
Providing Care: Intrinsic Human–Machine Teams and Data

Abstract
:1. Introduction
2. Background and Related Work
2.1. Artificial Intelligence, Explainability, and HMT
2.2. Integrating Qualitative Human Perspective in Machine Learning Training-Data
2.3. Clinical Decision Support Systems, a Target for Improving HMT by Incorporating Qualitative Scales
3. Technical Approach
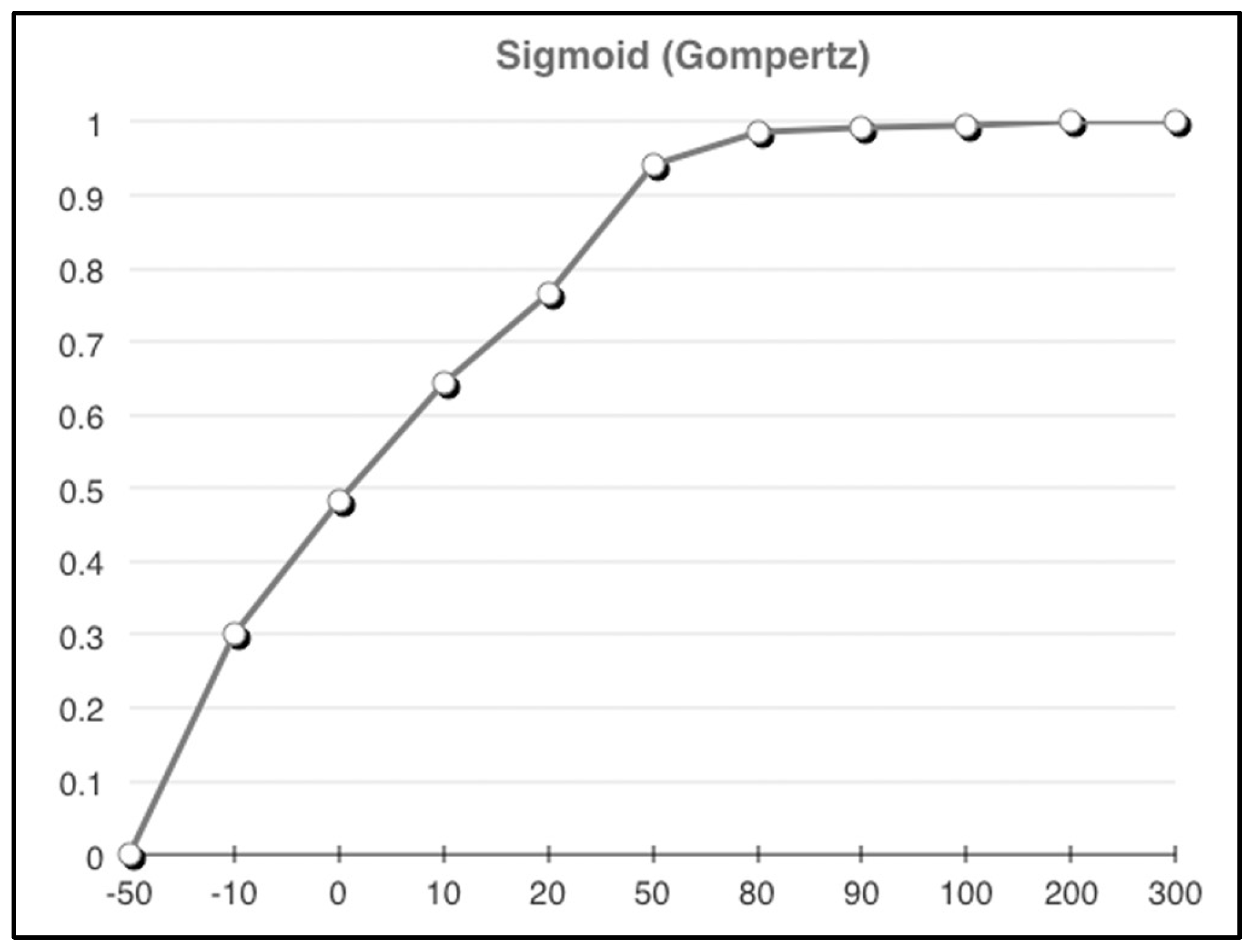
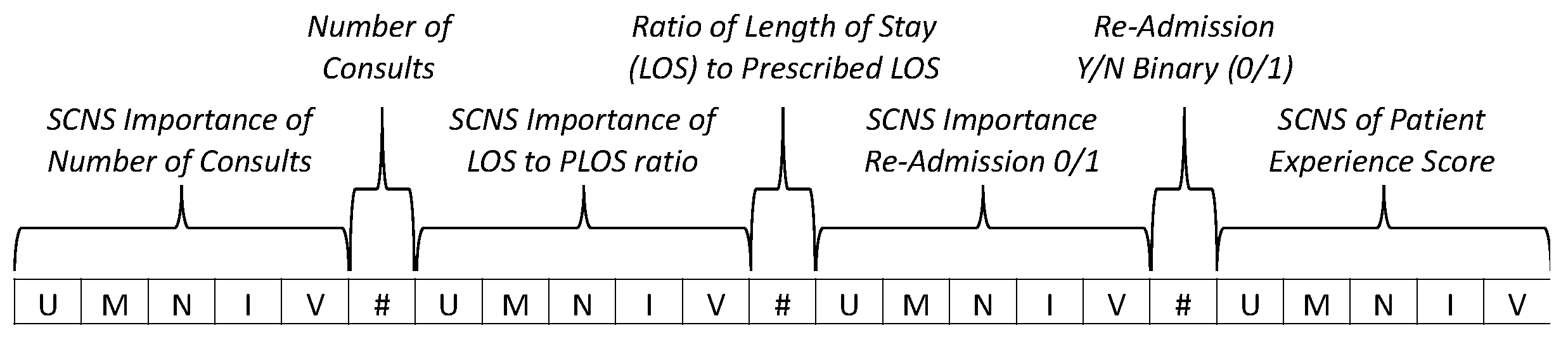
3.1. Integrating Qualitative Weights as Part of a Critical Clinical Events Vector
3.2. Consensus Adjustment for Sample Size and Contextual Considerations
3.3. The CCE Vector with Integrated Consensus Scores
4. Discussion of Similarity, Machine Learning, and Human Machine Teaming in Decision Support
4.1. Similarity—A Simple Approach to Referenced-Based Guidance
4.2. Machine Learning and Decision Support
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rajpurkar, P.; Chen, E.; Banerjee, O.; Topol, E.J. AI in Health and Medicine. Nat. Med. 2022, 28, 31–38. [Google Scholar] [CrossRef] [PubMed]
- Sarker, S.; Jamal, L.; Ahmed, S.F.; Irtisam, N. Robotics and Artificial Intelligence in Healthcare during COVID-19 Pandemic: A Systematic Review. Robot. Auton. Syst. 2021, 146, 103902. [Google Scholar] [CrossRef] [PubMed]
- Pradhan, B.; Bharti, D.; Chakravarty, S.; Ray, S.S.; Voinova, V.V.; Bonartsev, A.P.; Pal, K. Internet of Things and Robotics in Transforming Current-Day Healthcare Services. J. Healthc. Eng. 2021, 2021, 9999504. [Google Scholar] [CrossRef] [PubMed]
- Kolpashchikov, D.; Gerget, O.; Meshcheryakov, R. Robotics in Healthcare. In Handbook of Artificial Intelligence in Healthcare; Springer: Berlin/Heidelberg, Germany, 2022; pp. 281–306. [Google Scholar]
- Bakshi, G.; Kumar, A.; Puranik, A.N. Adoption of Robotics Technology in Healthcare Sector. In Advances in Communication, Devices and Networking; Springer: Berlin/Heidelberg, Germany, 2022; pp. 405–414. [Google Scholar]
- Kulkov, I. Next-Generation Business Models for Artificial Intelligence Start-Ups in the Healthcare Industry. Int. J. Entrep. Behav. Res. 2021, 27. [Google Scholar] [CrossRef]
