1. Introduction
The random graph is a useful concept that is frequently applied in complex systems modeling. The employment of random graph models has grown rapidly with the explosive development of computer and social networks.
There is no single approach to what random graphs are or how they can be generated. If there are any characteristic properties that one can expect from the structure of the studied complex system, it may be possible to either pick a suitable random graph model (e.g., Erdős–Rényi–Gilbert, small-world, or scale-free, see
Section 2.1) or to construct an bespoke model based on the maximum entropy graph model (see
Section 2.2)
However, if the prototype system to be modeled is very complex and/or weakly studied, the researcher may not know its connection structure. The researcher may not even wish to spend resources on the clarification of this connection structure, as the purpose of the study may be nothing but fast prototyping.
There are many important domains where the necessary empirical dataset is too large to work with or too hard to obtain; some examples are information flows in global computer networks [
1,
2], large-scale social networks [
3,
4], signal flows in the brain [
5,
6], interactions of cells within a multicellular organism [
7,
8], and protein–protein interaction networks [
9].
Furthermore, the empirical data that does exist in these domains can be ambiguous, forcing the community to regularly review the models used for them [
10,
11,
12,
13,
14,
15]. Finally, there are examples of complex systems (albeit rather controversial ones) where the connection structure is entirely unknown [
16,
17].
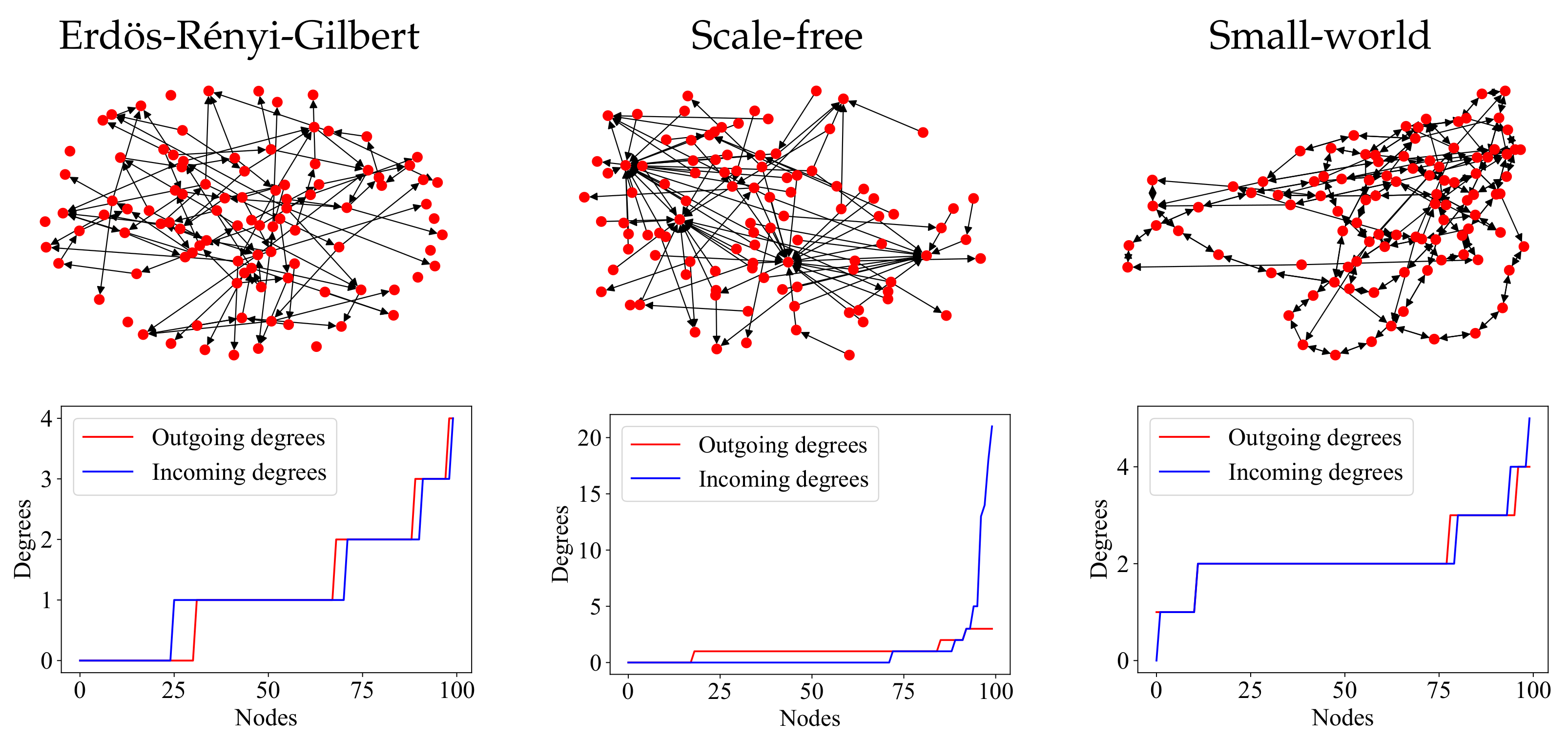
In the present paper, we address the question of how to construct a random graph model for a complex system, the connection structure of which cannot be (or is not intended to be) estimated empirically. As the examples in the Appendix show, real-world complex systems give rise to graphs with a huge variety of possible vertex degree distributions. This means that if a model is selected based on a guessed degree distribution (on account of a hypothesis that may turn out to be wrong), substantial errors may result; consider, for example, the scale-free graph (the first figure) as a model of either the DBLP citation database or the cell connections in a stem of
Arabidopsis Columbia (see
Table A1 in
Appendix A).
In situations where information is meager, we propose that, instead of attempting to guess the true connection structure, one should model the complex system via an ensemble of graphs whose vertex degree distributions are as diverse as possible. Such an approach may prevent a narrowing in the variety of behavior that the prototype system is able to exhibit. For example, it can help to avoid “false calm” conclusions about the possible outcomes of a dangerous process run in the complex system (see
Section 6.8).
As a method of constructing a diverse ensemble of graphs, we present the Random Plots model. This model produces each sample graph with
N vertices by (1) generating a “random” nondecreasing function from
to
as a reference (we call it reference
vertex degree plot or rVDP) or (2) applying any graph generator that implements the soft configuration model [
18] to construct a graph whose array of vertex degrees sorted in ascending order (we call this the actual vertex degree plot or aVDP, see the first figure) is close to the constructed rVDP.
In the next section, we consider several common random graph models, placing emphasis on the models that represent complex systems for which no additional knowledge is available. Algorithms implementing the Random Plots model are given in
Section 3. In
Section 4, we consider the time complexity, space complexity, and scalability of the proposed algorithms. In
Section 5, we study the accuracy of the construction, i.e., how close the aVDPs of the constructed graphs are to the corresponding rVDPs. In
Section 6, we compare the diversity (in terms of several different scalar properties) of a set of graphs produced by the Random Plots model to the diversity of sets produced by the Erdős–Rényi–Gilbert, scale-free, and small-world models. We find that, with respect to six out of the seven scalar properties studied, as well as with respect to the terminal states of one dynamic process, our model produces the most diverse set of graphs.
Section 7 contains some concluding remarks.
3. Algorithms
Before proceeding to the algorithms, let us briefly recall some terms and notations that are used below. Digraph means directed graph; the indegree of a vertex in a digraph is the number of edges incoming to this vertex; and the outdegree is the the number of edges outgoing from this vertex. The notation for any natural means . The vertex degree plot (VDP) of a graph is the array of vertex degrees sorted in ascending order. A digraph has two VDPs: for the indegrees and outdegrees. The notation means that the random variable has a uniform distribution within the interval . The notation means discrete uniform distribution within
In the Random Plots model, the construction of each sample graph involves the consecutive execution of two algorithms: (1) an algorithm that produces a “random” (in some sense) pair of vertex in- and outdegree plots, termed reference VDPs (rVDPs); (2) an algorithm that generates a simple digraph whose actual VDPs (or aVDPs) are close to the reference ones.
