1. Introduction
Metric learning and few-shot classification are two problem settings that test a model’s ability to classify data from classes that were unseen during training. Such problems are also commonly interpreted as testing meta-learning ability, since the process of constructing a classifier with examples from new classes can be seen as learning. Many recent works [
1,
2,
3,
4] tackled this problem by learning a continuous embedding (
) of datapoints. Such models compare pairs of embeddings using, e.g., Euclidean distance to perform nearest neighbor classification. However, it remains unclear whether such models effectively utilize the entire space of
.
Information theory provides a framework for effectively asking such questions about representation schemes. In particular, the information bottleneck principle [
5,
6] characterizes the optimality of a representation. This principle states that the optimal representation
is one that maximally compresses the input
X while also being predictive of labels
Y. From this viewpoint, we see that the previous methods which map data to
focus on being predictive of labels
Y without considering the compression of
X.
The degree of compression of an embedding is the number of bits it reflects about the original data. Note that for continuous embeddings, each of the n numbers in a n-dimensional embedding requires 32 bits. It is unlikely that unconstrained optimization of such embeddings use all of these bits effectively. We propose to resolve this limitation by instead using discrete embeddings and controlling the number of bits in each dimension via hyperparameters. To this end, we propose a model that produces discrete infomax codes (DIMCO) via an end-to-end learnable neural network encoder.
This work’s primary contributions are as follows. We usw mutual information as an objective for learning embeddings, and propose an efficient method of estimating it in the discrete case. We experimentally demonstrate that learned discrete embeddings are more memory and time-efficient compared to continuous embeddings. Our experiments also show that using discrete embeddings help meta-generalization by acting as an information bottleneck. We also provide theoretical support for this connection through an information-theoretic probably approximately correct (PAC) bound that shows the generalization properties of learned discrete codes.
This paper is organized as follows. We propose our model for learning discrete codes in
Section 2. We justify our loss function and also provide a generalization bound for our setup in
Section 3. We compare our method to related work in
Section 4, and present experimental results in
Section 5. Finally, we conclude our paper in
Section 6.
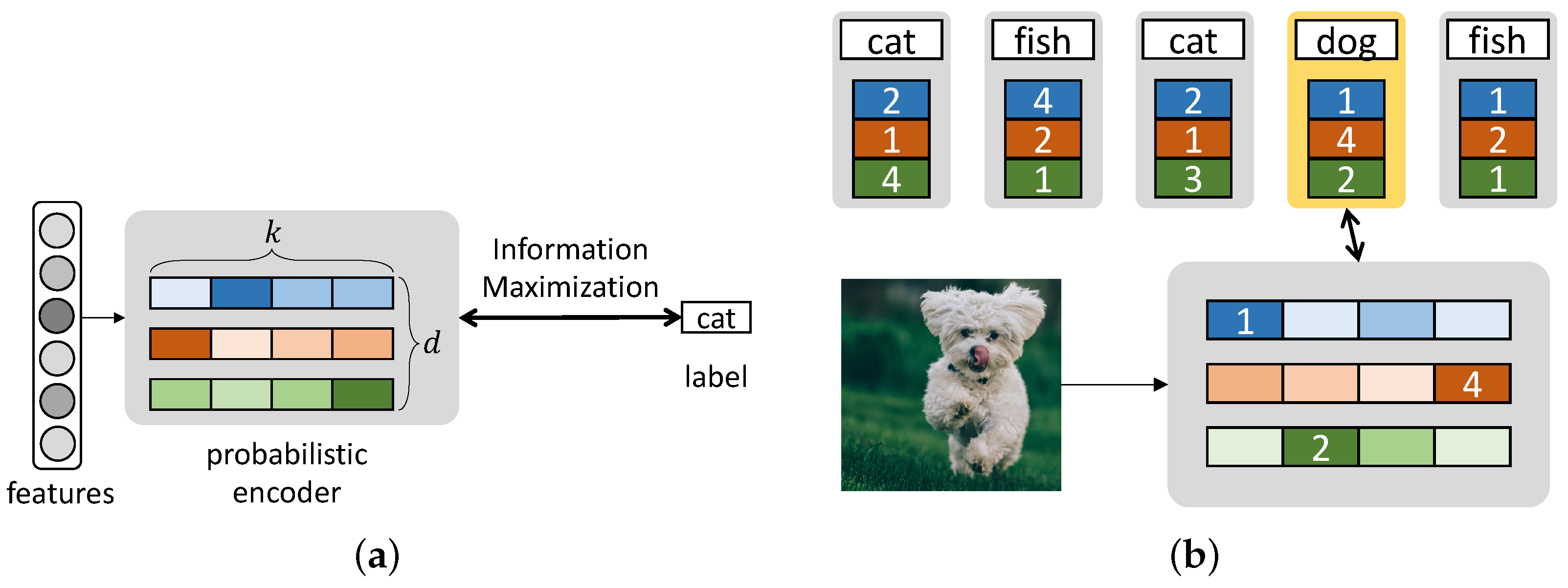
2. Discrete Infomax Codes (Dimco)
We present our model which produces discrete infomax codes (DIMCO). A deep neural network is trained end-to-end to learn
k-way
