

A Parallel Multi-Modal Factorized Bilinear Pooling Fusion Method Based on the Semi-Tensor Product for Emotion Recognition


Abstract
:1. Introduction
- (1)
- Multi-modal, factorized, bilinear pooling based on STP, which can avoid data redundancy due to dimension matching, and reduces the computational and memory costs.
- (2)
- We proposed a parallel, multi-modal, factorized, bilinear pooling method based on STP which can capture the rich interactions between the features by hierarchical fusion, and which realizes the arbitrary combination and fusion of three modalities.
- (3)
- Experimental evaluation of the proposed methodology on two multi-modal datasets.
2. Notation and Preliminaries
3. Methodology
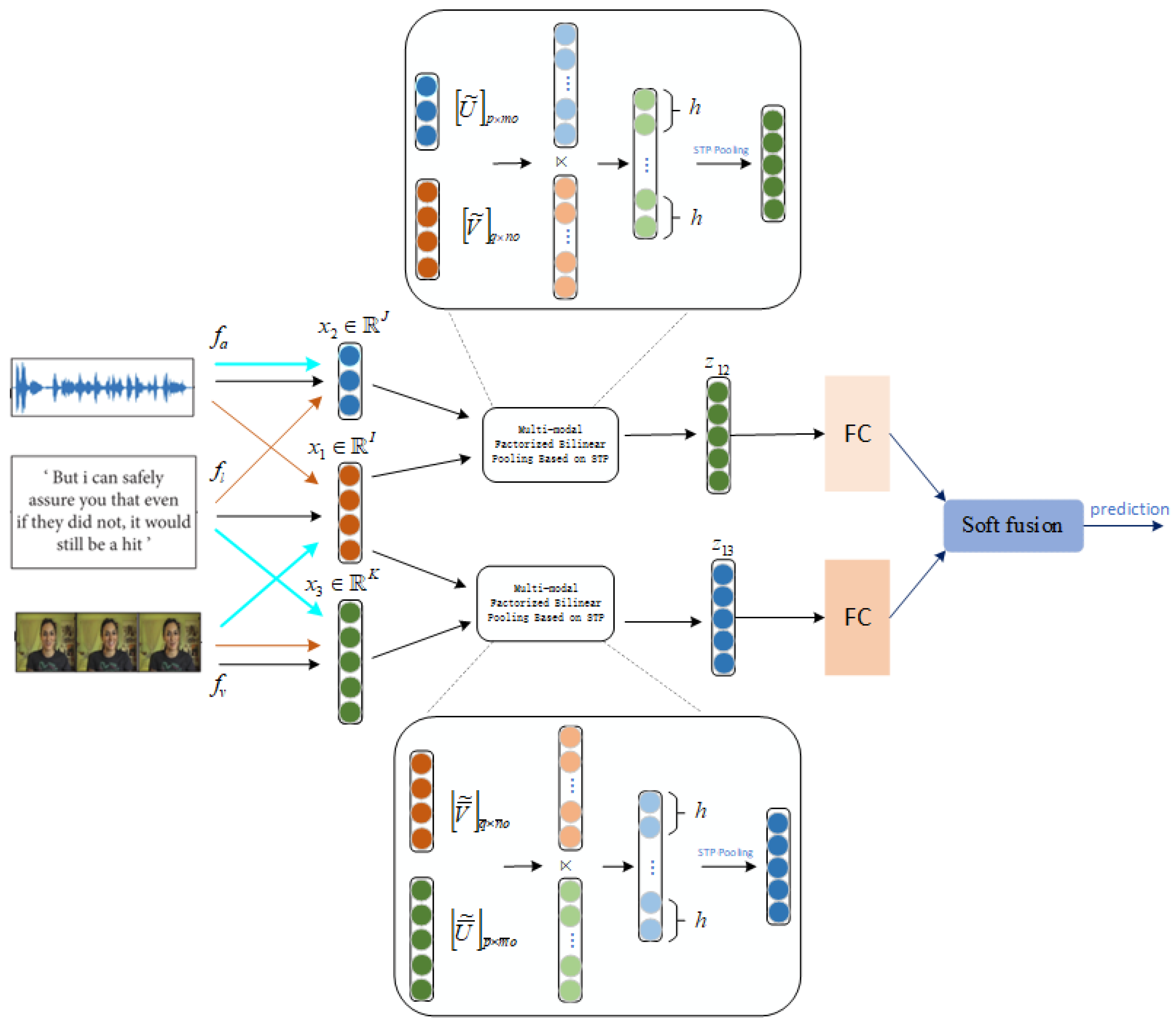
3.1. Model Architecture
3.2. Multi-Modal, Factorized Bilinear Pooling
3.3. Multi-Modal, Factorized Bilinear Pooling Based on STP
3.4. Parallel, Multi-Modal, Factorized Bilinear Pooling Based on STP (PFBP-STP)
| Algorithm 1 PFBP-STP |
| Input:
vectors , and ; Output: vector , ;
|
4. Experimental
- (1)
- Comparison with state-of-the-art: We conducted experiments on PFBP-STP and state-of-the-art methods for an emotion-recognition task on IEMOCAP and CMU-MOSI datasets;
- (2)
- The advantage of the PFBP-STP: It allows the information fusion independent of the dimension-matching conditions in matrix multiplication by replacing matrix products with semi-tensor products;
- (3)
- Complexity analysis: We evaluate the speed and learned parameters of the method by comparing them with those of other methods.
4.1. Datasets
4.2. Multi-Modal Data Features
4.3. Baseline
4.4. Evaluation Metrics
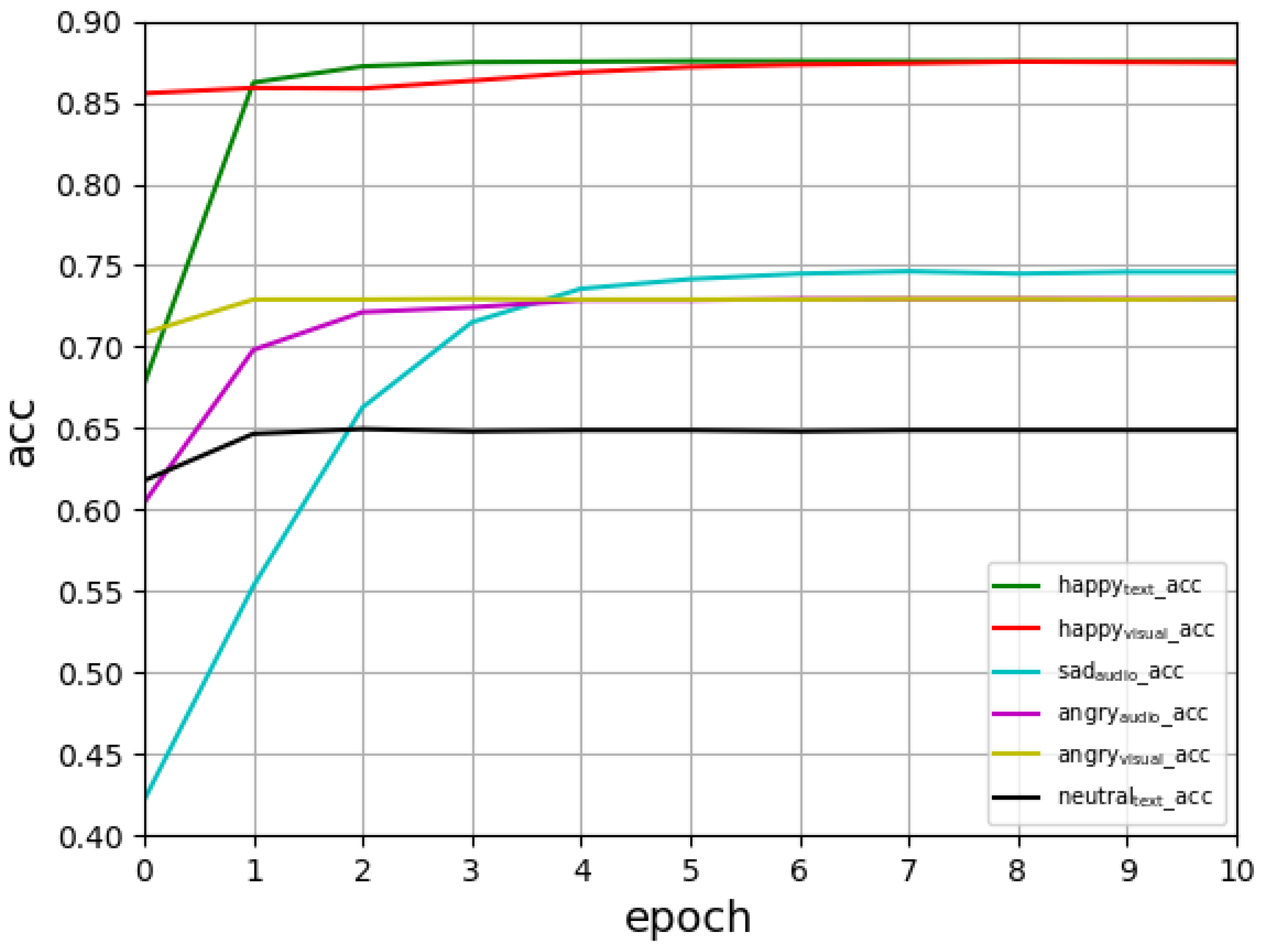
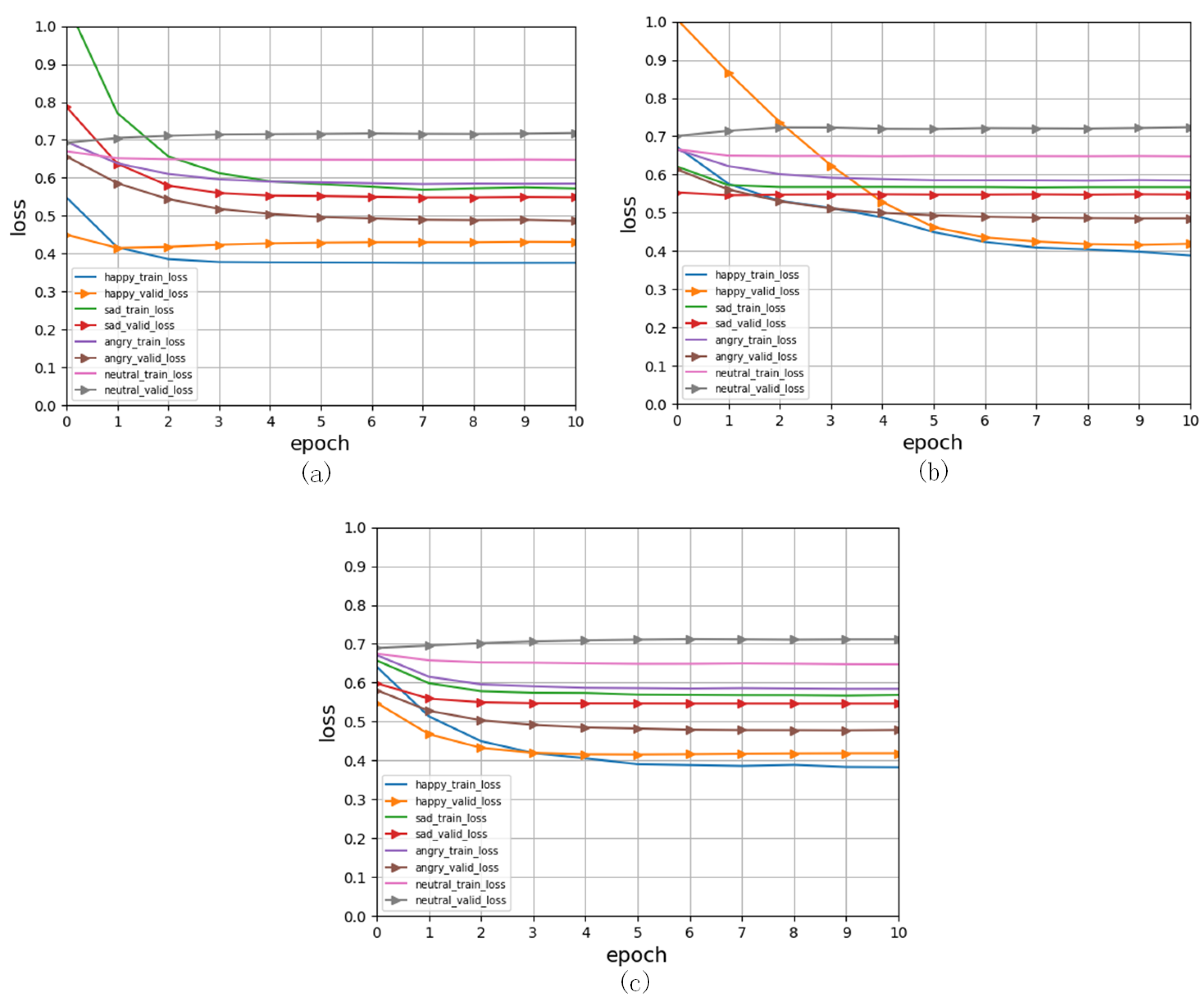
4.5. Training Setup
5. Results and Discussion
5.1. Comparison with the State-of-the-Art
5.2. Ablation Experiment
5.3. Evaluation Indicators
5.4. Computational Complexity
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| TFN | Tensor Fusion Network |
