
Inter- and Intra-Modal Contrastive Hybrid Learning Framework for Multimodal Abstractive Summarization


Abstract
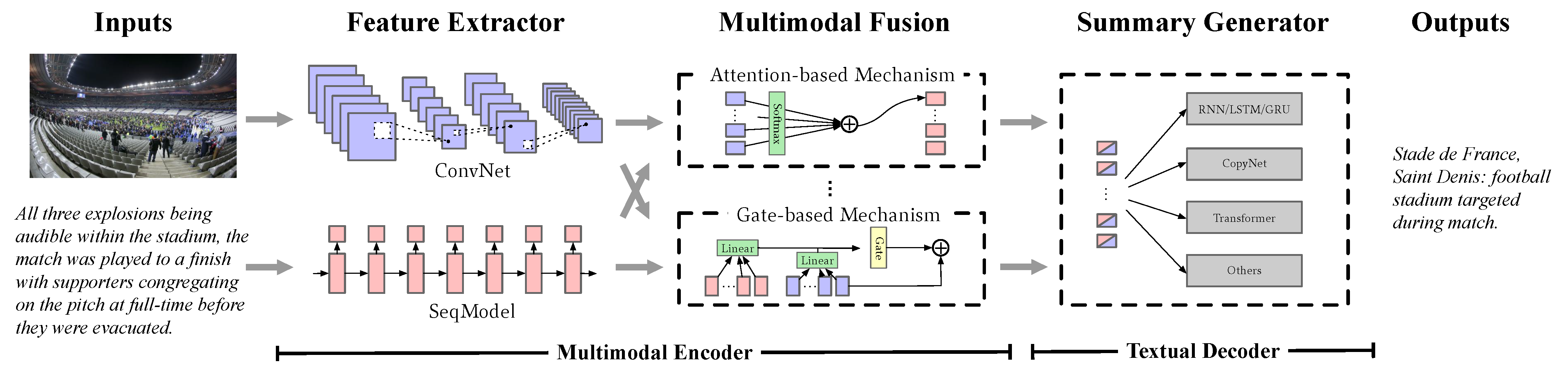
:1. Introduction
- (1)
- An ITCH framework is proposed for tackling multimodal abstractive summarization in a supervised approach. Moreover, with ITCH as a component and integrated into an existing system, it is appropriate for unsupervised learning environments.
- (2)
- A cross-modal fusion module is designed for obtaining textually enhanced representation. It merges contextual vision and language information, and makes visual features align to textual representation.
- (3)
- The objectives of the inter-modal and intra-modal frameworks are integrated with a reconstruction objective in summary generation. The inter-modal objective measures consistency for input images and texts, while the intra-modal objective maintains the semantic similarity between input sentences and output summary.
2. Related Work
2.1. Visual and Semantic Feature Extractors
2.2. Multimodal Fusion Methods
2.3. Methods for Abstractive Summarization
2.4. Contrastive Learning
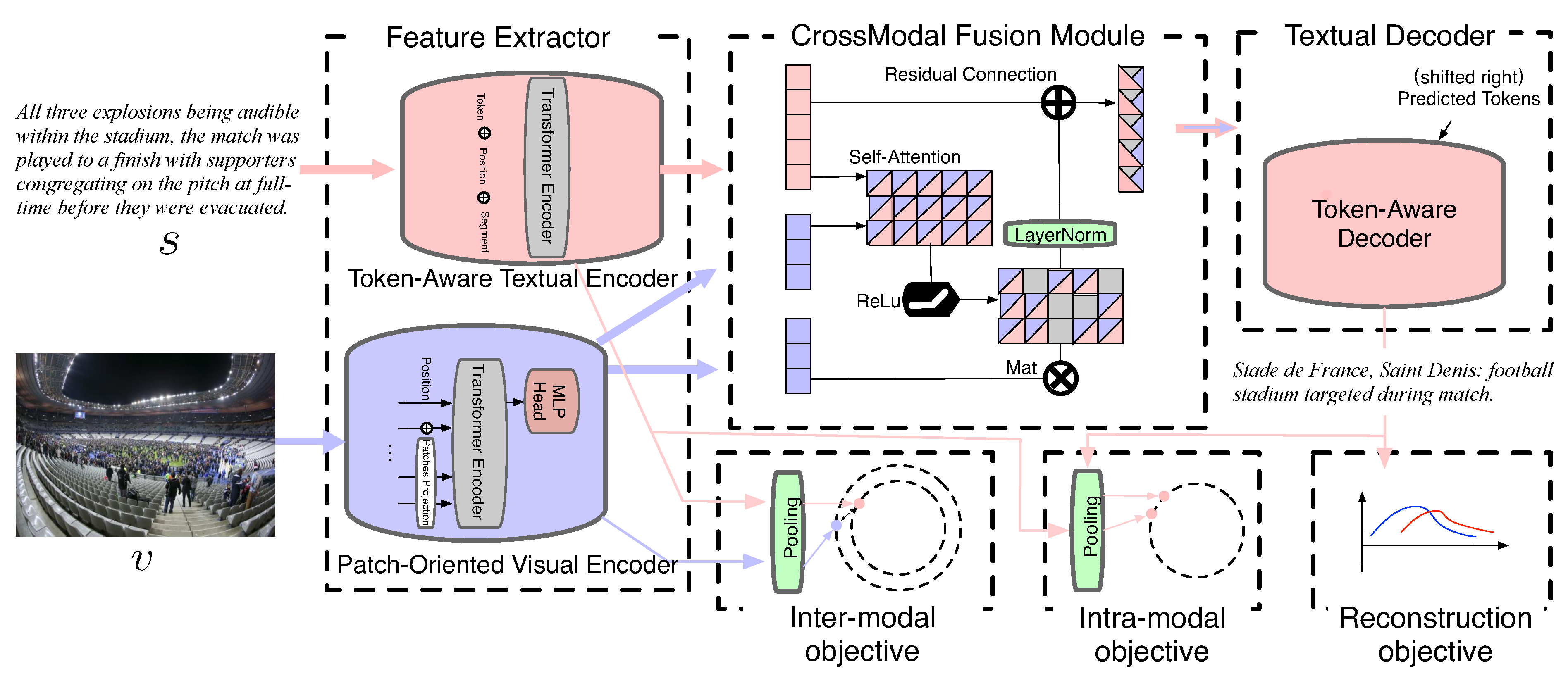
3. The ITCH Framework
3.1. Visual and Textual Feature Extractor
3.2. Cross-Modal Fusion Module
3.3. Textual Decoder
3.4. Hybrid Contrastive Objectives
3.5. Unsupervised Learning Combined with ITCH
- (1)
- The input and output of the whole model changes from to . The supervised ITCH takes bi-modal inputs to generate a summary directly, while the unsupervised ITCH generates a summary in the middle of the whole model and takes these sequences to reconstruct the input text.
- (2)
- Additional transformers, and , are added for reconstructing input sentences, while the supervised ITCH does not consider and .
4. Experiment
4.1. Setup
4.2. Evaluation Metrics and Baselines
4.2.1. Evaluation Metrics
- ROUGE [57]: the standard metric to calculate the scores between the generated summary and the target sentences using the recall and precision overlaps (details are R-N and R-L). R-N refers to an N-gram recall between a candidate summary and a set of reference summaries. R-N is computed as follows:where N means the length of N-gram, and and are the maximum number of N-grams co-occurring in a candidate summary and a set of reference summaries. Here, we selected R-1 and R-2 as the evaluation metrics. R-L uses longest-common-subsequence (LCS)-based F-measure to estimate the similarity between two summaries. The longer the LCS of the two summaries is, the more similar the two summaries are.
- Relevance [58]: we used embedding-based metrics to evaluate the similarity of the generated summary and the target summary. In particular, Embedding Average and Embedding Extrema use the mean embedding and max-pooled embedding to compute the cosine similarity. Embedding Greedy does not pool word embeddings but greedily finds the best matching words. These metrics are used to measure the semantic similarity of the generated summary and the ground-truth.
