
Missing Value Imputation Method for Multiclass Matrix Data Based on Closed Itemset

Abstract
:1. Introduction
2. Closed Itemset
2.1. Definition
2.2. LCM Algorithm
3. Methods
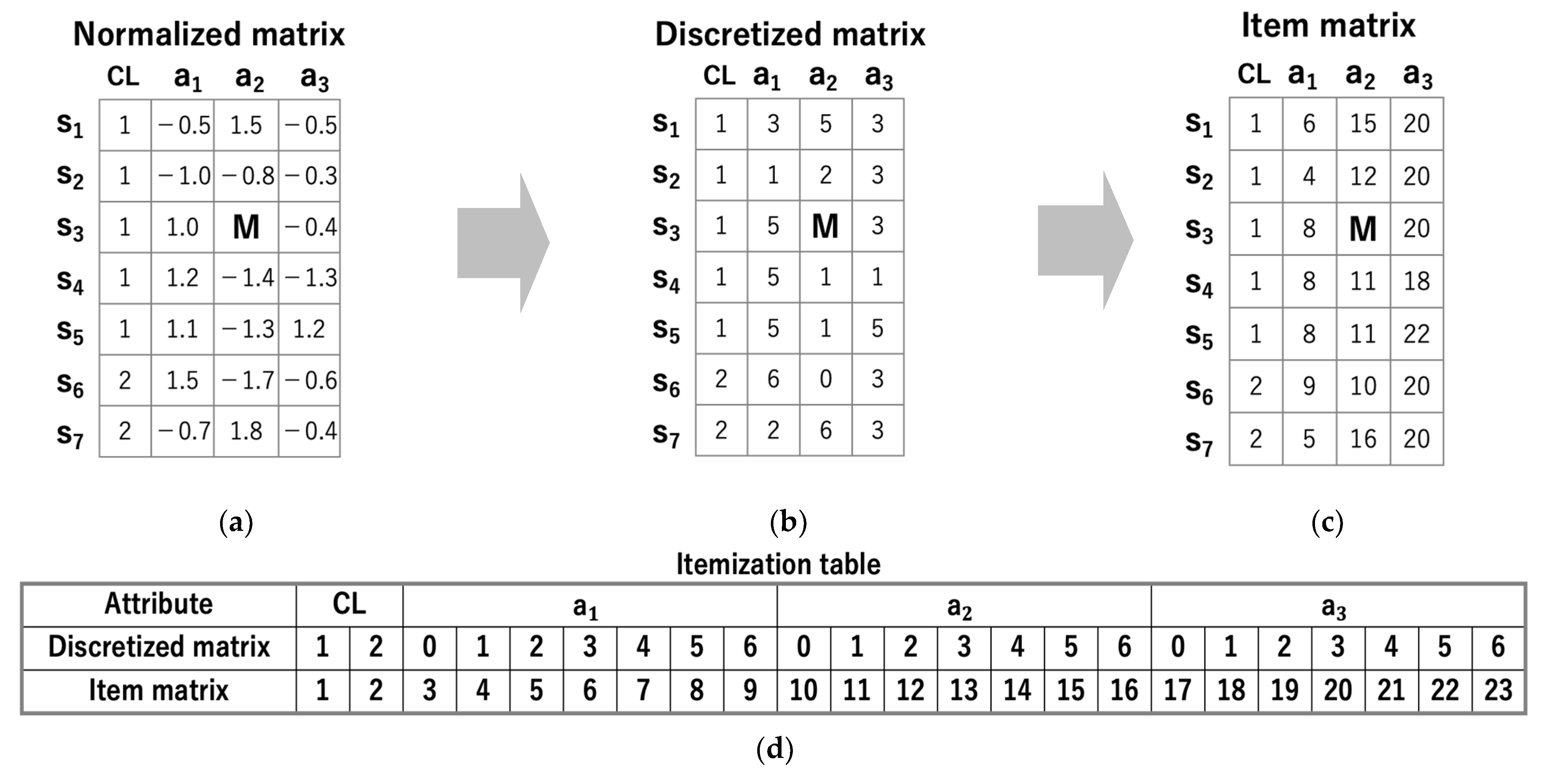
3.1. Preprocessing
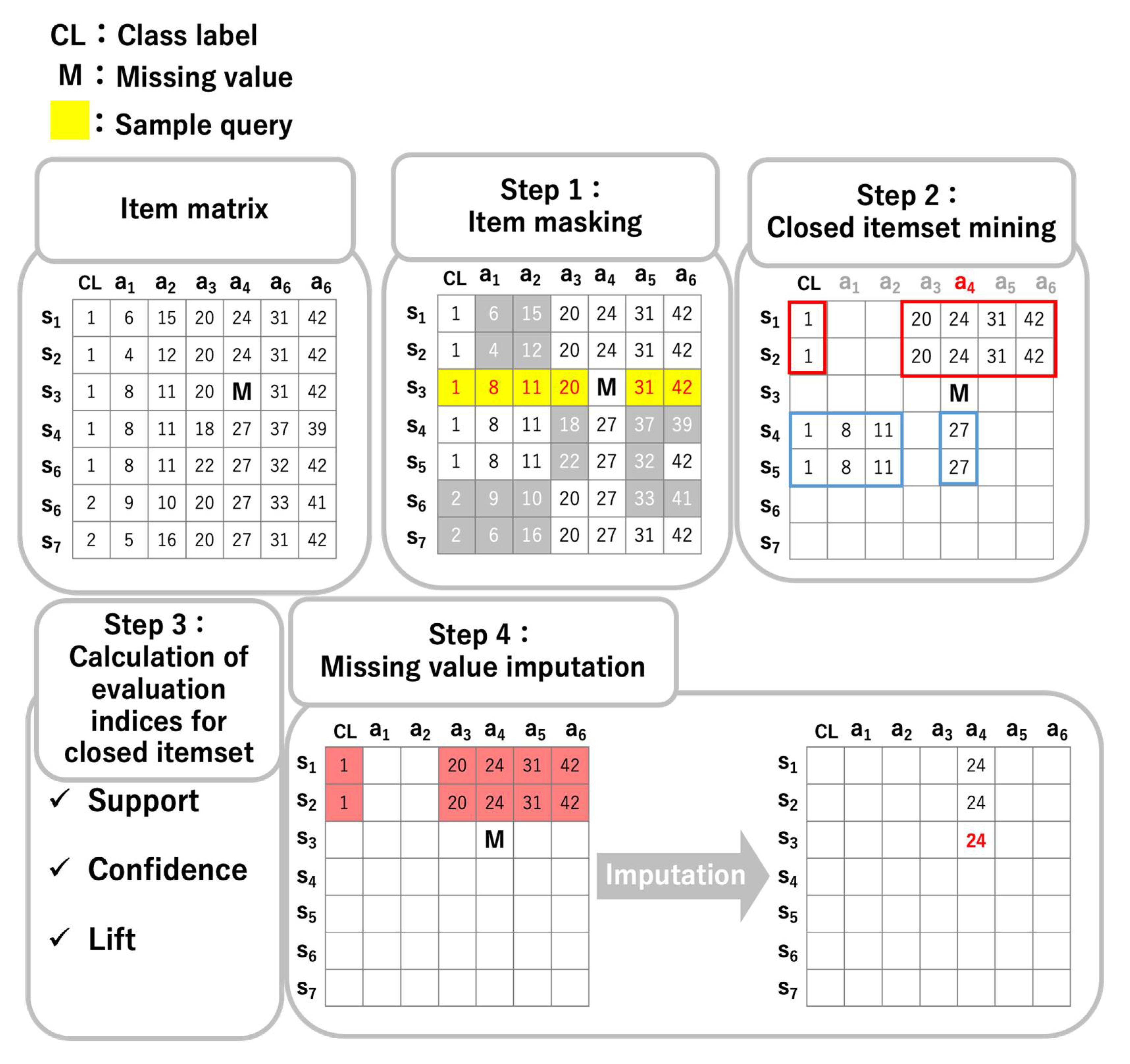
3.2. CIimpute: Closed Itemset-Based Imputation Method
3.2.1. Step 1: Item Masking
3.2.2. Step 2: Closed Itemset Mining
3.2.3. Step 3: Calculation of Evaluation Indices for Closed Itemset
3.2.4. Step 4: Missing Value Imputation
3.3. ICIimpute: Improved Closed Itemset-Based Imputation Method
4. Experiments
4.1. Dataset
4.2. Evaluation Method
5. Results and Discussion
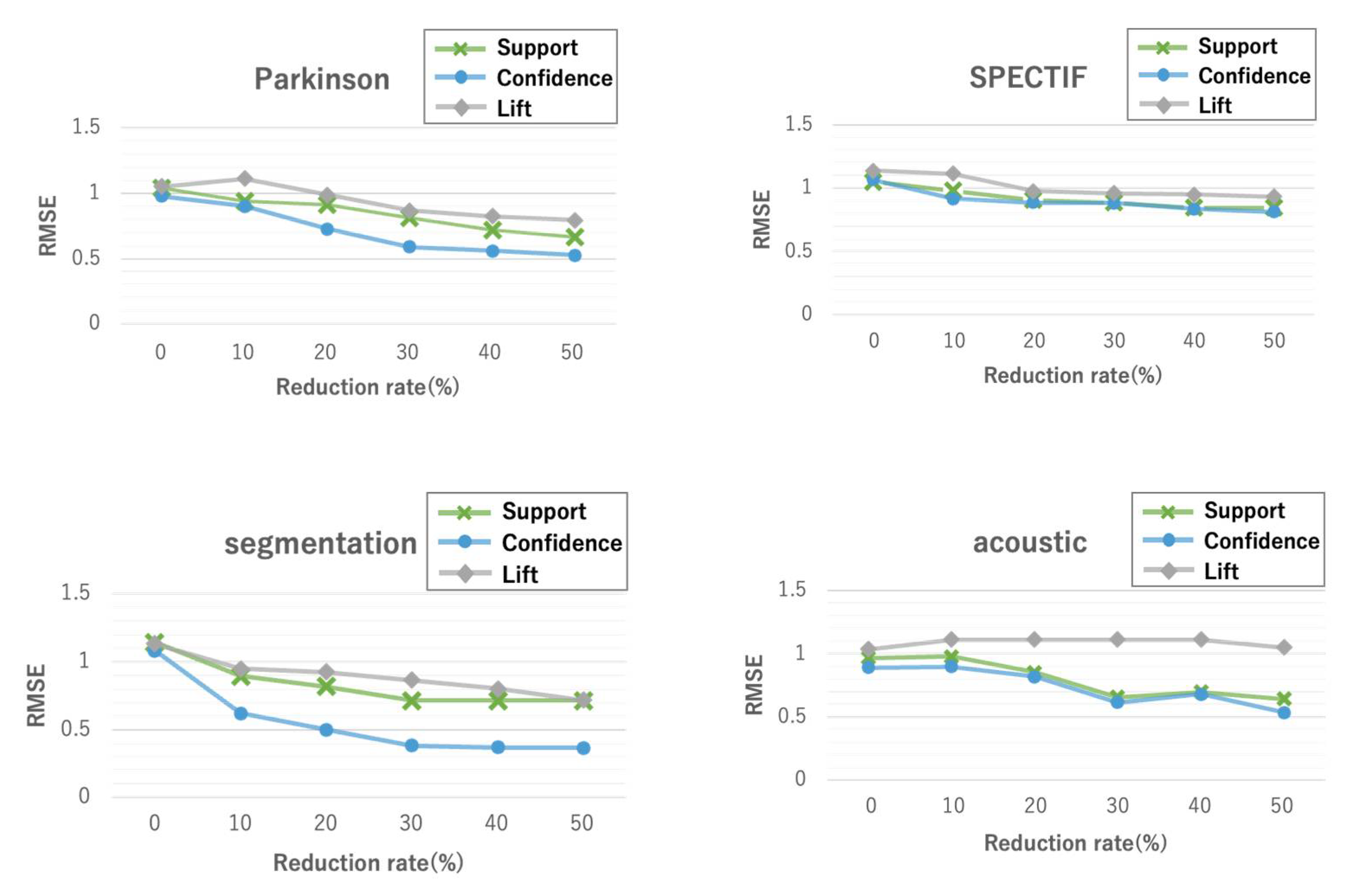
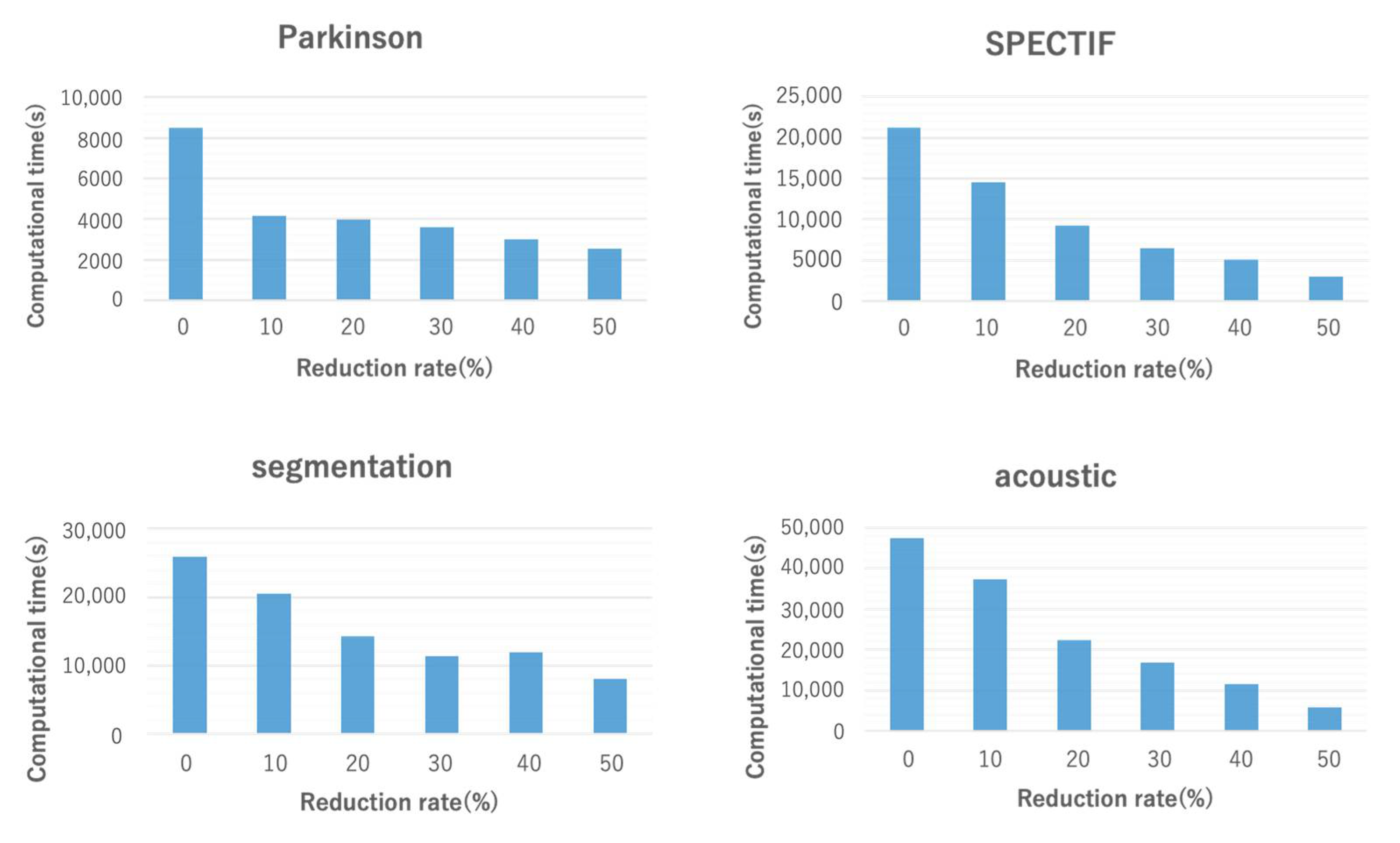
5.1. Evaluation Results with Different Attribute Reduction Rates
5.1.1. Imputation Accuracy
5.1.2. Computational Time
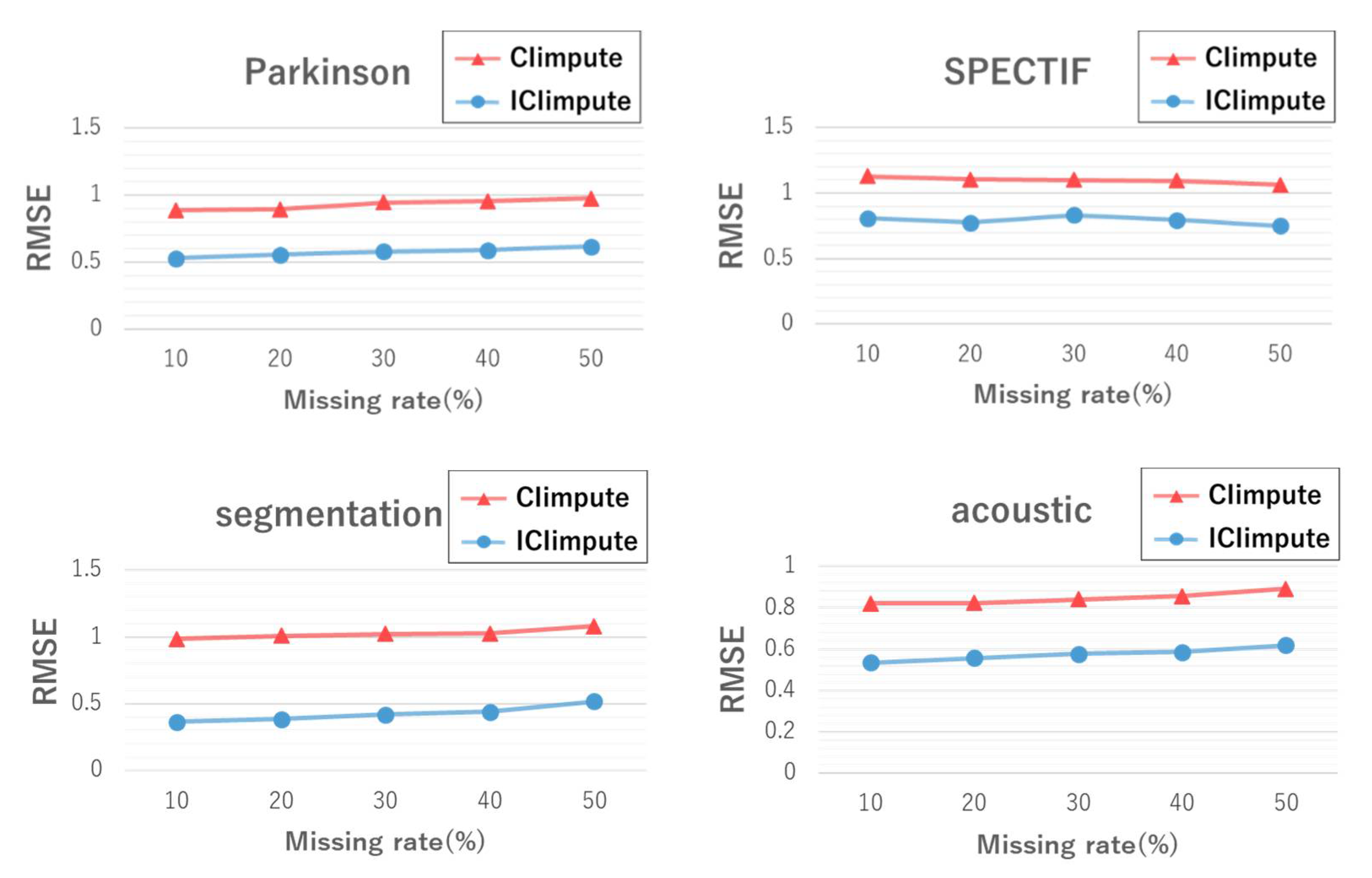
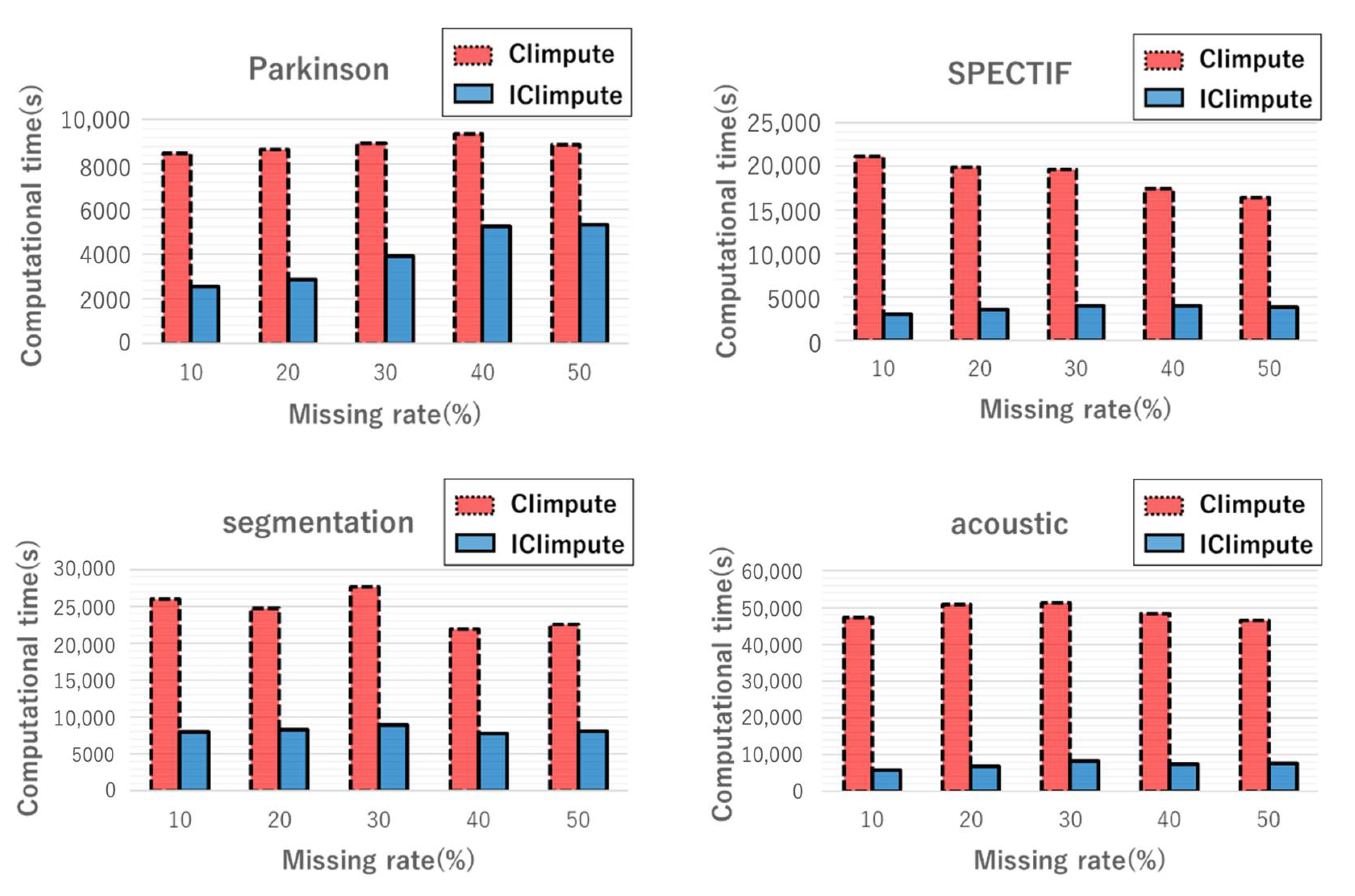
5.2. Evaluation Results with Different Missing Value Rates
5.2.1. Imputation Accuracy
5.2.2. Computational Time
