1. Introduction
Consider an ecological community with a well-defined set of species
and an associated distribution of proportions, also known as species abundances,
. More generally,
and
may be considered as a countable alphabet and an associated probability distribution, where
K may be a finite integer or infinite. In this article, the
s may be interchangeably referred to as letters of an alphabet or species in a community, and
may be referred to as a species abundance distribution or a probability distribution. The notion of diversity in a community has been of long standing research interest. What is diversity and how should it be quantified have been the two fundamental questions at the center of diversity literature for many decades. A large number of diversity indices have been proposed in the history, for example, those by Simpson in [
1], Shannon in [
2], Rényi in [
3] and Tsallis in [
4] are among many most commonly used indices, each of which has been argued to have particular merit. The opinions on diversity and possible numerical indices to measure it are indeed diverse. There are even doubts in the general concept of diversity, for example see [
5,
6]; and there is also a school of thought which believes that the species richness is the only acceptable diversity index, for example see [
7]. There have also been unifying efforts to define diversity indices to accommodate a range of such indices, for example see [
8,
9,
10,
11], among others. Nevertheless when it come to measuring diversity, there is a lack of agreement for a generally satisfactory univariate index. The general consensus in the existing literature seems to be that a better description of diversity should be a multidimensional index set, or a profile. A good introduction to diversity profiles is offered in [
10] where many basic concepts are articulated and many related references are found.
The departure point of this article is the species richness index, K, the number of different species in a community. The species richness index is a part of almost every discussion in the existing literature, and it is so for a good reason. Like the notion of happiness, diversity is an intuitively clear notion for most, but is difficult to quantify. Does there exist a universally accepted index (or an index profile) that would please all? The answer is unknown. If there does, it has not been found. If not, then the objective would be to find one that would have wider acceptance. Either way, the search should and does continue. In that regard, the species richness index K is perhaps one of the simplest, the most direct and most intuitive of all existing diversity indices. It is difficult to dismiss such an index.
Nevertheless the species richness index has many weaknesses which can be summarized into the following list.
It is oblivious to the magnitude of species abundances.
It is ultra-sensitive to redistribution of any arbitrarily small proportion.
It is difficult to estimate based on a sample.
It does not provide an ordering, or a partial ordering, for communities with infinite number of species.
The first weakness is easily illustrated by a simple example. Consider two distributions with , and . The species richness is 2 for both but it clearly does not capture the intuitive notion of diversity. In the diversity literature species richness is sometimes considered a separated type of index from those taking abundances into consideration. This article argues that the separation is not necessary and a slight change of perspective would embed species richness in a profile that naturally takes abundances into consideration.
The second weakness is also easily illustrated by a simple example. Consider where is an arbitrarily small value. The species richness of is . However taking the abundance and redistributing it to m new species, , evenly, a new distribution is created. It is easily seen first that the species richness of is , second that m is arbitrarily large so the species richness of can be carried over all bounds, and third that the arbitrarily large difference in species richness between and is due to an arbitrarily small difference between and .
The second weakness demonstrated above is not unique to the species richness. Consider Shannon’s entropy,
. Taking an arbitrarily small quantity
(from any
), re-distributing it evenly to
m new species each of which with proportion
, and hence creating distribution
, it would then add approximately
to
H in evaluating entropy of
. (1) may be carried over all bounds as
m increases indefinitely.
In fact, this issue of ultra-sensitivity is well-known beyond the boundary of diversity literature. In modern data science where the sample space is large, non-metrized, non-ordinal, and not completely pre-scribed, statistical inference often relies on information theoretical quantities that are sensitive to the probabilities of rare events. Such information-theoretic quantities are often ultra-sensitive toward small perturbations in the tail of a distribution.
The third weakness is essentially caused by the second weakness. As demonstrated above, two distributions, different only in the way that one is an arbitrarily stretched version of another by an arbitrarily small mass in abundance, can have arbitrarily different values in species richness. In that regard, in a random sample of size
n, the species with stretched proportions collectively have very small probability to be represented. This makes it nearly impossible to estimate
K with any reliability non-parametrically. Estimating
K with a random sample is a long standing difficult problem in statistics. Interested readers may refer to two excellent survey papers, ref. [
12,
13], respectively. More specifically, a worthy line of approaches based on Turing’s formula may also be of interest, see [
14]. See also for example, [
15,
16,
17,
18]. Nevertheless it is fair to say that, not surprisingly, there are no known generally satisfactory estimators of
K.