- Human: we invited twelve native speakers to evaluate the generated summary according to fluency and relevancy. The judges can give a score from 0 to 4, as detailed in Table 3. We randomly sampled 100 results for each dataset and divided them into four batches. The judges were broken into four groups and each batch of samples was annotated by two groups of judges. For each sample, we used above two ratings for each aspect (fluency or relevance) and we took the average as the final rating. The male-to-female ratio was 1:1. Within a batch, if the ratings differed substantially between the two groups of judges, a third group of judges would be invited to annotate the batch. The judges did not have access to the ground-truth response, and saw only the inputs and the predicted summary.
4.2.2. Baselines
4.3. Experimental Results and Analysis
4.4. Ablation Analysis
5. Case Study
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNN | Convolutional neural network |
| CV | Computer vision |
| GRU | Gated recurrent unit |
| InfoNCE | Information NCE |
| ITCH | Inter- and intra-modal contrastive hybrid learning framework |
| LCS | Longset common subsequence |
| LSTM | Long short-term memory |
| MAS | Multimodal abstractive summarization |
| NCE | Noise-contrastive estimation |
| NLP | Natural language processing |
| RNN | Recurrent neural network |
References
- Gupta, A.; Chugh, D.; Katarya, R. Automated news summarization using transformers. In Sustainable Advanced Computing; Springer: Berlin/Heidelberg, Germany, 2022; pp. 249–259. [Google Scholar]
- Sanabria, R.; Caglayan, O.; Palaskar, S.; Elliott, D.; Barrault, L. How2: A Large-scale Dataset For Multimodal Language Understanding. In Proceedings of the ViGIL, NeurIPS, Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Liu, N.; Sun, X.; Yu, H. Multistage Fusion with Forget Gate for Multimodal Summarization in Open-Domain Videos. In Proceedings of the EMNLP, Online, 16–20 November 2020; pp. 1834–1845. [Google Scholar]
- Baziotis, C.; Androutsopoulos, I.; Konstas, I.; Potamianos, A. SEQ3: Differentiable Sequence-to-Sequence-to-Sequence Autoencoder for Unsupervised Abstractive Sentence Compression. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, Minnesota, 2–7 June 2019; Association for Computational Linguistics: Minneapolis, Minnesota, 2019; pp. 673–681. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, Z.; Li, J.; Liu, Q.; Zhu, H. CtnR: Compress-then-Reconstruct Approach for Multimodal Abstractive Summarization. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Kato, T.; Matsushita, M.; Kando, N. MuST: Workshop on MUltimodal Summarization for Trend Information. In Proceedings of the NTCIR, Tokyo, Japan, 6–9 December 2005. [Google Scholar]
- Zhu, J.; Zhou, Y.; Zhang, J.; Li, H.; Zong, C.; Li, C. Multimodal summarization with guidance of multimodal reference. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 9749–9756. [Google Scholar]
- Chen, J.; Hu, H.; Wu, H.; Jiang, Y.; Wang, C. Learning the Best Pooling Strategy for Visual Semantic Embedding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Libovický, J.; Helcl, J. Attention Strategies for Multi-Source Sequence-to-Sequence Learning. In Proceedings of the ACL, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 196–202. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. Adv. Neural Inf. Process. Syst. 2014, 27, 3104–3112. [Google Scholar]
- Gu, J.; Lu, Z.; Li, H.; Li, V.O. Incorporating Copying Mechanism in Sequence-to-Sequence Learning. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Volume 1: Long Papers, Berlin, Germany, 7–12 August 2016; Association for Computational Linguistics: Berlin, Germany, 2016; pp. 1631–1640. [Google Scholar] [CrossRef] [Green Version]
