
Manipulating Voice Attributes by Adversarial Learning of Structured Disentangled Representations


Abstract
:1. Introduction
1.1. Context
1.2. Related Works
1.3. Contributions of This Paper
- -
- An extension of the VC architecture presented in [40] that allows for the encoding and manipulation of the voice by means of multiple attributes (content, identity, age, or gender);
- -
- An implementation of a network for voice attribute disentanglement based on a fader network [33], an adversarial neural network originally established for face manipulation. In the proposed VC architecture, the speaker identity code is further decomposed adversarially into two parts, namely, a speaker identity code that is independent of the desired attribute and an attribute code;
- -
- The application of the proposed neural architecture to voice gender manipulation. While this study only focuses on voice gender manipulation, we foresee extending it in the future to manipulate other identity-related attributes such as age, accent, or speaking style.
2. Neural VC: Manipulating Identity and Beyond
2.1. Neural VC with Content and Identity Disentanglement
2.1.1. Speaker Encoder
2.1.2. Content Encoder
2.1.3. Disentangling Identity and Content Information
2.1.4. Decoder
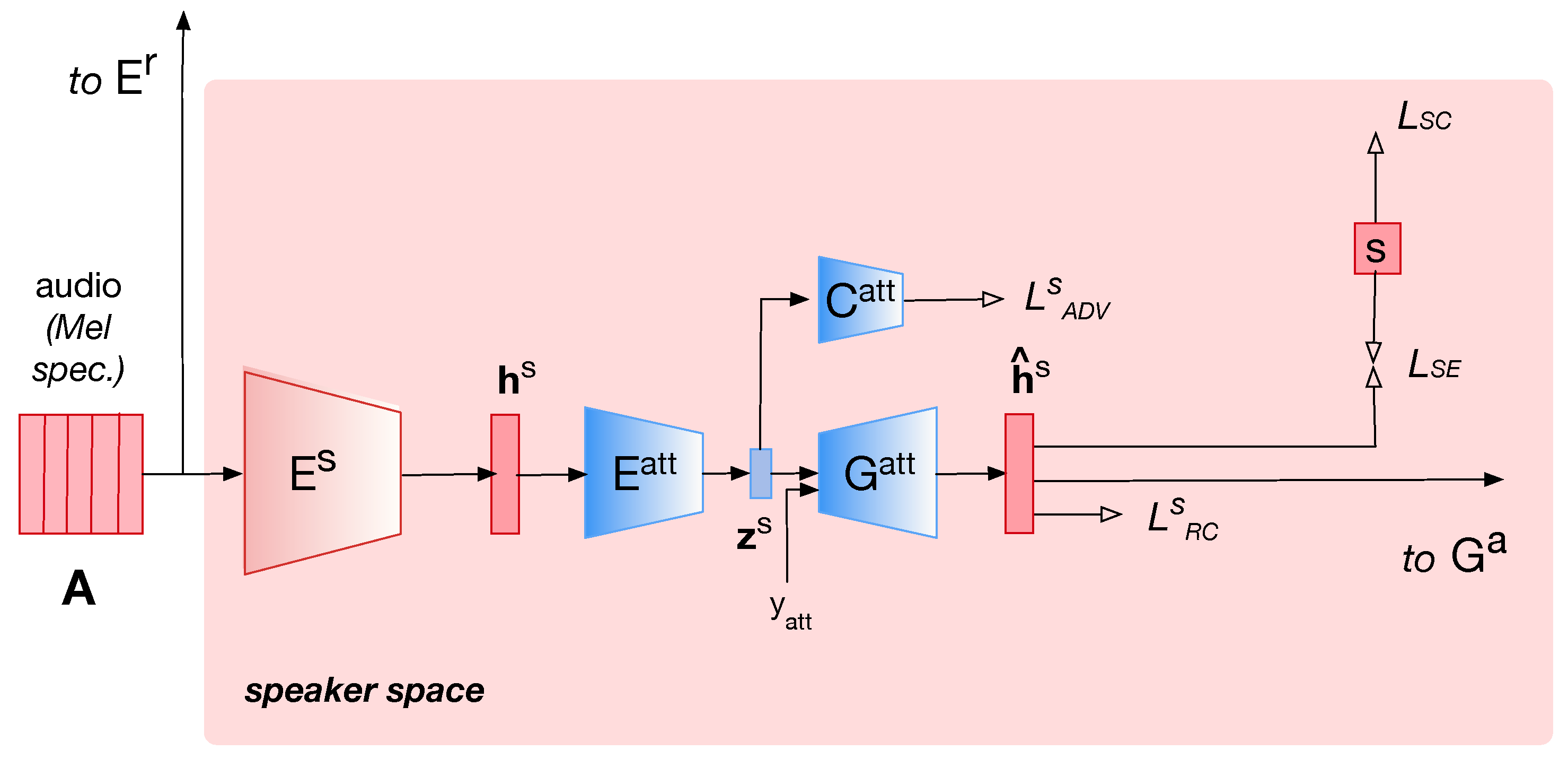
2.2. Disentanglement of Voice Attributes with Fader Network
3. Implementation Details
3.1. Neural VC Architecture
3.2. Pre- and Post-Processing
3.3. Computation Infrastructure and Runtime Costs
4. Experiments
4.1. Dataset
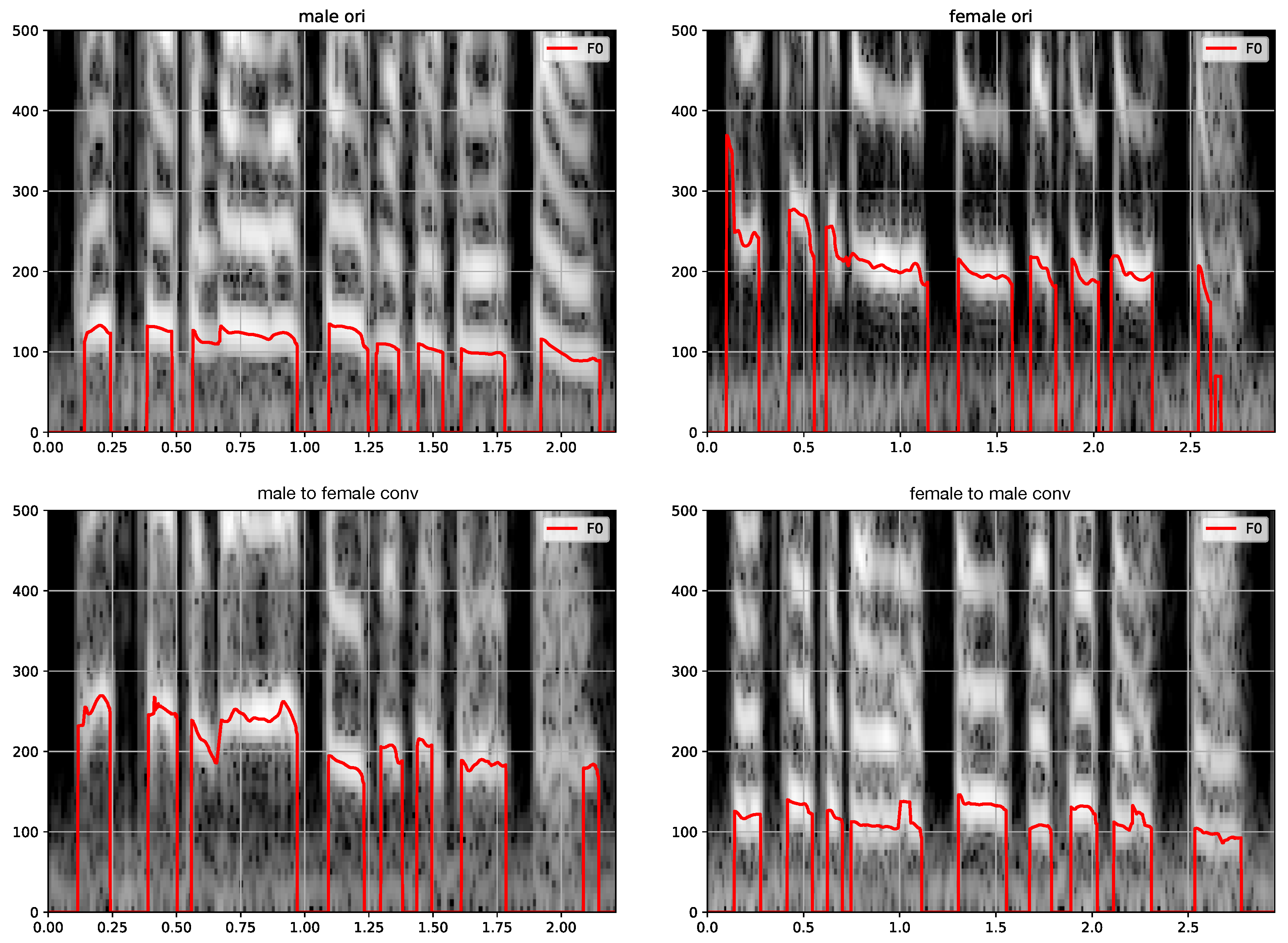
4.2. Preliminary Illustration
4.3. Objective Evaluations
4.3.1. Experiment 1: Gender Recognition
4.3.2. Experiment 2: Speaker Recognition
4.3.3. Experiment 3: Mutual Information and Visualization of Embeddings
4.4. Subjective Evaluation
4.4.1. Baseline Algorithm
4.4.2. Experimental Protocol
- (1)
- whether the voice is typically perceived as: feminine, rather feminine, uncertain, rather masculine, or masculine;
- (2)
- the sound quality on a standard Mean Opinion Score (MOS) 5-degree scale from 1 (bad) to 5 (perfect), which is commonly used for experimental evaluation of Text-To-Speech and Voice Conversion systems.
- (1)
- the original audio signal (True) and converted audio signal with:
- (2)
- the original VC system (VC);
- (3)
- a phase vocoder (phase voc.; see supplementary for details) with two cases: female-to-male conversion (f2m) and male-to-female conversion (m2f);
- (4)
- the VC system with the proposed gender autoencoder (base) with five conditioning values of the parameter ;
- (5)
- the VC system with the gender autoencoder but trained without the fader loss (nofader), with the five values of the parameter; and