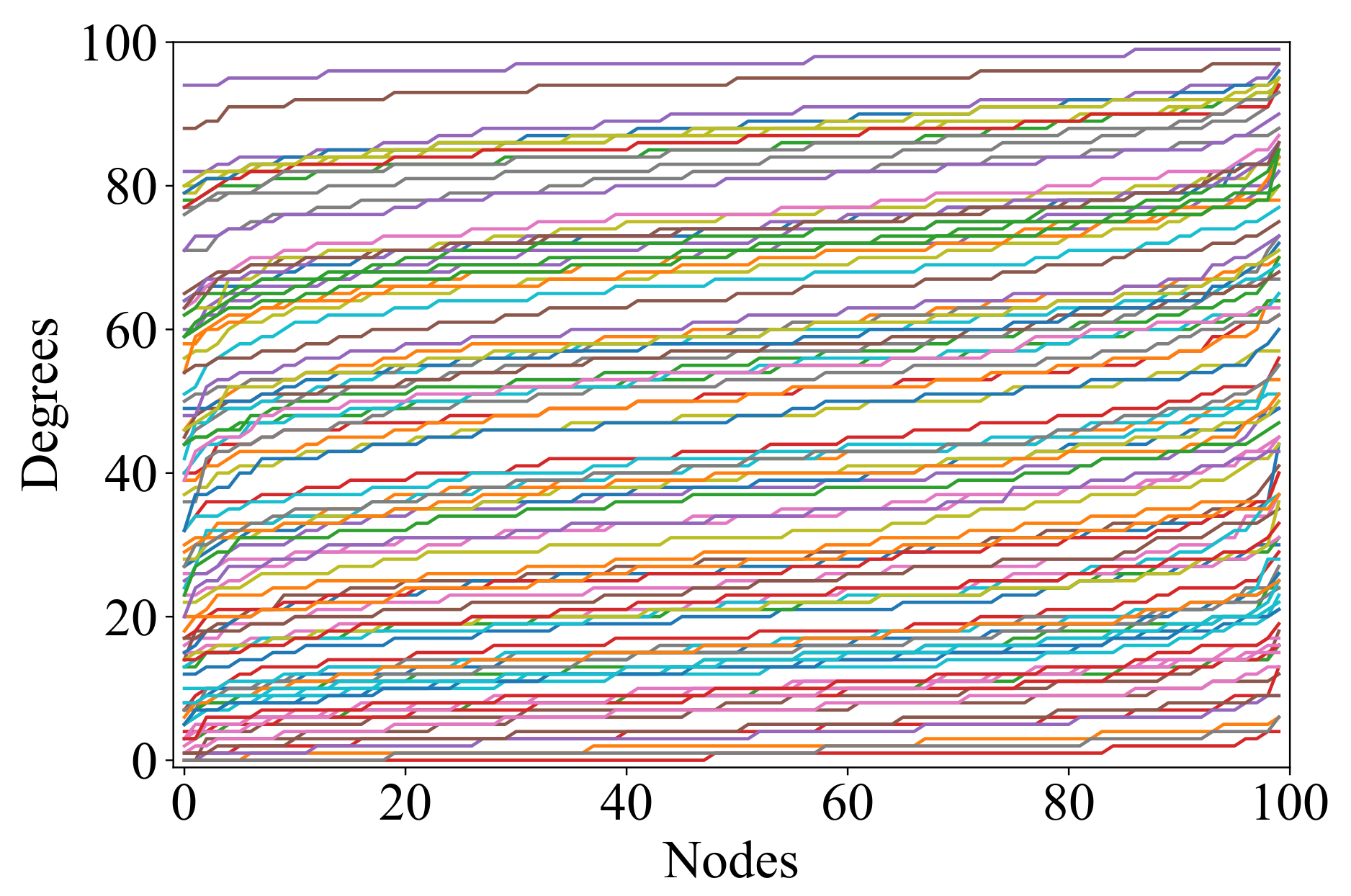
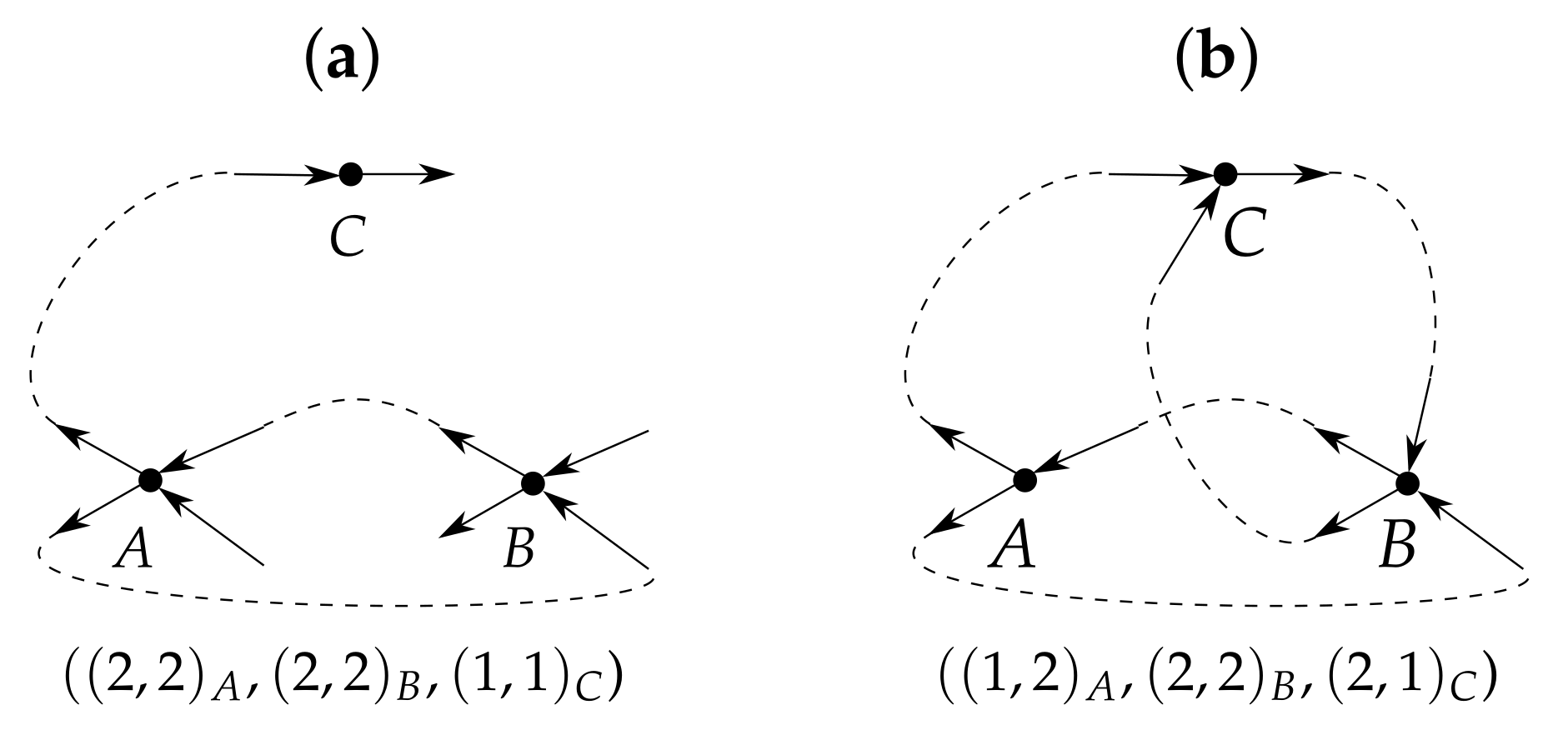
Algorithm 1 produces a pair of functions (arrays) whose values are the target vertex in- and outdegrees of the simple digraph with N vertices, which is to be generated by Algorithm 2. Each array is sorted in ascending order, so that index i in usually does not refer to the same vertex as in (see examples in the ninth figure).
Note that the construction of a “feasible” pair of in- and outdegree sequences, i.e., one that can, in fact, be realized by a simple digraph, is a rather difficult problem (see, for example, [
41] and the comments preceding Algorithm 2 below). However, in Algorithm 1, we do not care about this kind of feasibility; the only restriction we impose on the two sequences comes from the natural equality between the sums of the outgoing and incoming degrees in a graph (see Step 8).
| Algorithm 1: Construction of reference vertex in- and outdegree plots (rVDPs). |
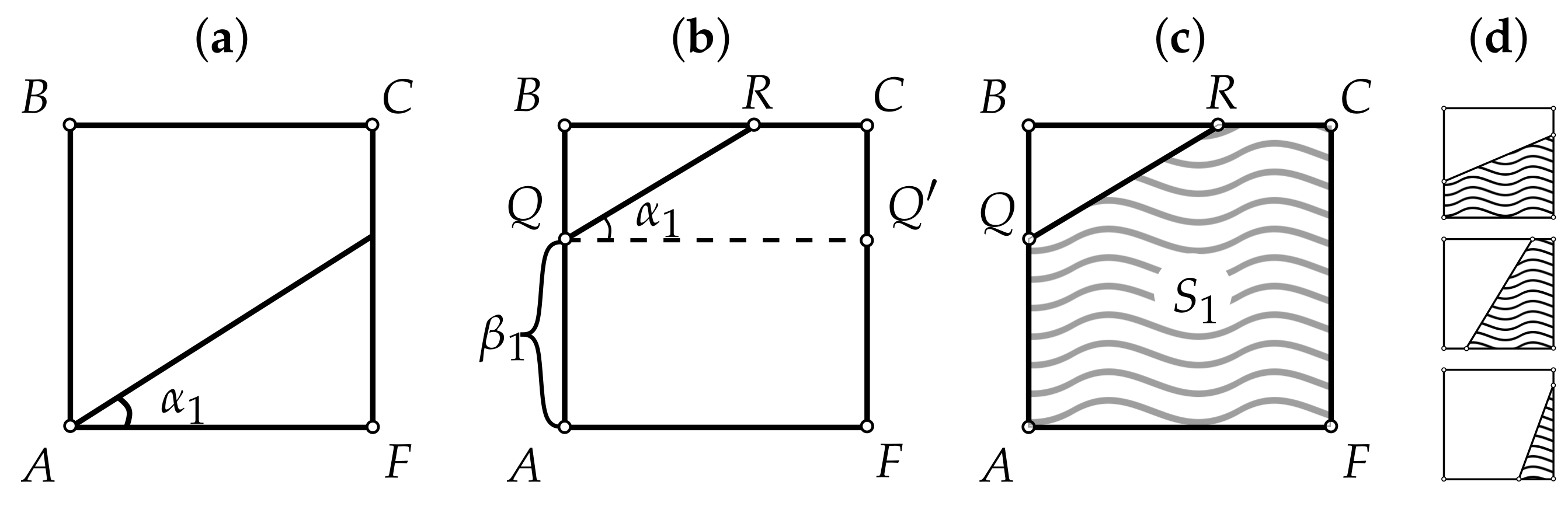
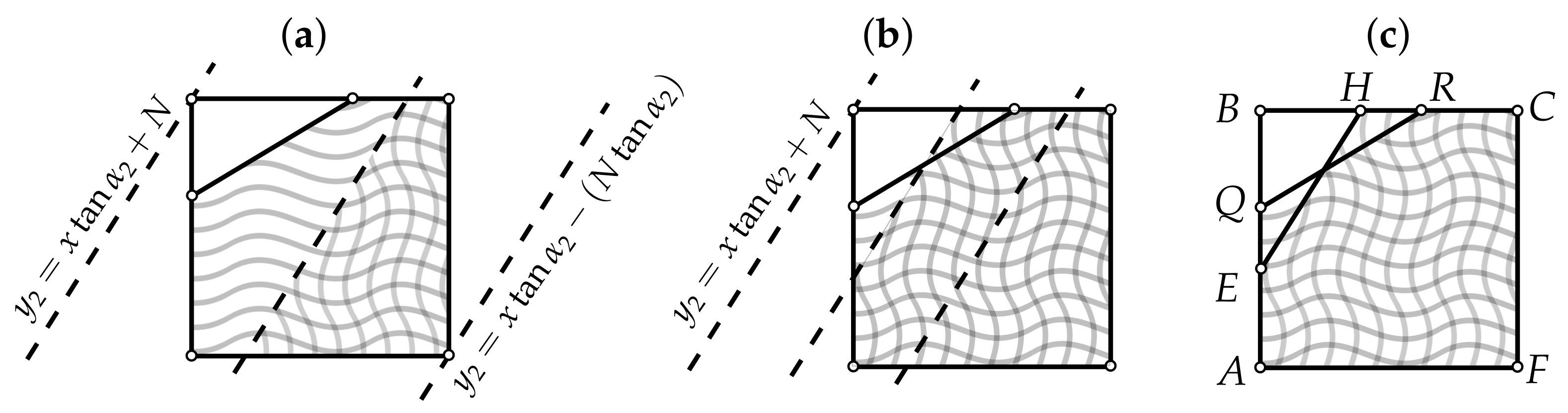
Let N be the number of elements within the complex system under study. Let , , , (see Figure 3a); uniformly choose an angle . Choose equiprobably one of the two directions of shift: from A to B or from A to F. Without loss of generality, let it be the first direction (see Figure 3b). Uniformly choose the shift ; the equation of the line going through Q at an angle to the horizontal is , where (had the shift been done towards F, the constant term would have been equal to ). Given that , R belongs to , so its coordinates can be easily derived (see Figure 3b). Knowing the coordinates of R, one can compute the area of the polygon (see Figure 3c); this area will be approximately equal to the total number of incoming edges in the graph under construction. The other possible forms of the incoming VDP are shown in Figure 3d. Uniformly choose an angle . Choose so that the resulting area is equal to (this corresponds to the condition of equality between the sums of the incoming and outgoing degrees). The unknown can be expressed analytically, but because there are many possible configurations for the intersections of the lines and with the edges of the square (4 variants for each line, resulting in variants for the pair ), it may be more convenient to use the bisection method starting from the interval (see Figure 4). Generate a random binary number . If , construct the arrays based on the functions and the bounding edges of so that for every ,
(Here, we require , but this is an arbitrary condition that can be relaxed to without a loss of generality.) If , use in the construction of and in the construction of instead. If
return the constructed rVDPs . In case the sums are not equal, say
iteratively apply one of the following procedures (selected equiprobably) until ( 6) is true: for a random , either (a) add 1 to , given that , or (b) subtract 1 from , given that . Return the constructed rVDPs .
