

On Neural Networks Fitting, Compression, and Generalization Behavior via Information-Bottleneck-like Approaches


Abstract
:1. Introduction
1.1. Paper Contributions
- 1
- First, we propose to use more tractable measures to capture the relationship between an intermediate network data representation and the original data or the intermediate network representation and the data label. In particular, we used the minimum mean-squared error between the intermediate data representation and the original data to try to capture fitting and compression phenomena occurring in a neural network; we also used the well-known cross-entropy between the intermediate data representation and the data label to capture performance.
- 2
- Second, by building upon the variational representations of these quantities, we also propose to estimate such measures using neural networks. In particular, our experimental results demonstrate that such an approach leads to consistent estimates of the measures using different estimator neural network architectures and initializations.
- 3
- Finally, using our proposed approach, we conducted an empirical study to reveal the influence of various factors on neural network learning processing, including compression, fitting, and generalization phenomena. Specifically, we considered the impact of (1) the machine learning model, (2) the learning algorithm (optimizer and regularization techniques), and (3) the data.
1.2. Scope of Study
1.3. Paper Organization
1.4. Paper Notation
2. Related Work
3. Proposed Framework
- First, the minimum mean-squared error can act as a proxy to capture fitting—the lower the MMSE, the easier it is to recover the data from the representation—and compression—the higher the MMSE, the more difficult it is to estimate the data from the representation.
- Second, this quantity is also easier to estimate than mutual information, allowing us to capture the phenomena above reliably (see Section 5.1).
- Finally, the minimum mean-squared error is also connected to mutual information (see Section 3.1).
3.1. Connecting our Approach to the Information Bottleneck
4. Implementation Aspects
4.1. Experimental Procedure
| Algorithm 1: Train the subject network |
 |
| Algorithm 2: Estimate Z-X measure and Z-Y measure |
 |
4.2. Experimental Setups
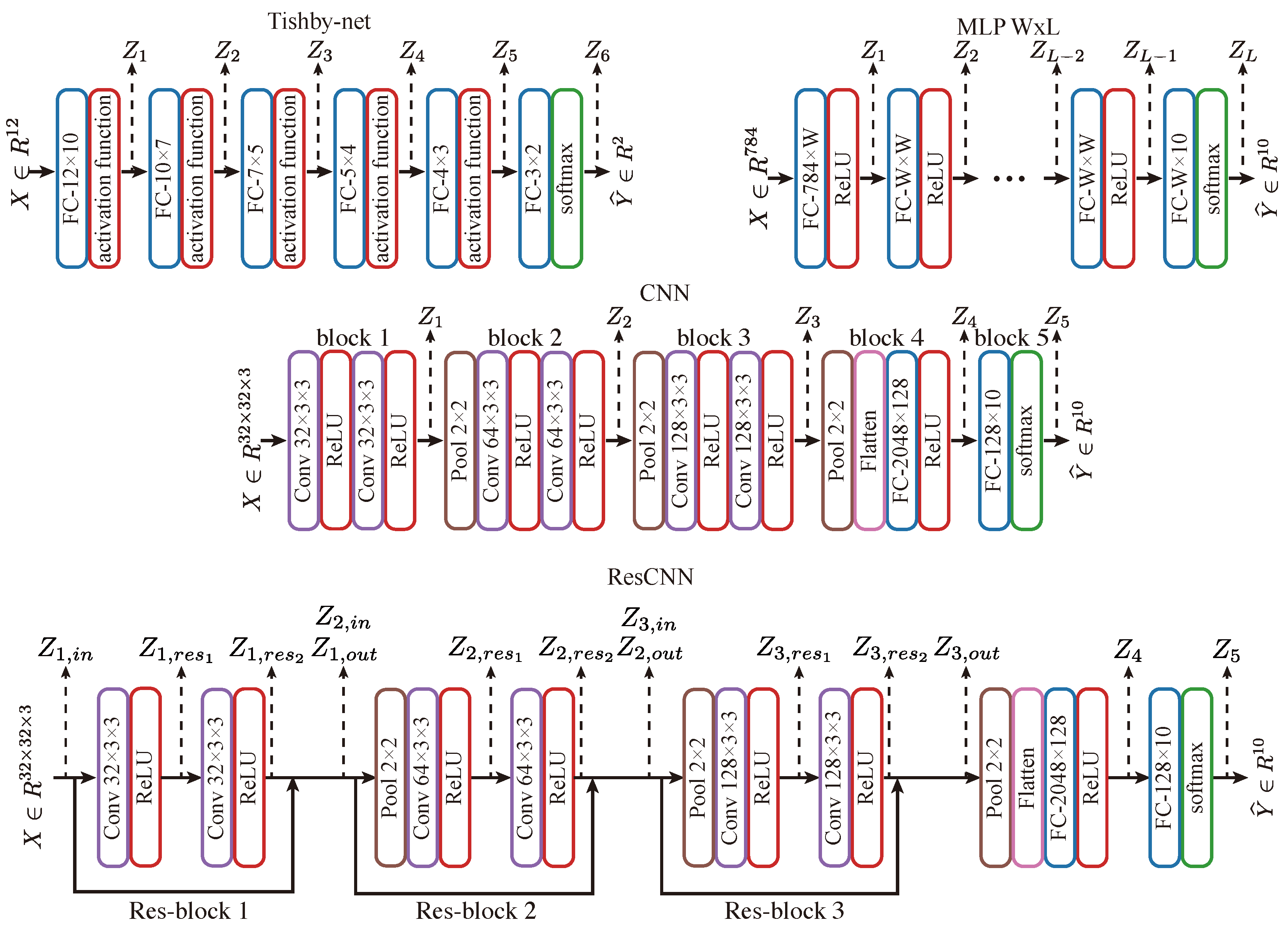
