
Semi-Supervised Semantic Segmentation of Remote Sensing Images Based on Dual Cross-Entropy Consistency


Abstract
:1. Introduction
2. The Proposed Model
2.1. Semi-Supervised Segmentation Model Based on Dual Cross-Entropy Consistency
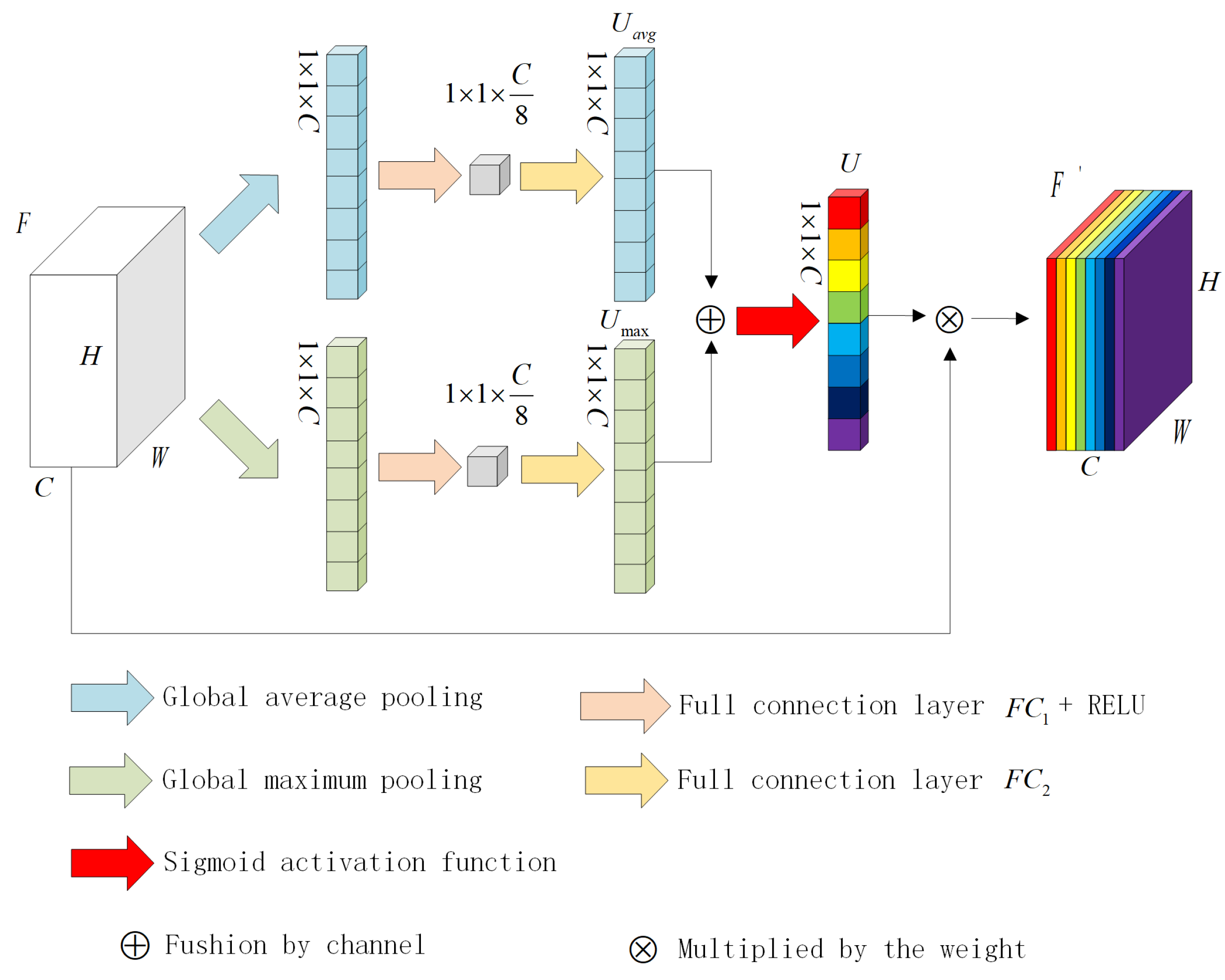
2.2. Channel Attention Mechanism
2.3. The Sharpen Function
2.4. Loss Function
3. Experiments
3.1. Experimental Dataset and Environment
3.2. Evaluation Indicators
3.3. Analysis of the Experimental Results
3.4. Ablation Experiment
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lu, H.; Liu, Q.; Liu, X.; Zhang, Y. A survey of semantic construction and application of satellite remote sensing images and data. J. Organ. End User Comput. (JOEUC) 2021, 33, 1–20. [Google Scholar] [CrossRef]
- Waage, M.; Singhroha, S.; Bünz, S.; Planke, S.; Waghorn, K.A.; Bellwald, B. Feasibility of using the P-Cable high-resolution 3D seismic system in detecting and monitoring CO2 leakage. Int. J. Greenh. Gas Control. 2021, 106, 103240. [Google Scholar] [CrossRef]
- Gómez, C.; White, J.C.; Wulder, M.A. Optical remotely sensed time series data for land cover classification: A review. ISPRS J. Photogramm. Remote Sens. 2016, 116, 55–72. [Google Scholar] [CrossRef]
- Lu, B.; Dao, P.D.; Liu, J.; He, Y.; Shang, J. Recent advances of hyperspectral imaging technology and applications in agriculture. Remote Sens. 2020, 12, 2659. [Google Scholar] [CrossRef]
- Sun, X.; Wang, B.; Wang, Z.; Li, H.; Li, H.; Fu, K. Research progress on few-shot learning for remote sensing image interpretation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2387–2402. [Google Scholar] [CrossRef]
- Chen, Z.; Zhang, T.; Ouyang, C. End-to-end airplane detection using transfer learning in remote sensing images. Remote Sens. 2018, 10, 139. [Google Scholar] [CrossRef]
- Wu, F.; Wang, Z.; Zhang, Z.; Yang, Y.; Luo, J.; Zhu, W.; Zhuang, Y. Weakly semi-supervised deep learning for multi-label image annotation. IEEE Trans. Big Data 2015, 1, 109–122. [Google Scholar] [CrossRef]
- Huang, B.; Zhao, B.; Song, Y. Urban land-use mapping using a deep convolutional neural network with high spatial resolution multispectral remote sensing imagery. Remote Sens. Environ. 2018, 214, 73–86. [Google Scholar] [CrossRef]
- Song, X.; Aryal, S.; Ting, K.M.; Liu, Z.; He, B. Spectral–spatial anomaly detection of hyperspectral data based on improved isolation forest. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–16. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhang, Z.; Wu, C.; Zhang, Z.; He, T.; Zhang, H.; Manmatha, R.; Li, M.; Smola, A.J. Improving Semantic Segmentation via Efficient Self-Training. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef] [PubMed]