| EF-LSTM | Early Fusion LSTM |
| LF-LSTM | Late Fusion LSTM |
| MFB | Multi-Modal, Factorized Bilinear pooling |
| MuLT | Multi-modal Transformer |
| LMF-MulT | Low-Rank Fusion-based Transformer for Multi-modal Sequences |
| MFN | Memory Fusion Network |
| LMF | Low-rank Multi-modal Fusion |
| ACC | Accuracy |
| MAE | Mean Absolute Error |
References
- Baltrušaitis, T.; Ahuja, C.; Morency, L.P. Multimodal machine learning: A survey and taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 423–443. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Habibian, A.; Mensink, T.; Snoek, C. VideoStory Embeddings Recognize Events when Examples are Scarce. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 2013–2089. [Google Scholar] [CrossRef] [PubMed]
- Shuang, W.; Bondugula, S.; Luisier, F.; Zhuang, X.; Natarajan, P. Zero-Shot Event Detection Using Multi-modal Fusion of Weakly Supervised Concepts. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; IEEE: Washington, DC, USA, 2014; pp. 2665–2672. [Google Scholar]
- Park, S.; Han, S.S.; Chatterjee, M.; Sagae, K.; Morency, L.P. Computational Analysis of Persuasiveness in Social Multimedia: A Novel Dataset and Multimodal Prediction Approach. In Proceedings of the 16th International Conference on Multimodal Interaction, New York, NY, USA, 12–16 November 2014; pp. 50–57. [Google Scholar]
- Zadeh, A.; Chen, M.; Poria, S.; Cambria, E.; Morency, L.P. Tensor Fusion Network for Multimodal Sentiment Analysis. arXiv 2017, arXiv:1707.07250. [Google Scholar]
- Liu, F.; Chen, J.F.; Tan, W.J.; Cai, C. A Multi-Modal Fusion Method Based on Higher-Order Orthogonal Iteration Decomposition. Entropy 2021, 23, 1349. [Google Scholar] [CrossRef]
- Wu, D.; Chen, J.; Deng, W.; Wei, Y.; Luo, H.; Wei, Y. The recognition of teacher behavior based on multimodal information fusion. Math. Probl. Eng. 2020, 2020, 8269683. [Google Scholar] [CrossRef]
