1. Introduction
Since Hinton and Salakhutdinov [
1] introduced the restricted Boltzmann machines (RBMs), there have been many applications and research in which unsupervised learning using this type of neural network has allowed researchers to find complex representations of the input data in a compressed form in several disciplines. For example, the discovery of patterns of coevolution between amino acids in protein sequences [
2], the capture of higher-order statistical dependencies in ECG signals and their reconstruction [
3], the creation of representative vectors of speech in speaker recognition [
4] and the finding of product cross-categories dependencies obtained from sampling market baskets [
5], just to mention a few examples.
To achieve these high-level representations, the RBM must initiate a learning process that consists of an iterative adjustment of the weight’s connections between neurons in the input and the hidden layers, such that the likelihood of the training data being used is maximized. Once this process is completed, the neural network can be used to
generate or
reconstruct new samples from the learned probability distribution. In traditional feedforward neural networks, the information flows forward to calculate an error between the input value and the prediction and then adjusts the weights in proportion to that error (the backpropagation error). However, in an RBM, the learning is based on a process called
contrastive divergence [
6], which allows for a more-efficient and faster convergence than other traditional methods such as simulated annealing [
7] and sequential Gibbs sampling [
8] (for a more exhaustive review of the learning process, please review Zhang and colleagues [
9]). This particular distinction makes RBMs a type of neural network with sample-generation and learning-representation capabilities. Thus, the RBM trained with appropriate inputs provides an interesting tool to represent complex dependencies in the data through samples synthetically generated from the neural network itself.
Recent studies have used Boltzmann machines to produce generative samples on the paradigmatic Ising models. For example, the process of generating samples using RBMs accelerates the Monte Carlo simulation of the system, identifying distinct patterns of clusters in the lattice [
10]. Similar to this work, an RBM is trained from Metropolis samples of an Ising system at a fixed temperature, and they analyze the ability of the machine to reproduce salient features of phase transition [
11,
12].
Modeling the thermodynamic observables of many-body physical systems, such as, for example, that of an Ising system through unsupervised learning by using Boltzmann machines, has captured the attention of researchers who have found interesting results. First, the trained Boltzmann machines are able to generate spin states that capture thermodynamic observables (i.e., energy, magnetization, specific heat and susceptibility) similar to the original ones generated by Monte Carlo simulation methods [
13,
14], even identifying phase transitions [
15,
16]. Second, the appearance of the
RBM flow, a phenomenon consisting of the convergence of the machine to a fixed point (close to the critical temperature) after iterative reconstructions of spin configurations [
16,
17,
18,
19]. Third, the possibility of characterizing the Ising phase transition from the matrix of weights connecting the visible and hidden units of the RBM [
14,
18,
20].
There is evidence that RBMs are able to capture the distribution of the Ising model [
21,
22] and also detect phase transitions without external help from a human [
23]; however, the present work does not deal with the latter aspect but rather with the RBM’s ability to detect input configurations that do or do not correspond to a given system temperature even when the RBM has difficulty generating samples that are physically incompatible with the Ising system.
This study has two primary purposes: The first is to show that the RBM possesses some synthetic-sample-generation problems, particularly in situations where the distribution is bimodal, such as in an Ising system when the system temperature is below the critical temperature. Second, despite this difficulty, the trained RBM encodes sufficient information (with only one hidden layer) through the network weights to successfully guess the temperature of a system configuration.
The following sections of the manuscript are organized as follows: I describe the problem of RBMs to generate samples under certain conditions. I then describe the methodology used to train the RBM and generate Ising samples. Next, I describe the ability of the RBM to generate representations of various sample configurations and to discriminate whether or not the samples correspond to a certain temperature of the system. Finally, I show how these results can be helpful and applied in contexts other than an Ising system.
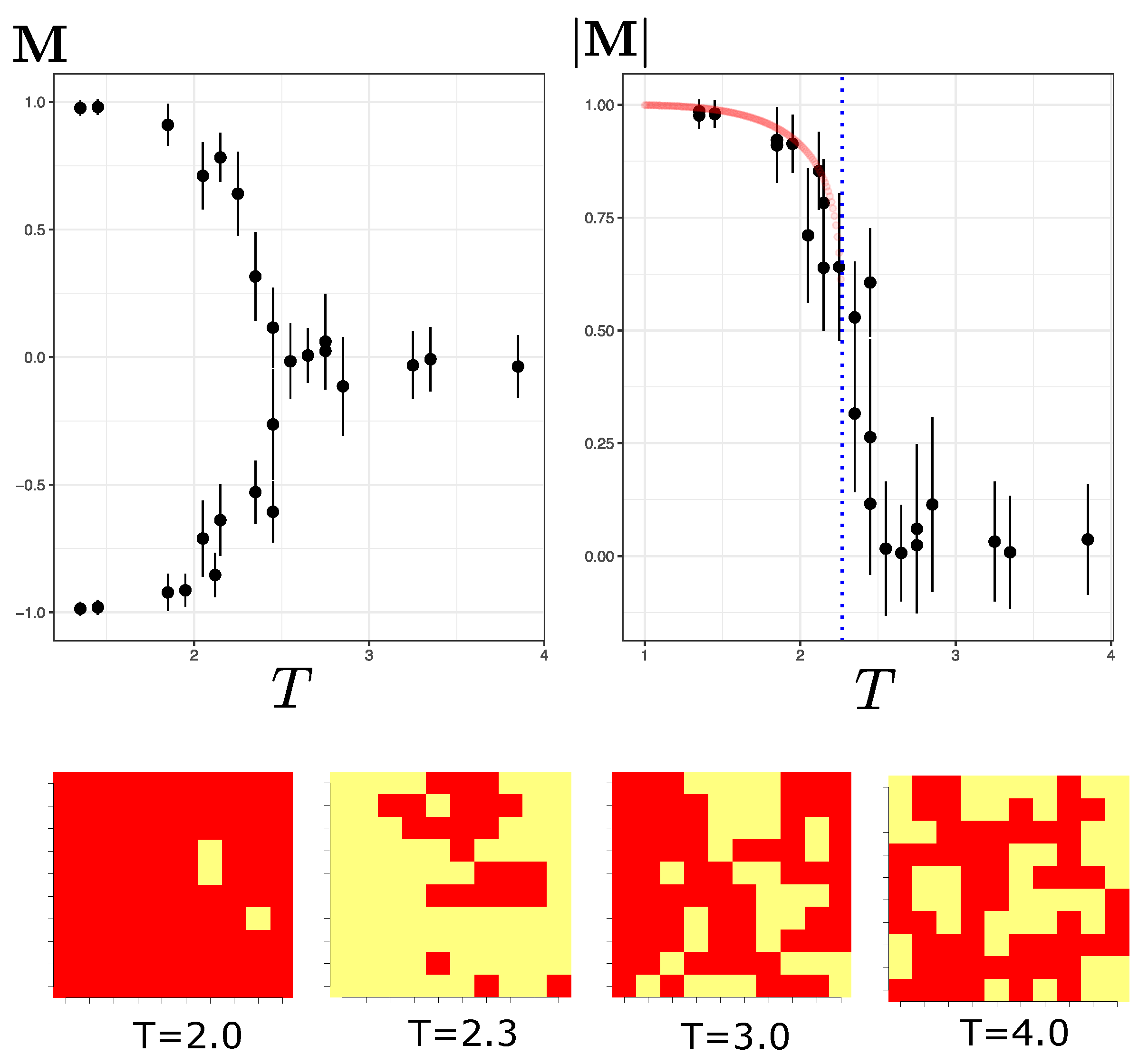
3. Simulation Results
Before beginning the analysis of training and classification, I present a simple example to denote the problem of the RBM to generate new samples. This problem manifests itself when the original distribution presents a bimodal distribution of the magnetizations of spins.
