MAGNet: A Camouflaged Object Detection Network Simulating the Observation Effect of a Magnifier


Abstract
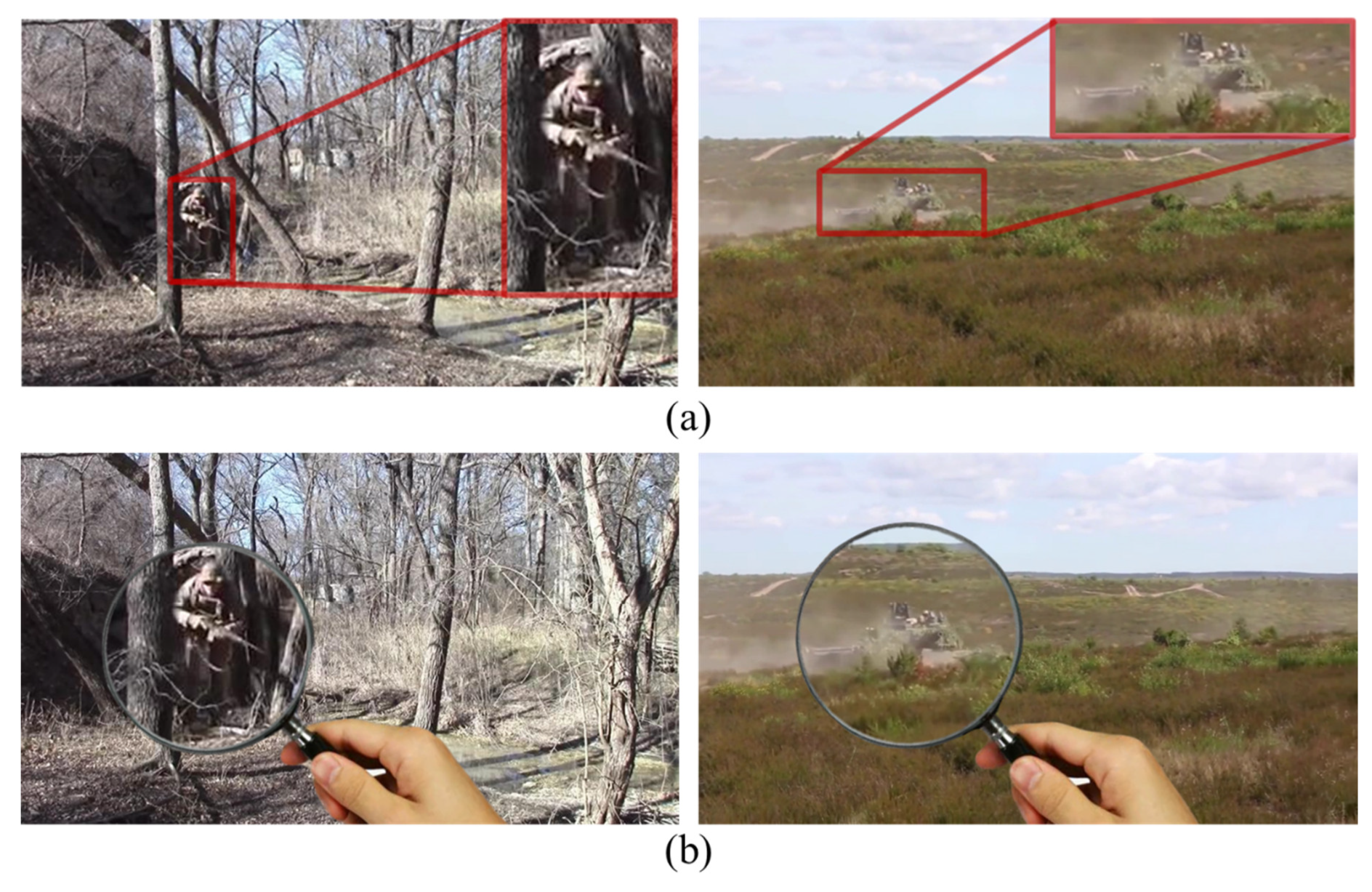
:1. Introduction
- We apply the concept of observation with a magnifier to the COD problem and propose a novel camouflaged object segmentation network called MAGNet with a clear structure. MAGNet can achieve higher segmentation accuracy with lower computational complexity.
- We design a parallel structure with the ergodic magnification module (EMM) and attention focus module (AFM) to simulate the magnifier functions. We propose a weighted key point area perception loss function to improve the focus of the camouflaged object, thus improving segmentation performance.
- We perform extensive experiments using public COD benchmark datasets and a camouflaged military object dataset constructed in-house. MAGNet has the best comprehensive effect in eight evaluation metrics in comparison with 19 cutting-edge detection models, and it can enable real-time segmentation. Finally, we experimentally explore several potential applications of camouflaged object segmentation.
2. Related Research
2.1. Semantic Segmentation Based on Deep Learning
2.2. Salient Object Detection Based on Deep Learning
2.3. Camouflaged Object Detection Based on Deep Learning
2.4. COD Dataset
3. MAGNet Detection Model
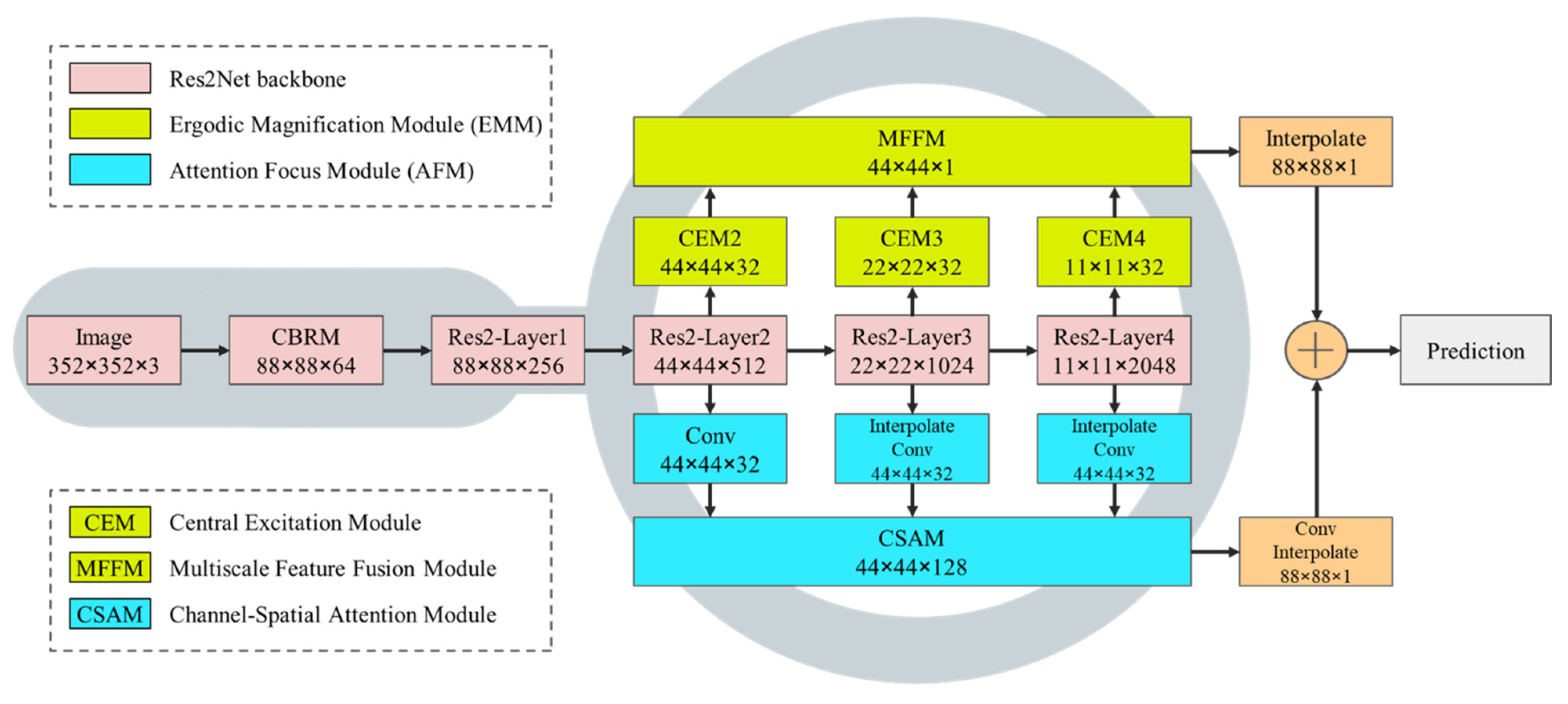
3.1. Network Overview
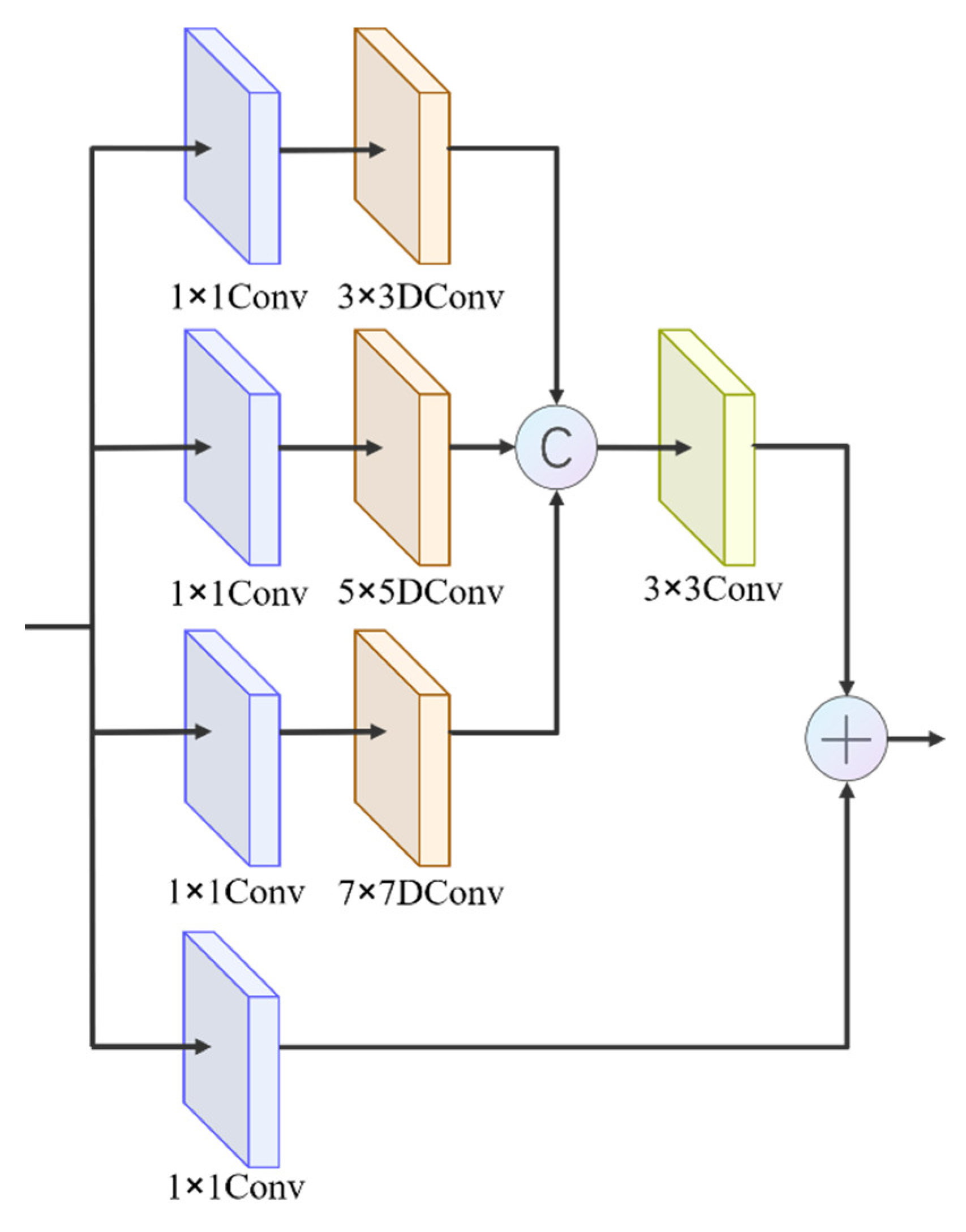
3.2. Ergodic Magnification Module (EMM)
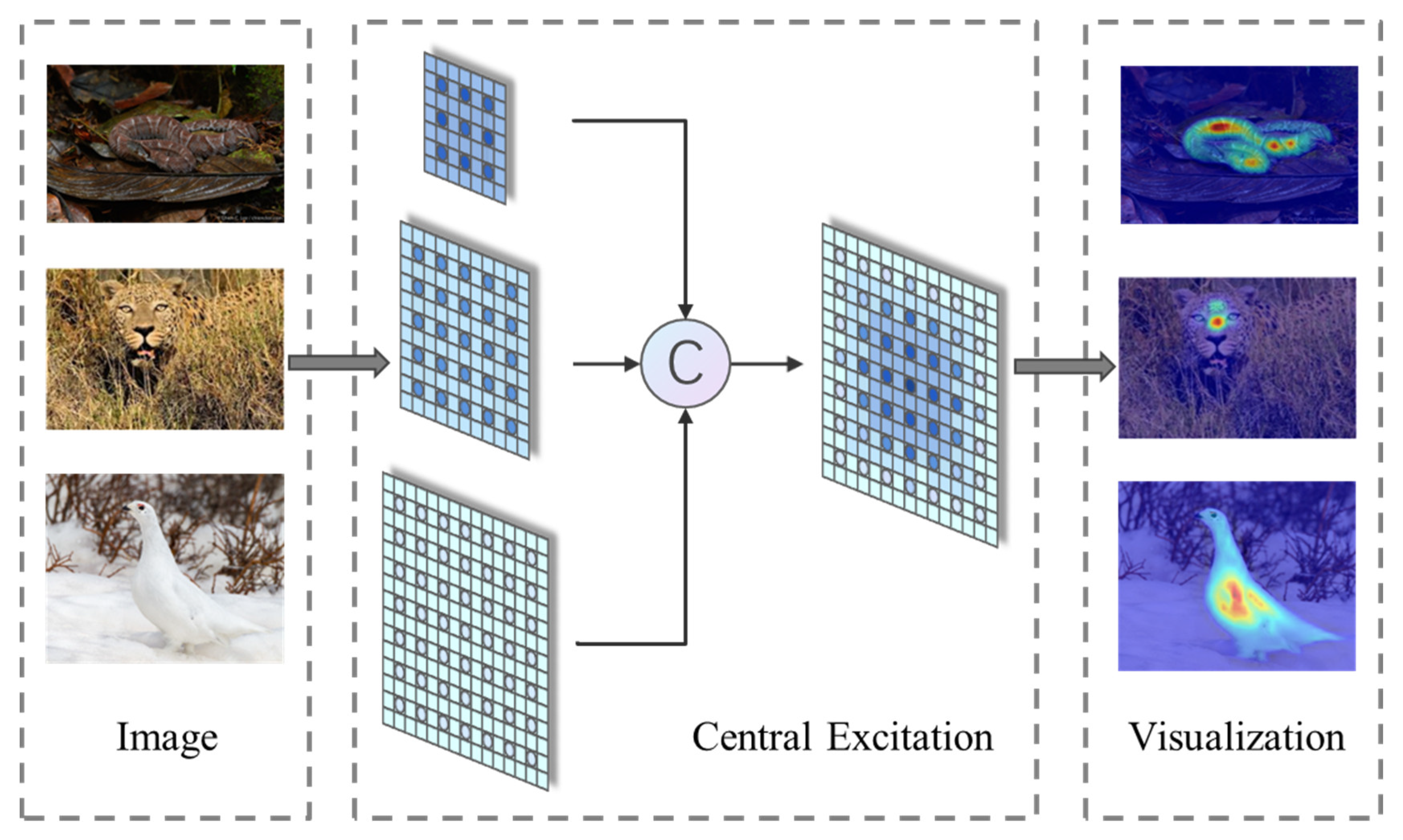
3.2.1. Central Excitation Module (CEM)
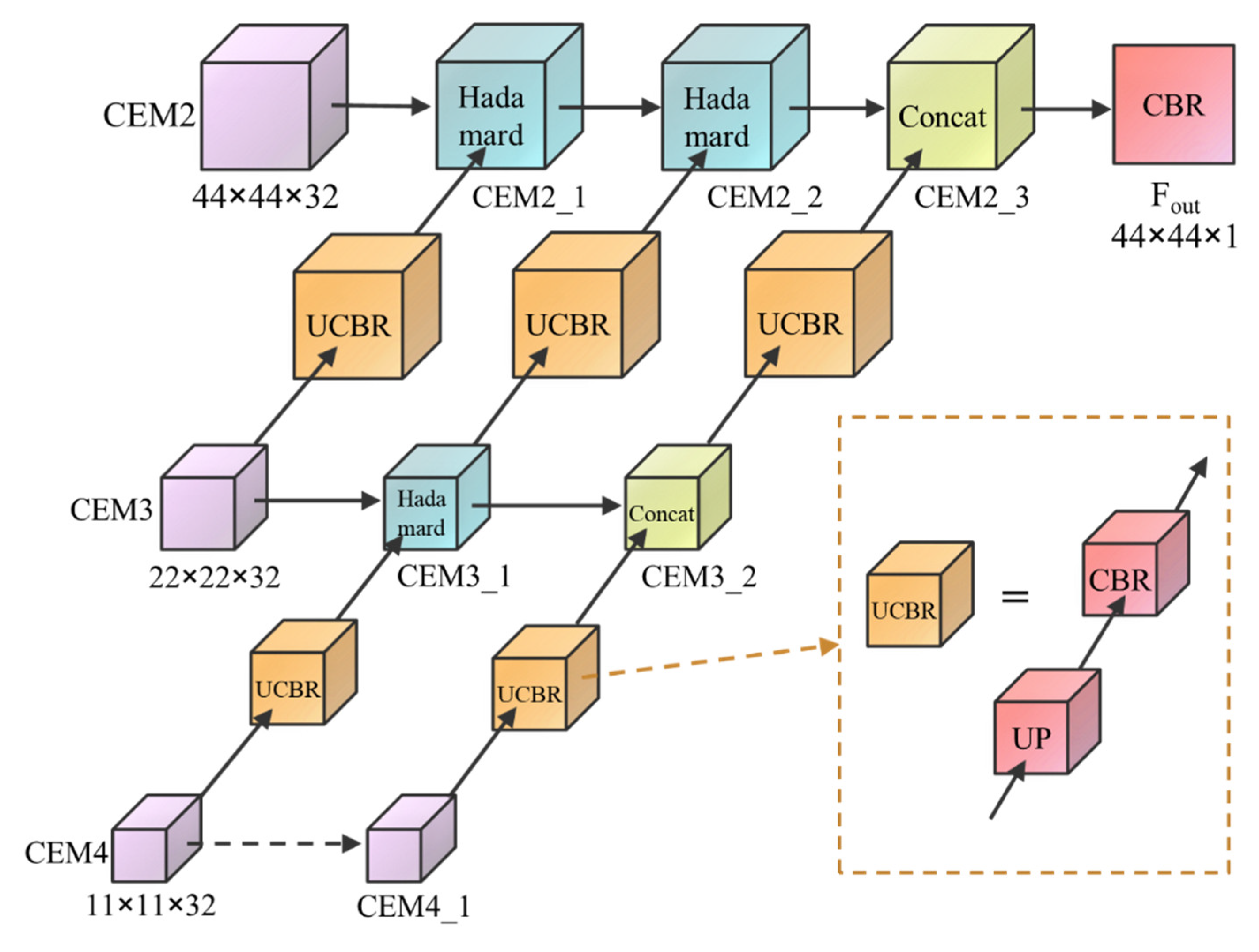
3.2.2. Multi-Scale Feature Fusion Module (MFFM)
| Algorithm 1: MFFM Algorithm |
| Input: CEM2, CEM3, CEM4. CEM4_1 = CEM4 |
| CEM3_1 = CBR (UP (CEM4))⊙CEM3 |
| CEM3_2 = Concat (CEM3_1, CBR (UP (CEM4_1))) |
| CEM2_1 = CBR (UP (CEM3))⊙CEM2 |
| CEM2_2 = CBR (UP (CEM3_1))⊙CEM2_1 |
| CEM2_3 = Concat (CEM2_2, CBR (UP (CEM3_2))) |
| Fout = CBR (CEM2_3) |
| Output: Fout. |
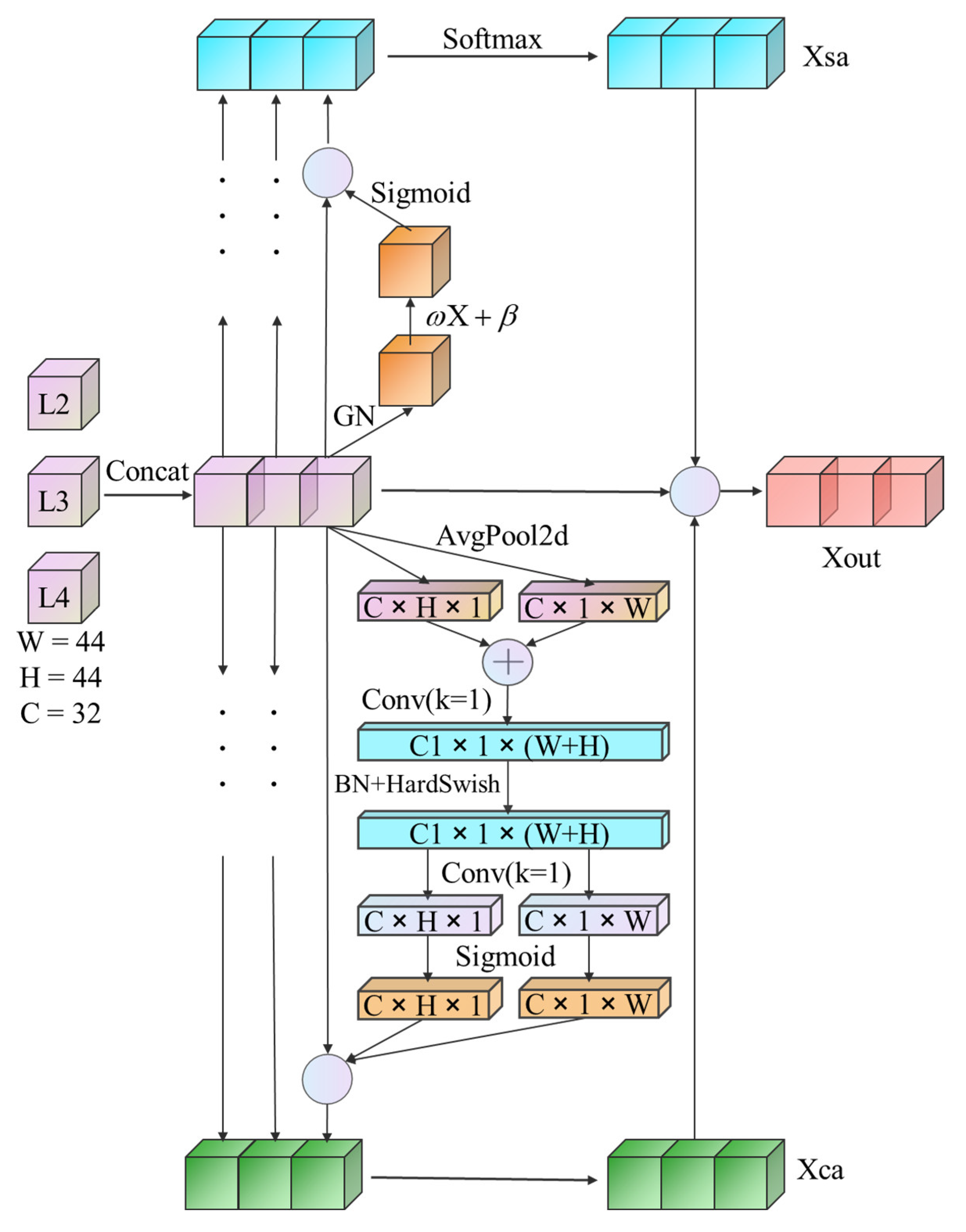
3.3. Attention Focus Module (AFM)
Channel-Spatial Attention Module (CSAM)
| Algorithm 2: CSAM Algorithm |
| Input: L2, L3, L4. # 1. Feature Maps Concat |
| X_original = Concat(L2, L3, L4) |
| For i = 2, 3, 4: # 2. Spatial Attention |
| xsa_i = SAmodule (Li) |