- Tarvainen, A.; Valpola, H. Mean Teachers Are Better Role Models: Weight-Averaged Consistency Targets Improve Semi-Supervised Deep Learning Results. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 1195–1204. [Google Scholar]
- Luo, Y.; Zhu, J.; Li, M.; Ren, Y.; Zhang, B. Smooth neighbors on teacher graphs for semi-supervised learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8896–8905. [Google Scholar]
- Ke, Z.; Qiu, D.; Li, K.; Yan, Q.; Lau, R.W. Guided collaborative training for pixel-wise semi-supervised learning. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 429–445. [Google Scholar]
- Zou, Y.; Zhang, Z.; Zhang, H.; Li, C.L.; Bian, X.; Huang, J.B.; Pfister, T. PseudoSeg: Designing Pseudo Labels for Semantic Segmentation. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Sohn, K.; Berthelot, D.; Carlini, N.; Zhang, Z.; Zhang, H.; Raffel, C.A.; Cubuk, E.D.; Kurakin, A.; Li, C.L. Fixmatch: Simplifying semi-supervised learning with consistency and confidence. Adv. Neural Inf. Process. Syst. 2020, 33, 596–608. [Google Scholar]
- Chen, X.; Yuan, Y.; Zeng, G.; Wang, J. Semi-supervised semantic segmentation with cross pseudo supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2613–2622. [Google Scholar]
- Wu, Y.; Xu, M.; Ge, Z.; Cai, J.; Zhang, L. Semi-supervised left atrium segmentation with mutual consistency training. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, 27 September–1 October 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 297–306. [Google Scholar]
- Chen, S.; Bortsova, G.; García-Uceda Juárez, A.; Van Tulder, G.; De Bruijne, M. Multi-task attention-based semi-supervised learning for medical image segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2019: 22nd International Conference, Shenzhen, China, 13–17 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 457–465. [Google Scholar]
- Ouali, Y.; Hudelot, C.; Tami, M. Semi-supervised semantic segmentation with cross-consistency training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12674–12684. [Google Scholar]
- Wu, J.; Fan, H.; Zhang, X.; Lin, S.; Li, Z. Semi-supervised semantic segmentation via entropy minimization. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Vu, T.H.; Jain, H.; Bucher, M.; Cord, M.; Pérez, P. Advent: Adversarial entropy minimization for domain adaptation in semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2517–2526. [Google Scholar]
- Nie, D.; Gao, Y.; Wang, L.; Shen, D. ASDNet: Attention based semi-supervised deep networks for medical image segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2018: 21st International Conference, Granada, Spain, 16–20 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 370–378. [Google Scholar]
- Guo, X.; Yuan, Y. Semi-supervised WCE image classification with adaptive aggregated attention. Med Image Anal. 2020, 64, 101733. [Google Scholar] [CrossRef] [PubMed]
