1. Introduction
Information geometry plays an important role in parametrical statistical analysis. Fisher information is the most common information measure that is instrumental in the construction of lower bounds for quadratic risk (information inequalities of Cramer–Rao type), optimal experimental designs (E-optimality) and noninformative priors in Bayesian analysis (Jeffreys prior). These applications of Fisher information require certain regularity conditions on the distributions of the parametric family, which include the existence and integrability of the partial derivatives of the distribution density function with respect to the components of vector parameter and independence of the density support on the parameter. If these regularity conditions are not satisfied, Cramer–Rao lower bounds might be violated, and Jeffreys prior might not be defined.
There exist a number of ways to define information quantities (for the scalar parameter case) and matrices (for the vector parameter case) in the nonregular cases when Fisher information might not exist. One of such suggestions is the Wasserstein information matrix [
1], which has been recently applied to the construction of objective priors [
2]. The Wasserstein matrix does not require the differentiablity of the distribution density function, but it cannot be extended to the case of discontinuous densities. This latter case requires a more general definition of information.
Our approach is based on analyzing the local behavior of parametric sets using finite differences of pdf values at two adjacent points instead of derivatives at a point, which allows us to include differentiable densities as a special case but also to treat non-differentiable densities including jumps and other types of nonregular behavior (for classification of nonregularities, see [
3]). A logical approach is to use (in lieu of Fisher information) the Hellinger information closely related to the definition of Hellinger distance between adjacent points of the parametric set.
Hellinger information for the case of scalar parameter was first defined in [
4] and suggested for the construction of noninformative Hellinger priors.
Section 2 is dedicated to the revision of this definition and the relationship of Hellinger information to the information inequalities for the scalar parameter proven in [
5,
6]. It contains some examples of noninformative Hellinger priors comparing the priors obtained in [
4] with more recent results.
Lin et al. [
7] extended the definition of Hellinger information to a special multiparameter case, where all components of a parameter expose the same type of nonregularity. This is effective in the resolution of some optimization problems in experimental design. However, the most interesting patterns of local behavior of Hellinger distance bringing about differences in the behavior of matrix lower bounds of the quadratic risk and multidimensional noninformative priors are observed when the parametric distribution family has different orders of nonregularity [
3] for different components of the vector parameter. Thus, the main challenge in the construction of a Hellinger information matrix in the general case consists in the necessity to consider different magnitudes of increments in different directions of the vector parametric space.
A general definition of the Hellinger information matrix was attempted in [
6] as related to information inequalities and in [
4] as related to noninformative priors. Important questions were left out, such as the conditions of Hellinger information matrix being positive definite and the existence of non-trivial matrix lower bounds for the quadratic risk in case of the vector parameter. These questions are addressed in
Section 3 of the paper. The main results are formulated, and several new examples are considered. General conclusions and possible future directions of study are discussed in
Section 4.
2. Hellinger Information for Scalar Parameter
In this section, we address the case of probability measures parametrized by a single parameter. We provide necessary definitions of information measures along with the discussion of their properties, including the new definition of Hellinger information. Then, we consider the applications of Hellinger information to the information inequalities of the Cramér–Frechet–Rao type, the construction of objective priors, and problems of optimal design.
Definition (2) is modified from [
8]. Inequality (5) was obtained in [
5]. Examples in
Section 2.3 are modified from [
4].
2.1. Definitions
A family of probability measures
is defined on a measurable space
so that all the measures from the family are absolutely continuous with respect to some
-finite measure
on
. The square of the Hellinger distance between any two parameter values can be defined in terms of densities
as
This definition of the Hellinger distance (also known as Hellinger–Bhattacharyya distance) in its modern form was given in [
9]. We use this definition to construct a new information measure. If for almost all
from
(with regard to measure
) there exists an
(
index of regularity) such that
we define
Hellinger information at a point
as
. The index of regularity is related to the local behavior of the density
. Using the classification of [
3],
corresponds to singularities of the first and the second type,
to densities with jumps, and
to singularities of the third type.
