
Weakly Supervised Building Semantic Segmentation Based on Spot-Seeds and Refinement Process


Abstract
:1. Introduction
- We release novel spot annotation datasets for building semantic segmentation.
- We propose a method for generating high-quality pixel-level annotations using spot annotations and a graphical model based on superpixel segmentation.
- A novel iterative training framework is proposed in our work. The performance can be improved by refining the pixel level annotation and iteratively optimizing the segmentation network.
- According to experimental results on three public datasets, the proposed framework achieves a marked improvement in the building’s segmentation quality while reducing human labeling efforts.
2. Related Work
2.1. Semantic Segmentation of Remote-Sensing Images
2.2. Weakly Supervised Learning
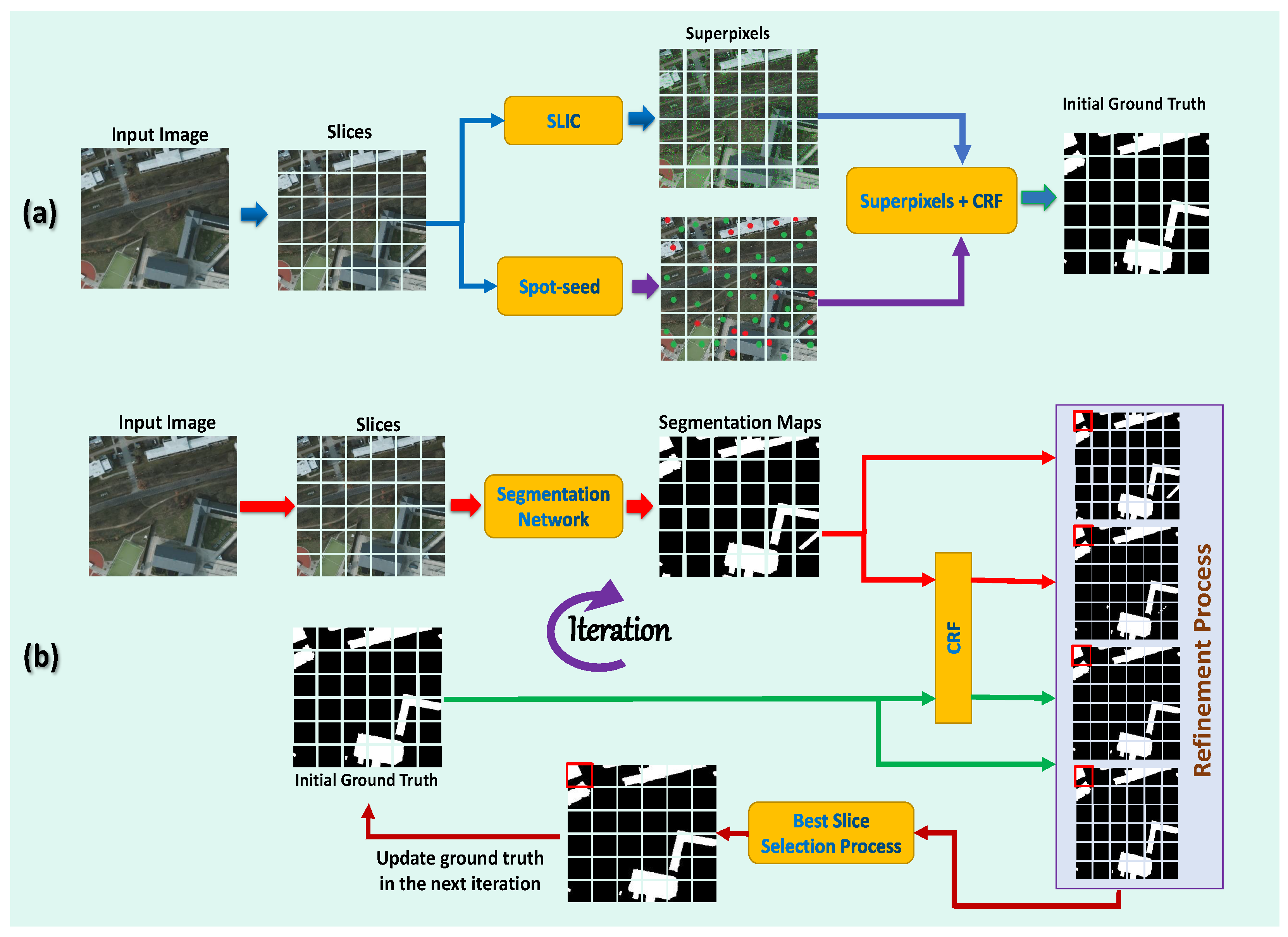
3. The Proposed Method
3.1. The Proposed Framework’s Architecture
3.2. Generating High-Quality Initial Ground Truths
3.3. Spot-Seeds Guided Superpixels-CRF Model for Object Region Supplement
3.4. Network Training
3.5. The Proposed Refinement Process

4. Experimental Results and Analysis
4.1. Dataset Preprocessing
4.2. Evaluation
4.3. Comparison with Other Methods on ISPRS Potsdam Challenge Dataset (Potsdam) Dataset
4.4. Comparison with Other Methods on WHU Building Dataset
4.5. Comparison with Other Methods on Vaihingen Dataset
5. Ablation Study
5.1. The Influence of Backbone Networks
5.2. The Influence of Refinement Process
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhang, X.; Yang, Y.; Li, Z.; Ning, X.; Qin, Y.; Cai, W. An Improved Encoder-Decoder Network Based on Strip Pool Method Applied to Segmentation of Farmland Vacancy Field. Entropy 2021, 23, 435. [Google Scholar] [CrossRef]
- Li, D.; Shen, X.; Yu, Y.; Guan, H.; Li, J.; Zhang, G.; Li, D. Building Extraction from Airborne Multi-Spectral LiDAR Point Clouds Based on Graph Geometric Moments Convolutional Neural Networks. Remote Sens. 2020, 12, 3186. [Google Scholar] [CrossRef]
- Peng, B.; Al-Huda, Z.; Xie, Z.; Wu, X. Multi-scale region composition of hierarchical image segmentation. Multimed. Tools Appl. 2020, 79, 32833–32855. [Google Scholar] [CrossRef]
- Al-Huda, Z.; Peng, B.; Yang, Y.; Ahmed, M. Object scale selection of hierarchical image segmentation using reliable regions. In Proceedings of the 2019 IEEE 14th International Conference on Intelligent Systems and Knowledge Engineering (ISKE), Dalian, China, 14–16 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1081–1088. [Google Scholar]
- Algabri, R.; Choi, M.T. Deep-learning-based indoor human following of mobile robot using color feature. Sensors 2020, 20, 2699. [Google Scholar] [CrossRef]
- Algabri, R.; Choi, M.T. Target Recovery for Robust Deep Learning-Based Person Following in Mobile Robots: Online Trajectory Prediction. Appl. Sci. 2021, 11, 4165. [Google Scholar] [CrossRef]
