Albergante, L.; Mirkes, E.; Bac, J.; Chen, H.; Martin, A.; Faure, L.; Barillot, E.; Pinello, L.; Gorban, A.; Zinovyev, A. Robust and Scalable Learning of Complex Intrinsic Dataset Geometry via ElPiGraph. Entropy 2020, 22, 296. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Moczko, E.; Mirkes, E.M.; Cáceres, C.; Gorban, A.N.; Piletsky, S. Fluorescence-based assay as a new screening tool for toxic chemicals. Sci. Rep. 2016, 6, 33922. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zadeh, L.A. Towards a theory of fuzzy information granulation and its centrality in human reasoning and fuzzy logic. Fuzzy Sets Syst. 1997, 19, 111–127. [Google Scholar] [CrossRef]
- Pedrycz, W.; Skowron, A.; Kreinovich, V. Handbook of Granular Computing; John Wiley & Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
- Guédon, O.; Milman, E. Interpolating thin-shell and sharp large-deviation estimates for lsotropic log-concave measures. Geom. Funct. Anal. 2011, 21, 1043–1068. [Google Scholar] [CrossRef]
- Lévy, P. Problèmes Concrets D’analyse Fonctionnelle; Gauthier-Villars: Paris, France, 1951. [Google Scholar]
- Khinchin, A.Y. Mathematical Foundations of Statistical Mechanics; Courier Corporation: New York, NY, USA, 1949. [Google Scholar]
- Thompson, C.J. Mathematical Statistical Mechanics; Princeton University Press: Princeton, NJ, USA, 2015. [Google Scholar]
- Kolmogorov, A.N. Foundations of the Theory of Probability, 2nd ed.; Courier Dover Publications: Mineola, NY, USA, 2018. [Google Scholar]
- Liu, L.; Shao, L.; Li, X. Evolutionary compact embedding for large-scale image classification. Inf. Sci. 2015, 316, 567–581. [Google Scholar] [CrossRef]
- Vemulapalli, R.; Agarwala, A. A Compact Embedding for Facial Expression Similarity. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5683–5692. Available online: https://openaccess.thecvf.com/content_CVPR_2019/html/Vemulapalli_A_Compact_Embedding_for_Facial_Expression_Similarity_CVPR_2019_paper.html (accessed on 12 August 2021).
- Bhattarai, B.; Liu, H.; Huang, H.H. Ceci: Compact embedding cluster index for scalable subgraph matching. In Proceedings of the 2019 International Conference on Management of Data, Amsterdam, The Netherlands, 30 June–5 July 2019; pp. 1447–1462. [Google Scholar] [CrossRef]
- Tyukin, I.Y.; Higham, D.J.; Gorban, A.N. On adversarial examples and stealth attacks in Artificial Intelligence systems. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Tyukin, I.Y.; Higham, D.J.; Woldegeorgis, E.; Gorban, A.N. The Feasibility and Inevitability of Stealth Attacks. arXiv 2021, arXiv:2106.13997. [Google Scholar]
- Colbrook, M.J.; Antun, V.; Hansen, A.C. Can stable and accurate neural networks be computed?—On the barriers of deep learning and Smale’s 18th problem. arXiv 2021, arXiv:2101.08286. [Google Scholar]
- Rudin, W. Functional Analysis; McGraw-Hill: New York, NY, USA, 1991. [Google Scholar]
- Xu, R.; Wunsch, D. Clustering; John Wiley & Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
- Tyukin, I.Y.; Gorban, A.N.; McEwan, A.A.; Meshkinfamfard, S.; Tang, L. Blessing of dimensionality at the edge and geometry of few-shot learning. Inf. Sci. 2021, 564, 124–143. [Google Scholar] [CrossRef]
- Tao, C.W. Unsupervised fuzzy clustering with multi-center clusters. Fuzzy Sets Syst. 2002, 128, 305–322. [Google Scholar] [CrossRef]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images. Master’s Thesis, University of Toronto, Toronto, ON, Canada, 2009. Available online: https://citeseerx.ist.psu.edu/viewdoc/versions?doi=10.1.1.222.9220 (accessed on 12 August 2021).
- Krizhevsky, A. CIFAR 10 Dataset. 2009. Available online: https://www.cs.toronto.edu/~kriz/cifar.html (accessed on 12 August 2021).
