1. Introduction
With the development of various time-sensitive applications, such as the industrial Internet of Things and automatic driving, the freshness of information has attracted more and more attention. It is important to transmit time-sensitive information to the central controller in a timely manner in order to ensure safety and efficient control in these networks.
Figure 1 shows a scenario for the industrial IoT where the central processor monitors the real-time status of various network components, including materials, equipment, power, transportation, staff, etc.
To evaluate the freshness of status updates, researchers have introduced the concept of the age of information (AoI) [
1], which is defined as the time elapsed since the the generation of the most recent status update. Previous studies [
2,
3,
4,
5,
6,
7,
8,
9,
10] have focused on developing scheduling algorithms that minimize the average AoI across the network in the generate-at-will scenario, which means the generation of status update packets can be controlled. Various low-complexity algorithms were presented in [
2] to minimize the average AoI in the network, demonstrating their proximity to the theoretical lower bound. Power constraints and cross-layer scheduling were considered in [
6], where the authors formulated the AoI optimization problem as a constrained Markov decision process and proposed an effective asymptotic optimal scheduling algorithm.
In addition to the generate-at-will scenario, researchers also focus on the random-update scenario, where status updates arrive at terminal devices randomly. Several scheduling algorithms have been proposed in [
11,
12,
13,
14,
15,
16] to minimize the average AoI. However, in the random-update scenario, the AoI may not show the desynchronization of the information. For example, if no new update arrives after the latest update is received, the information at the receiver remains fresh while the AoI still keeps increasing.
Therefore, the concept of the age of synchronization (AoS) was proposed in [
17], which is defined as the time elapsed since the desynchronization of the freshest information at the receiver. An age-based max-weight policy was proposed in [
18] to minimize the time-average AoS in error-free transmission scenarios. In [
19], scheduling algorithms based on the Markov decision process and the restless multi-arm bandit were designed to optimize AoS in unreliable wireless transmission channels. Additionally, when transmitting over unreliable time-varying wireless channels, the authors in [
20] modeled the AoS optimization problem as a constrained Markov decision process and revealed a threshold structure for the optimal policy. The primary objective of these works was to minimize the time-average AoS of the whole system. However, in broadcast services, network users may possess varying levels of importance and diverse requirements, such as different throughput needs. Previous studies have investigated the design of scheduling strategies that optimize data freshness, taking into account heterogeneous requirements such as timely throughput and transmission delay [