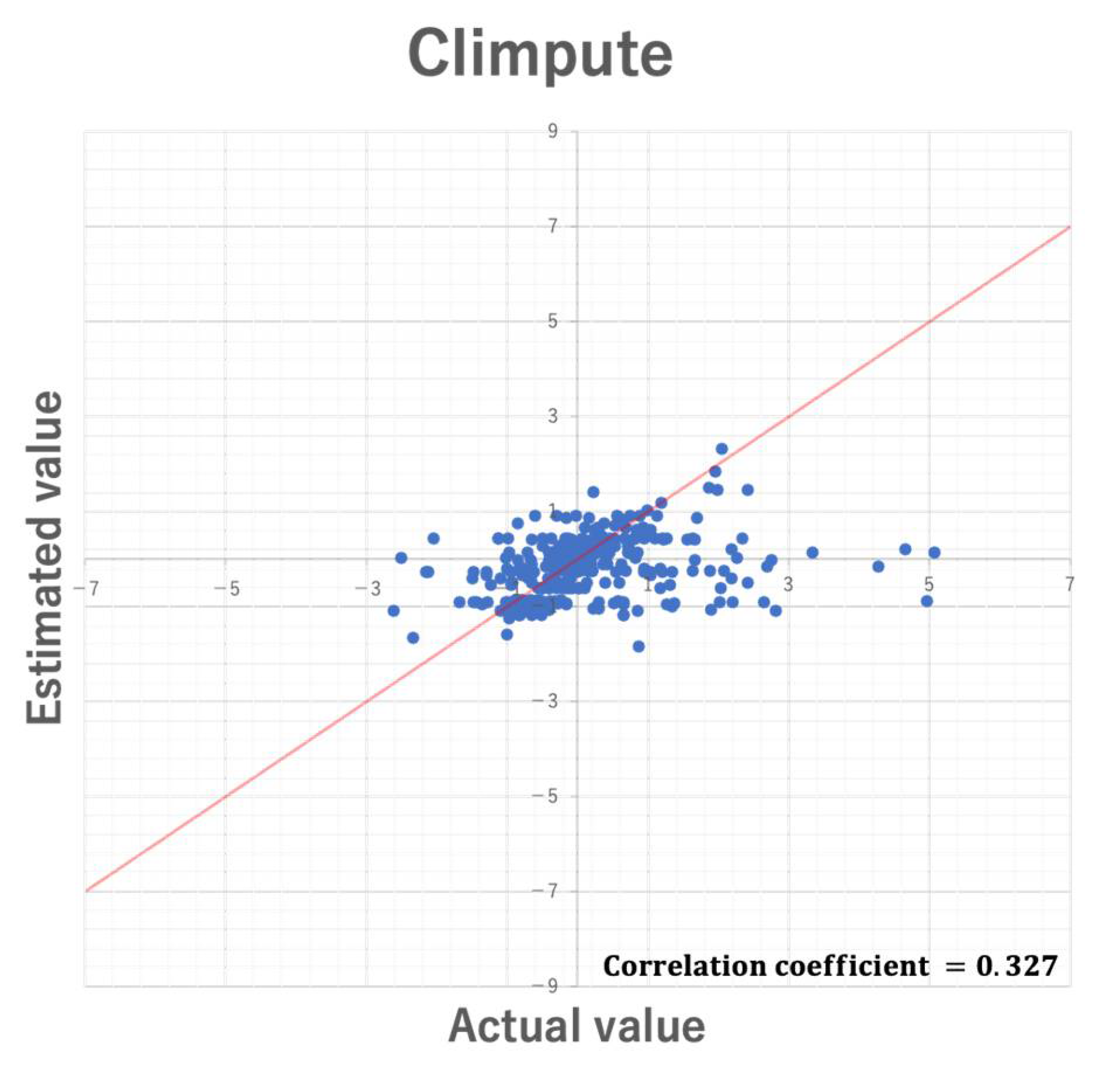
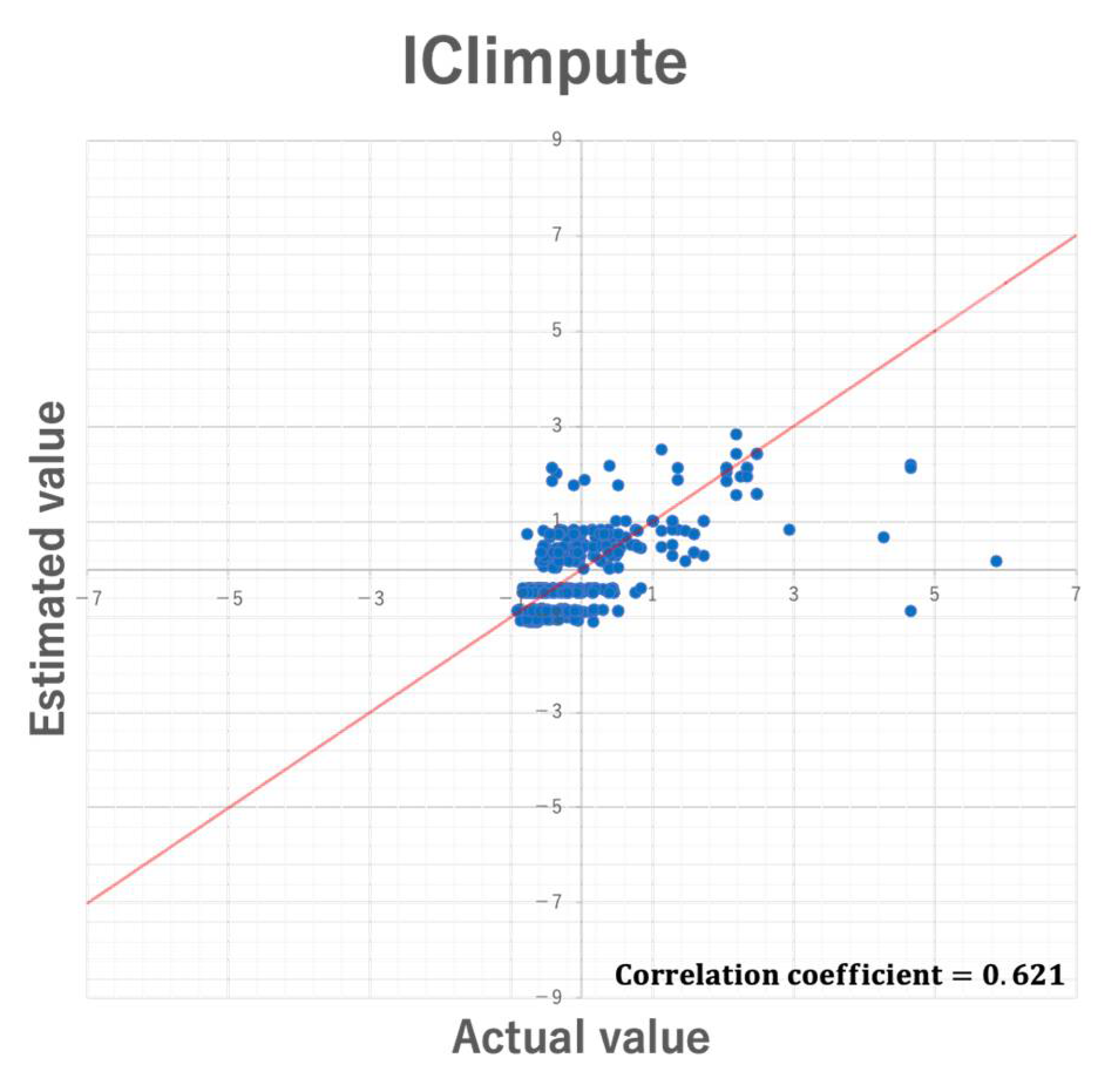
5.3. Comparison with Existing Methods
5.3.1. Comparison of Imputation Accuracy
5.3.2. Comparison of Computational Time
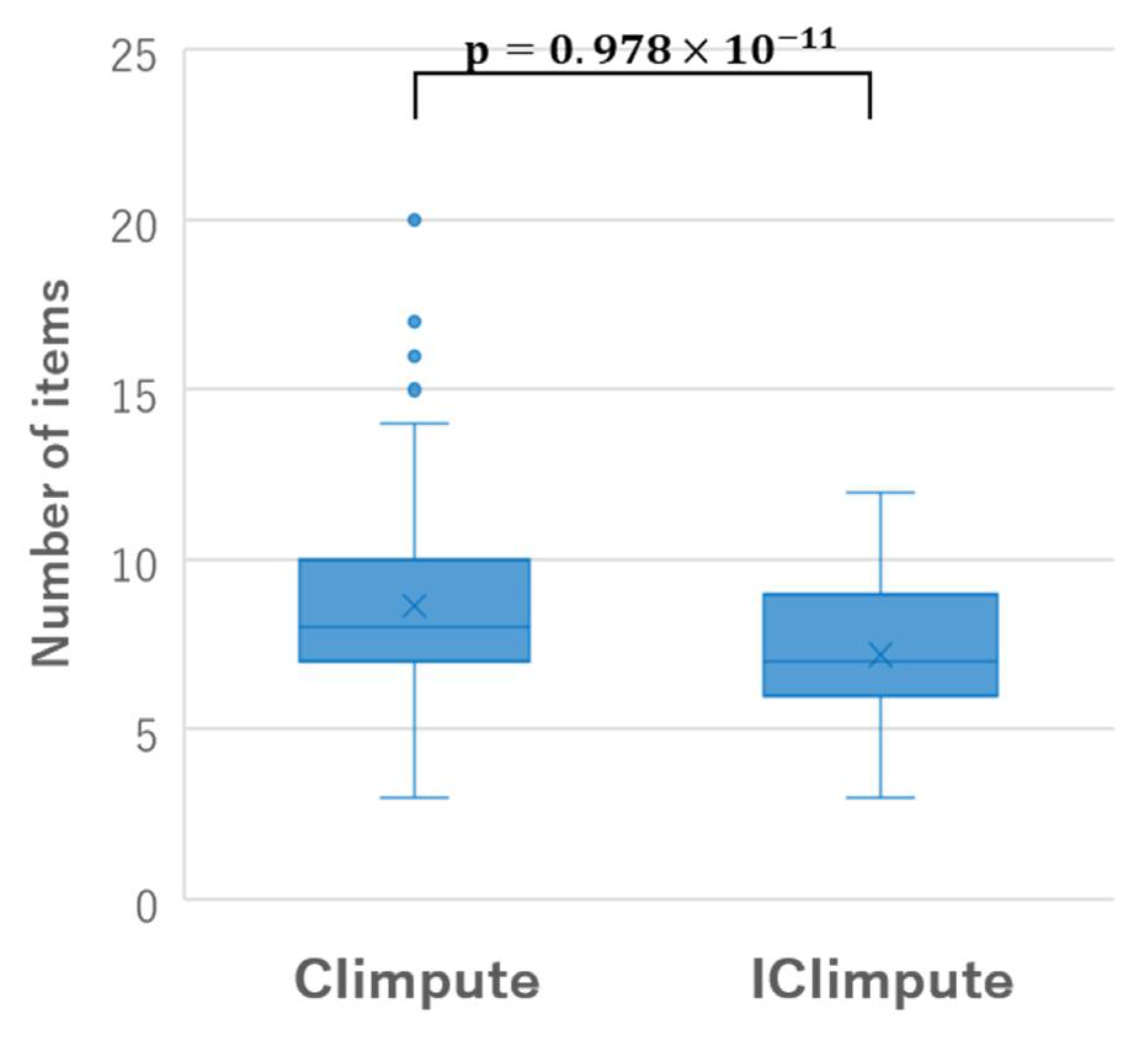
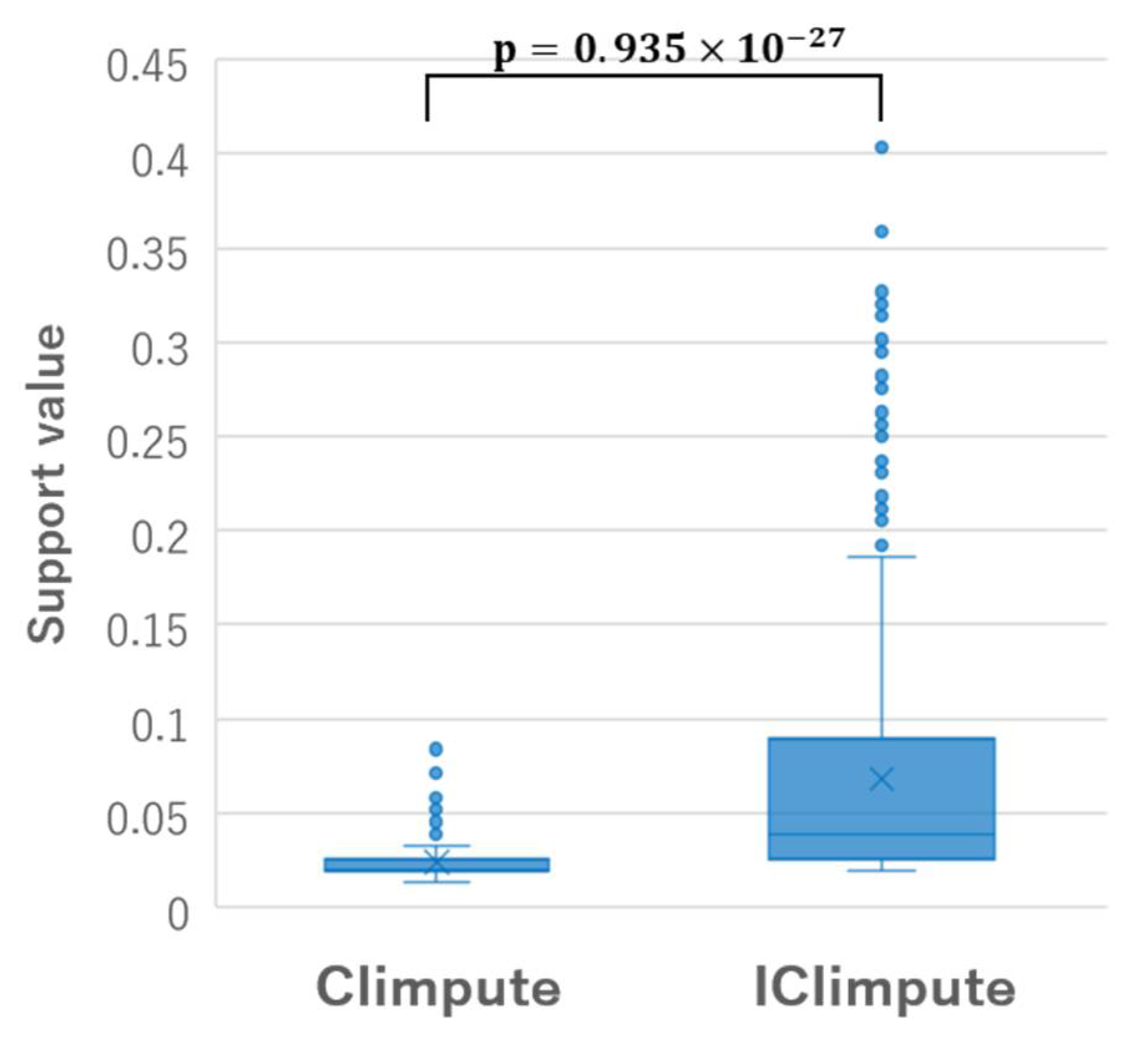
5.4. Discussion
- It is possible to estimate missing values using local feature space for multiclass matrix datasets.
- It is possible to provide more accurate estimated values that are robust to variation of missing rate compared to the existing methods.
- It requires more computational time compared to the existing methods.
- It requires further modifications to apply to MAR and MNAR.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- El Azzaoui, A.; Singh, S.K.; Park, J.H. Sns big data analysis framework for COVID-19 outbreak prediction in smart healthy city. Sustain. Cities Soc. 2021, 71, 102993. [Google Scholar] [CrossRef] [PubMed]
- Cheng, C.H.; Chang, S.K.; Huang, H.H. A novel weighted distance threshold method for handling medical missing values. Comput. Biol. Med. 2020, 122, 1023824. [Google Scholar] [CrossRef]
