5.1. Results on Imputation Accuracy and Model Prediction Accuracy
In this section, we present the results for the empirical data analysis based on the Airfoil dataset using the imputation and prediction accuracy measures described in
Section 2 for evaluation. We thereby focus on the Random Forest and the XGBoost prediction model. The results of the linear and the SGB model as well as the results for all other datasets are given in the supplement in [
44] (see Figures 1–19 therein) and summarized at the end of this section.
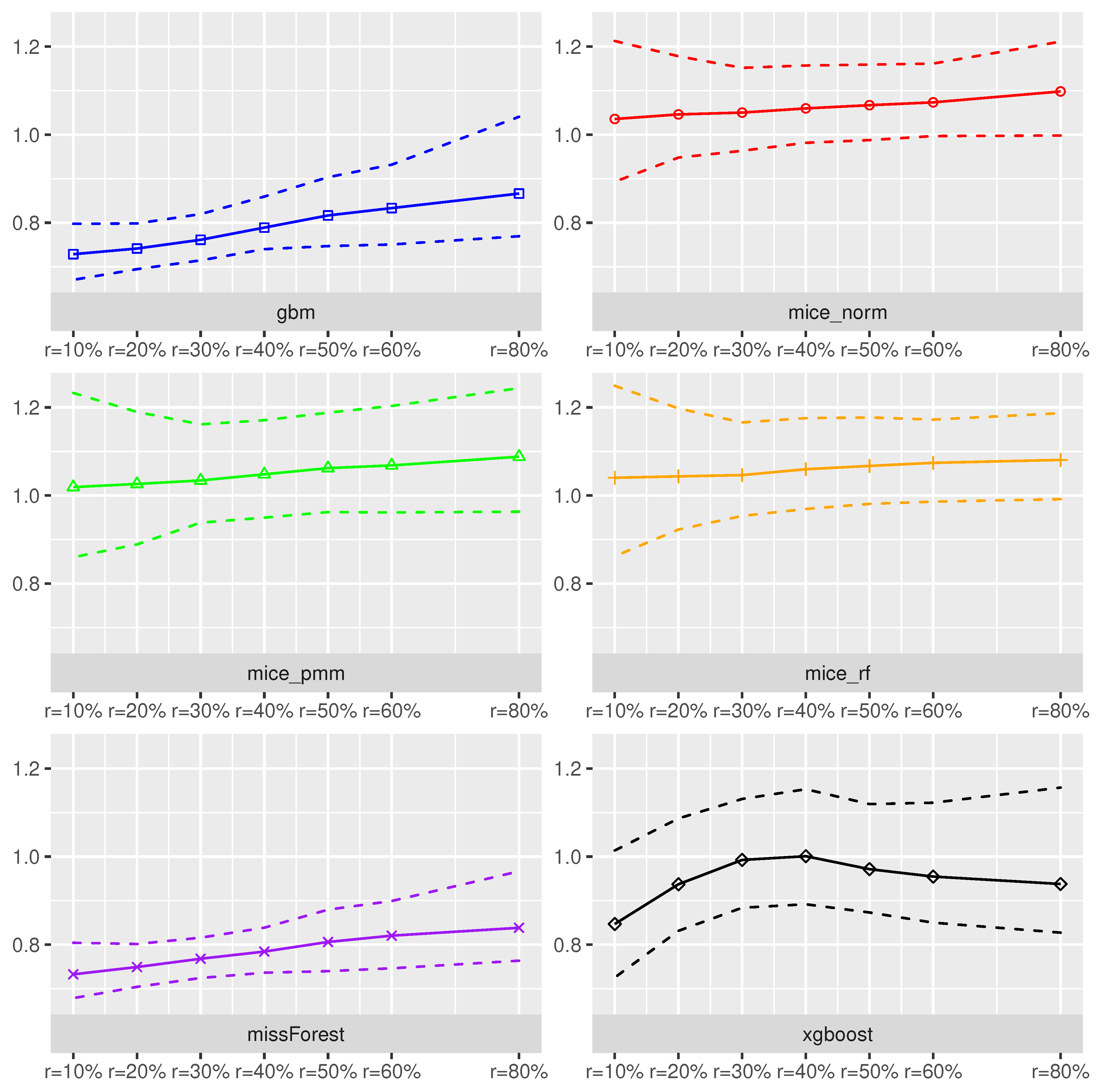
Random Forest as Prediction Model.Figure 1 and
Figure 2 summarize for each imputation method the imputation error (
) and the model prediction error (
) over
Monte-Carlo iterates using the Random Forest method for prediction on the imputed dataset. On average, the smallest imputation error measured with the
could be attained when using
missForest and the
gbm imputation method. In addition, these methods yielded low variations in
across the Monte-Carlo iterates. In contrast, the
mice_norm,
mice_pmm and
mice_rf behaved similarly resulting into largest
values across the different imputation schemes with an increased variation in
values.