- (6)
- the VC system with the gender autoencoder with the VC decoder re-trained (adapt) with the five values of the parameter.
4.4.3. Results and Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kuwabara, H.; Sagisak, Y. Acoustic Characteristics of Speaker Individuality: Control and Conversion. Speech Commun. 1995, 16, 165–173. [Google Scholar] [CrossRef]
- Stylianou, Y.; Cappé, O.; Moulines, E. Continuous Probabilistic Transform for Voice Conversion. IEEE Trans. Speech Audio Process. 1998, 6, 131–142. [Google Scholar] [CrossRef] [Green Version]
- Toda, T.; Chen, L.H.; Saito, D.; Villavicencio, F.; Wester, M.; Wu, Z.; Yamagishi, J. The Voice Conversion Challenge 2016. In Proceedings of the ISCA Interspeech, San Francisco, CA, USA, 8–12 September 2016; pp. 1632–1636. [Google Scholar]
- Lorenzo-Trueba, J.; Yamagishi, J.; Toda, T.; Saito, D.; Villavicencio, F.; Kinnunen, T.; Ling, Z. The Voice Conversion Challenge 2018: Promoting Development of Parallel and Nonparallel Methods. In Proceedings of the Speaker Odyssey: The Speaker and Language Recognition Workshop, Les Sables d’Olonne, France, 26–29 June 2018; pp. 195–202. [Google Scholar]
- Zhao, Y.; Huang, W.C.; Tian, X.; Yamagishi, J.; Das, R.K.; Kinnunen, T.; Ling, Z.; Toda, T. Voice Conversion Challenge 2020: Intra-lingual semi-parallel and cross-lingual voice conversion. In Proceedings of the ISCA Interspeech, Shanghai, China, 25–29 October 2020; pp. 80–98. [Google Scholar]
- Lorenzo-Trueba, J.; Fang, F.; Wang, X.; Echizen, I.; Yamagishi, J.; Kinnunen, T. Can we steal your vocal identity from the Internet?: Initial investigation of cloning Obama’s voice using GAN, WaveNet and low-quality found data. In Proceedings of the Speaker Odyssey: The Speaker and Language Recognition Workshop, Les Sables d’Olonne, France, 26–29 June 2018; pp. 240–247. [Google Scholar]
- Lal Srivastava, B.M.; Vauquier, N.; Sahidullah, M.; Bellet, A.; Tommasi, M.; Vincent, E. Evaluating Voice Conversion-Based Privacy Protection against Informed Attackers. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 2802–2806. [Google Scholar]
- Ericsson, D.; Östberg, A.; Listo Zec, E.; Martinsson, J.; Mogren, O. Adversarial representation learning for private speech generation. In Proceedings of the Workshop on Self-supervision in Audio and Speech at the International Conference on Machine Learning (ICML), Virtual, 12–18 July 2020. [Google Scholar]
- Wang, D.; Yu, J.; Wu, X.; Liu, S.; Sun, L.; Liu, X.; Meng, H. End-To-End Voice Conversion Via Cross-Modal Knowledge Distillation for Dysarthric Speech Reconstruction. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 7744–7748. [Google Scholar]