- Jerez, J.M.; Molina, I.; García-Laencina, P.J.; Alba, E.; Ribelles, N.; Martín, M.; Franco, L. Missing data imputation using statistical and machine learning methods in a real breast cancer problem. Artif. Intell. Med. 2010, 50, 105–115. [Google Scholar] [CrossRef] [PubMed]
- Razavi-Far, R.; Saif, M. Imputation of missing data using fuzzy neighborhood density-based clustering. In Proceedings of the 2016 IEEE International Conference on Fuzzy Systems, Vancouver, BC, Canada, 24–29 July 2016; pp. 1834–1841. [Google Scholar]
- Nelwamondo, F.V.; Golding Dan, I.; Marwala, T. A dynamic programming approach to missing data estimation using neural networks. Inf. Sci. 2013, 237, 49–58. [Google Scholar] [CrossRef]
- Li, D.; Deogun, J.; Sqaulding, W.; Shuart, B. Towards missing data imputation: A study of fuzzy k-means clustering method. In International Conference on Rough Sets and Current Trends in Computing; Springer: Berlin/Heidelberg, Germany, 2004; pp. 573–579. [Google Scholar]
- Pelckmans, K.; De Brabanter, J.; Suykens, J.A.K.; De Moor, B. Handling missing values in support vector machine classifiers. Neural Netw. 2005, 18, 684–692. [Google Scholar] [CrossRef]
- Han, J.; Kamber, M.; Pei, J. Data Mining Concepts and Techniques, 3rd ed.; Morgan Kaufmann Publishers: Waltham, MA, USA, 2012; pp. 83–85. [Google Scholar]
- Paradis, A.D.; Fitzmaurice, G.M.; Koenen, K.C.; Buka, S.L. A prospective investigation of neurodevelopmental risk factors for adult antisocial behavior combining official arrest records and self-reports. J. Psychiatr. Res. 2015, 68, 363–370. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bethlehem, J. Applied Survey Methods: A Statistical Perspective, 3rd ed.; Wiley Series in Survey Methodology; Wiley: Hoboken, NJ, USA, 2009; pp. 183–185. [Google Scholar]
- Troyanskaya, O.; Cantor, M.; Sherlock, G.; Brown, P.; Hastie, T.; Tibshirani, R.; Botstein, D.; Altman, R.B. Missing value estimation methods for DNA microarrays. Bioinformatics 2001, 17, 520–525. