




BPDGAN: A GAN-Based Unsupervised Back Project Dense Network for Multi-Modal Medical Image Fusion

Abstract
:1. Introduction
- The BPDB module is proposed and utilized in conjunction with the CBAM module. These modules can eliminate the obstacle of large black backgrounds in the fusion results and obtain high-quality fusion results.
- An end-to-end multimodal medical image fusion model is put forward to implement the fusion of three kind of medical images with MR images. No manual priori knowledge is required, no labelled data are needed, and the model’s robustness ability is strong.
- Our loss function, designed for medical image fusion, contains a content loss function and a gradient loss. The gradient loss focuses on high-frequency information of the image. An adversarial mechanism function with gradient information is used to make the fused images texturally clear and content-rich.
2. Related Work
3. Proposed Method
3.1. Pre-Processing
3.2. Network Structures
3.2.1. Generative Adversarial Networks
3.2.2. Overall Network Architecture
3.2.3. Generator Architecture
3.2.4. Discriminator Architecture
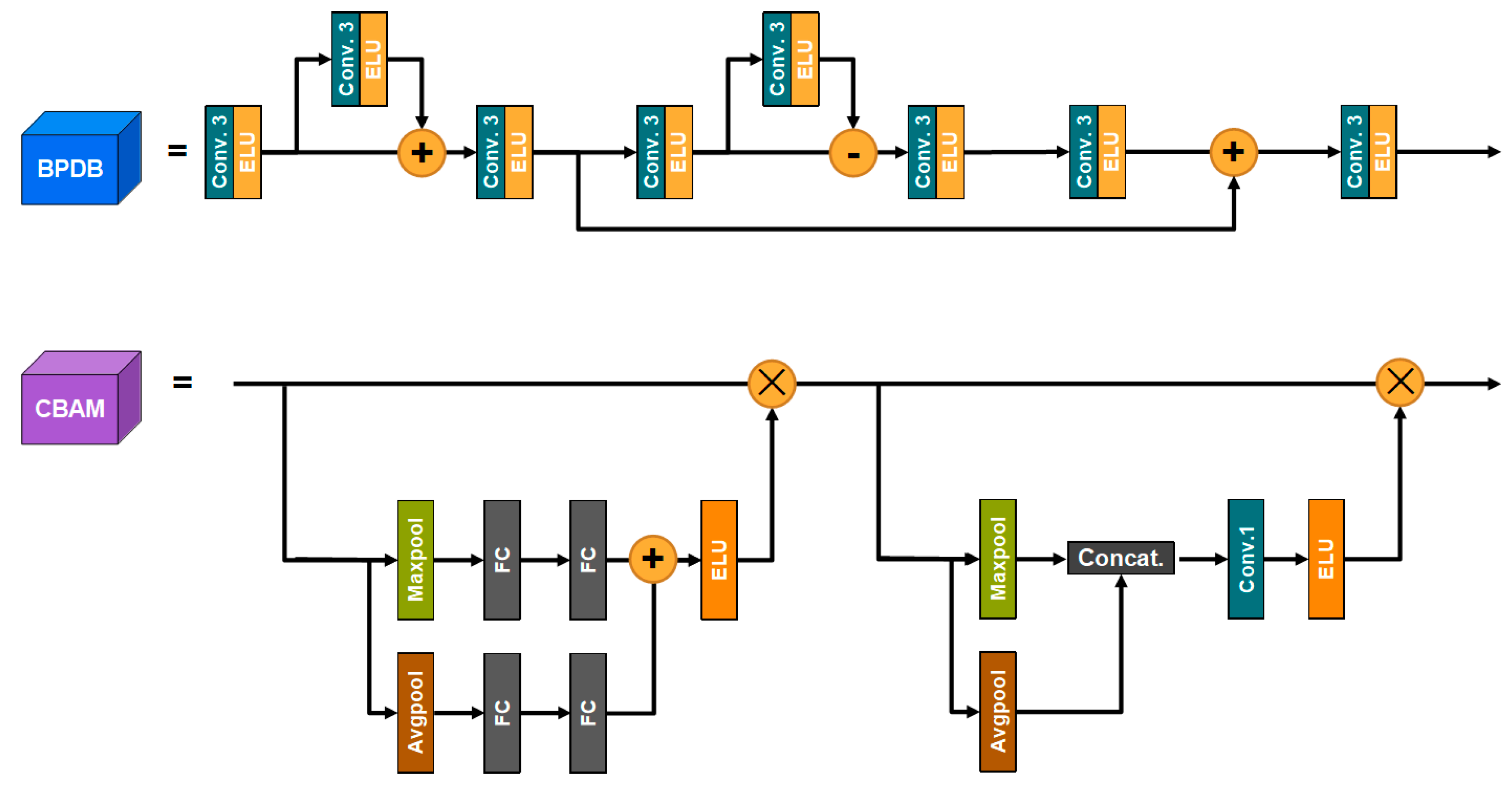
3.2.5. Back Project Dense Block (BPDB)
3.2.6. Convolutional Block Attention Module (CBAM)
3.3. Loss Function
3.3.1. Generator Loss
3.3.2. Adversarial Loss
3.3.3. Pixel-Level Euclidean Loss
3.3.4. Gradient Loss
3.3.5. Discriminator Loss
4. Experimental Results and Analysis
4.1. Training Details
| Algorithm 1: Generative adversarial network training algorithm (Take SPECT as an example) |
| Require: MR() and PET() image; |
| Require: A generator G and a discriminator D; |
| Require: Initialize parameters θg and θd randomly; |
| for number of training iterations M |
| for k step: RGB2YCbCr()Y, Cb, Cr G(,Y) YCbCr2RGB(, Cb, Cr)F End Calculate |
