

A Social Recommendation Model Based on Basic Spatial Mapping and Bilateral Generative Adversarial Networks



Abstract
:1. Introduction
2. Related Work
3. MBSGAN Model
3.1. Overview of the Model Framework
3.2. “User Vector Mapping” Module
3.3. “Interaction Space Adversarial Learning” Module
3.3.1. The Generator in the Interaction Space
3.3.2. The Discriminator in the Interaction Space
3.4. “Social Space Adversarial Learning” Module
3.4.1. The Generator in the Social Space
3.4.2. The Discriminator in the Social Space
3.5. Adversarial Training Process of the Model
| Algorithm 1: MBSGAN adversarial training algorithm. |
 |
4. Experimental Study
4.1. Dataset and Evaluation Metrics
4.2. Parameter Settings
4.3. Experimental Comparison of Social Recommendation Models
- (1)
- SBPR [15] (2014): for the first time, social relationships were added to the Bayesian personalized ranking algorithm (BPR), arguing that users are more biased towards items preferred by their friends than items with negative feedback or no feedback.
- (2)
- SoMA [29] (2022): a social recommendation model based on the Bayesian generative model that exploits the displayed social relationships and implicit social structures among users to mine their interests.
- (3)
- DiffNet++ (2020): a social recommendation model using graph convolutional networks, by aggregating higher-order neighbors in the social relationship graph and item interaction graph, respectively, and by distinguishing the influence of neighbors on users with an attention mechanism.
- (4)
- Light_NGSR [30] (2022): a social recommendation model based on the GNN framework, which retains only the neighborhood aggregation component and drops the feature transformation and nonlinear activation components. It aggregates higher-order neighborhood information from user–item interaction graphs and social network graphs.
- (5)
- GNN-DSR [31] (2022): a social recommendation model using graph convolutional networks, which considers dynamic and static representations of users and items and combines their relational influences. It models the short-term dynamic and long-term static interaction representations of user interest and item attractiveness, respectively.
- (6)
- RSGAN (2019): a social recommendation model that uses GAN and social reconstruction, where generators generate items that friends interact with as items that users like, and discriminators are used to distinguish items that friends interact with from items that users really like themselves.
- (7)
- DASO (2019): a social recommendation model based on GAN that fuses heterogeneous information by mapping each other in interaction space and social space. The generator picks samples that are likely to be of interest to users, and the discriminator distinguishes between real samples and generated samples.
- (8)
- ESRF (2020): a social recommendation model using generative adversarial networks and social reconstruction, where the generator generates friends with similar preferences to the user and the discriminator distinguishes between the user’s personal preferences and the average preferences of friends.
4.4. Experimental Comparison of Pairwise Training Recommendation Models
- (1)
- CFGAN (2018): a collaborative filtering recommendation model based on generative adversarial networks, where the generator generates the user’s purchase vector, and the discriminator is responsible for distinguishing between the generator’s “fake” purchase vector and the real user’s purchase vector.
- (2)
- GCGAN (2021): Based on CFGAN, the discriminator captures the latent features of users and items through a graph convolutional network to distinguish whether the input is a “fake” purchase vector by the generator or a real user purchase vector.
- (3)
- GANRec (2023): a collaborative filtering model based on generative adversarial networks, where the generator picks out items that the user may like as negative samples and the discriminator distinguishes between real positive samples and generator-generated negative samples.