- Dong, L.; Yang, N.; Wang, W. Unified Language Model Pre-training for Natural Language Understanding and Generation. arXiv 2019, arXiv:1905.03197. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the ACL, Online, 5–10 July 2020; pp. 7871–7880. [Google Scholar]
- Qi, W.; Yan, Y.; Gong, Y.; Liu, D. Prophetnet: Predicting future n-gram for sequence-to-sequence pre-training. In Proceedings of the EMNLP: Findings, Online Event, 16–20 November 2020; pp. 2401–2410. [Google Scholar]
- Tu, R.C.; Ji, L.; Luo, H.; Shi, B.; Huang, H.; Duan, N.; Mao, X.L. Hashing based Efficient Inference for Image-Text Matching. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online Event, 1–6 August 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 743–752. [Google Scholar] [CrossRef]
- Zhong, M.; Liu, P.; Chen, Y.; Wang, D.; Qiu, X.; Huang, X. Extractive Summarization as Text Matching. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 6197–6208. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, P. SimCLS: A Simple Framework for Contrastive Learning of Abstractive Summarization. In Proceedings of the ACL/IJCNLP, Bangkok, Thailand, 1–6 August 2021. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, Minnesota, 2–7 June 2019; Association for Computational Linguistics: Minneapolis, Minnesota, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Cho, K.; van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 1724–1734. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: New York, NY, USA, 2017; Volume 30. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Contextualized Word Representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), New Orleans, LA, USA, 2–7 June 2018; Association for Computational Linguistics: New Orleans, Louisiana, 2018; pp. 2227–2237. [Google Scholar] [CrossRef] [Green Version]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D. Language Models are Few-Shot Learners. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: New York, NY, USA, 2015; Volume 28. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; pp. 770–778. [Google Scholar]
- Nojavanasghari, B.; Gopinath, D.; Koushik, J.; Baltrušaitis, T.; Morency, L.P. Deep multimodal fusion for persuasiveness prediction. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; pp. 284–288. [Google Scholar]
- Zadeh, A.; Liang, P.P.; Mazumder, N.; Poria, S.; Cambria, E.; Morency, L.P. Memory fusion network for multi-view sequential learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Li, R.; Wu, X.; Li, A.; Wang, M. HFBSurv: Hierarchical multimodal fusion with factorized bilinear models for cancer survival prediction. Bioinformatics 2022, 38, 2587–2594. [Google Scholar] [CrossRef] [PubMed]
- Pruthi, D.; Gupta, M.; Dhingra, B.; Neubig, G.; Lipton, Z.C. Learning to Deceive with Attention-Based Explanations. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 4782–4793. [Google Scholar] [CrossRef]
- Liu, Z.; Shen, Y.; Lakshminarasimhan, V.B.; Liang, P.P.; Bagher Zadeh, A.; Morency, L.P. Efficient Low-rank Multimodal Fusion With Modality-Specific Factors. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; Association for Computational Linguistics: Melbourne, Australia, 2018; pp. 2247–2256. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Fan, Q.; Zhang, S.; Dong, H.; Funkhouser, T.; Yi, L. Contrastive Multimodal Fusion With TupleInfoNCE. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 754–763. [Google Scholar]