3.1. Reconstruction under Bimodal Spins Distribution
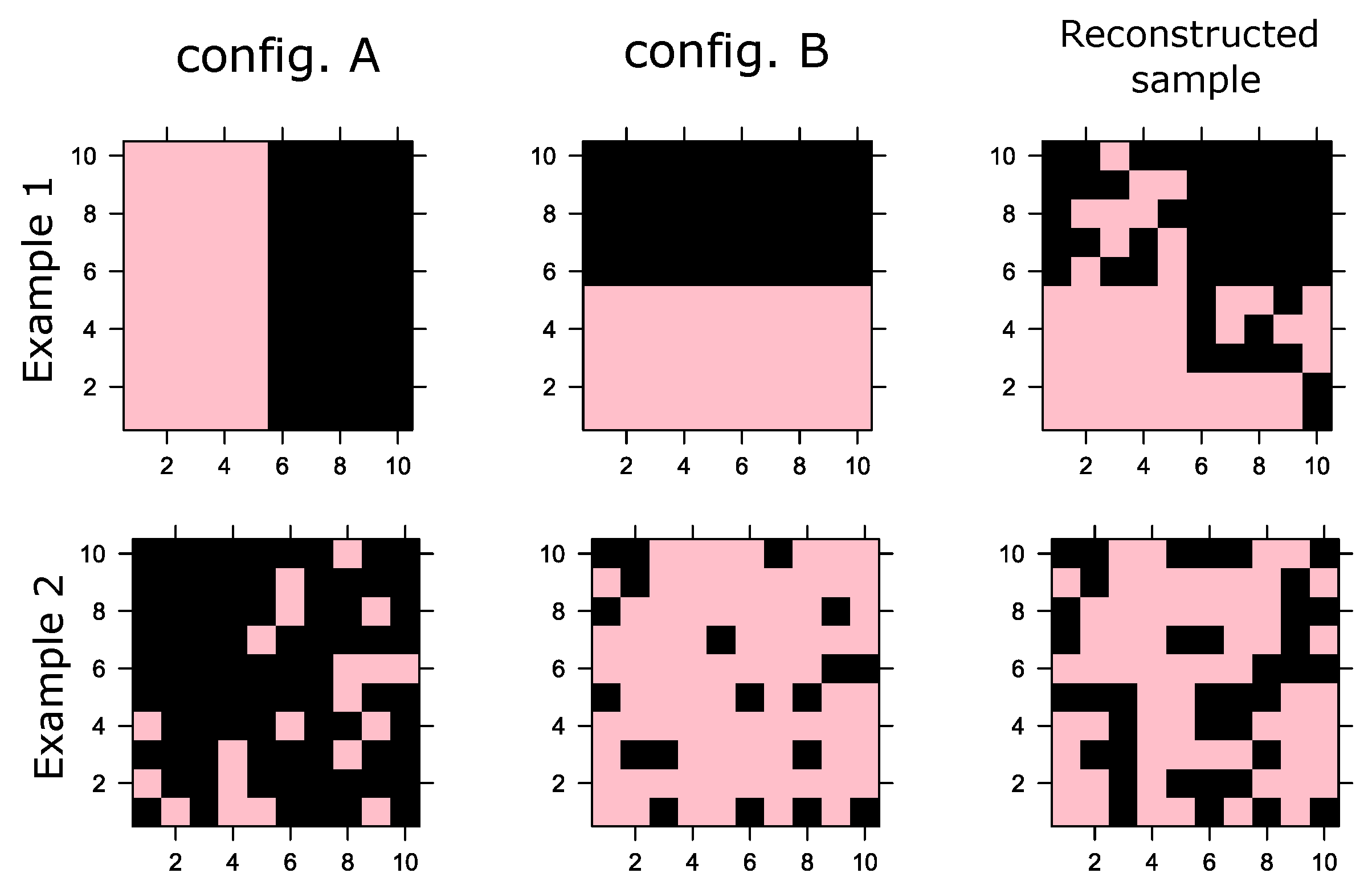
Let us assume two fictitious configurations: A and B, as shown in
Figure 2. Let us define the magnetization of a configuration
as
. In Example 1,
for both configurations; i.e., half of the spins are in −1 state and the rest are in +1 states. Consequently, the magnetization distribution of the samples is conserved at zero, but, especially, both configurations have marked concentration spins at −1 and +1 at different locations, as can be seen in Example 1. In contrast, in Example 2, the one training configuration has
(predominantly in the −1 state) and the other has
(predominantly in the +1 state), a distinctive bimodal distribution of spin magnetization; however, the mean of the magnetization distribution of the training data is 0.
As shown in Example 1, the reconstructed sample (using iterations of Gibbs samplings) results in a configuration that complies with the mean orientation of the spins (). However, it reconstructs a sample that violates the spatial correlations between the spins. In Example 2, the same thing happens, reconstructing a sample in which also but does not physically comply with a configuration predominantly with spins at −1 or +1. This problem is not in itself a machine failure since Gibbs sampling is essentially a stochastic procedure compliant with generating samples that satisfy the training configurations on average.
These examples are only intended to show that although the RBM manages to generate synthetic samples that comply with the above when observing the orientation of the spins, they do not correctly reproduce the spatial distribution of the orientations; i.e., they are configurations of the system that are physically not supported and fail to capture the large clusters present in the examples.
In the next section, I show that even though the machine cannot generate physically correct samples, it can still correctly store information on the temperature from which the training samples were generated.
3.2. Revealing RBM’s Representations of Spin Configurations
This section presents the training results of an RBM and analyzes its ability to generate Ising coherent samples. I then analyze the learned representations of the machine, projecting the values of the hidden units into a 2D plane.
For the 2D Ising system with N = 100 spins, I trained an RBM at a single temperature at
(near the critical temperature of
) by using
configurations generated from the MC sampling at that temperature. The number of hidden units is
. The hyperparameters used are described in
Section 2.2. Let us call this trained machine
to denote that it is a restricted Boltzmann machine trained with configurations at a temperature of
.
It is interesting to evaluate the ability of the RBM to learn representations between configurations of the same temperature at which the RBM was trained from other configurations generated at other temperatures. This approach is different from what has been conducted before, in which some kind of feedforward neural network is trained to determine the temperature of a configuration [
21]. The idea here is to analyze the ability of the RBM to detect configurations at a given temperature. A total of 8192 different configurations were presented to the
, 1024 for each temperature set
; two temperatures for the ordered phase, one near criticality (where magnetization converges to zero) and three for the disordered phase. Then, the resulting activation probabilities of the hidden units are projected on a 2D plane by using the first two principal components. The activation probabilities of the hidden units are computed by using Equation (
A2) (see
Appendix A).
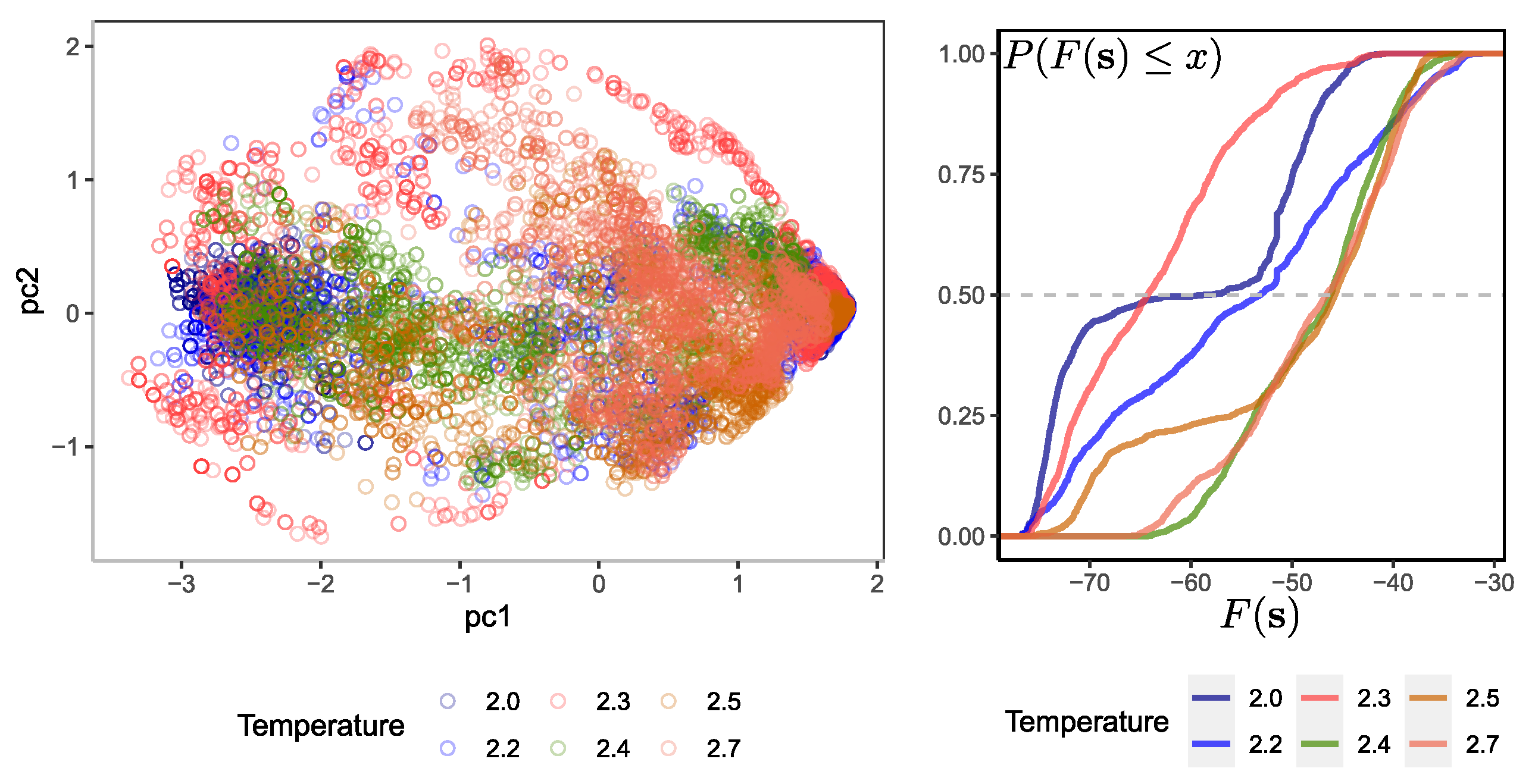
Similar to what was found by [
15], the variation along the first component is stronger than in the second. However, projecting the probabilities of the hidden RBM units provides a different perspective than doing the same directly on the original configurations.
Figure 3 on the left shows that the configurations at
tend to lie in the plane with a larger spread in both components than other samples at different temperatures. This denotes long fluctuations in the system’s dynamics and the effect of long-range spin ordering. On the other hand, it is observed in the projection that the components are concentrated at the opposite poles of the first component at low temperatures, and those at higher temperatures are scattered in a thinner band along the first component. These characteristics can help discriminate between configurations coming from the system at a near-critical temperature and other ones.
For a specific input configuration
, the log probability that the
assigns to a specific input vector
is equivalent to the likelihood that this configuration belongs to the temperature
T, which can be computed as
where
is the partition function of the
and
is the free energy computed as
where
. The partition function
can be considered here as a constant so that
is proportional to free energy.
The idea is to observe and compare the log likelihood distribution of
via the free energy (Equation (
9)) for configurations at different temperatures over an RBM trained for a specific temperature
. By calculating the distribution of
over configurations at
and other different temperatures, say
,
, then one should expect that the log likelihood of those configurations at
should be larger than those at a temperature
. In this way, one can observe the machine’s discrimination potential to differentiate configurations at different temperatures. This idea has been used to use RBMs as classifiers in other fields, such as spectral classification [
31].