- Qi, J.; Peng, Y. Cross-modal Bidirectional Translation via Reinforcement Learning. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; International Joint Conference on Artificial Intelligence: Stockholm, Sweden, 2018; pp. 2630–2636. [Google Scholar]
- Lee, S.; Kim, I. Multimodal feature learning for video captioning. Math. Probl. Eng. 2018, 2018, 3125879. [Google Scholar] [CrossRef] [Green Version]
- Bai, J.S.; Chen, J.F.; Wang, M. Multimodal Urban Sound Tagging with Spatiotemporal Context. IEEE Trans. Cogn. Dev. Syst. 2022, 2022, 1. [Google Scholar] [CrossRef]
- Guo, W.; Wang, J.; Wanga, S. Deep Multimodal Representation Learning: A Survey. IEEE Access 2019, 7, 63373–63394. [Google Scholar] [CrossRef]
- Xie, Z.; Guan, L. Multimodal Information Fusion of Audio Emotion Recognition Based on Kernel Entropy Component Analysis. Int. J. Semant. Comput. 2013, 7, 25–42. [Google Scholar] [CrossRef]
- Pang, L.; Ngo, C.W. Mutlimodal learning with deep boltzmann machine for emotion prediction in user generated videos. In Proceedings of the 5th ACM on International Conference on Multimedia Retrieval; ACM: New York, NY, USA, 2015; pp. 619–622. [Google Scholar]
- Tsai, Y.H.H.; Bai, S.; Liang, P.P.; Kolter, J.Z.; Morency, L.P.; Salakhutdinov, R. Multimodal transformer for unaligned multimodal language sequences. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics; Association for Computational Linguistics: Florence, Italy, 2019; pp. 6558–6569. [Google Scholar]
- Sahay, S.; Okur, E.; Kumar, S.H.; Nachman, L. Low rank fusion based transformers for multimodal sequences. arXiv 2020, arXiv:2007.02038. [Google Scholar]
- Zhou, H.; Du, J.; Zhang, Y.; Wang, Q.; Liu, Q.F.; Lee, C.H. Information fusion in attention networks using adaptive and multi-level factorized bilinear pooling for audio-visual emotion recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 2617–2629. [Google Scholar] [CrossRef]