- Daugherty, P.; Carrel-Billiard, M.; Biltz, M. Accenture Technology Vision 2019; Accenture: Dublin, Ireland, 2019. [Google Scholar]
- Collier, M.; Fu, R.; Yin, L.; Christiansen, P. Artificial Intelligence: Healthcare’s New Nervous System; Accenture: Dublin, Ireland, 2017. [Google Scholar]
- Park, S.Y.; Kuo, P.-Y.; Barbarin, A.; Kaziunas, E.; Chow, A.; Singh, K.; Wilcox, L.; Lasecki, W.S. Identifying Challenges and Opportunities in Human-AI Collaboration in Healthcare. In Proceedings of the Conference Companion Publication of the 2019 on Computer Supported Cooperative Work and Social Computing, Austin, TX, USA, 9–13 November 2019; pp. 506–510. [Google Scholar]
- Meskó, B.; Hetényi, G.; Gy Horffy, Z. Will Artificial Intelligence Solve the Human Resource Crisis in Healthcare? BMC Health Serv. Res. 2018, 18, 545. [Google Scholar] [CrossRef]
- Russell, S.; Jalaian, B.; Moskowitz, I.S. Re-Orienting towards the Science of the Artificial: Engineering AI Systems. In Systems Engineering and Artificial Intelligence; Springer Nature, Switzerland AG: Cham, Switzerland, 2021. [Google Scholar]
- Norori, N.; Hu, Q.; Aellen, F.M.; Faraci, F.D.; Tzovara, A. Addressing Bias in Big Data and AI for Health Care: A Call for Open Science. Patterns 2021, 2, 100347. [Google Scholar] [CrossRef]
- Lyons, J.B.; Wynne, K.T.; Mahoney, S.; Roebke, M.A. Trust and Human-Machine Teaming: A Qualitative Study. In Artificial Intelligence for the Internet of Everything; Elsevier: Amsterdam, The Netherlands, 2019; pp. 101–116. [Google Scholar]
- Paleja, R.; Ghuy, M.; Ranawaka Arachchige, N.; Jensen, R.; Gombolay, M. The Utility of Explainable Ai in Ad Hoc Human-Machine Teaming. Adv. Neural Inf. Process. Syst. 2021, 34, 610–623. [Google Scholar]
- Tucci, V.; Saary, J.; Doyle, T.E. Factors Influencing Trust in Medical Artificial Intelligence for Healthcare Professionals: A Narrative Review. J. Med. Artif. Intell. 2022, 5, 4. [Google Scholar] [CrossRef]