The xgboost method performed slightly worse than missForest and gbm, when focusing on imputation accuracy. In addition, all methods seemed to be more or less robust towards an increased missing rate. Interesting is the fact that volatility decreases, as missing rates increase for the MICE procedures. The prediction accuracy measured in terms of cross-validated using the Random-Forest model was the lowest under the missForest, xgboost and gbm, which corresponds with the results.
As expected, the estimated suffered from missing covariates and the effect became worse with an increased missing rate. For example, an increase in the missing rate from 10% to 50% yielded an increase of the by 8.4%, while the realized an increase of 127.6%. Hence, model prediction accuracy heavily suffered from an increased amount of missing values, independent of the used imputation scheme. In addition, if the increases by units, it is expected that the will increase by 122.1%. Although congeniality was defined for valid statistical inference procedures, the effect of using the same method for imputation and prediction seemed to also have a positive effect on model prediction accuracy.
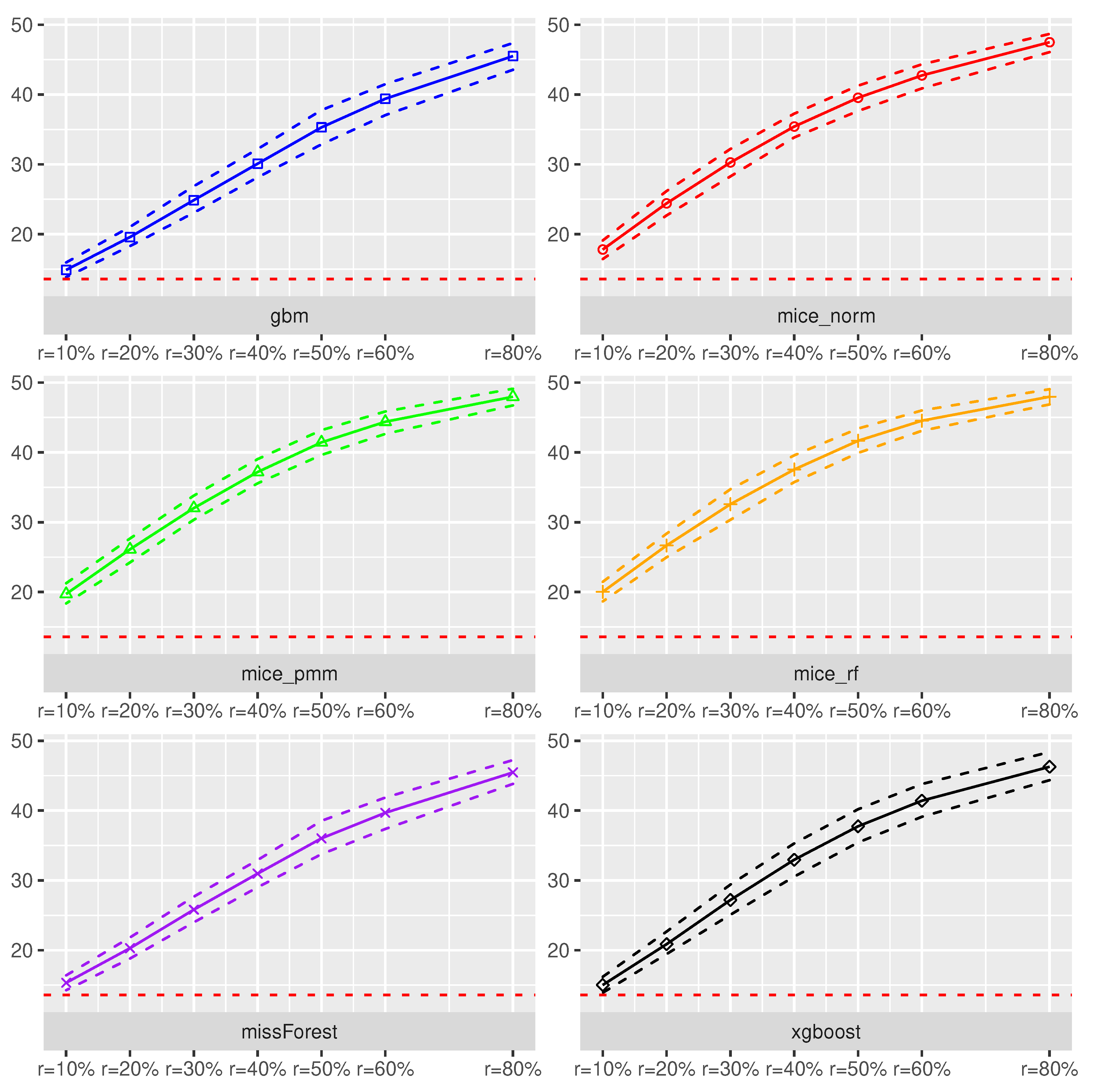
XGBoost as Prediction Model. In switching the prediction method to XGBoost, we realized an increase in model prediction accuracy for missing rates up to
as can be seen in
Figure 3. In addition, for those missing rates, the
xgboost imputation was competitive to the
missForest method but lost in accuracy for larger missing rates compared to the
missForest. Different from the Random Forest, the XGBoost prediction method was more sensitive towards an increased missing rate.