5,
21,
22,
23]. These works indicated that the AoS optimization strategies may cause unfairness among different users.
To address this issue, we consider a model in which each user in the network has a time-average throughput need. Our objective is to propose scheduling policies that not only minimize the time-average AoS for network users but also ensure that the throughput requirement of each user is met. Under different conditions, we propose three corresponding scheduling policies. To be specific, we propose the optimal stationary randomized policy, the max-weight policy, and the distributed policy to deal with ACK-available/ACK-unavailable and centralized/distributed scenarios, respectively. Part of this work has been published in Proceedings of the 2022 IEEE International Symposium on Broadband Multimedia Systems and Broadcasting (BMSB) [
24].
The rest of the paper is structured in the following manner.
Section 2 introduces the system model, the constraints, and the definition of AoS, and the optimization problem is modeled. In
Section 3, a lower bound of the AoS optimization problem is presented. In
Section 4, we proposed three scheduling policies—the optimal stationary randomized policy, the max-weight policy, and the distributed policy—and give the corresponding algorithms. In
Section 5, the performance of the policies is shown and compared with numerical simulations. Finally,
Section 6 concludes the paper.
2. System Model
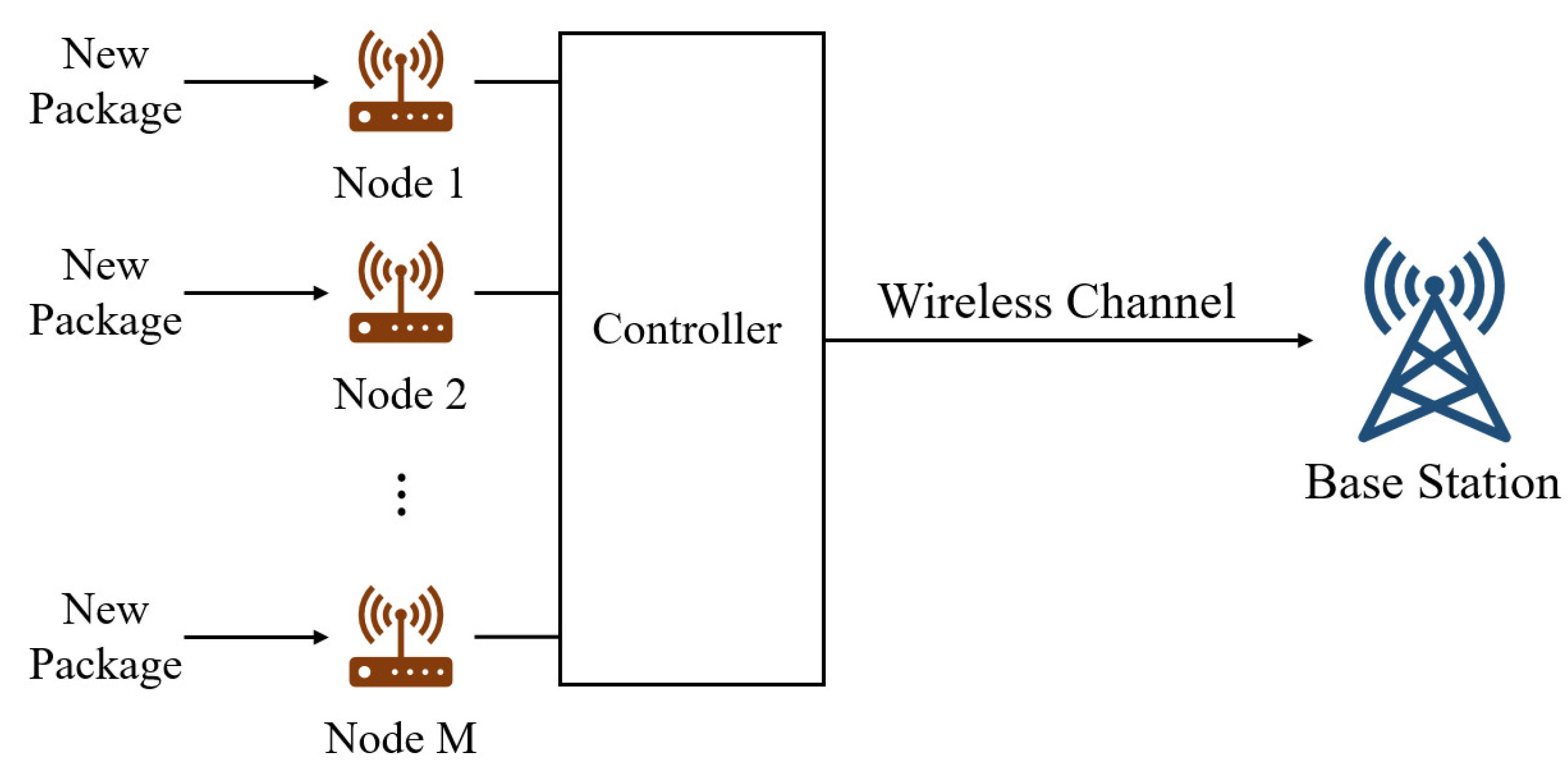
We consider a model where
M nodes transmit random status updates to a base station (BS), as illustrated in
Figure 2. The time is slotted and denoted by
. An indicator function
records whether a new update arrives at node
in the time slot before time slot
k.
follows an independent and identical Bernoulli distribution with parameter
.
The nodes transmit status updates the BS through a shared channel. denotes the transmission indicator function, meaning that suggests node i transmits an update to the BS at the beginning of time slot k. The transmission from node i succeeds with probability . An indicator of successful transmission is denoted by . If , the transmission succeeds and the BS receives the update from node i by the end of time slot k.
If at time slot k, node i transmits an update to the BS. with probability and with probability . If , indicating that node i does not transmit to the BS in time slot k, must be 0.
2.1. Age of Synchronization
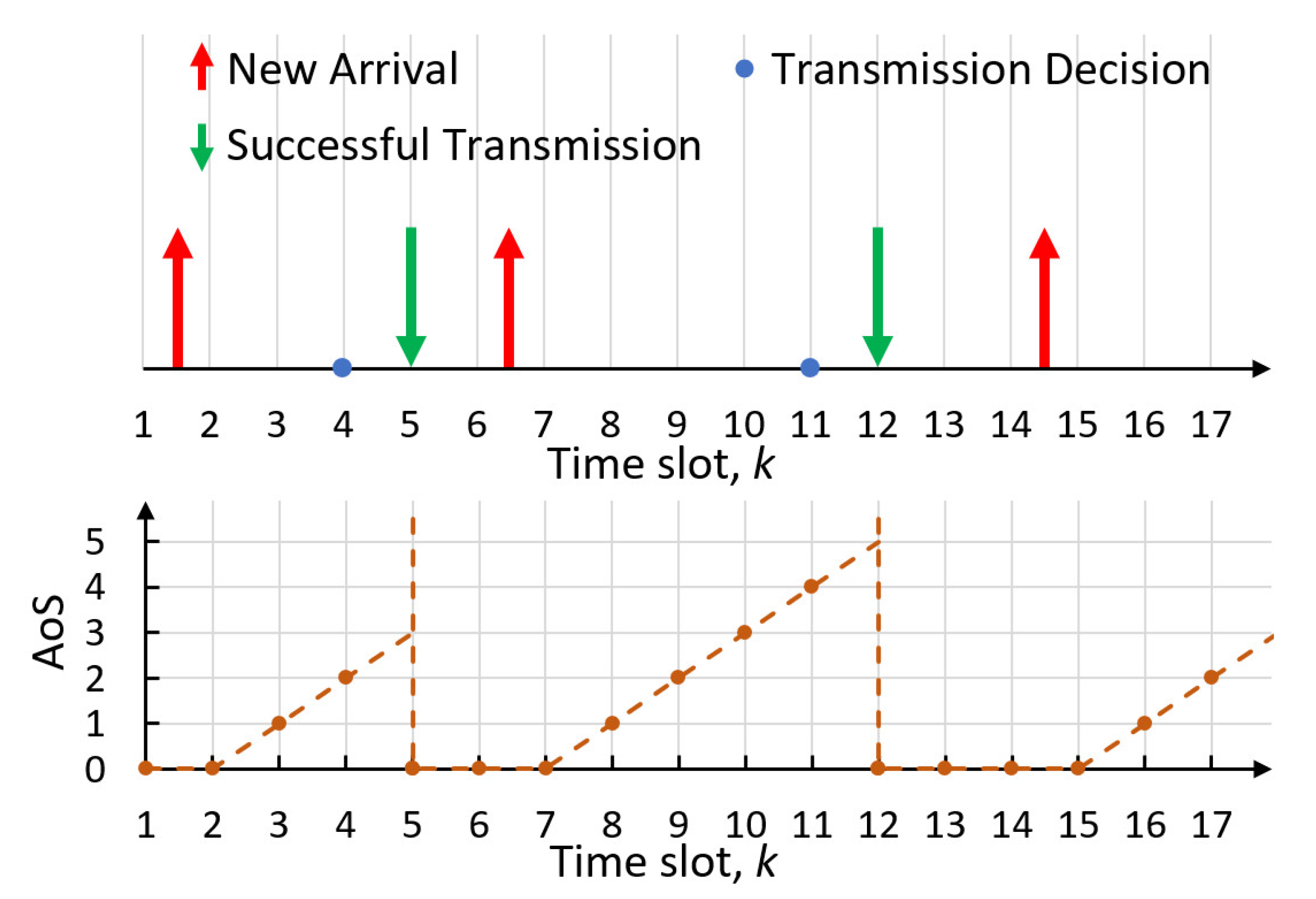
The age of synchronization (AoS) describes the time elapsed since the last time that the newest information at the receiver was synchronized with the transmitter. we define
as the AoS of node
i at the end of time slot
k. The evolution of the AoS with random arrival and successful transmission is illustrated in
Figure 3. While the latest update is successfully transmitted in time slot 5, the AoS of node
i drops to 0 and remains 0 until a new update arrives during time slot 7. Then, the AoS of node
i keeps increasing by 1 in every subsequent time slot until the new update is received by the BS in time slot 12.