4.5. Comparison of Ablation Experiments of Models
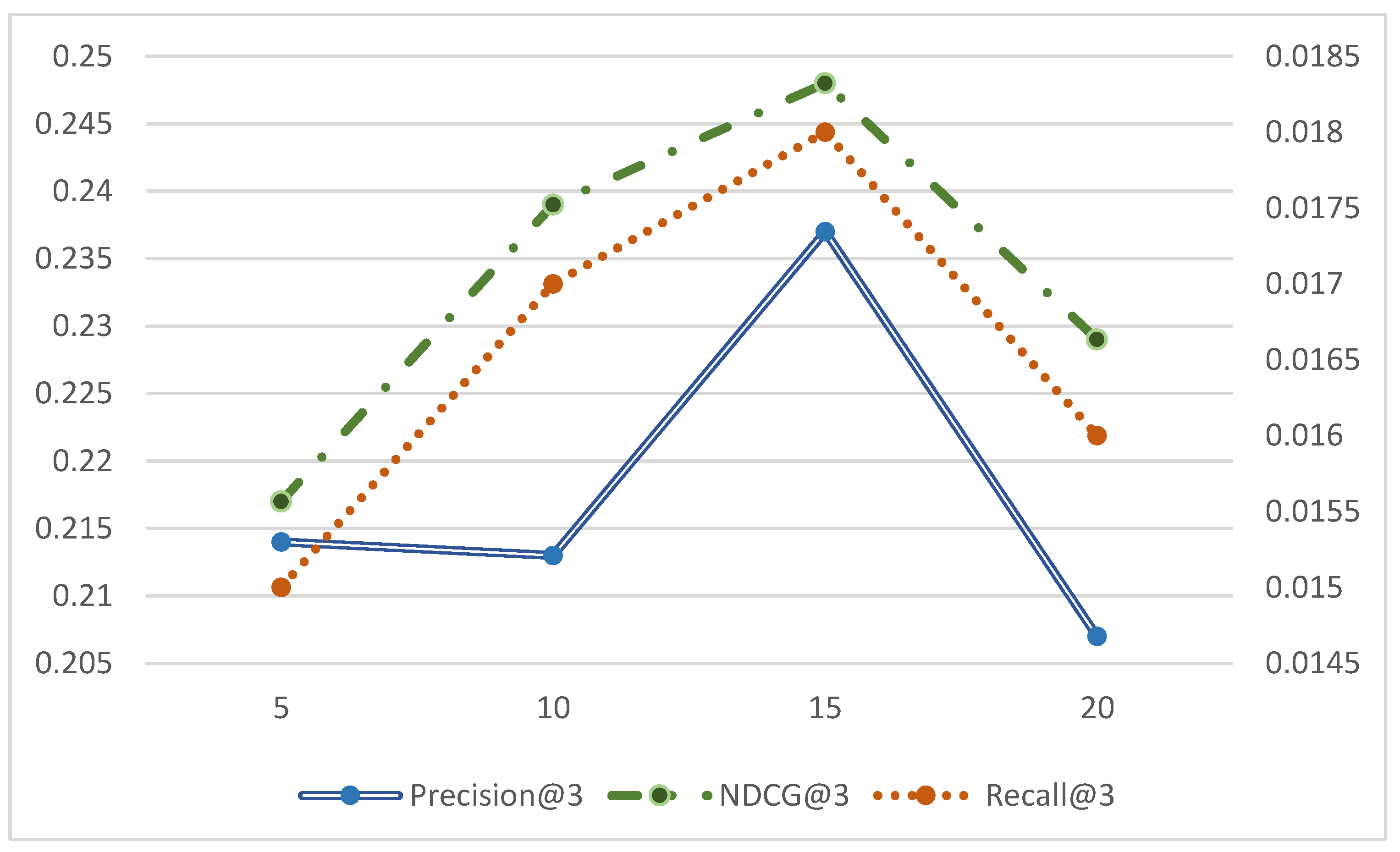
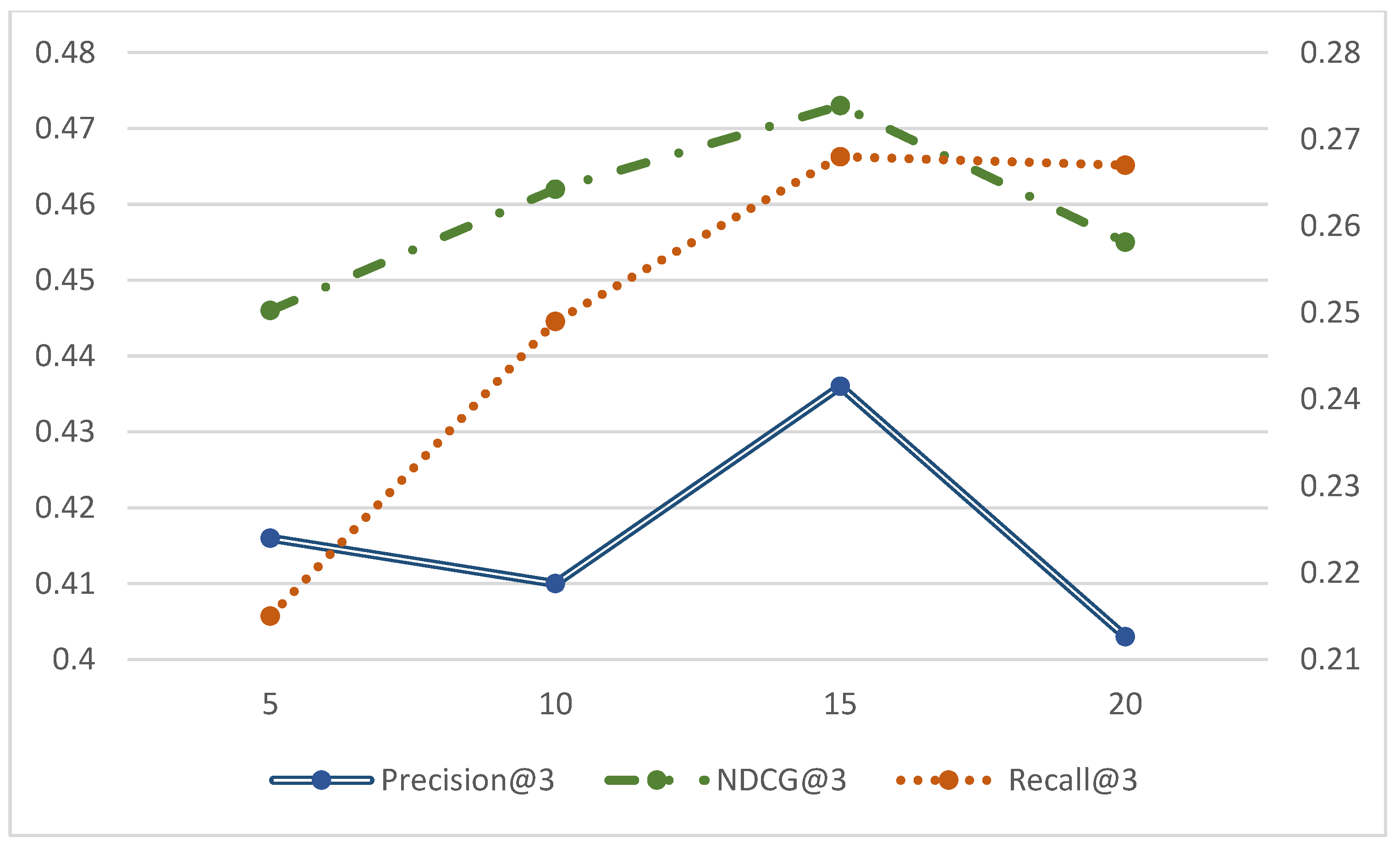
4.6. Effect of the Number of Candidate Samples k Values
4.7. Convergence of the Model
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Batmaz, Z.; Yurekli, A.; Bilge, A.; Kaleli, C. A review on deep learning for recommender systems: Challenges and remedies. Artif. Intell. Rev. 2019, 52, 1–37. [Google Scholar] [CrossRef]
- Ju, C.H.; Wang, J.; Zhou, G.L. The commodity recommendation method for online shopping based on data mining. Multimed. Tools Appl. 2019, 78, 30097–30110. [Google Scholar] [CrossRef]
- Sheu, H.S.; Chu, Z.X.; Qi, D.Q.; Li, S. Knowledge-guided article embedding refinement for session-based news recommendation. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 7921–7927. [Google Scholar] [CrossRef] [PubMed]
- Bonifazi, G.; Cauteruccio, F.; Corradini, E.; Marchetti, M.; Sciarretta, L.; Ursino, D.; Virgili, L. A Space-Time Framework for Sentiment Scope Analysis in Social Media. Big Data Cognit. Comput. 2022, 6, 130. [Google Scholar] [CrossRef]
- Xu, B.; Lin, H.F.; Yang, L.; Xu, K. Cognitive knowledge-aware social recommendation via group-enhanced ranking model. Cognit. Comput. 2022, 14, 1055–1067. [Google Scholar] [CrossRef]
- Liao, J.; Zhou, W.; Luo, F.J.; Wen, J.; Gao, M.; Li, X.; Zeng, J. SocialLGN: Light graph convolution network for social recommendation. Inf. Sci. 2022, 589, 595–607. [Google Scholar] [CrossRef]
- Mcpherson, M.; Smith-Lovin, L.; Cook, J.M. Birds of a Feather: Homophily in social networks. Annu. Rev. Sociol. 2001, 27, 415–444. [Google Scholar] [CrossRef]
- Shi, C.; Hu, B.B.; Zhao, W.X.; Yu, P.S. Heterogeneous information network embedding for recommendation. IEEE Trans. Knowl. Data Eng. 2019, 31, 357–370. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks; NIPS: Northern Ireland, UK, 2014; pp. 2672–2680. [Google Scholar]
- Nie, W.Z.; Wang, W.J.; Liu, A.A.; Nie, J.; Su, Y. HGAN: Holistic generative adversarial networks for two-dimensional Image-based three-dimensional object retrieval. ACM Trans. Multimed. Comput. Commun. Appl. 2019, 15, 1–24. [Google Scholar] [CrossRef]
