
Bayesian Network Model Averaging Classifiers by Subbagging


Abstract
:1. Introduction
2. Bayesian Network Classifier
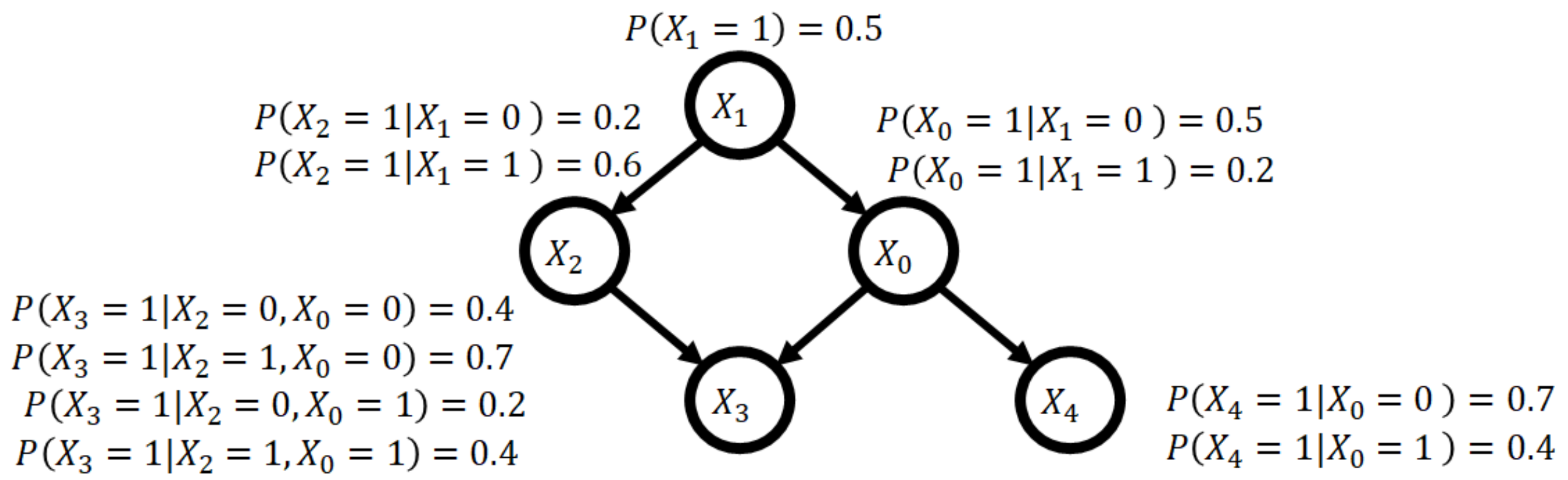
2.1. Bayesian Network
- includes a non-collider on ρ.
- There is a collider Z on ρ, and does not include Z or its descendants.
2.2. Bayesian Network Classifiers
3. Model Averaging of Bayesian Network Classifiers
4. Proposed Method
5. Experiments
5.1. Comparison of the SubbKB and Other Learning BNC Methods
- NB: Naive Bayes;
- TAN [10]: Tree-augmented naive Bayes;
- aCLL-TAN [12]: Exact learning TAN method by maximizing aCLL;
- EBN: Exact learning Bayesian network method by maximizing BDeu;
- EANB: Exact learning ANB method by maximizing BDeu;
- [29]: Ensemble method using adaboost, which starts with naive Bayes and greedily augments the current structure at iteration j with the j-th edge having the highest conditional mutual information;
- Adaboost(EBN): Ensemble method of 10 structures learned using adaboost to EBN;
- B-RAI [31]: Model averaging method over 100 structures sampled using B-RAI with ;
- Bagging(EBN): Ensemble method of 10 structures learned using bagging to EBN;
- Bagging(EANB): Ensemble method of 10 structures learned using bagging to EANB;
- KB10(EANB): K-best EC method under ANB constraints using the BDeu score with ;
- SubbKB10: SubbKB with and ;
- SubbKB10(MDL): the modified SubbKB10 to use MDL score.
- Generate 10 random structures ;
- Sample 10 datasets, , with replacement from the training dataset D, where ;
- Compute the posteriors ;
- Estimate the standard error of the posteriors as:
- Generate 10 random structures ;
- Sample 10 datasets, , with replacement from each bootstrapped dataset , where ;
- Compute the posteriors ;
- Estimate the standard error of each of the posteriors using formula (3).