| # 3. Channel Attention |
| xca_i = CAmodule(Li) |
| Xsa = Concat (xsa_3, xsa_4, xsa_5) |
| Xsa = Softmax (Xsa) |
| Xca = Concat (xca_3, xca_4, xca_5) # 4. Fusion Attention Maps |
| Xout = X_original ⊙ Xca ⊙ Xsa |
| Output: Xout. |
3.4. Output Prediction and Loss Function
4. Experimental Results and Analysis
4.1. Preparation Work
4.1.1. Dataset Preprocessing
4.1.2. Evaluation Metrics
4.1.3. Comparison Methods
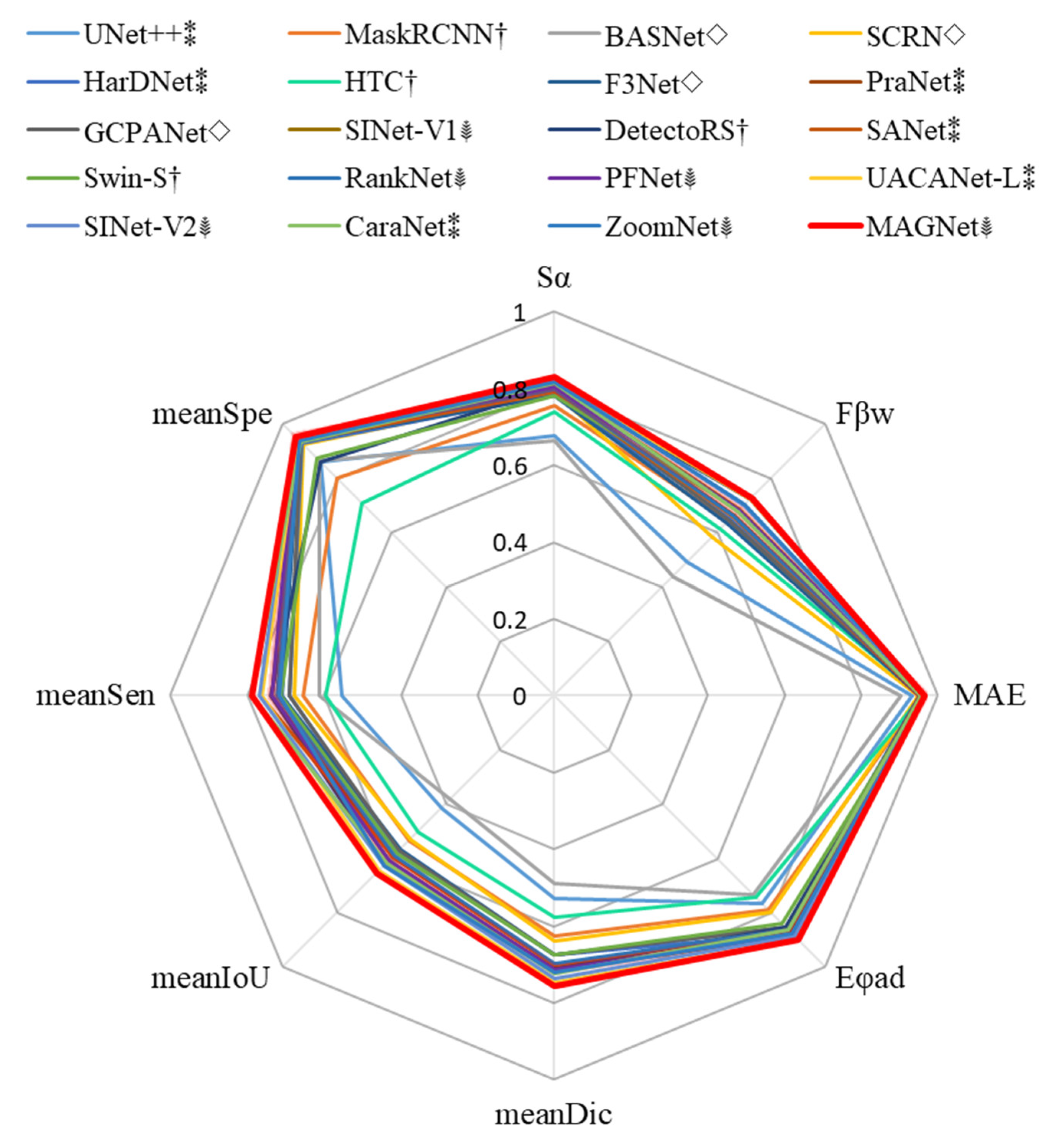
4.2. Comparison with State-of-the-Art Algorithms on Public Datasets
4.2.1. Quantitative Comparison
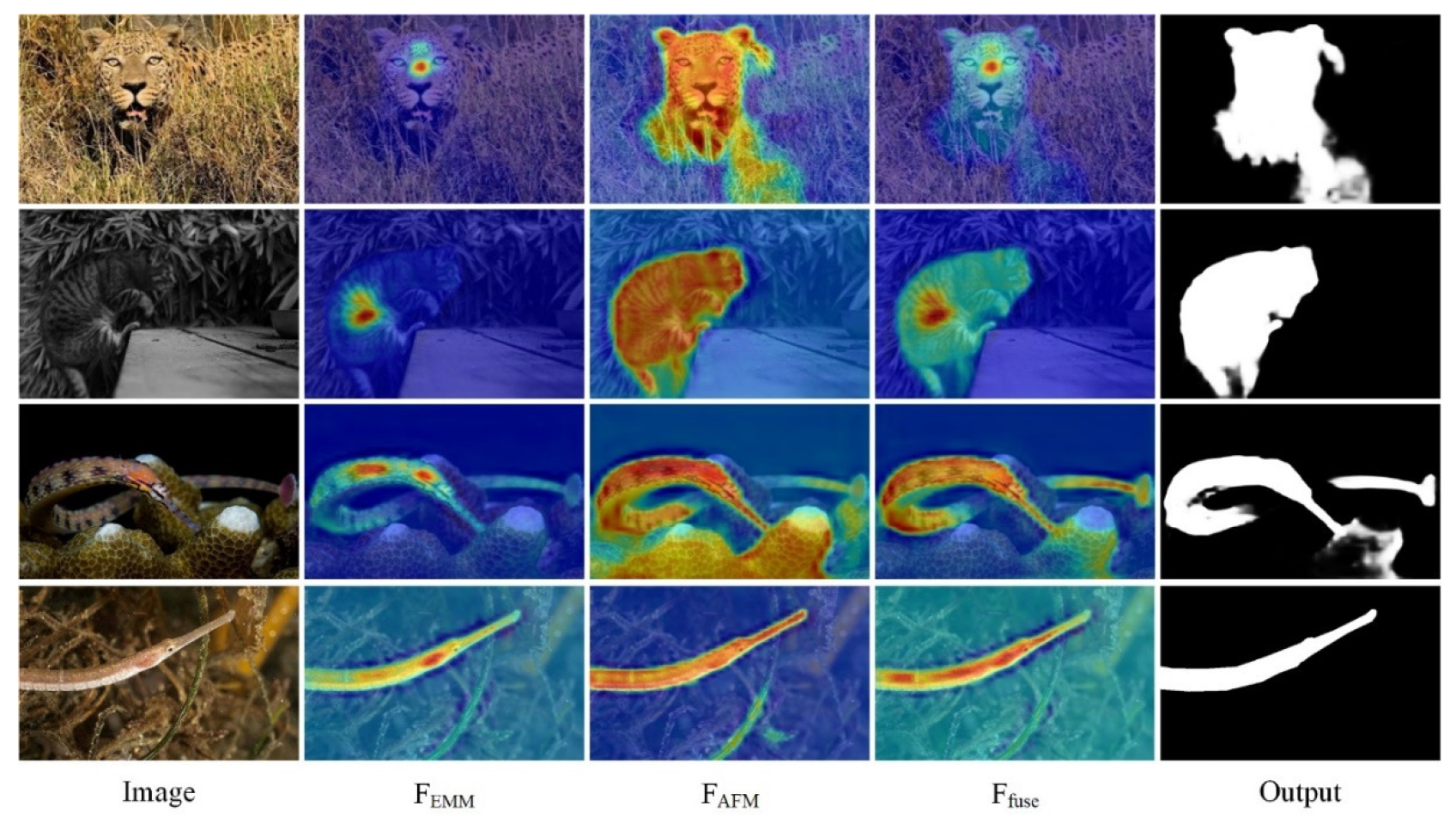
4.2.2. Qualitative Comparisons
4.3. Ablation Experiment
4.3.1. Quantitative Comparison
4.3.2. Qualitative Comparisons
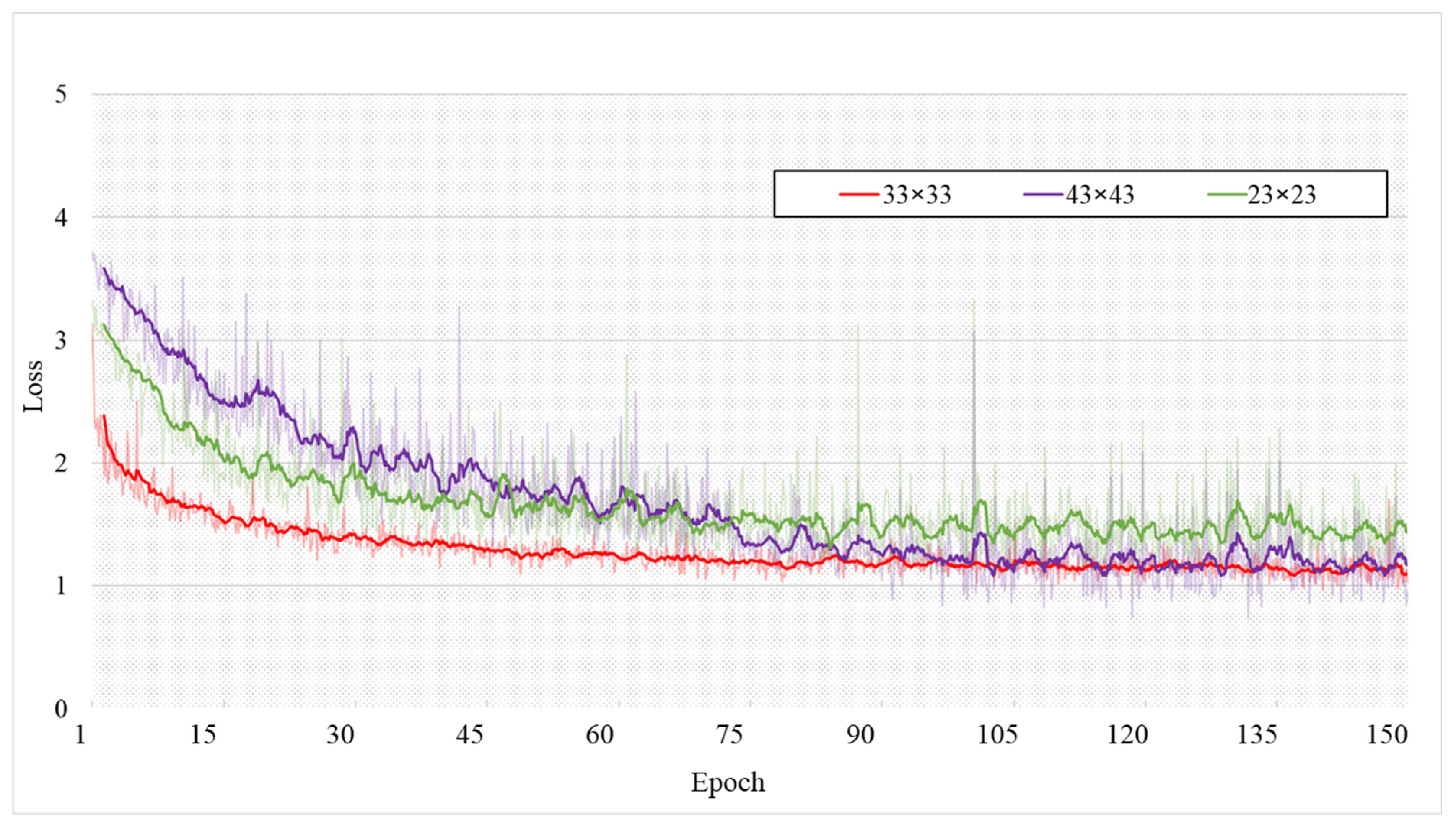
4.4. Comparison Experiment of Loss Function Parameter Settings
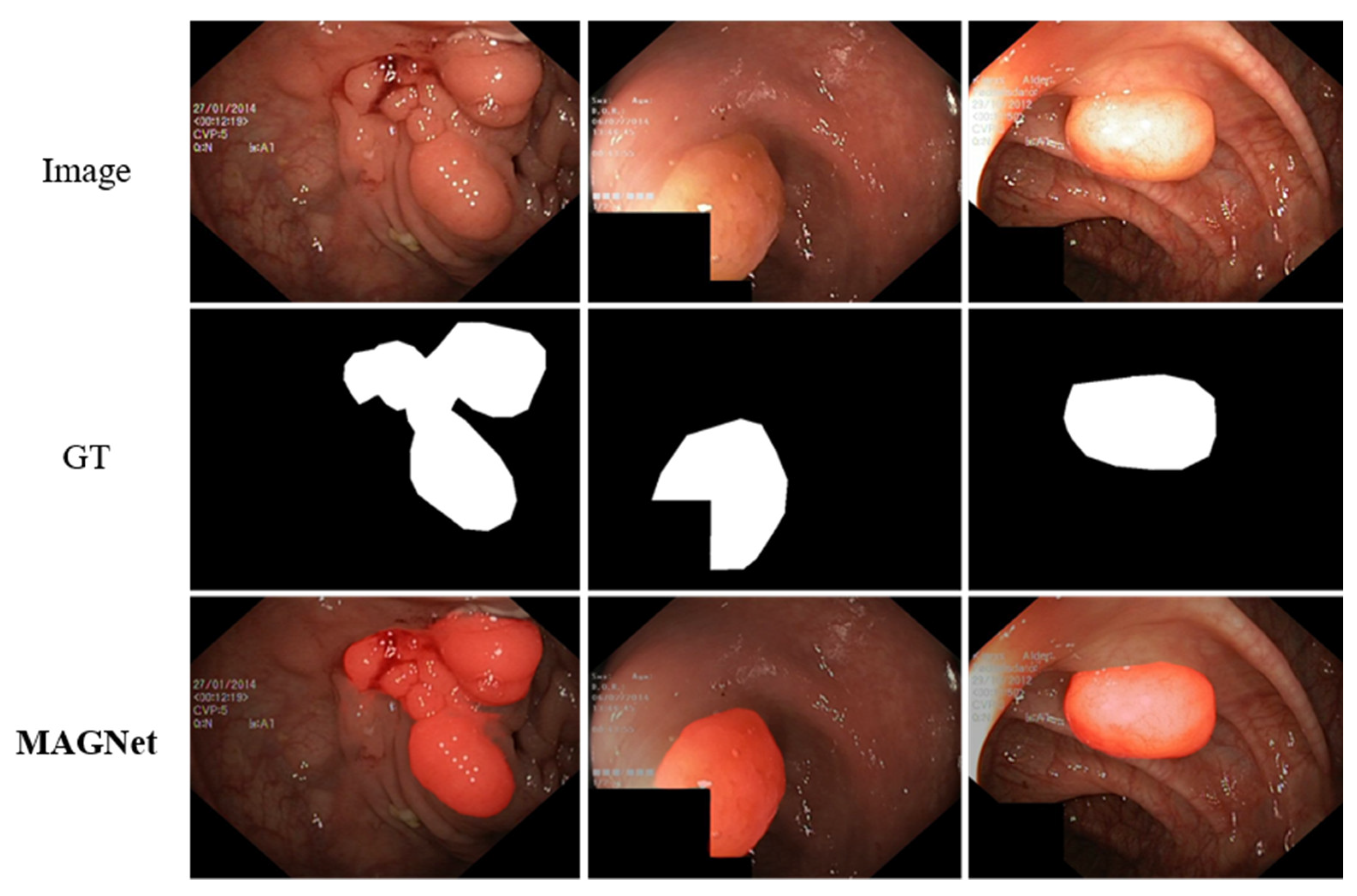
4.5. Comparison of the In-House Military Camouflaged Object Dataset
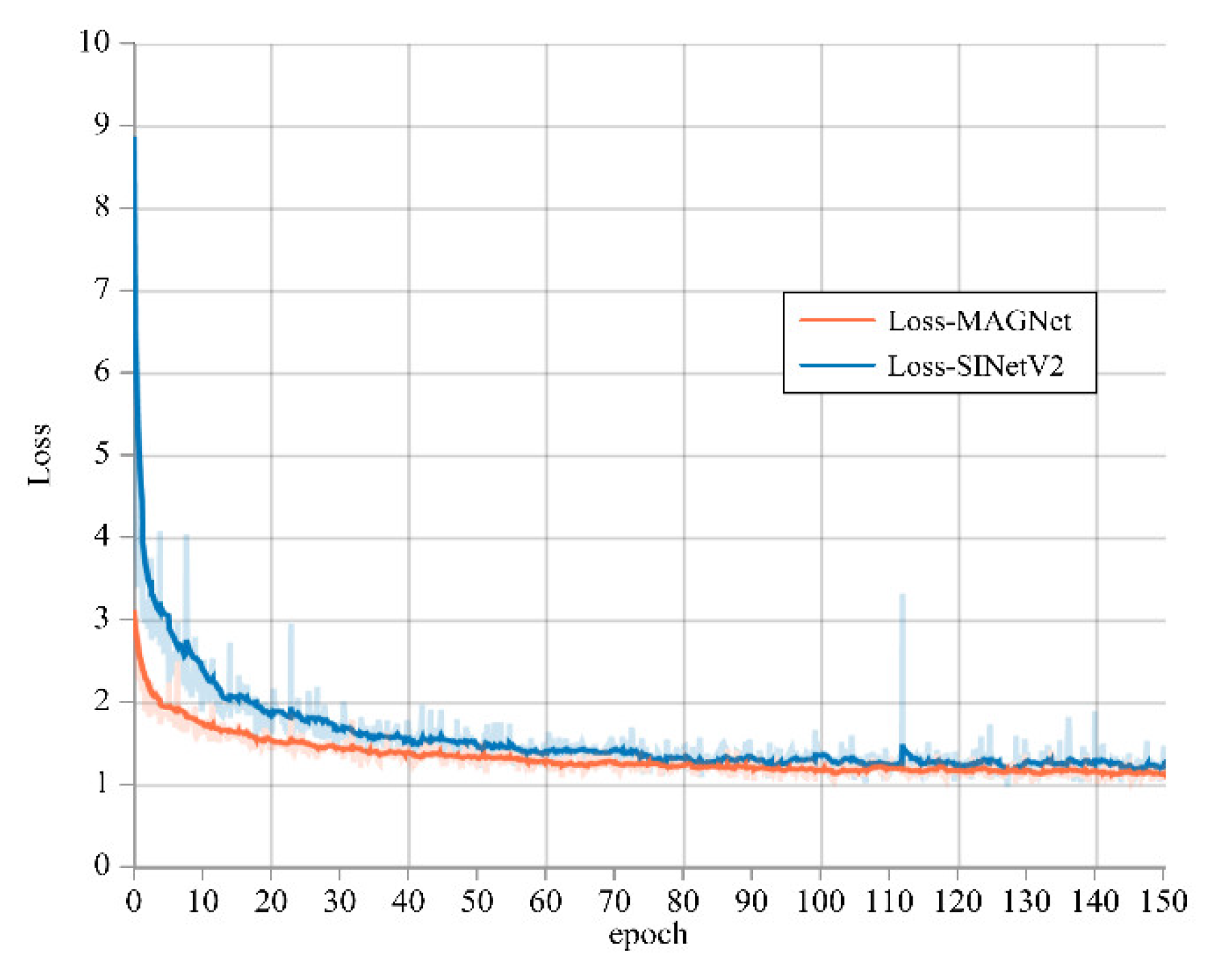
4.6. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Stevens M, Merilaita S Animal camouflage: Current issues and new perspectives. Philos. Trans. R. Soc. B Biol. Sci. 2009, 364, 423–427. [CrossRef] [PubMed] [Green Version]
- Puzikova, N.; Uvarova, E.; Filyaev, I.; Yarovaya, L. Principles of an approach coloring military camouflage. Fibre. Chem. 2008, 40, 155–159. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, D.; Lee, D.J. Automatic fabric defect detection with a wide-and-compact network. Neurocomputing 2019, 329, 329–338. [Google Scholar] [CrossRef]
- Zhang, M.; Li, H.; Pan, S.; Lyu, J.; Ling, S.; Su, S. Convolutional neural networks-based lung nodule classification: A surrogate-assisted evolutionary algorithm for hyperparameter optimization. IEEE Trans. Evol. Comput. 2021, 25, 869–882. [Google Scholar] [CrossRef]
- Fan, D.-P.; Ji, G.-P.; Zhou, T.; Chen, G.; Fu, H.; Shen, J.; Shao, L. PraNet: Parallel reverse attention network for polyp segmentation. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 263–273. [Google Scholar] [CrossRef]
- Zhou, M.; Li, Y.; Yuan, H.; Wang, J.; Pu, Q. Indoor WLAN personnel intrusion detection using transfer learning-aided generative adversarial network with light-loaded database. Mob. Netw. Appl. 2021, 26, 1024–1042. [Google Scholar] [CrossRef]