|
Let us proceed to the second algorithm, which constructs a simple digraph whose aVDPs are close to
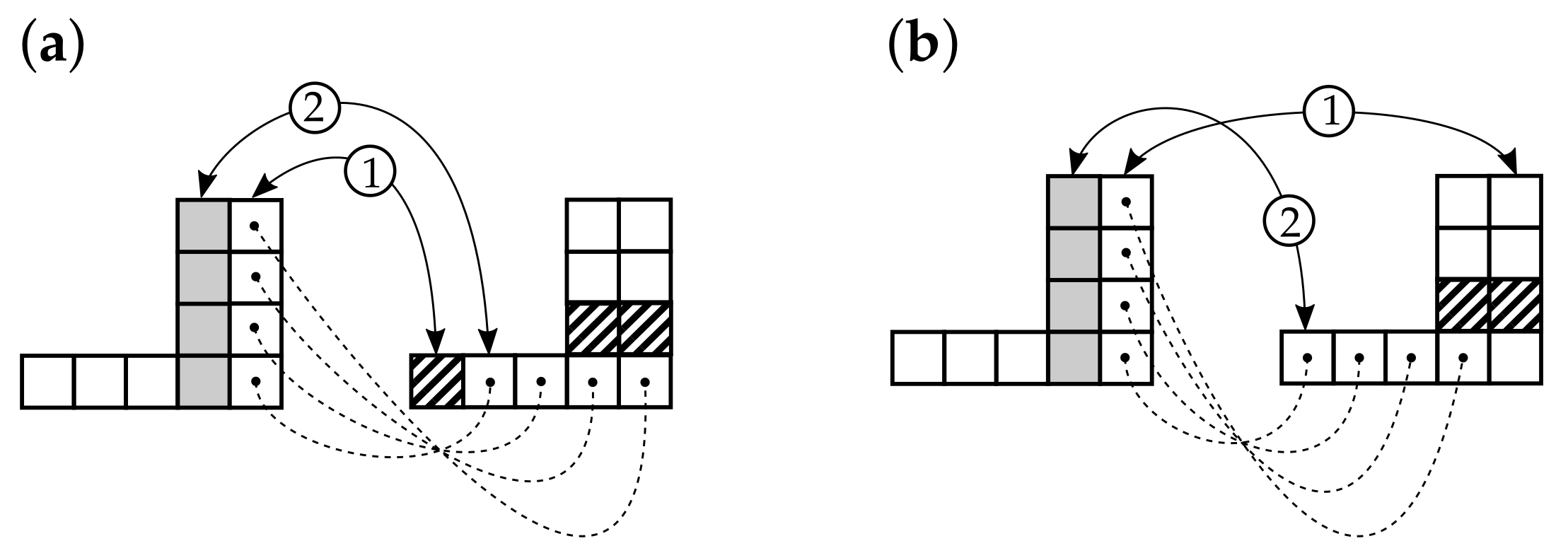
. As we mentioned above, far from every sequence of the form
allows the construction of a corresponding simple digraph, where the in- and outdegrees of the
ith vertex are
and
, respectively (see example in
Figure 5a).
Fortunately, for our purposes, there is no need to tie the values of the outdegrees to the values of the indegrees: it is sufficient to match the degrees to the sequences
and
separately. Formally, the relaxed problem may be written as follows: given a sequence of the form (
7), construct a simple digraph with
N vertices for which
where
and
are the in- and outdegrees of the vertex
respectively.
While the decoupling of the indegrees from the outdegrees enlarges the set of sequences for which a digraph can be constructed (
Figure 5b), it cannot guarantee the existence of a digraph for every possible pair of sequences (see example in
Figure 6). It would be interesting to mathematically characterize the “weakly graphical sequences”: those for which there is at least one solution to (
8).
In our case, the theoretical difficulties considered above are of no particular importance, as we are satisfied with constructing graphs whose aVDPs match only approximately the rVDPs generated by Algorithm 1. There are many works devoted to practical methods for constructing simple digraphs that match given degree sequences (at least approximately). The approach we use originated from the “sequential algorithm” of [
42]; it was also influenced by earlier methods [
43,
44,
45,
46,
47].
| Algorithm 2: Construction of a digraph whose aVDPs are close to given rVDPs. |
Let the algorithm’s input consist of two functions which are the results of Algorithm 1. (Recall that, by construction, and for every .) Choose an arbitrary permutation ; we are going to construct a simple digraph where and . (The permutation is used to destroy the positive correlation between and caused by the fact that and are monotonically increasing.) Initially, let for all (i.e., ). While , repeat
- (a)
Choose one of the two symbols + and − equiprobably; without loss of generality, let it be −, which leads to the processing of the outdegrees first and indegrees second. ( If + is chosen, then the processing order reverses with the corresponding changes in the next steps.) - (b)
Let be the set of vertices from which it is possible to start a new non-multiple edge: (, because if there is no pair such that and , then is already complete and the condition could not have been true). - (c)
Choose a head vertex with a probability of . - (d)
By construction is not empty, choose a tail vertex with a probability of . - (e)
Add to E.
Return the digraph .
|
Given that an rVDP is a piecewise linear approximation of the subsequent aVDP, it becomes clear why the order of degree introduced on the vertices in rVDP is important: it makes it possible to construct an approximation of reasonable accuracy using only a few line segments.
4. Complexity and Scalability
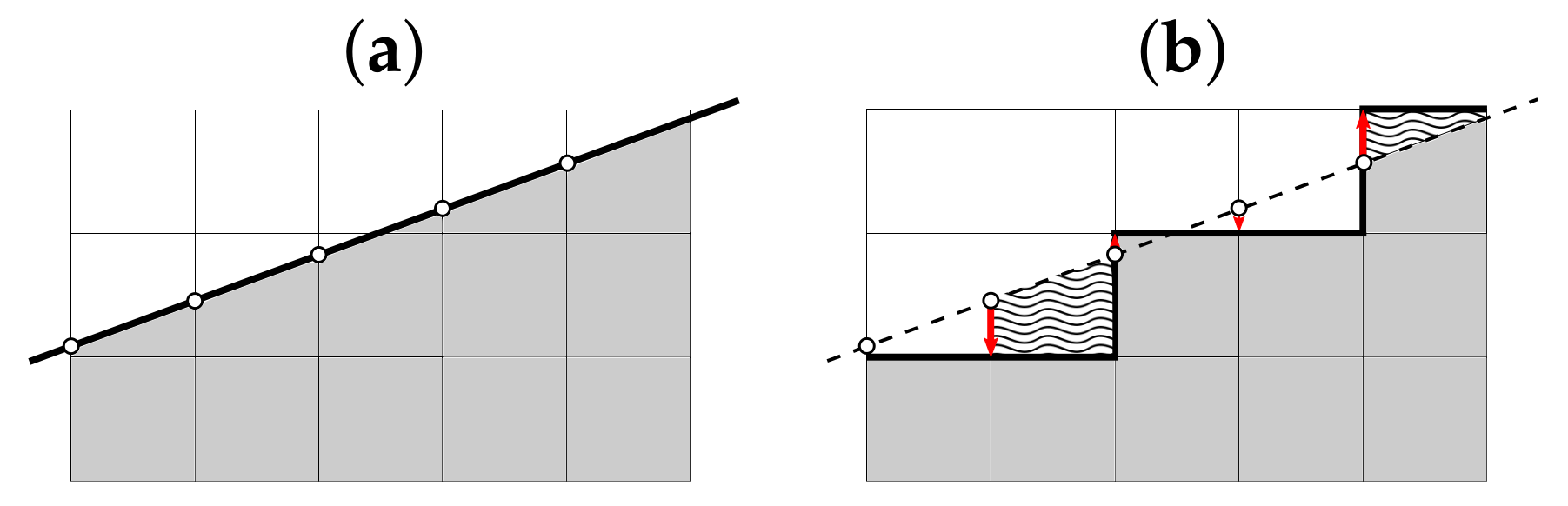
Steps 1–6 of Algorithm 1 have constant time complexity
, Steps 7, 8 have time complexity
. In Step 9, we iteratively adjust possibly different
and
. Let us estimate the number of iterations needed.
Figure 7 illustrates that
Given that, by construction,
we have
which proves that both Step 9 and, therefore, the whole Algorithm 1 have time complexity
.
The space complexity of Algorithm 1 is also , as the largest data we need to store during the runtime consist of the N values of and N values of .
The time complexity is for both the summation at Step 1 and permutation at Step 2. The time complexity of Step 3 is . Step 4 is repeated times at the most, where (at each iteration we add one new edge). Step 4a is , Steps 4b,c,d each have time complexity of (given that we store the lists of in- and out-neighbors for each vertex). Step 4e is . Thus, the resulting time complexity of both Step 4 and Algorithm 2 as a whole is .
The space complexity of Algorithm 2 is , since we need to store the constructed graph and some auxiliary 1-dimensional lists, the lengths of which do not exceed N for each.
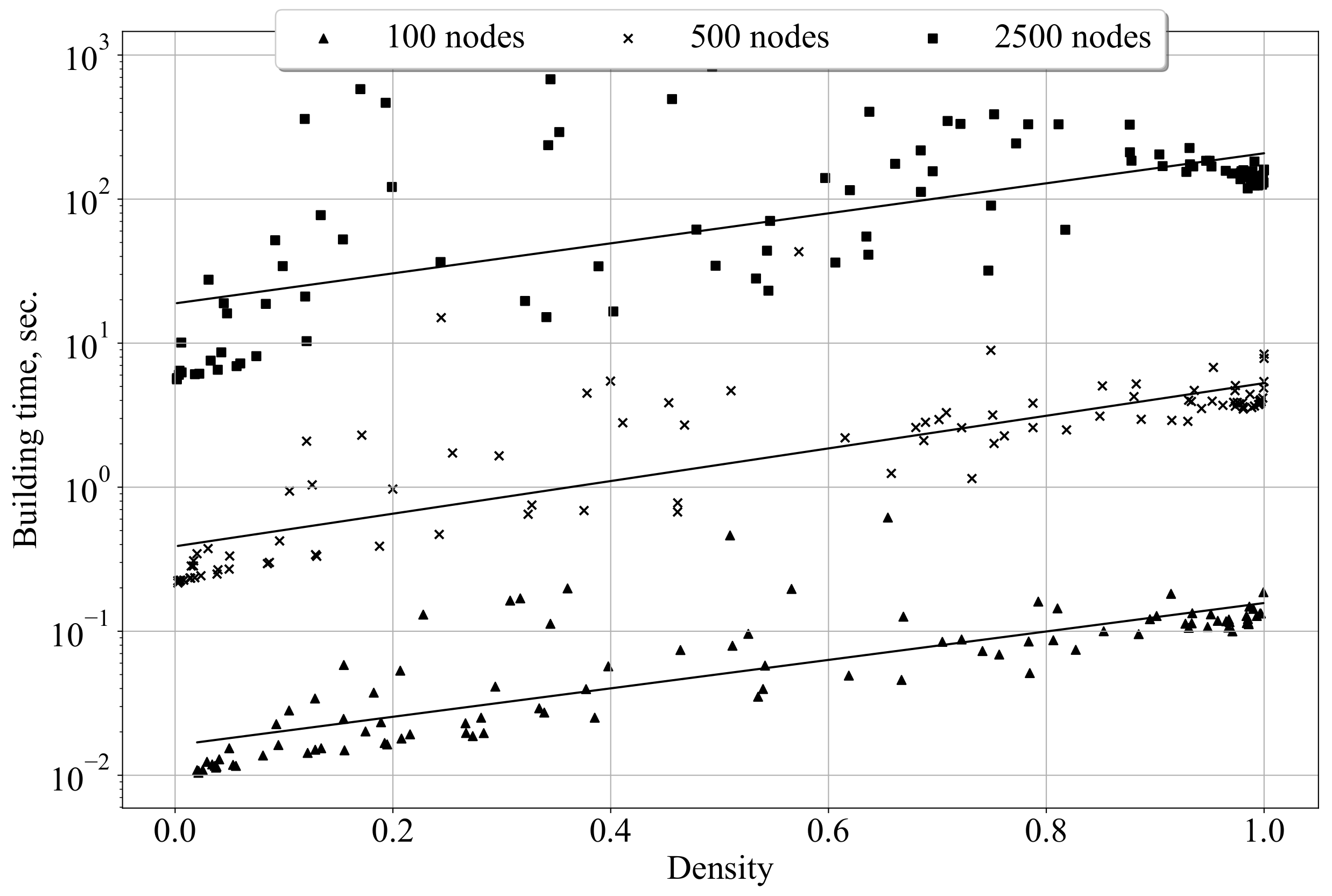
The actual scalability of the combination of Algorithms 1 and 2 is shown in
Figure 8. The computational experiments presented here and below were conducted using a PC with an Intel Core i7-7500U processor and 8 GB RAM. Although the time complexity of Algorithm 2 (in the worst case) is rather high–
, the experiments show that the Random Plots approach may be applied for the construction of ensembles of small- and medium-size random digraphs. To be applicable for generating ensembles of large graphs, the proposed method needs refinement.