- For Tishby-net and MLP WxL models, the models for both the Z-X measure estimator and Z-Y measure estimator are fully connected neural networks. The input layer of the estimator networks matches the dimension of the representation (), while the output layer has a dimension equivalent to either the input vector (for Z-X measures) or label length (for Z-Y measures). If the estimator network has multiple layers, its hidden layers will be connected using ReLU non-linearity and have a number of neurons equal to the dimension of representation ().
- To estimate the Z-Y measure for CNN and ResCNN, we flattened the representation into a vector and employed the same network architecture as for the Z-Y measure estimator of Tishby-net and MLP WxL models. In turn, to estimate the Z-X measure, we used a convolution layer with a 3 × 3 kernel size to map the representation into the input space of . However, if the representation is down-sampled by a pooling layer (e.g., Figure 2 CNN ), we up-sampled it using a transposed convolutional layer with a 2 × 2 kernel size before feeding it into the convolutional layer. The number of transposed convolutional layers equals the number of pooling layers that the representation has gone through since each transposed convolutional layer can only up-sample the representation by a factor of 2. ReLU non-linearity exists between all hidden layers. For example, when the representation is generated by a layer with two pooling layers before it (e.g., Figure 2 CNN ), the estimator for the Z-X measure would contain two transposed convolutional layers.
4.3. Other Practical Considerations
- (1)
- Parallelize checkpoint enumeration : To plot the Z-X / Z-Y measures dynamics, we need to calculate these quantities at different checkpoints saved from various epochs during the training of the subject network.We can easily deploy multiple Algorithm 2 instances on different checkpoints saved per Algorithm 1 in parallel;
- (2)
- Parallelize layer iteration : We can also break up the iteration of l layers in Algorithm 2 into parallel processes since the estimations of the measures on different layers are independent;
- (3)
- Parallelize estimation of Z-X measure and Z-Y measure: We can also deploy the Z-X measure estimator and the Z-Y measure estimator on different processes because they are also independent;
- (4)
- Warm-start: Moreover, we can accelerate the convergence of estimator networks by using warm-start. We randomly initialized and trained the estimators from scratch in the first checkpoint for Tishby-net and MLP WxL models. We then used the learned parameters as initialization for the estimators in subsequent checkpoints. However, we did not use warm-start in CNN and ResCNN estimator networks as it does not noticeably accelerate convergence in these cases.