- Toda, T.; Ohtani, Y.; Shikano, K. One-to-Many and Many-to-One Voice Conversion Based on Eigenvoices. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Honolulu, HI, USA, 15–20 April 2007; Volume 4, pp. 1249–1252. [Google Scholar]
- Desai, S.; Raghavendra, E.V.; Yegnanarayana, B.; Black, A.W.; Prahallad, K. Voice conversion using Artificial Neural Networks. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 3893–3896. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Hsu, C.C.; Hwang, H.T.; Wu, Y.C.; Tsao, Y.; Wang, H.M. Voice Conversion from Non-parallel Corpora Using Variational Auto-encoder. In Proceedings of the Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA), Jeju, Republic of Korea, 13–16 December 2016; pp. 1–6. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar]
- Kaneko, T.; Kameoka, H. Parallel-Data-Free Voice Conversion Using Cycle-Consistent Adversarial Networks. arXiv 2017, arXiv:1711.11293. [Google Scholar]
- Kaneko, T.; Kameoka, H.; Tanaka, K.; Hojo, N. CycleGAN-VC2: Improved CycleGAN-based Non-parallel Voice Conversion. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6820–6824. [Google Scholar]
- Fang, F.; Yamagishi, J.; Echizen, I.; Lorenzo-Trueba, J. High-Quality Nonparallel Voice Conversion Based on Cycle-Consistent Adversarial Network. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5279–5283. [Google Scholar]
- Tanaka, K.; Kameoka, H.; Kaneko, T.; Hojo, N. AttS2S-VC: Sequence-to-Sequence Voice Conversion with Attention and Context Preservation Mechanisms. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6805–6809. [Google Scholar]
- Kameoka, H.; Tanaka, K.; Kwaśny, D.; Kaneko, T.; Hojo, N. ConvS2S-VC: Fully Convolutional Sequence-to-Sequence Voice Conversion. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 1849–1863. [Google Scholar] [CrossRef]
- Kameoka, H.; Kaneko, T.; Tanaka, K.; Hojo, N. StarGAN-VC: Non-parallel many-to-many Voice Conversion Using Star Generative Adversarial Networks. In Proceedings of the 2018 IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018; pp. 266–273. [Google Scholar]
- Kaneko, T.; Kameoka, H.; Tanaka, K.; Hojo, N. StarGAN-VC2: Rethinking Conditional Methods for StarGAN-Based Voice Conversion. In Proceedings of the ISCA Interspeech, Graz, Austria, 15–19 September 2019; pp. 679–683. [Google Scholar]
- Zhou, C.; Horgan, M.; Kumar, V.; Vasco, C.; Darcy, D. Voice Conversion with Conditional SampleRNN. In Proceedings of the ISCA Interspeech, Hyderabad, India, 2–6 September 2018; pp. 1973–1977. [Google Scholar]