5.2. Comparison of SubbKB10 and State-of-the-Art Ensemble Methods
6. Conclusions
- Steck and Jaakkola [47] proposed a conditional independence test with an asymptotic consistency, a Bayes factor with BDeu; Moreover, Abellán et al. [48], Natori et al. [49], Natori et al. [50] proposed constraint-based learning methods using a Bayes factor, which can learn large size of networks. We will apply the constraint-based learning methods using a Bayes factor to SubbKB so as to handle much larger number of variables in our method;
- Liao et al. [25] proposed a novel approach to model averaging Bayesian networks using a Bayes factor. Their approach is significantly more efficient and scales to much larger Bayesian networks than existing approaches. We expect to employ their method to address much larger number of variables in our method.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| DAG | directed acyclic graph |
| ML | marginal likelihood |
| BDeu | Bayesian Dirichlet equivalence uniform |
| ESS | equivalent sample size |
| BNC | Bayesian network classifier |
| CLL | conditional log likelihood |
| ANB | augmented naive Bayes classifier |
| aCLL | approximated conditional log likelihood |
| SubbKB | Subbagging K-best |
References
- Buntine, W. Theory Refinement on Bayesian Networks. In Proceedings of the Seventh Conference on Uncertainty in Artificial Intelligence, Los Angeles, CA, USA, 13–15 July 1991; pp. 52–60. [Google Scholar]
- Heckerman, D.; Geiger, D.; Chickering, D.M. Learning Bayesian Networks: The Combination of Knowledge and Statistical Data. Mach. Learn. 1995, 20, 197–243. [Google Scholar] [CrossRef] [Green Version]
- Silander, T.; Kontkanen, P.; Myllymäki, P. On Sensitivity of the MAP Bayesian Network Structure to the Equivalent Sample Size Parameter. In Proceedings of the Twenty-Third Conference on Uncertainty in Artificial Intelligence, Vancouver, BC, Canada, 19–22 July 2007; pp. 360–367. [Google Scholar]
- Steck, H. Learning the Bayesian Network Structure: Dirichlet Prior vs. Data. In Proceedings of the 24th Conference in Uncertainty in Artificial Intelligence, UAI 2008, Helsinki, Finland, 9–12 July 2008; pp. 511–518. [Google Scholar]
- Ueno, M. Learning Networks Determined by the Ratio of Prior and Data. In Proceedings of Uncertainty in Artificial Intelligence, Catalina Island, CA, USA, 8–11 July 2010; pp. 598–605. [Google Scholar]
- Ueno, M. Robust learning Bayesian networks for prior belief. In Proceedings of the Uncertainty in Artificial Intelligence, Barcelona, Spain, 14–17 July 2011; pp. 689–707. [Google Scholar]
- Chickering, D.M. Learning Bayesian Networks is NP-Complete. In Learning from Data: Artificial Intelligence and Statistics V; Springer: Berlin/Heidelberg, Germany, 1996; pp. 121–130. [Google Scholar] [CrossRef]
- Campos, C.P.; Tong, Y.; Ji, Q. Constrained Maximum Likelihood Learning of Bayesian Networks for Facial Action Recognition. In Proceedings of the 10th European Conference on Computer Vision: Part III, Marseille, France, 12–18 October 2008; Springer: New York, NY, USA, 2008; pp. 168–181. [Google Scholar] [CrossRef]
- Reiz, B.; Csató, L. Bayesian Network Classifier for Medical Data Analysis. Int. J. Comput. Commun. Control 2009, 4, 65–72. [Google Scholar] [CrossRef] [Green Version]
- Friedman, N.; Geiger, D.; Goldszmidt, M. Bayesian Network Classifiers. Mach. Learn. 1997, 29, 131–163. [Google Scholar] [CrossRef] [Green Version]
- Grossman, D.; Domingos, P. Learning Bayesian Network classifiers by maximizing conditional likelihood. In Proceedings of the Twenty-First International Conference on Machine Learning, Banff, AB, Canada, 4–8 July 2004; pp. 361–368. [Google Scholar]