5. Results
5.1. Z-X and Z-Y Measures Estimation Stability
5.1.1. Criteria to Describe the Stability of Estimated Measures
- Stability with regard to the initialization of estimator networks: First, we explored how different initializations of an estimator network affect the Z-X and Z-Y measures.
- Stability with regard to the architecture of estimator networks: Second, we also explored how (estimator) neural network architectures—with different depths—affect the estimation of the Z-X and Z-Y measures.
5.1.2. Subject Networks, Estimator Networks, and Datasets Involved
5.1.3. Are the Measures Stable in the MLP-like Subject Neural Networks?
5.1.4. Are the Measures Stable in the Convolutional Subject Neural Networks?
5.2. The Impact of Model Architectures to the Network Dynamics
5.2.1. Does the Activation Function Affect the Existence of F/C Phases?
5.2.2. How Do the Width and Depth of an MLP Impact Network Dynamics?
5.2.3. How Do the Number of Kernels and Kernel Size of a CNN Impact Network Dynamics?
5.2.4. How Does Residual Connection Affect the Network Dynamics?
5.3. The Impact of Training Algorithm to the Network Dynamics
5.3.1. How Does the Optimizer Impact the Network Dynamics?
5.3.2. How Does Regularization Impact the Network Dynamics?
5.4. The Impact of Dataset to the Network Dynamics
6. Conclusions
- Impact of Neural Network Architecture:
- −
- We have found that MLPs appear to compress regardless of the non-linear activation function.
- −
- We have observed that MLP generalization, fitting, and compression behavior depend on the number of neurons per layer and the number of layers. In general, the MLPS offering the best generalization performance exhibit more pronounced fitting and compression phases.
- −
- We have also observed that CNN generalization, fitting, and compression behavior also depend on the kernel’s number/size. In general, CNNs exhibiting the best generalization performance also exhibit pronounced fitting and compression phases.
- −
- Finally, we have seen that the fitting/compression behavior exhibited by networks with residual connections is rather distinct from that shown in networks without such connections.
- Impact of Neural Network Algorithms: We have observed that adaptive optimizers seem to lead to more compression/better generalization in relation to non-adaptive ones. Likewise, we have also observed that regulation can help with compression/generalization.
- Impact of Dataset: Our main observation is that insufficient training data may prevent a model from compressing and hence generalizing; in turn, models trained with sufficient training data exhibit both a fitting phase followed by a compression phase, resulting in a higher generalization performance.
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Estimator Network Architectures



Appendix B. Empirical Comparison of MMSE Estimator and MI Estimator for Multivariant Gaussian Random Variables

References
- Shalev-Shwartz, S.; Ben-David, S. Understanding Machine Learning: From Theory to Algorithms; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Bengio, Y.; Goodfellow, I.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2017; Volume 1. [Google Scholar]
- Raukur, T.; Ho, A.C.; Casper, S.; Hadfield-Menell, D. Toward Transparent AI: A Survey on Interpreting the Inner Structures of Deep Neural Networks. arXiv 2022, arXiv:2207.13243. [Google Scholar]
