

Confounding Factor Analysis for Vocal Fold Oscillations


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. The VFO Model and the Effect of COVID-19
3. Multivariate Dependencies: Confounding Factor Analysis
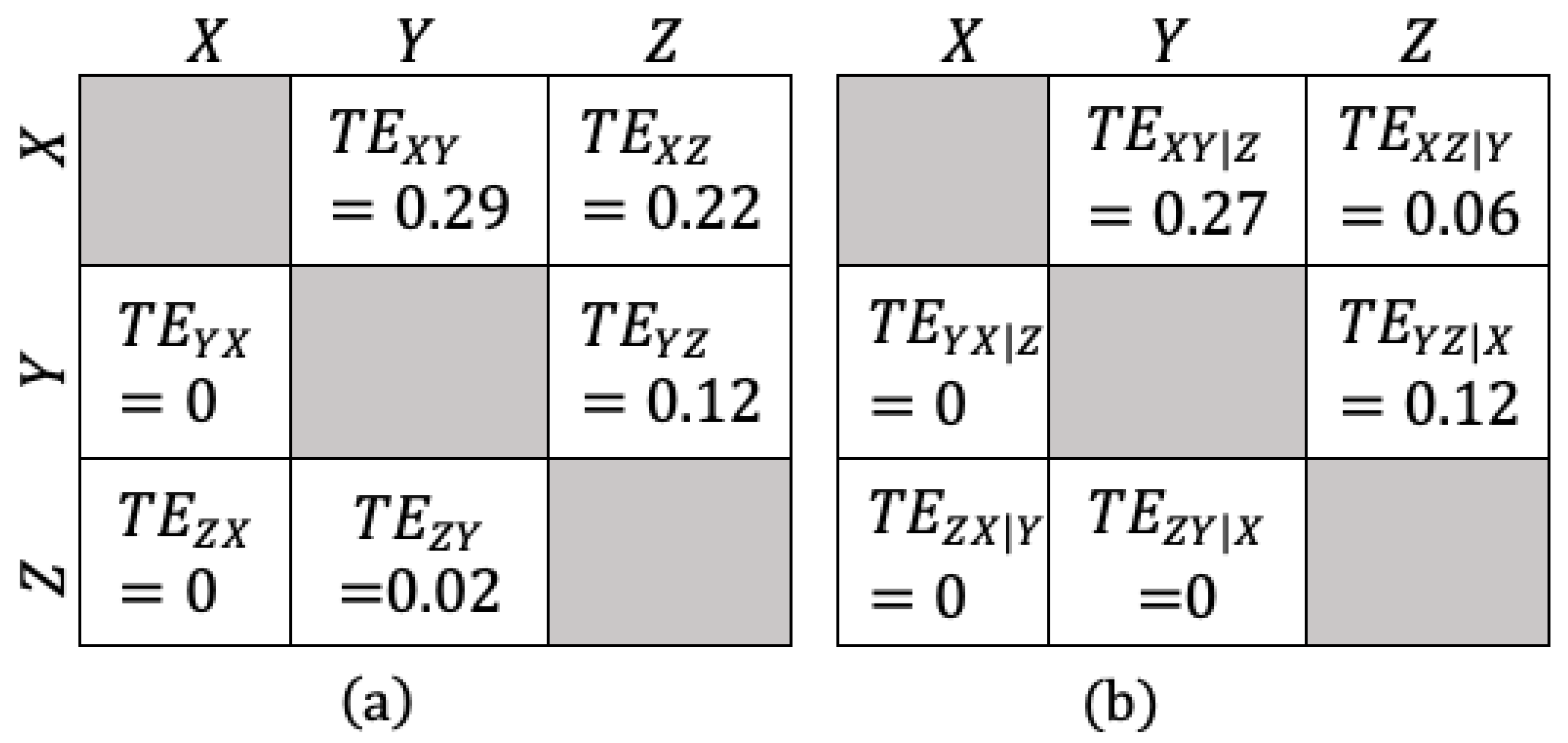
An Information-Theoretic Approach to Confounding Factor Analysis
- represents the transfer entropy from variable Y to variable X.
- and are the values of variable X at time t and time , respectively.
- is the value of variable Y at time t.
- is the joint probability distribution of , and .
- is the conditional probability distribution of given and .
- is the conditional probability distribution of given .
4. Confounding Factor Analysis on an Analytically Tractable Model
5. Proof of Concept: Experiments
Observations
- 1.