5. Accuracy
In this section, we present and discuss the results of computational experiments aimed at estimating the accuracy of the aVDPs of the digraphs produced by Algorithm 2 with respect to the input rVDPs .
To evaluate how close the aVDPs of the digraphs produced by Algorithm 2 are to the corresponding rVDPs from Algorithm 1, we use the
norms
where
N is the number of vertices,
and
are the rVDPs produced by Algorithm 1,
and
are the in- and outdegrees of vertex
in the digraph produced by Algorithm 2, and
is the shuffling permutation from Step 2 of Algorithm 2.
Recall that the form of the rVDPs is defined by the parameters
, where
,
, and
are random (see Steps 2–5 of Algorithm 1) and
is computed uniquely (see Step 6 of Algorithm 1) to satisfy the equality (
6).
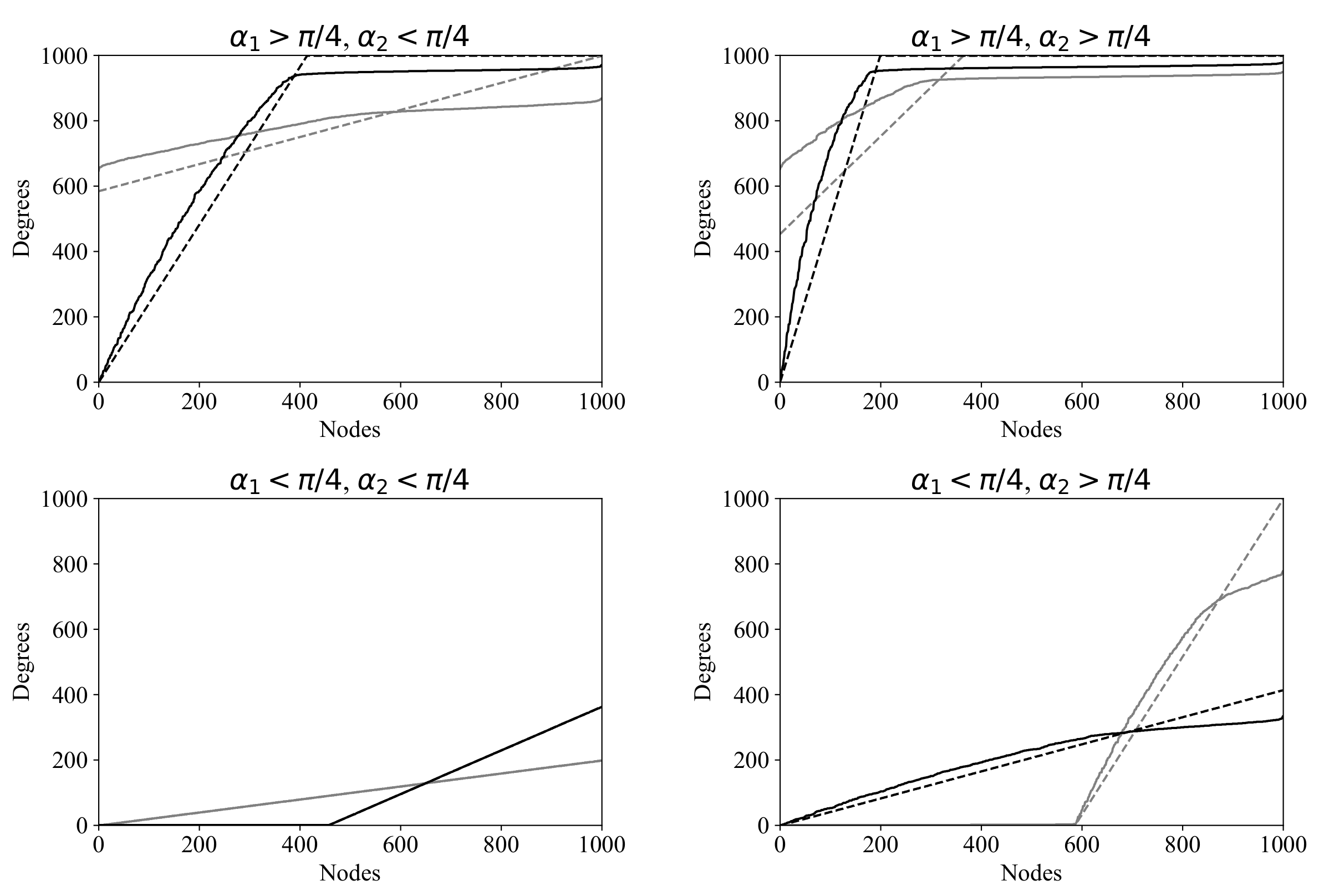
Figure 9 illustrates the differences between the rVDPs
and the corresponding aVDPs for several distinct choices of
(
is taken to be 0). Separate plots are shown depending on whether
and
are greater or less than
. One can see that the error grows as the plot approaches the upper bound. This is due to the following “smoothing effect”: (1) during the graph construction process, it becomes more and more difficult to find new neighbors for a high-degree vertex, as the number of vertices already connected to it increases; (2) for such vertices, Step 4b in Algorithm 2 and the subsequent resampling at Step 4a occur more and more often, pushing the new edges to less filled vertices; (3) as a result, the vertices with lower degrees in the rVDPs have greater degrees in the aVDPs, and vice versa. The smoothing effect is most pronounced at the steepest segments of the rVDP, where the plot approaches the ceiling of
neighbors.
Let us study the relationship between the coefficients
and the accuracy of the approximation in more detail.
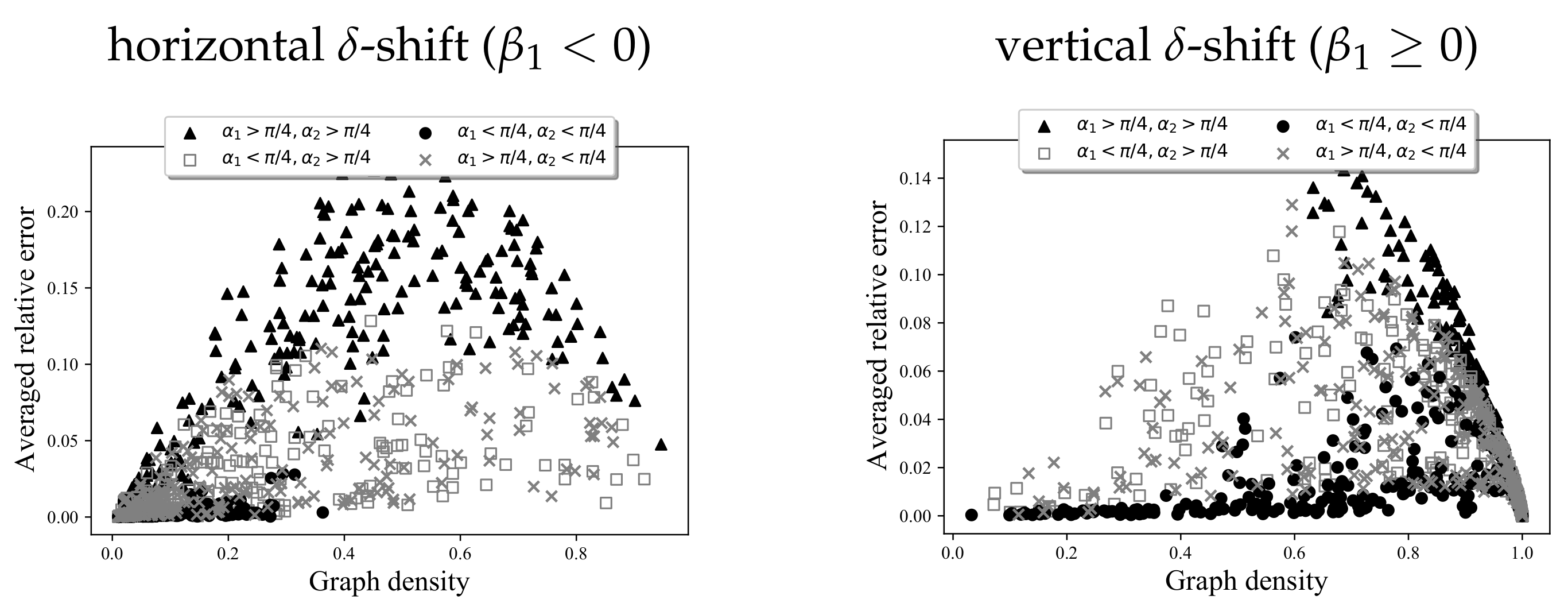
Figure 10 shows the dependence between the “steepness coefficients”
and
and the accuracy. The low-density graphs may be clearly divided into three types: low-steepness with higher accuracy (black circles), intermediate-steepness with average accuracy (gray squares and crosses), and high-steepness with lower accuracy (black triangles). The high-density graphs follow a similar, but messier, pattern. The peak error occurs at the intermediate values of graph density, which is unsurprising, since the structural variety of graphs with intermediate density is the highest, and the more variety there is, the more chances there are for the aVDPs to deviate from the rVDPs.