- Ma, S.; Bassily, R.; Belkin, M. The Power of Interpolation: Understanding the Effectiveness of SGD in Modern Over-parametrized Learning. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Frei, S.; Chatterji, N.S.; Bartlett, P.L. Benign Overfitting without Linearity: Neural Network Classifiers Trained by Gradient Descent for Noisy Linear Data. arXiv 2022, arXiv:2202.05928. [Google Scholar]
- Tishby, N.; Pereira, F.C.; Bialek, W. The information bottleneck method. arXiv 2000, arXiv:physics/0004057. [Google Scholar]
- Tishby, N.; Zaslavsky, N. Deep learning and the information bottleneck principle. In Proceedings of the 2015 IEEE Information Theory Workshop (ITW), Jerusalem, Israel, 26 April–1 May 2015; pp. 1–5. [Google Scholar]
- Shwartz-Ziv, R.; Tishby, N. Opening the black box of deep neural networks via information. arXiv 2017, arXiv:1703.00810. [Google Scholar]
- Belghazi, M.I.; Baratin, A.; Rajeshwar, S.; Ozair, S.; Bengio, Y.; Courville, A.; Hjelm, D. Mutual information neural estimation. In Proceedings of the International Conference on Machine Learning, PMLR, Vienna, Austria, 25–31 July 2018; pp. 531–540. [Google Scholar]
- Poole, B.; Ozair, S.; Van Den Oord, A.; Alemi, A.; Tucker, G. On variational bounds of mutual information. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 5171–5180. [Google Scholar]
- Chelombiev, I.; Houghton, C.; O’Donnell, C. Adaptive estimators show information compression in deep neural networks. arXiv 2019, arXiv:1902.09037. [Google Scholar]
- Geiger, B.C. On Information Plane Analyses of Neural Network Classifiers–A Review. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 7039–7051. [Google Scholar] [CrossRef]
- Fang, H.; Wang, V.; Yamaguchi, M. Dissecting deep learning networks—Visualizing mutual information. Entropy 2018, 20, 823. [Google Scholar] [CrossRef] [Green Version]
- Elad, A.; Haviv, D.; Blau, Y.; Michaeli, T. Direct validation of the information bottleneck principle for deep nets. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Yu, S.; Wickstrøm, K.; Jenssen, R.; Principe, J.C. Understanding convolutional neural networks with information theory: An initial exploration. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 435–442. [Google Scholar] [CrossRef] [Green Version]
- Elidan, G.; Friedman, N.; Chickering, D.M. Learning Hidden Variable Networks: The Information Bottleneck Approach. J. Mach. Learn. Res. 2005, 6, 81–127. [Google Scholar]
- Wickstrøm, K.; Løkse, S.; Kampffmeyer, M.; Yu, S.; Principe, J.; Jenssen, R. Information plane analysis of deep neural networks via matrix-based Renyi’s entropy and tensor kernels. arXiv 2019, arXiv:1909.11396. [Google Scholar]
- Kirsch, A.; Lyle, C.; Gal, Y. Scalable training with information bottleneck objectives. In Proceedings of the International Conference on Machine Learning (ICML): Workshop on Uncertainty and Robustness in Deep Learning, Virtual, 17–18 July 2020. [Google Scholar]
- Jónsson, H.; Cherubini, G.; Eleftheriou, E. Convergence behavior of DNNs with mutual-information-based regularization. Entropy 2020, 22, 727. [Google Scholar] [CrossRef]
- Schiemer, M.; Ye, J. Revisiting the Information Plane. 2020. Available online: https://openreview.net/forum?id=Hyljn1SFwr (accessed on 5 May 2023).
- Goldfeld, Z.; Berg, E.v.d.; Greenewald, K.; Melnyk, I.; Nguyen, N.; Kingsbury, B.; Polyanskiy, Y. Estimating information flow in deep neural networks. arXiv 2018, arXiv:1810.05728. [Google Scholar]