- Liu, D.Y.H.; Fu, J.; Qu, Q.; Nie, J.; Su, Y. BFGAN: Backward and forward generative adversarial networks for lexically constrained sentence generation. IEEE Acm Trans. Audio Speech Lang. Process. 2019, 27, 2350–2361. [Google Scholar] [CrossRef]
- Corradini, E.; Porcino, G.; Scopelliti, A.; Ursino, D.; Virgili, L. Fine-tuning SalGAN and PathGAN for extending saliency map and gaze path prediction from natural images to websites. Expert Syst. Appl. 2022, 191, 116282. [Google Scholar] [CrossRef]
- Yu, J.; Gao, M.; Yin, H.; Li, J.; Gao, C.; Wang, Q. Generating reliable friends via adversarial training to improve social recommendation. In Proceedings of the 2019 IEEE International Conference on Data Mining (ICDM), Beijing, China, 8–11 November 2019; IEEE: Manhattan, NY, USA, 2019; pp. 768–777. [Google Scholar]
- Yu, J.; Yin, H.; Li, J.; Gao, M.; Huang, Z.; Cui, L. Enhancing social recommendation with adversarial graph convolutional networks. IEEE Trans. Knowl. Data Eng. 2020, 34, 3727–3739. [Google Scholar] [CrossRef]
- Tong, Z.; Mcauley, J.; King, I. Leveraging social connections to improve personalized ranking for collaborative filtering. In Proceedings of the Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management, Shanghai, China, 3–7 November 2014; CIKM: Shanghai China, 2014; pp. 261–270. [Google Scholar]
- Hao, M.; Yang, H.; Lyu, M.R.; King, I. Sorec: Social recommendation using probabilistic matrix factorization. In Proceedings of the 17th ACM Conference on Information and Knowledge Management, Napa Valley, CA, USA, 26–30 October 2008; ACM: Manhattan, NY, USA, 2008; pp. 931–940. [Google Scholar]
- Fan, W.; Ma, Y.; Yin, D.; Wang, J.; Tang, J.; Li, Q. Deep social collaborative filtering. In Proceedings of the 13th ACM Conference on Recommender Systems, Copenhagen, Denmark, 16–20 September 2019; ACM: Manhattan, NY, USA, 2019; pp. 305–313. [Google Scholar]
- Wu, L.; Li, J.W.; Sun, P.J.; Hong, R.; Ge, Y.; Wang, M. DiffNet++: A neural Influence and Interest diffusion network for social recommendation. IEEE Trans. Knowl. Data Eng. 2020, 34, 4753–4766. [Google Scholar] [CrossRef]