| Update θd by : θdAdam |
| Update θg by : θgAdam |
| Return: Trained generator |
4.2. Quantitative Evaluation Indicators
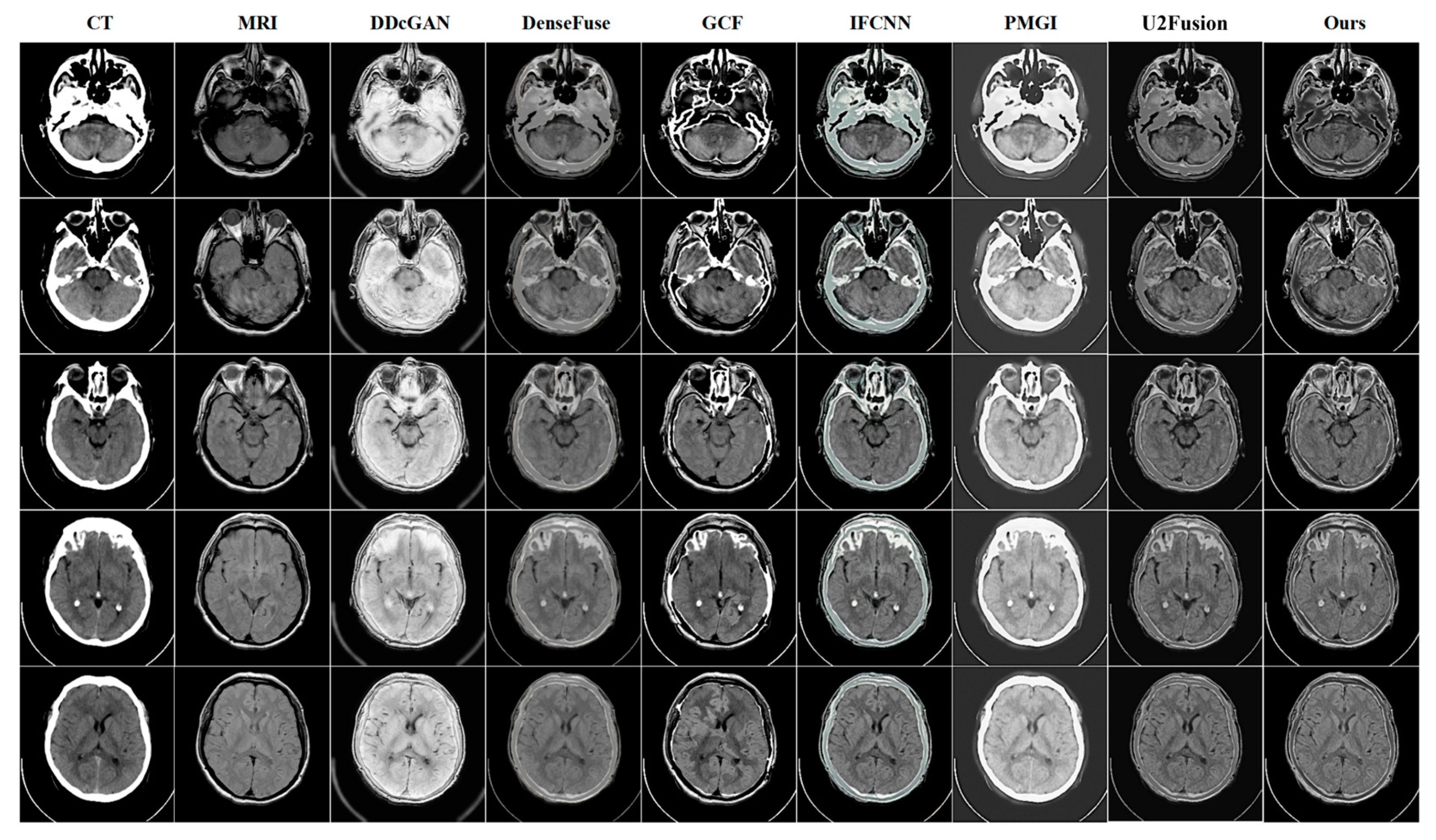
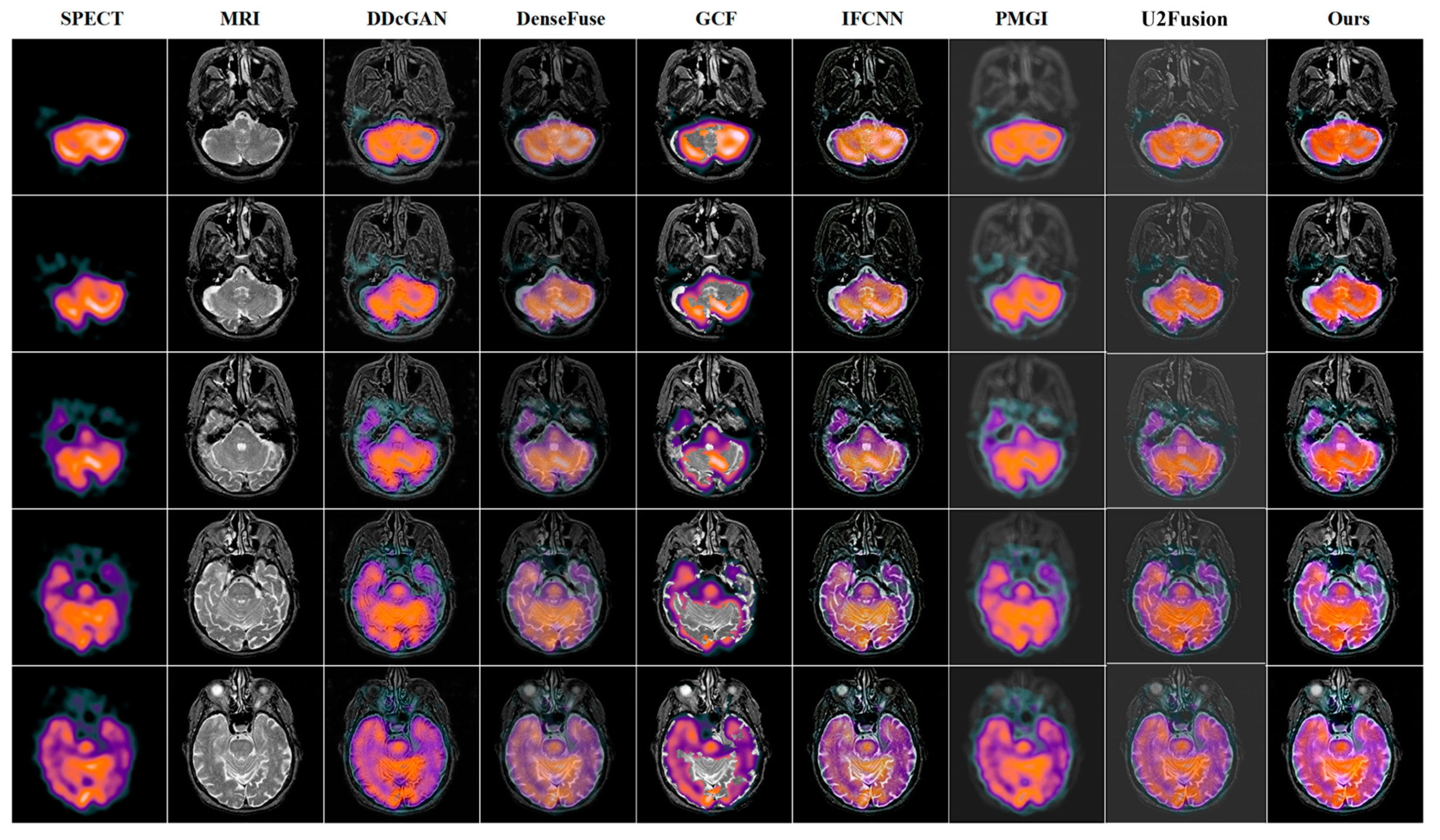
4.3. Quantitative and Qualitative Comparison Results
4.4. Ablation Experiments
4.5. Future Direction: BPDGAN vs. SwinFusion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Terreno, E.; Castelli, D.D.; Viale, A.; Aime, S. Challenges for Molecular Magnetic Resonance Imaging. Chem. Rev. 2010, 110, 3019–3042. [Google Scholar] [CrossRef] [PubMed]
- Buzug, T.M. Computed Tomography. In Springer Handbook of Medical Technology; Springer: Berlin/Heidelberg, Germany, 2011; pp. 311–342. [Google Scholar]
- Holly, T.A.; Abbott, B.G.; Al-Mallah, M.; Calnon, D.A.; Cohen, M.C.; DiFilippo, F.P.; Ficaro, E.P.; Freeman, M.R.; Hendel, R.C.; Jain, D.; et al. Single photon-emission computed tomography. J. Nucl. Cardiol. 2010, 17, 941–973. [Google Scholar] [CrossRef]
- Vita, T.; Okada, D.R.; Veillet-Chowdhury, M.; Bravo, P.E.; Mullins, E.; Hulten, E.; Agrawal, M.; Madan, R.; Taqueti, V.R.; Steigner, M.; et al. Complementary Value of Cardiac Magnetic Resonance Imaging and Positron Emission Tomography/Computed Tomography in the Assessment of Cardiac Sarcoidosis. Circ. Cardiovasc. Imaging 2018, 11, e007030. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huo, X.; Deng, Y.; Shao, K. Infrared and Visible Image Fusion with Significant Target Enhancement. Entropy 2022, 24, 1633. [Google Scholar] [CrossRef] [PubMed]
- Ma, X.; Wang, Z.; Hu, S.; Kan, S. Multi-Focus Image Fusion Based on Multi-Scale Generative Adversarial Network. Entropy 2022, 24, 582. [Google Scholar] [CrossRef] [PubMed]
- Hermessi, H.; Mourali, O.; Zagrouba, E. Multimodal medical image fusion review: Theoretical background and recent advances. Signal Process. 2021, 183, 108036. [Google Scholar] [CrossRef]