- Ma, R.; Wang, Y.; Cheng, L. Feature selection on data stream via multi-cluster structure preservation. In Proceedings of the 29th ACM International Conference on Information and Knowledge Management, Online. 19 October 2020; pp. 1065–1074. [Google Scholar] [CrossRef] [Green Version]
- Cai, D.; Zhang, C.; He, X. Unsupervised feature selection for multi-cluster data. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 24–28 July 2010; pp. 333–342. [Google Scholar] [CrossRef]
- Mani, P.; Vazquez, M.; Metcalf-Burton, J.R.; Domeniconi, C.; Fairbanks, H.; Bal, G.; Beer, E.; Tari, S. The hubness phenomenon in high-dimensional spaces. In Research in Data Science; Gasparovic, E., Domeniconi, C., Eds.; Springer: Cham, Switzerland, 2019; pp. 15–45. [Google Scholar] [CrossRef]
- Kolmogoroff, A.N. Über die beste Annaherung von Funktionen einer gegebenen Funktionenklasse. Ann. Math. 1936, 37, 107–110. [Google Scholar] [CrossRef]
- Tikhomirov, V.M. Diameters of sets in function spaces and the theory of best approximations. Russ. Math. Surv. 1960, 15, 75–111. [Google Scholar] [CrossRef]
- Dung, D.; Ullrich, T. N-widths and ε-dimensions for high-dimensional approximations. Found. Comput. Math. 2013, 13, 965–1003. [Google Scholar] [CrossRef]
- Gorban, A.N.; Mirkes, E.M.; Tukin, I.Y. How deep should be the depth of convolutional neural networks: A backyard dog case study. Cogn. Comput. 2020, 12, 388–397. [Google Scholar] [CrossRef] [Green Version]
- Cerquitelli, T.; Proto, S.; Ventura, F.; Apiletti, D.; Baralis, E. Towards a real-time unsupervised estimation of predictive model degradation. In Proceedings of the Real-Time Business Intelligence and Analytics, Los Angeles, CA, USA, 26 August 2019. [Google Scholar] [CrossRef]
- Chen, S.H.; Pollino, C.A. Good practice in Bayesian network modelling. Environ. Model. Softw. 2012, 37, 134–145. [Google Scholar] [CrossRef]
- Cobb, B.R.; Rumí, R.; Salmerón, A. Bayesian Network Models with Discrete and Continuous Variables. In Advances in Probabilistic Graphical Models. Studies in Fuzziness and Soft Computing; Lucas, P., Gámez, J.A., Salmerón, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; Volume 213. [Google Scholar] [CrossRef]
- Rezende, D.J.; Mohamed, S.; Wierstra, D. Stochastic backpropagation and approximate inference in deep generative models. In Proceedings of the 31st International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1278–1286. [Google Scholar]
- Hinton, G.E. A Practical Guide to Training Restricted Boltzmann Machines. In Neural Networks: Tricks of the Trade; Montavon, G., Orr, G.B., Müller, K.R., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7700, pp. 599–619. [Google Scholar] [CrossRef]
- Noble, W.S. How does multiple testing correction work? Nat. Biotechnol. 2009, 27, 1135–1137. [Google Scholar] [CrossRef] [Green Version]
- Streiner, D.L.; Norman, G.R. Correction for multiple testing: Is there a resolution? Chest 2011, 140, 16–18. [Google Scholar] [CrossRef] [PubMed]
- Sompairac, N.; Nazarov, P.V.; Czerwinska, U.; Cantini, L.; Biton, A.; Molkenov, A.; Zhumadilov, Z.; Barillot, E.; Radvanyi, F.; Gorban, A.; et al. Independent component analysis for unraveling the complexity of cancer omics datasets. Int. J. Mol. Sci. 2019, 20, 4414. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hicks, S.C.; Townes, F.W.; Teng, M.; Irizarry, R.A. Missing data and technical variability in single-cell RNA-sequencing experiments. Biostatistics 2018, 19, 562–578. [Google Scholar] [CrossRef]
- Krumm, N.; Sudmant, P.H.; Ko, A.; O’Roak, B.J.; Malig, M.; Coe, B.P.; Quinlan, A.R.; Nickerson, D.A.; Eichler, E.E. Copy number variation detection and genotyping from exome sequence data. Genome Res. 2012, 22, 1525–1532. [Google Scholar] [CrossRef] [Green Version]
- Koren, Y.; Carmel, L. Robust linear dimensionality reduction. IEEE Trans. Vis. Comput. Graph. 2004, 10, 459–470. [Google Scholar] [CrossRef]
- Mirkes, E.M.; Gorban, A.N.; Zinoviev, A. Supervised PCA. 2016. Available online: https://github.com/Mirkes/SupervisedPCA (accessed on 12 August 2021).