- Jin, L.; Chen, Y.; Wang, T.; Hui, P.; Vasilakos, A.V. Understanding user behavior in online social networks: A survey. IEEE Commun. Mag. 2013, 51, 144–150. [Google Scholar]
- Fan, W.; Derr, T.; Ma, Y.; Wang, J.; Tang, J.; Li, Q. Deep adversarial social recommendation. arXiv 2019, arXiv:1905.13160. [Google Scholar]
- Wu, J.; Fan, W.; Chen, J.; Liu, S.; Li, Q.; Tang, K. Disentangled contrastive learning for social recommendation. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, Atlanta, GA, USA, 17–21 October 2022; pp. 4570–4574. [Google Scholar]
- Liu, C.Y.; Zhou, C.; Wu, J.; Hu, Y.; Guo, L. Social Recommendation with an Essential Preference Space. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18), New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Zhang, S.Q.; Zhang, N.J.; Li, N.N.; Xie, Z.; Gu, J.; Li, J. Social recommendation based on quantified trust and user’s primary preference space. Appl. Sci. 2022, 12, 12141. [Google Scholar] [CrossRef]
- Wang, J.; Yu, L.; Zhang, W.; Gong, Y.; Xu, Y.; Wang, B.; Zhang, P.; Zhang, D. IRGAN: A minimax game for unifying generative and discriminative information retrieval models. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; ACM: Manhattan, NY, USA, 2017; pp. 515–524. [Google Scholar]
- Chae, D.K.; Kang, J.S.; Kim, S.W.; Lee, J.-T. CFGAN: A generic collaborative filtering framework based on generative adversarial networks. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; ACM: Manhattan, NY, USA, 2018; pp. 137–146. [Google Scholar]
- Sasagawa, T.; Kawai, S.; Nobuhara, H. Recommendation system based on generative adversarial network with graph convolutional layers. J. Adv. Comput. Intell. Intell. Inform. 2021, 25, 389–396. [Google Scholar] [CrossRef]
- Yang, Z.; Qin, J.W.; Lin, C.; Chen, Y.; Huang, R.; Qin, Y. GANRec: A negative sampling model with generative adversarial network for recommendation. Expert Syst. Appl. 2023, 214, 119155. [Google Scholar] [CrossRef]
- Caamares, R.; Castells, P. Should i follow the crowd? a prob-abilistic analysis of the effectiveness of popularity in recommender systems. In Proceedings of the SIGIR’18: The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 415–424. [Google Scholar]