- Information flow from LV to RV is most confounded by RD, while the exact opposite holds for information flow from RV to LV, i.e., it is the most independent of RD. This implies that the activity of the right vocal fold exerts a strong influence on the velocity of the left vocal fold, while the reverse is not true. This reveals a surprising unilateral influence of one vocal fold on the other (influence of R on L).
- 2.
- Information flow from LV to LV, RV to RV, and LD to LD is hardly affected, and is independent of RD, as expected.
- 3.
- Information flow from LV to LD, and the reverse, LD to LV, and also more significantly LD to RV, is similarly confounded by RD. This is expected if the “unilateral influence” hypothesis is valid. There is no doubt that velocity and displacement are physically highly correlated, but can be affected by mass.
- 1.
- TED values are in general higher for normal people, as compared to those affected by COVID-19. This supports the known fact that in normal, non-pathological cases of voice production, the vocal folds act in synchrony and are strongly coupled and highly entrained. Thus, their displacements and velocities are expected to be well-correlated and inter-related, and not easily confounded by other influencing factors.
- 2.
- Conversely, TED values are in general lower for affected people, indicating that the vocal folds are less entrained, less predictable, and more susceptible to confounding influences.
- 3.
- There is no canonical pattern of dependencies across individuals, regardless of their health status. Every individual’s vocal fold oscillations are different. It remains to be seen if they are also unique. However, this can only be revealed through studies performed on very large populations in future projects where the CFA-VFO approach will be utilized as a tool.
- 4.
- For normal people, the phonemes /aa/, /ey/, and /uw/ show more propensity for being influenced by confounding factors.
- 5.
- For the phoneme /ey/, three speakers out of nine in the normal group show almost the same pattern of TEDs. This indicates the presence of some factor of biological significance that could be related to some common articulatory-phonetic characteristic of this phoneme. The phoneme /ey/ is a diphthong, which means it is a complex voiced sound that consists of two distinct vowel qualities within the same syllable. It is an oral vowel, so the velum (soft palate) is raised, preventing airflow through the nasal cavity. In the case of /ey/, the sound begins with an open-mid front unrounded vowel and moves towards a close-mid front unrounded vowel. From an articulatory-phonetic perspective, to produce the phoneme /ey/, the tongue starts in a relatively low (open-mid) and front position in the oral cavity for the first vowel quality, which is similar to the position for /e/ as in “Bet”. As the sound progresses, the tongue moves upward and slightly forward towards a close-mid front position, similar to the position for /ih/ as in “Bit”. Throughout the production of /ey/, the lips remains unrounded. The corners of the lips may be slightly tensed or spread. The vocal tract remains relatively open during the production of /ey/, with the oral cavity taking on a more front-focused resonance due to the front position of the tongue. Perhaps it is the articulatory-phonetic complexity of /ey/ that requires people to adhere to more common vocal patterns. This is at least a hypothesis that can be made given the surprising degree of commonality in the TED patterns.
- 6.
- Example of a finer-level observation: For speaker 3 (normal case), the information flow from LV to RD and RV is mostly confounded by LD. It is only minimally affected by other confounding variables. For this speaker, the left vocal fold “influences” the right vocal fold in uttering the phone /aa/. This is not the case with other speakers. This could potentially help to identify the speaker, if it bears out across a large number of speaker and phone-specific recordings.
- 7.
- In the case of COVID-19-positive individuals, generally, there are fewer confounding factors in evidence. This indicates more loose coupling between different variables during phonation.
- 8.
- For the vowel sound /uw/, information flow patterns are similar across multiple pairs of individuals. Some aspect of articulation seems to be at play for this sound, making it more difficult for COVID-affected people to produce this sound. The phoneme /uw/ is a voiced monophthong, which means it is a simple vowel sound consisting of a single, steady vowel. It is a close back rounded vowel. During its production, the tongue is positioned high (close) and towards the back of the oral cavity. The lips are rounded and protruded (a characteristic feature of close back vowels). In addition, the vocal tract is relatively constricted due to the high position of the tongue, and the oral cavity takes on a more back-focused resonance due to the back position of the tongue. This may make it relatively more difficult for people affected by a respiratory condition to individualize the sound. Again, this is only a hypothesis that this analysis makes possible. Its validity remains to be properly proved or disproved by biological studies, which are out of the scope of this work.
6. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- IPCC. Climate Change 2014: Impacts, Adaptation, and Vulnerability; IPCC (Intergovernmental Panel on Climate Change): Geneva, Switzerland, 2014. [Google Scholar]
- DeAngelis, D.L.; Grimm, V. Individual-Based Models in Ecology after Four Decades. F1000Prime Rep. 2014, 6, 39. [Google Scholar] [CrossRef] [PubMed]
- Guyon, I.; Elisseeff, A. An Introduction to Variable and Feature Selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Maaten, L.V.d.; Hinton, G. Visualizing Data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Keeling, M.J.; Rohani, P. Modeling Infectious Diseases in Humans and Animals; Princeton University Press: Princeton, NJ, USA, 2008. [Google Scholar]
- Altman, E.I.; Resti, A.; Sironi, A. Default Recovery Rates in Credit Risk Modeling: A Review of the Literature and Empirical Evidence. J. Financ. Quant. Anal. 2011, 46, 1543–1575. [Google Scholar]
- Titze, I.R. Vocal Fold Biomechanics and Voice Quality. Curr. Opin. Otolaryngol. Head Neck Surg. 2001, 9, 145–149. [Google Scholar]
- Santerne, A. Statistical Methods in Exoplanet Demographics. Front. Astron. Space Sci. 2017, 4, 44. [Google Scholar]
- Shabani, A.; Lidar, D.A. Quantum Process Tomography: Resource Analysis and Online Machine Learning of Quantum States. Phys. Rev. 2009, 80, 012309. [Google Scholar] [CrossRef]
- Alexander, C. Risk Measurement: Models and Applications. J. Appl. Econom. 2006, 21, 1603–1604. [Google Scholar]
- Zhang, B.; Horvath, S. A General Framework for Weighted Gene Co-Expression Network Analysis. Stat. Appl. Genet. Mol. Biol. 2005, 4, 17. [Google Scholar] [CrossRef]
- Rao, R.B.; Hu, J. Multivariate statistical process control in manufacturing: A comprehensive review. J. Qual. Technol. 2017, 49, 193–214. [Google Scholar]
- Borgatti, S.P.; Mehra, A.; Brass, D.J.; Labianca, G. Network Analysis in the Social Sciences. Science 2009, 323, 892–895. [Google Scholar] [CrossRef] [PubMed]
- Papoulis, A. Probability, Random Variables and Stochastic Processes; McGraw-Hill: Tokyo, Japan, 1965. [Google Scholar]
- Tjøstheim, D.; Otneim, H.; Støve, B. Statistical Dependence: Beyond Pearson’s. Statist. Sci. 2022, 37, 90–109. [Google Scholar] [CrossRef]
- Young, A.L.; van den Boom, W.; Schroeder, R.A.; Krishnamoorthy, V.; Raghunathan, K.; Wu, H.; Dunson, D.B. Mutual information: Measuring nonlinear dependence in longitudinal epidemiological data. PLoS ONE 2023, 18, E0284904. [Google Scholar] [CrossRef]
- Príncipe, J.C. (Ed.) Information Theoretic Learning—Renyi’s Entropy and Kernel Perspectives; Springer: Berlin/Heidelberg, Germany, 2010; ISBN 978-1-4419-1569-6. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; Wiley: Hoboken, NJ, USA, 2006. [Google Scholar]
- Schreiber, T. Measuring information transfer. Phys. Rev. Lett. 2000, 85, 461–464. [Google Scholar] [CrossRef] [PubMed]
- Gencaga, D. (Ed.) Transfer Entropy; MDPI Books: Basel, Switzerland, 2018; ISBN 978-3-03842-919-7. [Google Scholar]
- Williams, P.L.; Beer, R.D. Generalized Measures of Information Transfer. arXiv 2011, arXiv:1102.1507. [Google Scholar]
- Faes, L. Multiscale information decomposition: Exact computation for multivariate Gaussian processes. Entropy 2017, 19, 408. [Google Scholar] [CrossRef]
- Timme, N.; Alford, W.; Flecker, B.; Beggs, J.M. Synergy, redundancy, and multivariate information measures: An experimentalist’s perspective. J. Comput. Neurosci. 2014, 36, 119–140. [Google Scholar] [CrossRef]
- Zhao, W.; Singh, R. Speech-based parameter estimation of an asymmetric vocal fold oscillation model and its application in discriminating vocal fold pathologies. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 7344–7348. [Google Scholar]
- Al Ismail, M.; Deshmukh, S.; Singh, R. Detection of Covid-19 Through the Analysis of Vocal Fold Oscillations. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 1035–1039. [Google Scholar]