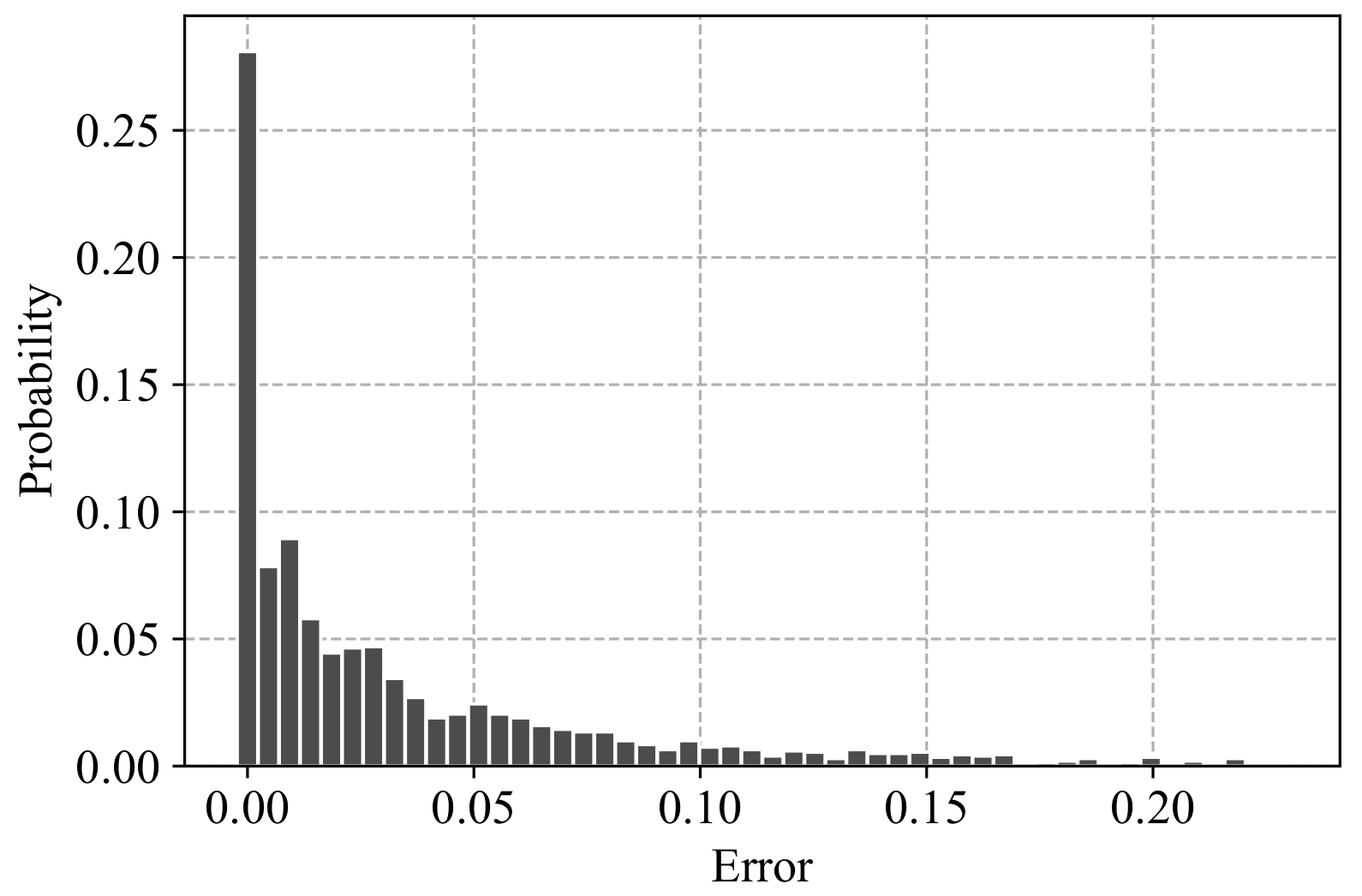
We conclude our analysis of the accuracy of Algorithm 2 with
Figure 11, which shows the distribution of the averaged relative errors (
9) for the 2000 graph generation experiments considered in
Figure 10.
6. Coverage
As discussed in the introduction, the main motivation for this paper is to maximize the diversity of the random graphs produced. The diversity of a set of graphs is a rather abstract notion. Our approach is to associate it with the diversity of the rVDPs and to construct the latter randomly in a certain sense. However, how effective is this approach?
First, let us see how expressive the method proposed in Algorithm 1 is, i.e., how closely the rVDPs produced by Algorithm 1 can simulate some real VDPs. The last column in
Table A1 shows that the most problematic VDPs have hinge points with average y-values (see
Figure 12). Probably the strongest effect this issue has on the rVDPs corresponding to SF graphs: Algorithm 1 is able to produce steeply concave rVDPs (if point
Q shifts towards
F (see
Figure 3), then according to (5), the vertex degrees on the segment
all are set to 1), but this is the only type of concave rVDP that Algorithm 1 can produce. Note that for VDPs with a hinge point whose y-value is close to either 1 or
N, Algorithm 1 is able to pick similar rVDPs (see, e.g., the fifth row in
Table A1).
The weakness outlined above can be overcome through the use of more sophisticated forms of rVDPs generated in Algorithm 1. For example, linear in Algorithm 1 can be replaced by piecewise linear functions with one or more breakpoints. Now, let us proceed to the practical assessment of the Random Plots method.
One natural way to measure its effectiveness is to proceed from the abstract notion of the diversity of a set of graphs to the tangible notion of the diversity of the specific scalar properties of the graphs. That is, if a set of graphs claims to be “diverse”, the graphs belonging to it should at least have diverse scalar properties.
In this section, we compare graph sets generated by our Random Plots (RP) model with sets generated by the three models described in the introduction—the Erdős–Rényi–Gilbert (ERG), scale-free (SF), and small-world (SW) models—in terms of seven well-known scalar properties of digraphs. The selection of these properties is contingent on two factors: (1) each property should be, to the greatest extent possible, typical of directed graphs; (2) each property should be applicable to the graphs produced by all four models considered (for example, we exclude properties defined only for weakly/strongly connected or acyclic digraphs).
In our experiments, we use each of the four models to generate 1000 digraphs on a set of 100 vertices. In each experiment, we work with a 2D parameter space where the first coordinate is the digraph density () and the second is the scalar property under consideration; each constructed graph defines a point in this parameter space. Since the proposed RP model is intended to produce maximally diverse random graphs, the cloud of 1000 points it generates in each of the 2D parameter spaces is expected to not only embrace the corresponding 1000-point clouds of the three reference models but also to cover some new areas of the parameter space.
The ERG and SF graphs are constructed using the corresponding Python 3 NetworkX 2.4 functions [
48,
49], while the SW graphs are constructed by [
50], which allows edge directions. The ERG graph generator takes the probability
for an edge to exist as a parameter (this value is the same for all the edges); in our experiments, we draw the value of
for each graph from the uniform distribution
. The SW graph generator takes the probability of rewiring,
, as a parameter, which, again, is chosen uniformly:
. The SF graph generator takes three basic parameters:
—the probability of adding a new node connected by an outgoing edge to an existing node chosen randomly according to the indegree distribution; —probability of adding an edge between two existing nodes, where one existing node is chosen randomly according [to] the indegree distribution, and the other is chosen randomly according to the outdegree distribution; and —the probability of adding a new node connected by an incoming edge to an existing node chosen randomly according to the outdegree distribution.
The SF graph generator requires , so we take and normalize: , , .
To compute the seven scalar graph properties, we applied ready-made Python 3 NetworkX 2.4 functions wherever possible. If there were no appropriate ones, we wrote our own code. The whole project for the computational experiments is written in Python 3 and is available at [
51].
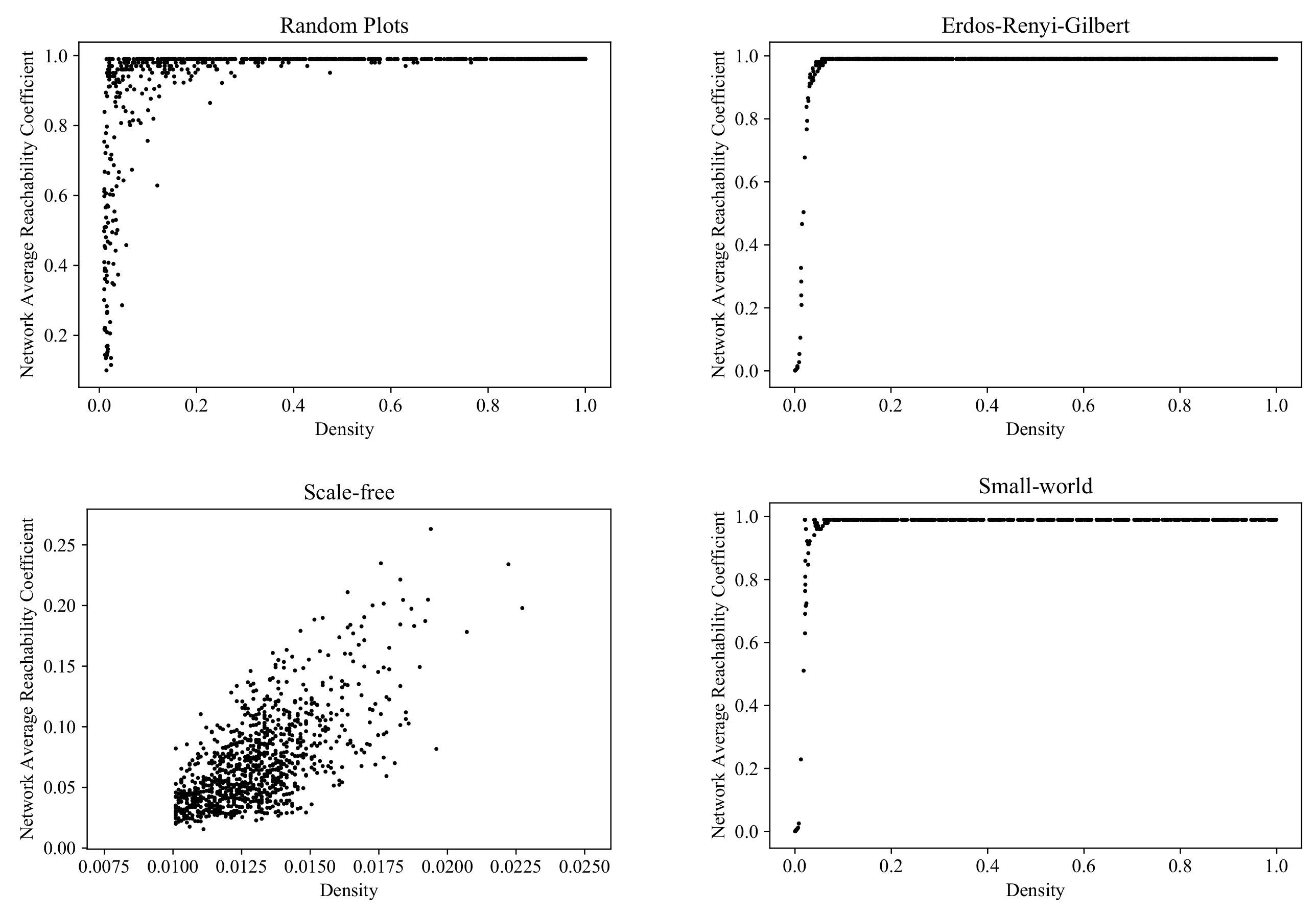
6.1. Average Reachability Coefficient
One of the basic characteristics of graphs as models of complex distributed systems is how tightly their elements are connected to each other. There are many ways to measure this; let us start with a rather simple and straightforward one, the average reachability coefficient. This is computed as follows: (1) for each vertex , find the proportion of the vertices that are reachable from v via a (directed) path in the graph ; (2) average this proportion over all the vertices .