- Carvalho, A.M.; Adão, P.; Mateus, P. Efficient Approximation of the Conditional Relative Entropy with Applications to Discriminative Learning of Bayesian Network Classifiers. Entropy 2013, 15, 2716. [Google Scholar] [CrossRef] [Green Version]
- Sugahara, S.; Uto, M.; Ueno, M. Exact learning augmented naive Bayes classifier. In Proceedings of the Ninth International Conference on Probabilistic Graphical Models, Prague, Czech Republic, 11–14 September 2018; Volume 72, pp. 439–450. [Google Scholar]
- Sugahara, S.; Ueno, M. Exact Learning Augmented Naive Bayes Classifier. Entropy 2021, 23, 1703. [Google Scholar] [CrossRef]
- Madigan, D.; Raftery, A.E. Model Selection and Accounting for Model Uncertainty in Graphical Models Using Occam’s Window. J. Am. Stat. Assoc. 1994, 89, 1535–1546. [Google Scholar] [CrossRef]
- Chickering, D.M.; Heckerman, D. A comparison of scientific and engineering criteria for Bayesian model selection. Stat. Comput. 2000, 10, 55–62. [Google Scholar] [CrossRef]
- Dash, D.; Cooper, G.F. Exact Model Averaging with Naive Bayesian Classifiers. In Proceedings of the Nineteenth International Conference on Machine Learning, San Francisco, CA, USA, 8–12 July 2002; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2002; pp. 91–98. [Google Scholar]
- Dash, D.; Cooper, G.F. Model Averaging for Prediction with Discrete Bayesian Networks. J. Mach. Learn. Res. 2004, 5, 1177–1203. [Google Scholar]
- Tian, J.; He, R.; Ram, L. Bayesian Model Averaging Using the K-Best Bayesian Network Structures. In Proceedings of the Twenty-Sixth Conference on Uncertainty in Artificial Intelligence, Catalina Island, CA, USA, 8–11 July 2010; pp. 589–597. [Google Scholar]
- Chen, Y.; Tian, J. Finding the K-best equivalence classes of Bayesian network structures for model averaging. Proc. Natl. Conf. Artif. Intell. 2014, 4, 2431–2438. [Google Scholar]
- He, R.; Tian, J.; Wu, H. Structure Learning in Bayesian Networks of a Moderate Size by Efficient Sampling. J. Mach. Learn. Res. 2016, 17, 1–54. [Google Scholar]
- Chen, E.Y.J.; Choi, A.; Darwiche, A. Learning Bayesian Networks with Non-Decomposable Scores. In Proceedings of the Graph Structures for Knowledge Representation and Reasoning, Buenos Aires, Argentina, 25 July 2015; pp. 50–71. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August; Association for Computing Machinery: New York, NY, USA, 2016; pp. 785–794. [Google Scholar] [CrossRef] [Green Version]
- Chen, E.Y.J.; Darwiche, A.; Choi, A. On pruning with the MDL Score. Int. J. Approx. Reason. 2018, 92, 363–375. [Google Scholar] [CrossRef]
- Liao, Z.; Sharma, C.; Cussens, J.; van Beek, P. Finding All Bayesian Network Structures within a Factor of Optimal. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2018. [Google Scholar]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Bagging Predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Buhlmann, P.; Yu, B. Analyzing bagging. Ann. Statist. 2002, 30, 927–961. [Google Scholar] [CrossRef]
- Jing, Y.; Pavlović, V.; Rehg, J.M. Boosted Bayesian network classifiers. Mach. Learn. 2008, 73, 155–184. [Google Scholar] [CrossRef] [Green Version]
- Dietterich, T.G. An Experimental Comparison of Three Methods for Constructing Ensembles of Decision Trees: Bagging, Boosting, and Randomization. Mach. Learn. 2000, 40, 139–157. [Google Scholar] [CrossRef]
- Rohekar, R.Y.; Gurwicz, Y.; Nisimov, S.; Koren, G.; Novik, G. Bayesian Structure Learning by Recursive Bootstrap. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; pp. 10546–10556. [Google Scholar]