The fourth weakness is in the generality of the definition. Generally one would prefer to have a notion of diversity not only for communities with finite K but also for . The species richness does not provide an ordering, or a partial ordering, for all communities with , In fact, it does not provide an ordering or partial ordering communities with a same .
The generalized species richness proposed in this article resolves, or at least alleviates all these weaknesses. Toward introducing the generalized species richness indices, consider the second weakness mentioned above once more. Recognizing the fact that an infinitesimal perturbation in the abundance distribution could greatly impact species richness, one may ask the following questions.
If , where , of the communities belonging to species with the lowest abundances is trimmed, what would be the species richness of the remaining community?
What is the least number of species that can be represented by of the community?
Let the non-increasing ordered
be denoted by
where
for all
. The answer to both above questions is, for a fixed
,
where
is the indicator function. For a given
, there is only one non-zero term in the summation of (3) with an integer value
k such that
is sandwiched between
exclusive and
inclusive. See a graphic representation of
in
Figure 1.
is the proposed generalized species richness, and it may also be reasonably referred to as the
-trimmed species richness. Let
be referred to as the species richness profile.
Revisiting the example of and mentioned above for the first weakness of species richness , with say , it is easily seen that and . Revisiting the example of and its stretched version mentioned above for the second weakness of species richness , it is also easy to see that arbitrary stretching of , that is, letting m increase indefinitely, will not carry over all bounds so long as . In this regard, it is clear that may be viewed as a robustified version of species richness. With the influence from arbitrary stretching of an infinitesimal mass in abundance controlled (but not eliminated), the difficulty level in estimating is considerably reduced from that in estimating K. Finally the fourth weakness of species richness is eliminated since is always finite so long as for distributions with as well as .
In
Section 2, several properties of the generalized species richness are established. More specifically, it is established that every member of
in (6) is a diversity index as it satisfies a weak version of the usual axioms of diversity indices; and a notion of “breakdown point” is introduced and the robustness of
is gauged accordingly. Furthermore, a notion of “completeness” in profiles is introduced and
of (6), as a profile, is shown to be complete.
To estimate
, let an identically and independently distributed (
) sample of size
n be summarized into sample species frequencies,
, and relative species frequencies,
; and let
be a non-increasingly ordered
. A natural estimator of
is (3), (4) or (5), with
in place of
, that is,
specifically noting that
is based on the same functional
in (3) but evaluated at the empirical distribution
instead of
. It is easy to see that (7) is simply counting the number of species in the sample after
of the observations in the sample with the lowest (observed) species relative frequencies trimmed.
in (7) will be referred to as the plug-in estimator of
in subsequent text.
However
significantly under-estimates
due to a well-known phenomenon—a perpetual under representation of small probability letters in a finite sample. This phenomenon was perhaps first explicitly identified by Alan Turing during World War II in an effort to break the German naval enigmas, and is referred to as the Turing phenomenon in the subsequent text. The core of the Turing phenomenon is the total probability associated with letters of the alphabet that are not represented in a sample, that is,
, also sometimes known as the “missing probability”. In non-parametric estimation of information-theoretic quantities, small probability letters often carry much information and the fact many (possibly infinitely many) of them are missing in a sample often causes a significant downward bias. For example, in view of
where
and
, Shannon’s entropy
is an weighted average of
with
. For another example, the species richness
is a weighted average of
with
. In both cases, the small probability events get heavy weights and therefore under-representation of them in a sample translates to under-estimation. In comparison of the two examples mentioned above, the Turing phenomenon has a much more profound impact on estimation of
K than
H in the sense that
and
as
. Having realized the difficulty in estimating such quantities, it would seem reasonable to device mechanisms, either by modifying the estimands (provided that the modified estimands remain relevant) or the assumption on the underlying distribution, to control the behavior of corresponding estimators. For example, ref. [
19,
20] discuss certain optimal rates of convergence for a class of estimators of entropy and community size under certain condition to prevent
from being arbitrarily small, in turn to control the behavior of the estimators. This article however seeks such controls by means of
-trimming, both in the estimand,
, as well as in its estimator,
, specifically with regard to the notion of species richness.