For example, an increase of the missing rate from 10% to 50% yields to an increase of the by 8.1%, while the suffered by an increase of 300% on average. In addition, an increase of the imputation error by points, can yield an average increase of prediction error by 189.9% Although under the completely observed framework the XGBoost method performed best in terms of estimated , the results indicate that missing covariates can disturb the ranking. In fact, for missing rates , the Random Forest exhibited a better prediction accuracy.
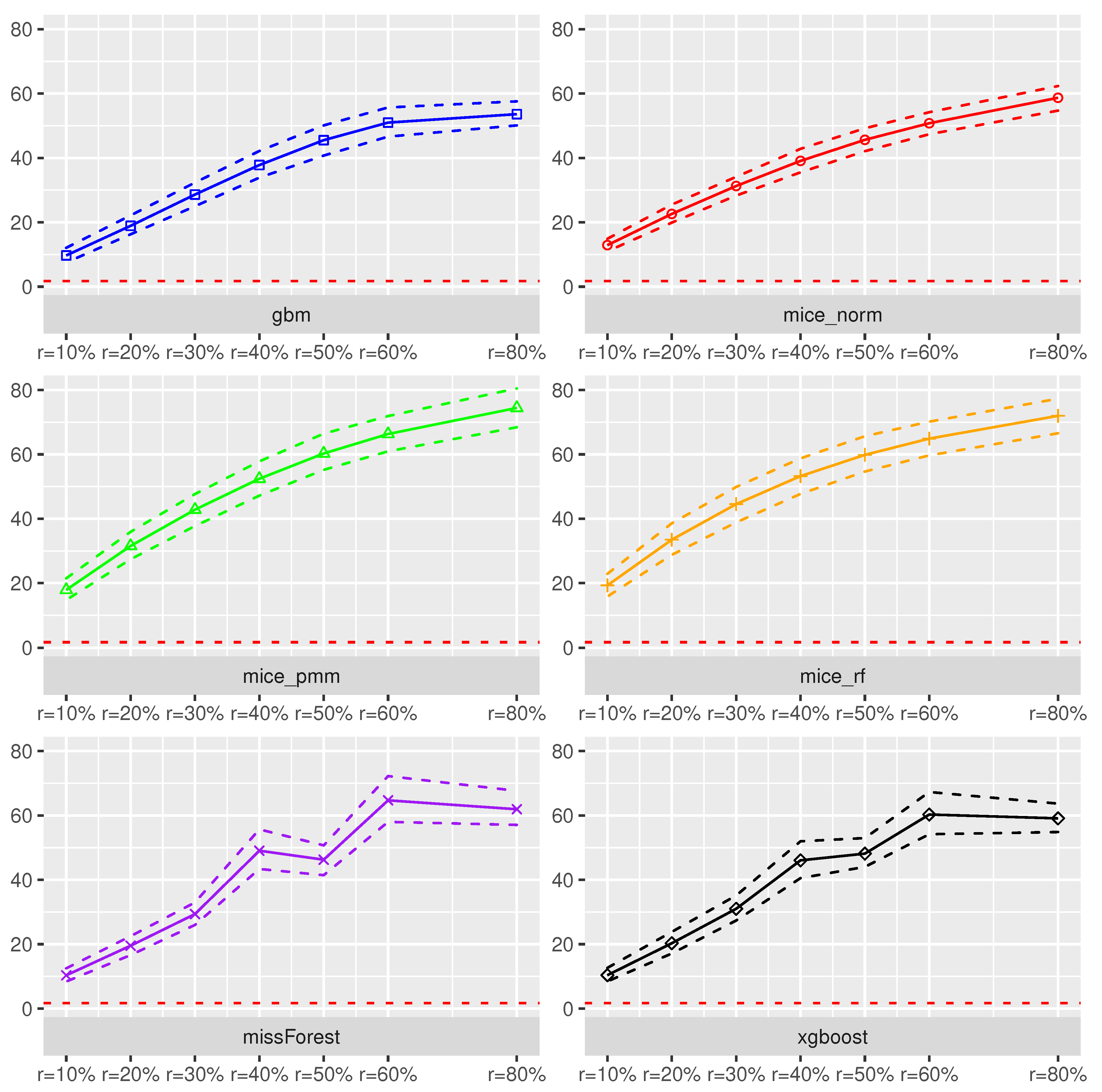
Other Prediction models. Using the linear model as the prediction model resulted in worse prediction accuracy with values ranging from 25 () to 45 (). For all missing scenarios, using the missForest or the gbm method for imputation before prediction with the linear model resulted in the lowest . The results for the SGB method were even worse with values between 80 and 99.