As the BS is only interested in the newest updates, each node always transmits the newest updates in the buffer to the BS. The evolution of
follows:
We consider that the AoSs of different nodes have different importance, which is represented by
, and we are interested in the
expected weighted sum AoS of the network. We denote the expected weighted-sum AoS during the first
K time slots under scheduling policy
as
where the expectation is denoted with respect to the randomness of the channel and the scheduling policy.
Without loss of generality, we assume that the sources are synchronized at the beginning, so the initial values of the AoS follow .
2.2. Constraints
We consider that the nodes transmit to the BS through a bandwidth-limited channel and the bandwidth requires that one node at most can transmit in each time slot. This
bandwidth constraint can be formulated as
We consider that each node in the network has a minimum throughput requirement and let
denote the minimum time-average throughput requirement of node
i. The long-term time-average throughput under a specific policy
denoted by
can be computed by
Then, the
throughput constraint can be expressed as
The minimum throughput requirement of the entire network is feasible under the following assumption.
2.3. Optimization Problem
We now formulate the optimization problem as follows.
Equation (
8b) describes the throughput constraints and (
8c) describes the bandwidth constraints. We denote the optimal expected weighted-sum AoS under the AoS-optimal policy as
Then, we give a lower bound of the AoS optimization problem (Equations (
8a)–(
8c)) first. In three different cases, three scheduling policies are proposed.
4. Scheduling Policies
In this section, we propose three scheduling policies. When a central controller schedules the transmissions, we propose the optimal stationary randomized policy in the case where transmission acknowledgement is unused and we propose the max-weight policy in the case where the central controller can get transmission acknowledgement. We consider the BS as the central controller for simplicity. When there is no central scheduling and each node is unaware of the status of the other nodes, we propose the distributed policy.
4.1. Optimal Stationary Randomized Policy
In the case without transmission acknowledgement, the BS cannot compute the AoS of the nodes simultaneously. Therefore, the scheduling policy needs to be independent of the AoS. If a policy is entirely based on probability and will not change with the state of the network, it is called a stationary randomized policy and denoted by . A stationary randomized policy R chooses node i to transmit with probability and keeps idle with probability . has the property that and . Then, we can determine the throughput and AoS of the stationary randomized policy R:
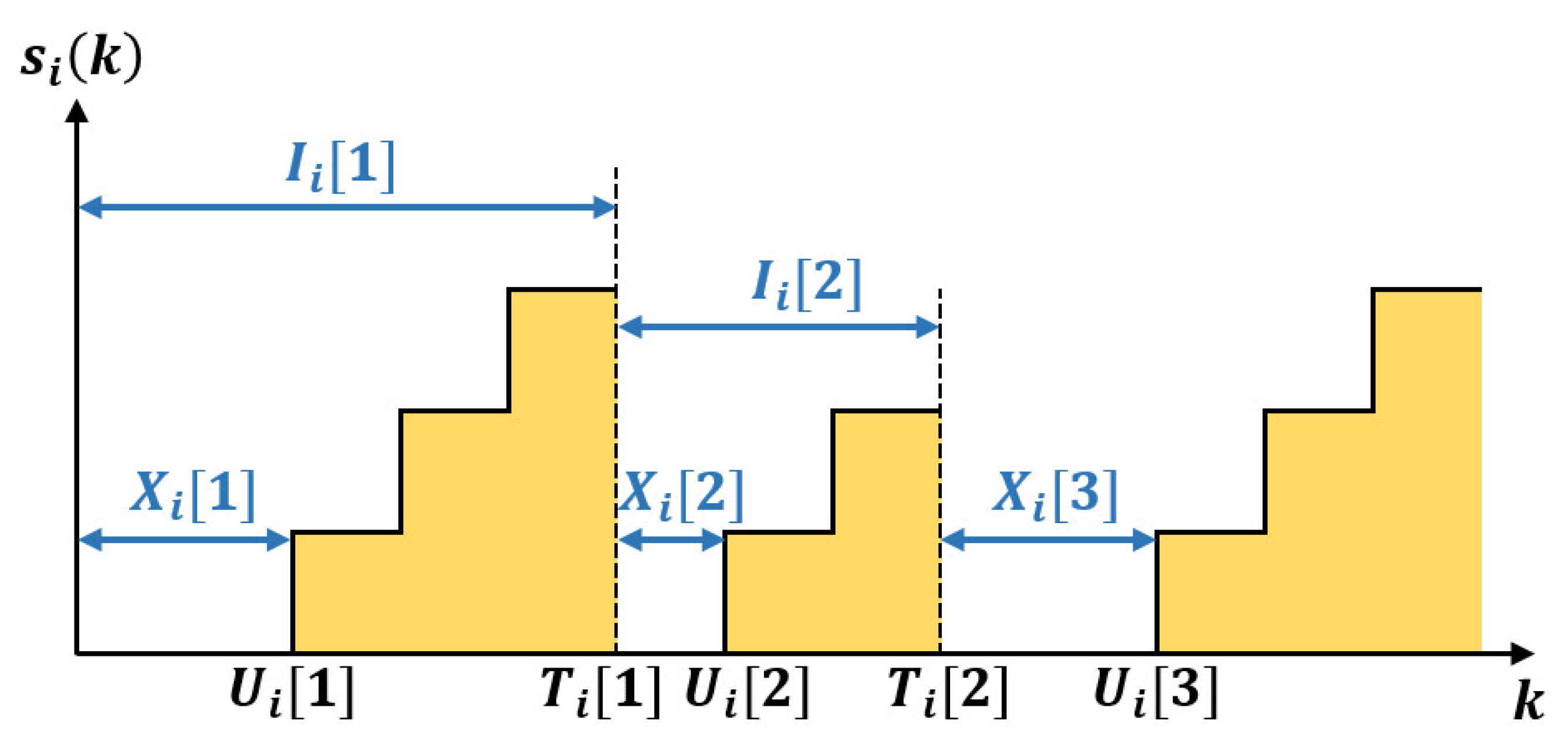
Proposition 1. The long-term throughput and the expected time-average AoS of node i under a policy is Proof. Since the probabilities of both transmitting to node i and transmitting successfully—which refer to and , respectively—are determined and independent, the BS receives an update from node i in a time slot with probability . This implies the long-term throughput . The inter-delivery time now follows a geometric distribution with parameter .