- Liu, H.; Wen, J.; Jing, L.; Yu, J. Leveraging implicit social structures for recommendation via a Bayesian generative model. Sci. China Inf. Sci. 2022, 65, 149104. [Google Scholar] [CrossRef]
- Yu, Y.H.; Qian, W.W.; Zhang, L.; Gao, R. A Graph-Neural-Network-Based social network recommendation algorithm using high-order neighbor information. Sensors 2022, 22, 7122. [Google Scholar] [CrossRef] [PubMed]
- Lin, J.; Chen, S.; Wang, J. Graph neural networks with dynamic and static representations for social recommendation. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2022; DASFAA: San Francisco, CA, USA, 2022; pp. 264–271. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Items | User Volume | Item Volume | Rating Amount | Social Relationships |
|---|---|---|---|---|
| Douban | 2848 | 39,586 | 894,887 | 35,770 |
| FilmTrust | 1508 | 2071 | 35,497 | 1853 |
| Ciao | 7375 | 105,114 | 284,086 | 111,781 |
| Epinions | 40,163 | 139,738 | 664,824 | 442,980 |
| Dataset | k | D | λ | batch | Lr |
|---|---|---|---|---|---|
| Douban | 15 | 32 | 1 × 10−7 | 512 | 5 × 10−5 |
| FilmTrust | 15 | 32 | 1 × 10−6 | 512 | 5 × 10−5 |
| Ciao | 20 | 32 | 2 × 10−5 | 1024 | 5 × 10−4 |
| Epinions | 20 | 32 | 2 × 10−5 | 1024 | 5 × 10−4 |
| Model | Douban | FilmTrust | Ciao | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Precision@3 | Recall@3 | NDCG@3 | Precision@3 | Recall@3 | NDCG@3 | Precision@3 | Recall@3 | NDCG@3 | |
| SBPR | 0.182 | 0.013 | 0.208 | 0.221 | 0.094 | 0.267 | 0.022 | 0.008 | 0.024 |
| DiffNet++ | 0.204 | 0.016 | 0.220 | 0.375 | 0.201 | 0.416 | 0.025 | 0.012 | 0.028 |
| RSGAN | 0.211 | 0.015 | 0.217 | 0.347 | 0.203 | 0.385 | 0.029 | 0.014 | 0.033 |
| DASO | 0.224 | 0.017 | 0.239 | 0.400 | 0.234 | 0.445 | 0.033 | 0.023 | 0.038 |
| ESRF | 0.223 | 0.017 | 0.238 | 0.380 | 0.232 | 0.392 | 0.032 | 0.016 | 0.037 |
| MBSGAN | 0.237 | 0.018 | 0.248 | 0.430 | 0.236 | 0.459 | 0.034 | 0.029 | 0.039 |
| Model | Ciao MAE | RMSE | MAE | Epinions RMSE |
|---|---|---|---|---|
| SoMA | 0.785 | 0.998 | 1.050 | 1.189 |
| Light_NGSR | 0.736 | 0.973 | 0.835 | 1.084 |
| GNN-DSR | 0.697 | 0.944 | 0.801 | 1.057 |
| MBSGAN | 0.704 | 0.807 | 0.765 | 0.931 |