- Wang, Y.; Huang, W.; Sun, F.; Xu, T.; Rong, Y.; Huang, J. Deep Multimodal Fusion by Channel Exchanging. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 4835–4845. [Google Scholar]
- Evangelopoulos, G.; Zlatintsi, A.; Potamianos, A.; Maragos, P.; Rapantzikos, K.; Skoumas, G.; Avrithis, Y. Multimodal saliency and fusion for movie summarization based on aural, visual, and textual attention. IEEE Trans. Multimed. 2013, 15, 1553–1568. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Zhu, J.; Ma, C.; Zhang, J.; Zong, C. Multi-modal summarization for asynchronous collection of text, image, audio and video. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 1092–1102. [Google Scholar]
- Sanabria, M.; Precioso, F.; Menguy, T. A deep architecture for multimodal summarization of soccer games. In Proceedings of the 2nd International Workshop on Multimedia Content Analysis in Sports, Seattle, WA, USA, 12–16 October 2019; pp. 16–24. [Google Scholar]
- Zhu, J.; Li, H.; Liu, T.; Zhou, Y.; Zhang, J. MSMO: Multimodal Summarization with Multimodal Output. In Proceedings of the EMNLP, Brussels, Belgium, 31 October–4 November 2018; pp. 4154–4164. [Google Scholar]
- Li, H.; Zhu, J.; Zhang, J.; He, X.; Zong, C. Multimodal Sentence Summarization via Multimodal Selective Encoding. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; International Committee on Computational Linguistics: Barcelona, Spain, 2020; pp. 5655–5667. [Google Scholar] [CrossRef]
- Zhu, J.; Xiang, L.; Zhou, Y.; Zhang, J.; Zong, C. Graph-based Multimodal Ranking Models for Multimodal Summarization. Trans. Asian Low-Resour. Lang. Inf. Process. 2021, 20, 1–21. [Google Scholar] [CrossRef]
- Gutmann, M.; Hyvärinen, A. Noise-contrastive estimation: A new estimation principle for unnormalized statistical models. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics. JMLR Workshop and Conference Proceedings, Sardinia, Italy, 3–15 May 2010; pp. 297–304. [Google Scholar]
- Oord, A.v.d.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Chen, X.; Fan, H.; Girshick, R.; He, K. Improved baselines with momentum contrastive learning. arXiv 2020, arXiv:2003.04297. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. arXiv 2020, arXiv:2002.05709. [Google Scholar]
- Yan, Y.; Li, R.; Wang, S.; Zhang, F.; Wu, W.; Xu, W. ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Bangkok, Thailand, 1–6 August 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 5065–5075. [Google Scholar] [CrossRef]
- Gao, T.; Yao, X.; Chen, D. SimCSE: Simple Contrastive Learning of Sentence Embeddings. In Proceedings of the Empirical Methods in Natural Language Processing (EMNLP), Punta Cana, Dominican Republic, 7–11 November 2021. [Google Scholar]
- Li, X.; Yin, X.; Li, C.; Zhang, P.; Hu, X.; Zhang, L.; Wang, L.; Hu, H.; Dong, L.; Wei, F.; et al. Oscar: Object-semantics aligned pre-training for vision-language tasks. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 121–137. [Google Scholar]
- Lei, J.; Li, L.; Zhou, L.; Gan, Z.; Berg, T.L.; Bansal, M.; Liu, J. Less is more: Clipbert for video-and-language learning via sparse sampling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 2–25 June 2021; pp. 7331–7341. [Google Scholar]
- Yuan, X.; Lin, Z.; Kuen, J.; Zhang, J.; Wang, Y.; Maire, M.; Kale, A.; Faieta, B. Multimodal contrastive training for visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 2–25 June 2021; pp. 6995–7004. [Google Scholar]