- Wang, K.; Du, S.; Liu, C.; Cao, Z. Interior Attention-Aware Network for Infrared Small Target Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Ghose, D.; Desai, S.M.; Bhattacharya, S.; Chakraborty, D.; Fiterau, M.; Rahman, T. Pedestrian detection in thermal images using saliency maps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019; pp. 988–997. [Google Scholar] [CrossRef] [Green Version]
- Mangale, S.; Khambete, M. Camouflaged Target Detection and tracking using thermal infrared and visible spectrum imaging. In Intelligent Systems Technologies and Applications 2016. Advances in Intelligent Systems and Computing; Springer: Cham, Switzerland, 2016; Volume 530, pp. 193–207. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, X.; Li, T.; Zeng, Y.; Lv, G.; Nian, F. Visible light polarization image desmogging via cycle convolutional neural network. Multimed. Syst. 2022, 28, 45–55. [Google Scholar] [CrossRef]
- Shen, Y.; Li, J.; Lin, W.; Chen, L.; Huang, F.; Wang, S. Camouflaged Target Detection Based on Snapshot Multispectral Imaging. Remote Sens. 2021, 13, 3949. [Google Scholar] [CrossRef]
- Suryanto, N.; Kim, Y.; Kang, H.; Larasati, H.; Yun, Y.; Le, T.; Yang, H.; Oh, S.; Kim, H. DTA: Physical Camouflage Attacks using Differentiable Transformation Network. arXiv 2022, arXiv:abs/2203.09831. [Google Scholar] [CrossRef]
- Zhang, Y.; Fan, Y.; Xu, M.; Li, W.; Zhang, G.; Liu, L.; Yu, D. An Improved Low Rank and Sparse Matrix Decomposition-Based Anomaly Target Detection Algorithm for Hyperspectral Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 2663–2672. [Google Scholar] [CrossRef]
- Chandesa, T.; Pridmore, T.P.; Bargiela, A. Detecting occlusion and camouflage during visual tracking. In Proceedings of the 2009 IEEE International Conference on Signal and Image Processing Applications, Kuala Lumpur, Malaysia, 18–19 November 2009; pp. 468–473. [Google Scholar] [CrossRef]
- Mondal, A. Camouflaged Object Detection and Tracking: A Survey. Int. J. Image Graph. 2020, 20, 2050028:1–2050028:13. [Google Scholar] [CrossRef]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A multimodal dataset for autonomous driving. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 11618–11628. [Google Scholar] [CrossRef]