As a surprising result, the prediction accuracy measured in terms of cross-validated
decreased with an increasing missing rate. A potential source of this effect could be the general weakness of the SGB in the Airfoil dataset without any missing values. After inserting and imputing missing values, which can yield to distributional changes of the data, it seems that the SGB method benefits from these effects. However, model prediction accuracy is still not satisfactory, see
Figure 2 in the supplement in [
44].
Other Datasets. For the other datasets, similar effects were obtained. The Random Forest and the XGBoost showed the best prediction accuracy, see Figures 4–19 in the supplement in [
44]. Again, larger missing rates affected model prediction accuracy for the XGBoost method, but the Random Forest was more robust to them overcoming XGBoost prediction performance measured in cross-validated
for larger missing rates. Overall,
and cross-validated
seem to be positively associated to each other. Hence, more accurate imputation models seemed to yield better model prediction measured by
.
5.2. Results on Prediction Coverage and Length
Using the prediction intervals in
Section 2, we present coverage rates and interval lengths of point-wise prediction intervals in simulated data. Both quantities were computed using 1000 Monte-Carlo iterations with sample sizes
. The boxplots presented here (see
Figure 4,
Figure 5,
Figure 6 and
Figure 7) and in the supplement in [
44] (see Figures 19–30 therein) spread over the different covariance structures used during the simulation. Every row corresponds to one of the simulated missing rates
, while the columns reflect the different Random-Forest-based prediction intervals.
The left column summarizes the results for the Random-Forest-based prediction interval using empirical quantiles (
), the center column reflects the Random Forest prediction interval using the simple residual variance estimator on Out-of-Bag errors (
), while the right column summarizes the Random-Forest-based prediction interval using the weighted residual variance estimator (
). We shifted the results of
,
and the prediction interval based on the linear model to the supplement in [
44] (see Figures 19–22, 24, 26, 28 and 30 therein). Under the complete case scenarios, the latter methods did not show comparably well coverage rates as
,
and
. For imputed missing covariates, the methods performed with less accuracy in terms of correct coverage rates, when comparing them with
,
and
.
Although the interval lengths of , and the linear model were, on average smaller, the coverage rate was not sufficient to make them competitive with , and . For prediction intervals that underestimated the threshold in the complete case scenario, we observed more accurate coverage rates for larger missing rates. It seems that larger missing rates increase coverage rates for the and methods, independent of the used imputation scheme.