- Lu, H.; Wu, Z.; Dai, D.; Li, R.; Kang, S.; Jia, J.; Meng, H. One-Shot Voice Conversion with Global Speaker Embeddings. In Proceedings of the ISCA Interspeech, Graz, Austria, 15–19 September 2019; pp. 669–673. [Google Scholar]
- Qian, K.; Zhang, Y.; Chang, S.; Yang, X.; Hasegawa-Johnson, M. AutoVC: Zero-Shot Voice Style Transfer with Only Autoencoder Loss. In Proceedings of the International Conference on Machine Learning (ICML), Long Beach, CA, USA, 10–15 June 2019; pp. 5210–5219. [Google Scholar]
- Zhang, Y.; Weiss, R.J.; Zen, H.; Wu, Y.; Chen, Z.; Skerry-Ryan, R.J.; Jia, Y.; Rosenberg, A.; Ramabhadran, B. Learning to Speak Fluently in a Foreign Language: Multilingual Speech Synthesis and Cross-Language Voice Cloning. In Proceedings of the ISCA Interspeech, Graz, Austria, 15–19 September 2019; pp. 2080–2084. [Google Scholar]
- Sun, L.; Li, K.; Wang, H.; Kang, S.; Meng, H. Phonetic Posteriorgrams for Many-to-One Voice Conversion without Parallel Data Training. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Seattle, WA, USA, 11–15 July 2016; pp. 1–6. [Google Scholar]
- Mohammadi, S.H.; Kim, T. One-Shot Voice Conversion with Disentangled Representations by Leveraging Phonetic Posteriorgrams. In Proceedings of the ISCA Interspeech, Graz, Austria, 15–19 September 2019; pp. 704–708. [Google Scholar]
- Jia, Y.; Zhang, Y.; Weiss, R.J.; Wang, Q.; Shen, J.; Ren, F.; Chen, Z.; Nguyen, P.; Pang, R.; Lopez-Moreno, I.; et al. Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 3–8 December 2018; pp. 4485–4495. [Google Scholar]
- Higgins, I.; Amos, D.; Pfau, D.; Racaniere, S.; Matthey, L.; Rezende, D.; Lerchner, A. Towards a Definition of Disentangled Representations. arXiv 2018, arXiv:1812.02230. [Google Scholar]
- Tishby, N.; Zaslavsky, N. Deep Learning and the Information Bottleneck Principle. In Proceedings of the IEEE Information Theory Workshop (ITW), Jerusalem, Israel, 26 April–1 May 2015. [Google Scholar]
- Lample, G.; Zeghidour, N.; Usunier, N.; Bordes, A.; Denoyer, L.; Ranzato, M. Fader Networks: Manipulating Images by Sliding Attributes. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 5967–5976. [Google Scholar]
- Belghazi, I.; Rajeswar, S.; Baratin, A.; Hjelm, R.D.; Courville, A.C. MINE: Mutual Information Neural Estimation. In Proceedings of the International Conference on Machine Learning (PMLR), Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Qian, K.; Zhang, Y.; Chang, S.; Hasegawa-Johnson, M.; Cox, D. Unsupervised Speech Decomposition via Triple Information Bottleneck. In Proceedings of the International Conference on Machine Learning (ICML), Virtual, 12–18 July 2020; pp. 7836–7846. [Google Scholar]