- Liu, Y.; Zhou, D.; Nie, R.; Hou, R.; Ding, Z. Construction of high dynamic range image based on gradient information transformation. IET Image Process. 2020, 14, 1327–1338. [Google Scholar] [CrossRef]
- Yousif, A.S.; Omar, Z.; Sheikh, U.U. An improved approach for medical image fusion using sparse representation and Siamese convolutional neural network. Biomed. Signal Process. Control. 2021, 72, 103357. [Google Scholar] [CrossRef]
- Hou, R.; Zhou, D.; Nie, R.; Liu, D.; Ruan, X. Brain CT and MRI medical image fusion using convolutional neural networks and a dual-channel spiking cortical model. Med. Biol. Eng. Comput. 2019, 57, 887–900. [Google Scholar] [CrossRef]
- Yang, D.; Hu, S.; Liu, S.; Ma, X.; Sun, Y. Multi-focus image fusion based on block matching in 3D transform domain. J. Syst. Eng. Electron. 2018, 29, 415–428. [Google Scholar] [CrossRef]
- Li, G.; Lin, Y.; Qu, X. An infrared and visible image fusion method based on multi-scale transformation and norm optimization. Inf. Fusion 2021, 71, 109–129. [Google Scholar] [CrossRef]
- Deng, Y.; Wu, Z.; Chai, L.; Wang, C.-Y.; Yamane, K.; Morita, R.; Yamashita, M.; Zhang, Z. Wavelet-transform analysis of spectral shearing interferometry for phase reconstruction of femtosecond optical pulses. Opt. Express 2005, 13, 2120–2126. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Z.; Cui, Z.; Zhu, Y. Multi-modal medical image fusion by Laplacian pyramid and adaptive sparse representation. Comput. Biol. Med. 2020, 123, 103823. [Google Scholar] [CrossRef] [PubMed]
- Shensa, M. The discrete wavelet transform: Wedding the a trous and Mallat algorithms. IEEE Trans. Signal Process. 1992, 40, 2464–2482. [Google Scholar] [CrossRef] [Green Version]
