
GTAD: Graph and Temporal Neural Network for Multivariate Time Series Anomaly Detection




Abstract
:1. Introduction
- We proposed a new framework for an unsupervised multivariate time series anomaly detection algorithm (GTAD) that combines the advantages of prediction-based approaches, which focus on feature engineering at the next time step, and reconstruction-based approaches, which emphasize capturing the overall distribution of the data.
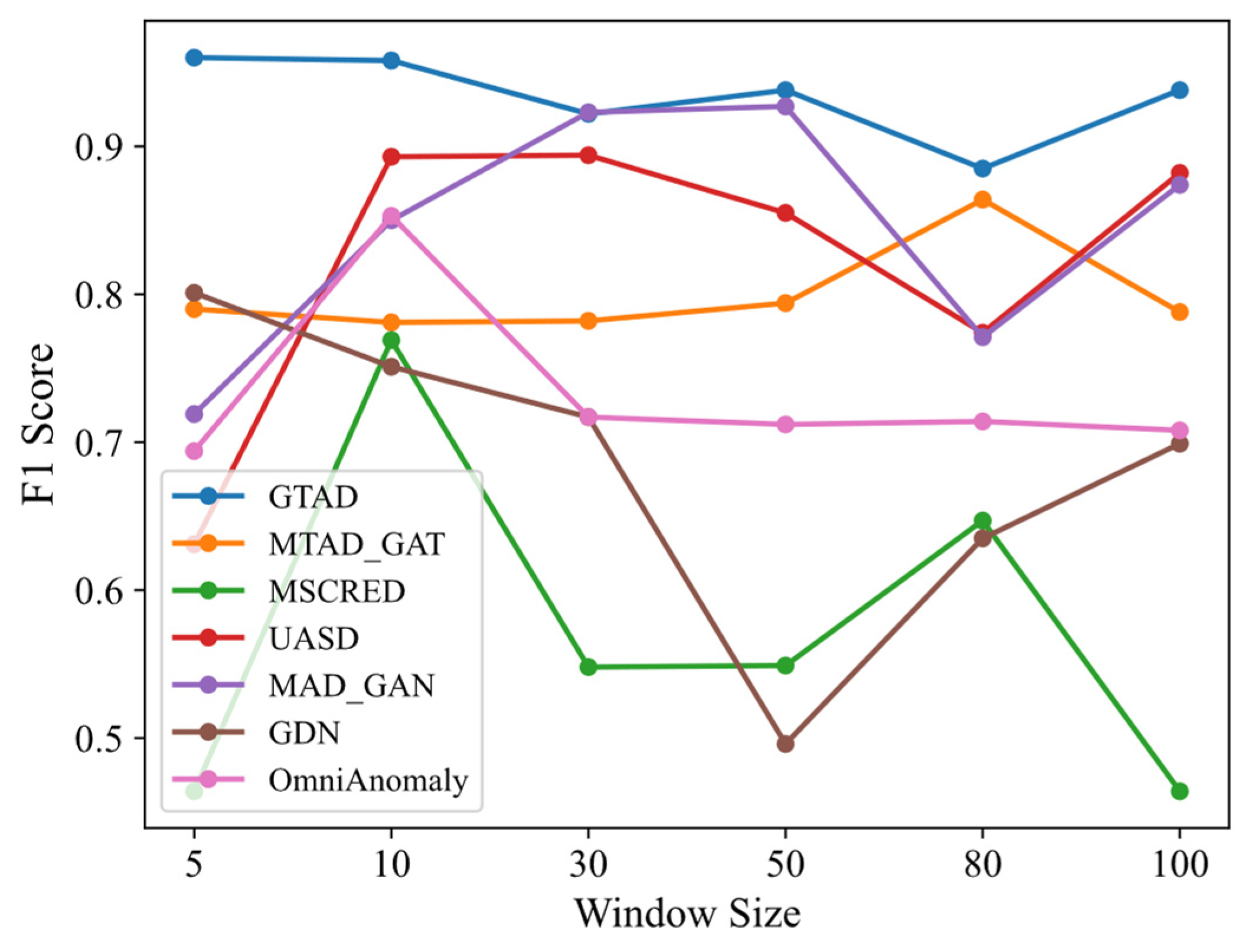
- GTAD uses parallel operations instead of RNN frameworks, such as LSTM and GRU, and its ability to extract contextual information is enhanced, resulting in a model with low sensitivity to sliding window size.
- GTAD specifies the optimization objective by using the error of prediction and reconstruction for one dimension as the loss function, rather than all dimensions, leading to better detection performance.