Notice that in the regular situations classified in [
3] (
is twice continuously differentiable with respect to
for almost all
with respect to
, the density support
does not depend on parameter
, Fisher information
is continuous, strictly positive and finite for almost all
from
), it is true that
. Under the regularity conditions above, the score function
has mean zero and Fisher information as variance. This helps to establish the connection of Fisher information to the limiting distribution of maximum likelihood estimators, its additivity with respect to i.i.d. sample observations, and its role in the lower bounds of risk (information inequalities).
Wasserstein information [
1] can be defined for the scalar parameter through the c.d.f.
as
which does not require differentiablity of the density function
. That opens new possibilities for the construction of an objective prior in the case of non-differentiable densities, see [
2].
However, we are interested in even less regular situations (including uniform densities with support depending on parameter) for which neither Fisher information nor Wasserstein information can be helpful, while Hellinger information may function as their substitute.
2.2. Information Inequalities
We define the quadratic Bayes risk for an estimator
constructed by an independent identically distributed sample
of size
n from the model considered above with
and prior
as
Let us consider an integral version of the classical Cramér–Frechet–Rao inequality, which under certain regularity conditions leads to the following asymptotic lower bound for the Bayes risk in terms of Fisher information:
This lower bound, which can be proven to be tight, was first obtained by [
10], also in [
11,
12] under slightly different regularity assumptions. This bound can be extended to the nonregular case, when Fisher information may not exist. One of these extensions is Hellinger information inequality, providing an asymptotic lower bound
obtained in [
6] under the assumptions of Hellinger information
being strictly positive, almost surely continuous, bounded on any compact subset of
, and satisfying condition
, where
is an open subset of real numbers and the constant
is related to technical details of the proof and is not necessarily tight.
The key identity establishing the role of
in the case of i.i.d. samples
easily follows from the definition and independence of
. Similar to the additivity of Fisher information, it allows for a transition from a single observation to a sample.