d-dimensional discrete codes that maximally preserve the information on labels. We outline the training procedure in Algorithm 1, and we also illustrate the overall structure in the case of 4-way 3-dimensional codes (
) in
Figure 1.
| Algorithm 1 DIMCO training procedure. |
|
2.1. Learnable Discrete Codes
Suppose that we are given a set of labeled examples, which are realizations of random variables , where X is the continuous input, and its corresponding discrete label is Y. Realizations of X and Y are denoted by and . The codebook serves as a compressed representation of X.
We constructed a probabilistic encoder —which is implemented by a deep neural network—that maps an input to a k-way d-dimensional code . That is, each entry of takes on one of k possible values, and the cardinality of is . Special cases of this coding scheme include k-way class labels (), d-dimensional binary codes (), and even fixed-length decimal integers ().
We now describe our model which produces discrete infomax codes. A neural network encoder
outputs
k-dimensional categorical distributions,
. Here,
represents the probability that output variable
i takes on value
j, consuming
as an input, for
and
. The encoder takes
as an input to produce logits
, which form a
matrix:
These logits undergo softmax functions to yield
Each example
in the training set is assigned a codeword
, each entry of which is determined by one of
k events that is most probable; i.e.,
While the stochastic encoder
induces a soft partitioning of input data, codewords assigned by the rule in (
3) yield a hard partitioning of
X.
2.2. Loss Function
The i-th symbol is assumed to be sampled from the resulting categorical distribution . We denote the resulting distribution over codes as and a code as . Instead of sampling during training, we use a loss function that optimizes the expected performance of the entire distribution .
We train the encoder by maximizing the mutual information between the distributions of codes
and labels
Y. The mutual information is a symmetric quantity that measures the amount of information shared between two random variables. It is defined as
Since
and
Y are discrete, their mutual information is bounded from both above and below as
. To optimize the mutual information, the encoder directly computes empirical estimates of the two terms on the right-hand side of (
4). Note that both terms consist of entropies of categorical distributions, which have the general closed-form formula:
Let
be the empirical average of
calculated using data points in a batch. Then,
is an empirical estimate of the marginal distribution
. We compute the empirical estimate of
by adding its entropy estimate for each dimension.
We can also compute
where
c is the number of classes. The marginal probability
is the frequency of class
y in the minibatch, and
can be computed by computing (
6) using only datapoints which belong to class
y. We emphasize that such a closed-form estimation of
is only possible because we are using discrete codes. If
were instead a continuous variable, we would only be able to maximize an approximation of
(e.g., Belghazi et al. [
7]).