- Chen, Y.J.; Tu, Z.D.; Kang, D.; Bao, L.C.; Zhang, Y.; Zhe, X.F.; Chen, R.Z.; Yuan, J.S. Model-based 3D hand reconstruction via self-supervised learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; Cornell University: Ithaca, NY, USA, 2021; pp. 10451–10460. [Google Scholar] [CrossRef]
- An, S.; Che, G.; Guo, J.; Zhu, H.; Ye, J.; Zhou, F.; Zhu, Z.; Wei, D.; Liu, A.; Zhang, W. ARShoe: Real-time augmented reality shoe try-on system on smartphones. In Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 1111–1119. [Google Scholar] [CrossRef]
- Hou, J.; Graham, B.; Nießner, M.; Xie, S.N. Exploring data-efficient 3D scene understanding with contrastive scene contexts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; Cornell University: Ithaca, NY, USA, 2021; pp. 15587–15597. [Google Scholar] [CrossRef]
- Huang, J.; Wang, H.; Birdal, T.; Sung, M.; Arrigoni, F.; Hu, S.M.; Guibas, L. MultiBodySync: Multi-body segmentation and motion estimation via 3D scan synchronization. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; Cornell University: Ithaca, NY, USA, 2021; pp. 7104–7114. [Google Scholar] [CrossRef]
- Liu, Z.; Qi, X.; Fu, C.W. One thing one click: A self-training approach for weakly supervised 3D semantic segmentation. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; Cornell University: Ithaca, NY, USA, 2021; pp. 1726–1736. [Google Scholar] [CrossRef]
- Yuan, K.; Zhuang, X.; Schaefer, G.; Feng, J.; Guan, L.; Fang, H. Deep-Learning-Based Multispectral Satellite Image Segmentation for Water Body Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 7422–7434. [Google Scholar] [CrossRef]
- Yuan, K.; Schaefer, G.; Lai, Y.; Wang, Y.; Liu, X.; Guan, L.; Fang, H. MuSCLe: A Multi-Strategy Contrastive Learning Framework for Weakly Supervised Semantic Segmentation. arXiv 2022, arXiv:2201.07021. Available online: https://arxiv.org/abs/2201.07021 (accessed on 5 December 2022).
- Wang, Y.; Zhang, J.; Kan, M.; Shan, S.; Chen, X. Self-Supervised Equivariant Attention Mechanism for Weakly Supervised Semantic Segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 12272–12281. [Google Scholar] [CrossRef]
- Wei, J.; Hu, Y.; Zhang, R.; Li, Z.; Zhou, S.K.; Cui, S. Shallow attention network for polyp segmentation. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2021; Springer International Publishing: Cham, Switzerland, 2021; pp. 699–708. [Google Scholar] [CrossRef]