- Mansoorizadeh, M.; Moghaddam Charkari, N. Multimodal information fusion application to human emotion recognition from face and speech. Multimed. Tools Appl. 2010, 49, 277–297. [Google Scholar] [CrossRef]
- Wang, Y.; Guan, L.; Venetsanopoulos, A.N. Kernel cross-modal factor analysis for information fusion with application to bimodal emotion recognition. IEEE Trans. Multimed. 2012, 14, 597–607. [Google Scholar] [CrossRef]
- Li, S.; Zheng, W.; Zong, Y.; Lu, C.; Tang, C.; Jiang, X.; Xia, W. Bi-modality fusion for emotion recognition in the wild. In Proceedings of the 19th International Conference on Multimodal Interaction, Suzhou, China, 14–18 October 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 589–594. [Google Scholar]
- Liu, C.; Tang, T.; Lv, K.; Wang, M. Multi-feature based emotion recognition for video clips. In Proceedings of the 20th ACM International Conference on Multimodal Interaction, Boulder, CO, USA, 16–20 October 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 630–634. [Google Scholar]
- Zeng, Z.; Tu, J.; Pianfetti, B.M.; Huang, T.S. Audio–visual affective expression recognition through multistream fused HMM. IEEE Trans. Multimed. 2008, 10, 570–577. [Google Scholar] [CrossRef]
- Mai, S.; Hu, H.; Xing, S. Modality to Modality Translation: An Adversarial Representation Learning and Graph Fusion Network for Multimodal Fusion. In Proceedings of the 32th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; AAAI: New York, NY, USA, 2020; pp. 164–172. [Google Scholar]
- Fukui, A.; Park, D.H.; Yang, D.; Rohrbach, A.; Darrell, T.; Rohrbach, M. Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding. arXiv 2016, arXiv:1606.01847. [Google Scholar]
- Zadeh, A.; Zellers, R.; Pincus, E.; Morency, L.P. MOSI: Multimodal Corpus of Sentiment Intensity and Subjectivity Analysis in Online Opinion Videos. arXiv 2016, arXiv:1606.06259. [Google Scholar]