- Miech, A.; Alayrac, J.B.; Smaira, L.; Laptev, I.; Sivic, J.; Zisserman, A. End-to-end learning of visual representations from uncurated instructional videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9879–9889. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Qu, L.; Liu, M.; Cao, D.; Nie, L.; Tian, Q. Context-aware multi-view summarization network for image-text matching. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1047–1055. [Google Scholar]
- Li, H.; Zhu, J.; Liu, T.; Zhang, J.; Zong, C. Multi-modal Sentence Summarization with Modality Attention and Image Filtering. In Proceedings of the IJCAI, Stockholm, Sweden, 13–19 July 2018; pp. 4152–4158. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. EMNLP-IJCNLP 2019, 3980–3990. [Google Scholar] [CrossRef] [Green Version]
- Lin, C.Y. ROUGE: A Package for Automatic Evaluation of Summaries. In Proceedings of the Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004; pp. 74–81. [Google Scholar]
- Liu, C.W.; Lowe, R.; Serban, I.; Noseworthy, M.; Charlin, L.; Pineau, J. How NOT To Evaluate Your Dialogue System: An Empirical Study of Unsupervised Evaluation Metrics for Dialogue Response Generation. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; Association for Computational Linguistics: Austin, TX, USA, 2016; pp. 2122–2132. [Google Scholar] [CrossRef] [Green Version]
- Erkan, G.; Radev, D.R. Lexrank: Graph-based lexical centrality as salience in text summarization. J. Artif. Intell. Res. 2004, 22, 457–479. [Google Scholar] [CrossRef]
- Ha, T.T.; Nguyen, T.C.; Nguyen, K.H.; Vu, V.C.; Nguyen, K.A. Unsupervised Sentence Embeddings for Answer Summarization in Non-factoid CQA. Comput. Sist. 2018, 22, 835–843. [Google Scholar] [CrossRef]
- See, A.; Liu, P.J.; Manning, C.D. Get To The Point: Summarization with Pointer-Generator Networks. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; Association for Computational Linguistics: Vancouver, BC, Canada, 2017; pp. 1073–1083. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Peng, Z.; Tang, S.; Zhang, C.; Ma, H. Text Summarization Method Based on Double Attention Pointer Network. IEEE Access 2020, 8, 11279–11288. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | #Train | #Valid | #Test | #MaxLength |
|---|---|---|---|---|
| MMS | 62,000 | 2000 | 2000 | 439 |
| MSMO | 240,000 | 3000 | 3000 | 492 |
| Symbol | Annotation | Value | Symbol | Annotation | Value |
|---|---|---|---|---|---|
| E | Word embedding size | 300 | EP | Number of epochs | 30 |
| V | Vocabulary size | 30,004 | DR | Dropout rate | 0.3 |
| D | Dimension of feature | 768 | Adjustable factor | −0.15 | |
| Batch size | 128 | Temperature parameter | 0.1 | ||
| LR0 | For pre-trained modules | 2 × 10 | LR1 | For other modules | 2 × 10 |
| Fluency (F) | Relevance (R) | ||
|---|---|---|---|
| Points | Explanations | Points | Explanations |
| 1 | Hard to read | 1 | Totally irrelevant |
| 2 | Not quite fluent and containing several grammatical errors | 2 | Marginally relevant |
| 3 | Fluent response with few errors | 3 | Somewhat relevant but not directly related to the query |
| 4 | Fluent response without errors | 4 | Relevant |
| Types | Resource | Methods | ROUGE | Relevance | Human | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| uni- | bi- | R-1 | R-2 | R-L | Average | Extrema | Greedy | F | R | ||
| ✓ | LexRank [59] | 32.54 | 9.96 | 28.02 | 0.277 | 0.204 | 0.278 | 2.72 | 3.02 | ||
| ✓ | W2VLSTM [60] | 29.86 | 13.11 | 27.68 | 0.278 | 0.201 | 0.296 | 2.54 | 2.82 | ||
| Unsupervised | ✓ | Seq3 [4] | 38.16 | 13.58 | 32.07 | 0.347 | 0.245 | 0.342 | 3.14 | 3.28 | |
| ✓ | GuideRank [39] | 37.13 | 15.03 | 36.18 | 0.332 | 0.231 | 0.341 | 3.12 | 3.31 | ||
| ✓ | CTNR [5] | 40.11 | 16.97 | 39.71 | 0.372 | 0.271 | 0.386 | 3.32 | 3.44 | ||
| ✓ | MMR [41] | 41.72 | 17.33 | 39.81 | 0.381 | 0.269 | 0.391 | 3.39 | 3.39 | ||