- Lorenzen, S.S.; Igel, C.; Nielsen, M. Information Bottleneck: Exact Analysis of (Quantized) Neural Networks. arXiv 2021, arXiv:2106.12912. [Google Scholar]
- Shwartz-Ziv, R.; Alemi, A.A. Information in infinite ensembles of infinitely-wide neural networks. In Proceedings of the Symposium on Advances in Approximate Bayesian Inference, PMLR, Vancouver, BC, Canada, 8 December 2020; pp. 1–17. [Google Scholar]
- Saxe, A.M.; Bansal, Y.; Dapello, J.; Advani, M.; Kolchinsky, A.; Tracey, B.D.; Cox, D.D. On the information bottleneck theory of deep learning. J. Stat. Mech. Theory Exp. 2019, 2019, 124020. [Google Scholar] [CrossRef]
- Zeitler, G.; Koetter, R.; Bauch, G.; Widmer, J. Design of network coding functions in multihop relay networks. In Proceedings of the 2008 5th International Symposium on Turbo Codes and Related Topics, Lausanne, Switzerland, 1–5 September 2008; pp. 249–254. [Google Scholar]
- Noshad, M.; Zeng, Y.; Hero, A.O. Scalable mutual information estimation using dependence graphs. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2962–2966. [Google Scholar]
- Abrol, V.; Tanner, J. Information-bottleneck under mean field initialization. In Proceedings of the ICML 2020 Workshop on Uncertainty and Robustness in Deep Learning, Virtual, 17–18 July 2020. [Google Scholar]
- Darlow, L.N.; Storkey, A. What Information Does a ResNet Compress? arXiv 2020, arXiv:2003.06254. [Google Scholar]
- Cheng, H.; Lian, D.; Gao, S.; Geng, Y. Utilizing Information Bottleneck to Evaluate the Capability of Deep Neural Networks for Image Classification †. Entropy 2019, 21, 456. [Google Scholar] [CrossRef] [Green Version]
- Voloshynovskiy, S.; Taran, O.; Kondah, M.; Holotyak, T.; Rezende, D.J. Variational Information Bottleneck for Semi-Supervised Classification. Entropy 2020, 22, 943. [Google Scholar] [CrossRef]
- Yu, S.; Príncipe, J.C. Understanding Autoencoders with Information Theoretic Concepts. Neural Netw. 2018, 117, 104–123. [Google Scholar] [CrossRef] [Green Version]
- Tapia, N.I.; Est’evez, P.A. On the Information Plane of Autoencoders. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Lee, S.; Jo, J. Compression phase is not necessary for generalization in representation learning. arXiv 2021, arXiv:2102.07402. [Google Scholar]
- Raj, V.; Nayak, N.; Kalyani, S. Understanding learning dynamics of binary neural networks via information bottleneck. arXiv 2020, arXiv:2006.07522. [Google Scholar]
- Strouse, D.; Schwab, D.J. The deterministic information bottleneck. Neural Comput. 2017, 29, 1611–1630. [Google Scholar] [CrossRef] [Green Version]
- Hsu, H.; Asoodeh, S.; Salamatian, S.; Calmon, F.P. Generalizing bottleneck problems. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; pp. 531–535. [Google Scholar]
- Pensia, A.; Jog, V.; Loh, P.L. Extracting robust and accurate features via a robust information bottleneck. IEEE J. Sel. Areas Inf. Theory 2020, 1, 131–144. [Google Scholar] [CrossRef]
- Xu, Y.; Zhao, S.; Song, J.; Stewart, R.; Ermon, S. A Theory of Usable Information under Computational Constraints. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Dubois, Y.; Kiela, D.; Schwab, D.J.; Vedantam, R. Learning optimal representations with the decodable information bottleneck. Adv. Neural Inf. Process. Syst. 2020, 33, 18674–18690. [Google Scholar]
- Wongso, S.; Ghosh, R.; Motani, M. Using Sliced Mutual Information to Study Memorization and Generalization in Deep Neural Networks. In Proceedings of the International Conference on Artificial Intelligence and Statistics, PMLR, Valencia, Spain, 25–27 April 2023; pp. 11608–11629. [Google Scholar]