- Petrovic, V.; Xydeas, C. Gradient-Based Multiresolution Image Fusion. IEEE Trans. Image Process. 2004, 13, 228–237. [Google Scholar] [CrossRef]
- Selesnick, I.; Baraniuk, R.; Kingsbury, N. The dual-tree complex wavelet transform. IEEE Signal Process. Mag. 2005, 22, 123–151. [Google Scholar] [CrossRef] [Green Version]
- Lian, X.Q.; Ding, X.H.; Guo, D.H. Digital watermarking based on non-sampled contourlet transform. In International Workshop on Anti-Counterfeiting, Security and Identification(ASID); IEEE: Amsterdam, The Netherlands, 2007; pp. 138–141. [Google Scholar]
- Reddy, S.; Krishnaiah, R.V.; Rao, Y.R. An Effective Approach in Fusion of Multispectral Medical Images Using Convolution Structure Sparse Coding. In Proceedings of the 2021 6th International Conference on Communication and Electronics Systems (ICCES), Coimbatre, India, 8–10 July 2021; pp. 1158–1165. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.-J. DenseFuse: A Fusion Approach to Infrared and Visible Images. IEEE Trans. Image Process. 2018, 28, 2614–2623. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Xu, H.; Xiao, Y.; Guo, X.; Ma, J. Rethinking the Image Fusion: A Fast Unified Image Fusion Network based on Proportional Maintenance of Gradient and Intensity. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12797–12804. [Google Scholar] [CrossRef]
- Ma, J.; Yu, W.; Liang, P.; Li, C.; Jiang, J. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 2018, 48, 11–26. [Google Scholar] [CrossRef]
- Wang, X.; Li, Z.; Kang, H.; Huang, Y.; Gai, D. Medical Image Segmentation using PCNN based on Multi-feature Grey Wolf Optimizer Bionic Algorithm. J. Bionic Eng. 2021, 18, 711–720. [Google Scholar] [CrossRef]
- Han, D.; Li, L.; Guo, X.; Ma, J. Multi-exposure image fusion via deep perceptual enhancement. Inf. Fusion 2021, 79, 248–262. [Google Scholar] [CrossRef]