- Alqudaihi, K.S.; Aslam, N.; Khan, I.U.; Almuhaideb, A.M.; Alsunaidi, S.J.; Ibrahim, N.M.A.R.; Alhaidari, F.A.; Shaikh, F.S.; Alsenbel, Y.M.; Alalharith, D.M.; et al. Cough Sound Detection and Diagnosis Using Artificial Intelligence Techniques: Challenges and Opportunities. IEEE Access 2021, 9, 102327–102344. [Google Scholar] [CrossRef]
- Deshpande, G.; Schuller, B.W. COVID-19 Biomarkers in Speech: On Source and Filter Components. In Proceedings of the 43rd Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Virtual Conference, 1–5 November 2021; pp. 800–803. [Google Scholar] [CrossRef]
- Quatieri, T.F.; Talkar, T.; Palmer, J.S. A Framework for Biomarkers of COVID-19 Based on Coordination of Speech-Production Subsystems. IEEE Open J. Eng. Med. Biol. 2020, 1, 203–206. [Google Scholar] [CrossRef] [PubMed]
- Kranthi Kumar, L.; Alphonse, P.J.A. COVID-19: Respiratory disease diagnosis with regularized deep convolutional neural network using human respiratory sounds. Eur. Phys. J. Spec. Top. 2022, 231, 3673–3696. [Google Scholar] [CrossRef] [PubMed]
- Asiaee, M.; Vahedian-azimi, A.; Atashi, S.S.; Keramatfar, A.; Nourbakhsh, M. Voice Quality Evaluation in Patients with COVID-19: An Acoustic Analysis. J. Voice 2022, 36, 879.e13–879.e19. [Google Scholar] [CrossRef]
- Singh, R. Production and perception of voice. In Profiling Humans from their Voice; Springer: Singapore, 2019; pp. 27–83. [Google Scholar] [CrossRef]
- Lucero, J.C.; Schoentgen, J.; Haas, J.; Luizard, P.; Pelorson, X. Self-entrainment of the right and left vocal fold oscillators. J. Acoust. Soc. Am. 2015, 137, 2036–2046. [Google Scholar] [CrossRef] [PubMed]
- Van der Pol, B. A theory of the amplitude of free and forced triode vibrations. Radio Rev. 1920, 1, 701–710. [Google Scholar]
- Strogatz, S. Nonlinear Dynamics and Chaos: With Applications to Physics, Biology, Chemistry, and Engineering, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2019; ISBN 978-0-367-09206-1. [Google Scholar]
- Zhao, W.; Singh, R. Deriving Vocal Fold Oscillation Information from Recorded Voice Signals Using Models of Phonation. Entropy 2023, 25, 1039. [Google Scholar] [CrossRef] [PubMed]
- Härdle, W.; Simar, L. Canonical Correlation Analysis. In Applied Multivariate Statistical Analysis; Springer: Berlin/Heidelberg, Germany, 2007; pp. 321–333. [Google Scholar]
- Peters, J.; Janzing, D.; Schölkopf, B. Elements of Causal Inference: Foundations and Learning Algorithms; The MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Pearl, J. Causality: Models, Reasoning and Inference, 2nd ed.; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Pourhoseingholi, M.; Baghestani, A.R.; Vahedi, M. How to control confounding effects by statistical analysis. Gastroenterol. Hepatol. Bed Bench 2012, 5, 79–83. [Google Scholar] [PubMed]
- Rosenbaum, P.R.; Rubin, D.B. The Central Role of the Propensity Score in Observational Studies for Causal Effects. Biometrika 1983, 70, 41–55. [Google Scholar] [CrossRef]
- Janzing, D.; Schölkopf, B. Detecting confounding in multivariate linear models via spectral analysis. J. Causal Inference 2017, 6, 20170013. [Google Scholar] [CrossRef]
- Lütkepohl, H. New Introduction to Multiple Time Series Analysis; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Hahs, D.W.; Pethel, S.D. Transfer Entropy for Coupled Autoregressive Processes. Entropy 2013, 15, 767–786. [Google Scholar] [CrossRef]
- Lizier, J.T. JIDT: An Information-Theoretic Toolkit for Studying the Dynamics of Complex Systems. Front. Robot. AI 2014, 1, 11. [Google Scholar] [CrossRef]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gençağa, D. Confounding Factor Analysis for Vocal Fold Oscillations. Entropy 2023, 25, 1577. https://doi.org/10.3390/e25121577
Gençağa D. Confounding Factor Analysis for Vocal Fold Oscillations. Entropy. 2023; 25(12):1577. https://doi.org/10.3390/e25121577
Chicago/Turabian StyleGençağa, Deniz. 2023. "Confounding Factor Analysis for Vocal Fold Oscillations" Entropy 25, no. 12: 1577. https://doi.org/10.3390/e25121577
APA StyleGençağa, D. (2023). Confounding Factor Analysis for Vocal Fold Oscillations. Entropy, 25(12), 1577. https://doi.org/10.3390/e25121577