Figure 3 on the right shows the cumulative distribution probability of the free energy calculated over several configurations at different temperatures. Recall that the set of parameters
of the RBM is always the same and corresponds to the trained RBM at
. As expected, those input vectors coming from a temperature equal to that of the RBM tend to have lower free energy than other configurations coming from a temperature
. In fact, it can be seen from the samples used that there are configurations at
that possess a slightly lower free energy than configurations at
. This could be a source of confusion in the ability of the machine to discriminate.
3.3. Sampling Configurations from the
As indicated in
Section 2.2, the trained RBM can approximate the data distribution with samples from
∼
q through a
p learned distribution. This approximation is conducted via the generative model such that the distribution
p remains a function of the machine parameters
. Once trained, the RBM is used as a generative model of
to generate new configurations using Equations (
A2) and (
A3) (see
Appendix A) through the block Gibbs sampling procedure: from an initial random spins system configuration
,
is computed, from which
is obtained. Then,
is computed and the sample
is obtained. We repeat this process of updating for visible and hidden units
k times to obtain a distribution
.
For the purposes of this study, with repetitions of Gibbs samplings (increasing k does not change the results), it is possible to obtain a sample of configurations with a distribution q similar to the original p used to train the RBM. Using this procedure, I generated 2048 synthetic configurations.
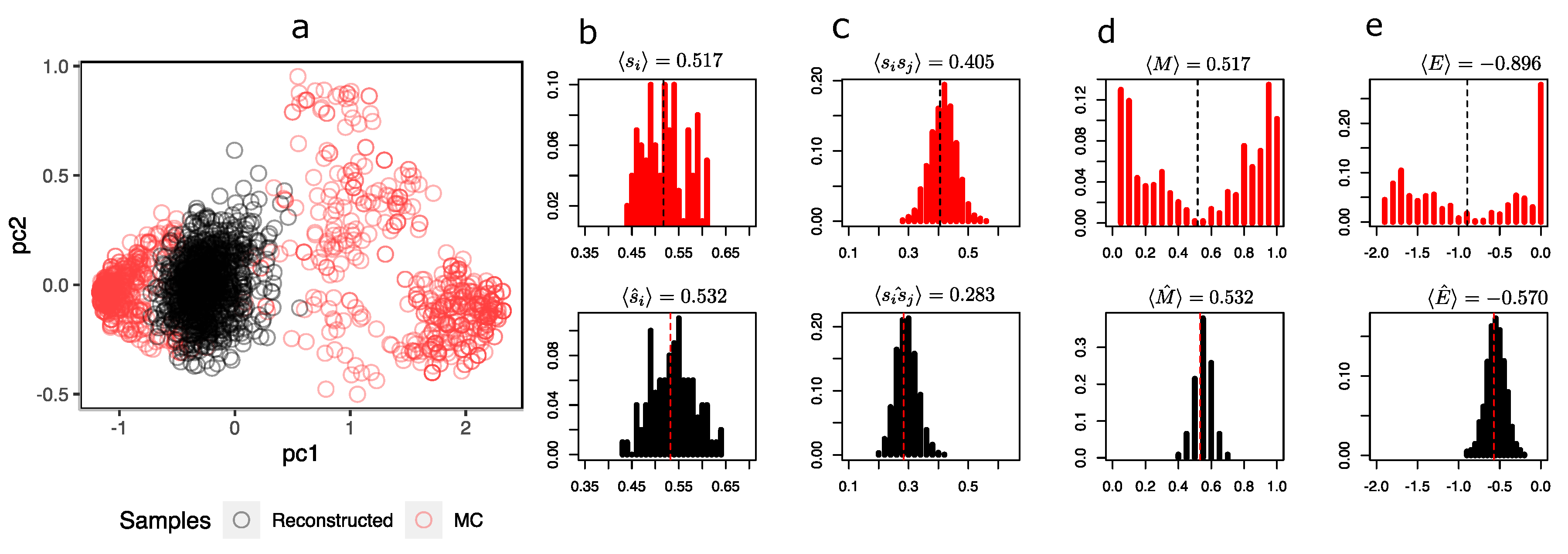
For clarity in the comparison between the configurations sampled by MCMC and generated by the RBM, the following observables are computed: First, represents the mean of the ith spin orientation of the lattice computed from the configurations sampled by MC and generated by the RBM. Second, the pairwise products between spins, , are the average of the multiplications between each pair of spins using all the sampled configurations. Third, the magnetization is the average of the states of each spin of a given configuration. Finally, the energy density of the system is for a given configuration, with being the nearest neighbors per spin for i and j.
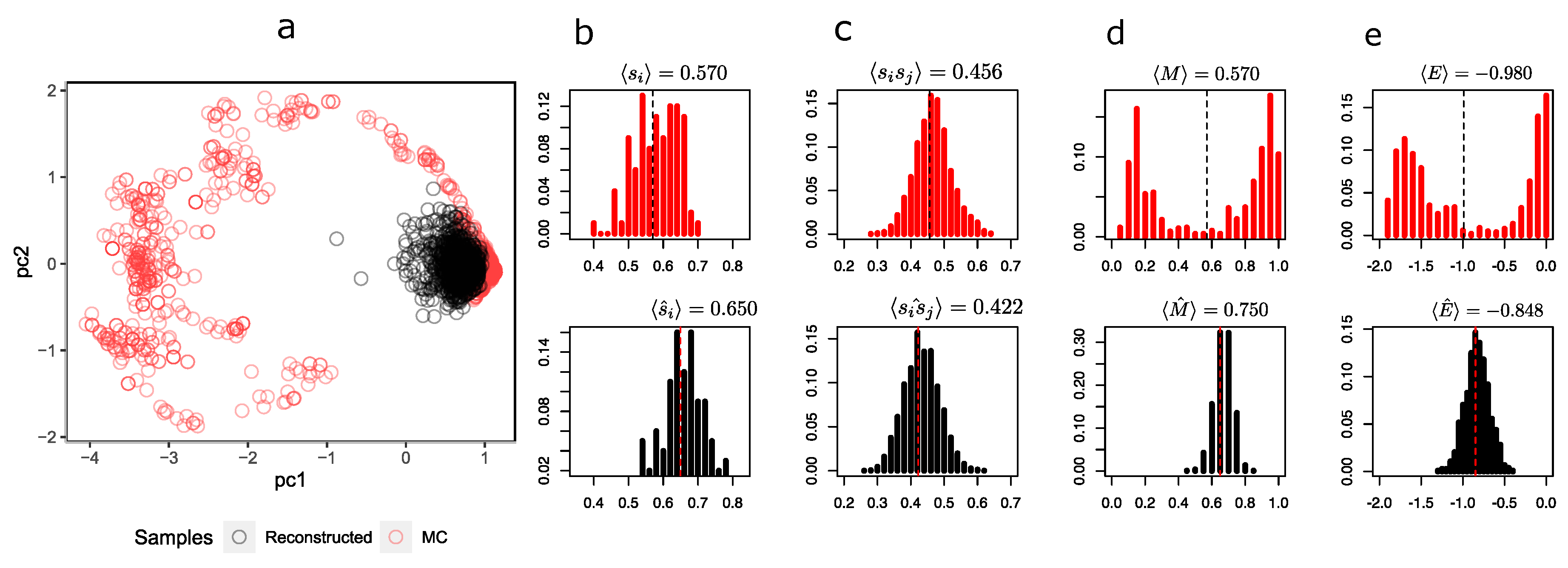
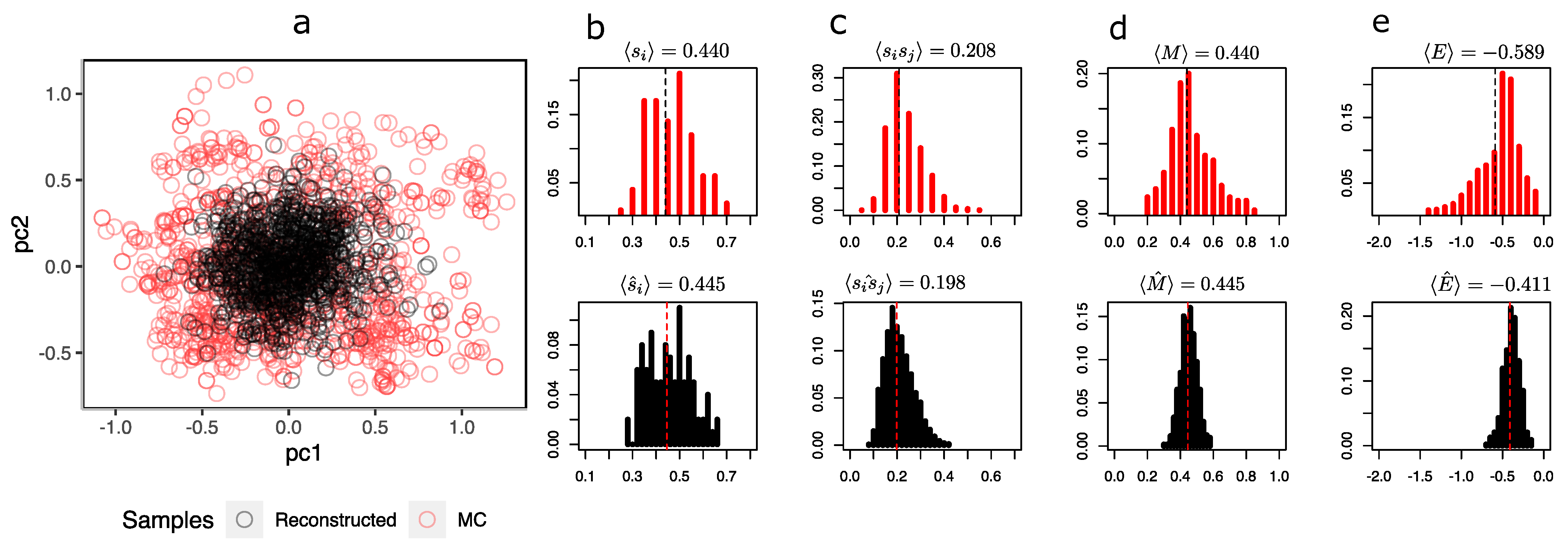
To compare the representations that the RBM sees in the hidden layer,
Figure 4 shows a scatterplot of the first two components of the hidden unit values of the MC samples and the synthetic configurations.