On the other hand,
in (7) may be improved by means of bias correction. There are many possible ways to correct the bias. For simplicity, an estimator based on the basic bootstrap method is proposed as in (14) of
Section 3. In the same section, the statistical properties of both
of (7) and
of (14) are discussed. More specifically several asymptotic properties of partial sums of
are given. Based on these asymptotic results, several conservative one-sample and two-samples inferential procedures regarding the underlying generalized species richness are proposed and justified. Several simulation results are also reported in gauging the performance of the estimators. Finally an real life ecological data set is used to illustrate the proposed method.
The article ends with an appendix where many lemmas, corollaries and propositions, along with their proofs, are found.
2. Properties of Generalized Species Richness Indices
Diversity as an intuitive notion is quite clear in most minds. However the quantification of diversity is still quite a distance away from a point of universal consensus. In the diversity literature it is commonly accepted that an index may be reasonably referred to as a diversity index if it satisfies several axioms. For notation convenience, let be the family of all distributions such that , that is, on a community with K species (or a finite alphabet with cardinality K), and let be the family of all possible distributions on a general countable community. It follows that . Let be a functional defined for every . The essential axioms of diversity indices include:
- A1:
A diversity index is invariant under any permutation of species labels, that is, any permutation on the index set .
- A2:
A diversity index is minimized at .
- A3:
A diversity index is maximized at , the uniform distribution in for every positive integer K.
- A4:
For any distribution , let be the associated distribution of resulted from a transfer of a mass from a higher to a lower subject to , with all other s remain unchanged. A diversity index satisfies .
The list of axioms may grow longer representing a more stringent imposition on the underlying diversity indices. There are also stronger versions of the axioms. For example, as stated is a weaker version of one that requires the index to be minimized only at but not at any other distributions. Similarly as stated above also has a stronger version which requires the index to be maximized only at but not at any other distributions. Axiom also has a stronger version which requires a strict inequality, that is, . The weaker axioms are chosen in this article because species richness K, the reference index of the discussion, satisfies them.
Regardless the length or the version of the axioms, Axiom is the most essential of them all and is universally accepted. It is important to recognize the implication of —every diversity index is a functional of only through . Consequently the domain of all diversity indices can be represented by the subset of that contains only distributions in non-increasing order, denoted as .
For a given
, it is clear
satisfies
,
and
. The fact that
satisfies
is true but is not so obviously. This fact is one of the main results of this article and is summarized in Proposition A1 along with a lengthy proof, both of which are given in
Appendix A. The fact that
satisfies all axioms
through
suggests that it may be reasonably regarded as a diversity index.
To quantify the robustness of the generalized species richness indices against disturbances due to re-distributions of a small abundance (or probability) mass, a notion of breakdown point may be introduced. Breakdown point, roughly speaking, is the greatest proportion of data, whose worst behavior may not carry a function of the data over all bounds. To be more precise, let
be an abundance distribution, let
be an arbitrarily small value, and let
and
be two non-negative sequences, each of which is with total mass of
, that is,
. Let
represent a perturbation by subtracting a mass
away from
by means of
and adding back the same mass by means of
.
Definition 1. Let be any non-negative function of . The breakdown point of D at is Obviously . A higher value of is regarded as an indication that D is more robust at .
Definition 2. Let be as in Definition 1. Let be a sub-family of . For any given , if for every , then is said to be robust with respect to . In particular, if for every , then is said to be robust.
Example 1. The species richness, K, is -robust. This is so because for any and any small .
Example 2. The generalized species richness, , is -robust. This claim is one of the main results of this article and is summarized in Proposition A2. Both the proposition and its proof are given in Appendix A. In passing, it may also be of interest to evaluate the robustness of two other community diversity indices, Shannon’s entropy and the Gini-Simpson index .
Example 3. Shannon’s entropy is -robust. To see this, for a given , let be an arbitrarily small value and let a total mass of cumulatively trimmed from the right end in , that is, using the language of Definition 1,which has zeros in the first positions and in the th position. In such a construction, the remainder of the mass of covers species, and . Redistributing the mass uniformly over m indices from to with mass , resulting in . It follows that, as , Example 4. The Gini-Simpson index is -robust. This is clearly true because for any abundance distribution .