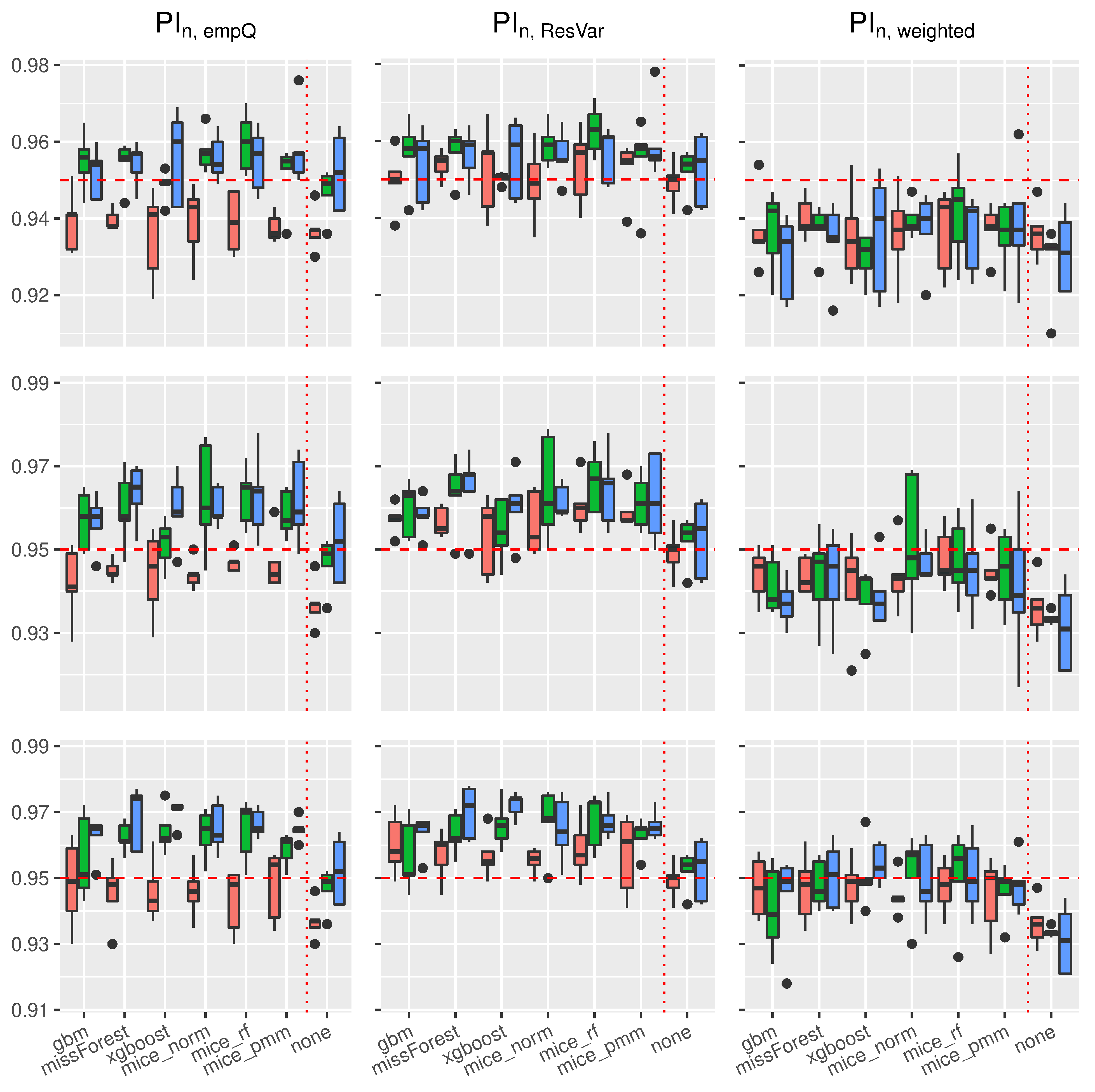
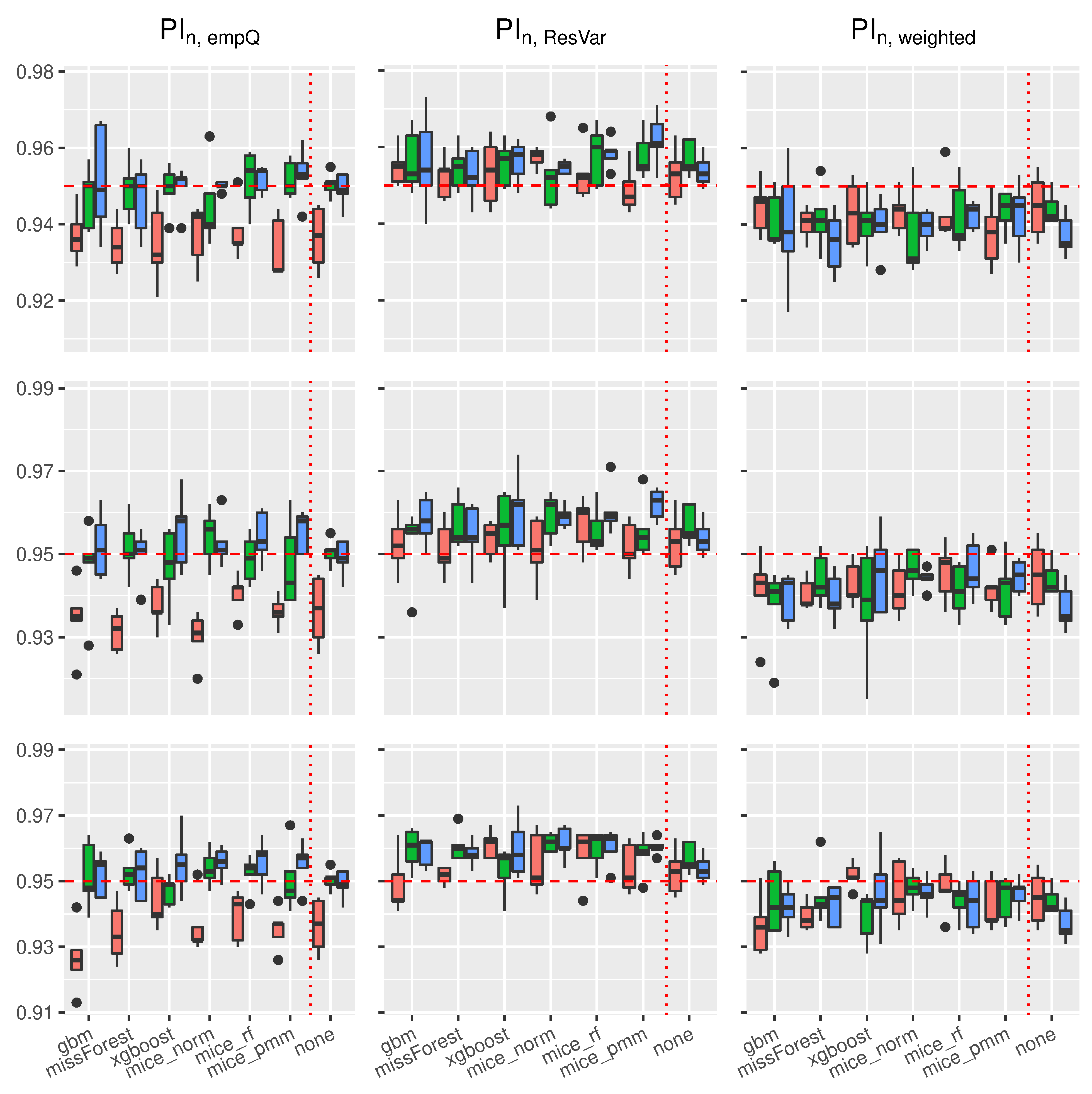
In
Figure 4, the boxplots of the linear regression model are presented. In general, the use of Random-Forest-based prediction intervals with empirical quantiles (
) or simple variance estimation (
) show competitive behavior in the complete case scenario. When considering the various imputation schemes, under the different missing rates, it can be seen that coverage rate slightly suffered compared to the complete case. To be more precise, larger missing rates lead to slightly larger coverage rates for
,
and
.
For the Random-Forest-based prediction interval with weighted residual variance, this effect seems to be positive, i.e., larger missing rates will lead to better coverage rates for . Comparing the results with the previous findings, we see that the xgboost yields, on average, the best coverage results across the different imputation schemes. While the MICE procedures did not reveal competitive performance in model prediction accuracy, the mice_norm method under the linear model performed similar to the missForest procedure when comparing coverage rates.
Figure 5 summarizes coverage rates of point-wise prediction intervals under the trigonometric model. Similar to the linear case, all three methods
,
and
yielded accurate coverage rates showing better approximation to the
threshold when the sample size increase under the complete observation case. On average, the
xgboost imputation method remains competitive compared to the other imputation methods.
Slightly different from the linear case, the
mice_norm approach gains in correct coverage rate approximation compared to the
missForest, together with the
mice_pmm approach. Nevertheless, the approximations between
mice_norm,
mice_pmm and
missForest are close to each other. As mentioned earlier,
turns more accurate in terms of correct coverage rates, when the missing rate increases. Similar results compared to the linear and trigonometric case could be obtained for the polynomial model and the non-continuous model. Boxplots of the coverage rates can be found in Figures 24 and 28 of the supplement in [
44].