- Falk, T.; Mai, D.; Bensch, R.; Çiçek, Ö.; Abdulkadir, A.; Marrakchi, Y.; Böhm, A.; Deubner, J.; Jäckel, Z.; Seiwald, K.; et al. U-Net: Deep learning for cell counting, detection, and morphometry. Nat. Methods 2019, 16, 67–70. [Google Scholar] [CrossRef] [PubMed]
- Xiong, Z.; Guo, Q.; Liu, M.; Li, A. Pan-sharpening based on convolutional neural network by using the loss function with no-reference. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 897–906. [Google Scholar] [CrossRef]
- Petrovai, A.; Nedevschi, S. Exploiting pseudo labels in a self-supervised learning framework for improved monocular depth estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1578–1588. [Google Scholar]
- Liu, R.; Li, S.; Liu, J.; Ma, L.; Fan, X.; Luo, Z. Learning hadamard-product-propagation for image dehazing and beyond. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 1366–1379. [Google Scholar] [CrossRef]
- Botev, Z.I.; Kroese, D.P.; Rubinstein, R.Y.; L’Ecuyer, P. The cross-entropy method for optimization. In Handbook of Statistics; Elsevier: Amsterdam, The Netherlands, 2013; Volume 31, pp. 35–59. [Google Scholar]
- Tong, X.Y.; Xia, G.S.; Lu, Q.; Shen, H.; Li, S.; You, S.; Zhang, L. Land-cover classification with high-resolution remote sensing images using transferable deep models. Remote Sens. Environ. 2020, 237, 111322. [Google Scholar] [CrossRef]
- He, T.; Zhang, Z.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of tricks for image classification with convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 558–567. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Dehghan, M.; Zaiane, O.R.; Jagersand, M. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognit. 2020, 106, 107404. [Google Scholar] [CrossRef]
- Feng, Z.; Zhou, Q.; Gu, Q.; Tan, X.; Cheng, G.; Lu, X.; Shi, J.; Ma, L. Dmt: Dynamic mutual training for semi-supervised learning. Pattern Recognit. 2022, 130, 108777. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Method | Labeled Image Proportion | |||
|---|---|---|---|---|---|
| 1/8 | 1/4 | 1/2 | 1 | ||
| Potsdam | Unet | - | - | - | 78.2 |
| Attention-Unet | - | - | - | 81.4 | |
| U2-Net | - | - | - | 81.3 | |
| MeanTeacher | 70.5 | 72.1 | 76.1 | - | |
| CPS | 73.4 | 75.2 | 77.8 | - | |
| DST-CBC | 73.3 | 75.4 | 78.3 | - | |
| Our Algorithm | 71.2 | 74.9 | 80.5 | 82.1 | |
| Vaihingen | Unet | - | - | - | 76.8 |
| Attention-Unet | - | - | - | 78.1 | |
| U2-Net | - | - | - | 78.3 | |
| MeanTeacher | 70.2 | 72.1 | 73.8 | - | |
| CPS | 71.7 | 72.8 | 74.0 | - | |
| DST-CBC | 72.3 | 73.4 | 74.9 | - | |
| Our Algorithm | 71.0 | 73.5 | 77.4 | 78.4 | |
| GID | Unet | - | - | - | 79.8 |
| Attention-Unet | - | - | - | 81.1 | |