It is possible to observe from
Figure 4a that the synthetic configurations (in black) tend to be grouped in the same place, being under-represented in relation to the greater heterogeneity of MC’s sample configurations (in red). The distribution of the magnetizations (
Figure 4d in black) simulated by the RBM fails to capture the bimodality produced by symmetry breaking in these two predominant states.
At this temperature, the system has configurations with both negative (in the figure with
) and positive (
) magnetizations, while the reconstructions are all with a magnetization close to
. Notwithstanding the above, the RBM does a decent job of recovering the average orientations of the spins
and pairwise products
in
Figure 4a and
Figure 4b, respectively. This is expected because RBM training is essentially based on maximizing the
log likelihood, i.e., finding a distribution
that models the underlying distribution
as indicated in Equation (
5), which necessarily implies achieving consistency between the first moment and second moment of the distribution of
and consequently also with the pairwise products
. In
Figure 4e, it is also observed that the energy distribution of MC and synthetic configurations only agree on the mean (at least they are very similar); however, both distributions differ in their shapes. A similar situation occurs at
(see
Appendix C.1), in which the mean orientation of the spins is correctly recovered but the mean pairwise product clearly starts to differ, revealing a problem with the synthetic configurations. At
(see
Appendix C.2), the RBM correctly recovers the observables and distributions.
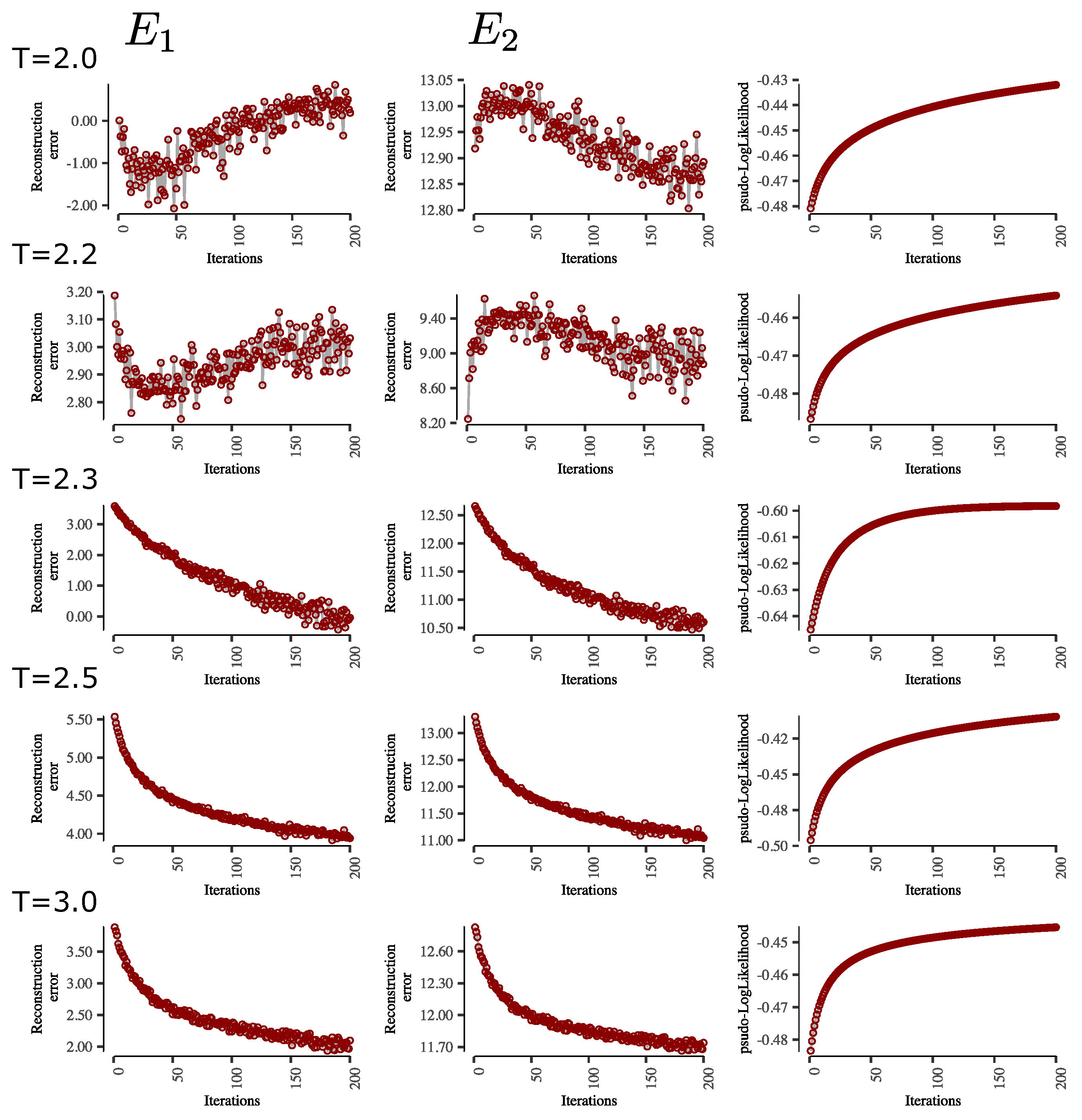
A manifestation of the learning problem with bimodal distributions is also observed in the error reconstruction of the configurations, particularly at low temperatures, which is more severe. The difference in the evolution of these errors in the learning process of an RBM with ordered and disordered phase configurations can be observed in
Appendix B.
It would be important to note at this point that the RBM does not have the inability to reproduce the statistics at different temperatures of the Ising system. The means of observables, such as the mean orientation of the spins and the pairwise product between spins, are quite similar between those of the data and those of the model. However, particularly at very low temperatures, when the system predominantly has states on −1 or +1 spins, the distribution of the magnetizations simulated by the RBM fails to capture the bimodality produced by symmetry breaking in these two predominant states.
3.4. Additional Training
The RBM does not entirely fail to reproduce specific statistics (the mean orientation and pairwise spin products) about those coming from the Ising system, a matter that other studies have shown that the RBM can perform quite well. What it fails to reproduce correctly, particularly at low temperatures, are the system configurations, in which at temperatures below the critical temperature of the system, the spins are highly correlated with large clusters with the same polarization. Specifically, it is observed that under these conditions, the magnetization
M and the system’s energy do not agree with the real ones. The RBM does not seem to capture the physical connections between the spins in the 2D Ising lattice. A situation similar to this one has also been reported by Azizi and Pleimling (2021) [
32].
Given the clustered nature of the distribution of Ising-system configurations at low temperatures, it is possible that the Gibbs sampling process to estimate the negative part of the log-likelihood gradient during training (Equation (
7)) fails to reach an equilibrium state; consequently, the RBM samples out-of-equilibrium configurations [
33], resulting in biased configurations. To analyze this issue, additional training was carried out with longer MCMC steps and also using Persistent Contrastive Divergence (PCD) [
34]. PCD can be considered as an improvement over contrastive divergence (CD), in which the final configurations of each Markov chain are used as a starting point in the next chain. Decelle and coauthors [
33] showed that the CD method is often poor because the sampling of the Markov chains in equilibrium differs from the training dataset’s distribution. In this sense, PCD could provide better results.