2. Related Works
3. Method Overview
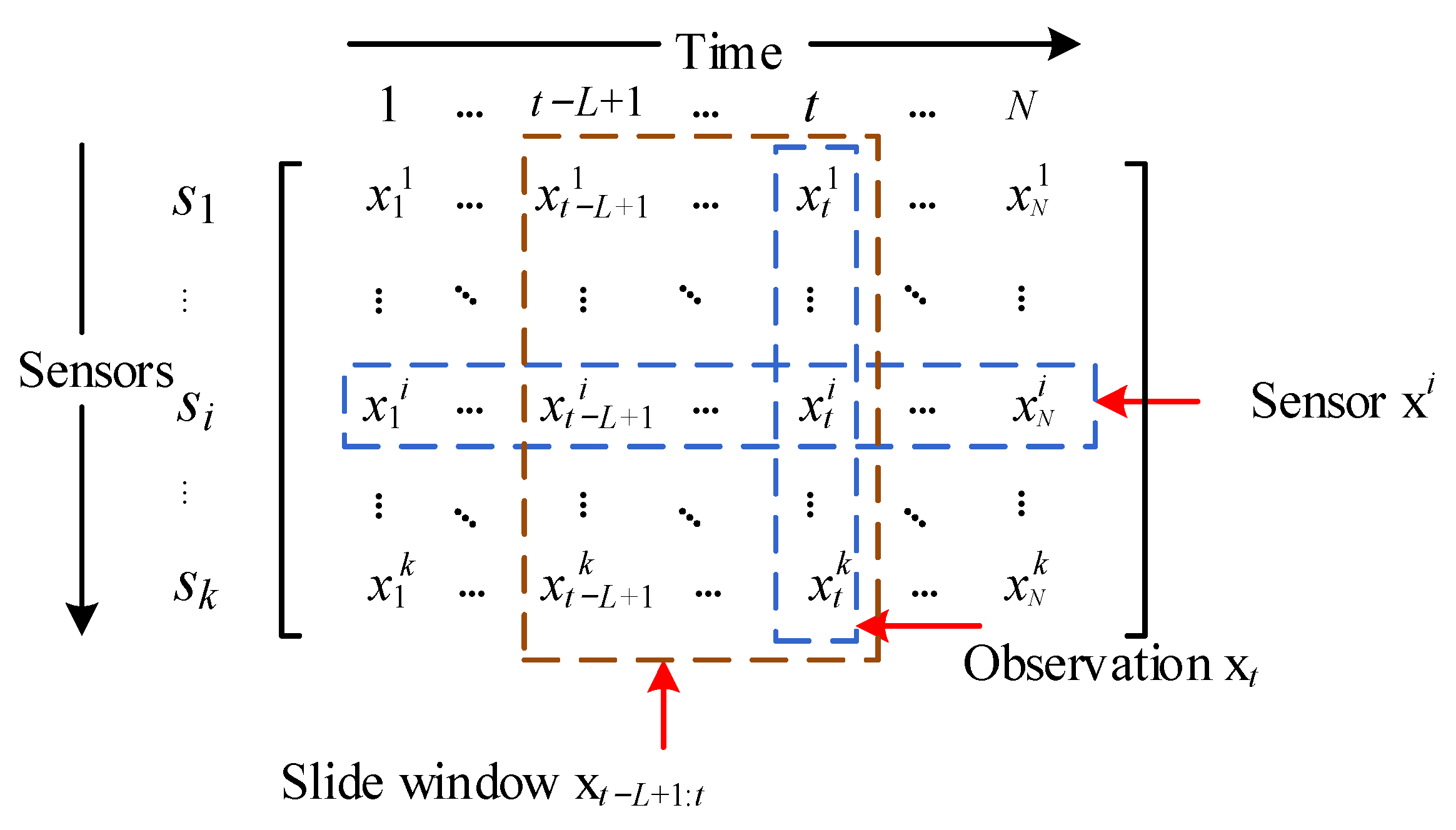
3.1. Problem Statement
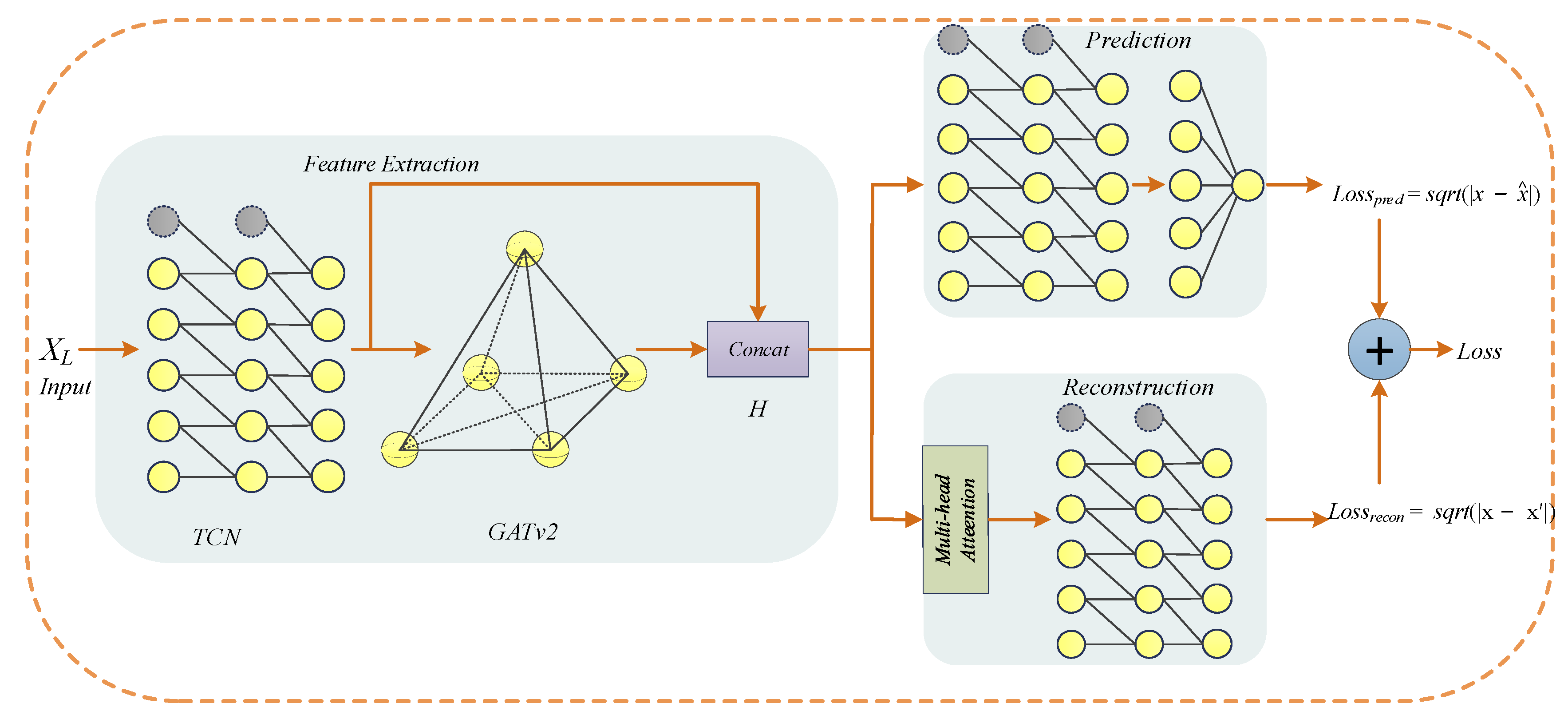
3.2. Model Architecture
| Algorithm 1: GTAD Training Algorithm |
| Input: Training Dataset X = {x1, …, xM}, The number of epochs R |
| Output: Trained GTAD |
| GTAD←initialize weight |
| epoch←1 |
| repeat |
| for t = L to M do |
| ← TAD (xt-L:t-1) |