| Model | Douban | FilmTrust | Ciao | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Precision@3 | Recall@3 | NDCG@3 | Precision@3 | Recall@3 | NDCG@3 | Precision@3 | Recall@3 | NDCG@3 | |
| CFGAN | 0.203 | 0.011 | 0.204 | 0.239 | 0.073 | 0.252 | 0.023 | 0.011 | 0.025 |
| RSGAN | 0.211 | 0.015 | 0.217 | 0.347 | 0.203 | 0.385 | 0.029 | 0.014 | 0.033 |
| DASO | 0.224 | 0.017 | 0.239 | 0.380 | 0.234 | 0.392 | 0.033 | 0.023 | 0.037 |
| ESRF | 0.223 | 0.017 | 0.238 | 0.400 | 0.232 | 0.445 | 0.032 | 0.016 | 0.038 |
| GCGAN | 0.190 | 0.014 | 0.218 | 0.212 | 0.229 | 0.229 | 0.021 | 0.010 | 0.022 |
| GANRec | 0.204 | 0.015 | 0.217 | 0.249 | 0.231 | 0.230 | 0.022 | 0.011 | 0.026 |
| MBSGAN | 0.237 | 0.018 | 0.248 | 0.436 | 0.268 | 0.473 | 0.034 | 0.029 | 0.039 |
| Model | Douban | FilmTrust | Ciao | |||
|---|---|---|---|---|---|---|
| MAE | RMSE | MAE | RMSE | MAE | RMSE | |
| CFGAN | 1.233 | 1.529 | 0.981 | 1.151 | 1.199 | 1.423 |
| RSGAN | 1.255 | 1.561 | 1.022 | 1.370 | 1.245 | 1.560 |
| DASO | 0.883 | 1.224 | 0.994 | 1.101 | 0.859 | 1.228 |
| ESRF | 0.900 | 1.256 | 1.683 | 1.849 | 1.701 | 1.869 |
| GCGAN | 0.898 | 1.253 | 0.956 | 1.005 | 0.889 | 1.255 |
| GANRec | 0.922 | 1.215 | 1.001 | 1.059 | 0.998 | 1.253 |
| MBSGAN | 0.820 | 1.187 | 0.895 | 0.946 | 0.704 | 0.807 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, S.; Zhang, N.; Wang, W.; Liu, Q.; Li, J. A Social Recommendation Model Based on Basic Spatial Mapping and Bilateral Generative Adversarial Networks. Entropy 2023, 25, 1388. https://doi.org/10.3390/e25101388
Zhang S, Zhang N, Wang W, Liu Q, Li J. A Social Recommendation Model Based on Basic Spatial Mapping and Bilateral Generative Adversarial Networks. Entropy. 2023; 25(10):1388. https://doi.org/10.3390/e25101388
Chicago/Turabian StyleZhang, Suqi, Ningjing Zhang, Wenfeng Wang, Qiqi Liu, and Jianxin Li. 2023. "A Social Recommendation Model Based on Basic Spatial Mapping and Bilateral Generative Adversarial Networks" Entropy 25, no. 10: 1388. https://doi.org/10.3390/e25101388
APA StyleZhang, S., Zhang, N., Wang, W., Liu, Q., & Li, J. (2023). A Social Recommendation Model Based on Basic Spatial Mapping and Bilateral Generative Adversarial Networks. Entropy, 25(10), 1388. https://doi.org/10.3390/e25101388