- Lai, Y.; Kankanhalli, A.; Ong, D. Human-AI Collaboration in Healthcare: A Review and Research Agenda. In Proceedings of the Hawaii International Conference on System Sciences 2021, Maui, HI, USA, 5–8 January 2021. [Google Scholar]
- Yang, Z.; Ng, B.-Y.; Kankanhalli, A.; Yip, J.W.L. Workarounds in the Use of IS in Healthcare: A Case Study of an Electronic Medication Administration System. Int. J. Hum. Comput. Stud. 2012, 70, 43–65. [Google Scholar] [CrossRef]
- Asan, O.; Bayrak, A.E.; Choudhury, A. Artificial Intelligence and Human Trust in Healthcare: Focus on Clinicians. J. Med. Internet Res. 2020, 22, e15154. [Google Scholar] [CrossRef]
- Maadi, M.; Akbarzadeh Khorshidi, H.; Aickelin, U. A Review on Human–AI Interaction in Machine Learning and Insights for Medical Applications. Int. J. Environ. Res. Public Health 2021, 18, 2121. [Google Scholar] [CrossRef]
- Wang, D.; Churchill, E.; Maes, P.; Fan, X.; Shneiderman, B.; Shi, Y.; Wang, Q. From Human-Human Collaboration to Human-AI Collaboration: Designing AI Systems That Can Work Together with People. In Proceedings of the Extended Abstracts of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; pp. 1–6. [Google Scholar]
- Mucha, T.; Halminen, O.; Tenhunen, H.; Seppälä, T. Commercial Adoption of AI in the Healthcare Sector: An Exploratory Analysis of S&P500 Companies. In Proceedings of the MIE, Geneva, Switzerland, 28 April–1 May 2020; pp. 113–117. [Google Scholar]
- Väänänen, A.; Haataja, K.; Vehviläinen-Julkunen, K.; Toivanen, P. AI in Healthcare: A Narrative Review. F1000Research 2021, 10, 6. [Google Scholar] [CrossRef]
- Laï, M.-C.; Brian, M.; Mamzer, M.-F. Perceptions of Artificial Intelligence in Healthcare: Findings from a Qualitative Survey Study among Actors in France. J. Transl. Med. 2020, 18, 14. [Google Scholar] [CrossRef]
- Health IT Analytics Arguing the Pros and Cons of Artificial Intelligence in Healthcare. Available online: https://healthitanalytics.com/news/arguing-the-pros-and-cons-of-artificial-intelligence-in-healthcare (accessed on 16 August 2022).