- Wongso, S.; Ghosh, R.; Motani, M. Understanding Deep Neural Networks Using Sliced Mutual Information. In Proceedings of the 2022 IEEE International Symposium on Information Theory (ISIT), Espoo, Finland, 26 June–1 July 2022; pp. 133–138. [Google Scholar]
- Polyanskiy, Y.; Wu, Y. Lecture notes on information theory. Lect. Notes ECE563 (UIUC) 2014, 6, 7. [Google Scholar]
- Kolchinsky, A.; Tracey, B.D. Estimating mixture entropy with pairwise distances. Entropy 2017, 19, 361. [Google Scholar] [CrossRef] [Green Version]
- Moon, Y.I.; Rajagopalan, B.; Lall, U. Estimation of mutual information using kernel density estimators. Phys. Rev. E 1995, 52, 2318. [Google Scholar] [CrossRef]
- Kolchinsky, A.; Tracey, B.D.; Wolpert, D.H. Nonlinear information bottleneck. Entropy 2019, 21, 1181. [Google Scholar] [CrossRef] [Green Version]
- Kraskov, A.; Stögbauer, H.; Grassberger, P. Estimating mutual information. Phys. Rev. E 2004, 69, 066138. [Google Scholar] [CrossRef] [Green Version]
- Kirsch, A.; Lyle, C.; Gal, Y. Learning CIFAR-10 with a simple entropy estimator using information bottleneck objectives. In Proceedings of the Workshop Uncertainty and Robustness in Deep Learning at International Conference on Machine Learning, ICML, Virtual, 17–18 July 2020. [Google Scholar]
- Goldfeld, Z.; Greenewald, K. Sliced mutual information: A scalable measure of statistical dependence. Adv. Neural Inf. Process. Syst. 2021, 34, 17567–17578. [Google Scholar]
- Li, J.; Liu, D. Information Bottleneck Theory on Convolutional Neural Networks. arXiv 2019, arXiv:1911.03722. [Google Scholar] [CrossRef]
- Song, J.; Ermon, S. Understanding the Limitations of Variational Mutual Information Estimators. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Wu, Y.; Verdú, S. Functional properties of minimum mean-square error and mutual information. IEEE Trans. Inf. Theory 2011, 58, 1289–1301. [Google Scholar] [CrossRef]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010. [Google Scholar]
- LeCun, Y.; Cortes, C.; Burges, C. MNIST Handwritten Digit Database. ATT Labs [Online]. 2010, Volume 2. Available online: http://yann.lecun.com/exdb/mnist (accessed on 1 May 2023).
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; Technical Report; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Darlow, L.N.; Crowley, E.J.; Antoniou, A.; Storkey, A.J. CINIC-10 is not ImageNet or CIFAR-10. arXiv 2018, arXiv:1810.03505. [Google Scholar]
- Díaz, M.; Kairouz, P.; Liao, J.; Sankar, L. Neural Network-based Estimation of the MMSE. In Proceedings of the 2021 IEEE International Symposium on Information Theory (ISIT), Melbourne, Australia, 12–20 July 2021; pp. 1023–1028. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian Error Linear Units (GELUs). arXiv 2020, arXiv:1606.08415. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics. JMLR Workshop and Conference Proceedings, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Clevert, D.A.; Unterthiner, T.; Hochreiter, S. Fast and accurate deep network learning by exponential linear units (elus). arXiv 2015, arXiv:1511.07289. [Google Scholar]
- Ramachandran, P.; Zoph, B.; Le, Q.V. Searching for activation functions. arXiv 2017, arXiv:1710.05941. [Google Scholar]