Let the sum AoS during an inter-delivery time
be
, where
if
and
if
.
can be derived by summing over the possible values of waiting time
.
The distribution of
gives
Combining Equations (
27)–(
30), the expectation of
is given as
The inter-delivery times
,
for each node
i are independently identically distributed, so the expected time-average AoS of node
i is equal to the ratio of expectation of
to
, which leads to Equation (
25). □
Substituting Equations (
24) and (
25) into Equations (
8a)–(
8c), the computation of the optimal stationary randomized policy can be formulated as follows.
Problem 2 (AoS optimization over stationary randomized policies).
Compare Equations (
32a)–(
32c) with the lower bound of Equations (
10a)–(
10c). The throughput
solving the lower bound can also satisfy Equations (
32b) and (
32c). Replacing
with
and subtracting the expression in the minimization function of
from that of
gives
Though Equation (
35) is smaller than 0 for
, it is much smaller than the common part
. Therefore,
can be bounded by
adding a small incremental.
Solving Problem 2 means finding the optimal set of scheduling probabilities
. For simplicity, we use
to represent
. Let
,
and
be the Lagrange multiplier. The Lagrange equation is defined as
Then, the KKT conditions are
We change the form of
as follows
can be expressed as the product of two parts that are both positive and monotonically decreasing with
, so
monotonically decreases with
and
. This gives
Combining Equations (
39) and (
42) we get
According to Equation (
38), a node
i indicates whether
or
. If
,
and
. If
, Equation (
42) turns to
. We can derive the monotonicity of
by calculating the second partial derivative of
.
It is clear that and , so and increases monotonically with .
Note that is shared by all , so can be derive by comparing and . When , is the solution of , which is bigger than ; otherwise, it is .
We can get the optimal with the following steps. Start from a large so that , . Now, we have . When decreases to the point that , will be replaced by the solution of , which increases gradually with the decrease in . Let decrease until reaches 1. That is when the solution is reached.
Theorem 2 (Optimal stationary randomized policy).
The optimal stationary randomized policy solving Equations (
32a)–(
32c)
is the set of scheduling probabilities derived from Algorithm 1. | Algorithm 1 Solution to the optimal stationary randomized policy |
- 1:
Initialization: M, , , , and - 2:
, - 3:
- 4:
- 5:
while do - 6:
decrease slightly - 7:
for each do - 8:
if then - 9:
replace by the solution of - 10:
end if - 11:
end for - 12:
end while - 13:
Output: and ,
|
4.2. Max-Weight Policy
When the transmission acknowledgement is used, the BS can make decisions according to the AoS of the network. The idea of the max-weight policy is to optimize the network by controlling the expected increase in the Lyapunov function. The Lyapunov function becomes large with a large AoS or a lack in throughput.
We define the throughput debt
as the difference between the target throughput and the number of actually delivered updates. A large
indicates that node
i needs more transmissions to satisfy the throughput constraint.
If
, node
i leads the target throughput so that the BS has no motivation to choose node
i from the perspective of throughput. Therefore, we just focus on positive
. We use operator
to denote the positive part of the throughput debt
. Then, the throughput constraint can be satisfied when
Define the system state at the beginning of time slot
k as
and the Lyapunov function as
where
V is a positive real number indicating the importance of the throughput constraint. Thus,
grows with the AoS or the throughput debt. We define the Lyapunov drift as
The Lyapunov drift describes the expected change in the Lyapunov function in each time slot, so can be restricted by reducing . To help execute the max-weight policy, an upper bound of is given below.
Proposition 2. The Lyapunov drift can be upper-bounded bywhere Proof. Consider the latter part first. By the definition of
,
Take the expectation and use the property of
:
The next step is dealing with the former part of
.
The inequality is because the AoS remains 0 rather than
if
. So, we have
Combining Equations (
52), (
54), and (
57) completes the proof. □
We can find from the form of Equations (
49)–(
51) that
and
fully depend on the system state
. What our policy controls is the set of
. We want to choose a node
i that can reduce
most to transmit in each time slot. So, the node with the largest
is the optimal choice. That is how max-weight works.