- Zadeh, A.; Liang, P.P.; Poria, S.; Vij, P.; Morency, L.P. Multi-attention Recurrent Network for Human Communication Comprehension. In Proceedings of the 32 AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; AAAI: New Orleans, LA, USA, 2018. [Google Scholar]
- Liu, Z.; Shen, Y.; Lakshminarasimhan, V.B.; Liang, P.P.; Zadeh, A.; Morency, L.P. Efficient Low-rank Multimodal Fusion with Modality-Specific Factors. arXiv 2018, arXiv:1806.00064. [Google Scholar]
- Yu, Z.; Yu, J.; Fan, J.; Tao, D. Multi-modal factorized bilinear pooling with co-attention learning for visual question answering. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; IEEE: Venice, Italy, 2017; pp. 1821–1830. [Google Scholar]
- Zadeh, A.; Liang, P.P.; Mazumder, N.; Poria, S.; Morency, L.P. Memory Fusion Network for Multi-view Sequential Learning. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; AAAI: New Orleans, LA, USA, 2018; pp. 5634–5641. [Google Scholar]
- Cheng, D. Semi-tensor product of matrices and its application to Morgen’s problem. Sci. China Ser. Inf. Sci. 2001, 44, 195–212. [Google Scholar] [CrossRef]
- Fu, W.; Li, S. Semi-Tensor Compressed Sensing for Hyperspectral Image. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; IEEE: Valencia, Spain, 2018; pp. 2737–2740. [Google Scholar]
- Bai, Z.; Li, Y.; Zhou, M.; Li, D.; Wang, D.; Połap, D.; Woźniak, M. Bilinear Semi-Tensor Product Attention (BSTPA) model for visual question answering. In Proceedings of the 2020 International Joint Conference on Neural Networks, Glasgow, UK, 19–24 July 2020; IEEE: Glasgow, UK, 2020; pp. 1–8. [Google Scholar]
- Chen, Z.; Li, L.; Peng, H.; Liu, Y.; Yang, Y. A novel digital watermarking based on general non-negative matrix factorization. IEEE Trans. Multimed. 2018, 20, 1973–1986. [Google Scholar] [CrossRef]
- Cheng, D.; Qi, H.; Zhao, Y. An Introduction to Semi-Tensor Product of Matrices and Its Applications; World Scientific: Singapore, 2012. [Google Scholar]