- Zhang, J.X.; Ling, Z.H.; Dai, L.R. Non-Parallel Sequence-to-Sequence Voice Conversion With Disentangled Linguistic and Speaker Representations. IEEE/ACM Trans. Audio Speech Lang. Process. (TASLP) 2020, 28, 540–552. [Google Scholar] [CrossRef] [Green Version]
- Yuan, S.; Cheng, P.; Zhang, R.; Hao, W.; Gan, Z.; Carin, L. Improving Zero-Shot Voice Style Transfer via Disentangled Representation Learning. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual, 3–7 May 2021. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.; Kim, S.; Choo, J. StarGAN: Unified Generative Adversarial Networks for Multi-domain Image-to-Image Translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8789–8797. [Google Scholar]
- Ying, L.; Fan, H.; Ni, F.; Xiang, J. ClsGAN: Selective Attribute Editing Based On Classification Adversarial Network. Neural Netw. 2019, 133, 220–228. [Google Scholar]
- Bous, F.; Benaroya, L.; Obin, N.; Roebel, A. Voice Reenactment with F0 and timing constraints and adversarial learning of conversions. In Proceedings of the European conference on signal processing (EUSIPCO), Dublin, Ireland, 23–27 August 2021. [Google Scholar]
- Qin, Z.; Kim, D.; Gedeon, T. Rethinking softmax with cross-entropy: Neural network classifier as mutual information estimator. In Proceedings of the International Conference on Machine Learning (ICML), Lille, France, 6–11 July 2015. [Google Scholar]
- Liu, L.J.; Ling, Z.H.; Jiang, Y.; Zhou, M.; Dai, L.R. WaveNet Vocoder with Limited Training Data for Voice Conversion. In Proceedings of the Interspeech 2018, Hyderabad, India, 2–6 September 2018; pp. 1983–1987. [Google Scholar]
- Griffin, D.; Lim, J. Signal Estimation from Modified Short-Time Fourier Transform. IEEE Trans. Acoust. Speech Signal Process. 1984, 32, 236–243. [Google Scholar] [CrossRef]
- Prenger, R.; Valle, R.; Catanzaro, B. WaveGlow: A Flow-based Generative Network for Speech Synthesis. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 3617–3621. [Google Scholar]
- Yamagishi, J.; Veaux, C.; Macdonald, K. CSTR VCTK Corpus: English Multi-Speaker Corpus for CSTR Voice Cloning Toolkit (Version 0.92); The Centre for Speech Technology Research (CSTR), University of Edinburgh: Edinburgh, UK, 2019. [Google Scholar]
- Farner, S.; Roebel, A.; Rodet, X. Natural transformation of type and nature of the voice for extending vocal repertoire in high-fidelity applications. In Proceedings of the Audio Engineering Society Conference: 35th International Conference: Audio for Games, London, UK, 11–13 February 2009. [Google Scholar]
- Gao, W.; Kannan, S.; Oh, S.; Viswanath, P. Estimating Mutual Information for Discrete-Continuous Mixtures. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 5986–5997. [Google Scholar]