- Elfwing, S.; Uchibe, E.; Doya, K. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning. Neural Netw. 2018, 107, 3–11. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; Volume 30, p. 3. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Qian, N. On the momentum term in gradient descent learning algorithms. Neural Netw. 1999, 12, 145–151. [Google Scholar] [CrossRef]
- Hinton, G. Coursera Neural Networks for Machine Learning; Lecture 6; University of Toronto: Toronto, ON, Canada, 2018. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Choi, D.; Shallue, C.J.; Nado, Z.; Lee, J.; Maddison, C.J.; Dahl, G.E. On Empirical Comparisons of Optimizers for Deep Learning. arXiv 2019, arXiv:1910.05446. [Google Scholar]
- Bianchini, B.; Halm, M.; Matni, N.; Posa, M. Generalization Bounded Implicit Learning of Nearly Discontinuous Functions. In Proceedings of the Conference on Learning for Dynamics & Control, Virtual Event, 7–8 June 2021. [Google Scholar]
- Oord, A.v.d.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Hjelm, R.D.; Fedorov, A.; Lavoie-Marchildon, S.; Grewal, K.; Bachman, P.; Trischler, A.; Bengio, Y. Learning deep representations by mutual information estimation and maximization. arXiv 2018, arXiv:1808.06670. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Model | Training Algorithm | Dataset | Section | Our Observation | Related Literature |
|---|---|---|---|---|---|---|
| Effects of model architectures | Tishby-nets with saturated or non-saturated activation functions | SGD | Tishby-dataset | Section 5.2.1 | Fit./Com. phases exist regardless of the type of activation function. | [8,11,14,24,26,27] |
| MLPs with more or fewer neurons per layer | MNIST | Section 5.2.2 | MLPs with more neurons per layer exhibit faster Fit., more Com., and better Gen. | - | ||
| MLPs with more or fewer layers | MLPs with more layers have less Fit. but more Com. The MLP that exhibits more pronounced Fit. and Com. also tends to Gen. better. | [27] | ||||
| CNNs with more or fewer kernels | Adam | CIFAR-10 | Section 5.2.3 | CNNs with fewer kernels cannot Fit. and Com. effectively, and do not Gen. well. Increasing the number of kernels on a well-generalized CNN does not have a significant impact on Fit., Com., or Gen. | - | |
| CNNs with bigger or smaller kernels | Both very large and very small kernel sizes tend to result in less Fit. and Com., and can harm Gen. | |||||
| ResCNN | Section 5.2.4 | The representations at the outputs of residual blocks do not exhibit Fit./Com. phases, while the representations in the residual blocks exhibit Fit./Com. phases. | [13,18,28] | |||
| Effects of training algorithms | CNN | SGD, SGD-momentum, RMSprop, Adam | Section 5.3.1 | Adaptive optimizers compress more on layers closer to the input. | [29] | |
| MLP | SGD with or without weight decay | MNIST | Section 5.3.2 | Weight decay does not significantly affect the Fit. phase, but it can increase the Com. capability of the model and improve its Gen. performance. | [11,18,21] | |
| CNN | Adam with or without dropout | CIFAR-10 | A low dropout rate does not significantly impact Fit., but it can enhance Com. and improve Gen. In contrast, a high dropout rate can lead to less Fit. and Com., resulting in worse Gen. | - | ||
| Effects of dataset size | Adam | CIFAR-10, CINIC | Section 5.4 | CINIC dataset enhances Fit., Com., and Gen. CIFAR-10 subset has less Com. and worse Gen. | [8,14] |
| Subject Network | ep. | Train Loss | Test Loss | GE | Train acc. | Test acc. |
|---|---|---|---|---|---|---|