| GTAD←update weight using Loss |
| end for |
| epoch←epoch + 1 |
| until epoch = R |
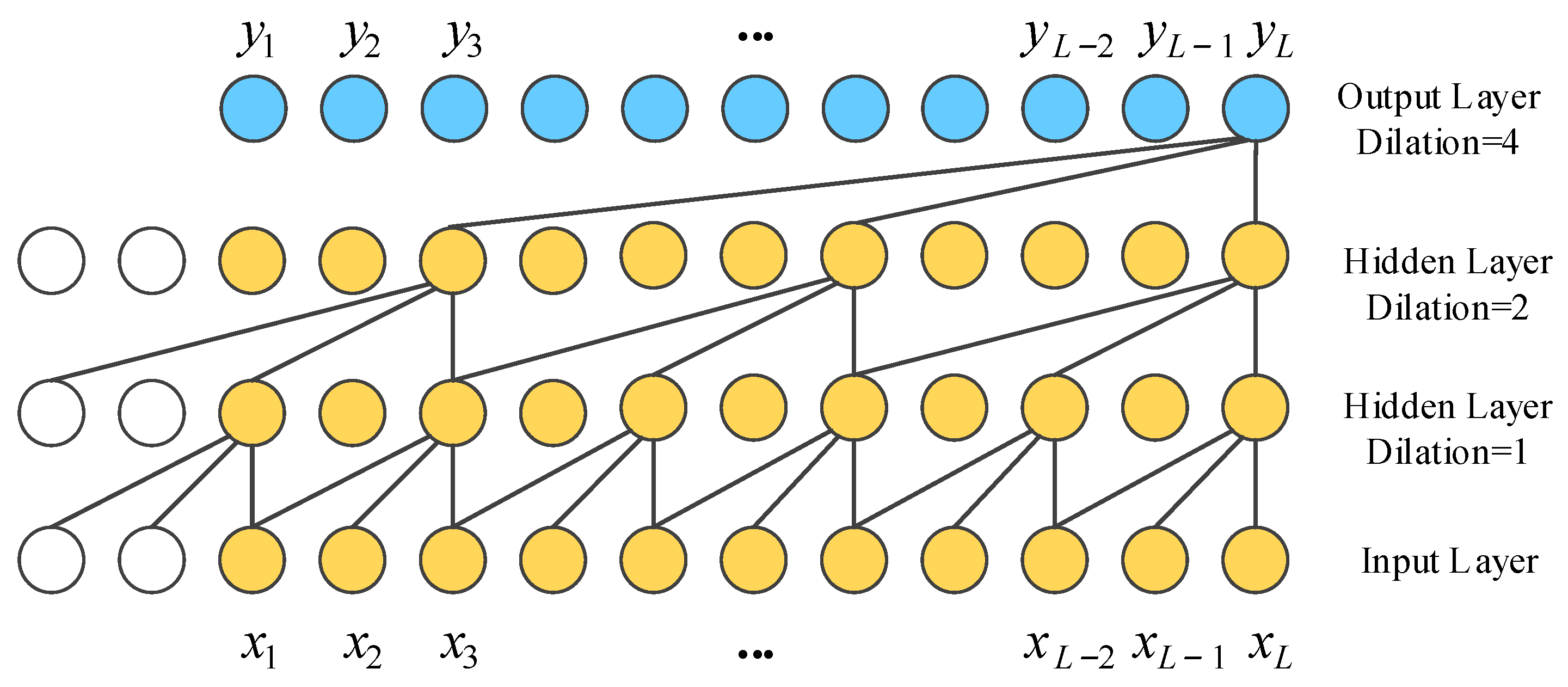
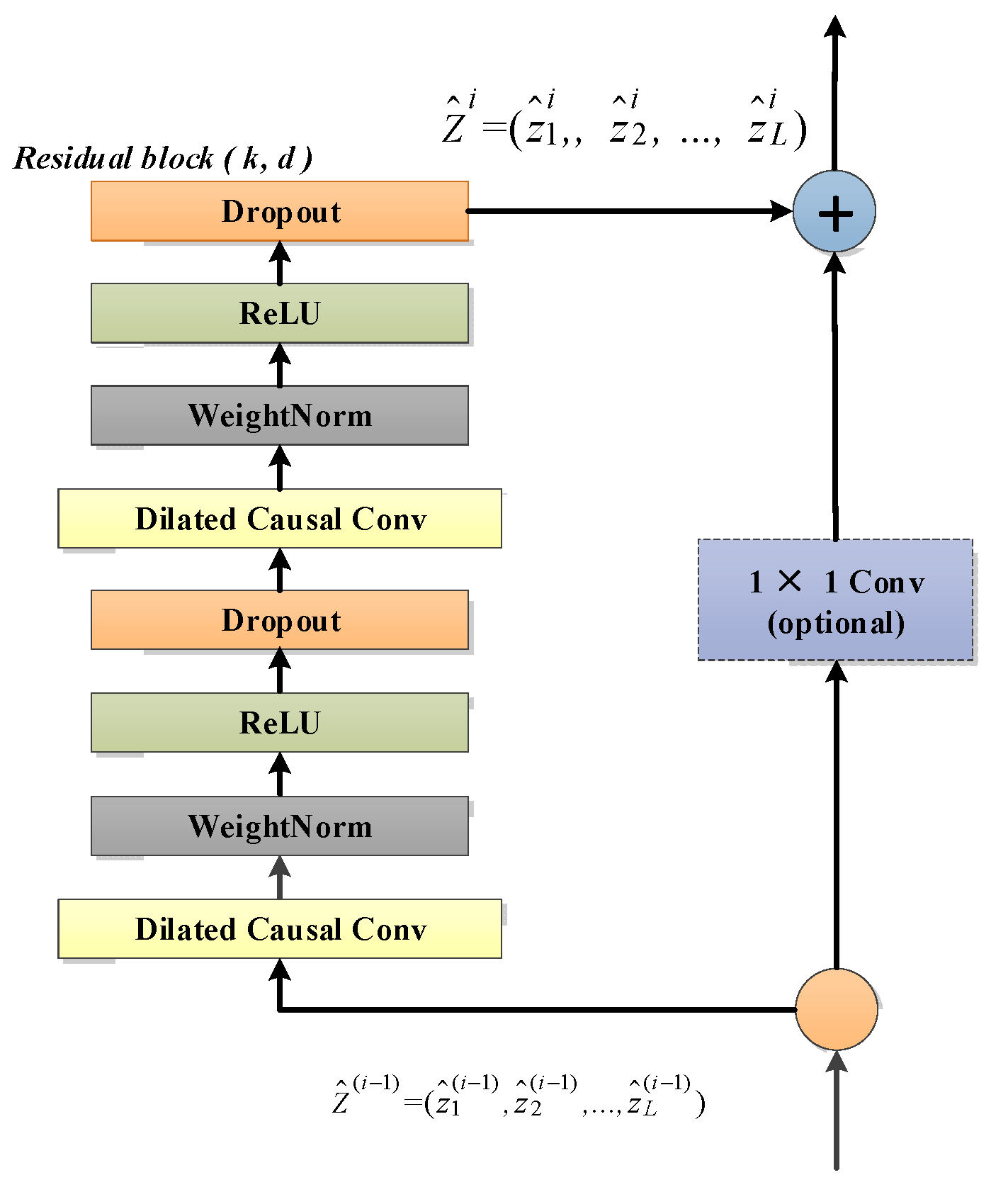
3.2.1. Temporal Convolution Network
3.2.2. Graph Attention Network
3.2.3. Loss Function
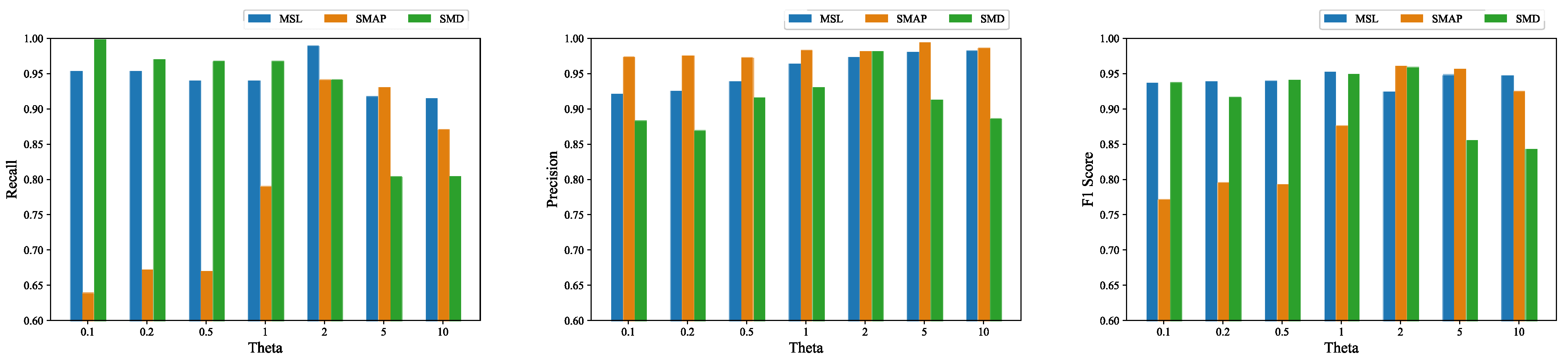
3.3. Automatic Threshold Selection Strategy
| Algorithm 2: GTAD Detection Algorithm |
| Input: Dataset X = {x1, …, xN}, parameter θ |