Lemma 1. The max-weight policy satisfies any feasible set of minimum throughput requirements .
Lemma 2 (Upper bound of the max-weight policy).
The optimal expected time-average AoS of the max-weight policy can be upper-bounded by Lemmas 1 and 2 are from Theorems 6 and 7 in [
25]. The upper bound of max-weight is near four times the lower bound in Equations (
10a)–(
10c). Though
has a large upper bound compared to
, it was found in the numerical simulation that max-weight performs much better than the optimal stationary randomized policy.
4.3. Distributed Policy
When the number of nodes increases, it is difficult and costly to apply the centralized policies proposed above. As an alternative, we study the distributed policy, where a node knows neither the system states of the other nodes nor when the other nodes are transmitting. It is possible that more than one node transmits to the BS in the same time slot. So, we first relax the bandwidth constraints (Equation (
8c)) to a time-average constraint
Then, we solve the optimization problem with the Lagrange multiplier method.
Problem 3 (Relaxed AoS optimization).
where
and
C are Lagrange multipliers respectively associated with throughput constraints
and the relaxed bandwidth constraint (Equation (
59)).
The form of Equation (
60a) is independent for each node. Thus, the relaxed optimization problems associated with each individual node can be solved separately. From the perspective of the nodes, each node only considers its own AoS, and the action space is simplified to either transmitting or not in each time slot. As the following proposition shows, the transmission policy has a threshold structure.
Proposition 3. (Threshold policy).
The relaxed optimization problem (Equations (
60a)–(
60c))
for each single node i has an optimal threshold policy. Under the policy, node i chooses to transmit when and to remain idle when in time slot k. For given C and , , and if , the threshold isIf , .
When
, the coefficient of
in the objective function (Equation (
60a)) is
. In that case, node
i will always choose to transmit, as there is no constraint on transmission, which is equivalent to
. When
, the proof of Proposition 3 follows from Appendix E in [
19].
The final issue is how to choose the values of
C and
. In order to examine the influence of the multipliers on the objective function, we can derive a lower bound of
. Let
, as the function will fail to meet the bandwidth constraint otherwise. We use
and
where
Taking the partial derivative of
C and
where
Let Equation (
64) equal 0
Substituting Equation (
67) into (
65), we derive
To maximize
, we can continuously decrease
C until Equation (
65) equals 0. The initial value of
C is given by Equation (
67) and
,
. The values of
C and
can be given by Algorithm 2.
Then, the distributed policy works in the following way. Each node
i monitors its own AoS
and transmits to the BS when
exceeds the threshold
. If multiple nodes attempt to transmit to the BS in a time slot, only one randomly selected node will be able to transmit, and the transmissions of the other nodes will be treated as failures.
| Algorithm 2 Solution of the distributed policy |
- 1:
Initialization: M, , , and - 2:
, - 3:
- 4:
, - 5:
, - 6:
while do - 7:
decrease C slightly - 8:
repeat steps 4 and 5 - 9:
end while - 10:
Output: and ,
|
5. Simulation Results