- Yehezkel, R.; Lerner, B. Bayesian Network Structure Learning by Recursive Autonomy Identification. J. Mach. Learn. Res. 2009, 10, 1527–1570. [Google Scholar]
- Haughton, D.M.A. On the Choice of a Model to Fit Data from an Exponential Family. Ann. Stat. 1988, 16, 342–355. [Google Scholar] [CrossRef]
- Ueno, M. Learning likelihood-equivalence Bayesian networks using an empirical Bayesian approach. Behaviormetrika 2008, 35, 115–135. [Google Scholar] [CrossRef]
- Ueno, M.; Uto, M. Non-informative Dirichlet score for learning Bayesian networks. In Proceedings of the Sixth European Workshop on Probabilistic Graphical Models, PGM 2012, Granada, Spain, 19–21 September 2012; pp. 331–338. [Google Scholar]
- Carvalho, A.M.; Roos, T.; Oliveira, A.L.; Myllymäki, P. Discriminative Learning of Bayesian Networks via Factorized Conditional Log-Likelihood. J. Mach. Learn. Res. 2011, 12, 2181–2210. [Google Scholar]
- Rao, J.N.K. On the Comparison of Sampling with and without Replacement. Rev. L’Institut Int. Stat. Rev. Int. Stat. Inst. 1966, 34, 125–138. [Google Scholar] [CrossRef]
- Chickering, D. Optimal Structure Identification With Greedy Search. J. Mach. Learn. Res. 2002, 3, 507–554. [Google Scholar] [CrossRef] [Green Version]
- Hommel, G. A Stagewise Rejective Multiple Test Procedure Based on a Modified Bonferroni Test. Biometrika 1988, 75, 383–386. [Google Scholar] [CrossRef]
- Demšar, J. Statistical Comparisons of Classifiers over Multiple Data Sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Ling, C.X.; Zhang, H. The Representational Power of Discrete Bayesian Networks. J. Mach. Learn. Res. 2003, 3, 709–721. [Google Scholar]
- Tsamardinos, I.; Brown, L.; Aliferis, C. The Max-Min Hill-Climbing Bayesian Network Structure Learning Algorithm. Mach. Learn. 2006, 65, 31–78. [Google Scholar] [CrossRef] [Green Version]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased Boosting with Categorical Features. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; Curran Associates Inc.: Red Hook, NY, USA, 2018; pp. 6639–6649. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Nice, France, 2017; Volume 30. [Google Scholar]
- Jensen, F.V.; Nielsen, T.D. Bayesian Networks and Decision Graphs, 2nd ed.; Springer Publishing Company, Incorporated: Lincoln, RI, USA, 2007. [Google Scholar]
- Darwiche, A. Three Modern Roles for Logic in AI. In Proceedings of the 39th ACM SIGMOD-SIGACT-SIGAI Symposium on Principles of Database Systems, Portland, OR, USA, 14–19 June 2020; pp. 229–243. [Google Scholar] [CrossRef]
- Steck, H.; Jaakkola, T. On the Dirichlet Prior and Bayesian Regularization. In Advances in Neural Information Processing Systems; Becker, S., Thrun, S., Obermayer, K., Eds.; MIT Press: Cambridge, MA, USA, 2003; Volume 15. [Google Scholar]
- Abellán, J.; Gómez-Olmedo, M.; Moral, S. Some Variations on the PC Algorithm; Department of Computer Science and Articial Intelligence University of Granada: Granada, Spain, 2006; pp. 1–8. [Google Scholar]
- Natori, K.; Uto, M.; Nishiyama, Y.; Kawano, S.; Ueno, M. Constraint-Based Learning Bayesian Networks Using Bayes Factor. In Proceedings of the Second International Workshop on Advanced Methodologies for Bayesian Networks, Yokohama, Japan, 16–18 November 2015; Volume 9505, pp. 15–31. [Google Scholar]
- Natori, K.; Uto, M.; Ueno, M. Consistent Learning Bayesian Networks with Thousands of Variables. Proc. Mach. Learn. Res. 2017, 73, 57–68. [Google Scholar]
- Isozaki, T.; Kato, N.; Ueno, M. Minimum Free Energies with “Data Temperature” for Parameter Learning of Bayesian Networks. In Proceedings of the 2008 20th IEEE International Conference on Tools with Artificial Intelligence, Dayton, OH, USA, 3–5 November 2008; Volume 1, pp. 371–378. [Google Scholar] [CrossRef]