Figure 13 shows the clouds generated by the RP, ERG, SF, and SW models in the parameter space
Density ×
Average reachability coefficient.
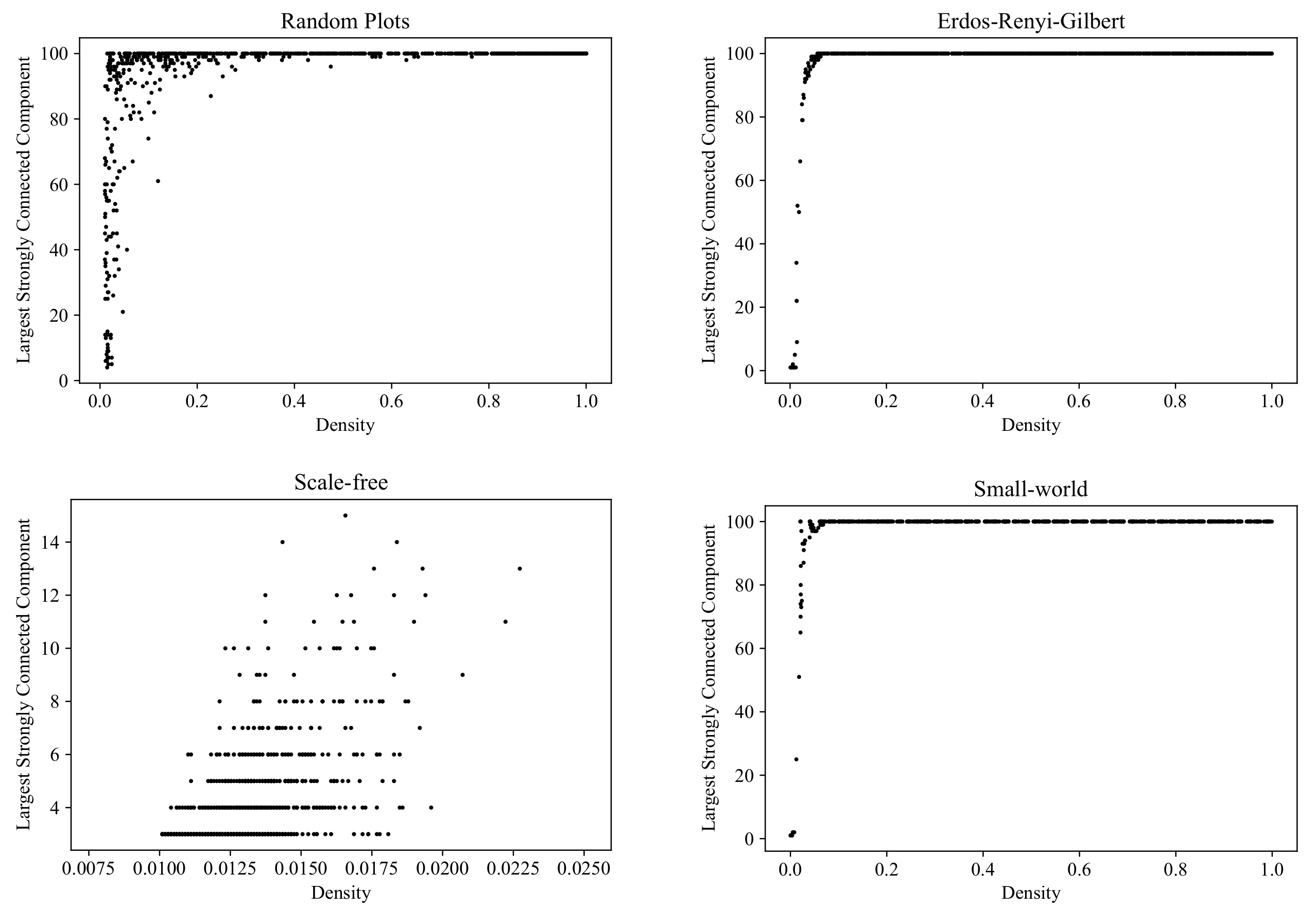
6.2. Size of the Largest Strongly Connected Component
Within a complex system, communities in which every member can reach all the other members are of particular practical interest. In digraph terms, such communities form
strongly connected components. In
Figure 14, we compare the graph sets generated by the RP, ERG, SF, and SW models in terms of the diversity of the size of the largest strongly connected component (computed with the NetworkX function [
52]).
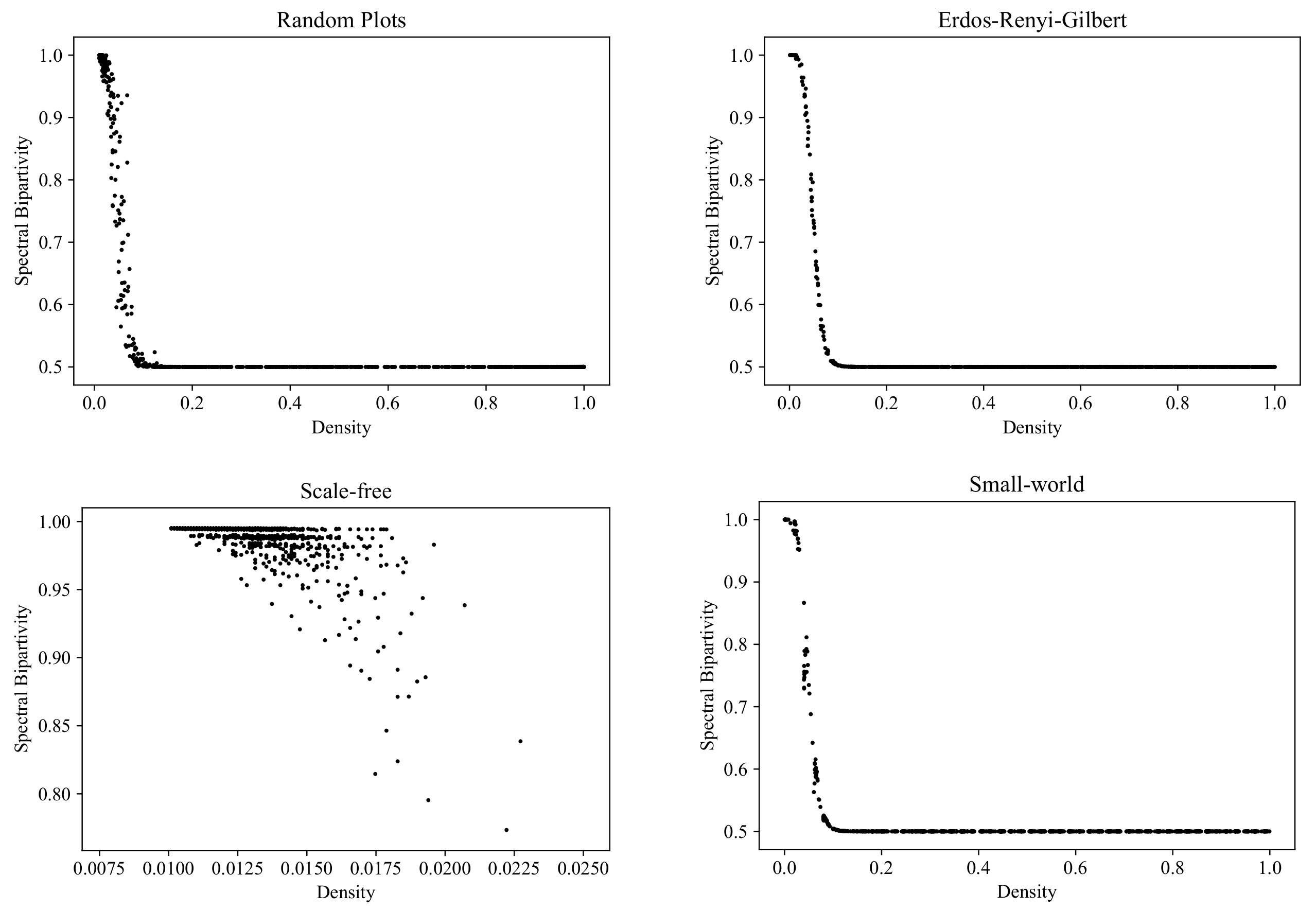
6.3. Spectral Bipartivity
A structure that is, in some sense, the opposite of a strongly connected component is a part of a bipartite graph: a part is a subset of vertices among which there are no connections.
Bipartite graphs are ubiquitous in graph theory; they are especially relevant to applications concerned with the modeling of interactions between two types of objects. In more or less homogeneous networks, bipartivity is often an unwanted property, indicating an absence of connections between the elements within some large groups and suggesting network misdesign [
53].
It is known that a graph is bipartite if and only if it contains no odd cycles. This criterion suggests a refinement of the yes/no notion of bipartivity to a kind of
bipartivity measure, given by the ratio of the number of even-length closed walks to the total number of closed walks in the network [
53].
Figure 15 shows the RP, ERG, SF, and SW clouds corresponding to bipartivity (computed with the NetworkX function [
54]).