- Wang, J.F.; Song, L.; Li, Z.M.; Sun, H.B.; Sun, J.; Zheng, N.N. End-to-end object detection with fully convolutional network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; Cornell University: Ithaca, NY, USA, 2021; pp. 15849–15858. [Google Scholar] [CrossRef]
- Patel, K.; Bur, A.M.; Wang, G. Enhanced U-Net: A feature enhancement network for polyp segmentation. In Proceedings of the 2021 18th Conference on Robots and Vision (CRV), Burnaby, BC, Canada, 26–28 May 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 181–188. [Google Scholar] [CrossRef]
- Fan, H.; Mei, X.; Prokhorov, D.; Ling, H. RGB-D scene labeling with multimodal recurrent neural networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 203–211. [Google Scholar] [CrossRef]
- Liu, K.; Ye, Z.; Guo, H.; Cao, D.; Chen, L.; Wang, F.Y. FISS GAN: A generative adversarial network for foggy image semantic segmentation. IEEE/CAA J. Autom Sin. 2021, 8, 1428–1439. [Google Scholar] [CrossRef]
- Tan, W.; Qin, N.; Ma, L.; Li, Y.; Du, J.; Cai, G.; Yang, K.; Li, J. Toronto-3D: A large-scale mobile LiDAR dataset for semantic segmentation of urban roadways. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14-19 June 2020; Cornell University: Ithaca, NY, USA, 2020; pp. 797–806. [Google Scholar] [CrossRef]
- Dovesi, P.L.; Poggi, M.; Andraghetti, L.; Martí, M.; Kjellström, H.; Pieropan, A.; Mattoccia, S. Real-time semantic stereo matching. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 10780–10787. [Google Scholar] [CrossRef]
- Gan, W.; Wong, P.K.; Yu, G.; Zhao, R.; Vong, C.M. Light-weight network for real-time adaptive stereo depth estimation. Neurocomputing 2021, 441, 118–127. [Google Scholar] [CrossRef]
- Ahn, E.; Feng, D.; Kim, J. A spatial guided self-supervised clustering network for medical image segmentation. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2021; Springer International Publishing: Cham, Switzerland, 2021; pp. 379–388. [Google Scholar] [CrossRef]
- Liu, Z.; Manh, V.; Yang, X.; Huang, X.; Lekadir, K.; Campello, V.; Ravikumar, N.; Frangi, A.F.; Ni, D. Style curriculum learning for robust medical image segmentation. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2021; Springer International Publishing: Cham, Switzerland, 2021; pp. 451–460. [Google Scholar] [CrossRef]