- Isozaki, T.; Kato, N.; Ueno, M. “Data temperature” in Minimum Free energies for Parameter Learning of Bayesian Networks. Int. J. Artif. Intell. Tools 2009, 18, 653–671. [Google Scholar] [CrossRef]
- Isozaki, T.; Ueno, M. Minimum Free Energy Principle for Constraint-Based Learning Bayesian Networks. In Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2009; pp. 612–627. [Google Scholar]
- Sugahara, S.; Aomi, I.; Ueno, M. Bayesian Network Model Averaging Classifiers by Subbagging. In Proceedings of the 10th International Conference on Probabilistic Graphical Models, Aalborg, Denmark, 23–25 September 2020; Volume 138, pp. 461–472. [Google Scholar]



{kind=link}
{kind=link}
| CPU | Intel(R) Xeon(R) E5-2630 v4 10 Cores, 2.20 GHz |
|---|---|
| System Memory | 128 GB |
| Software | Java 1.8 |
| No. | Datasets | Sample Size | Variables | Entropy |
|---|---|---|---|---|
| 1 | lenses | 24 | 5 | 0.9192 |
| 2 | mux6 | 64 | 7 | 0.6931 |
| 3 | post | 87 | 9 | 0.6480 |
| 4 | zoo | 101 | 17 | 1.2137 |
| 5 | HayesRoth | 132 | 5 | 1.0716 |
| 6 | iris | 150 | 5 | 1.0986 |
| 7 | wine | 178 | 14 | 1.0860 |
| 8 | glass | 214 | 10 | 1.5087 |
| 9 | CVR | 232 | 17 | 0.6908 |
| 10 | heart | 270 | 14 | 0.6870 |
| 11 | BreastCancer | 277 | 10 | 0.6043 |
| 12 | cleve | 296 | 14 | 0.6899 |
| 13 | liver | 345 | 7 | 0.6804 |
| 14 | threeOf9 | 512 | 10 | 0.6907 |
| 15 | crx | 653 | 16 | 0.6888 |
| 16 | Australian | 690 | 15 | 0.6871 |
| 17 | pima | 768 | 9 | 0.6468 |
| 18 | TicTacToe | 958 | 10 | 0.6453 |
| 19 | banknote | 1372 | 5 | 0.6870 |
| 20 | Solar Flare | 1389 | 11 | 0.6073 |
| 21 | CMC | 1473 | 10 | 1.0668 |
| 22 | led7 | 3200 | 8 | 2.3006 |
| 23 | shuttle-small | 5800 | 10 | 0.6606 |
| 24 | EEG | 14980 | 15 | 0.6879 |
| 25 | HTRU2 | 17898 | 9 | 0.3062 |
| 26 | MAGICGT | 19020 | 11 | 0.6484 |
| aCLL- | Adaboost | Bagging | Bagging | KB10 | SubbKB10 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| No. | NB | TAN | TAN | EBN | EANB | (EBN) | B-RAI | (EBN) | (EANB) | KB10 | (EANB) | KB20 | KB50 | KB100 | (MDL) | SubbKB10 | ||
| 1 | 0.9192 | 0.6250 | 0.7083 | 0.7083 | 0.8125 | 0.8750 | 0.6667 | 0.8125 | 0.8500 | 0.8333 | 0.8750 | 0.8333 | 0.6250 | 0.8333 | 0.8333 | 0.8333 | 0.8750 | 0.8333 |
| 2 | 0.6931 | 0.5469 | 0.6094 | 0.5938 | 0.4531 | 0.5469 | 0.5938 | 0.4531 | 0.3238 | 0.6094 | 0.4063 | 0.3594 | 0.5781 | 0.4219 | 0.4219 | 0.4219 | 0.3906 | 0.6250 |
| 3 | 0.6480 | 0.6552 | 0.6322 | 0.5977 | 0.7126 | 0.7126 | 0.6552 | 0.7126 | 0.7139 | 0.7126 | 0.7126 | 0.7126 | 0.6552 | 0.7126 | 0.7126 | 0.7126 | 0.7126 | 0.7126 |
| 4 | 1.2137 | 0.9901 | 0.9406 | 0.9505 | 0.9426 | 0.9604 | 0.9901 | 0.9406 | 0.9435 | 0.9604 | 0.9604 | 0.9505 | 0.9703 | 0.9505 | 0.9505 | 0.9505 | 0.9307 | 0.9505 |
| 5 | 1.0716 | 0.8106 | 0.6439 | 0.6742 | 0.6136 | 0.8333 | 0.6970 | 0.6136 | 0.6143 | 0.6136 | 0.8333 | 0.8182 | 0.7955 | 0.8182 | 0.8182 | 0.7803 | 0.8182 | 0.7727 |
| 6 | 1.0986 | 0.7133 | 0.8267 | 0.8200 | 0.8267 | 0.8067 | 0.8267 | 0.8200 | 0.8133 | 0.8267 | 0.8267 | 0.8267 | 0.8267 | 0.8267 | 0.8267 | 0.8200 | 0.8000 | 0.8267 |
| 7 | 1.0860 | 0.9270 | 0.9213 | 0.9157 | 0.9438 | 0.9270 | 0.9326 | 0.9213 | 0.8941 | 0.9551 | 0.9213 | 0.9438 | 0.9270 | 0.9438 | 0.9438 | 0.9438 | 0.9551 | 0.9438 |
| 8 | 1.5087 | 0.5421 | 0.5467 | 0.6215 | 0.5607 | 0.5280 | 0.5981 | 0.5701 | 0.5470 | 0.5701 | 0.5234 | 0.5701 | 0.5888 | 0.5748 | 0.5748 | 0.5748 | 0.5607 | 0.5748 |
| 9 | 0.6908 | 0.9095 | 0.9526 | 0.9224 | 0.9612 | 0.9526 | 0.9310 | 0.9655 | 0.9697 | 0.9698 | 0.9569 | 0.9612 | 0.9569 | 0.9655 | 0.9655 | 0.9655 | 0.9612 | 0.9698 |