| U2-Net | - | - | - | 81.2 | |
| MeanTeacher | 70.9 | 72.5 | 75.8 | - | |
| CPS | 72.6 | 75.7 | 76.4 | - | |
| DST-CBC | 72.4 | 75.1 | 76.5 | - | |
| Our Algorithm | 72.1 | 76.3 | 81.8 | 82.1 | |
| Dataset | Method | Category | Labeled Image Proportion | |||
|---|---|---|---|---|---|---|
| 1/8 | 1/4 | 1/2 | 1 | |||
| Potsdam | Our Algorithm | Impervious surface | 75.2 | 77.1 | 83.6 | 85.5 |
| Building | 76.9 | 81.8 | 86.3 | 87.3 | ||
| Low vegetation | 67.1 | 71.8 | 76.4 | 78.7 | ||
| Tree | 71.7 | 74.8 | 81.6 | 82.3 | ||
| Car | 69.5 | 73.1 | 78.8 | 80.7 | ||
| Clutter | 66.9 | 70.8 | 76.3 | 77.9 | ||
| Vaihingen | Our Algorithm | Impervious surface | 73.5 | 76.9 | 79.4 | 81.9 |
| Building | 77.9 | 81.0 | 83.4 | 85.2 | ||
| Low vegetation | 70.5 | 71.6 | 76.2 | 75.9 | ||
| Tree | 72.1 | 73.9 | 79.1 | 78.3 | ||
| Car | 59.2 | 62.2 | 66.5 | 68.5 | ||
| Clutter | 72.8 | 75.4 | 79.8 | 80.6 | ||
| GID | Our Algorithm | Farmland | 73.7 | 77.6 | 82.5 | 84.1 |
| Forest | 79.2 | 83.0 | 88.2 | 87.7 | ||
| Building | 77.2 | 81.2 | 86.5 | 86.6 | ||
| Meadow | 59.5 | 64.4 | 70.9 | 71.5 | ||
| Water | 71.1 | 75.3 | 80.9 | 80.5 | ||
| Dataset | Labeled Image Proportion | Method | MIou (%) |
|---|---|---|---|
| Potsdam | 1/2 | Baseline | 75.8 |
| Baseline + CA | 76.3 | ||
| Baseline + sharpen (s1) | 77.2 | ||
| Baseline + sharpen (s2) | 77.4 | ||
| Baseline + sharpen | 78.1 | ||
| Our Algorithm | 80.5 | ||
| Vaihingen | 1/2 | Baseline | 72.3 |
| Baseline + CA | 72.9 | ||
| Baseline + sharpen (s1) | 73.5 | ||
| Baseline + sharpen (s2) | 73.4 | ||
| Baseline + sharpen | 74.6 | ||
| Our Algorithm | 77.4 | ||
| GID | 1/2 | Baseline | 75.3 |
| Baseline + CA | 76.5 | ||
| Baseline + sharpen (s1) | 77.2 | ||
| Baseline + sharpen (s2) | 77.0 | ||
| Baseline + sharpen | 79.1 | ||
| Our Algorithm | 81.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, M.; Li, K.; Li, Y.; Kamuhanda, D.; Tessone, C.J. Semi-Supervised Semantic Segmentation of Remote Sensing Images Based on Dual Cross-Entropy Consistency. Entropy 2023, 25, 681. https://doi.org/10.3390/e25040681
Cui M, Li K, Li Y, Kamuhanda D, Tessone CJ. Semi-Supervised Semantic Segmentation of Remote Sensing Images Based on Dual Cross-Entropy Consistency. Entropy. 2023; 25(4):681. https://doi.org/10.3390/e25040681
Chicago/Turabian StyleCui, Mengtian, Kai Li, Yulan Li, Dany Kamuhanda, and Claudio J. Tessone. 2023. "Semi-Supervised Semantic Segmentation of Remote Sensing Images Based on Dual Cross-Entropy Consistency" Entropy 25, no. 4: 681. https://doi.org/10.3390/e25040681
APA StyleCui, M., Li, K., Li, Y., Kamuhanda, D., & Tessone, C. J. (2023). Semi-Supervised Semantic Segmentation of Remote Sensing Images Based on Dual Cross-Entropy Consistency. Entropy, 25(4), 681. https://doi.org/10.3390/e25040681