| MLP 16 × 4 | 197 | 0.0890 | 0.1471 | 0.0581 | 0.9740 | 0.9572 |
| MLP 64 × 4 | 168 | 0.0344 | 0.0967 | 0.0623 | 0.9919 | 0.9748 |
| MLP 512 × 4 | 142 | 0.0191 | 0.0697 | 0.0506 | 0.9967 | 0.9800 |
| MLP 64 × 2 | 299 | 0.0688 | 0.1247 | 0.0559 | 0.9815 | 0.9760 |
| MLP 64 × 3 | 275 | 0.0338 | 0.0570 | 0.0232 | 0.9919 | 0.9762 |
| MLP 64 × 4 | 142 | 0.0344 | 0.0967 | 0.0623 | 0.9919 | 0.9748 |
| MLP 64 × 5 | 85 | 0.0659 | 0.1185 | 0.0526 | 0.9822 | 0.9672 |
| MLP 64 × 6 | 68 | 0.0736 | 0.1320 | 0.0584 | 0.9798 | 0.9616 |
| Subject Network | ep. | Train Loss | Test Loss | GE | Train acc. | Test acc. |
|---|---|---|---|---|---|---|
| CNN baseline | 5 | 0.6747 | 0.8300 | 0.1553 | 0.7657 | 0.7190 |
| CNN ×2 | 7 | 0.3826 | 0.8303 | 0.4477 | 0.8637 | 0.7514 |
| CNN ×4 | 4 | 0.5667 | 0.7801 | 0.2135 | 0.8001 | 0.7332 |
| CNN /2 | 11 | 0.6015 | 0.9055 | 0.3040 | 0.7871 | 0.7008 |
| CNN /4 | 14 | 0.7704 | 1.0494 | 0.2790 | 0.7306 | 0.6492 |
| CNN /8 | 26 | 0.9515 | 1.1353 | 0.1838 | 0.6589 | 0.6060 |
| CNN 1 × 1 | 18 | 1.0307 | 1.1860 | 0.1553 | 0.6343 | 0.5978 |
| CNN 3 × 3 | 5 | 0.6747 | 0.8065 | 0.1318 | 0.7657 | 0.7190 |
| CNN 5 × 5 | 9 | 0.6001 | 0.9805 | 0.3804 | 0.7887 | 0.6958 |
| CNN 7 × 7 | 6 | 0.8372 | 1.2011 | 0.3639 | 0.7031 | 0.6042 |
| Subject Network | ep. | Train Loss | Test Loss | GE | Train acc. | Test acc. |
|---|---|---|---|---|---|---|
| CNN SGD | 106 | 0.0202 | 0.0429 | 0.0226 | 0.9945 | 0.9882 |
| CNN SGD-momentum | 131 | 0.0130 | 0.0356 | 0.0226 | 0.9972 | 0.9882 |
| CNN Adam | 24 | 0.0067 | 0.0275 | 0.0208 | 0.9979 | 0.9896 |
| CNN RMSproop | 11 | 0.0123 | 0.0263 | 0.0139 | 0.9965 | 0.9908 |
| Subject Network | ep. | Train Loss | Test Loss | GE | Train acc. | Test acc. |
|---|---|---|---|---|---|---|
| MLP w/o WD | 168 | 0.0344 | 0.0967 | 0.0623 | 0.9919 | 0.9748 |
| MLP w/ WD | 626 | 0.0216 | 0.0722 | 0.0505 | 0.9976 | 0.9784 |
| CNN 0% dropout | 5 | 0.6747 | 0.8300 | 0.1553 | 0.7657 | 0.7190 |
| CNN 30% dropout | 12 | 0.4993 | 0.7985 | 0.2992 | 0.7608 | 0.7398 |
| CNN 60% dropout | 10 | 0.6888 | 0.7606 | 0.0718 | 0.8237 | 0.7510 |
| CNN 90% dropout | 19 | 1.0768 | 0.8765 | 0.2003 | 0.5959 | 0.7000 |
| Subject Network | ep. | Train Loss | Test Loss | GE | Train acc. | Test acc. |
|---|---|---|---|---|---|---|
| CNN 1% CIFAR-10 | 38 | 1.2497 | 1.9902 | 0.7405 | 0.5380 | 0.3248 |
| CNN 100% CIFAR-10 | 5 | 0.6747 | 0.8300 | 0.1553 | 0.7657 | 0.7190 |
| CNN CINIC | 12 | 0.5952 | 0.6395 | 0.0443 | 0.7744 | 0.7872 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lyu, Z.; Aminian, G.; Rodrigues, M.R.D. On Neural Networks Fitting, Compression, and Generalization Behavior via Information-Bottleneck-like Approaches. Entropy 2023, 25, 1063. https://doi.org/10.3390/e25071063
Lyu Z, Aminian G, Rodrigues MRD. On Neural Networks Fitting, Compression, and Generalization Behavior via Information-Bottleneck-like Approaches. Entropy. 2023; 25(7):1063. https://doi.org/10.3390/e25071063
Chicago/Turabian StyleLyu, Zhaoyan, Gholamali Aminian, and Miguel R. D. Rodrigues. 2023. "On Neural Networks Fitting, Compression, and Generalization Behavior via Information-Bottleneck-like Approaches" Entropy 25, no. 7: 1063. https://doi.org/10.3390/e25071063
APA StyleLyu, Z., Aminian, G., & Rodrigues, M. R. D. (2023). On Neural Networks Fitting, Compression, and Generalization Behavior via Information-Bottleneck-like Approaches. Entropy, 25(7), 1063. https://doi.org/10.3390/e25071063