| 10 | 0.6870 | 0.8296 | 0.8333 | 0.8148 | 0.8296 | 0.8444 | 0.8333 | 0.8074 | 0.7611 | 0.8407 | 0.8407 | 0.8259 | 0.8222 | 0.8333 | 0.8333 | 0.8333 | 0.8333 | 0.8370 |
| 11 | 0.6043 | 0.7365 | 0.7220 | 0.6968 | 0.7076 | 0.6751 | 0.7148 | 0.7509 | 0.6888 | 0.7004 | 0.6787 | 0.7040 | 0.7148 | 0.7040 | 0.7076 | 0.7329 | 0.7004 | 0.7220 |
| 12 | 0.6899 | 0.8311 | 0.8243 | 0.8446 | 0.8074 | 0.8142 | 0.8176 | 0.7939 | 0.7771 | 0.8108 | 0.8142 | 0.8074 | 0.8209 | 0.8041 | 0.8074 | 0.8176 | 0.8142 | 0.8176 |
| 13 | 0.6804 | 0.6464 | 0.6609 | 0.6522 | 0.5768 | 0.6058 | 0.6638 | 0.5971 | 0.5995 | 0.6174 | 0.6261 | 0.5913 | 0.6783 | 0.6087 | 0.6145 | 0.6261 | 0.6087 | 0.6232 |
| 14 | 0.6907 | 0.8008 | 0.8691 | 0.8906 | 0.8691 | 0.8672 | 0.8789 | 0.9063 | 0.7598 | 0.8906 | 0.8789 | 0.9043 | 0.8926 | 0.8984 | 0.8965 | 0.9434 | 0.9043 | 0.9023 |
| 15 | 0.6888 | 0.8392 | 0.8515 | 0.8453 | 0.8392 | 0.8622 | 0.8331 | 0.8591 | 0.8590 | 0.8499 | 0.8652 | 0.8392 | 0.8392 | 0.8392 | 0.8499 | 0.8484 | 0.8530 | 0.8499 |
| 16 | 0.6871 | 0.8348 | 0.8290 | 0.8478 | 0.8565 | 0.8580 | 0.8333 | 0.8638 | 0.8493 | 0.8464 | 0.8594 | 0.8565 | 0.8362 | 0.8565 | 0.8536 | 0.8478 | 0.8565 | 0.8464 |
| 17 | 0.6468 | 0.7057 | 0.7188 | 0.7031 | 0.7253 | 0.7188 | 0.7083 | 0.7240 | 0.7123 | 0.7227 | 0.7161 | 0.7279 | 0.7201 | 0.7279 | 0.7266 | 0.7331 | 0.7266 | 0.7266 |
| 18 | 0.6453 | 0.6889 | 0.7599 | 0.7192 | 0.8549 | 0.8445 | 0.7505 | 0.9123 | 0.6994 | 0.8466 | 0.8445 | 0.8539 | 0.8518 | 0.8518 | 0.8528 | 0.8486 | 0.8925 | 0.8518 |
| 19 | 0.6870 | 0.8433 | 0.8819 | 0.8761 | 0.8812 | 0.8812 | 0.8754 | 0.8776 | 0.8812 | 0.8812 | 0.8812 | 0.8812 | 0.8812 | 0.8812 | 0.8812 | 0.8812 | 0.8812 | 0.8812 |
| 20 | 0.6073 | 0.7804 | 0.7970 | 0.8200 | 0.8431 | 0.8431 | 0.8143 | 0.8431 | 0.8409 | 0.8431 | 0.8431 | 0.8431 | 0.8236 | 0.8431 | 0.8431 | 0.8431 | 0.8431 | 0.8431 |
| 21 | 1.0668 | 0.4644 | 0.4725 | 0.4650 | 0.4549 | 0.4270 | 0.4779 | 0.4399 | 0.4100 | 0.4521 | 0.4270 | 0.4535 | 0.4623 | 0.4542 | 0.4494 | 0.4616 | 0.4481 | 0.4487 |
| 22 | 2.3006 | 0.7288 | 0.7309 | 0.7347 | 0.7288 | 0.7288 | 0.7300 | 0.7288 | 0.7228 | 0.7284 | 0.7284 | 0.7288 | 0.7281 | 0.7288 | 0.7288 | 0.7303 | 0.7272 | 0.7309 |
| 23 | 0.6606 | 0.9383 | 0.9567 | 0.9538 | 0.9693 | 0.9716 | 0.9681 | 0.9662 | 0.9659 | 0.9693 | 0.9702 | 0.9693 | 0.9714 | 0.9693 | 0.9693 | 0.9693 | 0.9393 | 0.9693 |
| 24 | 0.6879 | 0.5774 | 0.6298 | 0.6138 | 0.6844 | 0.6895 | 0.6031 | 0.6906 | 0.6450 | 0.6881 | 0.6955 | 0.6857 | 0.6931 | 0.6856 | 0.6856 | 0.6885 | 0.6918 | 0.6899 |
| 25 | 0.3062 | 0.8966 | 0.9141 | 0.9141 | 0.9141 | 0.9141 | 0.9102 | 0.9073 | 0.9066 | 0.9141 | 0.9141 | 0.9141 | 0.9141 | 0.9141 | 0.9141 | 0.9141 | 0.9141 | 0.9141 |
| 26 | 0.6484 | 0.7447 | 0.7769 | 0.7656 | 0.7859 | 0.7879 | 0.7734 | 0.7849 | 0.7827 | 0.7859 | 0.788 | 0.7863 | 0.7877 | 0.7863 | 0.7863 | 0.7871 | 0.7855 | 0.7860 |
| Ave | 0.7541 | 0.7696 | 0.7678 | 0.7752 | 0.7875 | 0.7722 | 0.7793 | 0.7512 | 0.7861 | 0.7841 | 0.7826 | 0.7831 | 0.7859 | 0.7864 | 0.7888 | 0.7855 | 0.7942 |
| aCLL- | Adaboost | Bagging | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NB | TAN | TAN | EBN | EANB | (EBN) | B-RAI | (EBN) | KB10 | KB20 | KB100 | ||
| p-values | 0.0016 | 0.0017 | 0.0046 | 0.0013 | 0.0749 | 0.0069 | 0.0197 | 0.0001 | 0.0315 | 0.0655 | 0.0694 | 0.0617 |
| No. | Datasets | Sample Size | Variables | EBN | SubbKB10 |
|---|---|---|---|---|---|
| 1 | lenses | 24 | 5 | 0.90 | 1.37 |
| 2 | mux6 | 64 | 7 | 5.70 | 4.68 |
| 3 | post | 87 | 9 | 0.00 | 0.02 |
| 4 | zoo | 101 | 17 | 3.70 | 4.31 |