A diversity profile is a set of diversity indices containing more than one index. A profile is generally preferred over a single diversity index because it is commonly accepted that diversity is a multi-dimensional notion and is better captured by a multivariate index. An immediate question naturally arises: how much diversity information is contained in a profile? This question can be partially answered with a notion of completeness defined below.
Definition 3. A profile of indices, where A is a set containing more than one element, is said to be complete, if, for any two distributions and , if and only if for every .
Definition 3 essentially says that a complete profile uniquely determines , and in turn uniquely determines any other diversity index evaluated at .
Example 5. of (6) is complete. This claim is clearly true noting, for each positive integer i, . of (6) is not the only complete profile. The two well known families of diversity indices given in the following two examples are also complete.
Example 6. The generalized Simpson’s diversity indices, , is complete. The fact that , indexed by positive integers , is a family of diversity indices is established by Grabchak, Marcon, Lang and Zhang (2017). The claim of completeness follows the fact that uniquely determines , a fact established in [21]. Example 7. Rényi’s diversity profile is complete. The completeness follows the fact that the subset of , , uniquely determines , which uniquely determines .
3. Inference
Let the discussion of this section begin with a natural estimator of , , as given in (7), which may be viewed an estimator based on the right-tail of being trimmed by a fixed mass . This estimator however presents several difficulties in developing valid inferential procedures regarding . Towards describing some of these difficulties, the following proposition is first stated and proved.
Proposition 1. Let be the underlying distribution on a countable alphabet, satisfying for every , let be the corresponding relative letter frequencies in an sample of size n, and let be a positive integer such that . Suppose the multiplicity of in is one. Then as ,
;
; and
.
Proof. Part 1 directly follows from the central limit theorem. For Part 2, first consider an aggregation of the letters as follows. If
let
, and if
let
be any index such that
. Let the observed relative letter frequencies in the sample be aggregated accordingly, in particularly let
. Let
, and let
. It follows that
, that is to say that,
where
is an arbitrarily small
-neighborhood centered at the point
. Noting
s are arranged in a non-increasing order,
has multiplicity 1,
is finite, and
is arbitrarily small, the event
implies the event that the set of
largest
s are identical to the first
s in
, that is,
. It follows that
, and that for any
.
Part 2 follows.
For Part 3, since
and the first term converges to zero in probability by Part 2, the asymptotic normality follows Part 1 by Slusky’s theorem. □
The first difficulty of
is that it cannot be guaranteed to be consistent under general conditions. To see this, one needs only to consider a special case of
. By Part 3 of Proposition 1, for sufficiently large
n,
(10) implies inconsistency and, in addition to that, (10) also suggests that, for sufficiently large
n,
could over-estimate
, albeit by at most one. Clearly the said inconsistency is caused by the discrete nature of the functional
.
The second difficulty of is its significant downward bias when n is relatively small. To illustrate the bias, consider the extreme case of in , which is simply the species richness index, K, in case of a finite sample space. If K is relatively large, a relatively small sample of size n would likely not cover all K species in the community. In fact, the sample would typically miss a large number of species, that is, where is observed number of species in a sample. Consequently the empirical distribution, would consist of mostly zeros and hence would severely under-represent in terms of species richness. When but small, the same qualitative argument explains the significant downward bias of .
The possible inconsistency, along with the persistent and significant downward bias, gives much difficulty in developing inferential procedures under general conditions based on asymptotic properties such as Part 3 of Proposition 1.
Next consider bootstrapping confidence intervals (in general standard notions), respectively, of the quantile method and of the centered quantile method, also known as the basic method, , where denotes the estimator based on the original sample of size n and and , respectively, denote the th and th percentiles of the bootstrapping samples.
First let it be noted that the quantile method
is an inadequate
confidence. To see this, let the extreme case of
with
be considered once again. There, given an empirical distribution,
. It is clear that
as already argued above. For the same reason, by sampling from
, every
. Consequently
necessarily excludes
far to the right, causing the coverage of the bootstrapping interval to have much lower coverage than
. This is to say that, in terms of estimating
, the downward bias of
strikes twice in bootstrapping with the quantile method, once in using the original sample and once in using a bootstrapping sample. In fact, it is commonly observed with real data sets that
where
and
are the
th and
th percentiles of the estimates of
based on bootstrapping samples. See Example 8 below. The discomforting (11) essentially disqualifies the bootstrapping confidence interval based on the quantile method as a valid inferential tool.