- Yu, B.; Yang, L.; Chen, F. Semantic segmentation for high spatial resolution remote sensing images based on convolution neural network and pyramid pooling module. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3252–3261. [Google Scholar] [CrossRef]
- Ok, A.O. Automated detection of buildings from single VHR multispectral images using shadow information and graph cuts. ISPRS J. Photogramm. Remote Sens. 2013, 86, 21–40. [Google Scholar] [CrossRef]
- Ghanea, M.; Moallem, P.; Momeni, M. Building extraction from high-resolution satellite images in urban areas: Recent methods and strategies against significant challenges. Int. J. Remote Sens. 2016, 37, 5234–5248. [Google Scholar] [CrossRef]
- Gao, H.; Tang, Y.; Jing, L.; Li, H.; Ding, H. A novel unsupervised segmentation quality evaluation method for remote sensing images. Sensors 2017, 17, 2427. [Google Scholar] [CrossRef]
- Ahmadi, S.; Zoej, M.V.; Ebadi, H.; Moghaddam, H.A.; Mohammadzadeh, A. Automatic urban building boundary extraction from high resolution aerial images using an innovative model of active contours. Int. J. Appl. Earth Obs. Geoinf. 2010, 12, 150–157. [Google Scholar] [CrossRef]
- Sun, Y.; Zhang, X.; Zhao, X.; Xin, Q. Extracting building boundaries from high resolution optical images and LiDAR data by integrating the convolutional neural network and the active contour model. Remote Sens. 2018, 10, 1459. [Google Scholar] [CrossRef] [Green Version]
- Vakalopoulou, M.; Karantzalos, K.; Komodakis, N.; Paragios, N. Building detection in very high resolution multispectral data with deep learning features. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1873–1876. [Google Scholar]
- Yang, H.L.; Yuan, J.; Lunga, D.; Laverdiere, M.; Rose, A.; Bhaduri, B. Building extraction at scale using convolutional neural network: Mapping of the united states. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2600–2614. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual attention network for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3156–3164. [Google Scholar]
- Jégou, S.; Drozdzal, M.; Vazquez, D.; Romero, A.; Bengio, Y. The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1175–1183. [Google Scholar]
- Al-Huda, Z.; Peng, B.; Yang, Y.; Algburi, R.N.A.; Ahmad, M.; Khurshid, F.; Moghalles, K. Weakly supervised semantic segmentation by iteratively refining optimal segmentation with deep cues guidance. Neural Comput. Appl. 2021, 33, 9035–9060. [Google Scholar] [CrossRef]
- Krähenbühl, P.; Koltun, V. Efficient inference in fully connected crfs with gaussian edge potentials. In Proceedings of the Advances in Neural Information Processing Systems, Granada, Spain, 12–14 December 2011; pp. 109–117. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Handa, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for robust semantic pixel-wise labelling. arXiv 2015, arXiv:1505.07293. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Yang, D.; Liu, G.; Ren, M.; Xu, B.; Wang, J. A Multi-Scale Feature Fusion Method Based on U-Net for Retinal Vessel Segmentation. Entropy 2020, 22, 811. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- Zheng, S.; Jayasumana, S.; Romera-Paredes, B.; Vineet, V.; Su, Z.; Du, D.; Huang, C.; Torr, P.H. Conditional random fields as recurrent neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Cambridge, MA, USA, 20–23 June 2015; pp. 1529–1537. [Google Scholar]