| 5 | HayesRoth | 132 | 5 | 3.00 | 2.46 |
| 6 | iris | 150 | 5 | 1.80 | 1.89 |
| 7 | wine | 178 | 14 | 1.70 | 1.40 |
| 8 | glass | 214 | 10 | 0.40 | 0.68 |
| 9 | CVR | 232 | 17 | 0.90 | 1.42 |
| 10 | heart | 270 | 14 | 1.70 | 1.54 |
| 11 | BreastCancer | 277 | 10 | 0.70 | 0.82 |
| 12 | cleve | 296 | 14 | 1.90 | 1.69 |
| 13 | liver | 345 | 7 | 0.00 | 0.19 |
| 14 | threeOf9 | 512 | 10 | 5.00 | 3.85 |
| 15 | crx | 653 | 16 | 1.20 | 1.08 |
| 16 | Australian | 690 | 15 | 1.00 | 1.14 |
| 17 | pima | 768 | 9 | 1.60 | 1.09 |
| 18 | TicTacToe | 958 | 10 | 1.60 | 0.40 |
| 19 | banknote | 1372 | 5 | 0.00 | 0.69 |
| 20 | Solar Flare | 1389 | 11 | 0.80 | 0.91 |
| 21 | CMC | 1473 | 10 | 0.90 | 0.82 |
| 22 | led7 | 3200 | 8 | 0.60 | 0.95 |
| 23 | shuttle-small | 5800 | 10 | 2.00 | 2.12 |
| 24 | EEG | 14980 | 15 | 0.50 | 0.47 |
| 25 | HTRU2 | 17898 | 9 | 1.50 | 1.62 |
| 26 | MAGICGT | 19020 | 11 | 0.00 | 0.47 |
| Average | 1.50 | 1.46 |
| EBN | KB10 | KB20 | KB50 | KB100 | SubbKB10 | |
|---|---|---|---|---|---|---|
| Accuracy | 0.7498 | 0.7509 | 0.7529 | 0.7557 | 0.7563 | 0.7579 |
| Bagging | Bagging | KB10 | ||||
|---|---|---|---|---|---|---|
| No. | (EBN) | (EANB) | KB10 | (EANB) | KB100 | SubbKB10 |
| 1 | 1.07 | 0.33 | 2.61 | 2.30 | 3.09 | 4.11 |
| 2 | 0.61 | 0.89 | 3.24 | 1.96 | 4.33 | 4.56 |
| 3 | 0.42 | 0.42 | 2.33 | 1.92 | 2.31 | 3.32 |
| 4 | 32.56 | 12.98 | 7.03 | 7.41 | 5.43 | 10.51 |
| 5 | 0.00 | 0.07 | 2.35 | 2.39 | 2.87 | 3.78 |
| 6 | 1.87 | 1.54 | 5.09 | 2.86 | 4.23 | 6.12 |
| 7 | 11.85 | 5.50 | 7.57 | 2.56 | 4.04 | 9.40 |
| 8 | 4.76 | 5.31 | 3.71 | 4.33 | 3.33 | 5.36 |
| 9 | 23.27 | 24.25 | 6.37 | 6.60 | 3.03 | 8.91 |
| 10 | 7.19 | 6.42 | 4.48 | 2.09 | 3.61 | 7.64 |
| 11 | 1.02 | 1.02 | 2.36 | 2.20 | 0.76 | 4.67 |
| 12 | 5.95 | 5.07 | 3.74 | 2.16 | 2.50 | 7.34 |
| 13 | 4.27 | 4.17 | 4.98 | 2.08 | 4.45 | 6.63 |
| 14 | 4.33 | 3.36 | 3.16 | 3.44 | 2.59 | 3.79 |
| 15 | 8.68 | 6.29 | 9.36 | 3.70 | 7.18 | 10.63 |
| 16 | 10.79 | 9.39 | 6.25 | 3.97 | 5.60 | 9.82 |
| 17 | 3.30 | 1.97 | 5.05 | 3.15 | 4.63 | 7.10 |
| 18 | 8.06 | 5.85 | 7.86 | 7.18 | 7.19 | 10.54 |
| 19 | 0.00 | 0.00 | 5.54 | 3.74 | 3.77 | 6.88 |
| 20 | 3.24 | 2.58 | 5.20 | 4.38 | 4.10 | 7.19 |
| 21 | 4.64 | 3.60 | 5.57 | 2.79 | 3.63 | 6.67 |
| 22 | 0.00 | 0.00 | 3.58 | 1.80 | 1.21 | 5.49 |
| 23 | 1.80 | 5.05 | 6.23 | 5.83 | 5.56 | 6.87 |
| 24 | 7.99 | 15.40 | 9.04 | 12.07 | 6.92 | 10.26 |
| 25 | 0.32 | 0.32 | 6.03 | 5.01 | 0.80 | 9.56 |
| 26 | 3.82 | 1.36 | 9.02 | 7.14 | 4.28 | 12.47 |
| Ave | 4.98 | 4.16 | 4.82 | 3.64 | 3.72 | 6.70 |
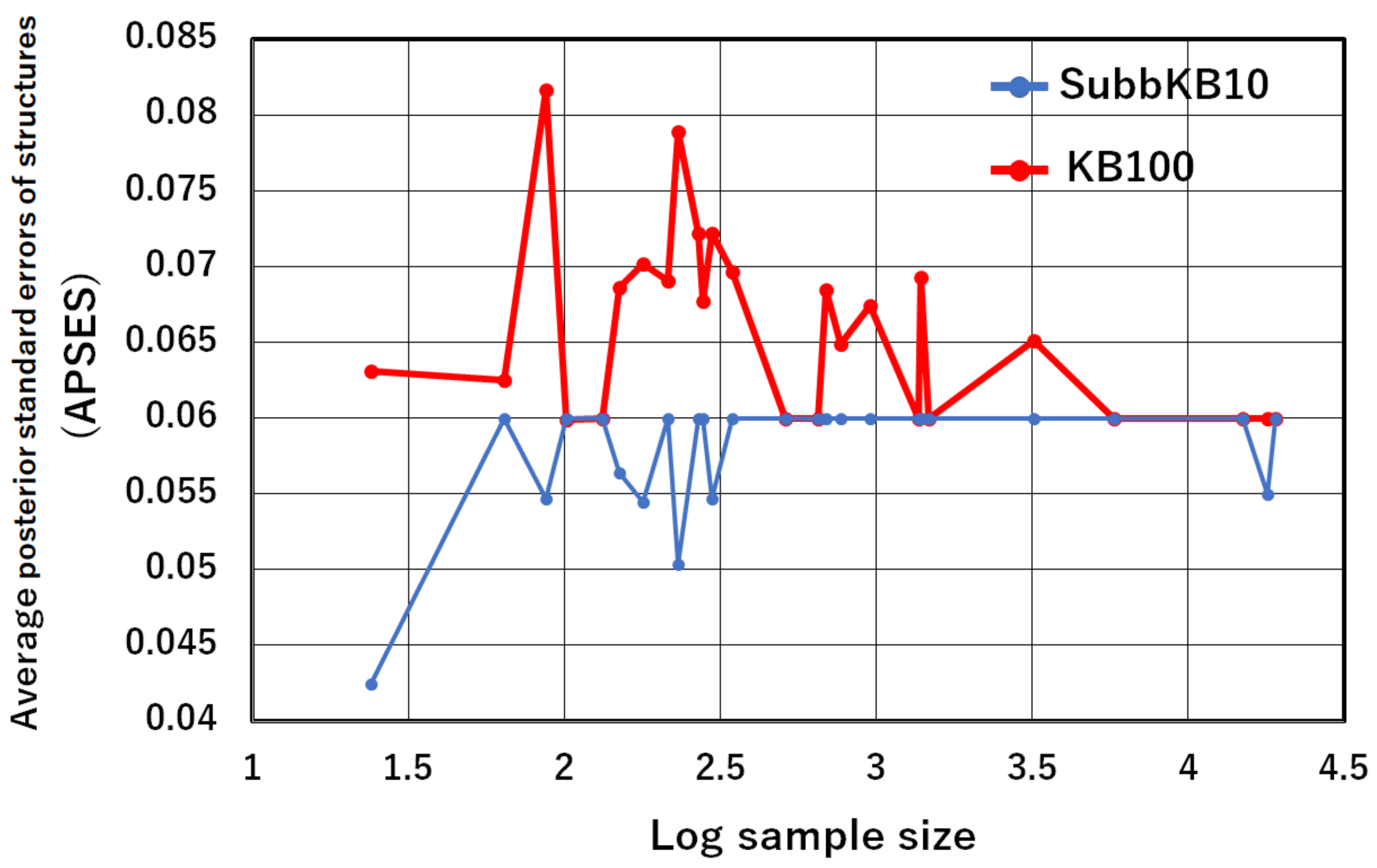
| (1) APSES | (2) Classification Accuracy | ||||||
|---|---|---|---|---|---|---|---|
| No. | Datasets | Sample Size | Variables | KB100 | SubbKB10 | KB100 | SubbKB10 |
| 1 | lenses | 24 | 5 | 0.0631 | 0.0425 | 0.8333 | 0.8333 |
| 2 | mux6 | 64 | 7 | 0.0625 | 0.0600 | 0.4219 | 0.6250 |
| 3 | post | 87 | 9 | 0.0817 | 0.0547 | 0.7126 | 0.7126 |
| 4 | zoo | 101 | 17 | 0.0599 | 0.0600 | 0.9505 | 0.9505 |
| 5 | HayesRoth | 132 | 5 | 0.0600 | 0.0600 | 0.7803 | 0.7727 |
| 6 | iris | 150 | 5 | 0.0686 | 0.0564 | 0.8200 | 0.8267 |
| 7 | wine | 178 | 14 | 0.0702 | 0.0545 | 0.9438 | 0.9438 |
| 8 | glass | 214 | 10 | 0.0691 | 0.0600 | 0.5748 | 0.5748 |
| 9 | CVR | 232 | 17 | 0.0789 | 0.0504 | 0.9655 | 0.9698 |
| 10 | heart | 270 | 14 | 0.0722 | 0.0600 | 0.8333 | 0.8370 |
| 11 | BreastCancer | 277 | 10 | 0.0677 | 0.0600 | 0.7329 | 0.7220 |
| 12 | cleve | 296 | 14 | 0.0722 | 0.0547 | 0.8176 | 0.8176 |
| 13 | liver | 345 | 7 | 0.0697 | 0.0600 | 0.6261 | 0.6232 |
| 14 | threeOf9 | 512 | 10 | 0.0600 | 0.0600 | 0.9434 | 0.9023 |