- Song, Y.; Nie, F.; Zhang, C.; Xiang, S. A unified framework for semi-supervised dimensionality reduction. Pattern Recognit. 2008, 41, 2789–2799. [Google Scholar] [CrossRef]
- Cangelosi, R.; Goriely, A. Component retention in principal component analysis with application to cDNA microarray data. Biol. Direct 2007, 2, 2. [Google Scholar] [CrossRef] [Green Version]
- Ben-David, S.; Blitzer, J.; Crammer, K.; Kulesza, A.; Pereira, F.; Vaughan, J.W. A theory of learning from different domains. Mach. Learn. 2010, 79, 151–175. [Google Scholar] [CrossRef] [Green Version]
- Sun, S.; Shi, H.; Wu, Y. A survey of multi-source domain adaptation. Inf. Fusion 2015, 24, 84–92. [Google Scholar] [CrossRef]
- Saito, K.; Watanabe, K.; Ushiku, Y.; Harada, T. Maximum classifier discrepancy for unsupervised domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3723–3732. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 2096–2130. [Google Scholar]
- Matasci, G.; Volpi, M.; Tuia, D.; Kanevski, M. Transfer component analysis for domain adaptation in image classification. In Image and Signal Processing for Remote Sensing XVII; International Society for Optics and Photonics: Bellingham, WA, USA, 2011; Volume 8180, p. 81800F. [Google Scholar] [CrossRef] [Green Version]
- Pestov, V. Is the k-NN classifier in high dimensions affected by the curse of dimensionality? Comput. Math. Appl. 2013, 65, 1427–1437. [Google Scholar] [CrossRef]
- Mirkes, E.M.; Allohibi, J.; Gorban, A.N. Fractional Norms and Quasinorms Do Not Help to Overcome the Curse of Dimensionality. Entropy 2020, 22, 1105. [Google Scholar] [CrossRef] [PubMed]
- Golubitsky, M.; Guillemin, V. Stable Mappings and Their Singularities; Springer: Berlin, Germany, 1974. [Google Scholar]
- Pugh, C. The closing lemma. Am. J. Math. 1967, 89, 956–1009. [Google Scholar] [CrossRef]
- Palis, J.; de Melo, W. The Kupka-Smale Theorem. In Geometric Theory of Dynamical Systems; Springer: New York, NY, USA, 1982. [Google Scholar] [CrossRef]
- Oxtoby, J.C. Measure and Category: A Survey of the Analogies between Topological and Measure Spaces; Springer: New York, NY, USA, 2013. [Google Scholar]
- Gorban, A.N. Equilibrium Encircling. Equations of Chemical Kinetics and Their Thermodynamic Analysis; Nauka: Novosibirsk, Russia, 1984. [Google Scholar]
- Gorban, A.N. Selection Theorem for Systems with Inheritance. Math. Model. Nat. Phenom. 2007, 2, 1–45. [Google Scholar] [CrossRef] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| n | 10 | 25 | 50 | 100 | 150 | 200 |
|---|---|---|---|---|---|---|
| 0.38 | 91 | |||||
| 2.86 | 13.9 | 194 |
| n | 10 | 25 | 50 | 100 | 150 | 200 |
|---|---|---|---|---|---|---|
| 0.61 | 910 |
| n | 25 | 50 | 100 | 150 | 200 |
|---|---|---|---|---|---|
| 30 |
| Layer Number | Type | Size |
|---|---|---|
| 1 | Input | |
| 2 | Conv2d | |
| 3 | ReLU | |
| 4 | Batch normalization | |
| 5 | Dropout 0.25 | |
| 6 | Conv2d | |
| 7 | ReLU | |
| 8 | Batch normalization | |
| 9 | Dropout 0.25 | |
| 10 | Conv2d | |
| 11 | ReLU | |
| 12 | Batch normalization | |
| 13 | Dropout 0.25 | |
| 14 | Conv2d | |
| 15 | ReLU | |
| 16 | Batch normalization | |
| 17 | Maxpool | pool size , stride |
| 18 | Dropout 0.25 | |
| 19 | Fully connected | 128 |
| 20 | ReLU | |
| 21 | Dropout 0.25 | |
| 22 | Fully connected | 128 |
| 23 | ReLU | |
| 24 | Dropout 0.25 | |
| 25 | Fully connected | 9 |
| 26 | Softmax | 9 |
| Attributes | ||||
|---|---|---|---|---|
| Layers | 26 (Softmax) | 19 (Fully connected) | 22 (Fully connected) | 23 (ReLU) |
| n | 20 | 100 | 137 | 300 | 393 |
|---|---|---|---|---|---|
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gorban, A.N.; Grechuk, B.; Mirkes, E.M.; Stasenko, S.V.; Tyukin, I.Y. High-Dimensional Separability for One- and Few-Shot Learning. Entropy 2021, 23, 1090. https://doi.org/10.3390/e23081090
Gorban AN, Grechuk B, Mirkes EM, Stasenko SV, Tyukin IY. High-Dimensional Separability for One- and Few-Shot Learning. Entropy. 2021; 23(8):1090. https://doi.org/10.3390/e23081090
Chicago/Turabian StyleGorban, Alexander N., Bogdan Grechuk, Evgeny M. Mirkes, Sergey V. Stasenko, and Ivan Y. Tyukin. 2021. "High-Dimensional Separability for One- and Few-Shot Learning" Entropy 23, no. 8: 1090. https://doi.org/10.3390/e23081090
APA StyleGorban, A. N., Grechuk, B., Mirkes, E. M., Stasenko, S. V., & Tyukin, I. Y. (2021). High-Dimensional Separability for One- and Few-Shot Learning. Entropy, 23(8), 1090. https://doi.org/10.3390/e23081090