| Output: Labels y: {yM+1, …, yN} |
| for t = L to M do |
| _← GTAD (xt-L:t-1) |
| _← GTAD (xt-L+1:t) |
| end for |
| Threshold λ = threshold function (e1, …, eM) |
| for t = M + 1 to N do |
| , _← GTAD (xt-L:t-1) |
| _← GTAD (xt-L+1:t) |
| If et > λ then |
| yt = 1 |
| else |
| yt = 0 |
| end if |
| end for |
4. Experimental Evaluation
4.1. Datasets
4.2. Experimental Setup
4.3. Baseline Methods and Indicators Evaluation
4.4. Results
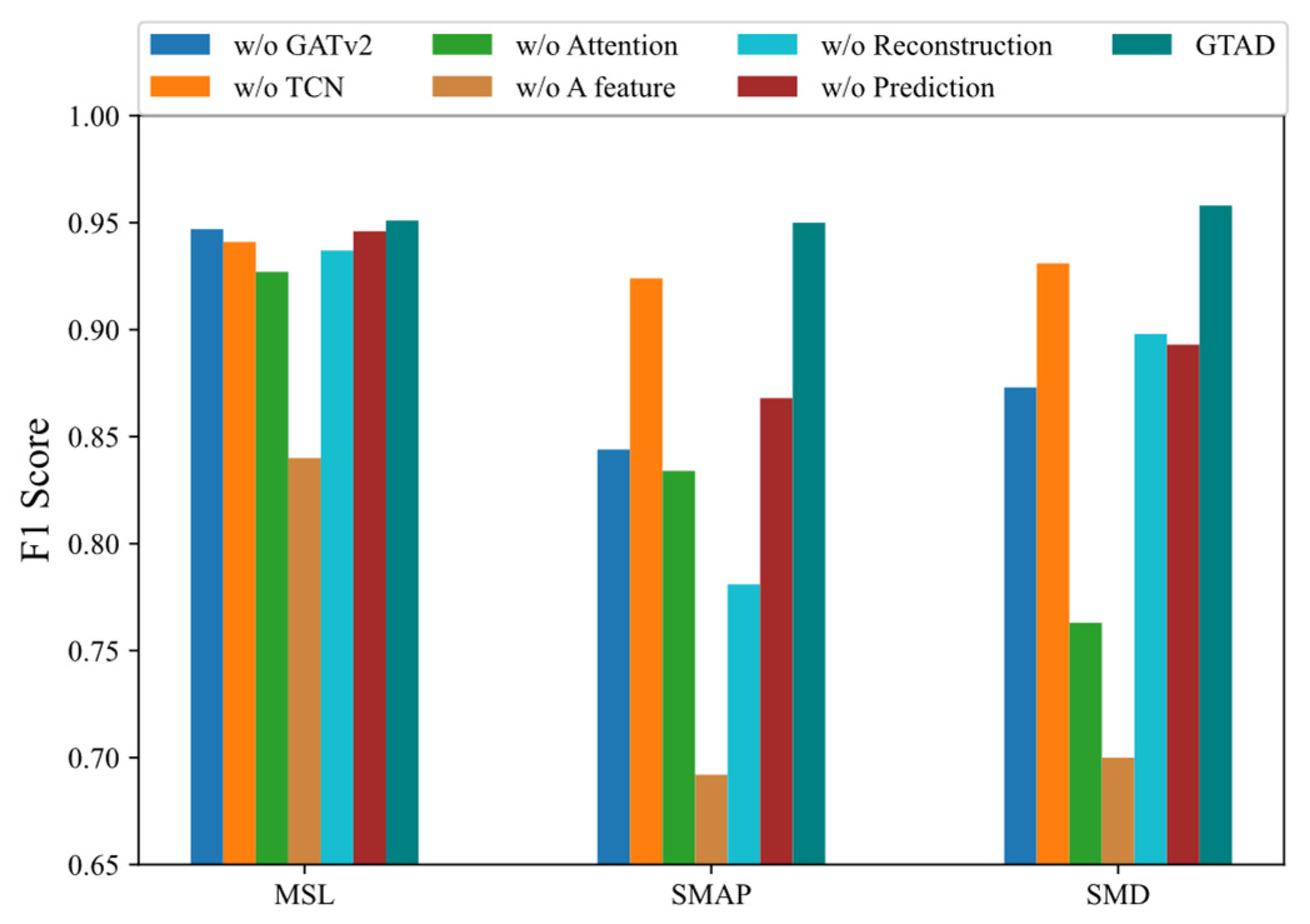
4.5. Ablation Analysis
- Using the prediction and reconstruction errors of all dimensions as a loss function and anomaly detection resulted in an average decrease of about 23% in the F1 score. The most notable of these was a 26% decrease on the SMAP dataset, implying that the loss in selecting a dimension was significant.