2.3. Hellinger Priors
The three most popular ways to obtain a non-informative prior might be as follows:
The Jeffreys rule
[
13],
Probability matching priors [
14,
15],
Reference priors [
16,
17].
For many regular parameter families, probability matching and reference priors both satisfy the Jeffreys rule. However, it is not necessary in case of multi-parametric families and the loss of regularity. Let us focus on the nonregular case, when Fisher information may not be defined. Most comprehensive results on reference priors in the nonregular case were obtained in [
18].
Define Hellinger prior for the parametric set as in [
4,
8]:
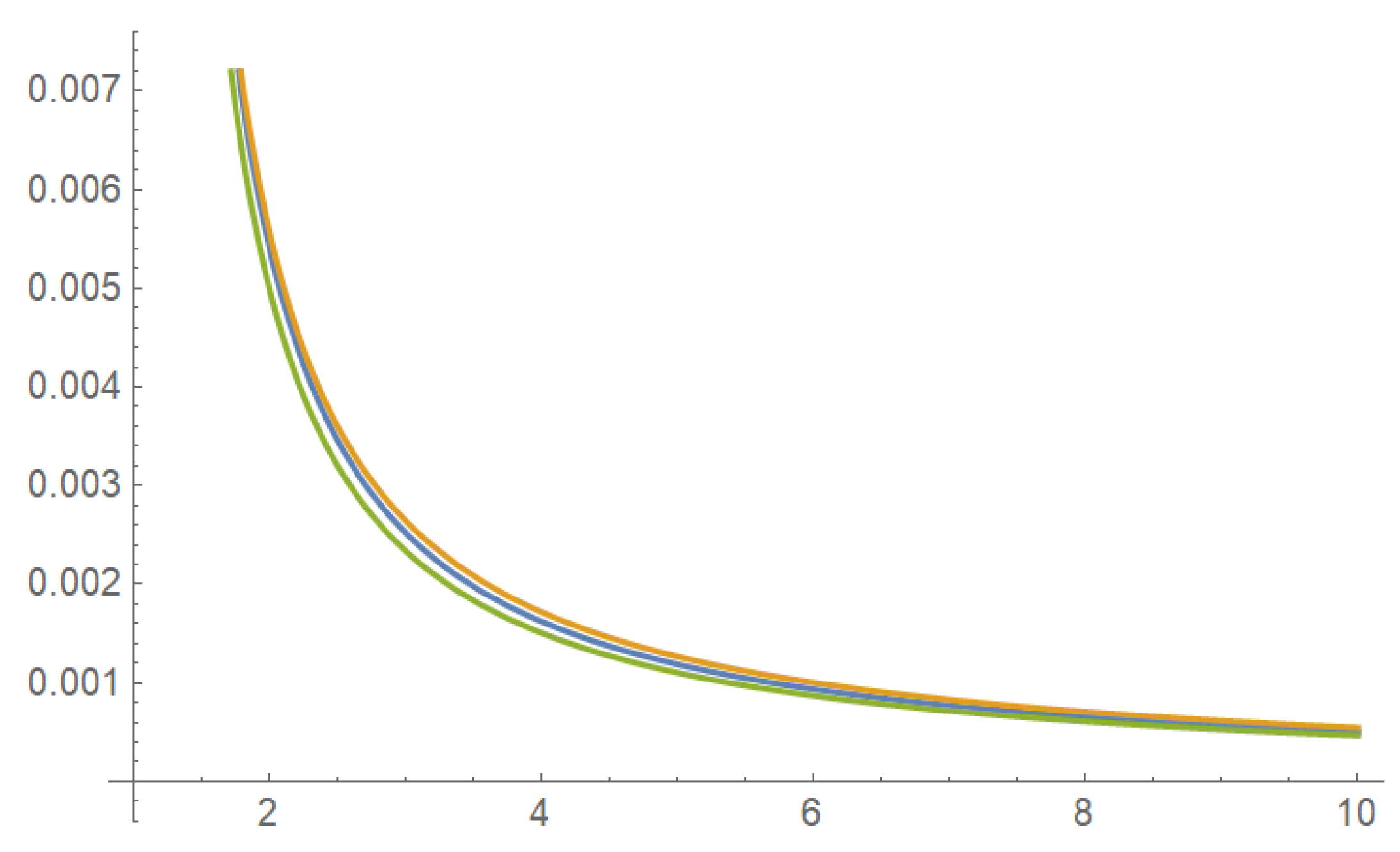
Hellinger priors will often coincide with well-known priors obtained by the approaches described above. However, there are some distinctions. A special role might be played by Hellinger priors in nonregular cases. We provide two simple examples of densities with support depending on the parameter.
Example 1. Uniform .The same prior can be constructed as the probability matching prior g or the reference prior [18]. Example 2. Uniform . This prior is different from the reference prior obtained in [
18] by rather technical calculations, maximizing the Kullback–Leibler divergence from the prior to the posterior:
where
is the polygamma function order 1. Tri Minh Le [
19] used a similar approach, maximizing Hellinger distance between the prior and the posterior, and obtained
All three priors in (8), (9), and (10) have distinct functional forms. However, they are very close after appropriate re-normalization on the entire domain, which can be demonstrated graphically and numerically. See
Figure 1 and the following comment.
For instance, the ratio monotonically increases for from 1 to ∞ so that
2.4. Optimal Design
A polynomial model of the experimental design may be presented as in [
20],
where
are scalars,
is the unknown vector parameter of interest, and errors
are non-negative i.i.d variables with density
(e.g., Weibull or Gamma). The space of balanced designs is defined as
and there exist several definitions of optimal design. Lin et al. [
7] suggest using criterion
where
is Hellinger information in the direction
, defined as
which is similar to the definition given in
Section 1, but notice the difference with (2) in the treatment of powers:
versus
in the denominator. Notice also that index of regularity
is assumed to be the same for all components of the vector parameter.