- Hu, X.; Zeng, D.; Xu, X.; Shi, Y. Semi-supervised contrastive learning for label-efficient medical image segmentation. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2021; Springer International Publishing: Cham, Switzerland, 2021; pp. 481–490. [Google Scholar] [CrossRef]
- Chen, H.; Li, Y.; Su, D. Multi-modal fusion network with multi-scale multi-path and cross-modal interactions for RGB-D salient object detection. Pattern Recognit. 2019, 86, 376–385. [Google Scholar] [CrossRef]
- Chen, H.; Li, Y. Three-stream attention-aware network for RGB-D salient object detection. IEEE Trans. Image Process. 2019, 28, 2825–2835. [Google Scholar] [CrossRef]
- Su, J.; Li, J.; Zhang, Y.; Xia, C.; Tian, Y. Selectivity or invariance: Boundary-aware salient object detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; Cornell University: Ithaca, NY, USA, 2019; pp. 3798–3807. [Google Scholar] [CrossRef] [Green Version]
- Fan, D.P.; Ji, G.P.; Sun, G.; Cheng, M.M.; Shen, J.; Shao, L. Camouflaged object detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; Cornell University: Ithaca, NY, USA, 2020; pp. 2774–2784. [Google Scholar] [CrossRef]
- Mei, H.; Ji, G.P.; Wei, Z.; Yang, X.; Wei, X.; Fan, D.P. Camouflaged object segmentation with distraction mining. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; Cornell University: Ithaca, NY, USA, 2021; pp. 8768–8777. [Google Scholar] [CrossRef]
- Lv, Y.; Zhang, J.; Dai, Y.; Li, A.; Liu, B.; Barnes, N.; Fan, D.P. Simultaneously localize, segment and rank the camouflaged objects. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; Cornell University: Ithaca, NY, USA, 2021; pp. 11586–11596. [Google Scholar] [CrossRef]
- Liang, X.; Lin, H.; Yang, H.; Xiao, K.; Quan, J. Construction of semantic segmentation dataset of camouflage target image. Laser Optoelectron. Prog. 2021, 58, 0410015. [Google Scholar] [CrossRef]
- Skurowski, P.; Abdulameer, H.; Błaszczyk, J.; Depta, T.; Kornacki, A.; Kozieł, P. Animal camouflage analysis: Chameleon database. Unpubl. Manuscr. 2018, 2, 7. Available online: https://www.polsl.pl/rau6/chameleon-database-animal-camouflage-analysis/ (accessed on 1 January 2022).