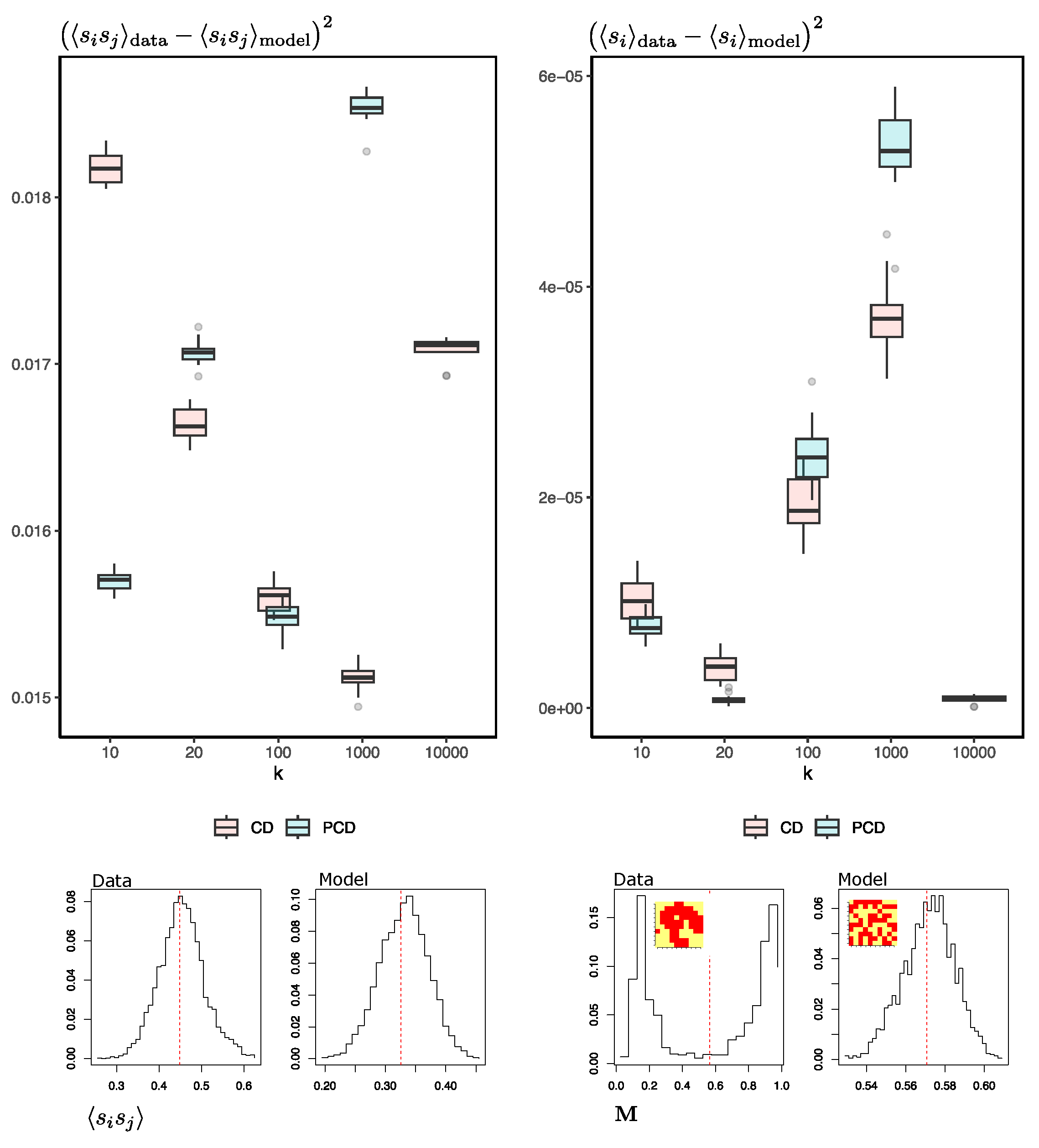
I chose to conduct the simulations at a temperature
close to the critical temperature. At this temperature, we already have evidence of symmetry breaking, where the system tends to form large clusters of neighboring spins with the same orientation. At lower temperatures, this phenomenon is more exacerbated, and the set of spins of the system is represented by a majority in one of the two possible equilibrium states, giving rise to magnetization distributions with a clear bimodality (
and
).
Figure 5 shows the degree of fit achieved by the RBM in reproducing synthetic samples by using the squared difference between the mean orientation of the spins of the (test) data and the samples generated by the RBM
and likewise for the pairwise products between spins
.
First, the differences between the test data and those generated by the machine do not decrease as we increase the number of MCMC steps. In fact, for the pairwise products, it seems to increase, being minimal at
k = 10,000. It is worth noting that the averages of the orientation of the reproduced spins fit reasonably well; however, looking at the distribution of the magnetizations of the real and synthetic spins (right-lower part of the Figure, also similar to what happens in
Figure 4d), we see that the machine-generated configurations are oblivious to the real ones. Second, this situation does not improve when using PCD. Either way, the dominance of metastable states or clustered data causes the mixing time to increase rapidly during training [
35]. This could explain why the RBM-generating configurations do not represent the natural Ising system.
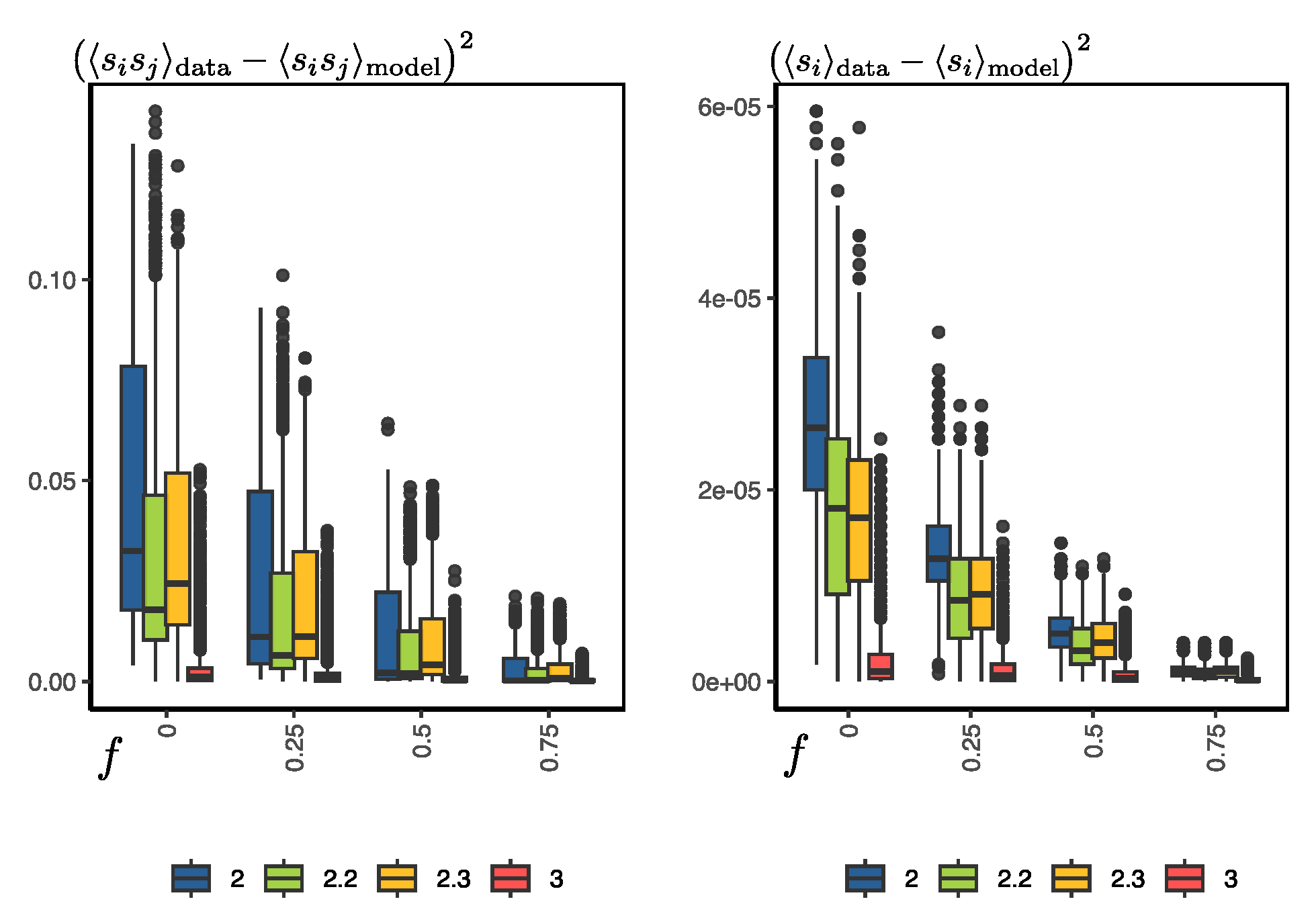
Several other simulations were carried out to evaluate the error of the configurations generated by the RBM at different temperatures and with different levels of randomness or noise in the initial configurations for synthetic-sample generation. Given an configuration of the Ising system at temperature T, let us define the parameter f, which is simply the ratio between the number of spin orientations from the MCMC data and the total number of spins of the system (in our case it is 100). So, for example, we can generate a new configuration with , which means that half of the spins are random and the other half are the actual orientations of . If , it is simply a completely random configuration. For a given temperature, we used the RBM to generate synthetic configurations, starting with configurations with different noise values (f), and then compared the error with the actual configurations. The error was evaluated as the squared difference of the magnetization of the synthetic and real samples and the squared difference of the pairwise products between spins .
In
Figure 6, we can observe the general results of the simulations. First, the error increases as we increase the level of randomness of the configurations to start the generation process. For example, when we leave 75% of the orientations untouched, the error in the magnetization and pairwise products is close to zero. However, the real test for the RBM is when
; i.e., we start the process from totally random configurations. In this case, the error is slightly larger, although it is worth noting that this error does not seem to decrease by increasing the number of Gibbs samplings in the training process or using PCD, as discussed previously (see
Figure 5). Second, for temperature
, the errors are very close to zero, but as we decrease the temperature, the average error increases slightly, but with a significant increase in the variance. Here, it is worth mentioning that the average magnetization and pairwise error at
and
are 15% and 1.7%, respectively. Hence, the main problem lies in the bimodality of the distribution of configurations at temperatures below the critical temperature, which becomes more pronounced at lower temperatures.