In this section, we provide simulation results for the optimal stationary randomized policy, the max-weight policy, and the distributed policy. For comparison, we simulated the round robin policy, the largest-weighted-debt-first policy, and the drift-plus-penalty policy. The round robin policy, which has no randomness and functions regardless of the system state, chooses each node that will transmit in turn. The largest-weighted-debt-first policy is proposed in [
26] and chooses the nodes with the highest
in time slot
k. The drift-plus-penalty policy proposed from [
25] chooses the node with the highest
, where
is the age of information of node
i and
is a positive real value associated with node
i. When transmission feedback is unavailable, only the optimal stationary randomized policy and the round robin policy can be used.
We simulated a network with M nodes. Node i has the weight . Arriving rates of the M new updates are evenly distributed between and . The set of channel reliability values is a vector of M evenly spaced points between and . A parameter shows the hardness of the throughput constraints to be satisfied. The set of sums to and is proportional to a set of M evenly spaced points between and . The importance of the throughput constraint in the max-weight was set to .
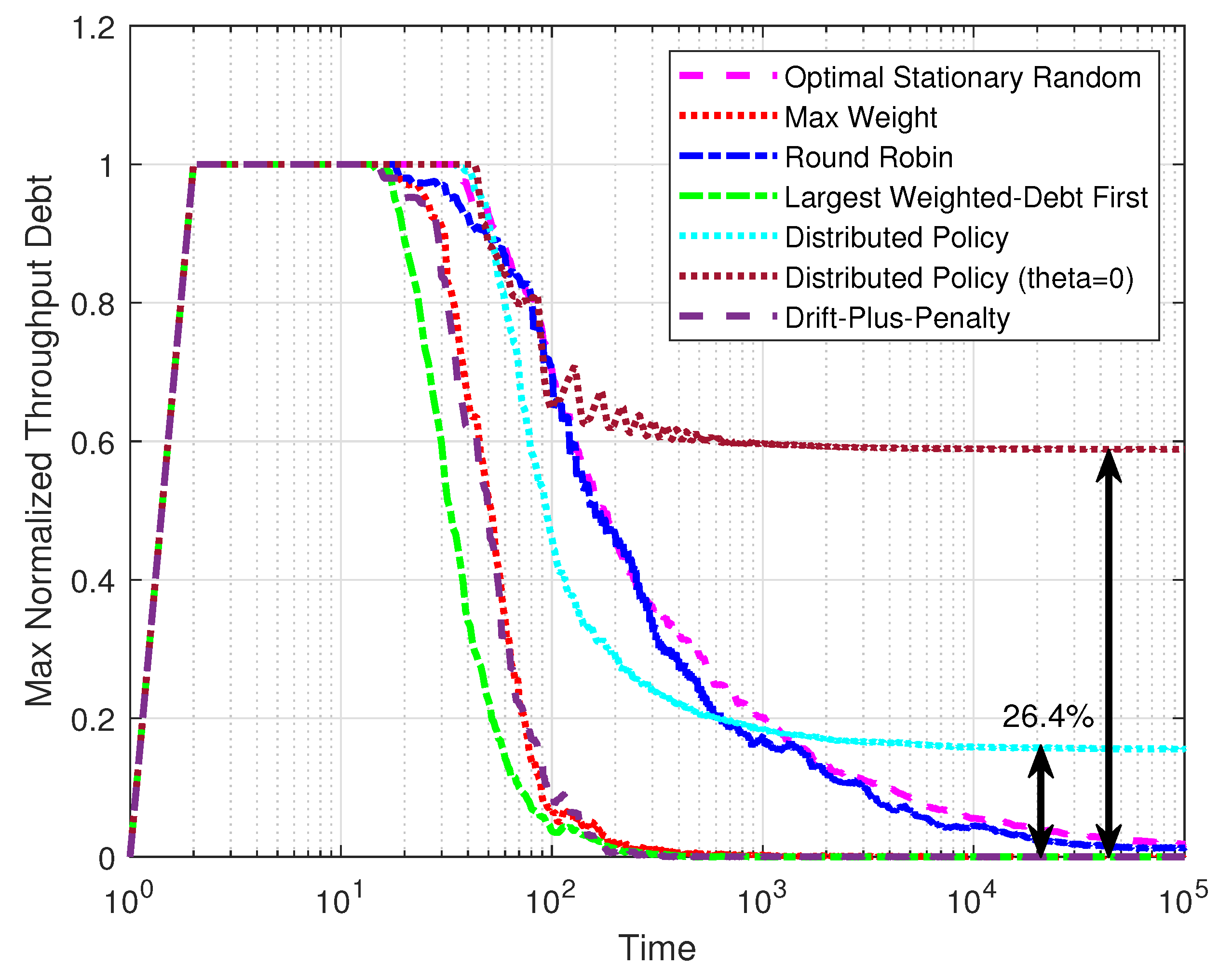
Figure 5 shows the performance of the throughput of the policies over time. The max normalized throughput debt was defined as
. The system was set with
,
, and
, and the results were taken as the average from 100 simulations. After the initial rise, the max normalized throughput debt of the optimal stationary randomized policy, the max-weight policy, the round robin policy, the largest-weighted-debt-first policy, and the drift-plus-penalty policy gradually approached zero with different speeds, which proves that these policies can satisfy throughput constraints in steady state. It is reasonable that the largest-weighted-debt-first policy descended fastest, as its optimization objective is the same as this measurement. Notice that the max normalized throughput debt of the distributed policy could not reach zero, meaning that the distributed policy could not give a throughput guarantee. However, compared with the results for the distributed policy without the multipliers
, our distributed policy has made great progress in meeting the throughput constraints.
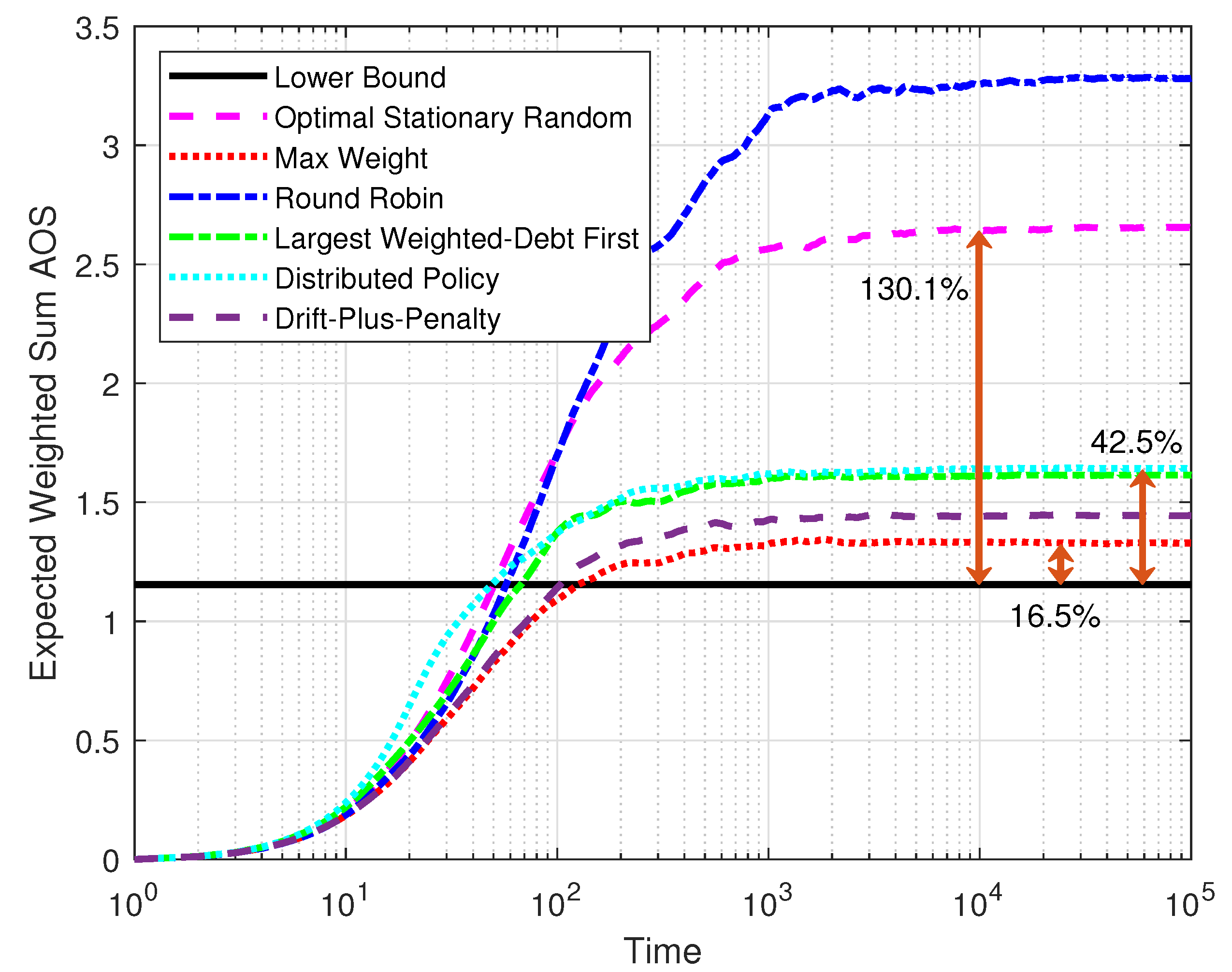
Figure 6 compares the expected weighted-sum AoS of five policies over time and the lower bound defined by Equations (
10a)–(
10c). The system was set with
,
, and
. The results were taken as the average from 100 simulations. The optimal stationary randomized policy and the round robin policy had significant disadvantages compared to the other policies because they are unable to use the system states. However, the optimal stationary randomized policy performed much better than the round robin policy. The steady AoS of the optimal stationary randomized policy was close to twice the lower bound, which matches the previous analysis. When transmission feedback was available, it was clear that max-weight performed best regarding the expected weighted-sum AoS and was close to the lower bound. Though the AoS of the distributed policy grew faster at the beginning due to the threshold structure, it gradually converged to a good level close to the largest-weighted-debt-first policy.