| ✓ | ITCH | 43.77 | 21.62 | 44.02 | 0.393 | 0.296 | 0.401 | 3.46 | 3.42 | ||
| ✓ | S2S [10] | 32.32 | 12.44 | 29.65 | 0.292 | 0.209 | 0.287 | 3.24 | 3.32 | ||
| ✓ | PointerNet [61] | 34.62 | 13.72 | 30.05 | 0.339 | 0.267 | 0.352 | 3.21 | 3.41 | ||
| Supervised | ✓ | UniLM [12] | 42.32 | 22.04 | 40.03 | 0.443 | 0.308 | 0.438 | 3.71 | 3.54 | |
| ✓ | Doubly-Attn [62] | 41.11 | 21.75 | 39.92 | 0.434 | 0.297 | 0.433 | 3.46 | 3.52 | ||
| ✓ | Select [40] | 46.25 | 24.68 | 44.02 | 0.466 | 0.331 | 0.471 | 3.62 | 3.59 | ||
| ✓ | ITCH | 47.78 | 25.39 | 46.82 | 0.476 | 0.342 | 0.484 | 3.67 | 3.63 | ||
| Types | Resource | Methods | ROUGE | Relevance | Human | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| uni- | bi- | R-1 | R-2 | R-L | Average | Extrema | Greedy | F | R | ||
| ✓ | LexRank [59] | 36.52 | 9.16 | 27.66 | 0.264 | 0.192 | 0.271 | 2.86 | 3.17 | ||
| ✓ | W2VLSTM [60] | 29.14 | 9.77 | 28.11 | 0.272 | 0.202 | 0.283 | 2.71 | 2.92 | ||
| Unsupervised | ✓ | Seq3 [4] | 36.42 | 10.22 | 34.91 | 0.339 | 0.221 | 0.341 | 3.21 | 3.24 | |
| ✓ | GuideRank [39] | 35.31 | 10.11 | 33.91 | 0.302 | 0.211 | 0.312 | 3.01 | 3.15 | ||
| ✓ | CTNR [5] | 39.69 | 13.16 | 39.22 | 0.371 | 0.254 | 0.357 | 3.37 | 3.37 | ||
| ✓ | MMR [41] | 41.29 | 16.75 | 38.29 | 0.382 | 0.269 | 0.393 | 3.43 | 3.41 | ||
| ✓ | ITCH | 44.61 | 18.91 | 42.72 | 0.396 | 0.301 | 0.399 | 3.49 | 3.41 | ||
| ✓ | S2S [10] | 30.81 | 11.72 | 28.23 | 0.285 | 0.202 | 0.278 | 3.24 | 3.32 | ||
| ✓ | PointerNet [61] | 35.61 | 14.64 | 33.62 | 0.345 | 0.271 | 0.355 | 3.32 | 3.46 | ||
| Supervised | ✓ | UniLM [12] | 41.82 | 20.82 | 39.83 | 0.451 | 0.311 | 0.459 | 3.73 | 3.57 | |
| ✓ | Doubly-Attn [62] | 39.82 | 19.72 | 38.21 | 0.438 | 0.302 | 0.431 | 3.44 | 3.54 | ||
| ✓ | Select [40] | 45.63 | 23.68 | 42.97 | 0.466 | 0.327 | 0.473 | 3.64 | 3.55 | ||
| ✓ | MMAF [55] | 47.28 | 24.85 | 44.48 | 0.472 | 0.336 | 0.480 | - | - | ||
| ✓ | MMCF [55] | 46.84 | 24.25 | 43.76 | 0.470 | 0.335 | 0.476 | - | - | ||
| ✓ | ITCH | 48.62 | 26.73 | 46.93 | 0.487 | 0.351 | 0.493 | 3.68 | 3.61 | ||
| Unsupervised | Supervised | |||||
|---|---|---|---|---|---|---|
| Methods | ROUGE | Relevance | M | ROUGE | Relevance | M |
| ITCH | 36.47 | 0.363 | 0.547 | 39.99 | 0.434 | 0.623 |
| Default | ||||||
| ITCH () | 36.31 ↓ | 0.357 ↓ | 0.541 ↓ | 39.49 ↓ | 0.431 ↓ | 0.618 ↓ |
| ITCH () | 35.23 ↓ | 0.343 ↓ | 0.511 ↓ | 39.02 ↓ | 0.424 ↓ | 0.611 ↓ |
| ITCH () | 33.28 ↓ | 0.318 ↓ | 0.436 ↓ | 37.66 ↓ | 0.397 ↓ | 0.528 ↓ |
| ITCH () | 31.74 ↓ | 0.394 ↓ | 0.402 ↓ | 36.81 ↓ | 0.389 ↓ | 0.503 ↓ |
| Default | ||||||
| ITCH () | 35.62 ↓ | 0.347 ↓ | 0.556 ↑ | 38.74 ↓ | 0.418 ↓ | 0.634 ↑ |
| ITCH () | 35.17 ↓ | 0.339 ↓ | 0.493 ↓ | 37.87 ↓ | 0.401 ↓ | 0.589 ↓ |
| Unsupervised | Supervised | ||||||
|---|---|---|---|---|---|---|---|
| Methods | ROUGE | Relevance | M | Methods | ROUGE | Relevance | M |
| ITCH | 36.47 | 0.363 | 0.547 | ITCH | 39.99 | 0.434 | 0.623 |
| MMR | 32.95 | 0.347 | 0.382 | Select | 38.32 | 0.423 | 0.452 |
| - | 34.18 | 0.359 | 0.389 | - | 38.66 | 0.427 | 0.471 |
| - | 33.71 | 0.350 | 0.443 | - | 38.89 | 0.428 | 0.581 |
| - | 30.11 | 0.336 | 0.301 | - | 36.91 | 0.396 | 0.449 |
| - CrossFusion | 32.71 | 0.343 | 0.408 | - CrossFusion | 38.51 | 0.425 | 0.518 |