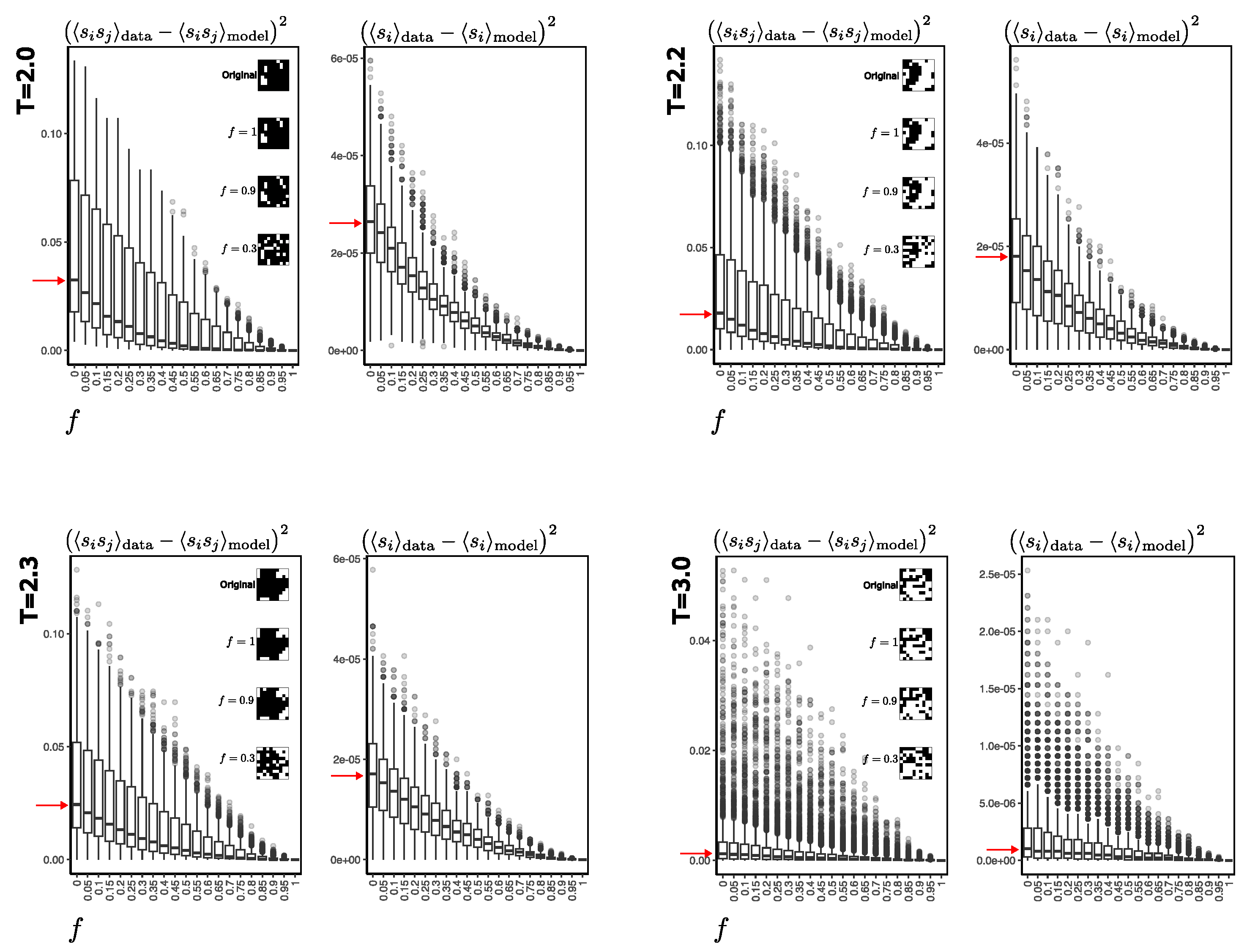
A more detailed comparison can be seen in
Figure 7. The errors are quite low at higher temperatures (here at
) compared to lower temperatures, even with noise parameters
f close to one. For example, at lower temperatures (here at
and
), the RBM has more difficulty recovering the original configurations. From the physical point of view, as the temperature is low, the system is predominantly in two equilibrium states: one where almost all the spins are at +1, and another where almost all are oriented at −1. This condition occurs predominantly at temperatures below the critical temperature, in which there is an increase in the error in the reconstruction of the configurations. Note that, as expected, with low noise values, the RBM will recover the real configurations virtually perfectly.
3.5. Training a Critical Spin Configuration’s Detector
Although the RBM is among the types of machines trained under unsupervised learning, its feature representation can help discriminate system configurations that belong to a particular condition. In this case, to verify the ability of the representation achieved by the RBM with the Ising system, I train a multilayer perceptron (MLP) as a binary classifier whose input information is the representation of the RBM in the hidden layer, say , and the output y of the neural model is a classification indicating whether the configuration belongs to the system at a temperature T.
For MLP training and testing purposes, I generated ten different sample sets of MC configurations of an Ising system as described in
Section 2.1. Each set has 16,384 different configurations. About 80% of them are used for training, and the remaining 20% are used for testing. For each set, I generated a class variable
y indicating 1 if the probability vector
belongs to a configuration
at a temperature of
or 0 if it belongs to a configuration of any other different temperature. Likewise, to ensure a balanced sampling of classes, for each set, half of the samples correspond to configurations at
, and the other half correspond to different temperatures of 2.0, 2.2, 2.4, 2.5, 2.7, 3.0 and 3.4. Each training set was used to train 10 different MLPs independently. All MLPs have an input layer with
units, an intermediate layer with two neurons with a RELU activation function and an output neuron with a sigmoid activation function. Initial random weights for the MLP training were set to 0.5. The parameter for weight decay was set to 0.004, and the maximum number of iterations was set to 200.
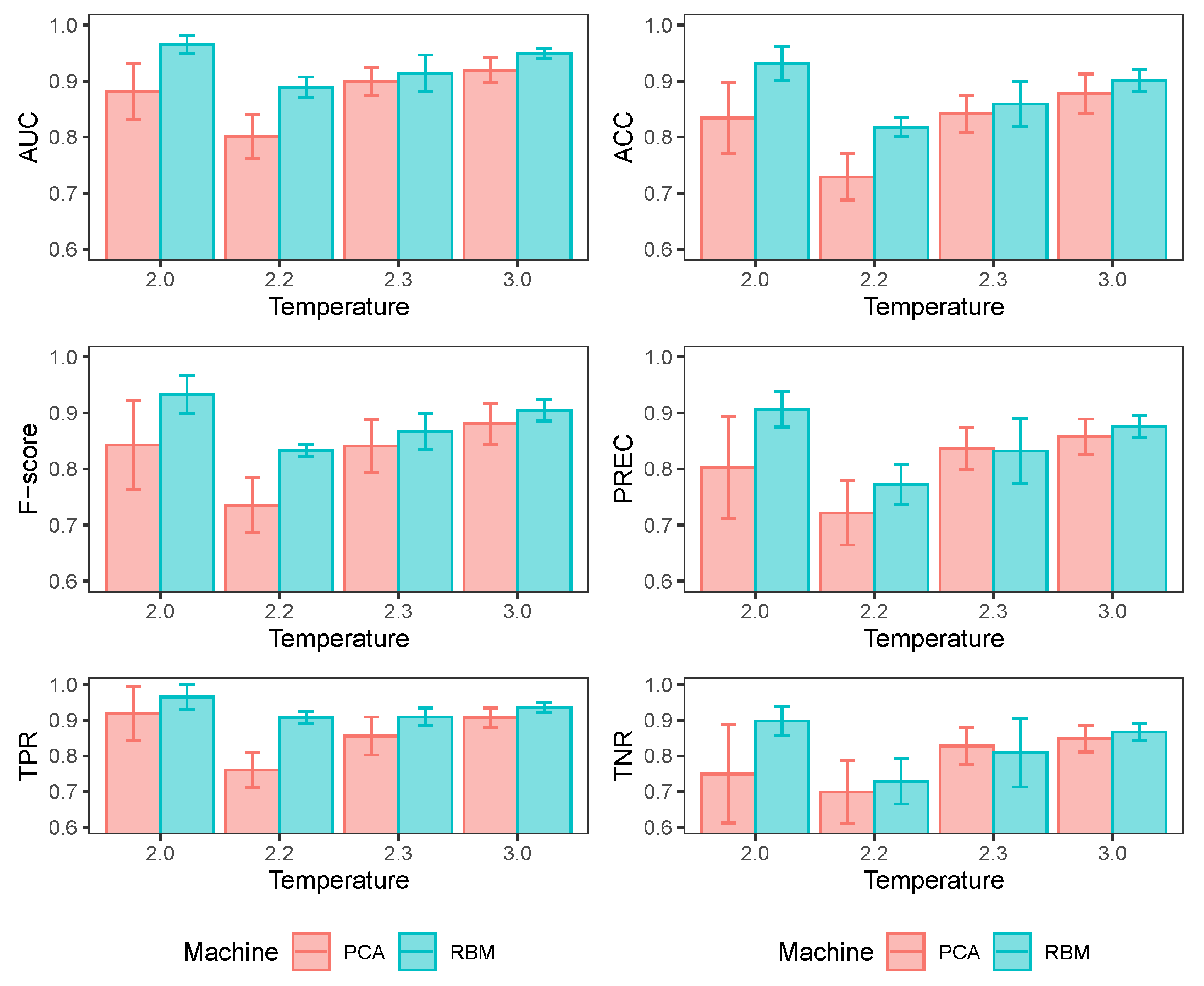
Table 1 shows the performance of the MLP classifiers. These results appear to be respectable, considering the overlap between the classes and the nature of the problem we are dealing with. This indicates that the hidden layer of the RBM carries enough system information to discriminate whether the configurations in the input layer belong to valid configurations at the system temperature. This is attractive because if we are interested only in some particular system temperature (in this case, the near-critical temperature), training a series of other RBMs at different temperatures is unnecessary to discriminate between other system states. In
Appendix D, I show the results of repeating precisely the same MLP training exercise but using a different number of hidden RBM units. In short, it can be seen that there is a marginal impact on the classifier’s ability to discriminate configurations. The higher the number of hidden units, the slightly better the performance of the classifier.