- Peterson, G.E.; Barney, H.L. Control methods used in a study of the vowels. J. Acoust. Soc. Am. 1952, 24, 175–184. [Google Scholar] [CrossRef] [Green Version]
- Iseli, M.; Shue, Y.L.; Alwan, A. Age, sex, and vowel dependencies of acoustic measures related to the voice source. J. Acoust. Soc. Am. 2007, 121, 2283–2295. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Röbel, A. Shape-invariant speech transformation with the phase vocoder. In Proceedings of the Proc. International Conference on Spoken Language Processing (InterSpeech), Chiba, Japan, 26–30 September 2010; pp. 2146–2149. [Google Scholar]
- Röbel, A.; Rodet, X. Efficient Spectral Envelope Estimation and its application to pitch shifting and envelope preservation. In Proceedings of the 8th International Conference on Digital Audio Effects (DAFx’05), Madrid, Spain, 20–22 September 2005; pp. 30–35. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 2 layers BLSTM-Dropout(0.2), 256 cells each direction → FC-512-Tanh | |
| 2 layers BLSTM-Dropout(0.2), 128 cells each direction → average pooling → FC-128-Tanh | |
| 2 layers BLSTM, 64 cells each direction → FC-80 | |
| FC-60 | |
| FC-1 | |
| FC-128-Tanh |
| Gender Accuracy [%] | |
|---|---|
| with adv. loss | |
| Original | 99.2 |
| Est. Gender () | 99.0 |
| Inv. Gender () | 0.8 |
| De-gender () | 54.6 |
| without adv. loss | |
| Original | 99.2 |
| Est. Gender () | 99.2 |
| Inv. Gender () | 98.8 |
| De-gender () | 99.1 |
| EER [%] | |
|---|---|
| Original | 2.8 |
| Est. Gender () | 6.9 |
| Inv. Gender () | 9.2 |
| De-gender () | 6.8 |
| Mutual Information | |
|---|---|
| Original | 0.47 |
| Est. Gender () | 0.44 |
| Inv. Gender () | 0.38 |
| De-gender () | 0.16 |
| Latent code | 0.11 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Benaroya, L.; Obin, N.; Roebel, A. Manipulating Voice Attributes by Adversarial Learning of Structured Disentangled Representations. Entropy 2023, 25, 375. https://doi.org/10.3390/e25020375
Benaroya L, Obin N, Roebel A. Manipulating Voice Attributes by Adversarial Learning of Structured Disentangled Representations. Entropy. 2023; 25(2):375. https://doi.org/10.3390/e25020375
Chicago/Turabian StyleBenaroya, Laurent, Nicolas Obin, and Axel Roebel. 2023. "Manipulating Voice Attributes by Adversarial Learning of Structured Disentangled Representations" Entropy 25, no. 2: 375. https://doi.org/10.3390/e25020375
APA StyleBenaroya, L., Obin, N., & Roebel, A. (2023). Manipulating Voice Attributes by Adversarial Learning of Structured Disentangled Representations. Entropy, 25(2), 375. https://doi.org/10.3390/e25020375