| 15 | crx | 653 | 16 | 0.0600 | 0.0600 | 0.8484 | 0.8499 |
| 16 | Australian | 690 | 15 | 0.0685 | 0.0600 | 0.8478 | 0.8464 |
| 17 | pima | 768 | 9 | 0.0649 | 0.0600 | 0.7331 | 0.7266 |
| 18 | TicTacToe | 958 | 10 | 0.0674 | 0.0600 | 0.8486 | 0.8518 |
| 19 | banknote | 1372 | 5 | 0.0600 | 0.0600 | 0.8812 | 0.8812 |
| 20 | Solar Flare | 1389 | 11 | 0.0693 | 0.0600 | 0.8431 | 0.8431 |
| 21 | CMC | 1473 | 10 | 0.0600 | 0.0600 | 0.4616 | 0.4487 |
| 22 | led7 | 3200 | 8 | 0.0651 | 0.0600 | 0.7303 | 0.7309 |
| 23 | shuttle-small | 5800 | 10 | 0.0600 | 0.0600 | 0.9693 | 0.9693 |
| 24 | EEG | 14980 | 15 | 0.0600 | 0.0600 | 0.6885 | 0.6899 |
| 25 | HTRU2 | 17898 | 9 | 0.0600 | 0.0550 | 0.9141 | 0.9141 |
| 26 | MAGICGT | 19020 | 11 | 0.0600 | 0.0600 | 0.7871 | 0.7860 |
| Average | 0.0658 | 0.0580 | 0.7888 | 0.7942 | |||
| p-value | 0.0001 | - | - | - | |||
| No. | Datasets | Sample Size | Variables | XGBoost | CatBoost | LightGBM | SubbKB10 | |
|---|---|---|---|---|---|---|---|---|
| 1 | lenses | 24 | 5 | 0.9192 | 0.7833 | 0.7833 | 0.6667 | 0.8333 |
| 2 | mux6 | 64 | 7 | 0.6931 | 0.8333 | 0.9857 | 0.5357 | 0.8281 |
| 3 | post | 87 | 9 | 0.6480 | 0.6806 | 0.6000 | 0.7139 | 0.7011 |
| 4 | zoo | 101 | 17 | 1.2137 | 0.9509 | 0.9409 | 0.9309 | 0.9505 |
| 5 | HayesRoth | 132 | 5 | 1.0716 | 0.7967 | 0.7956 | 0.7429 | 0.8258 |
| 6 | iris | 150 | 5 | 1.0986 | 0.8200 | 0.8267 | 0.8200 | 0.8267 |
| 7 | wine | 178 | 14 | 1.0860 | 0.9268 | 0.9373 | 0.9088 | 0.9157 |
| 8 | glass | 214 | 10 | 1.5087 | 0.6457 | 0.6604 | 0.6407 | 0.6402 |
| 9 | CVR | 232 | 17 | 0.6908 | 0.9656 | 0.9612 | 0.9612 | 0.9612 |
| 10 | heart | 270 | 14 | 0.6870 | 0.8370 | 0.8111 | 0.8185 | 0.8259 |
| 11 | BreastCancer | 277 | 10 | 0.6043 | 0.7390 | 0.7361 | 0.7394 | 0.6931 |
| 12 | cleve | 296 | 14 | 0.6899 | 0.8277 | 0.7940 | 0.8172 | 0.8311 |
| 13 | liver | 345 | 7 | 0.6804 | 0.6635 | 0.6434 | 0.6548 | 0.6174 |
| 14 | threeOf9 | 512 | 10 | 0.6907 | 1.0000 | 1.0000 | 1.0000 | 0.9980 |
| 15 | crx | 653 | 16 | 0.6888 | 0.8589 | 0.8697 | 0.8513 | 0.8637 |
| 16 | Australian | 690 | 15 | 0.6871 | 0.8623 | 0.8565 | 0.8609 | 0.8507 |
| 17 | pima | 768 | 9 | 0.6468 | 0.7136 | 0.7188 | 0.7149 | 0.7018 |
| 18 | TicTacToe | 958 | 10 | 0.6453 | 1.0000 | 1.0000 | 1.0000 | 0.9979 |
| 19 | banknote | 1372 | 5 | 0.6870 | 0.8812 | 0.8812 | 0.8812 | 0.8812 |
| 20 | Solar Flare | 1389 | 11 | 0.6073 | 0.8402 | 0.8359 | 0.8186 | 0.8409 |
| 21 | CMC | 1473 | 10 | 1.0668 | 0.4894 | 0.4684 | 0.4725 | 0.4807 |
| 22 | led7 | 3200 | 8 | 2.3006 | 0.7297 | 0.7309 | 0.7303 | 0.7281 |
| 23 | shuttle-small | 5800 | 10 | 0.6606 | 0.9721 | 0.9721 | 0.9721 | 0.9722 |
| 24 | EEG | 14980 | 15 | 0.6879 | 0.7376 | 0.7308 | 0.7348 | 0.8901 |
| 25 | HTRU2 | 17898 | 9 | 0.3062 | 0.9141 | 0.9141 | 0.9141 | 0.9141 |
| 26 | MAGICGT | 19020 | 11 | 0.6484 | 0.7871 | 0.7863 | 0.7870 | 0.7855 |
| Average | 0.8176 | 0.8169 | 0.7957 | 0.8213 | ||||
| p-value | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sugahara, S.; Aomi, I.; Ueno, M. Bayesian Network Model Averaging Classifiers by Subbagging. Entropy 2022, 24, 743. https://doi.org/10.3390/e24050743
Sugahara S, Aomi I, Ueno M. Bayesian Network Model Averaging Classifiers by Subbagging. Entropy. 2022; 24(5):743. https://doi.org/10.3390/e24050743
Chicago/Turabian StyleSugahara, Shouta, Itsuki Aomi, and Maomi Ueno. 2022. "Bayesian Network Model Averaging Classifiers by Subbagging" Entropy 24, no. 5: 743. https://doi.org/10.3390/e24050743
APA StyleSugahara, S., Aomi, I., & Ueno, M. (2022). Bayesian Network Model Averaging Classifiers by Subbagging. Entropy, 24(5), 743. https://doi.org/10.3390/e24050743