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, S. Nearest neighbor selection for iteratively kNN imputation. J. Syst. Softw. 2012, 85, 2541–2552. [Google Scholar] [CrossRef]
- Bø, D.J.; Dysvik, B.; Jonassen, I. LSimpute: Accurate estimation of estimation of missing values in microarray data with least squares methods. Nucleic Acids Res. 2004, 32, e34. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kokla, M.; Virtanen, J.; Kolehmainen, M.; Paananen, J.; Hanhineva, K. Random forest-based imputation outperforms other methods for imputing LC-MS metabolomics data: A comparative study. BMC Bioinform. 2019, 20, 492. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rahman, G.; Islam, Z. A decision tree-based missing value imputation technique for data pre-processing. In Proceedings of the 9th Australasian Data Mining Conference, Ballarat, Australia, 1–2 December 2011; pp. 41–50. [Google Scholar]
- Zhang, W.; Yang, Y.; Wang, Q. Handling missing data in software effort prediction with naive Bayes and EM algorithm. In Proceedings of the 7th International Conference on Predictive Models in Software Engineering, Banff, AB, Canada, 20–21 September 2011; p. 4. [Google Scholar]
- Newman, D. UCI Machine Learning Repository. Available online: http://archive.ics.uci.edu/ml/ (accessed on 1 December 2021).
- Uno, T.; Asai, T.; Uchida, Y.; Arimura, H. An efficient algorithm for enumerating closed patterns in transaction databases. In International Conference on Discovery Science; Springer: Berlin/Heidelberg, Germany, 2004; pp. 16–31. [Google Scholar]
- Uno, T.; Arimura, H. LCM Program Code. Available online: http://research.nii.ac.jp/~uno/codes.htm (accessed on 1 December 2021).
- Okada, Y.; Fujibuchi, W.; Horton, P. A biclustering method for gene expression module discovery using closed itemset enumeration algorithm. IPSJ Trans. Bioinform. 2007, 48, 39–48. [Google Scholar] [CrossRef] [Green Version]
- Jin, L.; Bi, Y.; Hu, C.; Qu, J.; Shen, S.; Wang, X.; Tian, Y. A comparative study of evaluating missing value imputation methods in label-free proteomics. Sci. Rep. 2021, 11, 1760. [Google Scholar] [CrossRef] [PubMed]