- Le, T.-N.; Nguyen, T.V.; Nie, Z.; Tran, M.-T.; Sugimoto, A. Anabranch network for camouflaged object segmentation. Comput. Vis. Image Underst. 2019, 184, 45–56. [Google Scholar] [CrossRef]
- Gao, S.H.; Cheng, M.M.; Zhao, K.; Zhang, X.Y.; Yang, M.H.; Torr, P. Res2Net: A new multi-scale backbone architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 652–662. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the effective receptive field in deep convolutional neural networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Curran Associates Inc.: Red Hook, NY, USA, 2016; pp. 4905–4913. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. Available online: https://arxiv.org/abs/1511.07122 (accessed on 5 December 2022).
- Zhu, X.; Cheng, D.; Zhang, Z.; Lin, S.; Dai, J. An empirical study of spatial attention mechanisms in deep networks. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; Cornell University: Ithaca, NY, USA; pp. 6687–6696. [Google Scholar] [CrossRef] [Green Version]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-excitation networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 13708–13717. [Google Scholar] [CrossRef]
- Wei, J.; Wang, S. F³Net: Fusion, feedback and focus for salient object detection. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12321–12328. [Google Scholar] [CrossRef]
- Fan, D.P.; Cheng, M.M.; Liu, Y.; Li, T.; Borji, A. Structure-measure: A new way to evaluate foreground maps. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; Cornell University: Ithaca, NY, USA, 2017; pp. 4558–4567. [Google Scholar] [CrossRef] [Green Version]
- Margolin, R.; Zelnik-Manor, L.; Tal, A. How to evaluate foreground maps. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; Cornell University: Ithaca, NY, USA, 2014; pp. 248–255. [Google Scholar] [CrossRef]
- Perazzi, F.; Krähenbühl, P.; Pritch, Y.; Hornung, A. Saliency filters: Contrast based filtering for salient region detection. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 733–740. [Google Scholar] [CrossRef]
- Fan, D.P.; Gong, C.; Cao, Y.; Ren, B.; Cheng, M.M.; Borji, A. Enhanced-alignment measure for binary foreground map evaluation. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; Cornell University: Ithaca, NY, USA, 2018; pp. 698–704. [Google Scholar] [CrossRef] [Green Version]
- Milletari, F.; Navab, N.; Ahmadi, S. V-Net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 565–571. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R.B. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Chen, K.; Pang, J.; Wang, J.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Shi, J.; Ouyang, W.; et al. Hybrid Task Cascade for Instance Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 4969–4978. [Google Scholar] [CrossRef] [Green Version]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the 2020 ECCV: European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Glasgow, UK, 2020; pp. 213–229. [Google Scholar] [CrossRef]
- Qiao, S.; Chen, L.; Yuille, A.L. DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 10208–10219. [Google Scholar] [CrossRef]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: Redesigning skip connections to exploit multiscale features in image segmentation. IEEE Trans. Med. Imaging 2020, 39, 1856–1867. [Google Scholar] [CrossRef] [Green Version]
- Chao, P.; Kao, C.Y.; Ruan, Y.; Huang, C.H.; Lin, Y.L. HarDNet: A low memory traffic network. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 3551–3560. [Google Scholar] [CrossRef] [Green Version]
- Lou, A.G.; Guan, S.Y.; Loew, M. CaraNet: Context axial reverse attention network for segmentation of small medical objects. In Proceedings of the Medical Imaging 2022: Image Processing, San Diego, CA, USA, 20 February–28 March 2022; SPIE: Bellingham, WA, USA, 2022; Volume 12032, pp. 81–92. [Google Scholar] [CrossRef]
- Kim, T.; Lee, H.; Kim, D. UACANet: Uncertainty augmented context attention for polyp segmentation. In Proceedings of the 29th ACM International Conference on Multimedia, New York, NY, USA, 20–24 October 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 2167–2175. [Google Scholar] [CrossRef]
- Qin, X.; Zhang, Z.; Huang, C.; Gao, C.; Dehghan, M.; Jagersand, M. BASNet: Boundary-aware salient object detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 7471–7481. [Google Scholar] [CrossRef]
- Wu, Z.; Su, L.; Huang, Q. Stacked cross refinement network for edge-aware salient object detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 7263–7272. [Google Scholar] [CrossRef]
- Chen, Z.; Xu, Q.; Cong, R.; Huang, Q. Global context-aware progressive aggregation network for salient object detection. Proc. AAAI Conf. Artif. Intell. 2020, 34, 10599–10606. [Google Scholar] [CrossRef]
- Fan, D.P.; Ji, G.P.; Cheng, M.M.; Shao, L. Concealed object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 6024–6042. [Google Scholar] [CrossRef]
- Pang, Y.; Zhao, X.; Xiang, T.; Zhang, L.; Lu, H. Zoom In and Out: A Mixed-scale Triplet Network for Camouflaged Object Detection. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 2150–2160. [Google Scholar] [CrossRef]
- Jha, D.; Smedsrud, P.H.; Riegler, M.A.; Halvorsen, P.; de Lange, T.; Johansen, D.; Johansen, H.D. Kvasir-SEG: A segmented polyp dataset. In MultiMedia Modeling; Springer International Publishing: Cham, Switzerland, 22 December 2020; pp. 451–462. [Google Scholar] [CrossRef] [Green Version]
- Vázquez, D.; Bernal, J.; Sánchez, F.J.; Fernández-Esparrach, G.; López, A.M.; Romero, A.; Drozdzal, M.; Courville, A. A benchmark for endoluminal scene segmentation of colonoscopy images. J. Healthc. Eng. 2017, 2017, 4037190. [Google Scholar] [CrossRef] [Green Version]
- Tajbakhsh, N.; Gurudu, S.R.; Liang, J. Automatic polyp detection in colonoscopy videos using an ensemble of convolutional neural networks. In Proceedings of the 2015 IEEE 12th International Symposium on Biomedical Imaging (ISBI), Brooklyn, NY, USA, 16–19 April 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 79–83. [Google Scholar] [CrossRef]
- Huang, Y.; Qiu, C.; Yuan, K. Surface defect saliency of magnetic tile. Vis. Comput. 2020, 36, 85–96. [Google Scholar] [CrossRef]
- Bahnsen, C.H.; Moeslund, T.B. Rain removal in traffic surveillance: Does it matter? IEEE Trans. Intell. Transp. Syst. 2019, 20, 2802–2819. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Categories | Descriptions | Quantities |
|---|---|---|
| Disguised persons | The woods in spring | 800 |
| The woods in summer | 900 | |
| The woods in autumn | 400 | |
| The woods in winter | 500 | |
| Disguised tanks | Complex environments | 100 |
| Total | 2700 |
| Methods | Pub. ‘Year | MAE | meanDic | meanIoU | meanSen | meanSpe | FPS | GFLOPs | Params (M) | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| UNet++ ⁑ | DLMIA ‘17 | 0.678 | 0.491 | 0.067 | 0.763 | 0.529 | 0.416 | 0.553 | 0.859 | 60.29 | 106.74 | 24.89 |