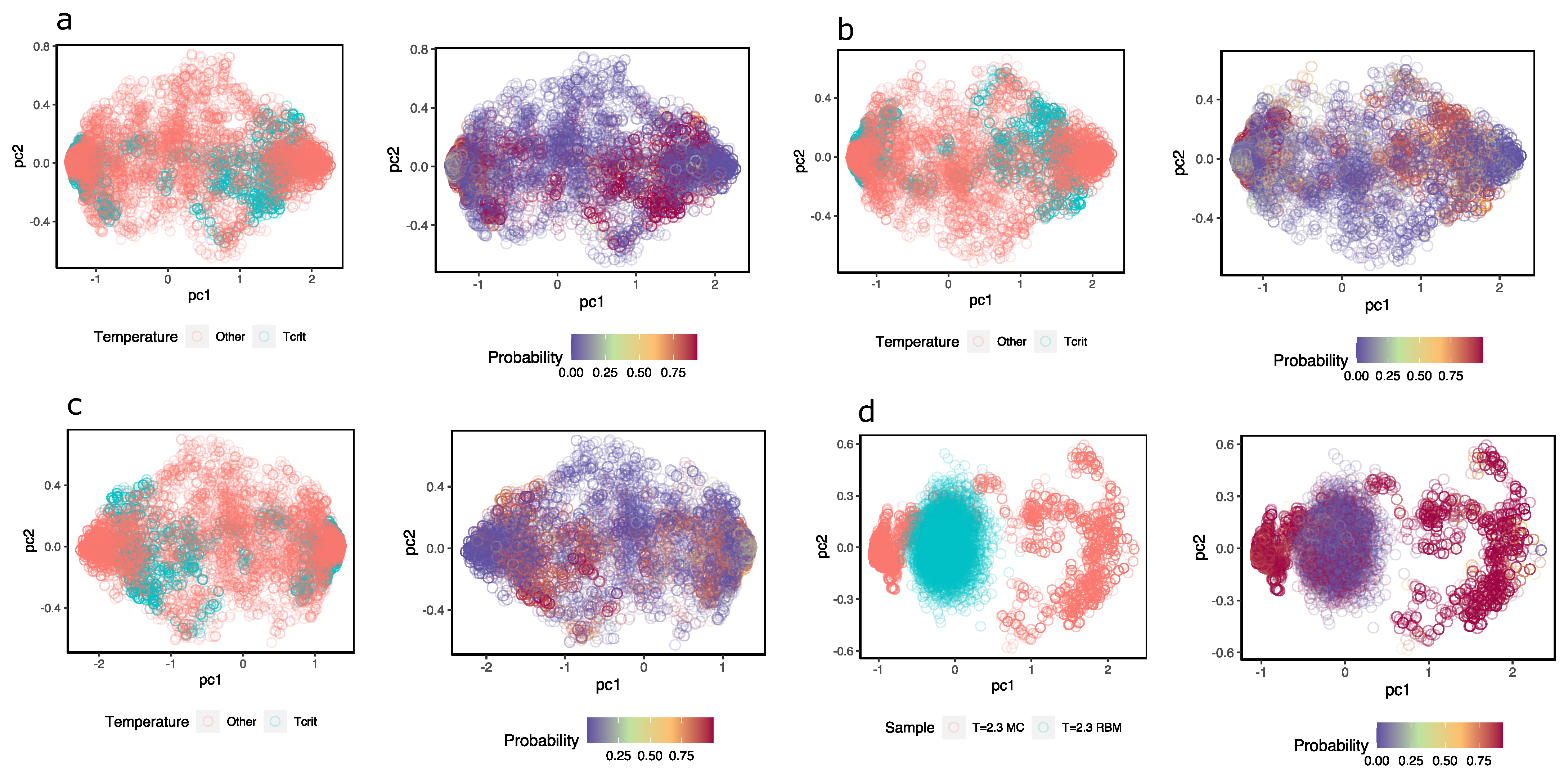
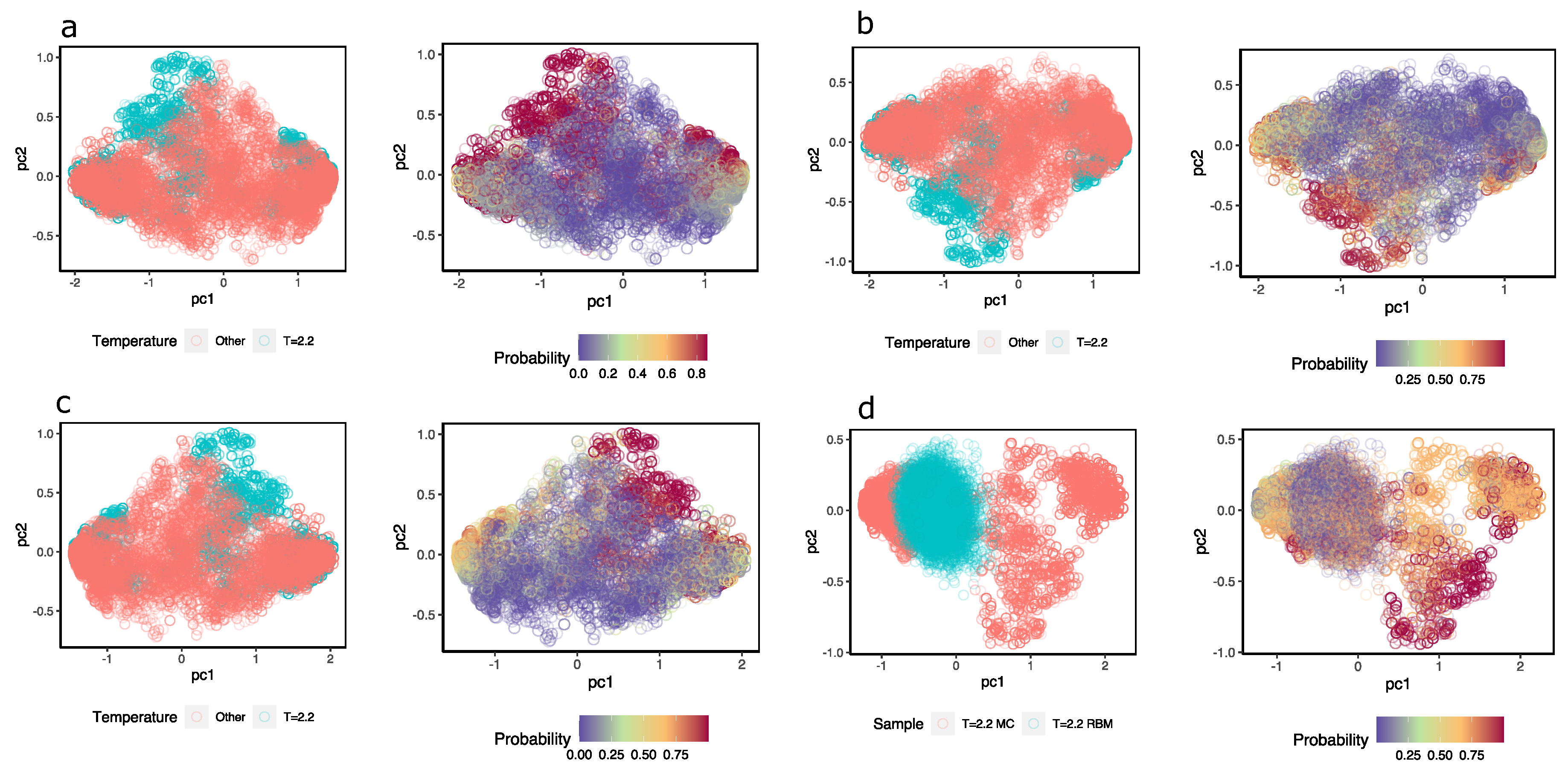
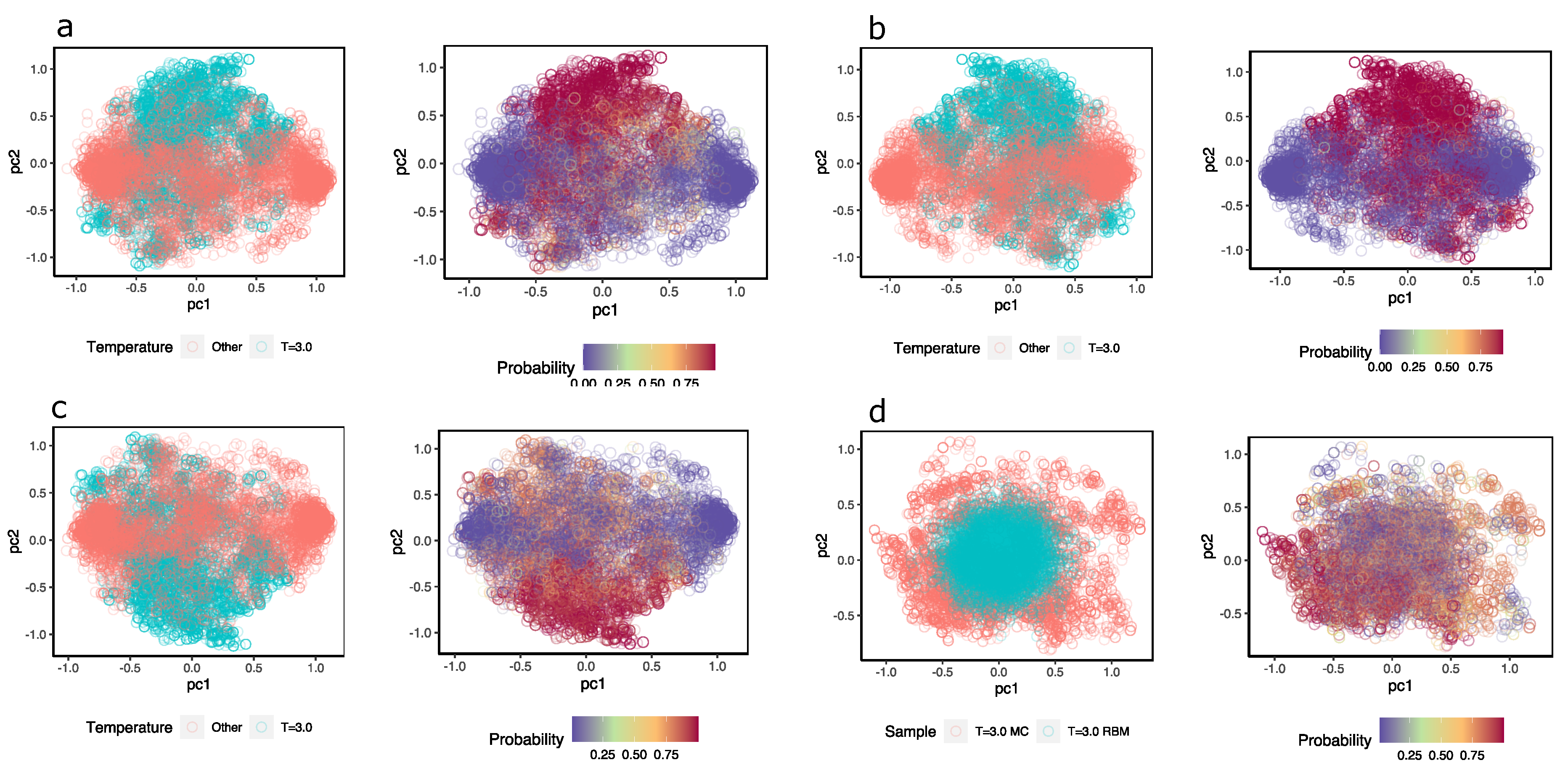
To obtain an idea of how the MLP discriminates near-critical temperature configurations from others,
Figure 8a–c shows a representation of the hidden units colored according to the class they belong to; next to them, the hidden units are the same, but they are colored according to the probability that the MLP assigns configuration at
. In this case, different samples were taken from configurations at temperature
(magenta) and the same number of samples from configurations with
(in pink). Although a high degree of overlap between the two sets of configurations can be observed, the MLP (three different ones) assign high probabilities to values of the hidden units of configurations at
and low probabilities to those that are not.