- Okada, Y.; Tada, T.; Fukuta, K.; Nagashima, T. Audio classification based on closed itemset mining algorithm. Int. J. Comput. Inf. Syst. Ind. Manag. Appl. 2011, 3, 159–164. [Google Scholar]
- Nadimi-Shahraki, M.H.; Mohammadi, S.; Zamani, H.; Gandomi, M.; Gandomi, A.H. A hybrid imputation method for multi-pattern missing data: A case study on type II diabetes diagnosis. Electronics 2021, 10, 3167. [Google Scholar] [CrossRef]
- Tomita, H.; Fujisawa, H.; Henmi, M. A bias-corrected estimator in multiple imputation for missing data. Stat. Med. 2018, 37, 3373–3386. [Google Scholar] [CrossRef] [PubMed]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | # of Attributes | # of Samples | Class Label | # of Samples in Each Class |
|---|---|---|---|---|
| Parkinson | 23 | 197 | 1 | 49 |
| 2 | 148 | |||
| SPECTIF | 44 | 80 | 1 | 30 |
| 2 | 50 | |||
| segmentation | 19 | 210 | 1 | 30 |
| 2 | 30 | |||
| 3 | 30 | |||
| 4 | 30 | |||
| 5 | 30 | |||
| 6 | 30 | |||
| 7 | 30 | |||
| acoustic | 46 | 240 | 1 | 121 |