- Alwan, Z.A.; Farhan, H.M.; Mahdi, S.Q. Color image steganography in YCbCr space. Int. J. Electr. Comput. Eng. (IJECE) 2020, 10, 202–209. [Google Scholar] [CrossRef]
- Gui, J.; Sun, Z.; Wen, Y.; Tao, D.; Ye, J. A Review on Generative Adversarial Networks: Algorithms, Theory, and Applications. IEEE Trans. Knowl. Data Eng. 2021, 1, 1. [Google Scholar] [CrossRef]
- Xydeas, C.; Petrović, V. Objective image fusion performance measure. Electron. Lett. 2000, 36, 308–309. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.; Varshney, P.K. A human perception inspired quality metric for image fusion based on regional information. Inf. Fusion 2007, 8, 193–207. [Google Scholar] [CrossRef]
- Cui, G.; Feng, H.; Xu, Z.; Li, Q.; Chen, Y. Detail preserved fusion of visible and infrared images using regional saliency extraction and multi-scale image decomposition. Opt. Commun. 2015, 341, 199–209. [Google Scholar] [CrossRef]
- Rajalingam, B.; Priya, R. Hybrid multimodality medical image fusion technique for feature enhancement in medical diagnosis. Int. J. Eng. Sci. 2018, 2, 52–60. [Google Scholar]
- Ma, J.; Xu, H.; Jiang, J.; Mei, X.; Zhang, X.-P. DDcGAN: A Dual-Discriminator Conditional Generative Adversarial Network for Multi-Resolution Image Fusion. IEEE Trans. Image Process. 2020, 29, 4980–4995. [Google Scholar] [CrossRef]
- Xu, H.; Fan, F.; Zhang, H.; Le, Z.; Huang, J. A Deep Model for Multi-Focus Image Fusion Based on Gradients and Connected Regions. IEEE Access 2020, 8, 26316–26327. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Y.; Sun, P.; Yan, H.; Zhao, X.; Zhang, L. IFCNN: A general image fusion framework based on convolutional neural network. Inf. Fusion 2019, 54, 99–118. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J.; Jiang, J.; Guo, X.; Ling, H. U2Fusion: A Unified Unsupervised Image Fusion Network. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 502–518. [Google Scholar] [CrossRef] [PubMed]