Additionally, the same idea is shown in
Figure 8d but with samples of configurations at
and others that the RBM generated. When feeding the hidden unit values of these configurations to the MLP, the MLP successfully recognizes the configurations at
; however, the reconstructions achieved with the same RBM are classified as configurations other than
, when in fact, they should not be. This again highlights the problems of the RBM in generating appropriate configurations.
As a complement, in
Appendix C, I repeat the same exercise for two other system temperatures—one at a disordered phase temperature at
and one at an ordered phase at
. In the first case, it is possible to observe that the results of generating configurations using
are much better than those when using
and also in the second case with
. This is not surprising: with disordered or high-temperature configurations, there are no bimodal distributions, while in the opposite case, as we have already indicated above, with bimodal distributions, the RBM has difficulties generating correct configurations. Despite this problem, the RBMs still encode in the hidden units the information necessary to identify whether or not the configurations belong to the RBM temperature when we use the hidden units as inputs to train MLP classifiers.
Previous research [
15,
36] has shown that other much simpler unsupervised learning techniques, such as principal component analysis (PCA), can successfully recognize the phase changes in an Ising system. Thus, it can be assumed that it could be a good competitor to RBMs for detecting the temperature of configurations. Additional temperature-detection models of configurations of an Ising system have been added, but only using the PCA components applied directly on training setups. This allows for a comparison of both PCA and RBM performance (under the same MLP architectures described before) in identifying samples of different temperatures.
In
Figure 9, it can be seen that PCA is a good competitor to RBMs for detecting temperature, although RBMs perform better than PCA in detecting temperatures below the critical temperature. Above it, the performance of both alternatives is similar. At temperatures above the critical temperature, the configurations tend to be disordered with a magnetization level close to zero. In contrast, configurations with metastates begin to exist below the critical temperature, so the PCA has a more challenging time discriminating from other configurations at higher temperatures. The PCA finds the directions of the greatest variance in the dataset and plots each configuration in its coordinates along these directions. In contrast, the RBM provides a nonlinear generalization of the PCA that transforms the high dimensionality of the system configurations into a low-dimensional code, turning the hidden layer into a feature detector of higher-order correlations of the individual activity of the spins. In this sense, it seems to us that the RBM is more flexible than a PCA in that it can transform the input into complex nonlinear representations.
4. Discussion and Conclusions
This work has shown that an RBM trained with configurations of a 2D Ising system at a given temperature can store enough information in the network weights to be used later as a configuration discriminator. The RBM converts the input information into a transformed vector, a simplified dimensionality representation of a raw system state. This vector can feed a simple MLP (previously trained) to recognize a system state at a specific temperature.
Why not simply use a neural network with enough hidden layers and train it as a classifier? Unlike a conventional feedforward neural network, the RBM is trained through an unsupervised process in which no information is presented to the class to which the configurations belong. Thus, in its original conception, the RBM is a model that maps the input data distribution into an alternative (ideally simplified) representation. When the RBM is trained with data for a specific temperature, say
, this representation may be sufficient to subsequently discriminate between Ising configurations at that temperature and those not. In other words, the RBM, in addition to informing us about how the configurations are distributed in a latent space simpler than the original space to which the system configurations belong, contains enough information to use this representation to train a classifier. Simple unsupervised learning techniques, such as principal component analysis (PCA) and autoencoders applied directly on the raw spin configurations of a typical Ising lattice, can identify the phase transition in the system [
15,
23]. The low-dimensional representations of the original data keep relevant phase information and, consequently, can be used to identify the states of interest in which the system is found.
This capability of the RBM could be helpful in frustrated systems with a wide range of ground states and roughness of the energy landscape. In these cases, there is no possibility of finding analytical solutions in advance in which one knows that under certain temperature conditions, the system could undergo a phase transition. Also, in situations where there are no singular phase transitions with abrupt changes and broken symmetry but there is a crossover region, the RBM could help to identify them. It has been shown that this is possible [
37] but by using a Variational Autoencoder [
38], which also achieves a dimensional data reduction in unsupervised learning. For example, with just data on the configurations of a system, one could train an RBM that takes “special” configurations and, consequently, use that RBM to detect configurations that fall into that “special” domain. To be more specific, let us think of the financial system, where we collect all the states (previously represented in a binary system) and train an RBM only on conditions of that system when it is in crisis (high volatility, for example).
Although the RBM seems useful as an alternative to creating a latent representation of an Ising system and a discriminator of configurations between different temperatures, the same cannot be said for a generator of new configurations, particularly in the ordered phase. The Ising model is characterized by a symmetry break at temperatures below the critical temperature, in which the system tends to polarize in one of the two magnetization states (+1 or −1). Under the same temperature, the distribution of the system configurations will be bimodal. This work shows that under these conditions, the RBM can capture “on average" the magnetization, correlation, energy and other measurements, but this does not imply that it can adequately reproduce system configurations. When examining the configurations generated by the RBM (at temperatures
), they fail to capture the characteristic polarization of the Ising system, instead reproducing average configurations. This does not occur at temperatures
since there is no correlation between states in the disordered phase, and the distribution of the states tends to be offset around a magnetization around zero. This problem was initially detected by [
32] by training RBMs at different temperatures but keeping the magnetization fixed at zero (
).
The RBM is not a good generator of Ising-system configurations at temperatures below the critical temperature due to the dominance of metastable states; consequently, the chains fail to mix in a reasonable amount of time [
35]. This study did not solve this problem, but it may be addressed in future research by considering other types of sampling techniques that deal with data with multimodal distributions.
An actual solution to this problem, according to [
39], is to predefine a concentration at a magnetization
. The previously trained RBM generates a sample. If it has magnetization
, it is accepted. If the magnetization is less than
, the number of spins in state −1 must be reduced, so a node
k in state −1 is randomly selected and rebinarized according to Equation (
A3). The process is repeated until the desired magnetization is achieved. The same idea applies when the sample has a magnetization greater than desired. The disadvantage of this solution is that in systems with a large number of spins, the sample-generation process can take a long time; however, it is a solution so far that manages to generate synthetic samples consistent with the actual system. Another alternative is to extend the RBM with local and shared connections to a convolutional layer [
40] so that the machine can capture and preserve the spatial structure of the configurations.
I would like to point out that our study does not show the ability of the RBM to reproduce physical observables of the RBM, which is shown to be possible in several papers (as, for example, in [
14,
41]), but rather highlights the difficulty of correctly reproducing the bimodality observed in the Ising-model configurations at low temperatures. We have observed that once the RBM has been trained with low-temperature configurations when reproducing synthetic configurations, the average observables may agree with those measured from the data. However, when looking at the individual configurations, we see that they are not representative of those corresponding to the configuration of that temperature. We can note that the distribution of the magnetizations of the synthetic configurations fails to reproduce the bimodality of the distribution of original configurations adequately. Note that sampling feeding to the input layer contains configurations with spins predominantly with an orientation of +1 or −1 simultaneously. However, if we train considering only configurations with predominantly +1 (or −1) spins, the RBM can reproduce physically correct samples with excellent coherence of the magnetization distribution. An alternative way to overcome this problem is to alter the input configurations by imposing the constraint of leaving the predominant orientations at +1 or −1 for all the training configurations. In other words, making
become
. This arrangement, while not altering the physical distribution of the orientations, destroys the original bimodality of the probability distribution and changes the distribution of the energies of the system as well because
. Again, an additional constraint can be imposed on the RBM such that
by making the visible and hidden layer biases vanish (suggested by Fernandez-de-Cossio-Diaz et al. [
42]) and using the centering trick (Melchior, et al., 2016) [
43]. Recently, Béreux and colleagues [
44] noted the problem of the RBMs to reproduce synthetic samples in the presence of highly clustered distributions by implementing a Tethered Monte Carlo (TMC) method, a form of biased sampling to approximate the negative part of the log-likelihood gradient. This line of research could be highly relevant to expanding the data domain for unsupervised learning with energy-based models.
Although in the classification problem, the RBM performs quite well, new quantum learning models can help overcome some difficulties in generating synthetic samples that are representative of the physical system. In this sense, quantum RBMs can offer new development perspectives [
45,
46].
In summary, I envision that RBMs have a high potential for applicability in highly complex systems, particularly in retaining essential information in the latent parameters. The latent representation of the states into the RBM can be handy for detecting states or phases of the system, without necessarily possessing a priori knowledge of the interactions among units or the energy-functional form.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