However bootstrapping based on the centered quantile method, also known as the basic bootstrapping method, is qualitatively different. There the downward bias
is off set by the bootstrapping downward bias
. Once again in the extreme case of
with
, since
for every bootstrapping sample, it follows that
and hence
, or
that is, the centered bootstrapping confidence interval excludes
to the left of the interval. In fact (12) is commonly observed with real data sets even when
is small. See Example 8 below. Unlike (11), the fact that
is outside of the centered bootstrapping confidence interval in (12) only indicates inadequacy of the estimator
but not that of the interval itself. In fact the centered bootstrapping confidence interval,
represents a bias-adjustment in the right direction, that is, the bias in
as an estimator of
is partially offset by that in
as an estimator of
. It is to be noted that (12) suggests a bias-adjusted alternative estimator to
,
where
is the median of bootstrapped estimates.
The
bootstrapping confidence interval, or confidence set since only the integer values in the interval are relevant, in (13) provides a basic assessment of
’s whereabouts. However its coverage does necessarily converge to the claimed value
as
n increasing indefinitely, due to the above mentioned possible inconsistency of
and the consequential “at-most-one” over-estimation asymptotically. To take that into consideration, a conservative adjustment may be adopted by extending the lower limit of (13) by one, that is,
An advantage of (15) is that its asymptotic coverage is at least
for general
, but a disadvantage is that the limiting form of (15) necessarily contains two integer values instead of one, which (13) could achieve when
is consistent.
On the other hand, while (15) accommodates the issue of possible asymptotic over-estimation (by at most one) by
, in most practical cases, the more acute issue is still the under-estimation of
by
when
n is not sufficiently large. The confidence set in (15) generally requires
n to be quite large for its coverage to be reasonably close to the claimed coverage
. To help accelerate the convergence of the actual coverage to the claimed coverage, a more conservative adjustment may be adopted by extending the right limit of (15) by one, that is,
Advantages of (16) are that its asymptotic coverage is at least
for general
and that its actual coverage converges to at least
faster as
n increases. However a disadvantage is that the limiting form of (16) necessarily contains three integer values and no fewer.
The bootstrapping confidence intervals, described in (13), (15) and (16), may also be utilized in testing hypothesis with different degrees of conservativeness. For example, based on (13) and at the
level of significance, in testing
versus
,
or
,
is a pre-specified positive integer, one may choose to reject
when
respectively.
Based on (15) and at the
level of significance, in testing
versus
,
or
,
is a pre-specified positive integer, one may choose to reject
when
respectively.
Based on (16) and at the
level of significance, in testing
versus
,
or
,
is a pre-specified positive integer, one may choose to reject
when
respectively.
Suppose there are two communities and it is of interest to estimate the difference between the two
-trimmed richness indices,
where
and
are
-trimmed richness indices of the two underlying communities, respectively. The proposed estimator of
in (26) is
where
and
, where
and
are as in (7) and
and
are respective bootstrapping medians from the two samples as in (14).
In testing equality of generalized species richness of two communities,
, one may first consider a bootstrapping
confidence interval for
based on two independent samples are size
and
, respectively,
where
,
where
and
are the
th and the
th percentiles of the bootstrapping estimates, each of which is based a sample of size
from
and a sample of size
from
, where, for
or
,
is the ordered relative frequencies of letters in the sample of size
from the
j th community.
For,
versus
, or
, where
and
are the respective generalized species richness of two communities and
is a pre-fixed integer, approximate testing procedures may be devised based (28) or (29). For example, based on (28), one may choose to reject
when
Similarly, based on (29), one may choose to reject
when
To assess the reliability of the inferential procedures discussed above, several simulation studies are conducted. The studies are carried out under three different distributions. The first distribution is the uniform distribution with and for . The second distribution is a triangular distribution with and for . The third distribution is the Poisson distribution with and , noting that in this case K is infinite.
In
Table 1,
Table 2 and
Table 3, the bias and the mean squared errors of
of (7) and
of (14) are compared, at two levels of
,
and
, for various sample sizes,
n.