- Cheng, D.; Qi, H. A linear representation of dynamics of Boolean networks. IEEE Trans. Autom. Control 2010, 55, 2251–2258. [Google Scholar] [CrossRef]
- Tucker, L. Some mathematical notes on three-mode factor analysis. Psychometrika 1966, 31, 279–311. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.H.; Zhen, N.N.; You, Q.B. Non-negative matrix factorization and its application in pattern recognition. Chin. Sci. Bull. 2006, 51, 241–250. [Google Scholar]
- Hubert, L.; Meulman, J.; Heiser, W. Two purposes for matrix factorization: A historical appraisal. SIAM Rev. 2000, 42, 68–82. [Google Scholar] [CrossRef] [Green Version]
- Busso, C.; Bulut, M.; Lee, C.C.; Kazemzadeh, A.; Mower, E.; Kim, S.; Chang, J.N.; Lee, S.; Narayanan, S.S. IEMOCAP: Interactive Emotional Dyadic Motion Capture Database. Lang. Resour. Eval. 2008, 42, 335–359. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 1532–1543. [Google Scholar]
- DeGottex, G.; Kane, J.; Drugman, T.; Raitio, T.; Scherer, S. COVAREP: A Collaborative Voice Analysis Repository for Speech Technologies. In Proceedings of the IEEE International Conference on Acoustics Speech and Signal Processing, Florence, Italy, 4–9 May 2014; IEEE: Florence, Italy, 2014; pp. 960–964. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Dataset | IEMOCAP | CMU-MOSI |
|---|---|---|
| Training | 6373 | 1284 |
| Validation | 1775 | 229 |
| Test | 1807 | 686 |
| Emotion | Happy | Sad | Angry | Neutral | ||||
|---|---|---|---|---|---|---|---|---|
| Metric | F1 | Acc | F1 | Acc | F1 | Acc | F1 | Acc |
| EF-LSTM | 75.7 | 76.2 | 70.5 | 70.2 | 67.1 | 72.7 | 57.4 | 58.1 |
| LF-LSTM | 71.8 | 72.5 | 70.4 | 72.9 | 67.9 | 68.6 | 56.2 | 59.6 |
| MulT | 79.0 | 85.6 | 70.3 | 79.4 | 65.4 | 75.8 | 44.0 | 59.2 |
| LMF-MulT | 79.0 | 85.6 | 70.3 | 79.4 | 65.4 | 75.8 | 44.0 | 59.3 |
| OURS | 79.0 | 85.7 | 70.3 | 79.5 | 65.4 | 75.9 | 43.8 | 59.2 |
| Metric | MAE | Corr | Acc-2 | F1 | Acc-7 |
|---|---|---|---|---|---|
| EF-LSTM | 1.078 | 0.542 | 73.6 | 74.5 | 31.0 |