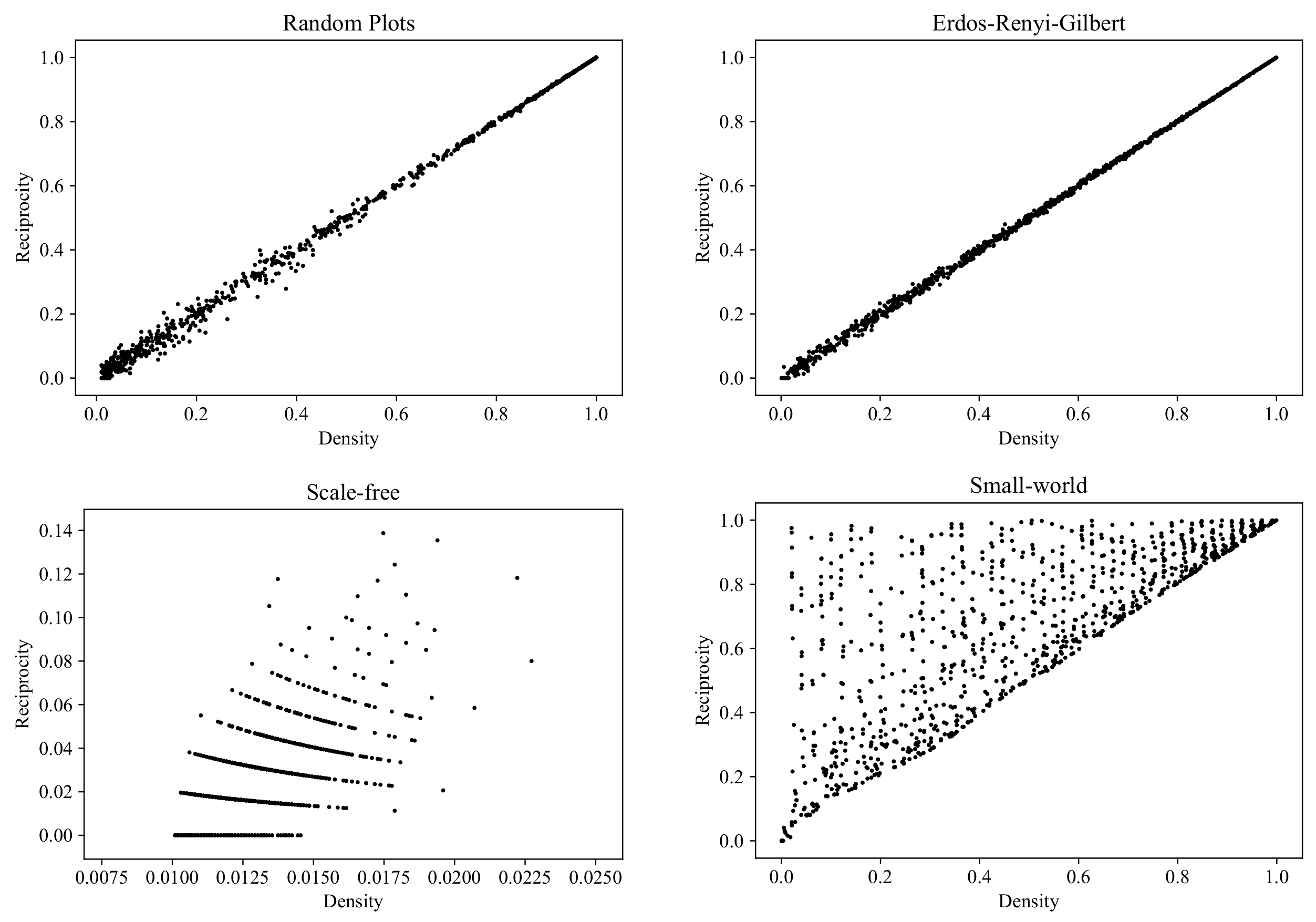
6.4. Reciprocity
Now, we proceed from the properties characterizing global structures in graphs to the properties of local vertex neighborhoods. One of the basic local connectivity properties is
reciprocity (also known as symmetry, in the context of binary relations in mathematics). The reciprocity of a digraph
is the proportion of edges for which there exists a reverse edge:
Reciprocity is the only test that our RP model fails to pass. As can be seen in
Figure 16, the SW model shows a much greater diversity in reciprocity values, for the following simple reason. By construction (see [
55]), the SW model initially generates a regular graph with all edges being reciprocal. If the rewiring probability
is equal to 0, then all of the edges remain reciprocal and the reciprocity of the graph is equal to one, independently of the density. If
, the graph turns into an ERG-type graph with the corresponding typical reciprocity values (see the upper right plot in
Figure 16). Since
is sampled uniformly from
, the SW model produces all possible intermediate values of reciprocity for any graph density.
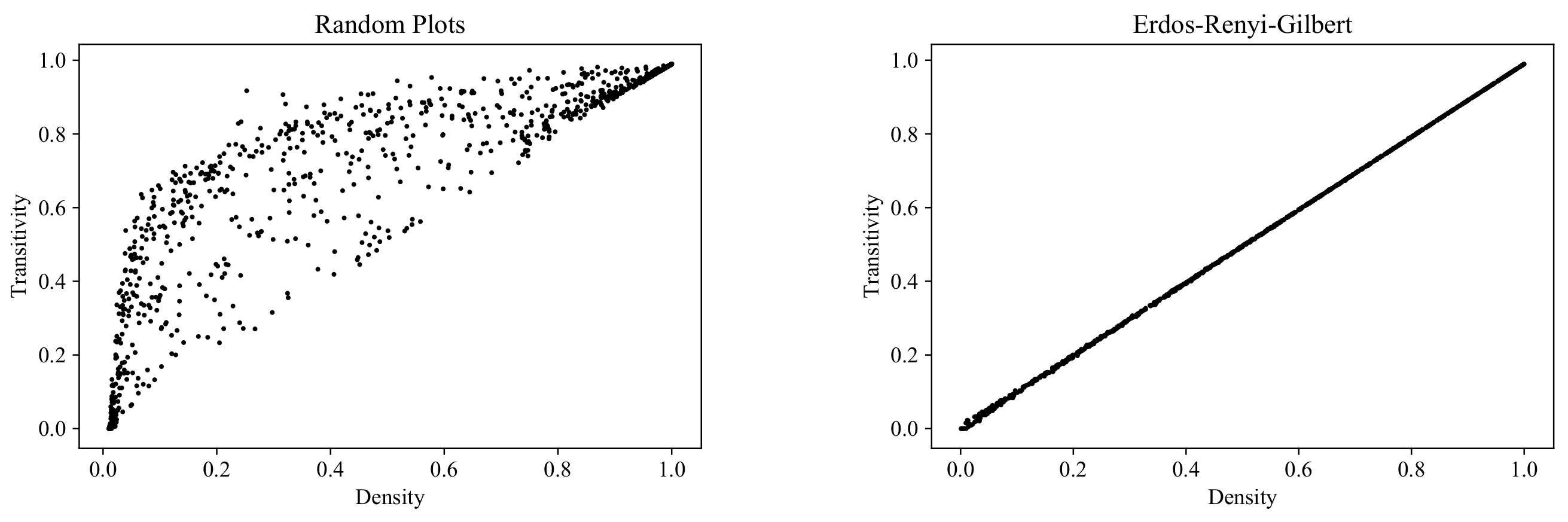
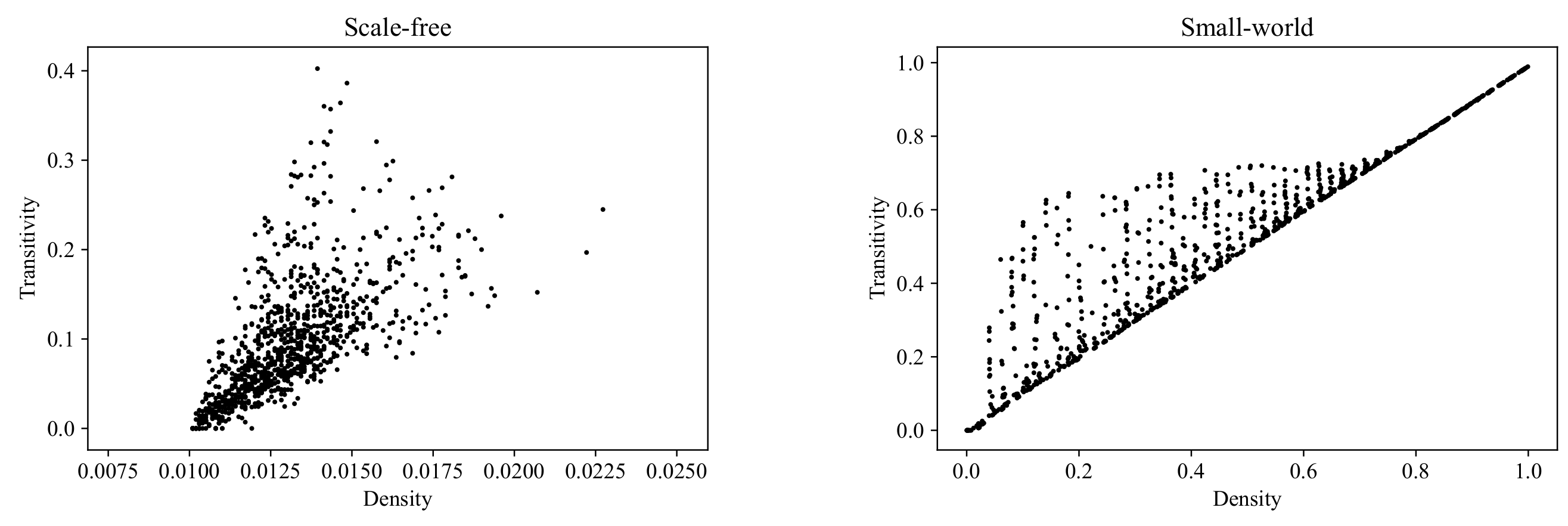
6.5. Transitivity
Another basic local connectivity property (as well as another property relevant to binary relations in mathematics) is
transitivity. By the
degree of transitivity of a labeled digraph
we can understand the proportion of the vertex triples for which the graph edges define a transitive relation:
Figure 17 shows the range of transitivity values at different values of graph density for the RP, ERG, SF, and SW models. The results here differ considerably from those for reciprocity: the RP cloud not only embraces the other three clouds, but also covers a new region in the area corresponding to high-density graphs.
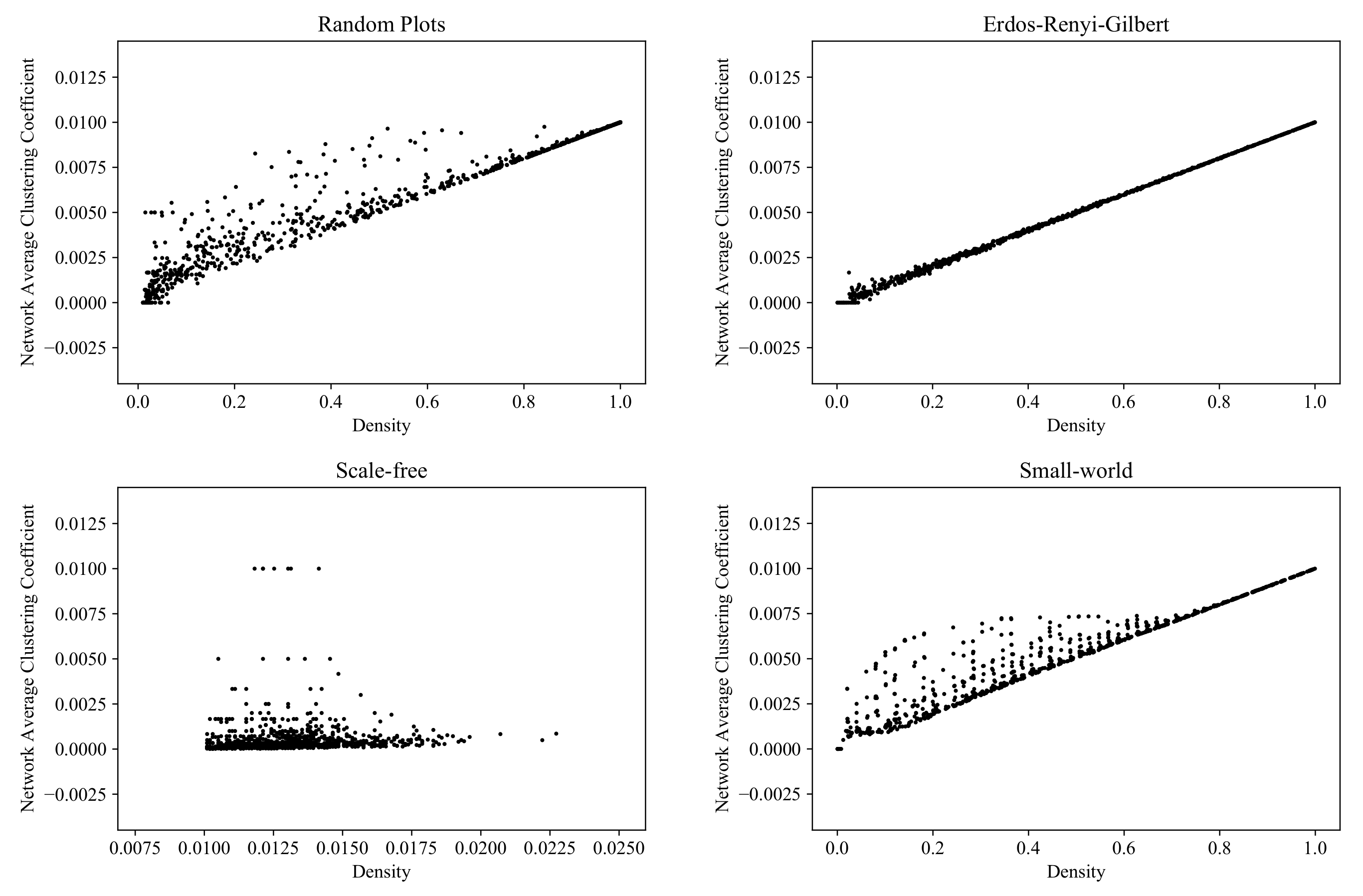
6.6. Average Clustering Coefficient
The last local property studied is the
local clustering coefficient, which shows the extent to which the vertices of a graph form tightly connected local communities. This measure is of particular importance in the study of social networks. The clustering coefficient of a vertex is equal to the proportion of existing edges between its neighbors, out of all the possible edges between these neighbors (see [
31] for the formal definition and an algorithm).