- Wang, S.; Sun, G.; Zheng, B.; Du, Y. A Crop Image Segmentation and Extraction Algorithm Based on Mask RCNN. Entropy 2021, 23, 1160. [Google Scholar] [CrossRef]
- Saiz-Vivó, M.; Colomer, A.; Fonfría, C.; Martí-Bonmatí, L.; Naranjo, V. Supervised Domain Adaptation for Automated Semantic Segmentation of the Atrial Cavity. Entropy 2021, 23, 898. [Google Scholar] [CrossRef] [PubMed]
- Bearman, A.; Russakovsky, O.; Ferrari, V.; Li, F.F. What’s the Point: Semantic Segmentation with Point Supervision. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Jing, L.; Chen, Y.; Tian, Y. Coarse-to-Fine Semantic Segmentation From Image-Level Labels. IEEE Trans. Image Process. 2019, 29, 225–236. [Google Scholar] [CrossRef] [Green Version]
- Ahn, J.; Kwak, S. Learning Pixel-level Semantic Affinity with Image-level Supervision for Weakly Supervised Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Dai, J.; He, K.; Sun, J. Boxsup: Exploiting bounding boxes to supervise convolutional networks for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1635–1643. [Google Scholar]
- Boykov, Y.; Veksler, O.; Zabih, R. Fast approximate energy minimization via graph cuts. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 1222–1239. [Google Scholar] [CrossRef] [Green Version]
- Leung, T.; Malik, J. Representing and recognizing the visual appearance of materials using three-dimensional textons. Int. J. Comput. Vis. 2001, 43, 29–44. [Google Scholar] [CrossRef]
- Li, L.; Liang, J.; Weng, M.; Zhu, H. A multiple-feature reuse network to extract buildings from remote sensing imagery. Remote Sens. 2018, 10, 1350. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Zhang, X.; Xiao, P.; Zheng, Z. On the Effectiveness of Weakly Supervised Semantic Segmentation for Building Extraction From High-Resolution Remote Sensing Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3266–3281. [Google Scholar] [CrossRef]
- Fang, F.; Zheng, D.; Li, S.; Liu, Y.; Zeng, L.; Zhang, J.; Wan, B. Improved Pseudomasks Generation for Weakly Supervised Building Extraction From High-Resolution Remote Sensing Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 1629–1642. [Google Scholar] [CrossRef]
- Wu, H.; Zhang, J.; Huang, K.; Liang, K.; Yu, Y. Fastfcn: Rethinking dilated convolution in the backbone for semantic segmentation. arXiv 2019, arXiv:1903.11816. [Google Scholar]
- Yan, X.; Shen, L.; Wang, J.; Deng, X.; Li, Z. MSG-SR-Net: A Weakly Supervised Network Integrating Multiscale Generation and Superpixel Refinement for Building Extraction From High-Resolution Remotely Sensed Imageries. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 1012–1023. [Google Scholar] [CrossRef]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Name | Total Images | Image Size | Train Set | Validation Set | Test Set |