We briefly examine the loss function (
4) to see why maximizing it results in discriminative
. Maximizing
encourages the distribution of all codes to be as dispersed as possible, and minimizing
encourages the average embedding of each class to be as concentrated as possible. Thus, the overall loss
imposes a partitioning problem on the model: it learns to split the entire probability space into regions with minimal overlap between different classes. As this problem is intractable for the large models considered in this work, we seek to find a local minima via stochastic gradient descent (SGD). We provide a further analysis of this loss function in
Section 3.1.
2.3. Similarity Measure
Suppose that all data points in the training set are assigned their codewords according to the rule (
3). Now we introduce how to compute a similarity between a query datapoint
and a support datapoint
for information retrieval or few-shot classification, where the superscripts
stand for query and support, respectively. Denote by
the codeword associated with
, constructed by (
3). For the test data
, the encoder yields
for
and
. As a similarity measure between
and
, we calculate the following log probability.
The probabilistic quantity (
8) indicates that
and
become more similar when the encoder’s output—when
is provided—is well aligned with
.
We can view our similarity measure (
8) as a probabilistic generalization of the Hamming distance [
8]. The Hamming distance quantifies the similarity between two strings of equal length as the number of positions at which the corresponding symbols are equal. As we have access to a distribution over codes, we use (
8) to directly compute the log probability of having the same symbol at each position.
We use (
8) as a similarity metric for both few-shot classification and image retrieval. We perform few-shot classification by computing a codeword for each class via (
3) and classifying each test image by choosing the class that has the highest value of (
8). We similarly perform image retrieval by mapping each support image to its most likely code (
3) and for each query image retrieving the support image that has the highest (
8).
While we have described the operations in (
3) and (
8) for a single pair
, one can easily parallelize our evaluation procedure, since it is an argmax followed by a sum. Furthermore,
typically requires little memory, as it consists of discrete values, allowing us to compare against large support sets in parallel. Experiments in
Section 5.4 investigate the degree of DIMCO’s efficiency in terms of both time and memory.
2.4. Regularizing by Enforcing Independence
One way of interpreting the code distribution
is as a group of
d separate code distributions
. Note that the similarity measure described in (
8) can be seen as ensemble of the similarity measures of these
d models. A classic result in ensemble learning is that using more diverse learners increases ensemble performance [
9]. In a similar spirit, we used an optional regularizer which promotes pairwise independence between each pair in these
d codes. Using this regularizer stabilized training, especially in more large-scale problems.
Specifically, we randomly sample pairs of indices
from
during each forward pass. Note that
and
are both categorical distributions with support size
, and that we can estimate the two different distributions within each batch. We minimize their KL divergence to promote independence between these two distributions:
We compute (
9) for a fixed number of random pairs of indices for each batch. The cost of computing this regularization term is miniscule compared to that of other components such as feeding data through the encoder.
Using this regularizer in conjunction with the learning objective (
4) yields the following regularized loss:
We fix
in all experiments, as we found that DIMCO’s performance was not particularly sensitive to this hyperparameter. We emphasize that while this optional regularizer stabilizes training, our learning objective is the mutual information
in (
4).
2.5. Visualization of Codes
In
Figure 2, we show images retrieved using our similarity measure (
8). We trained a DIMCO model (
,
) on the CIFAR100 dataset. We selected specific code locations and plotted the top 10 test images according to our similarity measure. For example, the top (leftmost) image for code
would be computed as
where
N is the number of test images.
We visualize two different combinations of codes in
Figure 2. The two examples show that using codewords together results in their respective semantic concepts being combined: (man + fish = man holding fish), (round + warm color = orange). While we visualized combinations of 2 codewords for clarity, DIMCO itself uses a combination of
d such codewords. The regularizer described in
Section 2.4 further encourages each of these
d codewords to represent different concepts. The combinatorially many (
) combinations in which DIMCO can assemble such codewords gives DIMCO sufficient expressive power to solve challenging tasks.