- Davenport, T.H.; Bean, R. Clinical AI Gets the Headlines, but Administrative AI May Be a Better Bet. Available online: https://sloanreview.mit.edu/article/clinical-ai-gets-the-headlines-but-administrative-ai-may-be-a-better-bet/ (accessed on 16 August 2022).
- Nazar, M.; Alam, M.M.; Yafi, E.; Mazliham, M.S. A Systematic Review of Human-Computer Interaction and Explainable Artificial Intelligence in Healthcare with Artificial Intelligence Techniques. IEEE Access 2021, 9, 153316–153348. [Google Scholar] [CrossRef]
- Pawar, U.; O’Shea, D.; Rea, S.; O’Reilly, R. Explainable Ai in Healthcare. In Proceedings of the 2020 International Conference on Cyber Situational Awareness, Data Analytics and Assessment (CyberSA), Dublin, Ireland, 15–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–2. [Google Scholar]
- Benrimoh, D.; Israel, S.; Fratila, R.; Armstrong, C.; Perlman, K.; Rosenfeld, A.; Kapelner, A. Editorial: ML and AI Safety, Effectiveness and Explainability in Healthcare. Front. Big Data 2021, 4, 727856. [Google Scholar] [CrossRef]
- Stiglic, G.; Kocbek, P.; Fijacko, N.; Zitnik, M.; Verbert, K.; Cilar, L. Interpretability of Machine Learning-Based Prediction Models in Healthcare. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2020, 10, e1379. [Google Scholar] [CrossRef]
- Wang, F.; Kaushal, R.; Khullar, D. Should Health Care Demand Interpretable Artificial Intelligence or Accept “Black Box” Medicine? Ann. Intern. Med. 2020, 172, 59–60. [Google Scholar] [CrossRef]
- Neuhauser, L.; Kreps, G.L.; Morrison, K.; Athanasoulis, M.; Kirienko, N.; Van Brunt, D. Using Design Science and Artificial Intelligence to Improve Health Communication: ChronologyMD Case Example. Patient Educ. Couns. 2013, 92, 211–217. [Google Scholar] [CrossRef]
- Myroniuk, T.W.; Teti, M.; Schatz, E. Without Qualitative Health Data, Precision Health Will Be Imprecise. Int. J. Qual. Methods 2021, 20, 16094069211045476. [Google Scholar] [CrossRef]
- Janisse, T. The Human-Machine Interface: Inviting Your Computer Into Your Patient-Clinician Relationship. Perm. J. 2001, 5, 2–4. [Google Scholar]
- Willits, F.K.; Theodori, G.L.; Luloff, A.E. Another Look at Likert Scales. J. Rural Soc. Sci. 2016, 31, 6. [Google Scholar]
- Allen, I.E.; Seaman, C.A. Likert Scales and Data Analyses. Qual. Prog. 2007, 40, 64–65. [Google Scholar]
- Albaum, G. The Likert Scale Revisited. Mark. Res. Soc. J. 1997, 39, 331–348. [Google Scholar] [CrossRef]
- Hodge, D.R.; Gillespie, D. Phrase Completions: An Alternative to Likert Scales. Soc. Work Res. 2003, 27, 45–55. [Google Scholar] [CrossRef]
- Trevelyan, E.G.; Robinson, N. Delphi Methodology in Health Research: How to Do It? Eur. J. Integr. Med. 2015, 7, 423–428. [Google Scholar] [CrossRef]
- Laka, M.; Milazzo, A.; Merlin, T. Factors That Impact the Adoption of Clinical Decision Support Systems (CDSS) in Healthcare Settings for Evidence-Based Decision Making. Int. J. Environ. Res. Public Health 2021, 18, 1901. [Google Scholar] [CrossRef]
- Agency for Healthcare Research and Quality (AHRQ). Clinical Decision Support Systems; Agency for Healthcare Research and Quality (AHRQ): Rockville, MD, USA, 2019. [Google Scholar]
- Denolle, T.; Groupe de Travail; Groupe de Lecture. Expert consensus statement on blood pressure measurement from the French Society of Hypertension, an affiliate of the French Society of Cardiology. Presse Medicale 2019, 48, 1319–1328. [Google Scholar] [CrossRef]
- Wierman, M.J.; Tastle, W.J. Consensus and Dissention: Theory and Properties. In Proceedings of the NAFIPS 2005-2005 Annual Meeting of the North American Fuzzy Information Processing Society, Detroit, MI, USA, 26–28 June 2005; IEEE: Piscataway, NJ, USA, 2005; pp. 75–79. [Google Scholar]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Tastle, J.M.; Tastle, W.J. Extending the Consensus Measure: Analyzing Ordinal Data with Respect to Extrema. Syst. Educ. J. 2006, 4. Available online: http://isedj.org/4/72/ (accessed on 22 August 2022).