| 2 | 119 |
| Methods | Parkinson | SPECTIF | Segmentation | Acoustic |
|---|---|---|---|---|
| Method2 | 3628 | 6537 | 11,384 | 16,827 |
| KNNimpute | 11 | 9 | 11 | 10 |
| LSimpute | 18 | 14 | N/A | 22 |
| RF | 67 | 68 | 64 | 261 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tada, M.; Suzuki, N.; Okada, Y. Missing Value Imputation Method for Multiclass Matrix Data Based on Closed Itemset. Entropy 2022, 24, 286. https://doi.org/10.3390/e24020286
Tada M, Suzuki N, Okada Y. Missing Value Imputation Method for Multiclass Matrix Data Based on Closed Itemset. Entropy. 2022; 24(2):286. https://doi.org/10.3390/e24020286
Chicago/Turabian StyleTada, Mayu, Natsumi Suzuki, and Yoshifumi Okada. 2022. "Missing Value Imputation Method for Multiclass Matrix Data Based on Closed Itemset" Entropy 24, no. 2: 286. https://doi.org/10.3390/e24020286
APA StyleTada, M., Suzuki, N., & Okada, Y. (2022). Missing Value Imputation Method for Multiclass Matrix Data Based on Closed Itemset. Entropy, 24(2), 286. https://doi.org/10.3390/e24020286