- When we removed GATv2 from GTAD, the F1 scores decreased by about 6%, indicating that GTAD could work well using the GATv2, taking into account the correlation of the time series.
- Without the attention mechanism, the F1 scores were reduced by 10% on average. This suggested that adding the attention mechanism allowed for more contextual information and facilitated reconstruction.
- The absence of TCN caused a decrease of about 2% in the F1 score, indicating that the TCN could capture temporal dependence and local features that could steadily improve the model performance.
- Both the prediction-based and reconstruction-based methods were less effective on their own than the integration of the two methods, demonstrating that GTAD could combine their advantages.
4.6. Sensitivity Analysis of Hyperparameters
4.7. Overhead Analysis
4.8. The Effectiveness of Automatic Threshold Selection
4.9. Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ren, H.; Xu, B.; Wang, Y.; Yi, C.; Huang, C.; Kou, X.; Xing, T.; Yang, M.; Tong, J.; Zhang, Q. Time-series anomaly detection service at microsoft. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 3009–3017. [Google Scholar]
- Chandola, V.; Mithal, V.; Kumar, V. Comparative evaluation of anomaly detection techniques for sequence data. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 5–19 December 2008; pp. 743–748. [Google Scholar]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, Y.; Wang, J.; Pan, Z. Unsupervised deep anomaly detection for multi-sensor time-series signals. IEEE Trans. Knowl. Data Eng. 2021. [Google Scholar] [CrossRef]
- Xu, H.; Chen, W.; Zhao, N.; Li, Z.; Bu, J.; Li, Z.; Liu, Y.; Zhao, Y.; Pei, D.; Feng, Y. Unsupervised anomaly detection via variational auto-encoder for seasonal kpis in web applications. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 187–196. [Google Scholar]
- Blázquez-García, A.; Conde, A.; Mori, U.; Lozano, J.A. A review on outlier/anomaly detection in time series data. ACM Comput. Surv. 2021, 54, 1–33. [Google Scholar] [CrossRef]
- Truong, H.T.; Ta, B.P.; Le, Q.A.; Nguyen, D.M.; Le, C.T.; Nguyen, H.X.; Do, H.T.; Nguyen, H.T.; Tran, K.P. Light-weight federated learning-based anomaly detection for time-series data in industrial control systems. Comput. Ind. 2022, 140, 103692. [Google Scholar] [CrossRef]
- Zhang, X.; Mu, J.; Zhang, X.; Liu, H.; Zong, L.; Li, Y. Deep anomaly detection with self-supervised learning and adversarial training. Pattern Recognit. 2022, 121, 108234. [Google Scholar] [CrossRef]
- Memarzadeh, M.; Matthews, B.; Avrekh, I. Unsupervised anomaly detection in flight data using convolutional variational auto-encoder. Aerospace 2020, 7, 115. [Google Scholar] [CrossRef]
- Hundman, K.; Constantinou, V.; Laporte, C.; Colwell, I.; Soderstrom, T. Detecting spacecraft anomalies using lstms and nonparametric dynamic thresholding. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 387–395. [Google Scholar]
- Thill, M.; Konen, W.; Wang, H.; Bäck, T. Temporal convolutional autoencoder for unsupervised anomaly detection in time series. Appl. Soft Comput. 2021, 112, 107751. [Google Scholar] [CrossRef]
- Shende, M.K.; Feijoo-Lorenzo, A.E.; Bokde, N.D. cleanTS: Automated (AutoML) Tool to Clean Univariate Time Series at Microscales. arXiv 2021, arXiv:2110.11815. [Google Scholar] [CrossRef]
- Zhou, Y.; Qin, R.; Xu, H.; Sadiq, S.; Yu, Y. A data quality control method for seafloor observatories: The application of observed time series data in the East China Sea. Sensors 2018, 18, 2628. [Google Scholar]
- Munir, M.; Siddiqui, S.A.; Dengel, A.; Ahmed, S. DeepAnT: A deep learning approach for unsupervised anomaly detection in time series. IEEE Access 2018, 7, 1991–2005. [Google Scholar] [CrossRef]
- Henríquez, J.; Kristjanpoller, W. A combined Independent Component Analysis–Neural Network model for forecasting exchange rate variation. Appl. Soft Comput. 2019, 83, 105654. [Google Scholar] [CrossRef]
- Parthasarathy, M.E.O.S. A dissimilarity measure for comparing subsets of data: Application to multivariate time series. Temporal Data Min. Alg. Theory Appl. 2005, 101, 1–12. [Google Scholar]
- Hautamaki, V.; Karkkainen, I.; Franti, P. Outlier detection using k-nearest neighbour graph. In Proceedings of the 17th International Conference on Pattern Recognition, Cambridge, UK, 26 August 2004; pp. 430–433. [Google Scholar]