3. Hellinger Information Matrix for Vector Parameter
In this section, we concentrate on the multivariate parameter case allowing for different degrees of regularity for different components of the vector parameter. We define the Hellinger information matrix, determine our understanding of matrix information inequalities, formulate main results establishing lower bounds for the Bayes risk in terms of Hellinger information matrix, and provide examples of Hellinger priors illustrating the conditions of Theorems 1 and 2.
Proofs of the main results use the approach developed in [
5]; Example 3 was previously mentioned in [
8].
3.1. Definitions
Extending definitions of
Section 1 to the vector case
, we first introduce, as in [
6], the
Hellinger distance matrix H with elements
where increments
are columns of an
matrix
U. Define also vectors
(
index of regularity with components
) and
with components
,
such that for all
there exist finite non-degenerate limits
Then, the
Hellinger information matrix will be defined by its components
Notice that components of the vector index of regularity can be different, and therefore, components of the vector of increments can have different orders of magnitude with respect to . As a result, while the elements of matrix may expose different local behavior depending on the components of , the elements of matrix are all finite.
3.2. Information Inequalities
Define the matrix of Bayes risk for an i.i.d. sample
with
as
and matrix ordering
as asymptotic positive semi-definite property
Let also
denote the expectation over
. The following results formulate conditions under which the lower bounds for risk (14) in the sense of (15) are obtained in terms of Hellinger information and the index of regularity.
3.3. Main Results
Theorem 1. Let , ,Then, if , , it is true that - 1.
- 2.
Theorem 2. Let ,Then, if , it is true that - 1.
- 2.
Proofs of Theorems 1 and 2 are technically similar to the proof of the main results of [
5], although the definition of Hellinger information was not explicitly provided in that paper.
3.4. Hellinger Priors
If
, as in the conditions of Theorems 1 and 2, the vector Hellinger prior can be defined as
In the case of all components
, Hellinger information reduces to the Fisher information matrix, and our approach leads to the Jeffreys prior [
12].
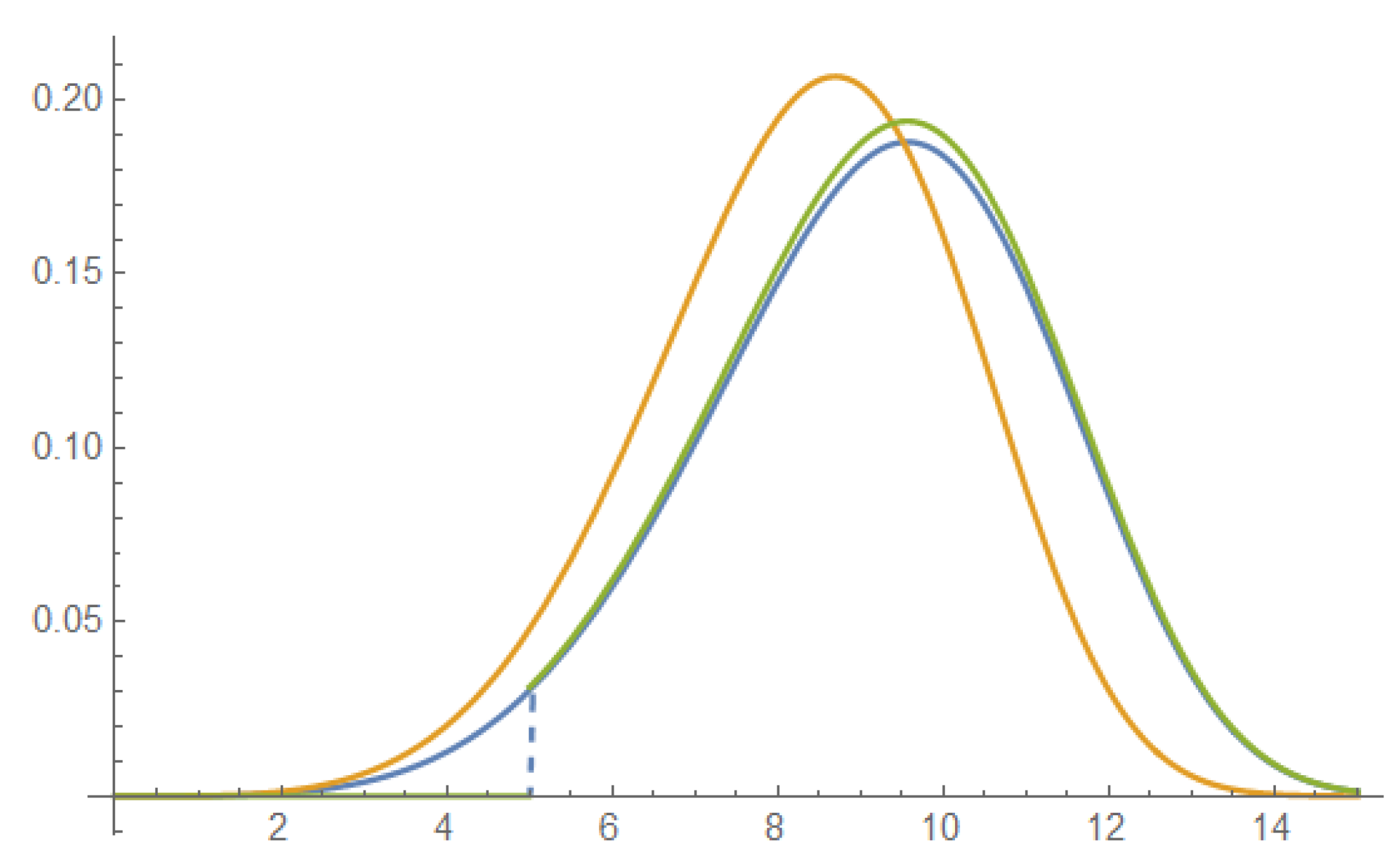
Example 3. Truncated Weibull distribution (see Theorem 1):with two parameters of interest: regular pseudo-scale and nonregular threshold . Assume fixed. See Figure 2. Using notation
, obtain
and
After limit transition in
,
Therefore,
, which is also the reference prior for the vector parameter [
21].
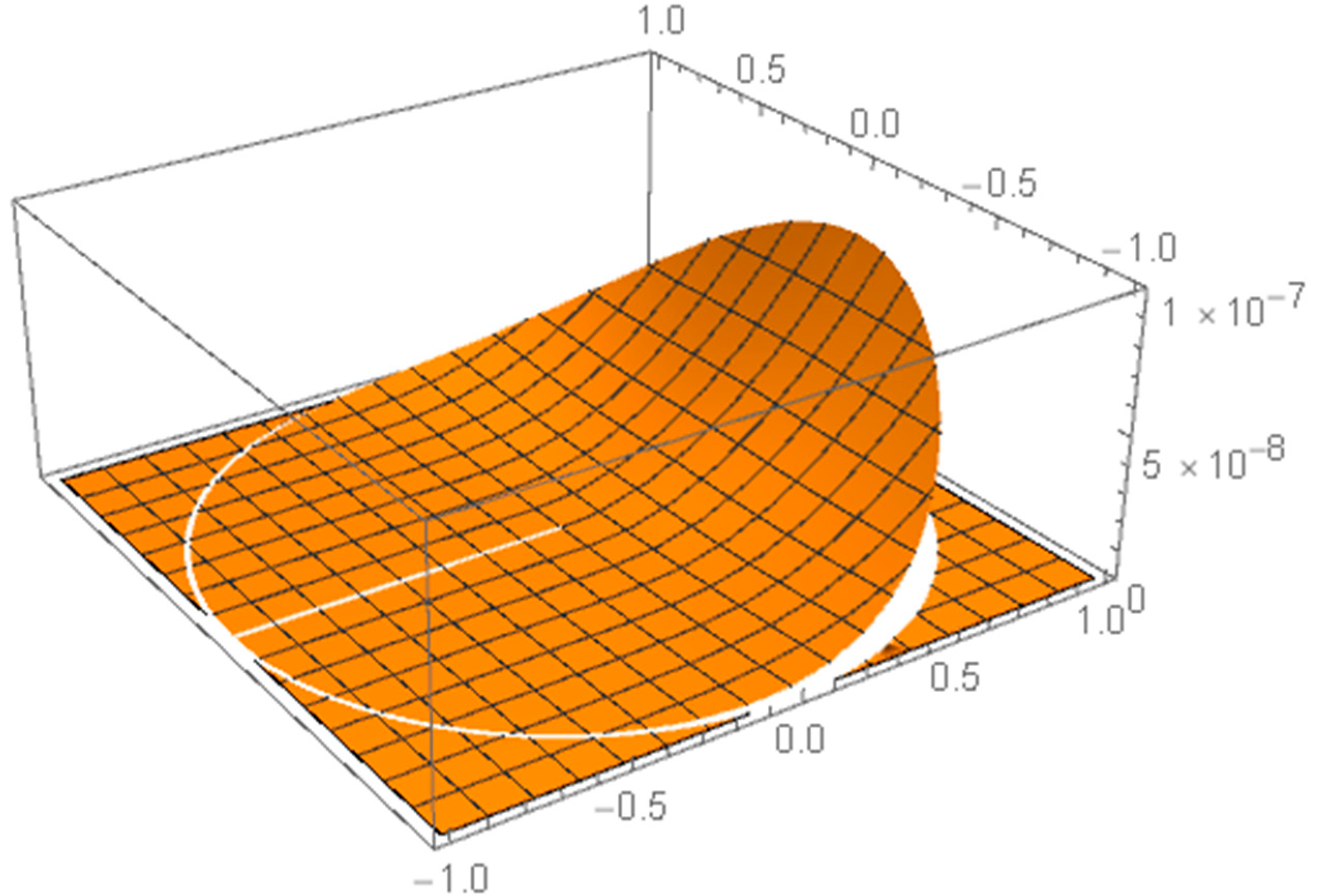
Example 4. Circular beta distribution on a disc (see Theorem 1):with three parameters of interest: regular and nonregular radius . See Figure 3.
where
is the polygamma function of order 1.
Therefore,
Example 5. Uniform on a rectangle (see Theorem 2): with two parameters of interest: regular pseudo-scale and nonregular threshold
Using notation , obtain andAfter the limit transition,Therefore, , also the reference prior. Example 6. Uniform with two moving boundaries (neither Theorem 1 nor Theorem 2 applies): using notation , obtain andAfter limit transition,Therefore, , also the reference prior. 4. Discussion
A Hellinger information matrix can be defined in a reasonable way to serve as a substitute for the Fisher information matrix in multivariate nonregular cases. It can be used as a technically simple tool for the elicitation of non-informative priors.
Properties of the Hellinger distance (symmetry, etc.) grant certain advantages vs analogous constructions based on Kullback–Leibler divergence.
Some interesting nonregularities are not covered by the conditions of Theorems 1 and 2 (see Example 6). More general results related to a positive definite property of would be interesting.
It is tempting to obtain Hellinger priors as the solution of a particular optimization problem (similar to the reference priors).
Funding
This research was supported by the Center for Applied Mathematics at the University of St. Thomas.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Acknowledgments
The author is grateful for helpful discussions at the online Borovkov Readings and O-Bayes-22 in Santa Cruz, CA in August 2022. The author is also thankful for many helpful comments by the reviewers.