4. Related Work
Information bottleneck. DIMCO and Theorem 1 are both close in spirit to the information bottleneck (IB) principle [
5,
6,
16]. IB finds a set of compact representatives
while maintaining sufficient information about
Y, minimizing the following objective function:
subject to
. Equivalently, it can be stated that one maximizes
while simultaneously minimizing
. Similarly, our objective (
15) is information maximization
, and our bound (
A11) suggests that the representation capacity
should be low for generalization. In the deterministic information bottleneck [
17],
is replaced by
. These three approaches to generalization are related via the chain of inequalities
, which is tight in the limit of
being imcompressible. For any finite representation, i.e.,
, the limit
in (
18) yields a hard partitioning of
X into
N disjoint sets. DIMCO uses the infomax principle to learn
such representatives, which are arranged by
k-way
d-dimensional discrete codes for compact representation with sufficient information on
Y.
Regularizing meta-learning. Previous meta-learning methods have restricted task-specific learning by learning only a subset of the network [
18], learning on a low-dimensional latent space [
19], learning on a meta-learned prior distribution of parameters [
20], and learning context vectors instead of model parameters [
21]. Our analysis in Theorem 1 suggests that reducing the expressive power of the task-specific learner has a meta-regularizing effect, indirectly giving theoretical support for previous works that benefited from reducing the expressive power of task-specific learners.
Discrete representations. Discrete representations have been thoroughly studied in information theory [
22]. Recent deep learning methods directly learn discrete representations by learning generative models with discrete latent variables [
23,
24,
25] or maximizing the mutual information between representation and data [
26]. DIMCO is related to but differs from these works, as it assumes a supervised meta-learning setting and performs infomax using
labels instead of data.
A standard approach to learning label-aware discrete codes is to first learn continuous embeddings and then quantize it using an objective that maximally preserves its information [
27,
28,
29]. DIMCO can be seen as an end-to-end alternative to quantization which directly learns discrete codes. Jeong and Song [
30] similarly learns a sparse binary code in an end-to-end fashion by solving a minimum cost flow problem with respect to labels. Their method differs from DIMCO, which learns a dense discrete code by optimizing
, which we estimate with a closed-form formula.
Metric learning. The structure and loss function of DIMCO are closely related to those of metric learning methods [
1,
11,
12,
31]. We show that the loss functions of these methods can be seen as approximations of the mutual information (
) in
Section 2.2, and provide more in-depth exposition in
Appendix A. While all of these previous methods require a support/query split within each batch, DIMCO simply optimizes an information-theoretic quantity of each batch, removing the need for such structured batch construction.
Information theory and representation learning. Many works have applied information-theoretic principles to unsupervised representation learning: to derive an objective for GANs to learn disentangled features [
32], to analyze the evidence lower bound (ELBO) [
33,
34], and to directly learn representations [
35,
36,
37,
38,
39]. Related also are previous methods that enforce independence within an embedding [
40,
41]. DIMCO is also an information-theoretic representation learning method, but we instead assume a supervised learning setup where the representation must reflect ground-truth labels. We also used previous results from information theory to prove a generalization bound for our representation learning method.
6. Discussion
We introduced DIMCO, a model that learns a discrete representation of data by directly optimizing the mutual information with the label. To evaluate our initial intuition that shorter representations generalize better between tasks, we provided generalization bounds that get tighter as the representation gets shorter. Our experiments demonstrated that DIMCO is effective at both compressing a continuous embedding, and also at learning a discrete embedding from scratch in an end-to-end manner. The discrete embeddings of DIMCO outperformed recent continuous feature extraction methods while also being more efficient in terms of both memory and time. We believe the tradeoff between discrete and continuous embeddings is an exciting area for future research.
DIMCO was motivated by concepts such as the minimum description length (MDL) principle and the information bottleneck: compact task representations should have less room to overfit. Interestingly, Yin et al. [
55] reports that doing the opposite—regularizing the task-general parameters—prevents meta-overfitting by discouraging the meta-learning model from memorizing the given set of tasks. In future work, we will investigate the common principle underlying these seemingly contradictory approaches for a fuller understanding of meta-generalization.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}