| Input | Text | Zika is primarily spread by mosquitoes but can also be transmitted through unprotected sex with an infect- ed person. Almost daily downpours, average temperature of 30 degrees Celsius (86 degrees Fahrenheit), large green areas in a populated urban setting makes Singapore a hospita- ble area for mosquitoes. So Singapore is the only Asian country with active transmission of the mosquitoborne Zika virus, the US, Australia, Taiwan and South Korea have all issued alerts advising pregnant women against traveling to Singapore. Singapore is known to suffer wi- dely from dengue virus, a mosquito-borne tropical dis- ease that triggers high fevers, headaches, vomiting and skin rashes in those infected to a considerable extent and therefore may be mistaken for another. Singapore’s government has a long history of using aggressive spraying, information campaigns and heavy fines for homeowners who leave water vesse in the open, in a bid to control mosquito-borne dengue. Indoor spray, misting and oiling were conducted, and daily misting of common areas is ongoing, hundreds of specialist workers conduct island-wide inspections for mosquito breeding g- rounds, spray insecticide and clear stagnant water. | Image |  | |||
| TargetSummary | Singapore has suffered from the Zika virus and dengue virus, both of them are mosquitoborne disease with high fevers. The government employ aggressive spraying and information campaign to prevent its spread. | ||||||
| Types | Methods | Generated Summary | R-1 | R-2 | R-L | M | |
| LexRank | Singapore is known to suffer widely from virus, a mosquitoborne tropical disease that trigger high fevers, vomiting and skin rashes in infected. | 25.8 | 4.0 | 24.1 | 0.36 | ||
| Unsupervised | GuidRank | Singapore is the Asian country with active transmission of <> virus and dengue virus. They mimic each other to a considerable extent. | 29.3 | 11.7 | 20.7 | 0.42 | |
| CTNR | Singapore is known to suffer from <>, a tropical disease that <> fevers in infected. It spread by and government use spread mosquitoes. | 32.2 | 13.6 | 27.6 | 0.40 | ||
| Output | ITCH | The Singapore in <> and dengue virus, and are <> disease with fevers. They employ spraying campaign to prevent. | 48.3 | 25.0 | 44.8 | 0.52 | |
| PointNet | The Singapore’s government aggressive spray and information prevent zika and dengue virus. | 33.7 | 21.5 | 27.5 | 0.41 | ||
| Supervised | UniLM | Zika is primarily spread by <> and dengue virus tropical disease that triggers high fevers. They may be mistaken for another. The Singapore’s employing spraying and campaign to prevent and altering travelers. | 42.0 | 19.7 | 38.1 | 0.44 | |
| Select | The Singapore taking spraying and information campaign to prevent <unk> virus. It suffering from virus that are fevers and transmission. | 52.1 | 27.9 | 29.6 | 0.51 | ||
| ITCH | The Singapore take aggressive spraying, indoor spraying and information campaign to prevent <> virus and dengue virus spread. They are <> disease with high fevers and transmission. | 61.3 | 42.1 | 61.0 | 0.69 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Zhang, Z.; Wang, B.; Zhao, Q.; Zhang, C. Inter- and Intra-Modal Contrastive Hybrid Learning Framework for Multimodal Abstractive Summarization. Entropy 2022, 24, 764. https://doi.org/10.3390/e24060764
Li J, Zhang Z, Wang B, Zhao Q, Zhang C. Inter- and Intra-Modal Contrastive Hybrid Learning Framework for Multimodal Abstractive Summarization. Entropy. 2022; 24(6):764. https://doi.org/10.3390/e24060764
Chicago/Turabian StyleLi, Jiangfeng, Zijian Zhang, Bowen Wang, Qinpei Zhao, and Chenxi Zhang. 2022. "Inter- and Intra-Modal Contrastive Hybrid Learning Framework for Multimodal Abstractive Summarization" Entropy 24, no. 6: 764. https://doi.org/10.3390/e24060764
APA StyleLi, J., Zhang, Z., Wang, B., Zhao, Q., & Zhang, C. (2022). Inter- and Intra-Modal Contrastive Hybrid Learning Framework for Multimodal Abstractive Summarization. Entropy, 24(6), 764. https://doi.org/10.3390/e24060764