|---|---|---|---|---|---|
| Potsdam | 36,245 | 18,122 | 10,874 | 7249 | |
| WHU | 8189 | 4736 | 1036 | 2416 | |
| Vaihingen | 8118 | 4059 | 2435 | 1624 |
| Methods | Recall (%) | Precision (%) | F1 | IoU (%) |
|---|---|---|---|---|
| Deeplab-V3 [15] (fully) | 88.89 | 83.00 | 83.36 | 79.37 |
| MFRN [36] (fully) | 86.24 | 74.43 | 91.80 | 89.74 |
| DAN [14] (fully) | 84.13 | 83.00 | 92.56 | 90.56 |
| Li et al. [37] (weakly) | 91.60 | 87.60 | 89.50 | 81.00 |
| ACGC [38] (weakly) | 91.20 | 92.00 | 91.60 | 84.50 |
| Ours (weakly) | 84.05 | 77.15 | 87.45 | 85.65 |
| Methods | Recall (%) | Precision (%) | F1 | IoU (%) |
|---|---|---|---|---|
| FastFCN [39] (fully) | 81.37 | 87.98 | 84.55 | 73.23 |
| Deeplab-V3 [15] (fully) | 92.99 | 93.11 | 93.05 | 87.00 |
| Xin et al. (weakly) [40] | - | - | 68.98 | 52.64 |
| Ours (weakly) | 86.75 | 87.02 | 85.45 | 82.34 |
| Methods | Recall (%) | Precision (%) | F1 | IoU (%) |
|---|---|---|---|---|
| UNet [24] (fully) | 90.66 | 91.95 | 94.98 | 91.58 |
| UNet++ [41] (fully) | 91.90 | 92.87 | 95.54 | 92.37 |
| Deeplab-V3 [15] (fully) | 92.75 | 95.15 | 96.73 | 94.05 |
| Li et al. [37] (weakly) | 84.50 | 83.60 | 84.10 | 72.50 |
| ACGC [38] (weakly) | 83.40 | 92.80 | 87.90 | 78.40 |
| Ours (weakly) | 88.02 | 90.89 | 91.75 | 89.34 |
| Backbone Network | MIoU (%) | Training Time/Image (s) | Inference Time/Image (s) |
|---|---|---|---|
| VGG16 [16] | 75.24 | 0.556 | 0.119 |
| Resnet-101 [42] | 74.65 | 1.725 | 0.195 |
| Deeplab-V3 [15] | 75.82 | 2.986 | 1.563 |
| UNet [24] | 72.58 | 0.835 | 0.205 |
| Dataset | Training Type | Recall (%) | Precision (%) | F1 | MIoU (%) |
|---|---|---|---|---|---|
| Potsdam | w/o the refinement process | 65.34 | 69.28 | 71.42 | 63.47 |
| w/ the refinement process | 84.05 | 77.15 | 87.45 | 75.24 | |
| WHU | w/o the refinement process | 73.56 | 75.68 | 72.54 | 71.73 |
| w/ the refinement process | 86.75 | 87.02 | 85.45 | 82.34 | |
| Vaihingen | w/o the refinement process | 78.62 | 76.27 | 77.85 | 76.82 |
| w/ the refinement process | 88.02 | 90.89 | 91.75 | 89.34 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moghalles, K.; Li, H.-C.; Alazeb, A. Weakly Supervised Building Semantic Segmentation Based on Spot-Seeds and Refinement Process. Entropy 2022, 24, 741. https://doi.org/10.3390/e24050741
Moghalles K, Li H-C, Alazeb A. Weakly Supervised Building Semantic Segmentation Based on Spot-Seeds and Refinement Process. Entropy. 2022; 24(5):741. https://doi.org/10.3390/e24050741
Chicago/Turabian StyleMoghalles, Khaled, Heng-Chao Li, and Abdulwahab Alazeb. 2022. "Weakly Supervised Building Semantic Segmentation Based on Spot-Seeds and Refinement Process" Entropy 24, no. 5: 741. https://doi.org/10.3390/e24050741
APA StyleMoghalles, K., Li, H. -C., & Alazeb, A. (2022). Weakly Supervised Building Semantic Segmentation Based on Spot-Seeds and Refinement Process. Entropy, 24(5), 741. https://doi.org/10.3390/e24050741