| LF-LSTM | 0.988 | 0.624 | 77.6 | 77.8 | 33.7 |
| MulT | 1.008 | 0.645 | 80.3 | 80.4 | 34.3 |
| LMF-MulT | 0.957 | 0.681 | 78.5 | 78.5 | 34.0 |
| OURS | 1.038 | 0.683 | 71.7 | 78.9 | 34.5 |
| Methods | Happy | Sad | Angry | Neutral | ||||
|---|---|---|---|---|---|---|---|---|
| F1 | Acc | F1 | Acc | F1 | Acc | F1 | Acc | |
| PFBT-STP (a+v) | 77.9 | 85.2 | 69.2 | 79.3 | 65.4 | 75.8 | 42.5 | 57.9 |
| PFBT-STP (a+t) | 77.8 | 85.6 | 69.4 | 79.2 | 64.3 | 75.7 | 41.2 | 58.2 |
| PFBT-STP (t+v) | 78.5 | 85.7 | 70.0 | 79.5 | 65.1 | 75.9 | 43.7 | 58.8 |
| PFBT-STP (a+v+t) | 79.0 | 85.7 | 70.3 | 79.5 | 65.4 | 75.9 | 43.8 | 59.2 |
| Dataset | IEMOCAP | CMU-MOSI |
|---|---|---|
| MulT | 1074998 | 1071211 |
| LMF-MulT | 856078 | 512121 |
| OURS | 559872 | 500342 |
| Dataset | IEMOCAP | CMU-MOSI |
|---|---|---|
| MulT | 37.93 | 19.25 |
| LMF-MulT | 23.53 | 12.03 |
| OURS | 17.92 | 11.92 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, F.; Chen, J.; Li, K.; Tan, W.; Cai, C.; Ayub, M.S. A Parallel Multi-Modal Factorized Bilinear Pooling Fusion Method Based on the Semi-Tensor Product for Emotion Recognition. Entropy 2022, 24, 1836. https://doi.org/10.3390/e24121836
Liu F, Chen J, Li K, Tan W, Cai C, Ayub MS. A Parallel Multi-Modal Factorized Bilinear Pooling Fusion Method Based on the Semi-Tensor Product for Emotion Recognition. Entropy. 2022; 24(12):1836. https://doi.org/10.3390/e24121836
Chicago/Turabian StyleLiu, Fen, Jianfeng Chen, Kemeng Li, Weijie Tan, Chang Cai, and Muhammad Saad Ayub. 2022. "A Parallel Multi-Modal Factorized Bilinear Pooling Fusion Method Based on the Semi-Tensor Product for Emotion Recognition" Entropy 24, no. 12: 1836. https://doi.org/10.3390/e24121836
APA StyleLiu, F., Chen, J., Li, K., Tan, W., Cai, C., & Ayub, M. S. (2022). A Parallel Multi-Modal Factorized Bilinear Pooling Fusion Method Based on the Semi-Tensor Product for Emotion Recognition. Entropy, 24(12), 1836. https://doi.org/10.3390/e24121836