- Ma, J.; Tang, L.; Fan, F.; Huang, J.; Mei, X.; Ma, Y. SwinFusion: Cross-domain Long-range Learning for General Image Fusion via Swin Transformer. IEEE/CAA J. Autom. Sin. 2022, 9, 1200–1217. [Google Scholar] [CrossRef]
- Roccetti, M.; Delnevo, G.; Casini, L.; Cappiello, G. Is bigger always better? A controversial journey to the center of machine learning design, with uses and misuses of big data for predicting water meter failures. J. Big Data 2019, 6, 70. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CT-MRI | DDcGAN | DenseFuse | GCF | IFCNN | PMGI | U2Fusion | Ours |
|---|---|---|---|---|---|---|---|
| AG↑ | 9.0754 | 5.6772 | 9.1627 | 7.7264 | 7.895 | 6.8957 | 10.1333 |
| EI↑ | 91.0206 | 57.5941 | 97.2749 | 81.7838 | 79.8071 | 70.5399 | 99.7997 |
| Qabf↑ | 0.3563 | 0.3393 | 0.5682 | 0.5122 | 0.508 | 0.4102 | 0.5402 |
| Qcv↓ | 4974.886 | 2599.490 | 4902.781 | 1922.205 | 1592.081 | 2610.5305 | 3376.064 |
| PET-MRI | DDcGAN | DenseFuse | GCF | IFCNN | PMGI | U2Fusion | Ours |
|---|---|---|---|---|---|---|---|
| AG↑ | 6.0128 | 4.9272 | 7.0089 | 6.9044 | 2.7804 | 3.8598 | 8.3813 |
| EI↑ | 60.3775 | 51.1228 | 75.6065 | 73.8009 | 29.6103 | 40.6413 | 84.7561 |
| Qabf↑ | 0.3655 | 0.2863 | 0.5848 | 0.5026 | 0.1736 | 0.1705 | 0.6456 |
| Qcv↓ | 1577.441 | 947.514 | 718.393 | 412.393 | 3667.634 | 1861.1615 | 220.779 |
| SPECT-MRI | DDcGAN | DenseFuse | GCF | IFCNN | PMGI | U2Fusion | Ours |
|---|---|---|---|---|---|---|---|
| AG↑ | 4.7542 | 3.4322 | 5.9096 | 6.1458 | 1.9178 | 3.8571 | 6.1660 |
| EI↑ | 50.1068 | 36.6158 | 62.9763 | 64.8819 | 20.7479 | 39.1411 | 65.3377 |
| Qabf↑ | 0.2334 | 0.1444 | 0.3896 | 0.4065 | 0.0798 | 0.2113 | 0.4353 |