| MaskRCNN † | ICCV ‘17 | 0.756 | 0.643 | 0.042 | 0.790 | 0.625 | 0.534 | 0.653 | 0.803 | 26.90 | 75.82 | 43.75 |
| BASNet ◊ | CVPR ‘19 | 0.663 | 0.439 | 0.097 | 0.732 | 0.490 | 0.381 | 0.611 | 0.865 | 9.36 | 481.14 | 87.06 |
| SCRN ◊ | ICCV ‘19 | 0.791 | 0.583 | 0.052 | 0.799 | 0.640 | 0.529 | 0.676 | 0.926 | 35.27 | 30.32 | 25.22 |
| HarDNet ⁑ | ICCV ‘19 | 0.785 | 0.651 | 0.043 | 0.874 | 0.676 | 0.575 | 0.690 | 0.930 | 61.51 | 22.80 | 17.42 |
| HTC † | CVPR ‘19 | 0.738 | 0.611 | 0.041 | 0.741 | 0.576 | 0.501 | 0.596 | 0.710 | 9.20 | 188.84 | 79.73 |
| F3Net ◊ | AAAI ‘20 | 0.781 | 0.636 | 0.049 | 0.851 | 0.675 | 0.565 | 0.709 | 0.940 | 62.12 | 32.86 | 25.54 |
| PraNet ⁑ | MICCAI ‘20 | 0.799 | 0.665 | 0.045 | 0.866 | 0.700 | 0.595 | 0.737 | 0.939 | 45.83 | 26.15 | 32.58 |
| GCPANet ◊ | AAAI ‘20 | 0.800 | 0.646 | 0.042 | 0.851 | 0.674 | 0.573 | 0.691 | 0.934 | 9.36 | 131.40 | 67.06 |
| SINet-V1 ⸙ | CVPR ‘20 | 0.806 | 0.684 | 0.039 | 0.883 | 0.714 | 0.608 | 0.737 | 0.948 | 37.64 | 38.76 | 48.95 |
| Swin-S † | ICCV ‘20 | 0.780 | 0.681 | 0.040 | 0.840 | 0.676 | 0.580 | 0.712 | 0.873 | 14.30 | 89.82 | 68.69 |
| SANet ⁑ | MICCAI ‘21 | 0.791 | 0.659 | 0.046 | 0.862 | 0.702 | 0.593 | 0.766 | 0.938 | 69.09 | 22.56 | 23.90 |
| RankNet ⸙ | CVPR ‘21 | 0.799 | 0.661 | 0.043 | 0.860 | 0.696 | 0.588 | 0.723 | 0.947 | 29.51 | 66.63 | 50.94 |
| PFNet ⸙ | CVPR ‘21 | 0.805 | 0.683 | 0.040 | 0.882 | 0.714 | 0.607 | 0.737 | 0.951 | 33.74 | 53.24 | 46.50 |
| DetectoRS † | CVPR ‘21 | 0.804 | 0.725 | 0.039 | 0.851 | 0.712 | 0.624 | 0.739 | 0.861 | 5.50 | 188.36 | 134.00 |
| UACANet-L ⁑ | ACMMM ‘21 | 0.816 | 0.724 | 0.034 | 0.901 | 0.745 | 0.646 | 0.763 | 0.945 | 23.19 | 119.05 | 69.6 |
| SINet-V2 ⸙ | TPAMI ‘21 | 0.822 | 0.700 | 0.038 | 0.883 | 0.735 | 0.627 | 0.767 | 0.955 | 52.20 | 24.48 | 26.98 |
| CaraNet ⁑ | MIIP ‘22 | 0.815 | 0.679 | 0.044 | 0.862 | 0.722 | 0.618 | 0.789 | 0.937 | 31.88 | 43.30 | 46.63 |
| ZoomNet ⸙ | CVPR ‘22 | 0.818 | 0.703 | 0.037 | 0.875 | 0.721 | 0.625 | 0.716 | 0.941 | 12.06 | 203.50 | 32.38 |
| MAGNet ⸙ | Ours | 0.829 | 0.727 | 0.034 | 0.901 | 0.757 | 0.656 | 0.789 | 0.954 | 56.91 | 24.36 | 27.12 |
| Methods | Pub. ‘Year | FPS | FLOPs (G) | Params (M) |
|---|---|---|---|---|
| SINet-V1 ⸙ | CVPR ‘20 | 37.64 | 38.76 | 48.95 |
| RankNet ⸙ | CVPR ‘21 | 29.51 | 66.63 | 50.94 |
| PFNet ⸙ | CVPR ‘21 | 33.74 | 53.24 | 46.50 |
| SINet-V2 ⸙ | TPAMI ‘21 | 52.20 | 24.48 | 26.98 |
| ZoomNet ⸙ | CVPR ‘22 | 12.06 | 203.50 | 32.38 |
| MAGNet ⸙ | Ours | 56.91 | 24.36 | 27.12 |
| Baseline | With AFM | With EMM | In Series | In Parallel | MAE | meanDic | meanIoU | meanSen | meanSpe | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ✓ | 0.663 | 0.315 | 0.151 | 0.711 | 0.522 | 0.399 | 0.761 | 0.826 | ||||
| ✓ | ✓ | 0.675 | 0.308 | 0.163 | 0.843 | 0.616 | 0.509 | 0.824 | 0.812 | |||
| ✓ | ✓ | 0.825 | 0.715 | 0.035 | 0.900 | 0.742 | 0.638 | 0.755 | 0.956 | |||
| ✓ | ✓ | ✓ | ✓ | 0.827 | 0.723 | 0.034 | 0.902 | 0.753 | 0.652 | 0.785 | 0.949 | |
| ✓ | ✓ | ✓ | ✓ | 0.829 | 0.727 | 0.034 | 0.901 | 0.757 | 0.656 | 0.789 | 0.954 |
| Settings | MAE | meanDic | meanIoU | meanSen | meanSpe | Time/s | |||
|---|---|---|---|---|---|---|---|---|---|
| 23 × 23 | 0.809 | 0.644 | 0.046 | 0.847 | 0.719 | 0.610 | 0.787 | 0.946 | 137.2 |
| 43 × 43 | 0.824 | 0.723 | 0.034 | 0.903 | 0.746 | 0.648 | 0.760 | 0.952 | 146.9 |
| 33 × 33 | 0.829 | 0.727 | 0.034 | 0.901 | 0.757 | 0.656 | 0.789 | 0.954 | 142 |
| Methods | Pub. ‘Year | MAE | meanDic | meanIoU | meanSen | meanSpe | |||
|---|---|---|---|---|---|---|---|---|---|
| UNet++ ⁑ | DLMIA ‘17 | 0.717 | 0.594 | 0.009 | 0.736 | 0.513 | 0.421 | 0.471 | 0.747 |
| MaskRCNN † | ICCV ‘17 | 0.825 | 0.762 | 0.008 | 0.856 | 0.695 | 0.543 | 0.746 | 0.874 |
| BASNet ◊ | CVPR ‘19 | 0.865 | 0.757 | 0.008 | 0.928 | 0.763 | 0.666 | 0.758 | 0.950 |
| SCRN ◊ | ICCV ‘19 | 0.847 | 0.603 | 0.010 | 0.677 | 0.687 | 0.575 | 0.726 | 0.955 |
| HarDNet ⁑ | ICCV ‘19 | 0.876 | 0.784 | 0.005 | 0.953 | 0.795 | 0.695 | 0.806 | 0.967 |
| HTC † | CVPR ‘19 | 0.848 | 0.766 | 0.006 | 0.824 | 0.753 | 0.504 | 0.764 | 0.858 |
| F3Net ◊ | AAAI ‘20 | 0.889 | 0.798 | 0.005 | 0.944 | 0.816 | 0.716 | 0.846 | 0.972 |
| PraNet ⁑ | MICCAI ‘20 | 0.887 | 0.781 | 0.006 | 0.915 | 0.802 | 0.696 | 0.834 | 0.977 |
| GCPANet ◊ | AAAI ‘20 | 0.874 | 0.721 | 0.006 | 0.821 | 0.733 | 0.623 | 0.714 | 0.971 |
| SINet-V1 ⸙ | CVPR ‘20 | 0.876 | 0.800 | 0.005 | 0.965 | 0.810 | 0.706 | 0.842 | 0.977 |
| Swin-S † | ICCV ‘20 | 0.858 | 0.710 | 0.008 | 0.834 | 0.741 | 0.635 | 0.837 | 0.951 |
| SANet ⁑ | MICCAI ‘21 | 0.804 | 0.647 | 0.010 | 0.853 | 0.673 | 0.563 | 0.720 | 0.917 |
| RankNet ⸙ | CVPR ‘21 | 0.847 | 0.693 | 0.008 | 0.825 | 0.737 | 0.622 | 0.840 | 0.960 |
| PFNet ⸙ | CVPR ‘21 | 0.873 | 0.771 | 0.006 | 0.941 | 0.785 | 0.682 | 0.804 | 0.965 |
| DetectoRS † | CVPR ‘21 | 0.863 | 0.784 | 0.007 | 0.917 | 0.803 | 0.698 | 0.826 | 0.965 |
| UACANet-L ⁑ | ACM MM ‘21 | 0.880 | 0.823 | 0.004 | 0.963 | 0.817 | 0.715 | 0.853 | 0.979 |
| SINet-V2 ⸙ | TPAMI ‘21 | 0.884 | 0.788 | 0.004 | 0.926 | 0.806 | 0.699 | 0.843 | 0.982 |
| CaraNet ⁑ | MIIP ‘22 | 0.865 | 0.729 | 0.006 | 0.873 | 0.763 | 0.654 | 0.832 | 0.964 |
| ZoomNet ⸙ | CVPR ‘22 | 0.881 | 0.798 | 0.005 | 0.888 | 0.783 | 0.685 | 0.784 | 0.965 |
| MAGNet ⸙ | Ours | 0.924 | 0.864 | 0.003 | 0.946 | 0.868 | 0.779 | 0.917 | 0.992 |
| Methods | Pub. ‘Year | meanDic | MAE | meanIoU | ||
|---|---|---|---|---|---|---|
| UNet++ ⁑ | DLMIA ‘17 | 0.821 | 0.048 | 0.862 | 0.910 | / |
| HarDNet ⁑ | ICCV ‘19 | 0.912 | 0.025 | 0.923 | 0.958 | 0.857 |
| PraNet ⁑ | MICCAI ‘20 | 0.898 | 0.030 | 0.915 | 0.948 | 0.849 |
| UACANet-L ⁑ | ACM MM ‘21 | 0.912 | 0.025 | 0.917 | 0.958 | 0.862 |
| CaraNet ⁑ | MIIP ‘22 | 0.918 | 0.023 | 0.929 | 0.968 | 0.865 |
| MAGNet ⸙ | Ours | 0.890 | 0.033 | 0.912 | 0.960 | 0.830 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, X.; Cai, W.; Zhang, Z.; Jiang, B.; Yang, Z.; Wang, X. MAGNet: A Camouflaged Object Detection Network Simulating the Observation Effect of a Magnifier. Entropy 2022, 24, 1804. https://doi.org/10.3390/e24121804
Jiang X, Cai W, Zhang Z, Jiang B, Yang Z, Wang X. MAGNet: A Camouflaged Object Detection Network Simulating the Observation Effect of a Magnifier. Entropy. 2022; 24(12):1804. https://doi.org/10.3390/e24121804
Chicago/Turabian StyleJiang, Xinhao, Wei Cai, Zhili Zhang, Bo Jiang, Zhiyong Yang, and Xin Wang. 2022. "MAGNet: A Camouflaged Object Detection Network Simulating the Observation Effect of a Magnifier" Entropy 24, no. 12: 1804. https://doi.org/10.3390/e24121804
APA StyleJiang, X., Cai, W., Zhang, Z., Jiang, B., Yang, Z., & Wang, X. (2022). MAGNet: A Camouflaged Object Detection Network Simulating the Observation Effect of a Magnifier. Entropy, 24(12), 1804. https://doi.org/10.3390/e24121804