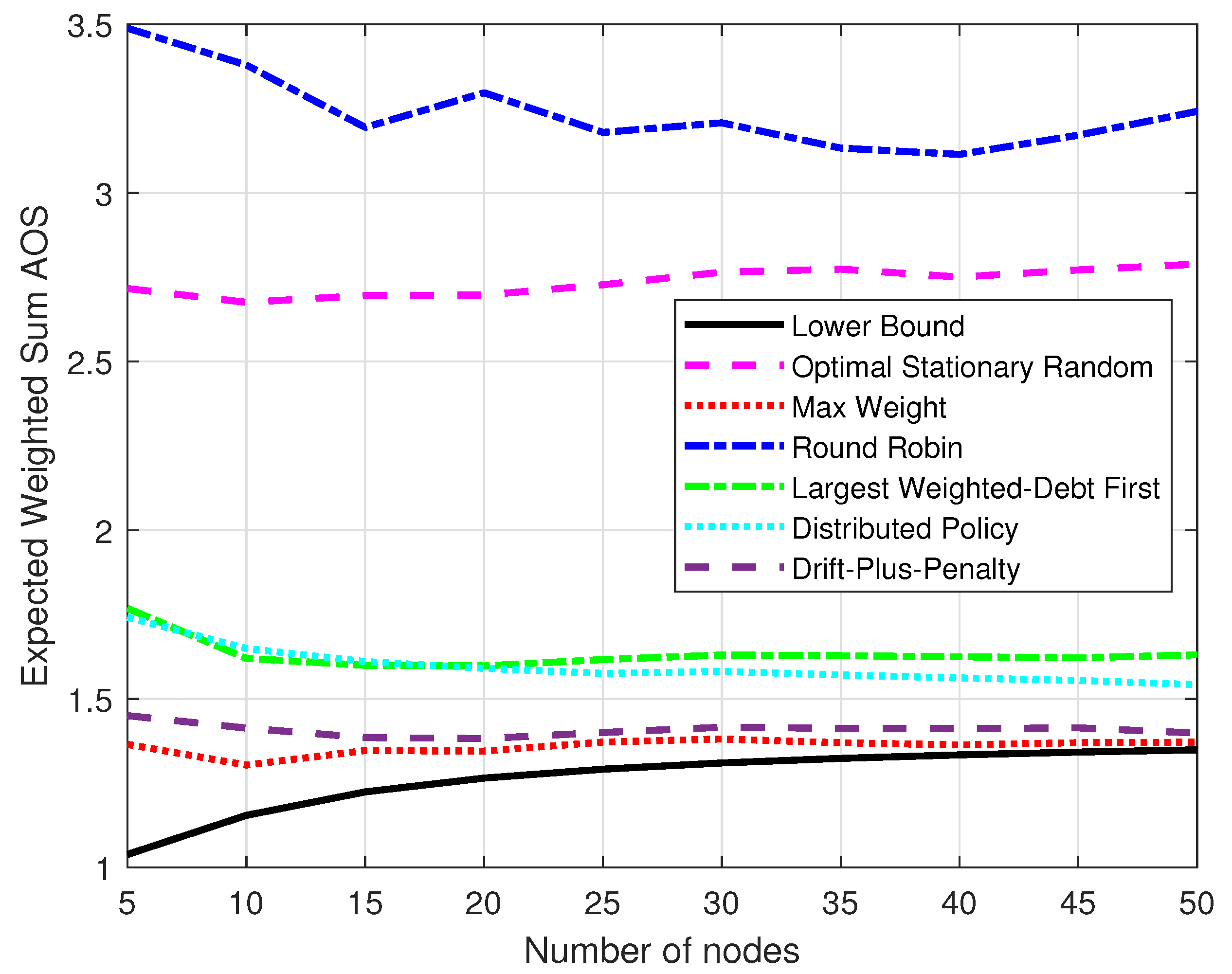
Figure 7 compares the expected weighted-sum AoS of the policies and the lower bound with different numbers of nodes, which were set by
. The total simulation time was
. Each result was the average of the data for the time duration
to
. The hardness of throughput constraints was
. The performance of the six policies generally kept stable gaps and moved closer to the lower bound while the number of nodes grew. When the number of nodes was very large, the distributed policy showed greater potential for progress and the AoS of the max-weight policy was very close to the lower bound.