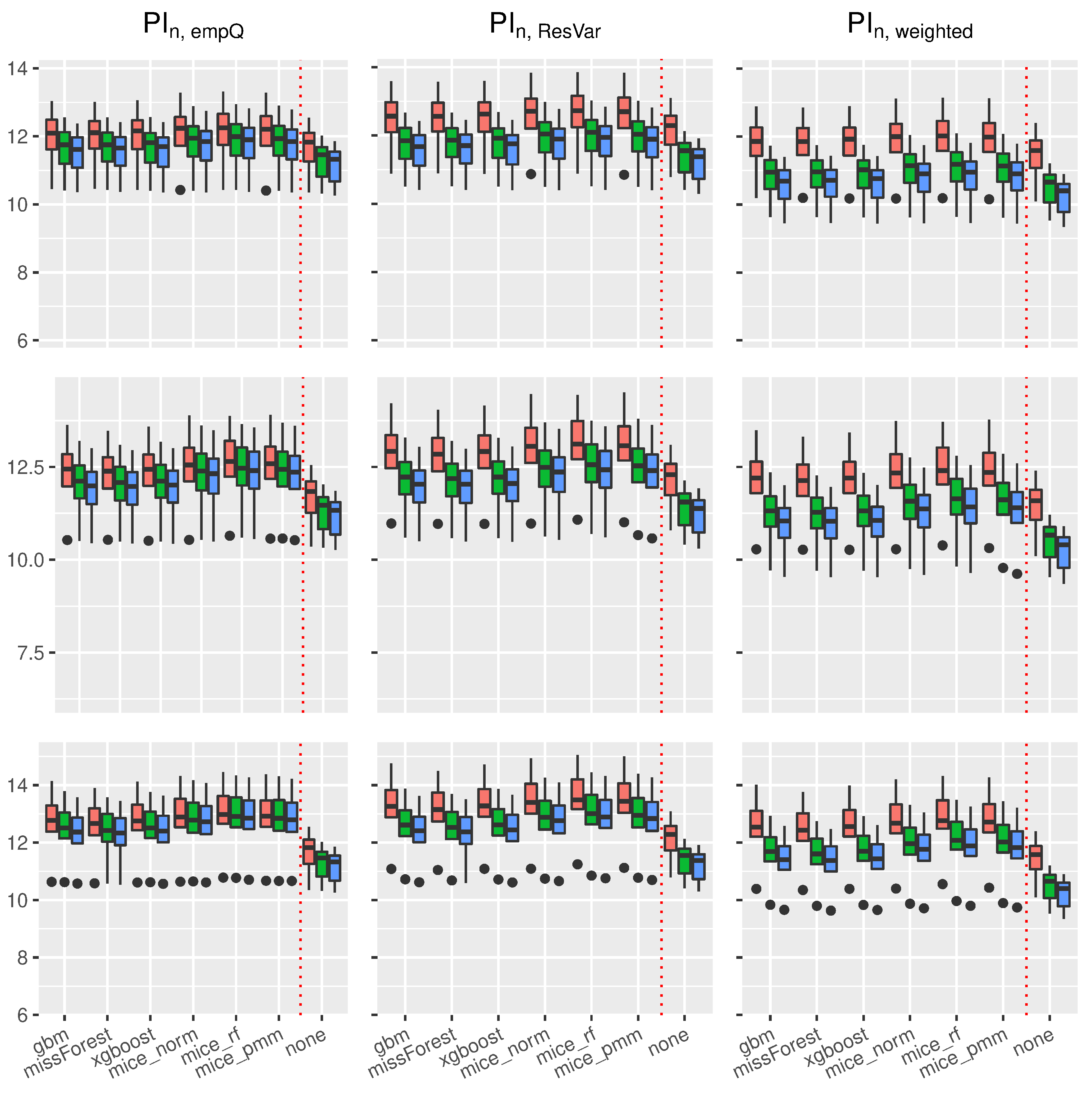
Regarding the length of the intervals for the linear model (see
Figure 6), the prediction interval
and the parametric interval
yielded similar interval lengths. Under imputed missing covariates, however, the
interval led to slightly smaller intervals than
. Nevertheless, the prediction interval based on the weighted residual variance estimator
had the smallest intervals on average. This comes with the cost of less accurate coverage rates as can be seen in
Figure 4.
In addition, independent of the used prediction interval, an increased missing rate yielded larger intervals making the learning methods, such as Random Forest, more insecure about future predictions. Regarding the used imputation method, almost all imputation methods resulted in similar interval lengths. On average, the missForest method had slightly smaller intervals comparable to the xgboost imputation.