- Mori, U.; Mendiburu, A.; Lozano, J.A. Distance Measures for Time Series in R: The TSdist Package. R J. 2016, 8, 451. [Google Scholar] [CrossRef] [Green Version]
- Breunig, M.M.; Kriegel, H.; Ng, R.T.; Sander, J. LOF: Identifying density-based local outliers. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 15–18 May 2000; pp. 93–104. [Google Scholar]
- Li, J.; Izakian, H.; Pedrycz, W.; Jamal, I. Clustering-based anomaly detection in multivariate time series data. Appl. Soft Comput. 2021, 100, 106919. [Google Scholar] [CrossRef]
- Lu, H.; Shi, J.; Fei, Z.; Zhou, Q.; Mao, K. Measures in the time and frequency domains for fitness landscape analysis of dynamic optimization problems. Appl. Soft Comput. 2017, 51, 192–208. [Google Scholar] [CrossRef]
- Wang, X.; Yu, F.; Pedrycz, W. An area-based shape distance measure of time series. Appl. Soft Comput. 2016, 48, 650–659. [Google Scholar] [CrossRef]
- Akouemo, H.N.; Povinelli, R.J. Probabilistic anomaly detection in natural gas time series data. Int. J. Forecast. 2016, 32, 948–956. [Google Scholar] [CrossRef] [Green Version]
- Hu, M.; Ji, Z.; Yan, K.; Guo, Y.; Feng, X.; Gong, J.; Zhao, X.; Dong, L. Detecting anomalies in time series data via a meta-feature based approach. IEEE Access 2018, 6, 27760–27776. [Google Scholar] [CrossRef]
- Hamilton, J.D. Time Series Analysis; Princeton University Press: Princeton, NJ, USA, 2020; ISBN 0691218633. [Google Scholar]
- Bianco, A.M.; Garcia Ben, M.; Martinez, E.J.; Yohai, V.J. Outlier detection in regression models with arima errors using robust estimates. J. Forecast. 2001, 20, 565–579. [Google Scholar] [CrossRef]
- Bashar, M.A.; Nayak, R. TAnoGAN: Time series anomaly detection with generative adversarial networks. In Proceedings of the 2020 IEEE Symposium Series on Computational Intelligence (SSCI), Canberra, Australia, 1–4 December 2020; pp. 1778–1785. [Google Scholar]
- Malhotra, P.; Ramakrishnan, A.; Anand, G.; Vig, L.; Agarwal, P.; Shroff, G. LSTM-based encoder-decoder for multi-sensor anomaly detection. arXiv 2016, arXiv:1607.00148. [Google Scholar]
- Su, Y.; Zhao, Y.; Niu, C.; Liu, R.; Sun, W.; Pei, D. Robust anomaly detection for multivariate time series through stochastic recurrent neural network. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2828–2837. [Google Scholar]
- Deng, A.; Hooi, B. Graph neural network-based anomaly detection in multivariate time series. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; pp. 4027–4035. [Google Scholar]
- Feng, C.; Tian, P. Time series anomaly detection for cyber-physical systems via neural system identification and bayesian filtering. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Virtual, 14–18 August 2021; pp. 2858–2867. [Google Scholar]
- Zhao, H.; Wang, Y.; Duan, J.; Huang, C.; Cao, D.; Tong, Y.; Xu, B.; Bai, J.; Tong, J.; Zhang, Q. Multivariate time-series anomaly detection via graph attention network. In Proceedings of the 2020 IEEE International Conference on Data Mining (ICDM), Sorrento, Italy, 17–20 November 2020; pp. 841–850. [Google Scholar]
- Shyu, M.; Chen, S.; Sarinnapakorn, K.; Chang, L. A Novel Anomaly Detection Scheme Based on Principal Component Classifier; Miami Univ Coral Gables Fl Dept of Electrical and Computer Engineering: Coral Gables, FL, USA, 2003. [Google Scholar]
- Cha, J. Partial least squares. In Advanced Methods of Marketing Research; Bagozzi, R.P., Ed.; Blackwell: Cambridge, MA, USA, 1994; pp. 52–78. [Google Scholar]
- He, Z.; Xu, X.; Deng, S. Discovering cluster-based local outliers. Pattern Recognit. Lett. 2003, 24, 1641–1650. [Google Scholar] [CrossRef]
- Ruff, L.; Vandermeulen, R.; Goernitz, N.; Deecke, L.; Siddiqui, S.A.; Binder, A.; Müller, E.; Kloft, M. Deep one-class classification. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 4393–4402. [Google Scholar]
- Chalapathy, R.; Menon, A.K.; Chawla, S. Anomaly detection using one-class neural networks. arXiv 2018, arXiv:1802.06360. [Google Scholar]
- Liu, F.T.; Ting, K.M.; Zhou, Z. Isolation Forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 413–422. [Google Scholar]