- Tastle, W.J.; Wierman, M.J. An Information Theoretic Measure for the Evaluation of Ordinal Scale Data. Behav. Res. Methods 2006, 38, 487–494. [Google Scholar] [CrossRef]
- Santoyo-Sánchez, G.; Merino-Soto, C.; Flores-Hernández, S.; Pelcastre-Villafuerte, B.E.; Reyes-Morales, H. Content Validity of a Scale Designed to Measure the Access of Older Adults to Outpatient Health Services. Int. J. Environ. Res. Public Health 2022, 19, 10102. [Google Scholar] [CrossRef] [PubMed]
- Bahaitham, H.A. A Framework for Quantifying Sustainability of Lean Implementation in Healthcare Organizations. Ph.D. Thesis, College of Engineering and Computer Science, University of Central Florida, Orlando, FL, USA, 2011. [Google Scholar]
- Engle, K.M.; Forgionne, G.A. Rescaling Non-Metric Data to Metric Data Using Multi-Dimensional Scaling. In Proceedings of the International Conference on Internationalization, Design and Global Development, San Diego, CA, USA, 19–24 July 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 245–253. [Google Scholar]
- Gaube, S.; Suresh, H.; Raue, M.; Merritt, A.; Berkowitz, S.J.; Lermer, E.; Coughlin, J.F.; Guttag, J.V.; Colak, E.; Ghassemi, M. Do as AI Say: Susceptibility in Deployment of Clinical Decision-Aids. NPJ Digit. Med. 2021, 4, 31. [Google Scholar] [CrossRef] [PubMed]
- Henry, K.E.; Kornfield, R.; Sridharan, A.; Linton, R.C.; Groh, C.; Wang, T.; Wu, A.; Mutlu, B.; Saria, S. Human–Machine Teaming Is Key to AI Adoption: Clinicians’ Experiences with a Deployed Machine Learning System. NPJ Digit. Med. 2022, 5, 97. [Google Scholar] [CrossRef] [PubMed]
- Evers, E.R.; Imas, A.; Kang, C. On the Role of Similarity in Mental Accounting and Hedonic Editing. Psychol. Rev. 2022, 129, 777. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Garcia, E.K.; Gupta, M.R.; Rahimi, A.; Cazzanti, L. Similarity-Based Classification: Concepts and Algorithms. J. Mach. Learn. Res. 2009, 10, 741–776. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Assessment Score Frequency | Strength-of-Consensus | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| U (1) | M (2) | N (3) | I (4) | V (5) | Mean | StDv | Cns | U | M | N | I | V | |
| V1 | 5 | 0 | 0 | 0 | 5 | 3.000 | 2.000 | 0.000 | 0.500 | 0.565 | 0.585 | 0.565 | 0.500 |
| V2 | 2 | 2 | 2 | 2 | 2 | 3.000 | 1.414 | 0.425 | 0.543 | 0.704 | 0.757 | 0.704 | 0.543 |
| V3 | 0 | 3 | 4 | 3 | 0 | 3.000 | 0.775 | 0.605 | 0.573 | 0.798 | 0.884 | 0.798 | 0.573 |
| V4 | 0 | 0 | 10 | 0 | 0 | 3.000 | 0.000 | 1.000 | 0.585 | 0.807 | 1.000 | 0.807 | 0.585 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Russell, S.; Kumar, A. Providing Care: Intrinsic Human–Machine Teams and Data. Entropy 2022, 24, 1369. https://doi.org/10.3390/e24101369
Russell S, Kumar A. Providing Care: Intrinsic Human–Machine Teams and Data. Entropy. 2022; 24(10):1369. https://doi.org/10.3390/e24101369
Chicago/Turabian StyleRussell, Stephen, and Ashwin Kumar. 2022. "Providing Care: Intrinsic Human–Machine Teams and Data" Entropy 24, no. 10: 1369. https://doi.org/10.3390/e24101369
APA StyleRussell, S., & Kumar, A. (2022). Providing Care: Intrinsic Human–Machine Teams and Data. Entropy, 24(10), 1369. https://doi.org/10.3390/e24101369