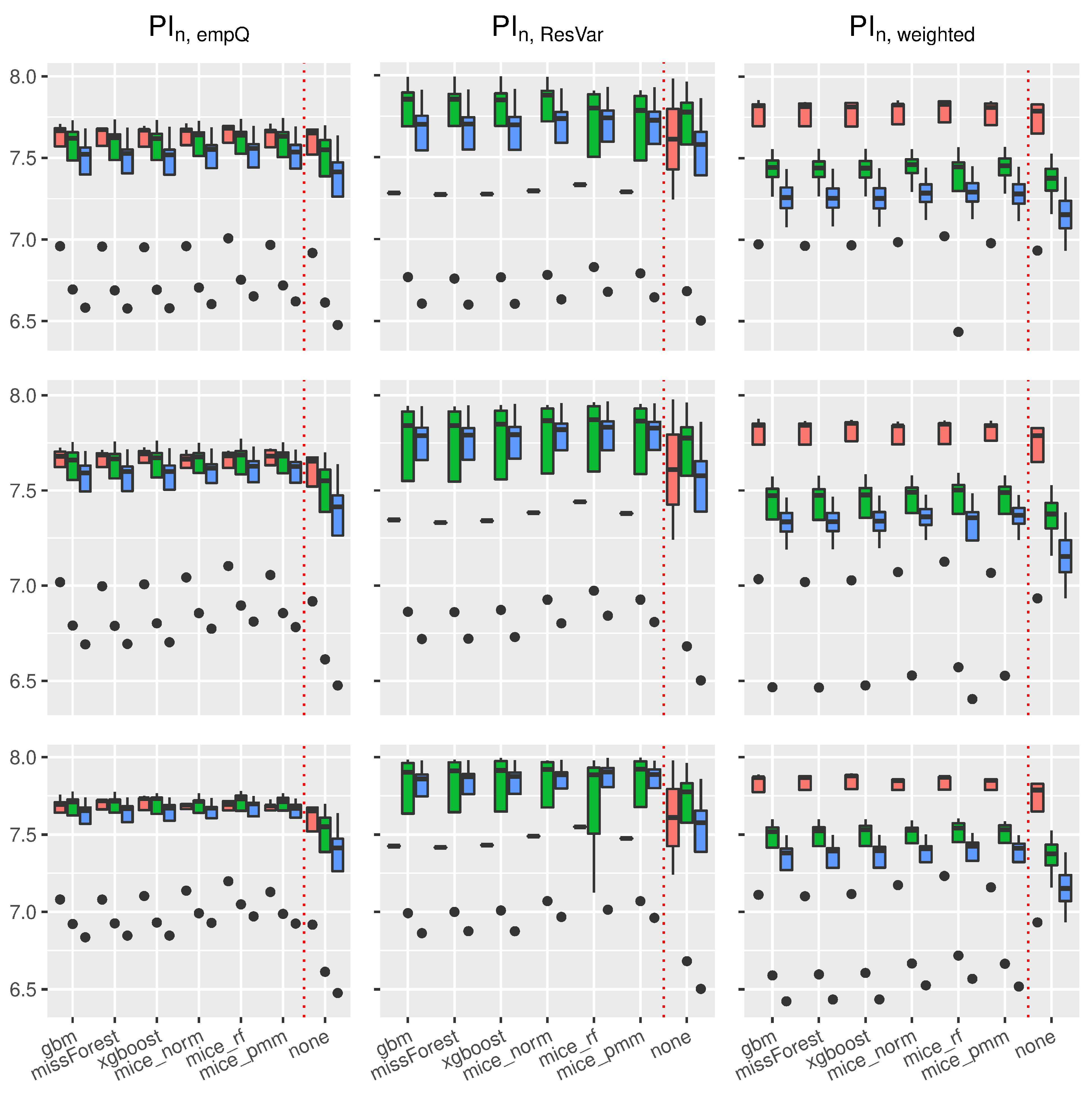
Similar results on prediction lengths were obtained with other models. Considering the trigonometric function as in
Figure 7, it can be seen that
results in slightly smaller intervals than
. However, the interval lengths for the empirical quantiles under the trigonometric model were more robust towards dependent covariates.
Comparably to the linear case,
results in the smallest interval lengths, but suffers from less accurate coverage. Furthermore, all imputation methods behave similar with respect to prediction interval lengths under the trigonometric case and other models (see Figures 21 and 22 in the supplement in [
44]). It can be seen that Random-Forest-based prediction intervals are, more or less, universally applicable to the different imputation schemes used in this scenario yielding similar interval lengths.
In summary, Random-Forest-based prediction intervals with imputed missing covariates yielded slightly wider intervals compared to the regression framework without missing values. For prediction intervals that underestimated the true coverage rate, such as , and , an increased missing rate had positive effects on the coverage rate. Overall, missForest and xgboost were competitive imputation schemes when considering accurate coverage rates and interval lengths using the and intervals. mice_norm resulted in similar, but slightly less accurate, coverage compared to missForest and xgboost.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