Conflicts of Interest
The author declares no conflict of interest.
References
- Li, W.; Zhao, J. Wasserstein information matrix. arXiv 2019, arXiv:1910.11248. [Google Scholar]
- Li, W.; Rubio, F.J. On a prior based on the Wasserstein information matrix. arXiv 2022, arXiv:2202.03217. [Google Scholar] [CrossRef]
- Ibragimov, I.A.; Has’minskii, R.Z. Statistical Estimation: Asymptotic Theory; Springer: New York, NY, USA, 1981. [Google Scholar]
- Shemyakin, A. A New Approach to Construction of Objective Priors: Hellinger Information. Appl. Econom. 2012, 28, 124–137. (In Russian) [Google Scholar]
- Shemyakin, A. Rao-Cramer type multidimensional integral inequalities for parametric families with singularities. Sib. Math. J. 1991, 32, 706–715. (In Russian) [Google Scholar] [CrossRef]
- Shemyakin, A. On Information Inequalities in the Parametric Estimation. Theory Probab. Appl. 1992, 37, 89–91. [Google Scholar] [CrossRef]
- Lin, Y.; Martin, R.; Yang, M. On Optimal Designs for Nonregular Models. Ann. Statist. 2019, 47, 3335–3359. [Google Scholar] [CrossRef]
- Shemyakin, A. Hellinger Distance and Non-informative Priors. Bayesian Anal. 2014, 9, 923–938. [Google Scholar] [CrossRef]
- Bhattacharyya, A. On a measure of divergence between two statistical populations defined by their probability distributions. Bull. Calcutta Math. Soc. 1943, 35, 99–109. [Google Scholar]
- Bobrovsky, B.Z.; Mayer-Wof, E.; Zakai, M. Some classes of global Cramer-Rao bounds. Ann. Statist. 1987, 15, 1421–1438. [Google Scholar] [CrossRef]
- Brown, L.D.; Gajek, L. Information inequalities for the Bayes risk. Ann. Statist. 1990, 18, 1578–1594. [Google Scholar] [CrossRef]
- Jeffreys, H. An invariant form for the prior probability in estimation problems. Proc. R. Soc. Lond. Ser. Math. Phys. Sci. 1946, 186, 453–461. [Google Scholar]
- Ghosal, S. Probability matching priors for non-regular cases. Biometrika 1999, 86, 956–964. [Google Scholar] [CrossRef]
- Berger, J.O.; Bernardo, J.M.T. On the development of reference priors (with discussion). Bayesian Anal. 1992, 4, 35–60. [Google Scholar]
- Ghosal, S.; Samanta, T. Expansion of Bayes risk for entropy loss and reference prior in nonregular cases. Statist. Decis. 1997, 15, 129–140. [Google Scholar] [CrossRef]
- Berger, J.O.; Bernardo, J.M.; Sun, D. The formal definition of reference priors. Ann. Statist. 2009, 37, 905–938. [Google Scholar] [CrossRef]
- Sun, D.; Berger, J.O. Reference priors with partial information. Biometrika 1998, 85, 55–71. [Google Scholar] [CrossRef]
- Le, T.M. The Formal Definition of Reference Priors under a General Class of Divergence. Electronic Dissertations, University of Missouri-Columbia, Columbia, MO, USA, 2014. [Google Scholar] [CrossRef]
- Smith, R.L. Nonregular regression. Biometrika 1994, 81, 173–183. [Google Scholar] [CrossRef]
- Ghosal, S.; Ghosh, J.; Samanta, T. On convergence of posterior distributions. Ann. Statist. 1995, 23, 2145–2152. [Google Scholar] [CrossRef]
- Sun, D. A note on non-informative priors for Weibull distribution. J. Stat. Plan. Inference 1997, 61, 319–338. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).



{kind=link}
{kind=link}
{kind=link}