Table 1,
Table 2 and
Table 3, respectively, summarize the results under three different distributions, the uniform, the triangular and the Poisson. Each simulation scenario is based on 5000 repeated samples. Each sample is bootstrapped 1000 times. The bias is defined in such a way that, a positive value indicates an under-estimation and a negative value indicates an over-estimation. The variable
T is the average of Turing’s formula,
, where
is the number of singletons in a sample, based on 5000 simulated samples.
T helps to indicate the adequacy of sample size. Turing’s formula,
, is sometimes called the sample coverage deficit and
is the sample coverage (see [
17]).
It is quite clear that generally has a smaller simulated bias than . More specifically, if one considers an absolute bias being less than one to be satisfactory, then gets there faster, as n increases, than in all cases considered in the simulation studies.
To assess the performance of the confidence sets in (13), (15) and (16), their actual coverage rates are evaluated by simulation studies with
for various sample sizes and distributions. For each scenario, the coverage rate is based on 5000 simulated samples and for each sample, the bootstrapping confidence set is based on 1000 bootstrapping samples. The results are summarized in
Table 4,
Table 5 and
Table 6.
Let it be noted that, although the confidence set of (13) could perform well in some cases (see Columns 3 and 6 in
Table 4, and Columns 6 and 12 of
Table 5), it has difficulty in providing an appropriate coverage in many other cases (see Column 12 of
Table 4, Columns 3, 6, 9 and 12 of
Table 5, and Columns 3 and 9 of
Table 6). The said difficulty is partially caused by the inconsistency mentioned above in combinations of certain distributional characteristics and the values of
. Similarly, the confidence set of (15) suffers from the same difficulty though to a lesser degree. It could also perform well in some cases (see Columns 4, 7, 10 and 13 in
Table 4, Columns 7 and 10 of
Table 5, and Columns 7 and 10 of
Table 6), but it does not in many other cases (see Column 4 of
Table 5, Columns 4 and 9 of
Table 6). Since in practice the underlying distribution is not observable, it cannot be determined a priori what values of
are appropriate and what are not. This fact essentially disqualifies the confidence sets of (13) and (15) as general inferential procedures, but (16). Additionally, to be noted is the fact that the confidence set of (16) performs well across all cases in the simulation studies albeit more conservative. The confidence sets of (28) and (29) have general better performances than their one-sample counterparts due to an offset of bias between the two one-sample estimators.
Another point of interest pertains to the practically important question of how large a sample should be in order for (16) to produce a reasonable coverage. Simulation results in
Table 4,
Table 5 and
Table 6 seem to indicate that the coverage is adequate when Turing’s formula, which estimates the total probability associated with the letters of the alphabet not represented in a given sample, takes on a value approximately at a level not much greater than
, that is,
where
is the number of species observed exactly once in the sample, referred to as the rule of thumb below. (Interested readers may refer to Zhang (2017) for a comprehensive introduction to Turing’s formula.)
In summary, all things considered, observing the rule of thumb,
(14) is the proposed estimator of ;
(16) is the proposed confidence set for ;
(23)–(25) are the proposed approximate size- tests of hypothesis involving ;
(29) is the proposed confidence set for ; and
(32) and (33) are the proposed approximate size- tests of hypothesis involving .