- Zong, B.; Song, Q.; Min, M.R.; Cheng, W.; Lumezanu, C.; Cho, D.; Chen, H. Deep autoencoding gaussian mixture model for unsupervised anomaly detection. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–31 May 2018. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Zhang, C.; Song, D.; Chen, Y.; Feng, X.; Lumezanu, C.; Cheng, W.; Ni, J.; Zong, B.; Chen, H.; Chawla, N.V. A deep neural network for unsupervised anomaly detection and diagnosis in multivariate time series data. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 1409–1416. [Google Scholar]
- Ergen, T.; Kozat, S.S. Unsupervised Anomaly Detection with LSTM Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 3127–3141. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, D.; Chen, D.; Jin, B.; Shi, L.; Goh, J.; Ng, S. MAD-GAN: Multivariate anomaly detection for time series data with generative adversarial networks. In Proceedings of the International Conference on Artificial Neural Networks, Munich, Germany, 17–19 September 2019; pp. 703–716. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Audibert, J.; Michiardi, P.; Guyard, F.; Marti, S.; Zuluaga, M.A. USAD: Unsupervised anomaly detection on multivariate time series. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual, 6–10 July 2020; pp. 3395–3404. [Google Scholar]
- Tuli, S.; Casale, G.; Jennings, N.R. TranAD: Deep Transformer Networks for Anomaly Detection in Multivariate Time Series Data. arXiv 2022, arXiv:2201.07284. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, A.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–15. [Google Scholar]
- Brody, S.; Alon, U.; Yahav, E. How attentive are graph attention networks? arXiv 2021, arXiv:2105.14491. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Variables | Train | Test | Anomalies (%) |
|---|---|---|---|---|
| SMAP | 25 | 135,183 | 427,617 | 13.13 |
| MSL | 55 | 58,317 | 73,729 | 10.27 |
| SMD | 38 | 708,405 | 708,420 | 4.16 |
| Method | MSL | ||
|---|---|---|---|
| Precision | Recall | F1 Score | |
| DAGMM | 0.5412 | 0.9934 | 0.7007 |
| MSCRED | 0.8912 | 0.9862 | 0.9363 |
| USAD | 0.7949 | 0.9912 | 0.8822 |
| MTAD-GAT | 0.7917 | 0.9824 | 0.8767 |
| OmniAnomaly | 0.8867 | 0.9117 | 0.8989 |
| GDN | 0.9308 | 0.9892 | 0.9591 |
| MAD-GAN | 0.8517 | 0.8991 | 0.8747 |
| GTAD | 0.9668 | 0.9413 | 0.9539 |
| Method | SMAP | ||
| Precision | Recall | F1 Score | |
| DAGMM | 0.5845 | 0.9058 | 0.7105 |
| MSCRED | 0.8175 | 0.9216 | 0.8664 |
| USAD | 0.7480 | 0.9627 | 0.8419 |
| MTAD-GAT | 0.7991 | 0.9991 | 0.8880 |
| OmniAnomaly | 0.7416 | 0.9776 | 0.8434 |
| GDN | 0.7480 | 0.9891 | 0.8518 |
| MAD-GAN | 0.8049 | 0.8214 | 0.8131 |
| GTAD | 0.9821 | 0.9426 | 0.9620 |
| Method | SMD | ||
| Precision | Recall | F1 Score | |
| DAGMM | 0.9869 | 0.8174 | 0.8942 |
| MSCRED | 0.8164 | 0.7261 | 0.7686 |
| USAD | 0.9858 | 0.8174 | 0.8937 |
| MTAD-GAT | 0.7609 | 0.9999 | 0.8643 |
| OmniAnomaly | 0.8854 | 0.8827 | 0.8531 |
| GDN | 0.7754 | 0.7286 | 0.7513 |
| MAD-GAN | 0.9750 | 0.8827 | 0.9265 |
| GTAD | 0.9515 | 0.9690 | 0.9601 |
| Methods | MSL | SMAP | SMD |
|---|---|---|---|
| DAGMM | 3.06 | 7.04 | 37.36 |
| MSCERD | 231.47 | 416.51 | 3332.12 |
| USAD | 2.78 | 6.35 | 34.08 |
| MTAD-GAT | 3.91 | 8.72 | 43.89 |
| OmniAnomaly | 5.83 | 13.05 | 70.72 |
| GDN | 4.57 | 10.72 | 53.51 |
| MAD-GAN | 7.84 | 18.66 | 86.68 |
| GTAD | 3.73 | 7.16 | 37.96 |
| Mothed | MSL | SMAP | SMD |
|---|---|---|---|
| F1 score-NDT | 0.9539 | 0.9620 | 0.9601 |
| F1 score-best | 0.9544 | 0.9634 | 0.9732 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guan, S.; Zhao, B.; Dong, Z.; Gao, M.; He, Z. GTAD: Graph and Temporal Neural Network for Multivariate Time Series Anomaly Detection. Entropy 2022, 24, 759. https://doi.org/10.3390/e24060759
Guan S, Zhao B, Dong Z, Gao M, He Z. GTAD: Graph and Temporal Neural Network for Multivariate Time Series Anomaly Detection. Entropy. 2022; 24(6):759. https://doi.org/10.3390/e24060759
Chicago/Turabian StyleGuan, Siwei, Binjie Zhao, Zhekang Dong, Mingyu Gao, and Zhiwei He. 2022. "GTAD: Graph and Temporal Neural Network for Multivariate Time Series Anomaly Detection" Entropy 24, no. 6: 759. https://doi.org/10.3390/e24060759
APA StyleGuan, S., Zhao, B., Dong, Z., Gao, M., & He, Z. (2022). GTAD: Graph and Temporal Neural Network for Multivariate Time Series Anomaly Detection. Entropy, 24(6), 759. https://doi.org/10.3390/e24060759