Figure 18 shows the distribution of the vertex-averaged local clustering coefficients for the RP, ERG, SF, and SW models (computed with the NetworkX function [
56]).
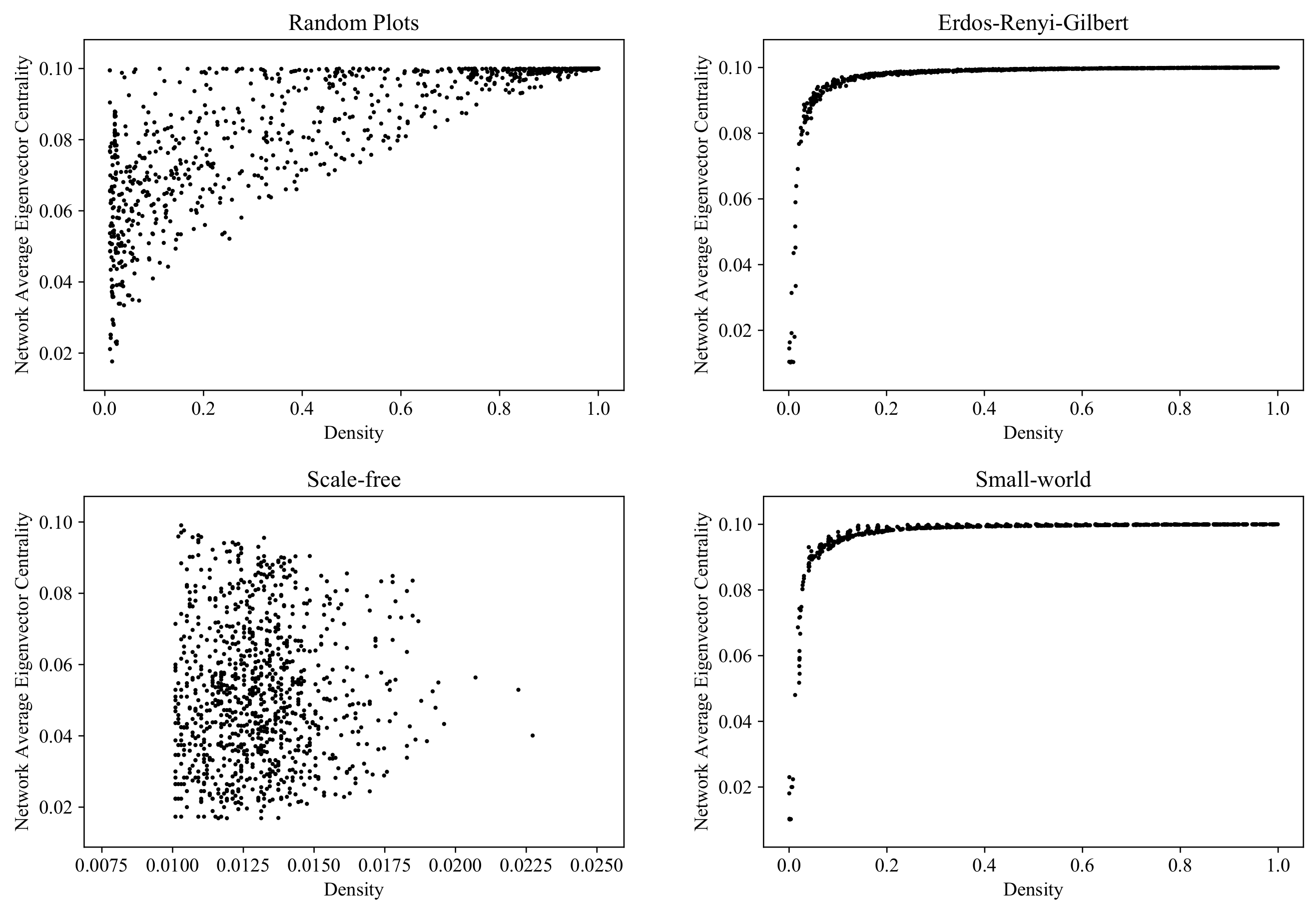
6.7. Average Eigenvector Centrality
The final scalar property considered is
eigenvector centrality, which measures the “importance” of each vertex in the network. Here, importance is calculated in terms of how many neighbors point to this vertex and how important these neighbors are by themselves (see [
33] for the details). One of the best-known applications of eigenvector centrality is web page scoring, which is widely used by search engines.
Figure 19 shows the distribution of vertex-averaged eigenvector centrality values for the graphs generated by the RP, ERG, SF, and SW models (computed with the NetworkX function [
57]).
6.8. Rumor Epidemic
The analysis of the diversity of static graph properties is not the only way to characterize the diversity of the graphs generated by a random graph model. Another indicator of the diversifying power of the model is the variety of states that a certain dynamic process takes in the graphs generated by the model. Choosing an overly restrictive model for a random graph may lead to a wrong conclusion of the form “the process always ends with YYY” or at least “the final state ZZZ never occurs”. Such narrowing conclusions may form a dangerous “false calm” opinion in many sensitive applications, one of which is epidemic modeling. Here, we consider an epidemic of rumors, where, in contrast to an epidemic of disease, each node can be both “spoiled” (with a rumor) and “cured” (with a contradiction) by each of its neighbors. We expect such a two-way process to be more sensitive to the structure of underlying graphs compared to the one-way dissemination of infection.
In our experiments, we generated 100 random graphs with 300 nodes for each of the 4 random graph models (RP, ERG, SF, SW) and each of the 5 graph density bins: . For each of the generated graphs, we repeated the following 10 times:
(1) Infect % of nodes with a rumor.
(2) Repeat the rumor-spreading process for 100 iterations. At each iteration, each spoiled node can infect each of its healthy neighbors with a probability of , and each healthy node can cure each of its spoiled neighbors with a probability of . The time is discrete, so the nodes do not change their state until the end of the iteration, e.g., if a healthy node is infected in the current iteration, it continues to act as a healthy node until the next iteration.
(3) At the end of the 100th iteration, capture one of the three possible states: all 300 nodes are spoiled; all are healthy; mixed—some spoiled, some healthy.
Thus, for each combination of values of the 5 input parameters (graph model, density quintile, ) we collected 1000 terminal states (100 graphs × 10 repetitions). In the computational experiments, we explored and . The experiments showed that:
(1) The terminal state “all spoiled” was never observed.
(2) In , all four random graph models showed some “all healed” and some “mixed” terminal states among the 1000 repetitions for all combinations of the other input parameters.
(3) For the graph models ERG, SF, and SW, the terminal state “mixed” was never observed in –.
(4) For the RP graph model in , both “all healthy” and “mixed” terminal states were observed for all combinations of , , and , except for the single combination , , , where all 1000 experiments ended in the “all healthy” state.
(5) For the RP graph model in , in 42 experiments out of 75, both “all healthy” and “mixed” terminal states were observed, and the remaining 33 experiments ended in the “all healthy” state.
(6) In all experiments with the RP graph model ended in the “all healthy” state.
By relying on the graph models ER, SF, or SW, the obtained results could suggest that the rumor epidemic ceases by the 100th iteration in all graphs, except for rather sparse ones; however, the RP model revealed many graphs with an average density, for which the epidemic was not over by the 100th iteration (see
Table 1).
7. Conclusions
In this paper, we proposed a method, which we call the Random Plots method, for constructing diverse sets of digraphs. These sets may be of practical use for modeling complex systems in which the structure of the connections between elements is not understood (either because this information is too difficult or expensive to obtain, or because it is not available in principle). In this situation, instead of trying to guess the unknown connection structure or averaging it by the maximum-entropy graph generation model, one can study a set of graphs covering “all sensible connection structures”.
The Random Plots method starts with the construction of a diverse set of pairs of piecewise linear nondecreasing plots, which is used as a reference vertex for in- and outdegree plots. At the second step, a digraph whose actual vertex in- and outdegree plots are similar to the reference plot is constructed.
To test the effectiveness of our approach, we compared the diversity of the graph sets produced by our model to that of the sets produced by some well-known graph generation models (the Erdős–Rényi–Gilbert, scale-free, and small-world models). To make the notion of “diversity” concrete, we studied each set with respect to several different scalar properties of graphs. Each graph gave rise to a point in a 2D space of the form Density × Scalar property, so we were able to understand the diversity of each graph set in terms of the given scalar property via the corresponding scatter of points in the plane. Our experiments showed that for 6 out of the 7 scalar properties considered, the Random Plots approach produced quite diverse clouds that not only embraced the clouds corresponding to the Erdős-Rényi-Gilbert, scale-free, and small-world models, but also covered some new areas in the 2D parameter spaces.
Another characteristic used to assess the diversity of graph ensembles was the variety of terminal states of a dynamic process—the rumor epidemic. Our experiments showed that for the graphs generated by the Erdős–Rényi–Gilbert, scale-free, and small-world models, the epidemic stopped by the end of the observation period in all cases, except for in sparse graphs. The proposed Random Plots model additionally revealed graphs of medium density for which the epidemic did not stop during the observation period. These results suggest that the Random Plots model may help, for example, to avoid dangerous “false calm” errors in the modeling of an epidemic in societies where the connection structure has been weakly studied.
The proposed approach could be improved in two ways: (1) by increasing the expressive power of Algorithm 1 (aimed, for example, at enhancing its ability to generate various SF-type graphs) and (2) reducing the time complexity of Algorithm 2. The first problem could be addressed by introducing more sophisticated rVDPs, for example, piecewise linear functions. To reduce the time complexity of graph construction, we propose that either the method of graph synthesis could be simplified (with a corresponding loss in accuracy) or we could proceed from simple graphs to multigraphs (which are considerably easier to generate). Further research could also be devoted to introducing a proper probability space for sample spaces consisting of random plots.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

