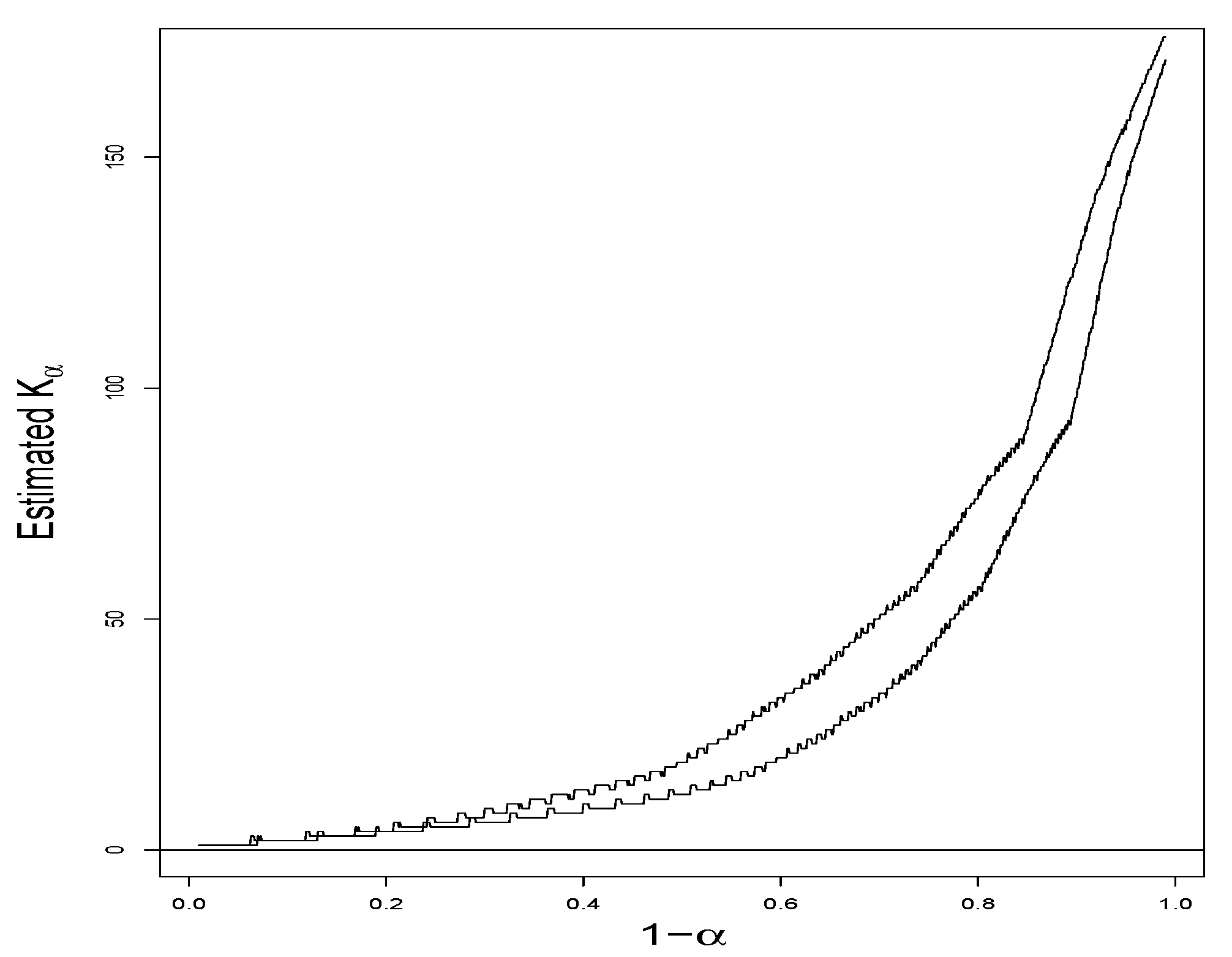
Example 8. Two tree samples of 1-ha plots (#6 and #18), respectively, indexed as samples 6 and 18, of tropical forest in the experimental forest of Paracou, French Guiana, described in [22], are compared in terms of biodiversity. Respectively 643 and 481 trees with diameter at breast height over 10 cm were inventoried. The data is available in the entropart package for R. In these samples, 147 and 149 tree species from plots #6 and #18 are, respectively, observed, along with their frequencies. In [23], the data are analyzed by using generalized Simpson’s indices and concluded that plot #18 is more diverse than plot #6. In the respective samples, Turing’s formula takes on the values of and . Observing the rule of thumb, let the generalized species richness be evaluated at . , (as compared to the plug-ins and ), and therefore . The proposed confidence sets for and are, respectively, and . The proposed one-sided and two-sided confidence sets for are, respectively, and , both of which exclude zero and therefore lead to a rejection of with either or , qualitatively supporting the findings of [23]. Let α vary from 0.01 to 0.99. and as functions of α by means of (14) give two curves in Figure 2, which visually suggests that plot #18 is more diverse than plot #6 for a wide range of α. as a function of α, along with the point-wise confidence band by means of (29), is given in Figure 3, where it is evident that, with reasonable statistical confidence, for α values in the range from 0.6 to 0.15, that is, for values from 0.4 to 0.85. 






{kind=link}
{kind=link}
{kind=link}