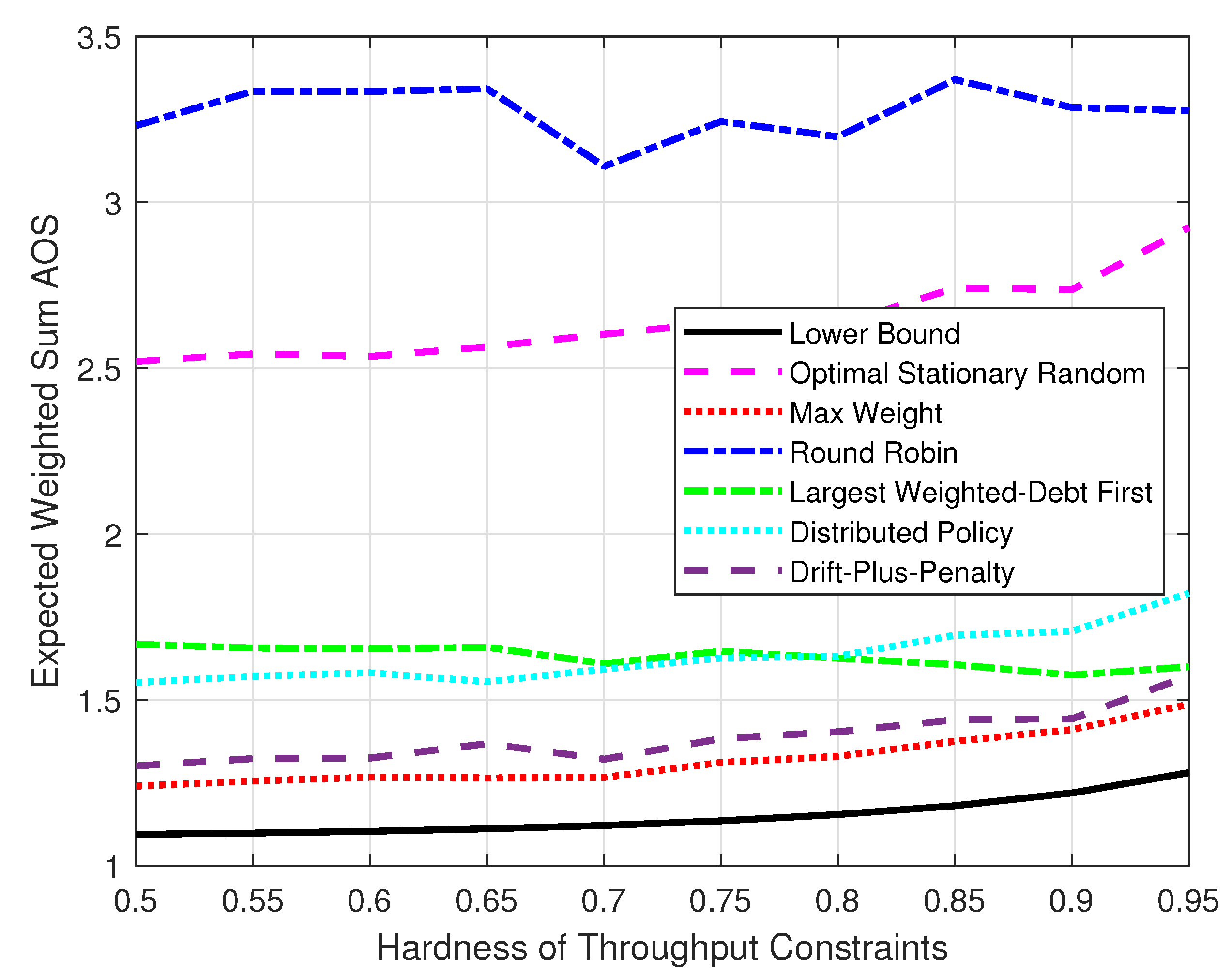
Figure 8 compares the expected weighted-sum AoS under different throughput constraints. We set the hardness of the throughput constraints
to change from
to
. A larger
means the throughput constraints are closer to the upper bound limited by Assumption 1. The system was set with
,
. Each result was the average of the data for the time duration
to
. When the hardness of satisfying the throughput constraints increased, each policy had to prioritize the throughput and had fewer resources available to reduce the AoS. Thus, it can be seen that the gap between the max-weight, the drift-plus-penalty, and the largest-weighted-debt-first policies and the gap between the optimal stationary randomized and round robin policies decreased with the growth in
. The distributed policy showed a similar trend as the max-weight policy.
6. Conclusions
In this study, we investigated a wireless network that transmits time-sensitive data from multiple nodes to a single base station (BS) over a shared imperfect channel while ensuring the minimum throughput requirement of each node. We measured the freshness of information stored at the BS with a metric called the age of synchronization (AoS). The objective of this study was to minimize the time-average AoS of the entire network while meeting the throughput requirement of each node. We proposed three low-complexity scheduling policies under different scenarios: the optimal stationary randomized policy, the max-weight policy, and the distributed policy. Numerical simulations showed that, in the central control scenario, the optimal stationary randomized policy and the max-weight policy could meet the minimum throughput requirement well. In the case where transmission feedback was unavailable to the BS, the optimal stationary randomized policy showed good AoS performance, and when transmission feedback was available, the max-weight policy closely approximated the AoS lower bound. In the distributed scenario, though the throughput requirement could not be guaranteed, the distributed policy made a great contribution toward meeting the throughput requirement and performed well in terms of AoS.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