| Qcv↓ | 844.875 | 560.090 | 317.356 | 1009.200 | 2473.292 | 886.6785 | 178.168 |
| Architecture | AG↑ | EI↑ | Qabf↑ | Qcv↓ |
|---|---|---|---|---|
| Backbone | 7.6270 | 77.5518 | 0.3635 | 2009.348 |
| Backbone + BPDB | 8.1466 | 81.4506 | 0.5358 | 417.2723 |
| Backbone + CBAM | 7.8281 | 78.7384 | 0.4325 | 620.3889 |
| Backbone + BPDB + CBAM | 8.3813 | 84.7561 | 0.6456 | 220.779 |
| Architecture | AG↑ | EI↑ | Qabf↑ | Qcv↓ |
|---|---|---|---|---|
| LGan + Lgard | 8.10 | 79.8556 | 0.5264 | 449.0945 |
| LGan + Lpixel | 8.17 | 81.2722 | 0.4428 | 727.8431 |
| LGan + Lpixel + Lgrad | 8.38 | 84.7561 | 0.6456 | 220.779 |
| Method | AG↑ | EI↑ | Qabf↑ | Qcv↓ | |
|---|---|---|---|---|---|
| CT-MRI | SwinFusion | 9.2796 | 94.1302 | 0.6059 | 2100.6508 |
| BPDGAN | 10.1333 | 99.7997 | 0.5402 | 3376.064 | |
| PET-MRI | SwinFusion | 10.7131 | 110.8256 | 0.7020 | 305.3309 |
| BPDGAN | 8.3813 | 84.7561 | 0.6456 | 220.779 | |
| SPECT-MRI | SwinFusion | 9.9039 | 98.4848 | 0.7175 | 257.2418 |
| BPDGAN | 6.1660 | 65.3377 | 0.4353 | 178.168 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, S.; Yang, L. BPDGAN: A GAN-Based Unsupervised Back Project Dense Network for Multi-Modal Medical Image Fusion. Entropy 2022, 24, 1823. https://doi.org/10.3390/e24121823
Liu S, Yang L. BPDGAN: A GAN-Based Unsupervised Back Project Dense Network for Multi-Modal Medical Image Fusion. Entropy. 2022; 24(12):1823. https://doi.org/10.3390/e24121823
Chicago/Turabian StyleLiu, Shangwang, and Lihan Yang. 2022. "BPDGAN: A GAN-Based Unsupervised Back Project Dense Network for Multi-Modal Medical Image Fusion" Entropy 24, no. 12: 1823. https://doi.org/10.3390/e24121823
APA StyleLiu, S., & Yang, L. (2022). BPDGAN: A GAN-Based Unsupervised Back Project Dense Network for Multi-Modal Medical Image Fusion. Entropy, 24(12), 1823. https://doi.org/10.3390/e24121823